

【深度學(xué)習(xí)系列】用Tensorflow實(shí)現(xiàn)經(jīng)典CNN網(wǎng)絡(luò)GoogLeNet
前面講了LeNet、AlexNet和Vgg,這周來(lái)講講GoogLeNet。GoogLeNet是由google的Christian Szegedy等人在2014年的論文《Going Deeper with Convolutions》提出,其最大的亮點(diǎn)是提出一種叫Inception的結(jié)構(gòu),以此為基礎(chǔ)構(gòu)建GoogLeNet,并在當(dāng)年的ImageNet分類(lèi)和檢測(cè)任務(wù)中獲得第一,ps:GoogLeNet的取名是為了向YannLeCun的LeNet系列致敬。
(本系列所有代碼均在github:https://github.com/huxiaoman7/PaddlePaddle_code)
關(guān)于深度網(wǎng)絡(luò)的一些思考
在本系列最開(kāi)始的幾篇文章我們講到了卷積神經(jīng)網(wǎng)絡(luò),設(shè)計(jì)的網(wǎng)絡(luò)結(jié)構(gòu)也非常簡(jiǎn)單,屬于淺層神經(jīng)網(wǎng)絡(luò),如三層的卷積神經(jīng)網(wǎng)絡(luò)等,但是在層數(shù)比較少的時(shí)候,有時(shí)候效果往往并沒(méi)有那么好,在實(shí)驗(yàn)過(guò)程中發(fā)現(xiàn),當(dāng)我們嘗試增加網(wǎng)絡(luò)的層數(shù),或者增加每一層網(wǎng)絡(luò)的神經(jīng)元個(gè)數(shù)的時(shí)候,對(duì)準(zhǔn)確率有一定的提升,簡(jiǎn)單的說(shuō)就是增加網(wǎng)絡(luò)的深度與寬度,但這樣做有兩個(gè)明顯的缺點(diǎn):
- 更深更寬的網(wǎng)絡(luò)意味著更多的參數(shù),提高了模型的復(fù)雜度,從而大大增加過(guò)擬合的風(fēng)險(xiǎn),尤其在訓(xùn)練數(shù)據(jù)不是那么多或者某個(gè)label訓(xùn)練數(shù)據(jù)不足的情況下更容易發(fā)生;
- 增加計(jì)算資源的消耗,實(shí)際情況下,不管是因?yàn)閿?shù)據(jù)稀疏還是擴(kuò)充的網(wǎng)絡(luò)結(jié)構(gòu)利用不充分(比如很多權(quán)重接近0),都會(huì)導(dǎo)致大量計(jì)算的浪費(fèi)。
解決以上兩個(gè)問(wèn)題的基本方法是將全連接或卷積連接改為稀疏連接。不管從生物的角度還是機(jī)器學(xué)習(xí)的角度,稀疏性都有良好的表現(xiàn),回想一下在講AlexNet這一節(jié)提出的Dropout網(wǎng)絡(luò)以及ReLU激活函數(shù),其本質(zhì)就是利用稀疏性提高模型泛化性(但需要計(jì)算的參數(shù)沒(méi)變少)。
簡(jiǎn)單解釋下稀疏性,當(dāng)整個(gè)特征空間是非線性甚至不連續(xù)時(shí):
- 學(xué)好局部空間的特征集更能提升性能,類(lèi)似于Maxout網(wǎng)絡(luò)中使用多個(gè)局部線性函數(shù)的組合來(lái)擬合非線性函數(shù)的思想;
- 假設(shè)整個(gè)特征空間由N個(gè)不連續(xù)局部特征空間集合組成,任意一個(gè)樣本會(huì)被映射到這N個(gè)空間中并激活/不激活相應(yīng)特征維度,如果用C1表示某類(lèi)樣本被激活的特征維度集合,用C2表示另一類(lèi)樣本的特征維度集合,當(dāng)數(shù)據(jù)量不夠大時(shí),要想增加特征區(qū)分度并很好的區(qū)分兩類(lèi)樣本,就要降低C1和C2的重合度(比如可用Jaccard距離衡量),即縮小C1和C2的大小,意味著相應(yīng)的特征維度集會(huì)變稀疏。
不過(guò)尷尬的是,現(xiàn)在的計(jì)算機(jī)體系結(jié)構(gòu)更善于稠密數(shù)據(jù)的計(jì)算,而在非均勻分布的稀疏數(shù)據(jù)上的計(jì)算效率極差,比如稀疏性會(huì)導(dǎo)致的緩存miss率極高,于是需要一種方法既能發(fā)揮稀疏網(wǎng)絡(luò)的優(yōu)勢(shì)又能保證計(jì)算效率。好在前人做了大量實(shí)驗(yàn)(如《On Two-Dimensional Sparse Matrix Partitioning: Models, Methods, and a Recipe》),發(fā)現(xiàn)對(duì)稀疏矩陣做聚類(lèi)得到相對(duì)稠密的子矩陣可以大幅提高稀疏矩陣乘法性能,借鑒這個(gè)思想,作者提出Inception的結(jié)構(gòu)。
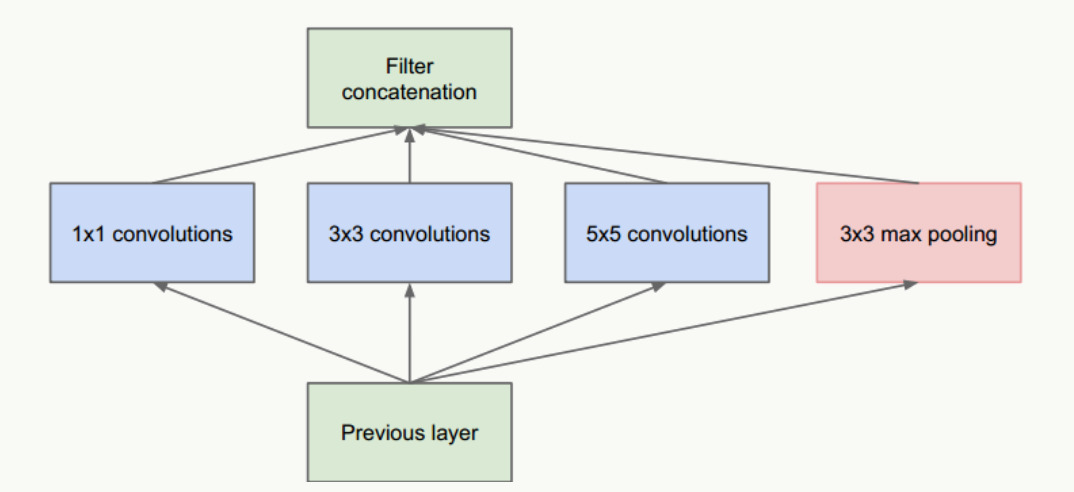
圖1 Inception結(jié)構(gòu)
- 把不同大小卷積核抽象得到的特征空間看做子特征空間,每個(gè)子特征空間都是稀疏的,把這些不同尺度特征做融合,相當(dāng)于得到一個(gè)相對(duì)稠密的空間;
- 采用1×1、3×3、5×5卷積核(不是必須的,也可以是其他大小),stride取1,利用padding可以方便的做輸出特征維度對(duì)齊;
- 大量事實(shí)表明pooling層能有效提高卷積網(wǎng)絡(luò)的效果,所以加了一條max pooling路徑;
- 這個(gè)結(jié)構(gòu)符合直觀理解,視覺(jué)信息通過(guò)不同尺度的變換被聚合起來(lái)作為下一階段的特征,比如:人的高矮、胖瘦、青老信息被聚合后做下一步判斷。
這個(gè)網(wǎng)絡(luò)的最大問(wèn)題是5×5卷積帶來(lái)了巨大計(jì)算負(fù)擔(dān),例如,假設(shè)上層輸入為:28×28×192:
- 直接經(jīng)過(guò)96個(gè)5×5卷積層(stride=1,padding=2)后,輸出為:28×28×96,卷積層參數(shù)量為:192×5×5×96=460800;
- 借鑒NIN網(wǎng)絡(luò)(Network in Network,后續(xù)會(huì)講),在5×5卷積前使用32個(gè)1×1卷積核做維度縮減,變成28×28×32,之后經(jīng)過(guò)96個(gè)5×5卷積層(stride=1,padding=2)后,輸出為:28×28×96,但所有卷積層的參數(shù)量為:192×1×1×32+32×5×5×96=82944,可見(jiàn)整個(gè)參數(shù)量是原來(lái)的1/5.5,且效果上沒(méi)有多少損失。
新網(wǎng)絡(luò)結(jié)構(gòu)為

圖2 新Inception結(jié)構(gòu)
GoogLeNet網(wǎng)絡(luò)結(jié)構(gòu)
利用上述Inception模塊構(gòu)建GoogLeNet,實(shí)驗(yàn)表明Inception模塊出現(xiàn)在高層特征抽象時(shí)會(huì)更加有效(我理解由于其結(jié)構(gòu)特點(diǎn),更適合提取高階特征,讓它提取低階特征會(huì)導(dǎo)致特征信息丟失),所以在低層依然使用傳統(tǒng)卷積層。整個(gè)網(wǎng)路結(jié)構(gòu)如下:
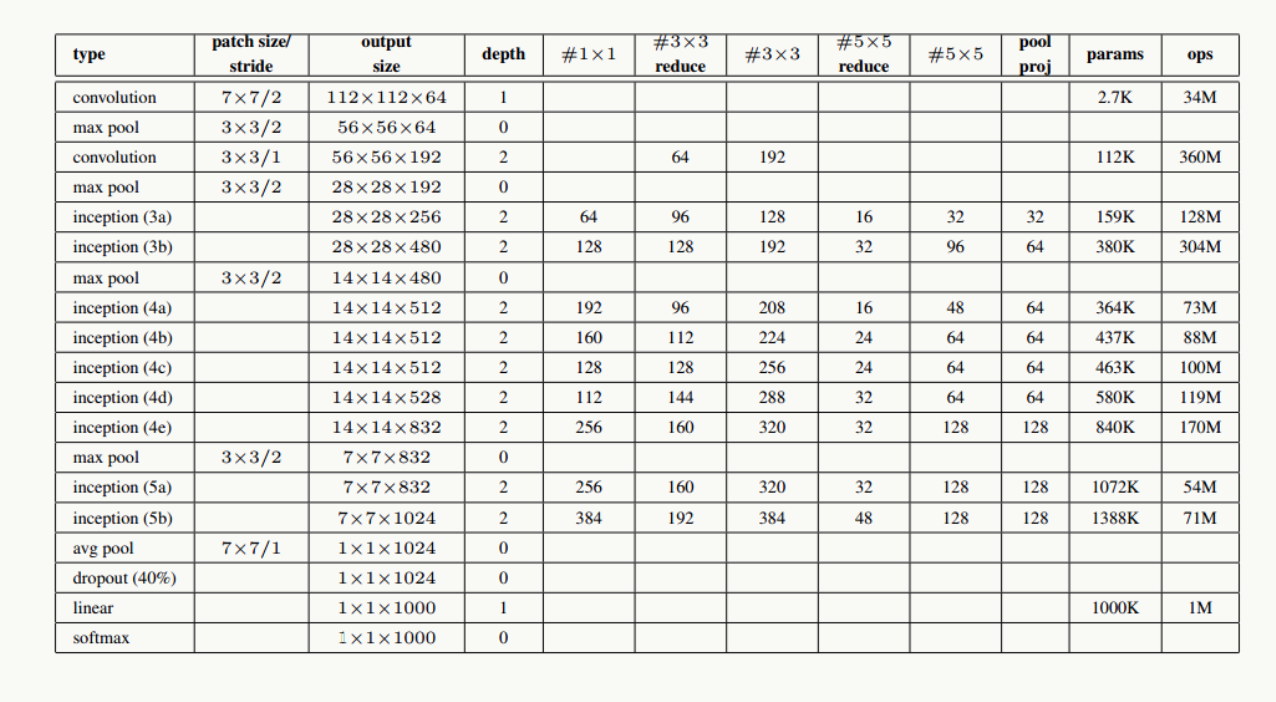
圖3 GoogLeNet網(wǎng)絡(luò)結(jié)構(gòu)

圖4 GoogLeNet詳細(xì)網(wǎng)絡(luò)結(jié)構(gòu)示意圖
網(wǎng)絡(luò)說(shuō)明:
- 所有卷積層均使用ReLU激活函數(shù),包括做了1×1卷積降維后的激活;
- 移除全連接層,像NIN一樣使用Global Average Pooling,使得Top 1準(zhǔn)確率提高0.6%,但由于GAP與類(lèi)別數(shù)目有關(guān)系,為了方便大家做模型fine-tuning,最后加了一個(gè)全連接層;
- 與前面的ResNet類(lèi)似,實(shí)驗(yàn)觀察到,相對(duì)淺層的神經(jīng)網(wǎng)絡(luò)層對(duì)模型效果有較大的貢獻(xiàn),訓(xùn)練階段通過(guò)對(duì)Inception(4a、4d)增加兩個(gè)額外的分類(lèi)器來(lái)增強(qiáng)反向傳播時(shí)的梯度信號(hào),但最重要的還是正則化作用,這一點(diǎn)在GoogLeNet v3中得到實(shí)驗(yàn)證實(shí),并間接證實(shí)了GoogLeNet V2中BN的正則化作用,這兩個(gè)分類(lèi)器的loss會(huì)以0.3的權(quán)重加在整體loss上,在模型inference階段,這兩個(gè)分類(lèi)器會(huì)被去掉;
- 用于降維的1×1卷積核個(gè)數(shù)為128個(gè);
- 全連接層使用1024個(gè)神經(jīng)元;
- 使用丟棄概率為0.7的Dropout層;
網(wǎng)絡(luò)結(jié)構(gòu)詳細(xì)說(shuō)明:
輸入數(shù)據(jù)為224×224×3的RGB圖像,圖中"S"代表做same-padding,"V"代表不做。
- C1卷積層:64個(gè)7×7卷積核(stride=2,padding=3),輸出為:112×112×64;
- P1抽樣層:64個(gè)3×3卷積核(stride=2),輸出為56×56×64,其中:56=(112-3+1)/2+1
- C2卷積層:192個(gè)3×3卷積核(stride=1,padding=1),輸出為:56×56×192;
- P2抽樣層:192個(gè)3×3卷積核(stride=2),輸出為28×28×192,其中:28=(56-3+1)/2+1,接著數(shù)據(jù)被分出4個(gè)分支,進(jìn)入Inception (3a)
- Inception (3a):由4部分組成
- 64個(gè)1×1的卷積核,輸出為28×28×64;
- 96個(gè)1×1的卷積核做降維,輸出為28×28×96,之后128個(gè)3×3卷積核(stride=1,padding=1),輸出為:28×28×128
- 16個(gè)1×1的卷積核做降維,輸出為28×28×16,之后32個(gè)5×5卷積核(stride=1,padding=2),輸出為:28×28×32
- 192個(gè)3×3卷積核(stride=1,padding=1),輸出為28×28×192,進(jìn)行32個(gè)1×1卷積核,輸出為:28×28×32
最后對(duì)4個(gè)分支的輸出做“深度”方向組合,得到輸出28×28×256,接著數(shù)據(jù)被分出4個(gè)分支,進(jìn)入Inception (3b);- Inception (3b):由4部分組成
- 128個(gè)1×1的卷積核,輸出為28×28×128;
- 128個(gè)1×1的卷積核做降維,輸出為28×28×128,進(jìn)行192個(gè)3×3卷積核(stride=1,padding=1),輸出為:28×28×192
- 32個(gè)1×1的卷積核做降維,輸出為28×28×32,進(jìn)行96個(gè)5×5卷積核(stride=1,padding=2),輸出為:28×28×96
- 256個(gè)3×3卷積核(stride=1,padding=1),輸出為28×28×256,進(jìn)行64個(gè)1×1卷積核,輸出為:28×28×64
最后對(duì)4個(gè)分支的輸出做“深度”方向組合,得到輸出28×28×480;
后面結(jié)構(gòu)以此類(lèi)推。
用PaddlePaddle實(shí)現(xiàn)GoogLeNet
1.網(wǎng)絡(luò)結(jié)構(gòu) googlenet.py
在PaddlePaddle的models下面,有關(guān)于GoogLeNet的實(shí)現(xiàn)代碼,大家可以直接學(xué)習(xí)拿來(lái)跑一下:
1 import paddle.v2 as paddle 2 3 __all__ = ['googlenet'] 4 5 6 def inception(name, input, channels, filter1, filter3R, filter3, filter5R, 7 filter5, proj): 8 cov1 = paddle.layer.img_conv( 9 name=name + '_1', 10 input=input, 11 filter_size=1, 12 num_channels=channels, 13 num_filters=filter1, 14 stride=1, 15 padding=0) 16 17 cov3r = paddle.layer.img_conv( 18 name=name + '_3r', 19 input=input, 20 filter_size=1, 21 num_channels=channels, 22 num_filters=filter3R, 23 stride=1, 24 padding=0) 25 cov3 = paddle.layer.img_conv( 26 name=name + '_3', 27 input=cov3r, 28 filter_size=3, 29 num_filters=filter3, 30 stride=1, 31 padding=1) 32 33 cov5r = paddle.layer.img_conv( 34 name=name + '_5r', 35 input=input, 36 filter_size=1, 37 num_channels=channels, 38 num_filters=filter5R, 39 stride=1, 40 padding=0) 41 cov5 = paddle.layer.img_conv( 42 name=name + '_5', 43 input=cov5r, 44 filter_size=5, 45 num_filters=filter5, 46 stride=1, 47 padding=2) 48 49 pool1 = paddle.layer.img_pool( 50 name=name + '_max', 51 input=input, 52 pool_size=3, 53 num_channels=channels, 54 stride=1, 55 padding=1) 56 covprj = paddle.layer.img_conv( 57 name=name + '_proj', 58 input=pool1, 59 filter_size=1, 60 num_filters=proj, 61 stride=1, 62 padding=0) 63 64 cat = paddle.layer.concat(name=name, input=[cov1, cov3, cov5, covprj]) 65 return cat 66 67 68 def googlenet(input, class_dim): 69 # stage 1 70 conv1 = paddle.layer.img_conv( 71 name="conv1", 72 input=input, 73 filter_size=7, 74 num_channels=3, 75 num_filters=64, 76 stride=2, 77 padding=3) 78 pool1 = paddle.layer.img_pool( 79 name="pool1", input=conv1, pool_size=3, num_channels=64, stride=2) 80 81 # stage 2 82 conv2_1 = paddle.layer.img_conv( 83 name="conv2_1", 84 input=pool1, 85 filter_size=1, 86 num_filters=64, 87 stride=1, 88 padding=0) 89 conv2_2 = paddle.layer.img_conv( 90 name="conv2_2", 91 input=conv2_1, 92 filter_size=3, 93 num_filters=192, 94 stride=1, 95 padding=1) 96 pool2 = paddle.layer.img_pool( 97 name="pool2", input=conv2_2, pool_size=3, num_channels=192, stride=2) 98 99 # stage 3 100 ince3a = inception("ince3a", pool2, 192, 64, 96, 128, 16, 32, 32) 101 ince3b = inception("ince3b", ince3a, 256, 128, 128, 192, 32, 96, 64) 102 pool3 = paddle.layer.img_pool( 103 name="pool3", input=ince3b, num_channels=480, pool_size=3, stride=2) 104 105 # stage 4 106 ince4a = inception("ince4a", pool3, 480, 192, 96, 208, 16, 48, 64) 107 ince4b = inception("ince4b", ince4a, 512, 160, 112, 224, 24, 64, 64) 108 ince4c = inception("ince4c", ince4b, 512, 128, 128, 256, 24, 64, 64) 109 ince4d = inception("ince4d", ince4c, 512, 112, 144, 288, 32, 64, 64) 110 ince4e = inception("ince4e", ince4d, 528, 256, 160, 320, 32, 128, 128) 111 pool4 = paddle.layer.img_pool( 112 name="pool4", input=ince4e, num_channels=832, pool_size=3, stride=2) 113 114 # stage 5 115 ince5a = inception("ince5a", pool4, 832, 256, 160, 320, 32, 128, 128) 116 ince5b = inception("ince5b", ince5a, 832, 384, 192, 384, 48, 128, 128) 117 pool5 = paddle.layer.img_pool( 118 name="pool5", 119 input=ince5b, 120 num_channels=1024, 121 pool_size=7, 122 stride=7, 123 pool_type=paddle.pooling.Avg()) 124 dropout = paddle.layer.addto( 125 input=pool5, 126 layer_attr=paddle.attr.Extra(drop_rate=0.4), 127 act=paddle.activation.Linear()) 128 129 out = paddle.layer.fc( 130 input=dropout, size=class_dim, act=paddle.activation.Softmax()) 131 132 # fc for output 1 133 pool_o1 = paddle.layer.img_pool( 134 name="pool_o1", 135 input=ince4a, 136 num_channels=512, 137 pool_size=5, 138 stride=3, 139 pool_type=paddle.pooling.Avg()) 140 conv_o1 = paddle.layer.img_conv( 141 name="conv_o1", 142 input=pool_o1, 143 filter_size=1, 144 num_filters=128, 145 stride=1, 146 padding=0) 147 fc_o1 = paddle.layer.fc( 148 name="fc_o1", 149 input=conv_o1, 150 size=1024, 151 layer_attr=paddle.attr.Extra(drop_rate=0.7), 152 act=paddle.activation.Relu()) 153 out1 = paddle.layer.fc( 154 input=fc_o1, size=class_dim, act=paddle.activation.Softmax()) 155 156 # fc for output 2 157 pool_o2 = paddle.layer.img_pool( 158 name="pool_o2", 159 input=ince4d, 160 num_channels=528, 161 pool_size=5, 162 stride=3, 163 pool_type=paddle.pooling.Avg()) 164 conv_o2 = paddle.layer.img_conv( 165 name="conv_o2", 166 input=pool_o2, 167 filter_size=1, 168 num_filters=128, 169 stride=1, 170 padding=0) 171 fc_o2 = paddle.layer.fc( 172 name="fc_o2", 173 input=conv_o2, 174 size=1024, 175 layer_attr=paddle.attr.Extra(drop_rate=0.7), 176 act=paddle.activation.Relu()) 177 out2 = paddle.layer.fc( 178 input=fc_o2, size=class_dim, act=paddle.activation.Softmax()) 179 180 return out, out1, out2
2.訓(xùn)練模型
1 import gzip 2 import paddle.v2.dataset.flowers as flowers 3 import paddle.v2 as paddle 4 import reader 5 import vgg 6 import resnet 7 import alexnet 8 import googlenet 9 import argparse 10 11 DATA_DIM = 3 * 224 * 224 12 CLASS_DIM = 102 13 BATCH_SIZE = 128 14 15 16 def main(): 17 # parse the argument 18 parser = argparse.ArgumentParser() 19 parser.add_argument( 20 'model', 21 help='The model for image classification', 22 choices=['alexnet', 'vgg13', 'vgg16', 'vgg19', 'resnet', 'googlenet']) 23 args = parser.parse_args() 24 25 # PaddlePaddle init 26 paddle.init(use_gpu=True, trainer_count=7) 27 28 image = paddle.layer.data( 29 name="image", type=paddle.data_type.dense_vector(DATA_DIM)) 30 lbl = paddle.layer.data( 31 name="label", type=paddle.data_type.integer_value(CLASS_DIM)) 32 33 extra_layers = None 34 learning_rate = 0.01 35 if args.model == 'alexnet': 36 out = alexnet.alexnet(image, class_dim=CLASS_DIM) 37 elif args.model == 'vgg13': 38 out = vgg.vgg13(image, class_dim=CLASS_DIM) 39 elif args.model == 'vgg16': 40 out = vgg.vgg16(image, class_dim=CLASS_DIM) 41 elif args.model == 'vgg19': 42 out = vgg.vgg19(image, class_dim=CLASS_DIM) 43 elif args.model == 'resnet': 44 out = resnet.resnet_imagenet(image, class_dim=CLASS_DIM) 45 learning_rate = 0.1 46 elif args.model == 'googlenet': 47 out, out1, out2 = googlenet.googlenet(image, class_dim=CLASS_DIM) 48 loss1 = paddle.layer.cross_entropy_cost( 49 input=out1, label=lbl, coeff=0.3) 50 paddle.evaluator.classification_error(input=out1, label=lbl) 51 loss2 = paddle.layer.cross_entropy_cost( 52 input=out2, label=lbl, coeff=0.3) 53 paddle.evaluator.classification_error(input=out2, label=lbl) 54 extra_layers = [loss1, loss2] 55 56 cost = paddle.layer.classification_cost(input=out, label=lbl) 57 58 # Create parameters 59 parameters = paddle.parameters.create(cost) 60 61 # Create optimizer 62 optimizer = paddle.optimizer.Momentum( 63 momentum=0.9, 64 regularization=paddle.optimizer.L2Regularization(rate=0.0005 * 65 BATCH_SIZE), 66 learning_rate=learning_rate / BATCH_SIZE, 67 learning_rate_decay_a=0.1, 68 learning_rate_decay_b=128000 * 35, 69 learning_rate_schedule="discexp", ) 70 71 train_reader = paddle.batch( 72 paddle.reader.shuffle( 73 flowers.train(), 74 # To use other data, replace the above line with: 75 # reader.train_reader('train.list'), 76 buf_size=1000), 77 batch_size=BATCH_SIZE) 78 test_reader = paddle.batch( 79 flowers.valid(), 80 # To use other data, replace the above line with: 81 # reader.test_reader('val.list'), 82 batch_size=BATCH_SIZE) 83 84 # Create trainer 85 trainer = paddle.trainer.SGD( 86 cost=cost, 87 parameters=parameters, 88 update_equation=optimizer, 89 extra_layers=extra_layers) 90 91 # End batch and end pass event handler 92 def event_handler(event): 93 if isinstance(event, paddle.event.EndIteration): 94 if event.batch_id % 1 == 0: 95 print "\nPass %d, Batch %d, Cost %f, %s" % ( 96 event.pass_id, event.batch_id, event.cost, event.metrics) 97 if isinstance(event, paddle.event.EndPass): 98 with gzip.open('params_pass_%d.tar.gz' % event.pass_id, 'w') as f: 99 trainer.save_parameter_to_tar(f) 100 101 result = trainer.test(reader=test_reader) 102 print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics) 103 104 trainer.train( 105 reader=train_reader, num_passes=200, event_handler=event_handler) 106 107 108 if __name__ == '__main__': 109 main()
3.運(yùn)行方式
1 python train.py googlenet
其中最后的googlenet是可選的網(wǎng)絡(luò)模型,輸入其他的網(wǎng)絡(luò)模型,如alexnet、vgg3、vgg6等就可以用不同的網(wǎng)絡(luò)結(jié)構(gòu)來(lái)訓(xùn)練了。
用Tensorflow實(shí)現(xiàn)GoogLeNet
tensorflow的實(shí)現(xiàn)在models里有非常詳細(xì)的代碼,這里就不全部貼出來(lái)了,大家可以在models/research/slim/nets/ 里詳細(xì)看看,關(guān)于InceptionV1~InceptionV4的實(shí)現(xiàn)都有。
ps:這里的slim不是tensorflow的contrib下的slim,是models下的slim,別弄混了,slim可以理解為T(mén)ensorflow的一個(gè)高階api,在構(gòu)建這些復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)時(shí),可以直接調(diào)用slim封裝好的網(wǎng)絡(luò)結(jié)構(gòu)就可以了,而不需要從頭開(kāi)始寫(xiě)整個(gè)網(wǎng)絡(luò)結(jié)構(gòu)。關(guān)于slim的詳細(xì)大家可以在網(wǎng)上搜索,非常方便。
總結(jié)
其實(shí)GoogLeNet的最關(guān)鍵的一點(diǎn)就是提出了Inception結(jié)構(gòu),這有個(gè)什么好處呢,原來(lái)你想要提高準(zhǔn)確率,需要堆疊更深的層,增加神經(jīng)元個(gè)數(shù)等,堆疊到一定層可能結(jié)果的準(zhǔn)確率就提不上去了,因?yàn)閰?shù)更多了啊,模型更復(fù)雜,更容易過(guò)擬合了,但是在實(shí)驗(yàn)中轉(zhuǎn)向了更稀疏但是更精密的結(jié)構(gòu)同樣可以達(dá)到很好的效果,說(shuō)明我們可以照著這個(gè)思路走,繼續(xù)做,所以后面會(huì)有InceptionV2 ,V3,V4等,它表現(xiàn)的結(jié)果也非常好。給我們傳統(tǒng)的通過(guò)堆疊層提高準(zhǔn)確率的想法提供了一個(gè)新的思路。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)