
深度學(xué)習(xí)基礎(chǔ)課:最大池化層的后向傳播推導(dǎo)
大家好~本課程為“深度學(xué)習(xí)基礎(chǔ)班”的線上課程,帶領(lǐng)同學(xué)從0開始學(xué)習(xí)全連接和卷積神經(jīng)網(wǎng)絡(luò),進(jìn)行數(shù)學(xué)推導(dǎo),并且實(shí)現(xiàn)可以運(yùn)行的Demo程序
線上課程資料:
加QQ群,獲得ppt等資料,與群主交流討論:106047770
本系列文章為線上課程的復(fù)盤,每上完一節(jié)課就會(huì)同步發(fā)布對(duì)應(yīng)的文章
本課程系列文章可進(jìn)入索引查看:
目錄
回顧相關(guān)課程內(nèi)容
- 最大池化層的前向傳播算法是什么?
為什么要學(xué)習(xí)本課
- 如何推導(dǎo)最大池化層的后向傳播?
主問題:如何推導(dǎo)最大池化層的后向傳播?
- 最大池化層的后向傳播算法有哪些步驟?
答:只有一步:已知下一層計(jì)算的誤差項(xiàng),反向依次計(jì)算這一層的誤差項(xiàng)
(因?yàn)檫@一層沒有權(quán)重值,所以不需要計(jì)算這一層中的梯度)
主問題:如何反向計(jì)算誤差項(xiàng)?

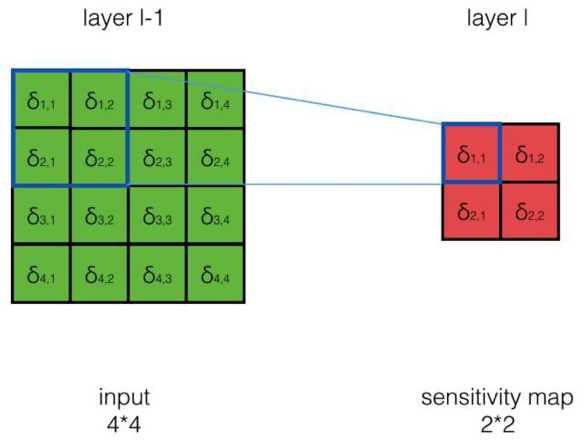
- 如何求\(\delta_{i,j}^{l-1} = \frac{dE}{dnet_{i,j}^{l-1}}\) = ?
答:我們先來考察一個(gè)具體的例子,然后再總結(jié)一般性的規(guī)律- 如何求\(\delta_{1,1}^{l-1} = \frac{dE}{dnet_{1,1}^{l-1}}\) = ?其中\(net_{1,1}^{l-1}對(duì)哪些net_{i,j}^l有影響?\)
答:

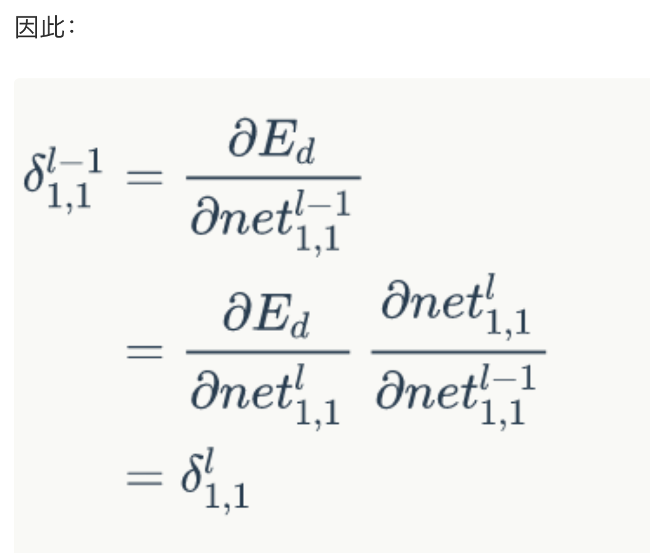
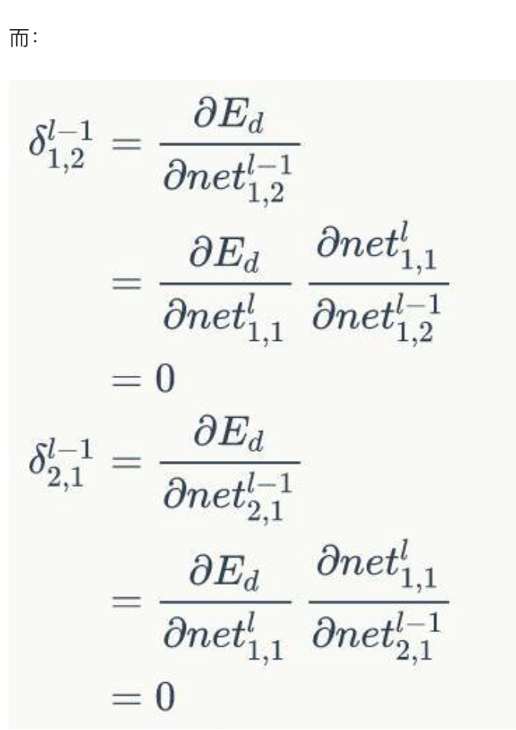
- 如何求\(\delta_{1,1}^{l-1} = \frac{dE}{dnet_{1,1}^{l-1}}\) = ?其中\(net_{1,1}^{l-1}對(duì)哪些net_{i,j}^l有影響?\)
\[\begin{aligned}
\delta_{2,2}^{l-1} &= \frac{dE}{dnet_{2,2}^{l-1}} \\
&= \frac{dE}{dnet_{1,1}^{l}} \frac{dnet_{1,1}^{l}}{dnet_{2,2}^{l-1}} \\
&= 0
\end{aligned}
\]
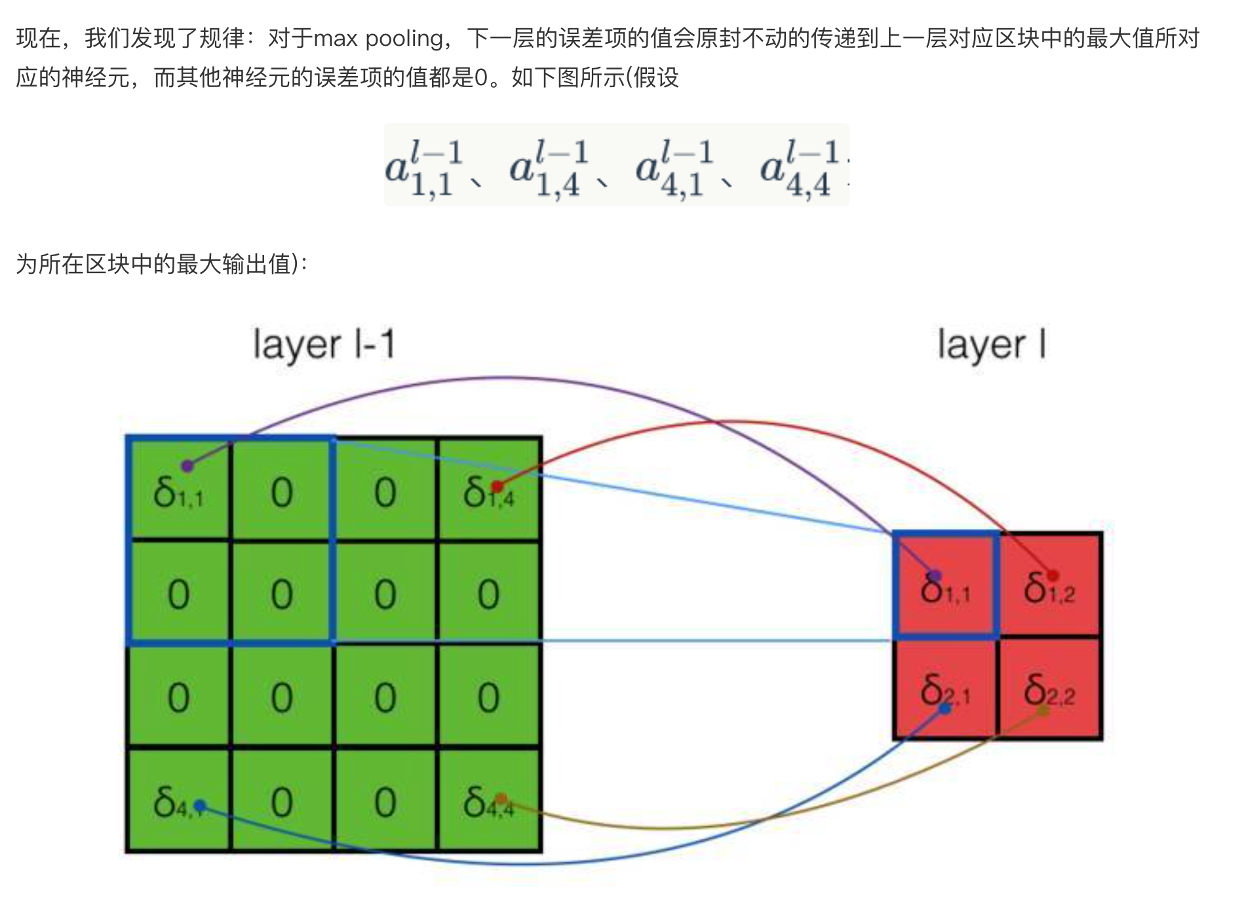
任務(wù):實(shí)現(xiàn)反向計(jì)算誤差項(xiàng)
- 請(qǐng)實(shí)現(xiàn)反向計(jì)算誤差項(xiàng)?
答:待實(shí)現(xiàn)的代碼為:MaxPoolingLayer,實(shí)現(xiàn)后的代碼為:MaxPoolingLayer.res_answer
總結(jié)
- 請(qǐng)總結(jié)本節(jié)課的內(nèi)容?
- 請(qǐng)回答開始的問題?
參考資料
擴(kuò)展閱讀
無
感謝您的閱讀~
掃碼加入我的QQ群:

掃碼加入免費(fèi)知識(shí)星球-YYC的Web3D旅程:


 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)