
深度學習基礎課:用全連接層識別手寫數字(下)
大家好~我開設了“深度學習基礎班”的線上課程,帶領同學從0開始學習全連接和卷積神經網絡,進行數學推導,并且實現可以運行的Demo程序
線上課程資料:
本節課錄像回放
加QQ群,獲得ppt等資料,與群主交流討論:106047770
本系列文章為線上課程的復盤,每上完一節課就會同步發布對應的文章
本課程系列文章可進入索引查看:
深度學習基礎課系列文章索引
任務:恢復梯度檢查
- 恢復梯度檢查后的代碼是什么?
答:恢復后的代碼為:ImplementTrain_restore_gradient_check - 請每個同學都運行代碼,看下是否通過了梯度檢查?
答:通過了梯度檢查
任務:實現推理
- 請實現“使用mnist的測試集推理一個樣本”的代碼
答:實現后的相關代碼為:
let inference = (state: state, feature: feature) => {
let inputVector = _createInputVector(feature)
let (_, (_, layer3OutputVector)) = forward(
(
_activate_sigmoid(
_handleInputValueToAvoidTooLargeForSigmoid(
Matrix.getColCount(state.wMatrixBetweenLayer1Layer2),
),
),
_activate_sigmoid(
_handleInputValueToAvoidTooLargeForSigmoid(
Matrix.getColCount(state.wMatrixBetweenLayer2Layer3),
),
),
),
inputVector,
state,
)
layer3OutputVector -> _getOutputNumber
}
...
let mnistData = Mnist.set(1, 1)
let features = mnistData.training->Mnist.getMnistData
let labels = mnistData.training->Mnist.getMnistLabels
inference(state, features[0])->Js.log
- 請實現“使用mnist的測試集推理多個樣本,并給出正確率”的代碼
答:待實現的代碼為:ImplementTrain_inference_many,實現后的代碼為:ImplementTrain_inference_many_answer - 請每個同學都運行代碼,查看推理正確率是否接近100%?
答:正確率只有不到40%左右
主問題:如何解決過擬合?
-
現在在訓練和推理時,正確率分別是什么情況?
答:推理正確率小于訓練正確率 -
這被稱為過擬合
-
請根據該圖,說下三種擬合情況?
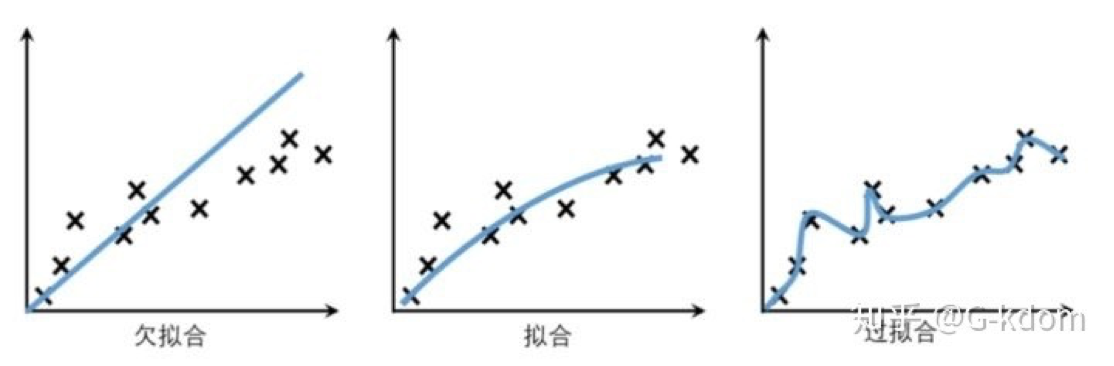
-
為什么會出現過擬合?
答:因為訓練集樣本太少 -
如何解決現在遇到的過擬合的問題?
答:增加訓練樣本個數 -
如果想要使每次訓練的樣本個數較小(從而訓練時間更快),但又能達到更大訓練樣本個數的效果,該如何做?
答:訓練數據集shuffle -
Shuffle是什么?
答:隨機從較大的數據集中選擇較小的數據集 -
為什么Shuffle能避免過擬合?
答:如下圖所示,固定的數據集順序意味著固定的訓練樣本,也就意味著權值更新的方向是固定的,而無順序的數據集,意味著更新方向是隨機的,更容易到最優點
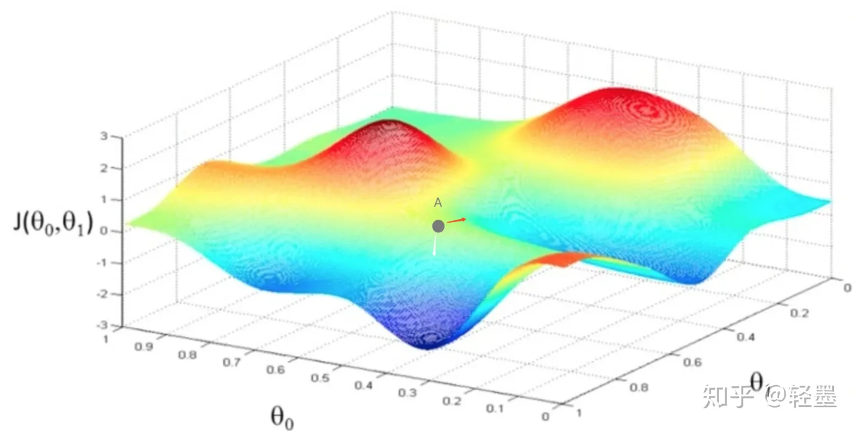
任務:解決過擬合
- 請實現所有解決方案的代碼
答:實現后的代碼為:ImplementTrain_solve - 請每個同學分別運行每個解決方案的代碼,看下是否都提高了推理正確率?
答:是的 - 請每個同學觀察實現第二個接近方案(shuffle)前和實現后的正確率的變化趨勢,說明為什么這樣變化?
答:實現“shuffle”后,訓練正確率會有起伏,這是因為權重更新方向是隨機的;并且推理正確率高于訓練正確率,這是因為shuffle提高了神經網絡的泛化能力 - 請每個同學運行包含兩個解決方案的代碼,看下是否提高了推理正確率?
答:是的
結學
- 什么現象屬于過擬合?
- 如何解決過擬合?
總結
- 請總結本節課的內容?
- 請回答所有主問題?
參考資料
感謝您的閱讀~
掃碼加入我的QQ群:

掃碼加入免費知識星球-YYC的Web3D旅程:


 浙公網安備 33010602011771號
浙公網安備 33010602011771號