
HBase 實(shí)戰(zhàn)(2)--時(shí)間序列檢索和面檢索的應(yīng)用場景實(shí)戰(zhàn)
前言:
作為Hadoop生態(tài)系統(tǒng)中重要的一員, HBase作為分布式列式存儲(chǔ), 在線實(shí)時(shí)處理的特性, 備受矚目, 將來能在很多應(yīng)用場景, 取代傳統(tǒng)關(guān)系型數(shù)據(jù)庫的江湖地位. 本篇主要講述面向時(shí)間序列/面檢索的應(yīng)用場景時(shí), 如何利用HBase的特性去處理和優(yōu)化.
構(gòu)造應(yīng)用場景
某氣象局對各個(gè)站點(diǎn)的信息進(jìn)行采集和匯總, 這些信息包括站點(diǎn)id, 時(shí)間點(diǎn), 采集要素(要素特別多). 然后對這些采集的數(shù)據(jù), 提出如下檢索需求:
1). 時(shí)間序列檢索(檢索出該站點(diǎn)的在某個(gè)時(shí)間范圍內(nèi)的全要素信息)
2). 面檢索(檢索出在某個(gè)時(shí)間點(diǎn), 各個(gè)站點(diǎn)在具體時(shí)間點(diǎn)的某要素信息)
而其數(shù)據(jù)信息的特別如下:
1). 要素種類多, 氣象涉及的觀測元素多(濕度, 溫度, 風(fēng)向等等)
2). 每個(gè)站點(diǎn)收集部分信息, 每個(gè)站點(diǎn)各司其職(觀測點(diǎn)的重新不一樣)
由此可見數(shù)據(jù)的分布是呈現(xiàn)大寬表的形式, 列多且稀疏的方式分布.
存儲(chǔ)選型
對比傳統(tǒng)關(guān)系型數(shù)據(jù)和HBase, 對照的衡量參數(shù)如下:
| 存儲(chǔ)選型 | 可擴(kuò)展性 | 索引支持 | 事務(wù)支持 | 存儲(chǔ)模式 | 應(yīng)用場景 |
| Oracle/DB2(CA) | 不支持水平擴(kuò)容 | 多索引支持 | 支持事務(wù) | 行式存儲(chǔ)(固定的schema, 對稀疏的列數(shù)據(jù)支持差) | 銀行金融機(jī)構(gòu)(對數(shù)據(jù)一致性要求高的場所) |
| Mysql Cluster(AP) | 支持水平擴(kuò)容(分庫分表, hash型) | 多索引支持 | 不支持事務(wù)(跨庫) | 行式存儲(chǔ)(固定的schema, 對稀疏的列數(shù)據(jù)支持差) | 互聯(lián)網(wǎng)/移動(dòng)互聯(lián)網(wǎng)(追求高并發(fā)/高性能) |
| HBase(CP) | 支持水平擴(kuò)容(按key范圍來劃分region, 區(qū)間型) | 無索引, 基于key/value | 不支持事務(wù) | 列式存儲(chǔ)(不固定的schema, 對稀疏的列數(shù)據(jù)支持好) | 大數(shù)據(jù)領(lǐng)域 |
評注: CAP理論, 任何的分布式系統(tǒng)中, 只能最多滿足CAP(一致性/高可用性/分區(qū)容忍性)中的兩種.
由以上圖數(shù)據(jù), 對比, 我們可以發(fā)現(xiàn), 傳統(tǒng)關(guān)系型數(shù)據(jù)庫很難滿足大寬表(列多且稀疏)的數(shù)據(jù)存儲(chǔ), 因此我們就選用HBase作為我們的存儲(chǔ)模型.
檢索分析
HBase作為分布式列式存儲(chǔ), 對列多且稀疏分布的數(shù)據(jù)支持非常的好. 而對于實(shí)時(shí)檢索, HBase借助rowkey來實(shí)現(xiàn), 其支持key的范圍/前綴搜索, 檢索性能非常好. 因此要應(yīng)用好hbase, 其rowkey的設(shè)計(jì)成為至關(guān)重要的一環(huán). 根據(jù)實(shí)戰(zhàn)的經(jīng)驗(yàn), rowkey由多個(gè)字段構(gòu)成且支持key前綴檢索, 這有點(diǎn)類似與傳統(tǒng)關(guān)系型數(shù)據(jù)庫的復(fù)合索引. 但不足的方面是, hbase表只有一個(gè)rowkey, 換句話說就是只有一個(gè)索引, 同時(shí)多個(gè)字段組成的rowkey, 需要等寬字節(jié)來構(gòu)建它. 這些因素就對上述的檢索需求產(chǎn)生了影響.
回到最初的應(yīng)用場景, 其檢索需求有時(shí)間序列檢索和面檢索, rowkey設(shè)計(jì)方案如下:
1). rowkey格式: timestamp:site_id:others, 其把時(shí)間字段作為rowkey的前綴, 對面檢索(檢索某個(gè)時(shí)間點(diǎn), 列出各個(gè)站點(diǎn)的要素信息)友好, 而對時(shí)間序列檢索(檢索該站點(diǎn)在某個(gè)時(shí)間范圍的要素檢索)不友好. 前者利用到了rowkey前綴, 后者利用不到, 因此掃描范圍變大, 效率迅速降低.
2). rowkey格式: site_id:timestamp:others, 把站點(diǎn)id放在rowkey的前綴, 則結(jié)果恰好于上相反.
由此可見, 兩種rowkey設(shè)計(jì)方案, 都無法同時(shí)滿足時(shí)間序列檢索和面檢索. 那我們該這么辦?
數(shù)據(jù)雙寫, 采用數(shù)據(jù)冗余的方式, 構(gòu)建兩張表. 一張表采用timestamp:site_id:others作為rowkey的設(shè)計(jì)方案, 另一張則采用site_id:timestamp:others作為rowkey的設(shè)計(jì)方案. 同時(shí)這兩張表的數(shù)據(jù)內(nèi)容完全一樣, 這樣就能滿足上述的時(shí)間序列檢索和面檢索的需求了. 這種冗余方案, 在分布式mysql集群中, 被廣泛的運(yùn)用.
評注: 數(shù)據(jù)雙寫, 是作為HA(高可用性)的一種方案, 常用的HA策略有主從備份(存在單點(diǎn)故障).
寫優(yōu)化
盡管數(shù)據(jù)雙寫方案解決了上述檢索需求(讀性能高), 但以tiemstamp作為rowkey前綴的hbase表, 存在寫入熱點(diǎn)問題. 因?yàn)閔base的region是按rowkey的范圍來劃分的, 而數(shù)據(jù)的時(shí)間密集性很高, 導(dǎo)致幾乎所有的數(shù)據(jù)都擱在同一個(gè)region上, 導(dǎo)致寫熱點(diǎn)問題. 因此我們需要對數(shù)據(jù)雙寫方案進(jìn)行補(bǔ)充, 使得能夠解決數(shù)據(jù)寫入熱點(diǎn)問題.
rowkey前綴加salt, 采用隨機(jī)/hash(站點(diǎn))的方式生成salt, 這樣分散了寫入, 避免了熱點(diǎn)問題. 當(dāng)然加salt是有代價(jià)的, 它加大讀取數(shù)據(jù)的難度, 因?yàn)樵具B續(xù)的數(shù)據(jù)被分散到了不同region上.
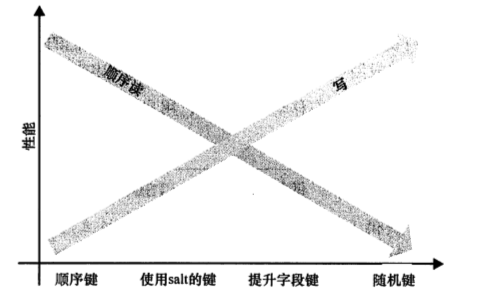
該圖取之書籍<<hbase權(quán)威指南>>, 表明了不同的salt選擇對讀寫性能的影響.
最終方案:
針對該應(yīng)用場景, 采用HBase作為底層儲(chǔ)存方案.
1). 數(shù)據(jù)雙寫的模式, 構(gòu)建兩張表, 數(shù)據(jù)冗余.
2). 表A以hash(site_id):timestamp:site_id:others作為rowkey, hash(site_id)表示對站點(diǎn)id取模作為salt.
3). 表B以site_id:timestamp:others作為rowkey, 站點(diǎn)(site_id)個(gè)數(shù)較多, 分散性好.
轉(zhuǎn)自:

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號