
Java 21 正式 GA,虛擬線程真的來了
UTC 時間 2023 年 9 月 19 日,期盼已久的 Java 21 終于發布正式版!
本文一起來看看其中最受 Java 開發者關注的一項新特性:Loom 項目的兩個新特性之一的 ”虛擬線程(Virtual Thread)“(另外一個新特性是 ”結構化并發(Structured Concurrency)“,當前是預覽狀態),它被稱之為 Java 版的 ”協程“,它到底是什么?有什么神奇之處嗎?
虛擬線程是輕量級線程(類似于 Go 中的 “協程(Goroutine)”),可以減少編寫、維護和調度高吞吐量并發應用程序的工作量。
線程是可供調度的最小處理單元,它與其他類似的處理單元并發運行,并且在很大程度上是獨立運行的。線程(java.lang.Thread)有兩種,平臺線程和虛擬線程。
平臺線程
平臺線程也就是之前的普通線程 java.lang.Thread 的實例,它被實現為對操作系統線程的簡單包裝,它通常以 1:1 的比例映射到由操作系統調度的內核線程中。它在其底層操作系統線程上運行 Java 代碼,并且在它的整個生命周期內捕獲著其映射的操作系統線程。因此,可用平臺線程的數量局限于對應操作系統線程的數量。
平臺線程通常有一個大的堆棧和其他由操作系統維護的資源,它適合運行所有類型的任務,但可供使用的資源可能有限。
平臺線程可被指定為守護線程或非守護線程,除了守護線程狀態之外,平臺線程還具有線程優先級,并且是線程組的成員。默認情況下,平臺線程會獲得自動生成的線程名稱。
與此同時,關于線程還有一些需要特別提到的變更,并值得我們的注意:如果我們先前有通過直接 new Thread(...) 手工創建單個平臺線程并使用(盡管此做法在大多數情況下是不推薦的)的話,請記住 Java 21 中的 suspend()、 resume()、stop() 和 countStackFrames() 等棄用方法將會直接拋出 UnsupportedOperationException 異常,可能會影響到之前的業務處理邏輯!
虛擬線程
與平臺線程一樣,虛擬線程同樣是 java.lang.Thread 的實例,但是,虛擬線程并不與特定的操作系統線程綁定。它與操作系統線程的映射關系比例也不是 1:1,而是 m:n。虛擬線程通常是由 Java 運行時來調度的,而不是操作系統。虛擬線程仍然是在操作系統線程上運行 Java 代碼,但是,當在虛擬線程中運行的代碼調用阻塞的 I/O 操作時,Java 運行時會將虛擬線程掛起,直到其可以恢復為止。此時與掛起的虛擬線程相關聯的操作系統線程便可以自由地為其他虛擬線程來執行操作。
與平臺線程不同,虛擬線程通常有一個淺層調用棧,它只需要很少的資源,單個 Java 虛擬機可能支持數百萬個虛擬線程(也正因為如此,盡管虛擬線程支持使用 ThreadLocal 或 InheritableThreadLocal 等線程局部變量,我們也應該仔細考慮是否需要使用它們)。虛擬線程適合執行大部分時間被阻塞的任務,這些任務通常需要等待 I/O 操作完成,它不適合用于長時間運行的 CPU 密集型操作。
虛擬線程通常使用一小組平臺線程作為載體線程(Carrier Thread),在虛擬線程中運行的代碼不知道其底層的載體線程。
虛擬線程是守護線程,具有固定的線程優先級,不能更改。默認情況下,虛擬線程沒有線程名稱,如果未設置線程名稱,則獲取當前線程名稱時將會返回空字符串。
那么,為什么要使用虛擬線程呢?
在高吞吐量并發應用程序中使用虛擬線程,尤其是那些包含由大量并發任務組成的應用程序,這些任務需要花費大量時間等待。例如服務器應用程序,因為它們通常處理許多執行阻塞 I/O 操作(例如獲取資源)的客戶端請求。
虛擬線程并不是更快的線程,它們運行代碼的速度并不會比平臺線程更快。它們的存在是為了提高擴展性(更高的吞吐量,而吞吐量意味著系統在給定時間內可以處理多少個信息單元),而不是速度(更低的延遲)。
創建和運行虛擬線程
1. Thread.ofVirtual() 創建和運行虛擬線程
Thread thread = Thread.ofVirtual().start(() -> System.out.println("Hello"));
thread.join(); // 等待虛擬線程終止
Thread.startVirtualThread(task) 可以快捷地創建并啟動虛擬線程,它與 Thread.ofVirtual().start(task) 是等價的。
2. Thread.Builder 創建和運行虛擬線程
Thread.Builder 接口允許我們創建具有通用的線程屬性(例如線程名稱)的線程,Thread.Builder.OfPlatform 子接口創建平臺線程,而 Thread.Builder.OfVirtual 子接口則創建虛擬線程。
Thread.Builder builder = Thread.ofVirtual().name("MyThread"); // 虛擬線程的名稱是 MyThread
Runnable task = () -> System.out.println("Running thread");
Thread t = builder.start(task);
System.out.println("Thread t name: " + t.getName()); // 控制臺打印:Thread t name: MyThread
t.join();
下面的示例代碼創建了 2 個虛擬線程,名稱分別是 worker-0 和 worker-1(這個是由 name() 中的兩個參數 prefix 和 start 指定的):
Thread.Builder builder = Thread.ofVirtual().name("worker-", 0);
Runnable task = () -> System.out.println("Thread ID: " + Thread.currentThread().threadId());
// 虛擬線程 1,名稱為 worker-0
Thread t1 = builder.start(task);
t1.join();
System.out.println(t1.getName() + " terminated");
// 虛擬線程 2,名稱為 worker-1
Thread t2 = builder.start(task);
t2.join();
System.out.println(t2.getName() + " terminated");
以上示例代碼運行結果,在控制臺中打印內容如下:
Thread ID: 21
worker-0 terminated
Thread ID: 24
worker-1 terminated
3. Executors.newVirtualThreadPerTaskExecutor() 創建和運行虛擬線程
Executor 允許我們將線程管理和創建與應用程序的其余部分分開:
// Java 21 中 ExecutorService 接口繼承了 AutoCloseable 接口,
// 所以可以使用 try-with-resources 語法使 Executor 在最后被自動地 close()
try (ExecutorService myExecutor = Executors.newVirtualThreadPerTaskExecutor()) {
// 每次 submit() 調用向 Executor 提交任務時都會創建和啟動一個新的虛擬線程
Future<?> future = myExecutor.submit(() -> System.out.println("Running thread"));
future.get(); // 等待線程任務執行完成
System.out.println("Task completed");
} catch (ExecutionException | InterruptedException ignore) {}
4. 一個多線程的回顯客戶端服務器示例
EchoServer 為回顯服務器程序,監聽本地 8080 端口并為每個客戶端連接創建并啟動一個新的虛擬線程:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.ServerSocket;
import java.net.Socket;
public class EchoServer {
public static void main(String[] args) {
try (ServerSocket serverSocket = new ServerSocket(8080)) {
while (true) {
try {
// 接受傳入的客戶端連接
Socket clientSocket = serverSocket.accept();
// 啟動服務線程,處理這個客戶端連接傳輸的數據并回顯。可以通過虛擬線程同時服務多個客戶端,每個客戶端連接一個線程。
Thread.ofVirtual().start(() -> {
try (PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()))) {
String inputLine;
while ((inputLine = in.readLine()) != null) {
System.out.println(inputLine);
out.println(inputLine);
}
} catch (IOException ignore) {}
});
} catch (Throwable unknown) {
break;
}
}
} catch (IOException e) {
System.err.println("Exception caught when trying to listen on port 8080 or listening for a connection: " + e.getMessage());
System.exit(1);
}
}
}
EchoClient 為回顯客戶端程序,它連接到本地的服務器并發送在命令行輸入的文本消息:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.Socket;
public class EchoClient {
public static void main(String[] args) {
try (Socket echoSocket = new Socket("127.0.0.1", 8080);
PrintWriter out = new PrintWriter(echoSocket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(echoSocket.getInputStream()))) {
BufferedReader stdIn = new BufferedReader(new InputStreamReader(System.in));
String userInput;
while ((userInput = stdIn.readLine()) != null) {
out.println(userInput);
System.out.println("echo: " + in.readLine());
if (userInput.equals("bye")) {
break;
}
}
} catch (Exception e) {
System.err.println("Couldn't get I/O for the connection to 127.0.0.1:8080: " + e.getMessage());
System.exit(1);
}
}
}
在上面的示例程序代碼中,可以看到 EchoServer 的 while (true) {...} 無限循環體內每次接受到一個新的客戶端連接時,都創建和啟動一個新的虛擬線程,并且沒有用到虛擬線程池。請不要擔心,事實上以上不管哪種創建和運行虛擬線程的方式,其背后都有一個線程池 ForkJoinPool(Carrier Thread 載體線程的池,這些載體線程是平臺線程)。ForkJoinPool 的默認的調度參數:parallelism 并行度為計算機處理器的可用核心數、maxPoolSize 池的最大線程數為 256 和 parallelism 的最大值、minRunnable 允許的不被 join 或阻塞的最小核心線程數為 1 和 parallelism /2 的最大值,它們可以通過系統屬性啟動參數 jdk.virtualThreadScheduler.parallelism、jdk.virtualThreadScheduler.maxPoolSize、jdk.virtualThreadScheduler.minRunnable 自定義修改。
5. CompletableFuture 應當如何適應虛擬線程?
CompletableFuture 平常我們用得比較多,在有虛擬線程以前,它一個慣常的使用方法如下:
long startMills = System.currentTimeMillis();
ExecutorService executor = Executors.newFixedThreadPool(256);
List<CompletableFuture<Void>> futures = new ArrayList<>();
IntStream.range(0, 10000).forEach(i -> {
// 如果 runAsync 不指定 Executor,則會使用默認的線程池(除非系統不支持并行,否則會使用一個通用的 ForkJoinPool.commonPool 線程池)
CompletableFuture<Void> f = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException ignore) {
Thread.currentThread().interrupt();
}
}, executor);
futures.add(f);
});
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
executor.shutdown();
System.out.println("【線程池】任務執行時間:" + (System.currentTimeMillis() - startMills) / 1000 + " 秒!");
以上示例代碼運行結果,在控制臺中打印內容如下:
【線程池】任務執行時間:40 秒!
在有虛擬線程后,其實改動非常少,只需要將平臺線程池的 executor 替換為虛擬線程的 executor 即可:
long startMills = System.currentTimeMillis();
List<CompletableFuture<Void>> futures = new ArrayList<>();
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10000).forEach(i -> {
// 如果 runAsync 不指定 Executor,則會使用默認的線程池(除非系統不支持并行,否則會使用一個通用的 ForkJoinPool.commonPool 線程池)
CompletableFuture<Void> f = CompletableFuture.runAsync(() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException ignore) {
Thread.currentThread().interrupt();
}
}, executor);
futures.add(f);
});
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
}
System.out.println("【虛擬線程】任務執行時間:" + (System.currentTimeMillis() - startMills) / 1000 + " 秒!");
以上示例代碼運行結果,在控制臺中打印內容如下:
【虛擬線程】任務執行時間:1 秒!
同時,也可以看到在這個示例代碼的場景下,虛擬線程相比平臺線程池的方案在性能上提升了約 40 倍!
調度和固定虛擬線程
平臺線程由操作系統來調度并決定何時運行,但是虛擬線程是由 Java 運行時來調度并決定何時運行的。當 Java 運行時調度虛擬線程時,它在平臺線程上分配或掛載虛擬線程,然后操作系統像往常一樣調度該平臺線程,這個平臺線程稱為載體(Carrier)。運行一些代碼后,虛擬線程可以從它的載體卸載,這通常發生在虛擬線程執行阻塞 I/O 操作時。虛擬線程從它的載體上卸載后,載體是空閑的,這意味著 Java 運行時調度器可以在其上掛載不同的虛擬線程。
在阻塞操作期間,當虛擬線程被固定到它的載體上時,它不能被卸載。虛擬線程在以下情況下會被固定(pinning):
- 虛擬線程在
synchronized同步塊或方法中運行代碼; - 虛擬線程運行本地方法(
native method)或外部函數(foreign function)。
固定不會使應用程序出錯,但可能會影響其擴展性。嘗試通過修改頻繁運行的 synchronized 同步塊或方法,并使用java.util.concurrent.locks.ReentrantLock 來保護可能長時間執行的 I/O 操作,以避免頻繁和長時間的虛擬線程固定。
調試虛擬線程
虛擬線程仍然是線程,調試器可以像平臺線程那樣對它們進行步進。Java Flight Recorder (JFR) 和 jcmd 工具具有額外的特性功能可以幫助觀察應用程序中的虛擬線程。
1. 用于虛擬線程的 JFR 事件
Java Flight Recorder (JFR) 可以發出以下與虛擬線程相關的事件:
jdk.VirtualThreadStart和jdk.VirtualThreadEnd虛擬線程的開始和結束的時間,這些事件在默認情況下是禁用的;jdk.VirtualThreadPinned表示一個虛擬線程被固定(并且它的載體線程沒有被釋放)的超過閾值的持續時間,缺省情況下啟用該事件,閾值為 20 毫秒;jdk.VirtualThreadSubmitFailed表示啟動或取消掛起(unpark)虛擬線程失敗,可能是由于資源問題。掛起(park)一個虛擬線程釋放底層的載體線程去做其他工作,取消掛起(unpark)一個虛擬線程以被調度它繼續,該事件默認開啟。
要打印這些事件,請運行以下命令,其中 recording.jfr 是我們記錄的文件名:
jfr print --events jdk.VirtualThreadStart,jdk.VirtualThreadEnd,jdk.VirtualThreadPinned,jdk.VirtualThreadSubmitFailed recording.jfr
2. 查看 jcmd 線程轉儲中的虛擬線程
可以創建純文本或 JSON 格式的線程轉儲:
jcmd <PID> Thread.dump_to_file -format=text <file>
jcmd <PID> Thread.dump_to_file -format=json <file>
jcmd 線程轉儲列出在網絡 I/O 操作中阻塞的虛擬線程和由 ExecutorService 接口創建的虛擬線程。它不包括對象地址、鎖、JNI 統計信息、堆統計信息和其他出現在傳統線程轉儲中的信息。
總結:虛擬線程采用指南
虛擬線程是由 Java 運行時而不是操作系統實現的 Java 線程。虛擬線程和傳統線程(我們現在稱之為平臺線程)之間的主要區別在于,我們可以很容易地在同一個 Java 進程中運行大量活動的虛擬線程,甚至數百萬個。大量的虛擬線程賦予了它們強大的功能:通過允許服務器并發處理更多的請求,它們可以更有效地運行以每個請求一個線程的方式編寫的服務器應用程序,從而實現更高的吞吐量和更少的硬件浪費。
由于虛擬線程是 java.lang.Thread 的實現,并且遵循自 Java SE 1.0 以來指定的 java.lang.Thread 的相同規則,因此開發人員不需要學習使用它們的新概念。然而,由于無法生成非常多的平臺線程(多年來 Java 中唯一可用的線程實現),因此產生了旨在應對其高成本的實踐做法。當這些做法應用于虛擬線程時會適得其反,必須摒棄。此外,成本上的巨大差異提示了一種考慮線程的新方式,這些線程一開始可能是外來的。
1. 編寫簡單、同步的代碼,采用單請求單線程風格的阻塞 I/O API
虛擬線程可以顯著提高以單請求單線程(Thread-Per-Request)的方式編寫的服務器應用程序的吞吐量(而不是延遲)。在這種風格中,服務器在整個持續時間內專用一個線程來處理每個傳入請求。它至少專用一個線程,因為在處理單個請求時,我們可能希望使用更多的線程來并發地執行一些任務。
阻塞平臺線程的代價很高,因為它占用了系統線程(相對稀缺的資源),而它并沒有做多少有意義的工作。因為虛擬線程可能很多,所以阻塞它們的成本很低,而且應該得到提倡。因此,應該以直接的同步風格編寫代碼,并使用阻塞 I/O API。
以下這種以非阻塞、異步風格編寫的代碼不會從虛擬線程中獲得太多好處:
CompletableFuture.supplyAsync(info::getUrl, pool)
.thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofString()))
.thenApply(info::findImage)
.thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofByteArray()))
.thenApply(info::setImageData)
.thenAccept(this::process)
.exceptionally(ignore -> null);
但是下面這種以同步風格編寫并使用簡單阻塞 I/O 的代碼卻將受益匪淺:
try {
String page = getBody(info.getUrl(), HttpResponse.BodyHandlers.ofString());
String imageUrl = info.findImage(page);
byte[] data = getBody(imageUrl, HttpResponse.BodyHandlers.ofByteArray());
info.setImageData(data);
process(info);
} catch (Exception ignore) {}
這樣的代碼也更容易在調試器中進行調試,在分析器中進行概要分析,或者使用線程轉儲進行觀察。為了觀察虛擬線程,使用 jcmd 命令創建一個線程轉儲:
jcmd <pid> Thread.dump_to_file -format=json <file>
以這種風格編寫的堆棧越多,虛擬線程的性能和可觀察性就越好。用其他風格編寫的程序或框架,如果沒有為每個任務指定一個線程,就不應該期望從虛擬線程中獲得顯著的好處。避免將同步、阻塞代碼與異步框架混在一起。
2. 將每個并發任務表示為一個虛擬線程,不要池化虛擬線程
關于虛擬線程,最難內化的是,雖然它們具有與平臺線程相同的行為,但它們不應該表示相同的程序概念。
平臺線程是稀缺的,因此是一種寶貴的資源。需要管理寶貴的資源,管理平臺線程的最常用方法是使用線程池。接下來需要回答的問題是,池中應該有多少線程?
但是虛擬線程非常多,因此每個線程不應該代表一些共享的、池化的資源,而應該代表一個任務。線程從托管資源轉變為應用程序域對象。我們應該有多少個虛擬線程的問題變得很明顯,就像我們應該使用多少個字符串在內存中存儲一組用戶名的問題一樣:虛擬線程的數量總是等于應用程序中并發任務的數量。
將 n 個平臺線程轉換為 n 個虛擬線程不會產生什么好處;相反,需要轉換的是任務。
為了將每個應用程序任務表示為一個線程,不要像下面的例子那樣使用共享線程池執行器:
Future<ResultA> f1 = sharedThreadPoolExecutor.submit(task1);
Future<ResultB> f2 = sharedThreadPoolExecutor.submit(task2);
// ... 使用 f1、f2
相反地,應該使用虛擬線程執行器,如下例所示:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { // 注意這里實際上并沒有將虛擬線程進行池化
Future<ResultA> f1 = executor.submit(task1);
Future<ResultB> f2 = executor.submit(task2);
// ... 使用 f1、f2
}
代碼仍然使用 ExecutorService,但是從 Executors.newVirtualThreadPerTaskExecutor() 返回的那個沒有使用線程池。相反,它為每個提交的任務創建一個新的虛擬線程。
此外,ExecutorService 本身是輕量級的,我們可以創建一個新的,就像處理任何簡單的對象一樣。這允許我們依賴于新添加的ExecutorService.close() 方法和 try-with-resources 語句。在 try 塊結束時隱式調用的 close 方法將自動等待提交給ExecutorService 的所有任務(即由 ExecutorService 生成的所有虛擬線程)終止。
對于 fanout 場景,這是一個特別有用的模式,在這種場景中,我們希望并發地向不同的服務執行多個傳出調用,如下面的示例所示:
void handle(Request request, Response response) {
var url1 = ...
var url2 = ...
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var future1 = executor.submit(() -> fetchURL(url1));
var future2 = executor.submit(() -> fetchURL(url2));
response.send(future1.get() + future2.get());
} catch (ExecutionException | InterruptedException e) {
response.fail(e);
}
}
String fetchURL(URL url) throws IOException {
try (var in = url.openStream()) {
return new String(in.readAllBytes(), StandardCharsets.UTF_8);
}
}
我們應該創建一個新的虛擬線程,如上例所示,即使是小型的、短暫的并發任務也是如此。
為了在編寫 fanout 模式和其他常見并發模式時獲得更多幫助,并且具有更好的可觀察性,請使用結構化并發。
根據經驗,如果我們的應用程序從來沒有 10000 個或更多的虛擬線程,那么它不太可能從虛擬線程中獲益。要么它的負載太輕,不需要更好的吞吐量,要么我們沒有向虛擬線程表示有足夠多的任務。
3. 使用信號量限制并發
有時需要限制某個確定操作的并發性。例如,某些外部服務可能無法處理 10 個以上的并發請求。由于平臺線程是通常在池中管理的寶貴資源,因此線程池已經變得如此普遍,以至于它們被用于限制并發性的目的,如下例所示:
ExecutorService es = Executors.newFixedThreadPool(10); // 固定線程池的核心及最大線程數量為 10
...
Result foo() {
try {
var fut = es.submit(() -> callLimitedService());
return f.get();
} catch (...){ ...}
}
此示例確保對有限的服務最多有 10 個并發請求。
但是限制并發性只是線程池操作的副作用。池被設計為共享稀缺資源,而虛擬線程并不稀缺,因此永遠不應該被池化!
在使用虛擬線程時,如果希望限制訪問某些服務的并發性,則應該使用專門為此目的設計的構造:Semaphore 類。如下示例:
Semaphore sem = new Semaphore(10); // 初始化一個信號量,擁有 10 個許可
...
Result foo() {
sem.acquire(); // 申請許可,如果當前沒有許可了,則阻塞直至其他線程 release 以釋放許可
try {
return callLimitedService(); // 只有申請并獲得了許可的線程,才能進入此處執行業務邏輯,從而控制了并發性
} finally {
sem.release(); // 釋放許可,以供其他線程使用
}
}
簡單地用信號量阻塞一些虛擬線程可能看起來與將任務提交到一個固定線程池有很大的不同,但事實上并非如此。將任務提交到線程池會將它們排隊等待以供稍后執行,但是信號量內部(或任何其他類似的阻塞同步構造)會創建一個阻塞在它上面的線程隊列,這些線程被阻塞在其上,與等待池化的平臺線程來執行它們的任務隊列相對應。因為虛擬線程即是任務,所以其結果結構是等價的:
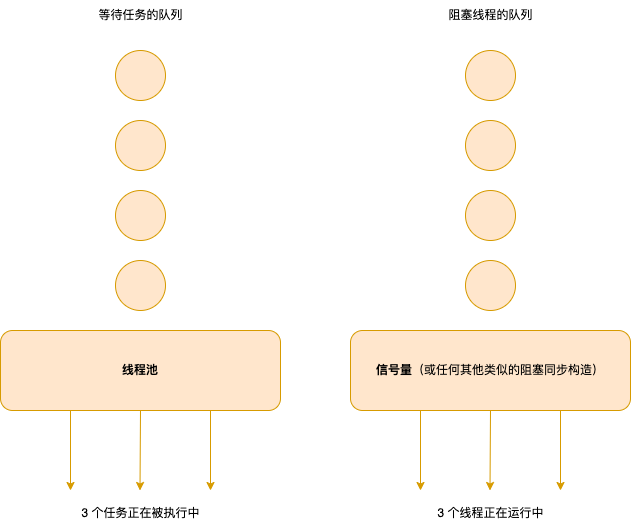
圖示:對比線程池和信號量
即使我們可以將平臺線程池視為從隊列中提取任務并處理它們的工作線程,而將虛擬線程視為等待繼續執行的任務本身,但在計算機中的基礎表示實際上幾乎相同。認識到排隊的任務和被阻塞的線程之間的等效性將有助于我們充分利用虛擬線程。
4. 不要在線程局部變量中緩存昂貴的可重用對象
虛擬線程與平臺線程一樣支持線程局部變量。通常,線程局部變量用于將某些與當前運行的代碼相關的上下文特定信息關聯起來,例如當前的事務和用戶 ID。在虛擬線程中,使用線程本地變量來實現這種用途是完全合理的。但是,考慮使用更安全和更高效的作用域值(java.lang.ScopedValue,當前為預覽特性)。
還有一種使用線程局部變量的方式與虛擬線程存在根本性沖突:緩存可重復使用的對象。這些對象通常創建昂貴(并消耗大量內存),是可變的,并且不是線程安全的。它們被緩存在線程局部變量中,以減少它們被實例化的次數和內存中的實例數量,但它們會被在不同時間運行在線程上的多個任務重復使用。
例如,SimpleDateFormat 的實例創建昂貴且不是線程安全的。一種常見的做法是將這樣的實例緩存在 ThreadLocal 中,如下例所示:
static final ThreadLocal<SimpleDateFormat> cachedFormatter = ThreadLocal.withInitial(SimpleDateFormat::new);
void foo() {
...
cachedFormatter.get().format(...);
...
}
這種類型的緩存僅在線程(因此在線程局部緩存的昂貴對象)被多個任務共享和重復使用時才有幫助,就像在平臺線程池中的池化線程時的情況一樣。在線程池中運行時,許多任務可能會調用 foo,但由于池中只包含一些線程,該對象只會被實例化幾次 - 每個池線程一次 - 然后被緩存和重復使用。
然而,虛擬線程從不被池化,也不會被不相關的任務重復使用。因為每個任務都有自己的虛擬線程,來自不同任務的每次對 foo 的調用都會觸發新的 SimpleDateFormat 實例的實例化。而且,由于可能有大量虛擬線程同時運行,昂貴的對象可能會消耗大量內存。這與線程局部緩存的預期成果完全相反。
沒有單一的通用替代方案,但在 SimpleDateFormat 的情況下,我們應該將其替換為 DateTimeFormatter。DateTimeFormatter 是不可變的,因此可以由所有線程共享單個實例:
static final DateTimeFormatter formatter = DateTimeFormatter….;
void foo() {
...
formatter.format(...);
...
}
請注意,有時候,使用線程局部變量來緩存共享的昂貴對象是由異步框架在幕后完成的,這是它們的隱式假設,認為它們會被一個非常小的線程池中的線程使用。這就是為什么混合使用虛擬線程和異步框架不是一個好主意的原因之一:調用一個方法可能會導致在本應緩存和共享的線程本地變量中實例化昂貴的對象。
5. 避免長時間和頻繁的固定
目前虛擬線程的實現存在一個限制,即在 synchronized 同步塊或方法內執行阻塞操作會導致 JDK 的虛擬線程調度器阻塞一個寶貴的操作系統線程,而如果阻塞操作在 synchronized 同步塊或方法之外執行,就不會出現這種情況。我們稱這種情況為 “pinning”(固定)。如果阻塞操作既長時間存在又頻繁發生,pinning 可能會對服務器的吞吐量產生不利影響。使用 synchronized 同步塊或方法保護短時操作(例如內存操作)或不頻繁的操作應該不會產生不利影響。
為了檢測可能有害的 pinning 情況,JDK Flight Recorder(JFR)在阻塞操作被固定時會發出 jdk.VirtualThreadPinned 線程事件;默認情況下,當操作持續時間超過 20 毫秒時,此事件被啟用。
或者,我們可以使用系統屬性 jdk.tracePinnedThreads,在線程被固定時發出堆棧跟蹤。使用選項 -Djdk.tracePinnedThreads=full 時,當線程被固定時會打印完整的堆棧跟蹤,突出顯示本機幀和持有監視器的幀。使用選項 -Djdk.tracePinnedThreads=short 時,輸出將限制為僅包括有問題的幀。
如果這些機制檢測到 pinning 在某些地方既長時間存在又頻繁發生,那么在那些特定地方使用 ReentrantLock 替代 synchronized(再次強調,不需要替代用于保護短時操作或不頻繁操作的 synchronized)。以下是一個長時間存在且頻繁使用同步塊的示例:
synchronized(lockObj) {
frequentIO();
}
我們可以將其替換為:
lock.lock();
try {
frequentIO();
} finally {
lock.unlock();
}

 浙公網安備 33010602011771號
浙公網安備 33010602011771號