
火山引擎發布數據飛輪 2.0,AI 重塑企業數據消費
12 月 18 日,在 2024 冬季火山引擎 FORCE 原動力大會上,火山引擎數智平臺(VeDI)正式升級發布數據飛輪 2.0 模式。
延續去年 4 月發布的數據飛輪“以數據消費促資產建設,以數據消費助業務發展”的核心內涵,此次升級后,數據飛輪 2.0 將 AI 視作數智化的核心競爭力,借助 AI 技術推動企業更普惠的數據消費。
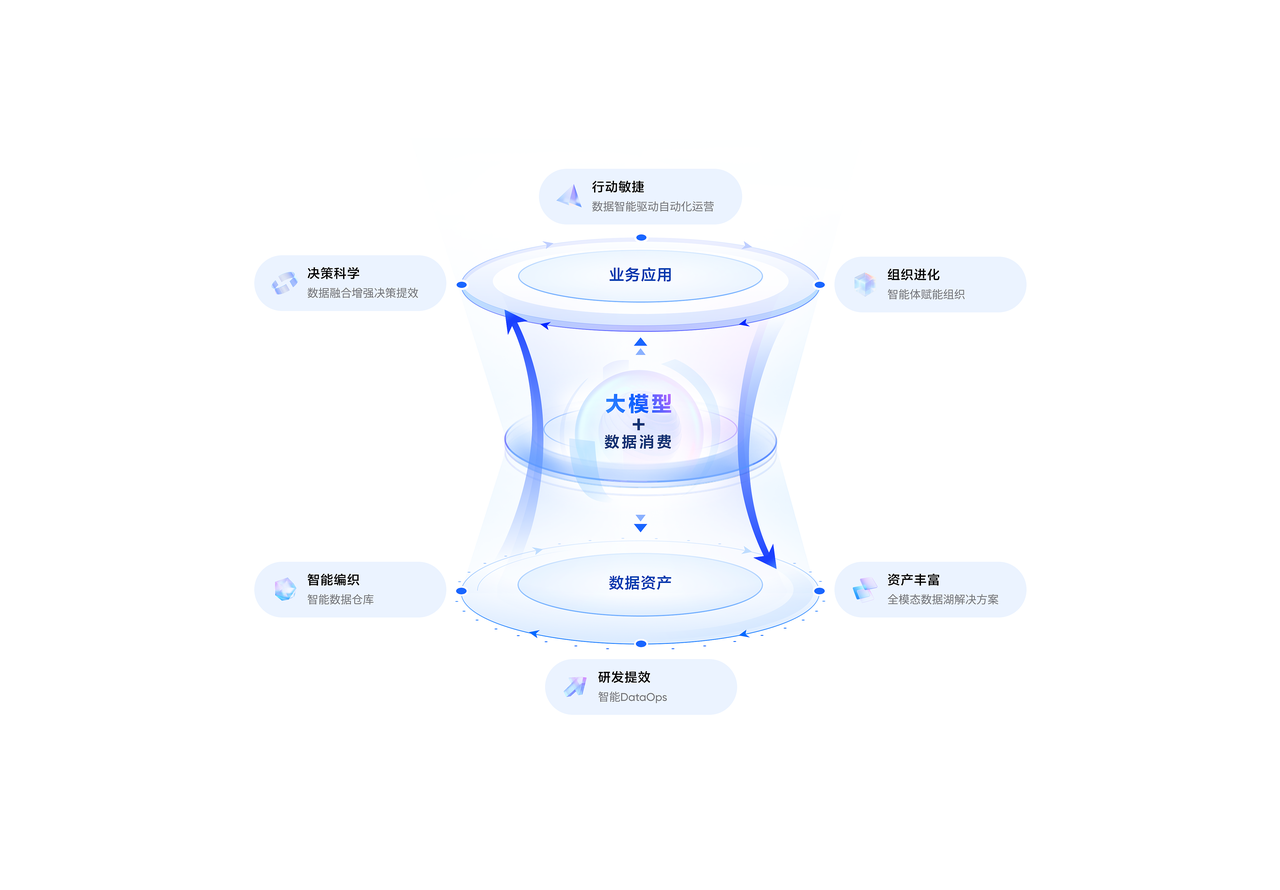
火山引擎數據飛輪 2.0 模式圖
本次模式升級包括了:智能數據洞察 DataWind ChatBI 智能體、增長分析 DataFinder 智能分析助手、A/B 測試 DataTester 智能實驗助手、客戶數據平臺 VeCDP 智能營銷助手、增長營銷平臺 GMP 創意助手、大數據研發治理套件 DataLeap 運維助手和 E-MapReduce 全模態數據處理引擎等,全系列火山引擎數智平臺產品 AI 能力的發布。
與此同時,兩大數據飛輪 2.0 核心解決方案首次公開亮相。
其一為 “DataFabric 驅動下的 ChatBI 智能體解決方案”,亮點在于賦予業務自定義的數據智能體能力,有效降低業務調用與理解數據的難度;
其二是 “多模態數據湖解決方案”,該方案專注于處理全模態數據,擴容企業潛在數字資產規模。
至此,數據飛輪 2.0 實現數據生產、管理與應用各環節全方位 AI 能力深度融合,推動企業數據消費便捷化、資產建設低門檻化,加速企業數據價值實現進程。
數據消費的新體驗:ChatBI 智能體
在 2.0 升級前,火山引擎數據飛輪已在近兩年的時間里,幫助眾多企業通過數據消費挖掘數據價值,助力業務增長:
領克汽車通過數據飛輪構建用戶數據平臺,精準洞察消費者需求,實現差異化營銷,運營成本降低 70%;德邦快遞通過數據飛輪解決數據"黑盒"問題,用戶識別和營銷效率顯著提升,月營銷活動峰值可達 100 場,效率提高 5 倍;瑪麗黛佳兩年內完成數智化轉型,搭建的“數據找人”模式,讓數據自動生成并流向業務負責人,實現實時決策……
數據飛輪模式并非靜態技術框架,而是有生命力的生態系統,其生命力源于數據消費。而,企業數據消費的廣度與深度,則直接決定企業數智化的程度。
上述企業在數據飛輪模式助力下,內部數據消費水平顯著提升。
然而,在與更廣泛的客戶合作中,火山引擎數智平臺察覺到一個關鍵難點:企業內部各崗位角色間的的數字化水平存在較大差異,數據分析與應用產品的使用往往局限在少部分專業角色中,這在一定程度上制約了企業級數據消費活力的釋放。
這也引發了火山引擎數智平臺的思考:如何確保企業各業務角色以及每一層級組織,都能便捷、高效地獲取和使用數據?
在 AI 涌現的趨勢下,他們摸索著找到了新解法——構建業務自己的數據智能體,在經由內部多個產品實踐后,最終發布了“Data Fabric 驅動下的 ChatBI 智能體”解決方案。

火山引擎 Data Fabric 驅動下的 ChatBI 智能體解決方案
事實上,在去年,圍繞大模型能力,火山引擎數智平臺已經推出了智能數據洞察 DataWind 分析助手等功能。企業員工可以通過自然語言輸入,查收到對應的可視化圖表并實現下鉆分析,實現數據分析效率的提升。
但在企業具體的實踐中,重新學習輸入 prompt(提示),并不能為專業的分析師“減負”;而對 BI 工具不精通的員工,在使用這類能力時,又會遇到如何選擇數據集等“專業”難題。
同時,籠統的分析助手無法理解不同行業與業務中的“黑話”,不理解使用者的真實意圖,從而大幅降低分析準確性。
“Data Fabric 驅動下的 ChatBI 智能體”解決方案,正在試圖解決上述這些問題:通過構建完整的智能數據服務體系,打破數據“專業”壁壘,幫助企業內每個業務都能定制專屬智能體,持續降低數據使用門檻,提升大模型能力下的數據反饋效率和準確率。
在這套解決方案中, Data Fabric 通過語義層和數據模型的整合,重構了數據生產關系,在顯著降低數據存儲和計算成本的基礎上,讓數據服務變得更加敏捷;而 ChatBI 智能體則能更貼合業務個性化需求,通過交互理解、數據訪問、分析推理和結果生成四大模塊,極大提升業務員工的數據生產力,讓數據消費變得更加簡單直接。
數據顯示,在字節跳動內部,這套方案已覆蓋超 200 個分析場景,每天處理 10 萬余次分析請求,平均分析時間降低了 80%,數據開發和運維成本也大幅下降。
數據資產的新生力:多模態數據湖
如果說“Data Fabric 驅動下的 ChatBI 智能體”解決方案,是火山引擎數智平臺持續在服務企業過程中,不斷洞察新的業務需求,實現的“數據+AI”能力沉淀和升級。那么“多模態數據湖”解決方案的誕生,則更像他們洞見當下企業即將遇到的問題時,所作出的敏捷反應。
LLM 的大熱,讓企業對于 AI 賦能的數字化滿懷憧憬,眾多企業投身大模型于業務場景的落地實踐。然而技術魅力與現實困境共生,大模型催生的圖像、視頻、音頻等海量多模態數據正在挑戰傳統湖倉技術。
傳統的結構化數據處理,無法滿足當下對多模態數據的存儲、計算,也無法挖掘出這部分數據背后的資產價值。
在深度參與大模型產業的同時,火山引擎數智平臺亦敏銳感知到了非結構數據變現成企業核心數據資產的意義。
多模態數據湖解決方案,應運而生。
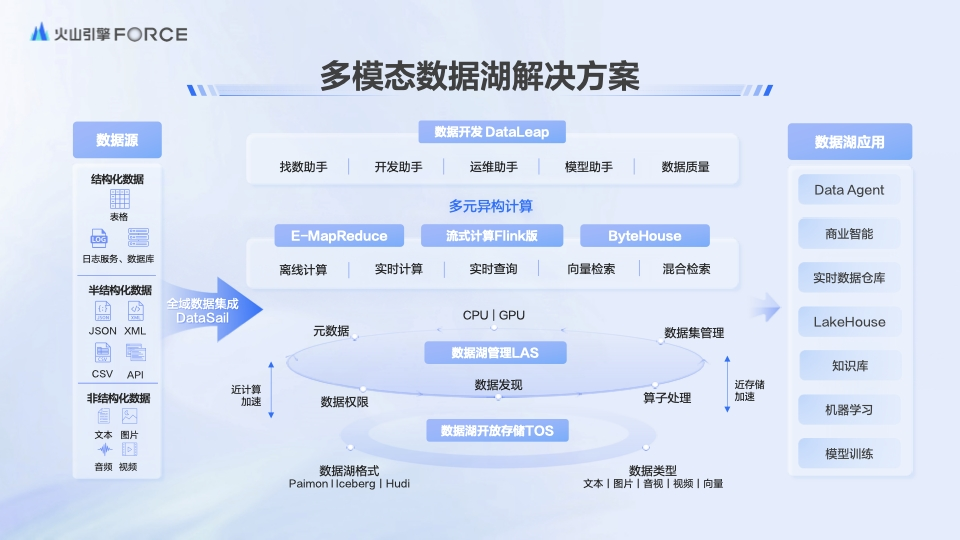
火山引擎多模態數據湖解決方案
火山引擎數據飛輪 2.0 所推出的多模態數據湖解決方案,可實現海量結構化、半結構化及非結構化數據的統一精細化管理,全方位兼容各類數據格式,為 LLM 預訓練、持續訓練和微調全程各個環節提供更好的數據支持。
從數據源來看,火山引擎多模態數據湖方案可實現各類數據的統一管理;在算子處理方面,該方案提供了 100 多種開箱即用的非結構數據處理算子;在多元異構計算上,方案提供了 CPU+GPU 異構計算,能讓數據計算提效 3 倍以上。
目前,該解決方案已廣泛應用在泛互聯網、汽車等行業,并取得實效。
以聚焦于智能網聯汽車的某科創公司為例,最初該公司使用自建開源大數據平臺支撐車聯網數據采集、加工及分析,但存在實時離線數據割裂、數據膨脹、系統穩定性低等問題。
通過引入火山引擎多模態數據湖解決方案,該公司將火山引擎 E-MapReduce 作為數據湖 OLAP 引擎,構建兼具離線、實時的湖倉一體架構,并運用其存算分離架構應對高膨脹增量數據,在確保計算性能 SLA 穩定的同時,成功將維護成本降為零;
還進一步借助全域數據集成 DataSail 實現 OLAP、OLTP 兩種不同負載要求的任務分離,保障了服務的可用性。最終在數據處理實效性提升為秒級的基礎上,資源成本還降低了 30%。
技術之外,能力的培養至關重要
數據飛輪 2.0 模式的誕生,不僅僅是火山引擎在當下技術變革的頂層設計進化。它更是來自字節跳動內部的數據驅動、AI 實踐經驗的再次總結。
事實上,目前火山引擎數據飛輪 2.0 模式提供給企業客戶的能力,均已在字節跳動內部進行了長期的沉淀與優化。
比如,多個業務線搭建了專屬 ChatBI 智能體,數據顯示,基于 ChatBI 智能體,業務用戶可自閉環完成“從業務問題到數據問題”的診斷和分析,數據自助分析率達 90%。
再比如,另一款數智產品增長營銷平臺 GMP 所提供的創意助手能力,生成營銷內容 80%可以無需人工干預直接投放。
經由內部的充分實踐,火山引擎數據飛輪 2.0 模式已經積累豐富的場景經驗。這些技術之外的經驗能力,亦是飛輪 2.0 模式能運行良好的重要保障。
因此,除了能力與方案的發布外,火山引擎在本次大會上也發布了“數據飛輪 2.0 加速計劃”,不僅為想要嘗試新能力的企業提供為期 3 個月的免費試用,更為需要深度挖掘數據飛輪 2.0 場景的企業,提供了最多 3 個月周期的免費項目制陪跑服務。
在為企業提供工具能力的同時,更要向企業傳遞方法與經驗。
據了解,該陪跑服務涵蓋了企業大模型數據應用方案規劃、企業 Data+AI 能力培育、業務陪跑等多個方面,目的是幫助企業用更短時間,更快構建并高效運行數據飛輪 2.0,實現業務價值提升。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號