
云數倉 ByteHouse 的湖倉一體設計與實踐
本次交流將聚焦 ByteHouse 湖倉一體主題,主要介紹:
-
ByteHouse 簡介
-
當代分析平臺的挑戰與 ByteHouse 一體化理念
-
ByteHouse 湖倉一體的核心能力
-
最佳實踐
ByteHouse 簡介
ByteHouse 是什么

ByteHouse 作為新一代云原生架構的數據倉庫,屬于數據倉庫技術流派。
回顧分析生態的發展歷程,自 2004 年 Google 發表 MapReduce 論文,以及 2006 年 Yahoo 推出 Hadoop 產品以來,分析生態領域就存在著多種技術流派。這些流派之間既有競爭,也有相互促進的良性互動。特別是隨著 Hadoop 體系的成熟和開源生態的蓬勃發展,以 Hadoop 為代表的大數據技術流派越來越受到企業和開發者的青睞。
然而,與此同時,以 MPP 為代表的傳統數據倉庫關系型數據庫技術流派也并未退出歷史舞臺。近年來,如 Databricks 與 Snowflake 等廠商之間的“口水仗”,更是凸顯了這兩大技術流派之間的激烈競爭。其中,Databricks 提出的“Lakehouse”概念,雖被視為一種創新,但其實并非全新的技術品類。
事實上,無論是 Hadoop 代表的“湖”技術路線,還是數據倉庫代表的“倉”技術路線,近年來都在不斷演進,呈現出相向而行的趨勢。例如,湖上出現了越來越多的關系型能力,如 Hudi 等技術在 Hadoop 體系上發展了事務能力,以及支持數倉基礎模型的算法等。同時,倉上也具備了越來越多的非結構化和半結構化分析能力。
因此,業界不應再糾結于誰能取代誰,尤其是在大型企業場景下,湖和倉之間越來越呈現出一種融合共存的態勢,這也是很多客戶的訴求。他們希望數據倉庫能夠提升對湖的聯邦能力,而湖也能具備更多數據倉庫的特性。
綜上,ByteHouse 作為數據倉庫關系數據庫技術流派的代表,正是順應了這一趨勢。在接下來的討論中,將更深入地探討 ByteHouse 在湖倉一體方面的核心能力,以及在抖音集團內部的實踐應用。
ByteHouse 支持抖音集團大部分的數據分析應用
接下來,將著重闡述數據倉庫技術流派中的 ByteHouse 是如何構建其數據倉庫,如何實現湖倉一體化的,同時簡要介紹 ByteHouse 在抖音集團的實際應用情況。
ByteHouse 通過獨特的技術架構和設計理念,成功實現了數據的高效存儲、查詢和分析。在湖倉一體化方面,ByteHouse 更是憑借其強大的數據處理能力和靈活的數據模型,打破了數據湖和數據倉庫之間的界限,為用戶提供了更加統一、便捷的數據分析體驗。
在抖音集團,ByteHouse 已經成為了事實上的分析型應用基座。無論是我們日常使用的抖音 APP 中的直播、音視頻等功能,還是背后的用戶數據分析、標簽生成等任務,都離不開 ByteHouse 的支持。ByteHouse 憑借其卓越的性能和穩定性,為抖音集團提供了強大的數據支撐。
從規模上看,ByteHouse 在抖音集團的應用已經達到了行業領先水平,不僅體現了 ByteHouse 在數據處理和分析方面的強大實力,也彰顯了抖音集團對數據分析的深厚積累和持續投入。
總的來說,ByteHouse 通過實現湖倉一體化,為抖音集團等大型企業提供了高效、便捷的數據分析解決方案。
當代分析平臺的挑戰與 ByteHouse 一體化理念
當下云數倉、分析平臺發展趨勢和面臨挑戰

在數據分析平臺和數據倉庫領域,無論是云數倉還是數據湖,高并發、高吞吐的寫入以及高并發的讀取都是最基本的需求。然而,這些年來,我們始終面臨著一系列的挑戰。
一個顯著的挑戰是,盡管業界推出了眾多數據產品,但很少有能夠完全滿足所有主流業務需求的單一產品。因此,我們往往需要通過拼接不同的產品來滿足業務需求,這導致了數據架構的復雜度極高,形成了一個拼湊的技術架構模式。這種拼湊的架構模式使得各個架構之間不兼容,進而產生了嚴重的孤島現象。
近年來,隨著開源生態的發展,這種現象進一步加劇。眾多開源數據產品如 ClickHouse、Doris 等不斷涌現,各自有其優勢,但也加劇了架構的孤島化和復雜度。運維這樣一個龐大復雜的數據架構或數據生態,為運維團隊帶來了極大的壓力,學習成本也相對較高。
為了解決這一問題,ByteHouse 立足于實現湖倉一體化,以打破這種孤島化的現象。
另一個挑戰是成本的可控性。由于架構不靈活,企業往往需要為需求的峰值進行預置,這導致了資源的浪費和成本的增加。在抖音集團內部也存在這種現象。例如,當一個業務從存算一體的傳統架構遷移到 ByteHouse 這種存算分離的云原生架構時,整個成本可以降低到原來的十分之一。
那么,我們如何應對這些挑戰呢?除了性能層面、架構層面的提升,本次分享將聚焦于一體化這一主題,探討 ByteHouse 在這一方面做出的努力。
ByteHouse 一體化理念:數據不再孤島化、數據效能最大化
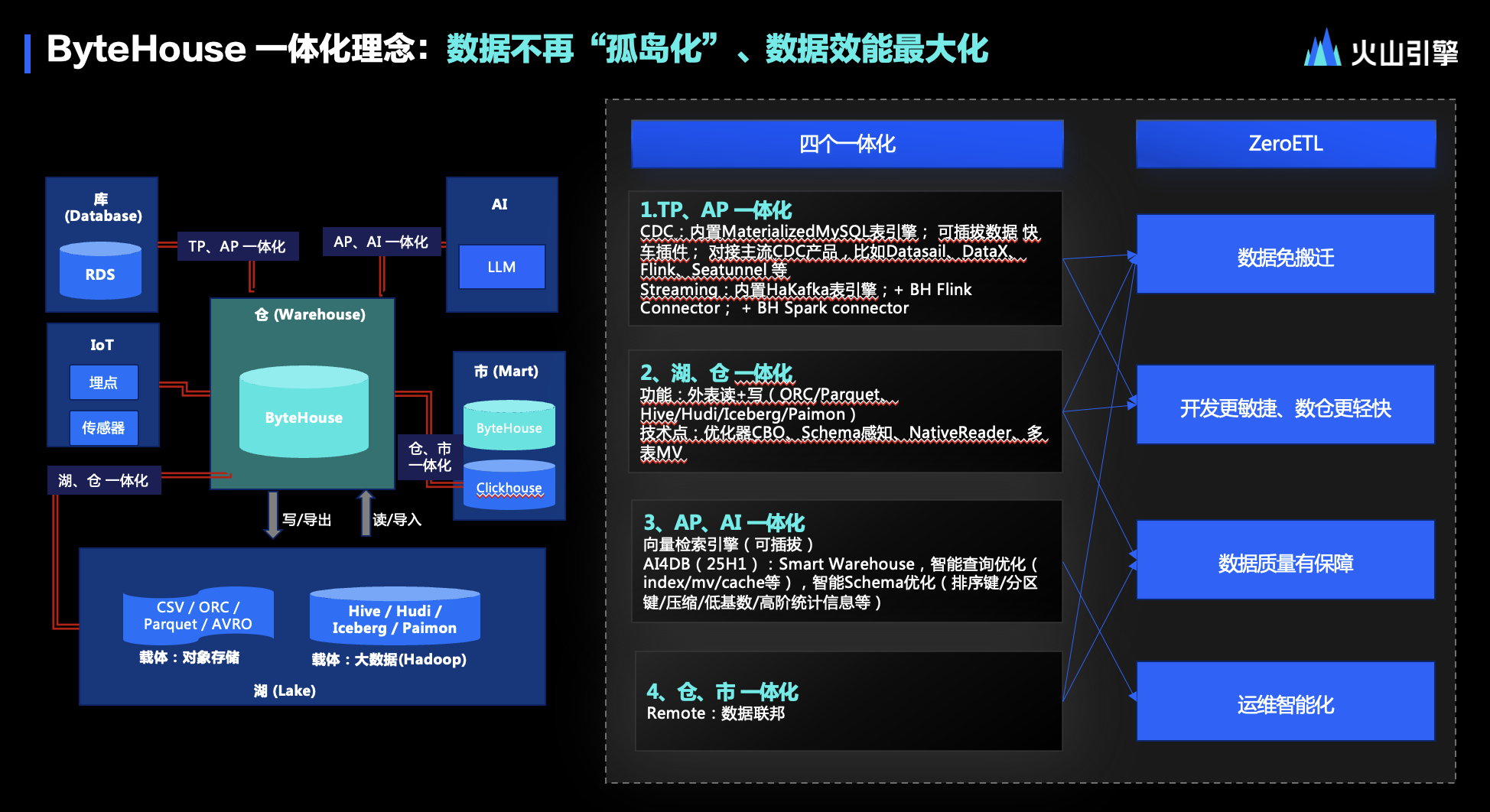
在 ByteHouse 中,如何應對數據孤島化問題,以確保數據架構的有效性和高效性呢?答案在于一體化理念,不僅局限于湖倉一體,而是貫穿于整個數據生態。
如果將數據架構比作人體,那么數據倉庫就像是人體的腰部,它的力量來源于上游源數據等“腿部”的支持,并通過下游各類服務、AI 等“胳膊”的輸出。沒有這些部分的協同,數據倉庫就無法充分發揮其潛力。
因此,ByteHouse 提出了四個一體化的概念。
首先,是 TP(事務處理)與 AP(分析處理)的一體化,這主要涉及到實時數據處理技術,如基于 binlog 的 CDC(變更數據捕獲)技術路線。ByteHouse 支持與主流 CDC 解決方案的集成,以及 Streaming 流式數據的處理,如與 Flink 和 Kafka 等工具的對接也非常順暢。
其次,是湖倉一體化。湖和倉都是分析架構中的核心部分,它們的一體化融合程度直接決定了分析生態的有效性和成本可控性。
再次,ByteHouse 還在探索 AP 與 AI 的一體化,這是未來一段時間內的發力方向。對于大型企業來說,數據倉庫和數據集市之間的一體化也是至關重要的,有助于解決數據冗余和搬遷等問題。
最后,隨著這四個一體化的不斷深入和強化,ZeroETL(無額外數據轉換)的理念將越來越接近現實。通過一體化的融合,減少上下游之間的數據搬遷,使數據架構更加簡潔和輕快。同時,ZeroETL 也能有效避免數據在多個地方的冗余存儲,從而降低成本和提高效率。
綜上,ByteHouse 在一體化方面的追求是:通過一體化的逐漸深入,打破數據孤島化,確保數據架構能夠最大化地發揮數據效能。
ByteHouse 湖倉一體的核心能力

接下來,將深入介紹 ByteHouse 在湖倉一體化方面的核心能力——快、通、全。
首先,“快”是 ByteHouse 設計與規劃的核心。ByteHouse 是基于 ClickHouse 的技術路線進行演進的,底層技術棧也源自 ClickHouse,但對其進行了極大的增強。比如,ClickHouse 在并發處理上存在不足,ByteHouse 已經很好地支持了并發;ClickHouse 在支持復雜數據模型時存在短板,如依賴寬表,對星型和雪花模型等復雜模型支持并不友好,而 ByteHouse 在支持這些模型時,通過自研優化器等手段,不僅場景支持得更寬,效率也更快。因此,“快”始終是 ByteHouse 規劃和設計時秉承第一性原理,通過一系列的組合策略來不斷提升性能。
其次,“通”指的是倉和湖之間的雙向互通。如果只是單向地以外表方式讀取湖里的數據,那并不能算是真正的互通。ByteHouse 追求的是雙向的,既能讀也能寫,從而簡化整個數據架構。
最后,“全”意味著 ByteHouse 能夠通過站在“倉”的視角,預覽并通覽全局數據架構中的高價值數據,包括倉、湖、數據集市等,這也是 ByteHouse 在湖倉一體方面持續增強的能力。簡單來說,就是更快、更融通以及更全面。通過 Multi Catalog(多元數據管理能力),做到一圖覽全域的效果。
接下來,將詳細介紹這三部分核心能力。
快:加速聯邦分析
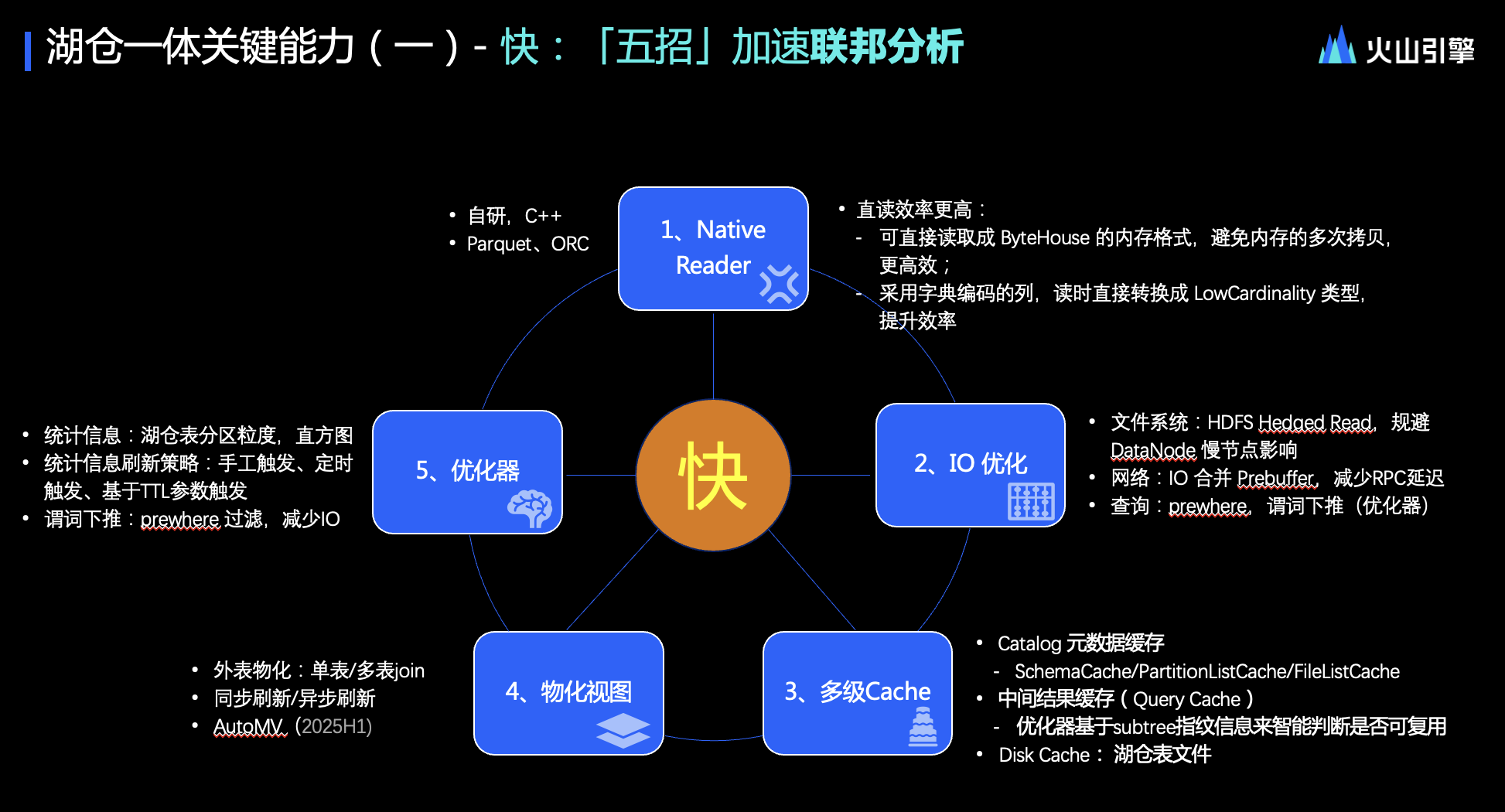
在性能優化方面,無論是開發還是運維團隊,日常工作中往往會將大量精力投入到性能調優與問題解決上。這些性能提升往往不僅僅是點對點的改進,更多的是體系化的提升。ByteHouse 在這一領域有著獨特的做法。
首先,立足于數據湖,無論是文件格式(如 Parquet、ORC)還是表格式(如 Hive、Hudi、Iceberg,甚至是新興的 Paimon),底層數據格式多采用開放式架構。ByteHouse 針對這些開放格式,自研了 Native Reader 特性,旨在提升 Parquet 和 ORC 等開源格式的讀取效率。
與開源的 ClickHouse 通過 Arrow Table 方式進行中轉不同,ByteHouse 的 Native Reader 能夠直接將 Parquet 和 ORC 格式的數據讀取為 ByteHouse 的內存格式,避免了內存中的多次拷貝,從而顯著提高了讀取性能。此外,對于采用字典編碼的列,ByteHouse 在讀取時也能直接轉換為高效的數據格式,如低基列,進一步提升了文件層面的讀取效率。
其次,IO 優化是性能提升的關鍵領域。無論是文件系統、網絡層面還是查詢優化器,IO 優化都是持續迭代的關鍵點
-
ByteHouse 在文件系統層面,針對訪問遠端 HDFS 時可能出現的熱點問題,采用了對沖讀(Hedged Read)優化策略。當查詢指令發出后超時,ByteHouse 會再次發送指令到其他 DataNode,以規避 Hadoop 或 DataNode 上的熱點或抖動情況。實踐表明,這種優化在負載較高的 HDFS 環境中,僅需增加約 10%的帶寬負載,就能使 P95 查詢性能得到極大提升。
-
在網絡層面,ByteHouse 通過 IO 合并策略,將多個小 IO 請求合并為一個大的請求,減少 IOPS,提升 IO 吞吐。同時,利用 Prebuffer 緩存段,方便后續查詢或負載復用,減少網絡層面的 IO 開銷。
-
此外,ByteHouse 還通過更智能的優化器,將謂詞下推到遠端執行,過濾掉遠端數據,進一步減少網絡 IO 開銷。
第三,多級緩存策略也是 ByteHouse 性能提升的重要手段。在進行湖倉聯邦數據查詢時,ByteHouse 會與 Hive metadata 頻繁交互。為了減少這種交互導致的查詢延時,ByteHouse 構建了多級緩存體系。包括 Catalog 緩存、中間查詢結果緩存以及磁盤緩存等。Catalog 緩存將關鍵的元數據信息(如 schema、partition list、file list 等)緩存到內存中,以便快速獲取。中間查詢結果緩存則用于存儲中間結果,方便后續查詢復用。磁盤緩存則用于緩存遠端湖中的數據文件。這些緩存策略共同提升了 ByteHouse 的性能。
第四,物化視圖是 ByteHouse 性能優化的另一大利器。ByteHouse 支持對外表進行物化,包括基于視圖的物化視圖和單表物化視圖等。此外,還支持多表緩存(帶有業務屬性的聚合)。這些功能不僅提升了湖倉性能,還可用于點查場景。同時,ByteHouse 還在內部業務中試點 auto MV(自動物化視圖)功能,通過機器學習和強化學習手段分析查詢日志和歷史,自動為需要加物化視圖或索引的字段和表添加相應的優化。目前 auto MV 功能尚未產品化,預計將在明年上半年擇期推出。
最后,優化器是 ByteHouse 性能提升的核心組件。為了制定更好的執行路徑,統計信息至關重要。ByteHouse 支持對湖倉外表和表進行分區粒度的統計信息收集,并通過直方圖方式展示數據分布,幫助優化器制定更優的執行計劃。同時,ByteHouse 還提供了統計信息的手動刷新、定時刷新等能力。然而,在湖倉聯邦場景中,由于遠端湖的數據量巨大,自動刷新可能會對湖、倉的負載以及整個湖倉聯邦分析性能產生較大沖擊。因此,在當前視角下,我們更建議采用計劃內的刷新方式,如手工觸發或定時觸發等。
綜上,ByteHouse 通過自研 Native Reader、IO 優化、多級緩存、物化視圖以及優化器等多個領域的持續迭代和增強,加速了湖倉聯邦分析的性能提升。
接下來,將展示這些策略帶來的成效。
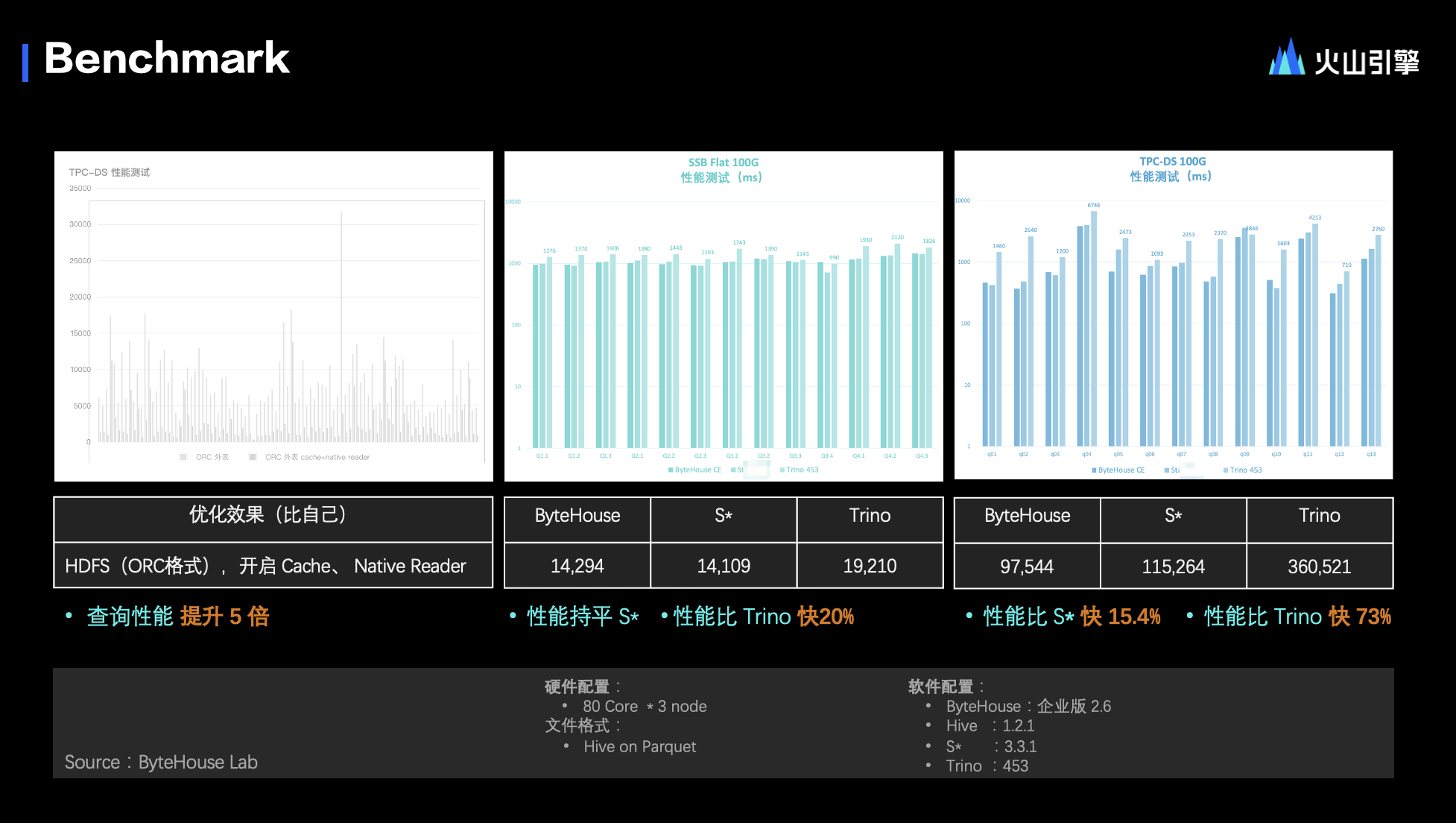
首先,第一個 Benchmark 是自己與自己對比的測試場景。在這個場景中,ByteHouse TPC-DS 所有數據都以 ORC 格式存儲在 HDFS 分布式文件系統中。在此基礎上,我們啟用了之前提到的 Cache 能力和第一個 native reader 能力。開啟這兩個功能后,性能優化效果顯著,直接提升了五倍。
接下來,再看傳統意義上的 OLAP 寬表分析場景。在 SSB 寬表分析領域,我們在測試環境中,將 ByteHouse 與行業同類產品進行了 Benchmark 比對。無論是 SSB 寬表模型,還是 TPC-DS 這種較為復雜的分析模型,如維度型、雪花型等,ByteHouse 的表現都相當出色。
通:簡化架構,實現 ZeroETL
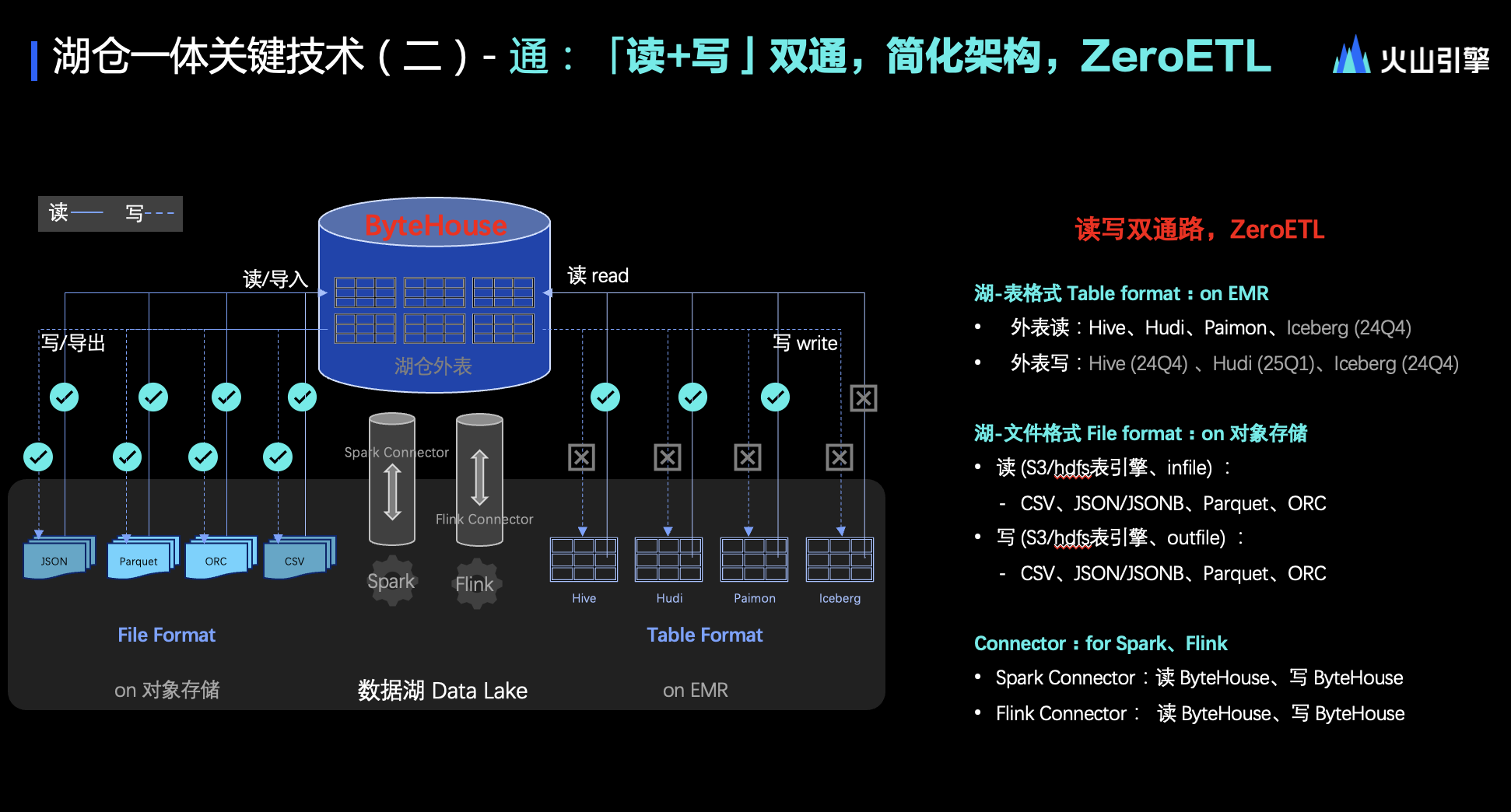
下面探討第二個關鍵技術——“通”,這不僅僅是讀取能力,更包括了寫入能力,即雙向的互操作性。這樣的設計能夠極大地簡化數據湖與數據倉庫之間的架構,甚至有可能完全規避復雜的 ETL 過程,從而實現 Zero ETL 理念的落地。
關于數據湖的實現,目前存在兩種主要流派。
-
第一種流派主要依賴于對象存儲,并以文件格式(如 parquet、ORC 等開放格式)進行數據承載。這種方式在一些地區的大型企業中有案例,其主要目的是提升架構的簡易性和通用性。這些企業會在對象存儲上存儲所有數據,然后利用 Presto、Trino 或 Spark 等分析引擎進行構建,形成數據湖。
-
而在國內,無論是互聯網企業還是金融等傳統大型企業,其數據湖架構更多是基于表格式,通過 Hive、Hudi、Iceberg 以及 Paimon 等表格式進行數據承載。這種方式的目標是讓數據湖更像數據庫,因為數據庫的 SQL 體驗是簡單且標準化的。
無論是哪種流派的數據湖實現方式,都在持續迭代和增強讀寫的雙向互操作性。以文件格式為例,無論是 JSON、JSONB、Parquet 還是 CSV 等半結構化格式,我們都已經實現了雙向的讀寫互操作性。從 ByteHouse(數據倉庫)的視角來看,這些格式的數據都能自由地進出。
在應用層面,比如 AI 領域,很多數據清洗工作都采用了這種模式,將數據存儲在對象存儲上,然后利用 Spark 引擎或其他 Reader 引擎進行直接讀取。在這個流派中,ByteHouse 已經實現了讀寫的雙向互操作性。
對于表格式的數據湖實現方式,ByteHouse 目前還在進行迭代和完善,目前已經打通了大部分讀鏈路,但寫鏈路還在規劃中。比如 Hive 的寫功能預計在這個季度(Q4)完成,Hudi 的寫功能可能會在 2025 年第一季度早些時候實現,而 Iceberg 的寫功能也計劃在這個季度(Q4)進行實現。
此外,業務還可能從數據湖或 EMR 的視角出發。因此,ByteHouse 提供了中間管道和 Spark Connector(由 ByteHouse 開發并免費提供),讓 Spark 能夠方便地讀取和寫入 ByteHouse 的數據,進行邏輯加工,同時也可以將 ByteHouse 的數據拉取出來進行加工和負載,或者落回到 ByteHouse、EMR 或 Hive 中。這個鏈路的暢通性是沒有問題的。
至于 Flink,ByteHouse 有很多實時數倉的案例都是聯合 Flink 構建的。例如,在某個游戲領域,利用 Flink 和 ByteHouse 實時去重寫入能力,可以實現每秒 260 萬筆數據的實時去重落盤,達到了業界領先的性能。
全:Multi-Catalog 一圖覽全域
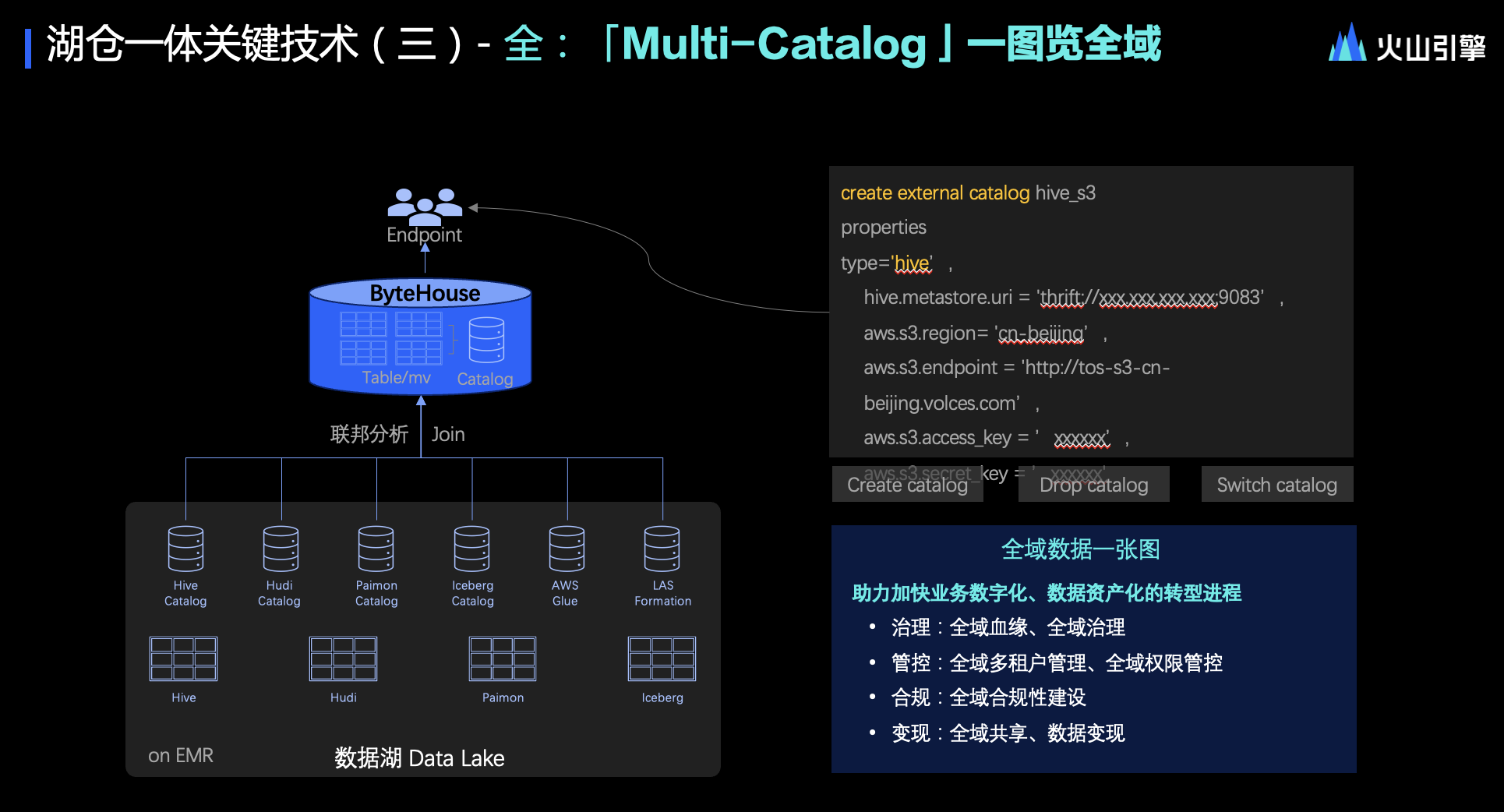
第三個關鍵點聚焦于“全”,即全面性與整合性。具體來說,當我們站在數據倉庫(Endpoint 或倉)的視角時,不僅能夠看到倉庫內的數據,還能無縫瀏覽到數據湖中的數據。簡而言之,就是實現“一圖覽全域”的能力。這一能力在技術上并不涉及特別大的阻礙或壁壘,更多是關于與眾多主流 Catalog(如 Hive、MA/MIMS、Hudi、Iceberg 乃至 Paimon 等)的打通、融合及兼容性工作。
ByteHouse 正在致力于將這些 Catalog 進行整合,追求的效果是能夠將全域數據真正匯聚成一張圖。回顧過去,元數據的重要性早已被業界所認識。十多年前,業界就開始探討如何構建企業的數據資產化。如果無法提供一個高效、全景式的數據視圖,那么企業的數據資產化無疑會成為空談,難以落地。
通過技術的不斷迭代,能幫助企業站在數據倉庫的視角,清晰地看到全域數據,這將極大地加速企業數據資產化的轉型進程。從數據治理的角度來看,ByteHouse 已能夠追溯全域數據的血緣關系,實現全域數據治理和管控,包括管理全域的租戶權限等。
此外,業務層面也提出了將數據變現的需求。要實現全域數據共享和更好的數據變現,數據質量至關重要。如果數據質量不佳,數據變現將舉步維艱,難以持續。
“全”是湖倉一體架構中一個非常關鍵的技術點。盡管在技術實現上并沒有太大的壁壘,但需要不斷迭代,以兼容更多主流的數據湖 Catalog 格式。通過這一努力,ByteHouse 將為企業提供更全面、更整合的數據視圖,助力企業實現數據資產化、數據治理和數據變現等目標。
最佳實踐
案例:抖音集團內部 BI 平臺 Zero ETL 最佳實踐

接下來分享抖音集團內部 BI 平臺的實戰案例。作為一個全面的 BI 平臺,它涵蓋了固定報表、靈活查詢以及管理駕駛艙等多種功能。
該 BI 平臺的初衷源于對原有復雜架構的革新需求。在過去,架構是組合式的,包括基于 Hive 架構的“湖”和 ByteHouse(稱之為“倉”)兩部分。每天,加工好的數據都會從湖中推送到倉里,而 BI 報表則需要同時連接湖和倉。這種雙連接的架構較為復雜,給管理和維護帶來了不小的挑戰。
在 ETL 方面,研發人員也面臨著規模龐大、SLA 不穩定等問題。因此,業務訴求是希望通過湖倉一體的融合模式來簡化架構,實現 Zero ETL 的理念。雖然 Zero ETL 是一個理想狀態,但至少先減輕 ETL 架構的負擔。
除了簡化架構外,業務還希望 Zero ETL 能夠支持復雜的查詢,包括多維度的查詢和新型維表查詢等。同時,ETL 任務既可以在湖中運行,也可以在倉中運行,以減輕湖中的加工分析負載。
此外,透明化目標之一。從 BI 用戶的角度來看,他們不需要清楚數據是存儲在湖中還是倉中,只需要通過鏈接訪問一個地方即可。這種透明化將大大簡化面向業務的開發工作。
在以上訴求上,還期望實現降本和提效。
為了滿足這些業務訴求,ByteHouse 研發團隊與業務團隊進行了緊密合作,采用了新一代 Data Fabric 架構。這種架構能夠助力實現 Zero ETL 或簡化架構。
在 Zero ETL 的關鍵技術方面,通過在 ByteHouse 中建立 Hive 外表,讓外表能夠自動感知 Hive 的 DDL 變化,無需人工刷新。這得益于 Hive 將 DDL 變化推送到 Kafka 中,ByteHouse 能夠實時抓取這些信息。
此外,ByteHouse 還支持在 SQL 中查詢多個外表的組合。在 Data Fabric 架構中,物化視圖是一個與性能密切相關的關鍵組件,ByteHouse 的物化視圖既能構建在外表之上,也能構建在視圖之上。同時,ByteHouse 還優化了單表和多表查詢的性能,特別是多表 join 的場景。
為了進一步提升智能化和性能優化能力,ByteHouse 還在業務上進行了 auto MV 的試點。這一舉措讓整個鏈路更加智能,減少 DBA 和優化層面的投入。同時,它還能根據日志自動發現慢查詢并進行優化。
從已經投產的部分業務來看,效果顯著。在性能層面,實現了兩到三倍的提升;在存儲層面,降低了約三分之一的成本。這主要得益于 Zero ETL 和 Data Fabric 架構的輕量化設計,減少了中間結果的存儲占用空間。
以上就是關于抖音集團內部 BI 平臺 Zero ETL 實戰應用的一些階段性產出和初步成果。
后續發展規劃
近期規劃——讓 ByteHouse 變得更加智能,即實現其智能化(smartization)。具體而言,聚焦于兩個維度:
-
首先,致力于讓查詢加速過程更加智能,例如通過自動物化視圖(auto MV)和自動索引(auto index)等技術手段,以及優化內部緩存機制,不僅限于使用 LRU 算法,還將引入 LFU 等更多算法,以提高緩存的效率和智能性。
-
其次,實現運維的智能化和無人化,包括自動優化表的分布鍵、排序鍵以及選擇最合適的壓縮算法,以最大化性能和壓縮空間。同時,ByteHouse 還將對集群內部的工作負載進行更智能的感知和優化,實現任務隊列的智能化管理,以及自動參數優化,減少對人為或專家(如 DBA)的依賴。
中長期規劃——持續增強 ByteHouse 作為 AI 底座的支撐能力,讓更多的 AI 負載能夠在 ByteHouse 上運行。
-
積極融入 AI 生態,特別是增強與 Python 的兼容性和融合能力,因為 Python 是 AI 生態中的主流語言。
-
計劃逐步加速 AI 全流程,包括數據清洗、特征工程、模型訓練和模型推理等各個環節,充分發揮 ByteHouse 在性能方面的優勢。
-
在 AI on ByteHouse 方面,逐漸支持主流 AI 框架,如 Pytorch 和 TensorFlow 等,使 ByteHouse 成為一個綜合性的平臺,不僅滿足傳統 DBA 和開發者的需求,還能降低開發者從編碼開發向數據科學家開發轉型的時間成本和學習成本。
以上就是 ByteHouse 接下來的一些重點規劃。我們將不斷努力,推動 ByteHouse 向更加智能、高效和綜合性的方向發展。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號