
基于 OLAP 湖倉一體架構,火山引擎 ByteHouse 助力企業降本增效
在數字化轉型的浪潮中,企業對數據處理能力的要求日益提高。
過去,數據湖和數據倉庫分別擁有兩套獨立的管理體系,這導致維護成本高昂,研發周期漫長。為了加強數據端到端的鏈路整合,構建一套低成本、高性能的數據湖倉一體分析能力成為越來越多企業的需求。
作為火山引擎推出的一款云原生數據倉庫,ByteHouse 基于 ClickHouse 技術路線優化和演進,已具備實時數據分析、海量數據離線分析能力,便捷的彈性擴縮容、極致分析性能以及豐富的企業級特性,在金融、游戲、泛互等領域加速企業數字化轉型。為了進一步提升使用體驗、降低運維成本,ByteHouse 構建了高性能、功能全面的湖倉一體能力,支持對多種數據湖開放格式進行讀寫,并通過優化器和 Schema 動態感知增強性能,確保湖倉間數據高效流動。
據火山引擎 ByteHouse 產品負責人李群介紹:“ByteHouse 湖倉一體能力具備快、通、全三大特點,在保障湖倉數據聯邦的分析高性能的同時,實現湖倉雙向讀寫,精簡了整體架構,還基于 Multi-Catalog 進行多源數據管理,提供更豐富、更全面的一體化能力。”
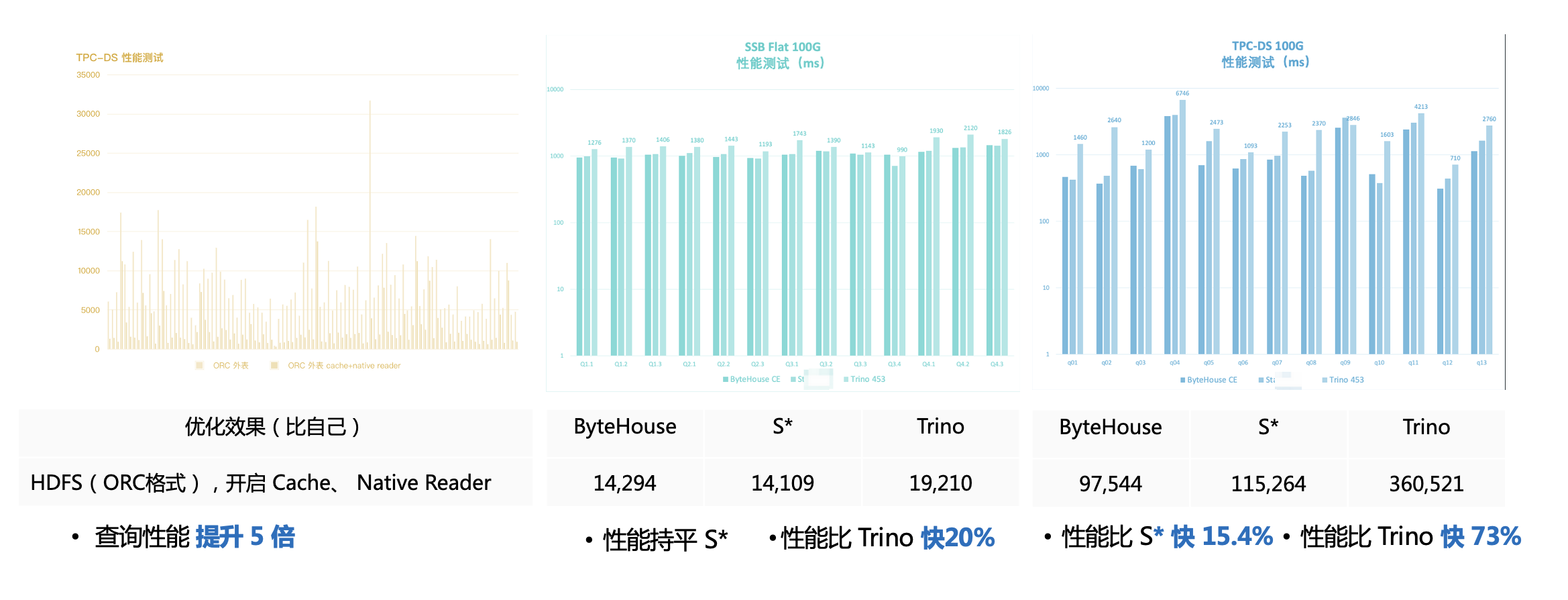
首先,ByteHouse 湖倉一體關鍵能力之一在于“快”。在當今復雜的商業環境下,企業每天需要面臨大量決策,而高效的數據反饋可以提升企業決策效率和準確度。從 Native Reader、IO 優化、多級 Cache、物化視圖、優化器五個方面,ByteHouse 針對性能進行了大量優化。例如,在并發支持和復雜模型處理上,ByteHouse 則通過自研優化器等手段優化了 ClickHouse 的不足,在經典的星星、雪花負載模型下已得到驗證。從數據效果上看,ByteHouse 在 SSB Flat 100G 、TPC-DS 100G 測試中的表現,基本高于行業同類型產品。
其次是“通”。ByteHouse 采用 ZeroETL 理念,實現了湖與倉之間的雙向互通,支持讀取和寫入數據,簡化數據架構。具體而言,ByteHouse 湖-表格式在 EMR 上運行,支持對 Hive、Hudi、Paimon、Iceberg 等多種數據源的外表讀操作。而湖-文件格式則支持在對象存儲上進行 CSV、JSON/JSONB、Parquet、ORC 等多種格式的讀寫操作。此外,ByteHouse 還提供了 Spark、Flink 等 Connector,方便企業將 ByteHouse 與其他大數據處理框架進行集成,實現更加高效的數據處理和分析。
最后是“全”。基于 Multi Catalog 多源數據管理能力,ByteHouse 具備全域數據一張圖的能力。例如,從治理角度,展示全域血緣、全域治理數據;從管控角度,展示全域多租戶管理、全域權限管控數據;從合規角度,展示全域合規性建設數據等,助力企業從全局視角更好洞察和分析高價值數據,提升數據資產化能力。
除了湖倉一體化,ByteHouse 還從 TP、AP 一體化,倉、市一體化,AP、AI 一體化方面,逐步實現 ZeroETL 輕量化數據架構。通過“四個一體化”策略,不僅讓數倉更輕快,數據免搬遷,還能保障數據質量,實現智能運維。
目前,ByteHouse“四個一體化”策略已經在抖音集團內部 BI 平臺落地和驗證,在報表查詢、管理駕駛艙、指標平臺等業務場景中,將性能至少提升 2 倍,成本降低 33%。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號