
火山引擎數(shù)智平臺(tái):高性能ChatBI的技術(shù)解讀和落地實(shí)踐
導(dǎo)讀:大模型能力的發(fā)展和成熟,催生出新一代智能化 BI—— ChatBI,即通過自然語言處理(NLP)與大型語言模型(LLMs)的結(jié)合,極大簡(jiǎn)化數(shù)據(jù)分析過程,提高效率并降低分析門檻。火山引擎數(shù)智平臺(tái)旗下智能數(shù)據(jù)洞察產(chǎn)品 DataWind 近期上線 ChatBI 能力,提供智能修復(fù)、多語法適用等能力,在性能上實(shí)現(xiàn)秒級(jí)響應(yīng)、一鍵生成。用戶只需要通過文字描述需求, 就能生成指標(biāo),快速實(shí)現(xiàn)數(shù)據(jù)獲取、分析計(jì)算與圖表搭建,大幅降低數(shù)據(jù)消費(fèi)門檻。本篇文章將從技術(shù)架構(gòu)、實(shí)現(xiàn)路徑、總結(jié)展望幾個(gè)方面,拆解火山引擎數(shù)智平臺(tái)如何落地 ChatBI 能力。
BI 其實(shí)是一個(gè)由來已久的名詞。其中 I——“intelligence”的內(nèi)涵已經(jīng)隨著時(shí)間推移和時(shí)代發(fā)展而逐漸發(fā)生變化。
起初,人們認(rèn)為在數(shù)據(jù)儀表盤和看板上能夠進(jìn)行篩選條件變更與維度下鉆就是智能化表現(xiàn)。
而隨著平臺(tái)更新迭代,更多高階、復(fù)雜的功能以更易操作的形式更新到平臺(tái)中,讓沒有計(jì)算機(jī)背景或編程背景的人也能夠深切體會(huì)到代碼、計(jì)算機(jī)或者大數(shù)據(jù)時(shí)代所帶來的智能之感。
隨著 AI 時(shí)代的來臨,大家對(duì)于智能化有了更多期待。例如: 它是否能夠“猜到”自己的想法進(jìn)行智能推薦?或是,當(dāng)看到數(shù)據(jù)異常,它能否幫忙找出原因?
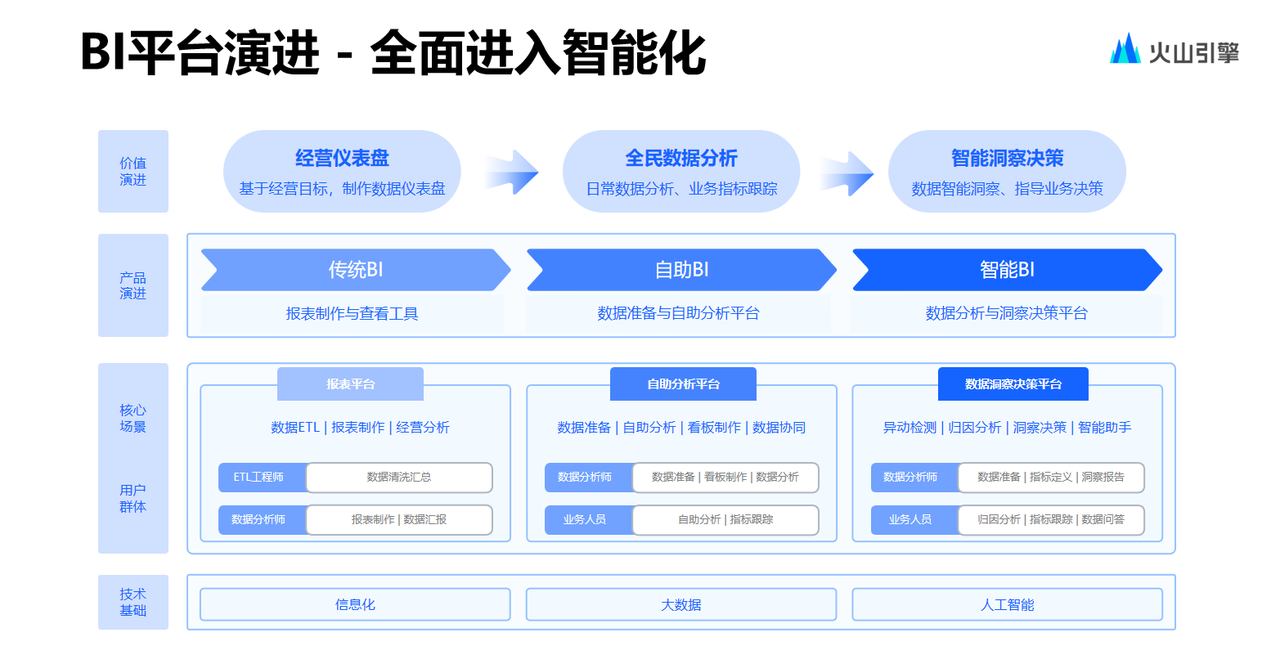
客觀而言,從 2018 年開始開發(fā)的抖音集團(tuán)內(nèi)部 BI 平臺(tái)起步較晚。 因此其直接跳過了 BI 平臺(tái)早期發(fā)展階段,從立項(xiàng)之初,它的目標(biāo)便是成為能夠滿足公司內(nèi)部幾乎所有數(shù)據(jù)分析需求的數(shù)據(jù)分析平臺(tái)。
在抖音集團(tuán)內(nèi)部,BI 平臺(tái)建設(shè)分為以下幾個(gè)階段:
一是 2020 年前后的開發(fā)建設(shè)。在這個(gè)階段投入了大量資源,對(duì)結(jié)果歸因相關(guān)功能進(jìn)行開發(fā),希望能夠幫助用戶解決歸因問題。
二是在 2021 年 4 月,發(fā)布了低代碼的可視化建模工具。原因在于,團(tuán)隊(duì)不想讓用戶在數(shù)據(jù)分析的過程中發(fā)現(xiàn)數(shù)據(jù)尚未準(zhǔn)備完畢時(shí),需要去專門聯(lián)系數(shù)倉開發(fā)人員重新準(zhǔn)備一份數(shù)據(jù)。為此開發(fā)了可視化建模工具,希望用戶僅需要進(jìn)行簡(jiǎn)單的拖拉拽操作就可以輕松處理數(shù)據(jù)。
三是 2023 年年底。內(nèi)部團(tuán)隊(duì)面對(duì)迅速發(fā)展的 ChatGPT,認(rèn)為它會(huì)對(duì) BI 產(chǎn)生具有如“掀桌子”一般顛覆性的影響,因此經(jīng)過一段時(shí)間的嘗試,便在今年 4 月份對(duì)內(nèi)進(jìn)行了產(chǎn)品發(fā)布。就目前而言落地效果不錯(cuò),已經(jīng)有幾千人在高頻使用這一內(nèi)部產(chǎn)品。
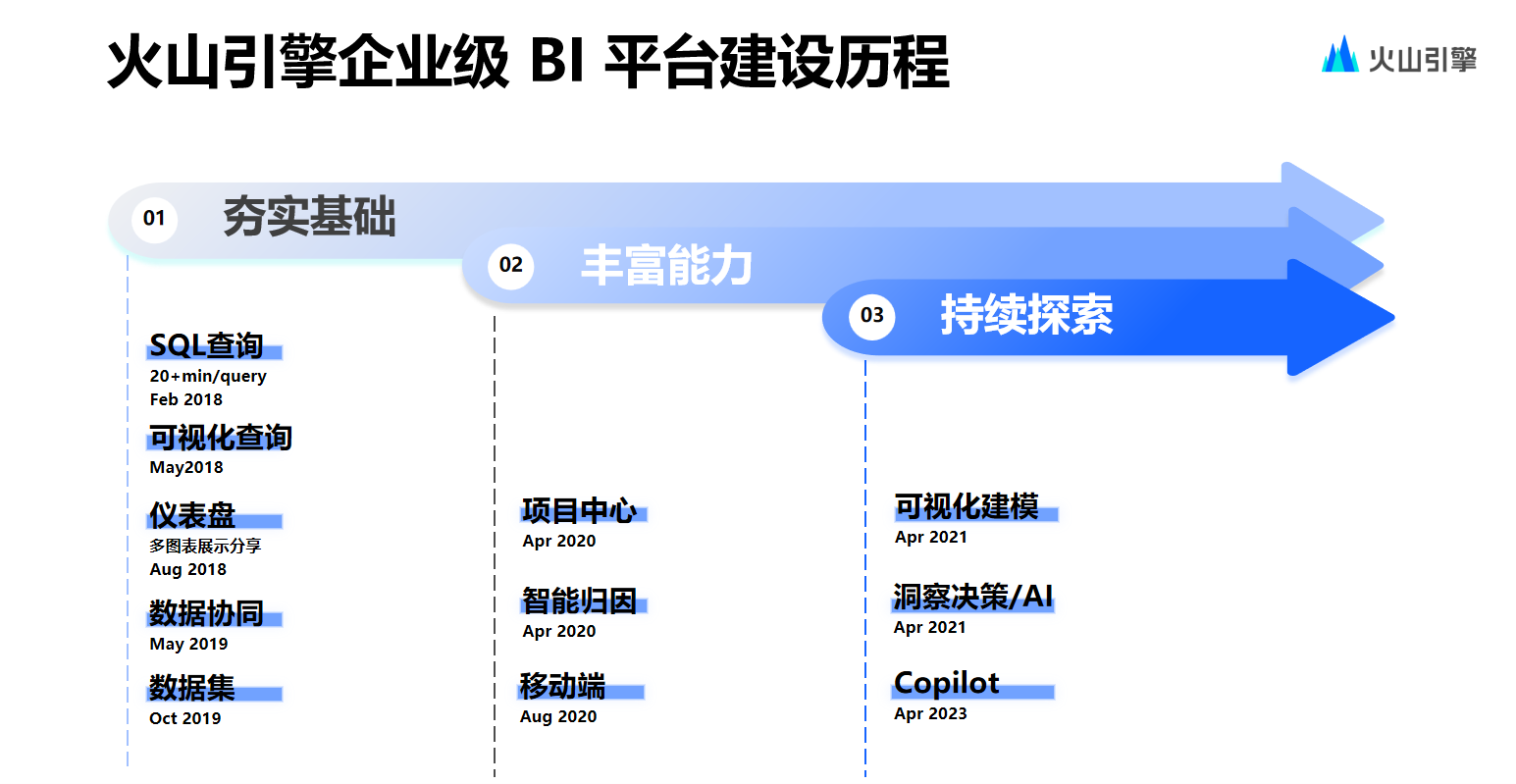
當(dāng)前,火山引擎數(shù)智平臺(tái)旗下的智能數(shù)據(jù)洞察 DataWind 已構(gòu)建起包含了數(shù)據(jù)準(zhǔn)備與管理,數(shù)據(jù)分析,以及多端展示等功能的相對(duì)完善的產(chǎn)品能力矩陣,同時(shí)賦予產(chǎn)品系統(tǒng)高度可運(yùn)維優(yōu)勢(shì)。

截至目前,抖音集團(tuán) 80%內(nèi)部員工成為產(chǎn)品月活用戶,同時(shí)在工作日單日的產(chǎn)品最低查詢量基本處于 200w 次以上。

火山引擎數(shù)智平臺(tái)高性能數(shù)據(jù)分析架構(gòu)方案
數(shù)據(jù)驅(qū)動(dòng)決策,是在抖音集團(tuán)內(nèi)部深入人心的重要概念,并與公司所推行的 OKR 理念相互契合。由于 OKR 通常以指標(biāo)化方式去衡量,在指標(biāo)出現(xiàn)問題需要進(jìn)行排查探尋原因時(shí),數(shù)據(jù)分析便成了必不可少的過程。同時(shí),在排查過程中用戶腦海中會(huì)同時(shí)存在多種分析思路,如果數(shù)據(jù)分析時(shí)間過長(zhǎng),就會(huì)將原本的分析思路打斷。因此,為了實(shí)現(xiàn)高速分析,企業(yè)內(nèi)部員工用戶對(duì)分析平臺(tái)的性能有著極大要求。
盡管性能十分重要,但 BI 平臺(tái)開發(fā)廠商往往認(rèn)為其更多與引擎有關(guān):引擎能力較差會(huì)導(dǎo)致 BI 所能處理的事情并不多。
但數(shù)據(jù)集、數(shù)據(jù)源、數(shù)據(jù)量的大小以及 Query 的復(fù)雜程度等并不是用戶所關(guān)心的,他們關(guān)心的是自己的數(shù)據(jù)分析能否能快速完成。因此在提高性能方面的開發(fā)面臨著很大挑戰(zhàn)。
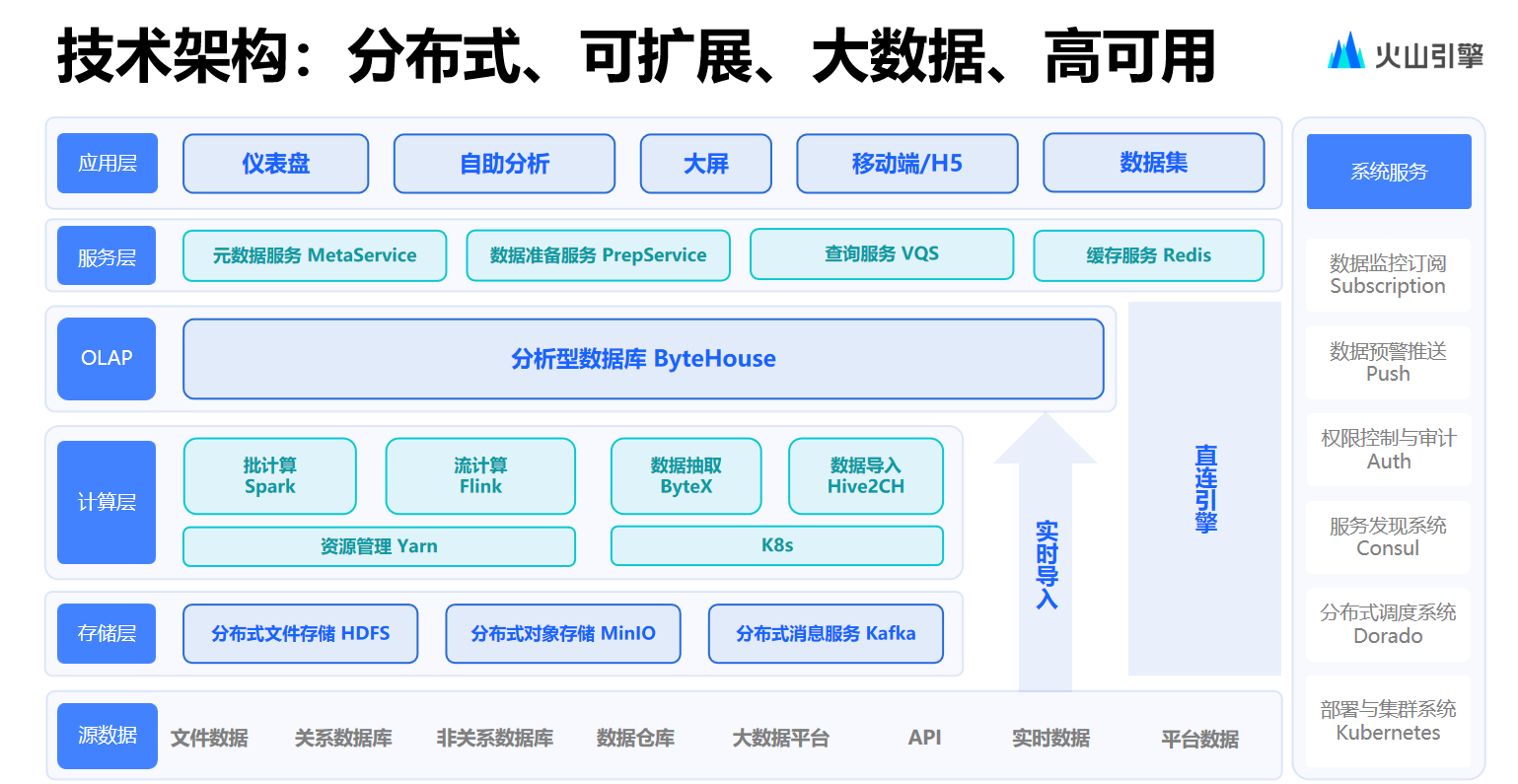
為了滿足用戶對(duì)性能的需求,開發(fā)中采取了有別于主流 BI 廠商的思路。雖然 DataWind 產(chǎn)品支持直連目前通用的大部分?jǐn)?shù)據(jù)源、數(shù)據(jù)引擎與數(shù)據(jù)庫。但在企業(yè)內(nèi)部用戶更多地使用“抽取”,即圍繞自研分析性數(shù)據(jù)庫 ByteHouse 建設(shè)了非常重的抽取鏈路,把公司內(nèi)幾乎全部需要進(jìn)行數(shù)據(jù)分析的數(shù)據(jù)全部放入 ByteHouse 中。
由于數(shù)據(jù)存放方式對(duì)于查詢效率有著極大影響,因此 BI 團(tuán)隊(duì)使用了大量的 ByteHouse 集群來滿足用戶對(duì)于實(shí)時(shí)連接、離線連接、不同表引擎連接的需求
同時(shí),如何充分有效地利用 ByteHouse 高性能引擎也十分重要。比如應(yīng)該向什么樣的集群推薦數(shù)據(jù)集,選擇什么樣的表引擎,以及確定什么樣的分片和排序鍵策略等。這些為問題對(duì)于性能而言都相當(dāng)關(guān)鍵。

在這里,先簡(jiǎn)單介紹一下 ByteHouse。相較于原生 Clickhouse,ByteHouse 針對(duì)多個(gè)領(lǐng)域做了性能優(yōu)化。
首先,是 HaMergeTree 方面的優(yōu)化工作。HaMergeTree 對(duì)于大部分企業(yè)用戶而言都不可或缺。原生 ClickHouse 在對(duì) Apache ZooKeeper(ZK)存在較大依賴,在文件的 part 信息處理方面依賴性更甚。這就導(dǎo)致 ClickHouse 處理大規(guī)模數(shù)據(jù)集時(shí),易造成 ZK 資源緊張,管理的 znode 數(shù)量暴增,影響系統(tǒng)性能和穩(wěn)定性。
ByteHouse 對(duì)此進(jìn)行了大量?jī)?yōu)化,從而降低了對(duì) ZK 的依賴程度。目前在 ByteHouse 中,對(duì) ZK 的一臉僅僅存在于 schema 信息,以及生成自增序列等極少數(shù)場(chǎng)景中,從而保證了 ByteHouse 的整體性能和可用性。
在 HAUniqueMergeTree,即原生 ClickHouse 的 Raplacing MergeTree 方面。相對(duì)而言,ClickHouse 引擎在讀取方面并不高效,而 ByteHouse 在處理此方面問題時(shí),會(huì)通過建立一定的索引實(shí)現(xiàn)對(duì)記錄的快速更新和標(biāo)記刪除,從而提高性能。
此外,原生 Clickhouse 的 join 能力因?yàn)閷?duì) coordinator 節(jié)點(diǎn)壓力較大的問題被大家詬病已久。ByteHouse 在這個(gè)方面實(shí)現(xiàn)了真正的分布式 join,同時(shí)也基于此做了大量?jī)?yōu)化器方面的工作。例如當(dāng)大表 join 小表時(shí),ByteHouse 會(huì)根據(jù)小表的數(shù)據(jù)情況進(jìn)行自主判斷,去對(duì)大表中的部分?jǐn)?shù)據(jù)免讀或免下封。
總體而言,把大量數(shù)據(jù)導(dǎo)入 ByteHouse 并不意味著表的數(shù)量很多。在抖音集團(tuán)內(nèi)部,大家更愿意把更全面、更明細(xì)的數(shù)據(jù)導(dǎo)入到 ByteHouse 集群中,從而避免在做數(shù)據(jù)分析的過程中出現(xiàn)某一方面的數(shù)據(jù)不存在或者明細(xì)級(jí)別不夠的情況。
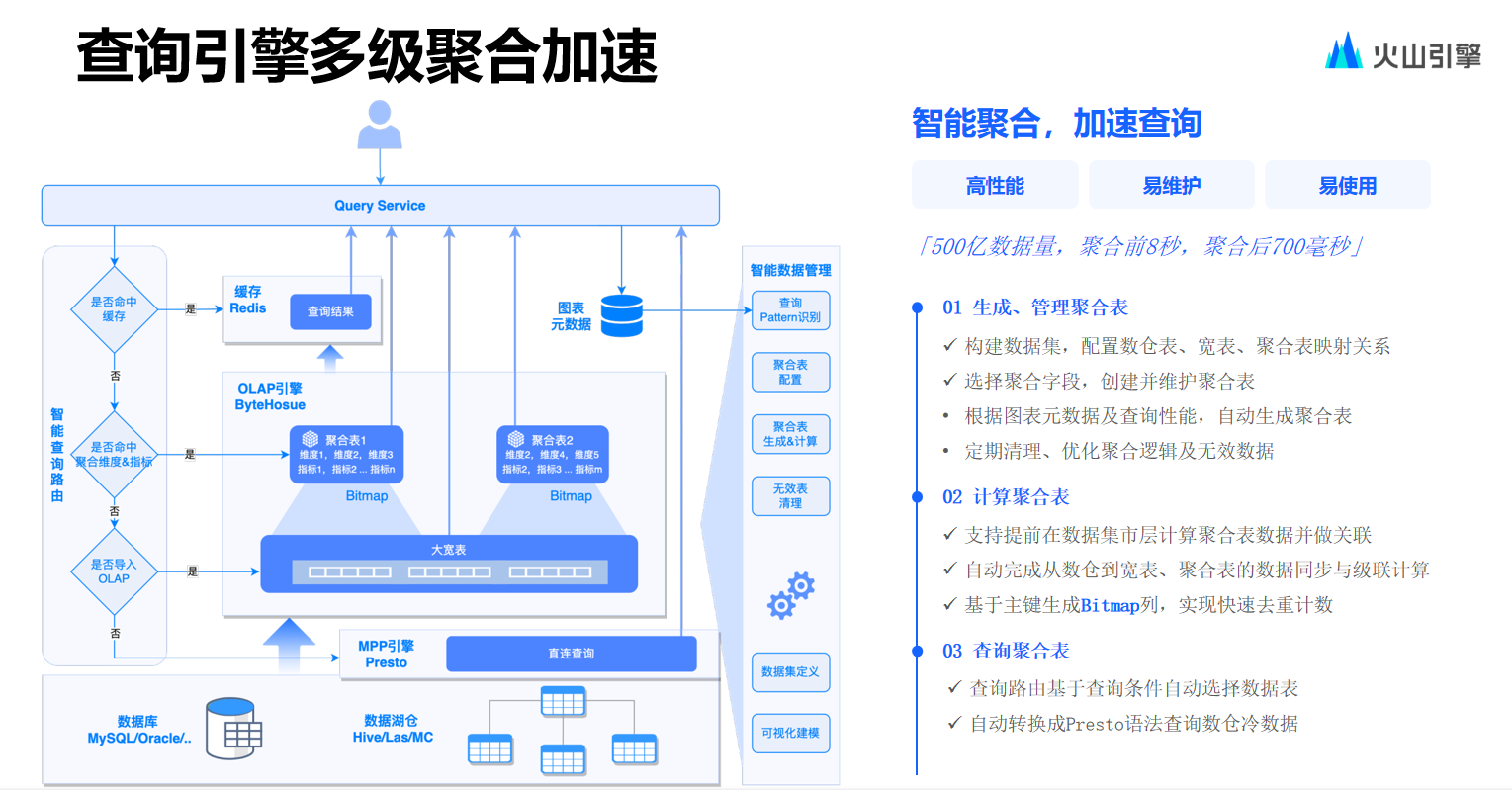
在使用到非常細(xì)的粒度的場(chǎng)景,團(tuán)隊(duì)認(rèn)為大部分查詢是基于某些高頻指標(biāo)維度,去找到非常明細(xì)的數(shù)據(jù)所做的查詢。因此會(huì)很容易地想到解決方案,即建立一些 Cube 或物化視圖,并且建立一些自動(dòng)路由。
對(duì)于用戶而言,這些操作都是十分透明的。而從工程上值得一提的是,團(tuán)隊(duì)并沒有使用 ByteHouse 自帶的物化視圖或是 projection 方式,因?yàn)樵陂_發(fā)實(shí)踐測(cè)試中,發(fā)現(xiàn)這種方式對(duì)于集群與整體性能有負(fù)面影響。目前,開發(fā)中主要使用基于 Hadoop 鏈路與基于 Spark 的鏈路去進(jìn)行 Cube 建設(shè),并且由此實(shí)現(xiàn)自動(dòng)路由。從用戶角度來看,用戶會(huì)面對(duì)一張寬泛且明細(xì)力度極細(xì)的大表。
但這種方法的副作用在于由于產(chǎn)品的各個(gè)業(yè)務(wù)線都采取了付費(fèi)使用形式,為數(shù)據(jù)集建設(shè)了大量聚合表必然會(huì)導(dǎo)致成本的上升。這就涉及到一個(gè)新的問題:在滿足了用戶的速度要求情況下,如何降低成本?
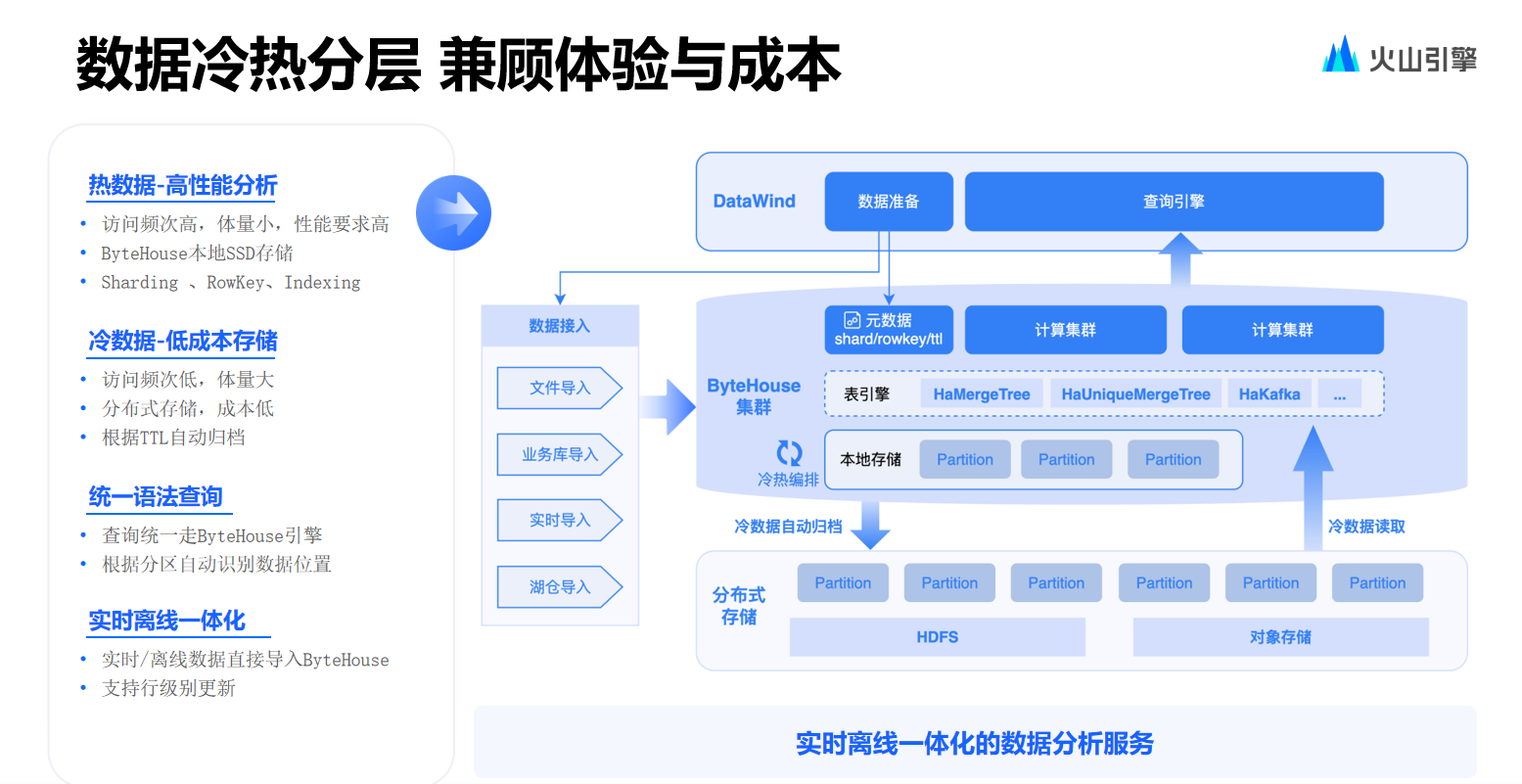
針對(duì)這個(gè)問題,解決的思路是提供數(shù)據(jù)冷熱分層,對(duì)于最為常用的數(shù)據(jù),例如最近 7 天或 14 天的數(shù)據(jù),可以放置于 ByteHouse 中進(jìn)行存儲(chǔ)。而相對(duì)距離當(dāng)前時(shí)間較遠(yuǎn)的數(shù)據(jù),則放置在存算分離的 ByteHouse 集群當(dāng)中,通過更為廉價(jià)的方式來實(shí)現(xiàn)查詢。至于時(shí)間更為久遠(yuǎn)的數(shù)據(jù),比如過去一年的數(shù)據(jù),就存于 Hive 表內(nèi),可以通過 Python 或者 Spark 的方式來進(jìn)行查詢。
而之所以保留對(duì)以 Sparck 方式進(jìn)行兜底查詢這一方式的支持,是由于 MPP 相關(guān)數(shù)據(jù)庫在兜底能力方面普遍存在硬傷。故而采用 Spark 方式來兜底,如此一來,至少能夠確保用戶在極為極端的情況下仍然能查詢到數(shù)據(jù)結(jié)果。
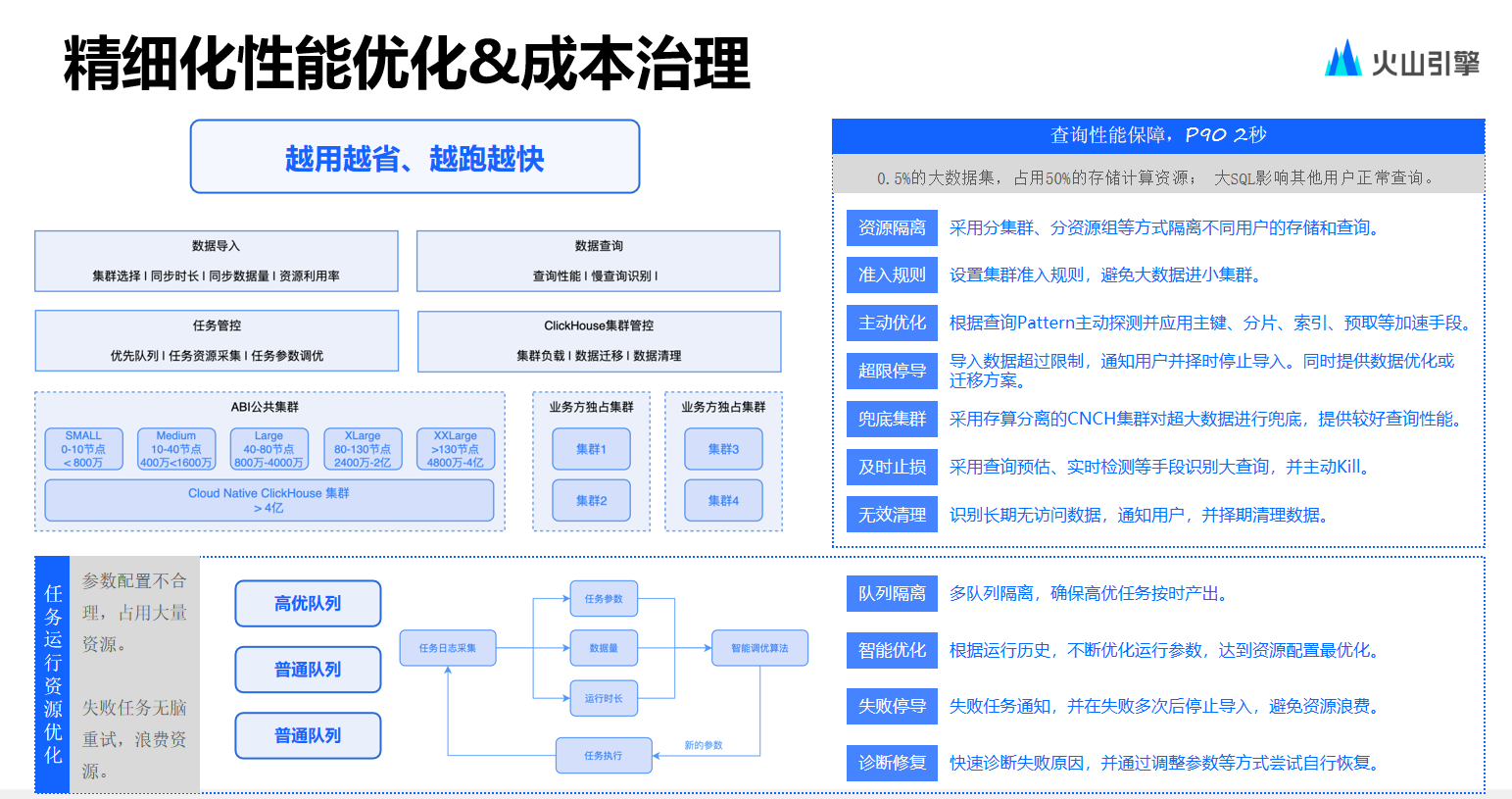
除此之外,性能優(yōu)化與成本治理也是值得研究的問題。對(duì)此開發(fā)中所采用的是一種較為偏向“人民戰(zhàn)爭(zhēng)”的方式。鑒于僅依賴平臺(tái)運(yùn)維團(tuán)隊(duì)來監(jiān)控所有性能指標(biāo)及具體數(shù)據(jù)庫表,難以滿足集團(tuán)公司龐大的業(yè)務(wù)需求,團(tuán)隊(duì)選擇將這種監(jiān)控與優(yōu)化的能力內(nèi)嵌于產(chǎn)品體系中。
從而讓每個(gè)業(yè)務(wù)線的負(fù)責(zé)人,乃至每個(gè)項(xiàng)目管理者,都能直觀地了解到哪些數(shù)據(jù)集消耗資源較多、哪些數(shù)據(jù)集的成本效益比較低——即投入大額資金但查詢頻率并不高的情況。該策略還可協(xié)助他們識(shí)別出哪些部分可通過構(gòu)建多級(jí)聚合來提升性能,以及在確保性能不受影響的前提下,如何實(shí)施成本控制措施以實(shí)現(xiàn)更高效的資源配置。
通過這種方式,不僅能夠分散管理和優(yōu)化的壓力,還能促進(jìn)全員對(duì)資源效率的關(guān)注與參與,確保了整個(gè)集團(tuán)在規(guī)模擴(kuò)張的同時(shí)保持成本效益與服務(wù)性能的最優(yōu)化。
BI + AI 實(shí)現(xiàn)智能數(shù)據(jù)洞察
抖音集團(tuán)內(nèi)部在 BI 平臺(tái)建設(shè)階段,對(duì)智能部分投入較多。
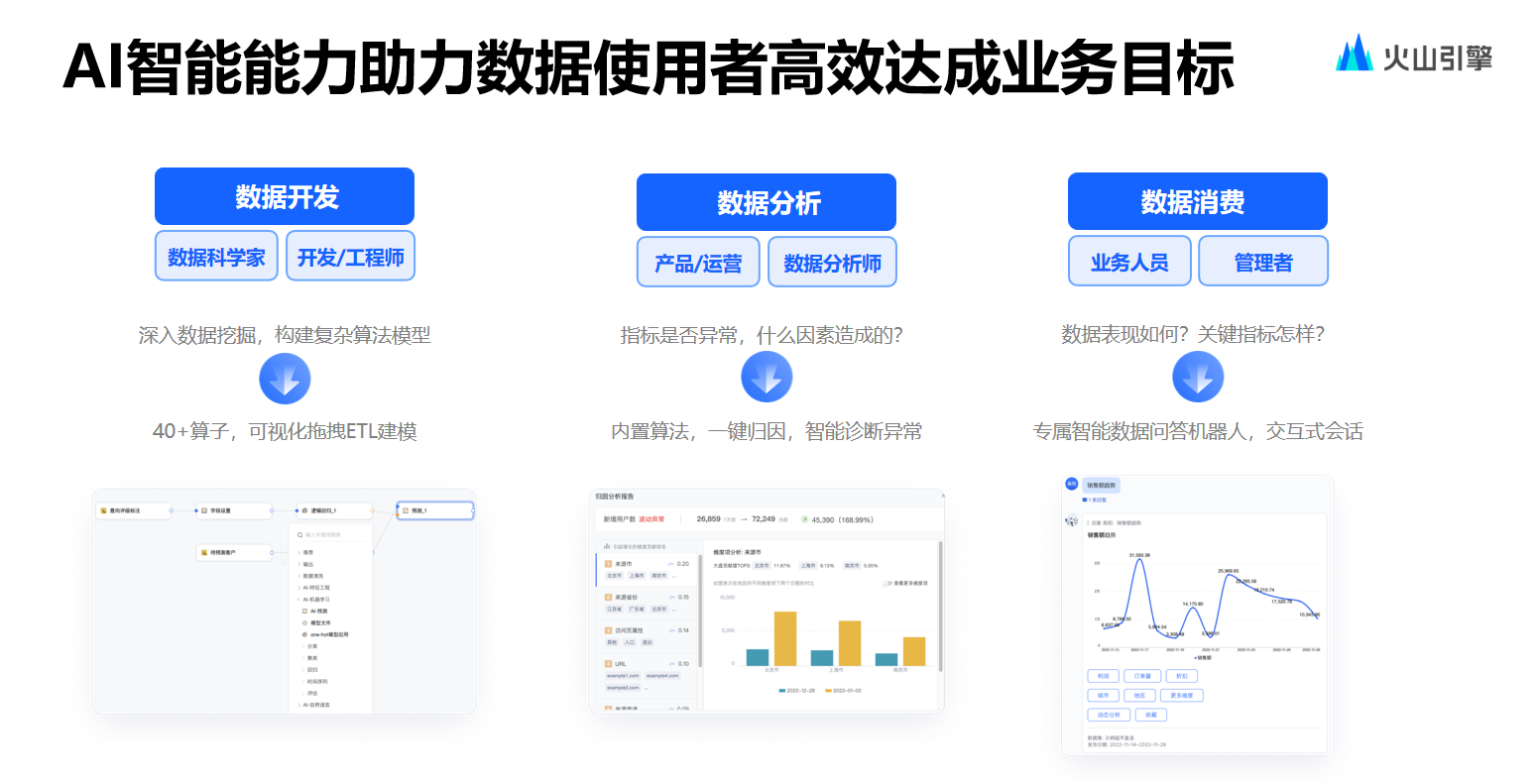
而對(duì)智能部分的分享可以大致分為三個(gè)部分。
其一為數(shù)據(jù)開發(fā),旨在幫助進(jìn)行數(shù)據(jù)準(zhǔn)備的人員能夠準(zhǔn)備更具價(jià)值的數(shù)據(jù);其二是數(shù)據(jù)分析,期望能夠助力用戶進(jìn)行異常指標(biāo)查詢以及異常歸因;其三為數(shù)據(jù)消費(fèi),通過對(duì)話式問答的方式來提升提取信息的效率。
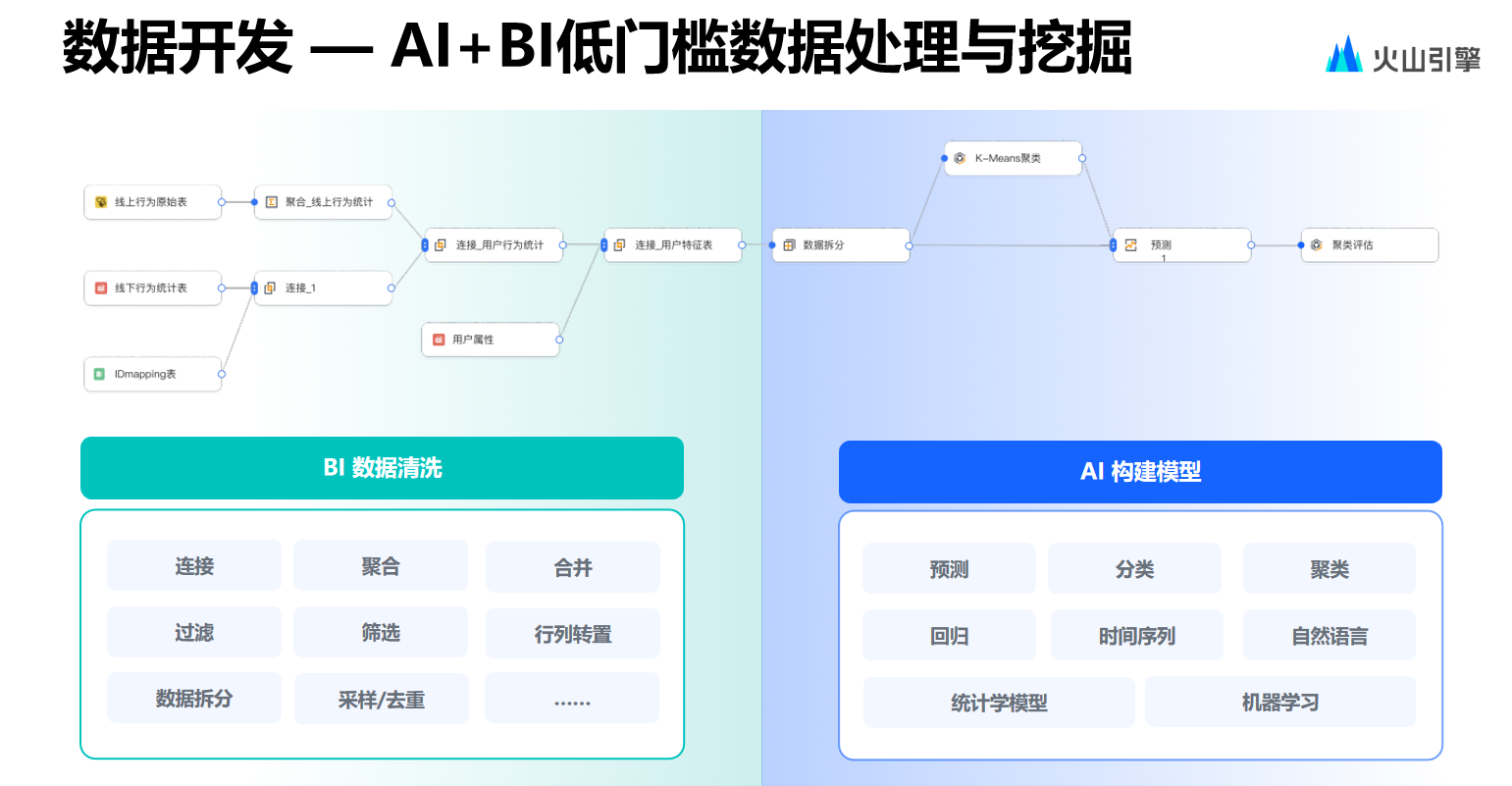
數(shù)據(jù)開發(fā)的場(chǎng)景相對(duì)簡(jiǎn)單,團(tuán)隊(duì)的工作主要是集成多種 AI 算子至低代碼可視化建模工具中,其中運(yùn)用較多的是預(yù)測(cè)能力。而使用預(yù)測(cè)的場(chǎng)景也非常容易理解。
假設(shè)用戶有一張表,其中某一列可能表示幾天后的數(shù)據(jù),若此時(shí)用戶已知道其他列的信息和歷史數(shù)據(jù),便會(huì)希望通過機(jī)器學(xué)習(xí)的方式預(yù)測(cè)出該列的新值。從目前來看,此類需求較多。從算子角度來講,產(chǎn)品母線已集成約 40 多種算子,其中特征工程算子與預(yù)測(cè)算子是被頻繁使用的兩類。
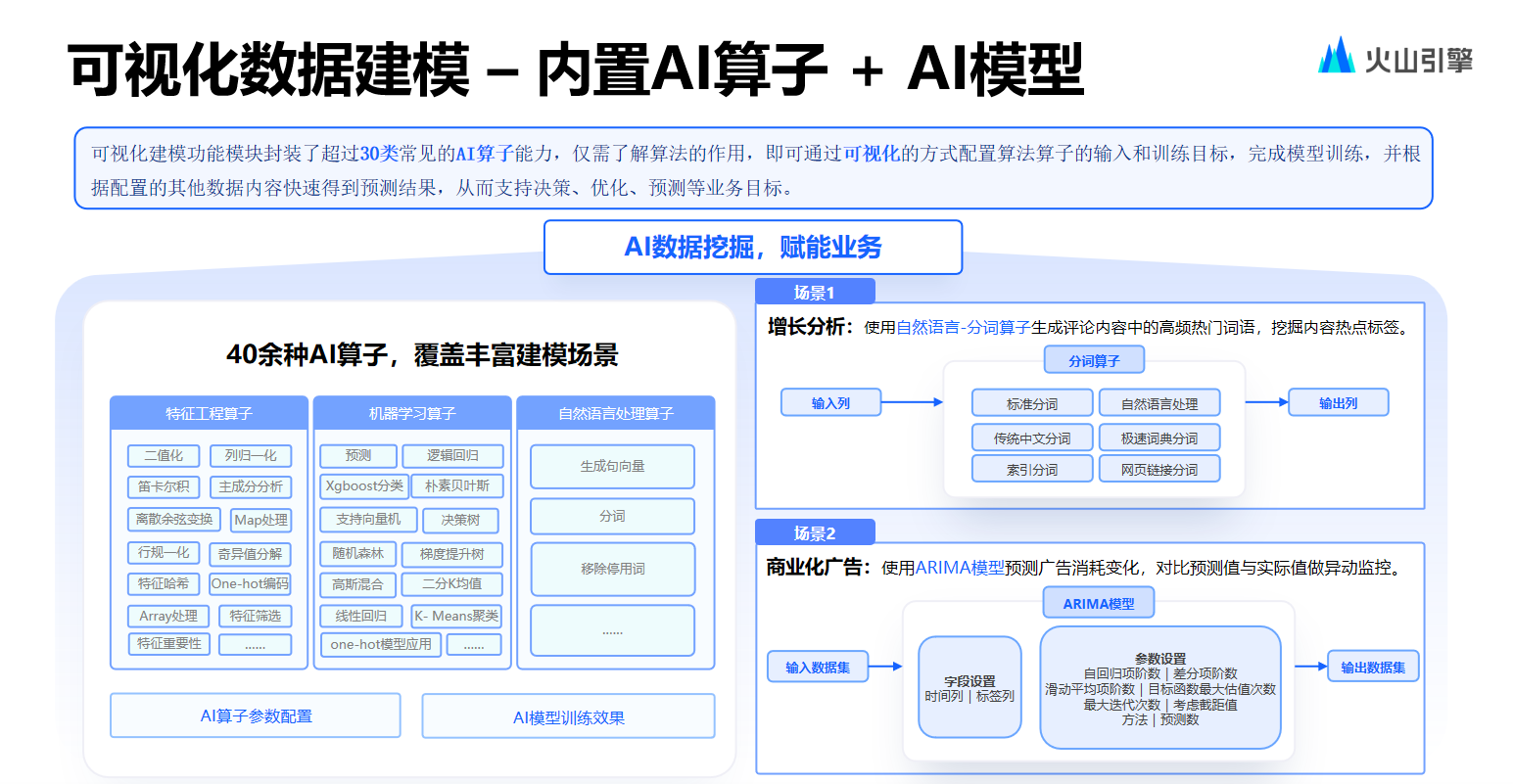
接著是數(shù)據(jù)分析場(chǎng)景。在數(shù)據(jù)分析場(chǎng)景中,開發(fā)團(tuán)隊(duì)希望能夠幫助用戶更快捷地進(jìn)行異常指標(biāo)查詢以及異常歸因,不想再為用戶配置例如當(dāng)數(shù)據(jù)指標(biāo)低于 10%或 5%再發(fā)送警告此類傻瓜式警告方式。
團(tuán)隊(duì)想要開發(fā)一個(gè)更為靈活、能夠反映指標(biāo)季節(jié)性的預(yù)警系統(tǒng),因此在開發(fā)中采用了 STO 算法,同時(shí)結(jié)合指標(biāo)平滑技術(shù),利用殘差結(jié)合歷史數(shù)據(jù)計(jì)算出指標(biāo)的波動(dòng)范圍,當(dāng)超出這一波動(dòng)范圍時(shí),就會(huì)進(jìn)行告警。
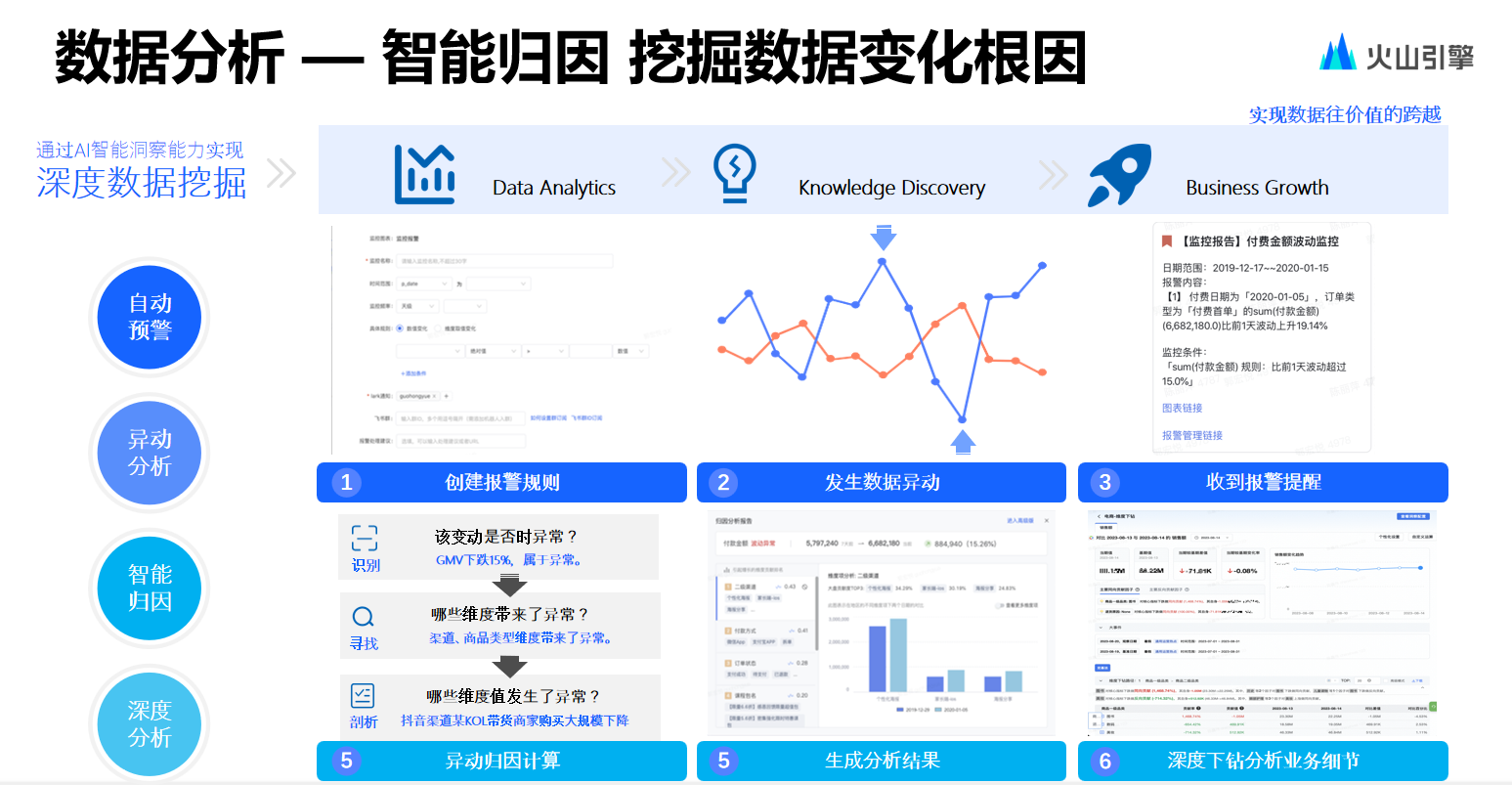
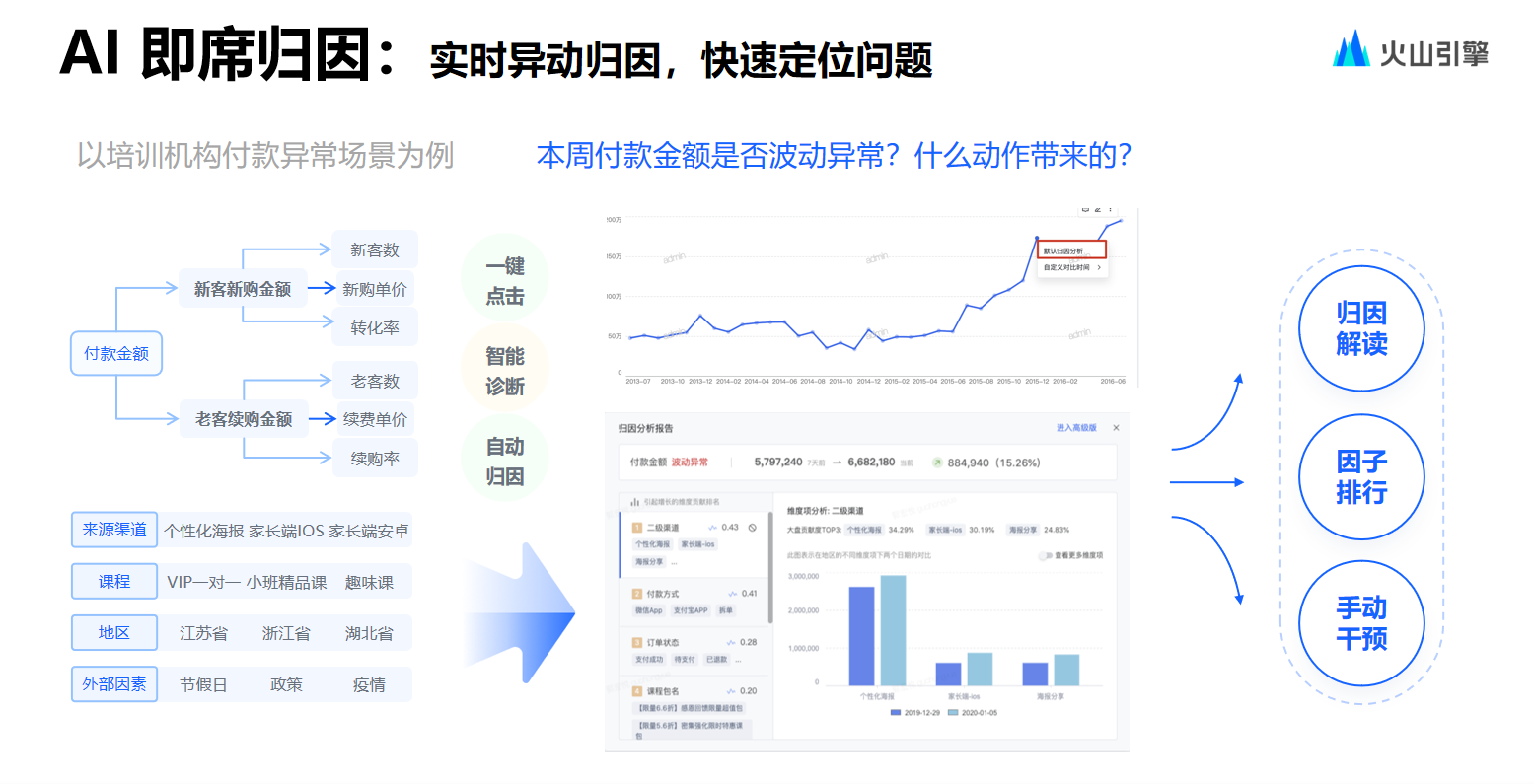
從產(chǎn)品形態(tài)方面分析,歸因可以分為以下幾類。
從產(chǎn)品形態(tài)上即時(shí)歸因較易理解,即用戶在發(fā)現(xiàn)異常時(shí)只需點(diǎn)擊一下,系統(tǒng)便會(huì)進(jìn)行歸因。就維度選擇而言,開發(fā)團(tuán)隊(duì)參照了一種基于基尼系數(shù)的維度選擇方式,基尼系數(shù)常被聯(lián)合國(guó)用于貧富差異比較,將其理解成維度后,可把每個(gè)維度視為一個(gè)國(guó)家,若某個(gè)維度中維值對(duì)某一指標(biāo)的貢獻(xiàn)較為平均且無明顯差異性,則認(rèn)為該維度可能并非主要原因。
在確定維度后會(huì)通過一系列方法計(jì)算維值的貢獻(xiàn)率。即時(shí)歸因?qū)磿r(shí)性要求較高,其可以在短時(shí)間,比如 15 秒鐘左右,返回查詢結(jié)果,但即時(shí)歸因能分析的事情相對(duì)較少,它不會(huì)進(jìn)行相關(guān)指標(biāo)分析,僅會(huì)做維度分析,也不會(huì)做過多維度組合相關(guān)分析,總體功能較為簡(jiǎn)單。

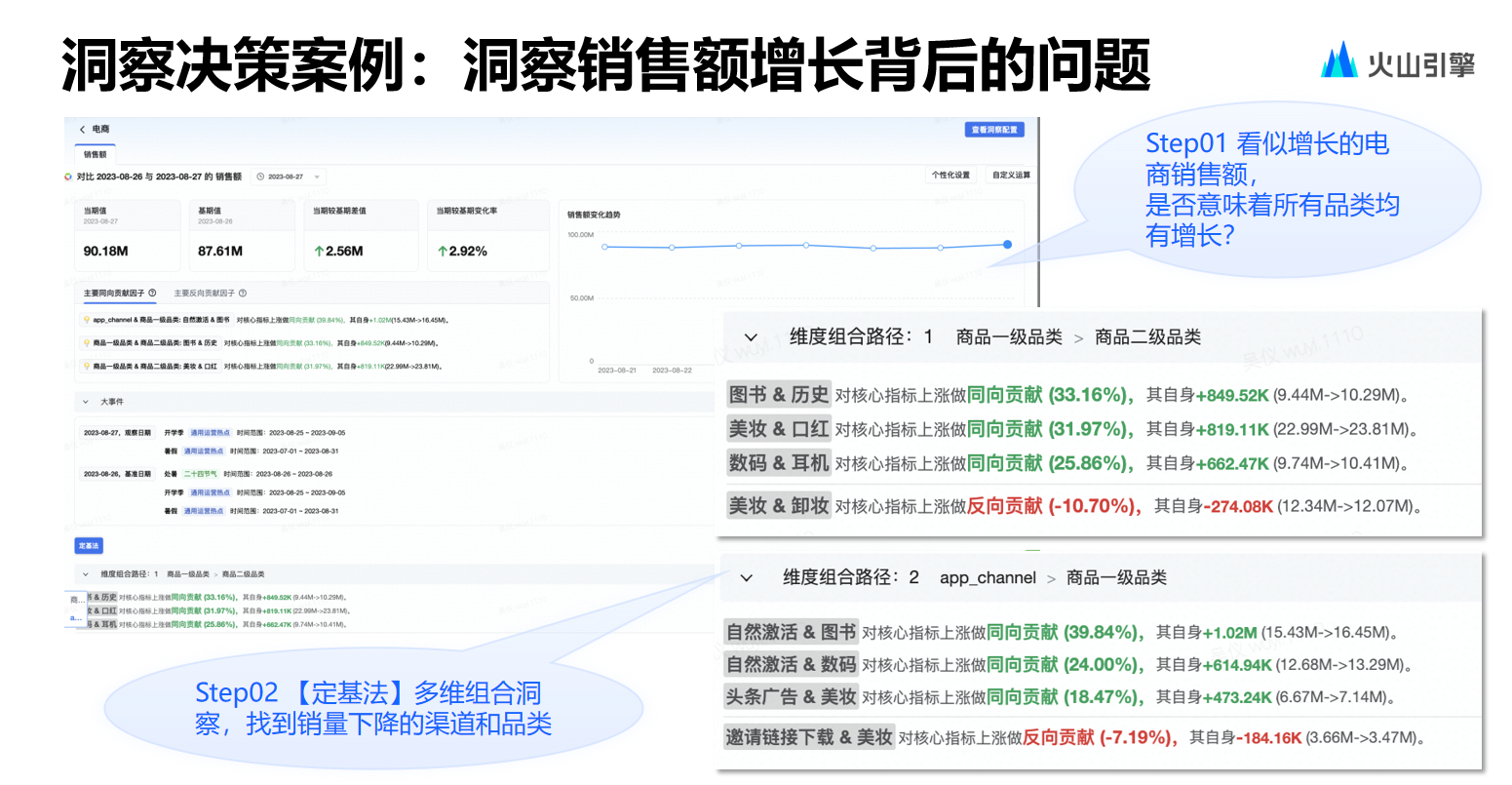
而另一種歸因——洞察報(bào)告的功能則相對(duì)豐富,洞察報(bào)告通過異步通知模式可以處理相對(duì)復(fù)雜的需求,能夠分析不同指標(biāo)和進(jìn)行多種維度組合。
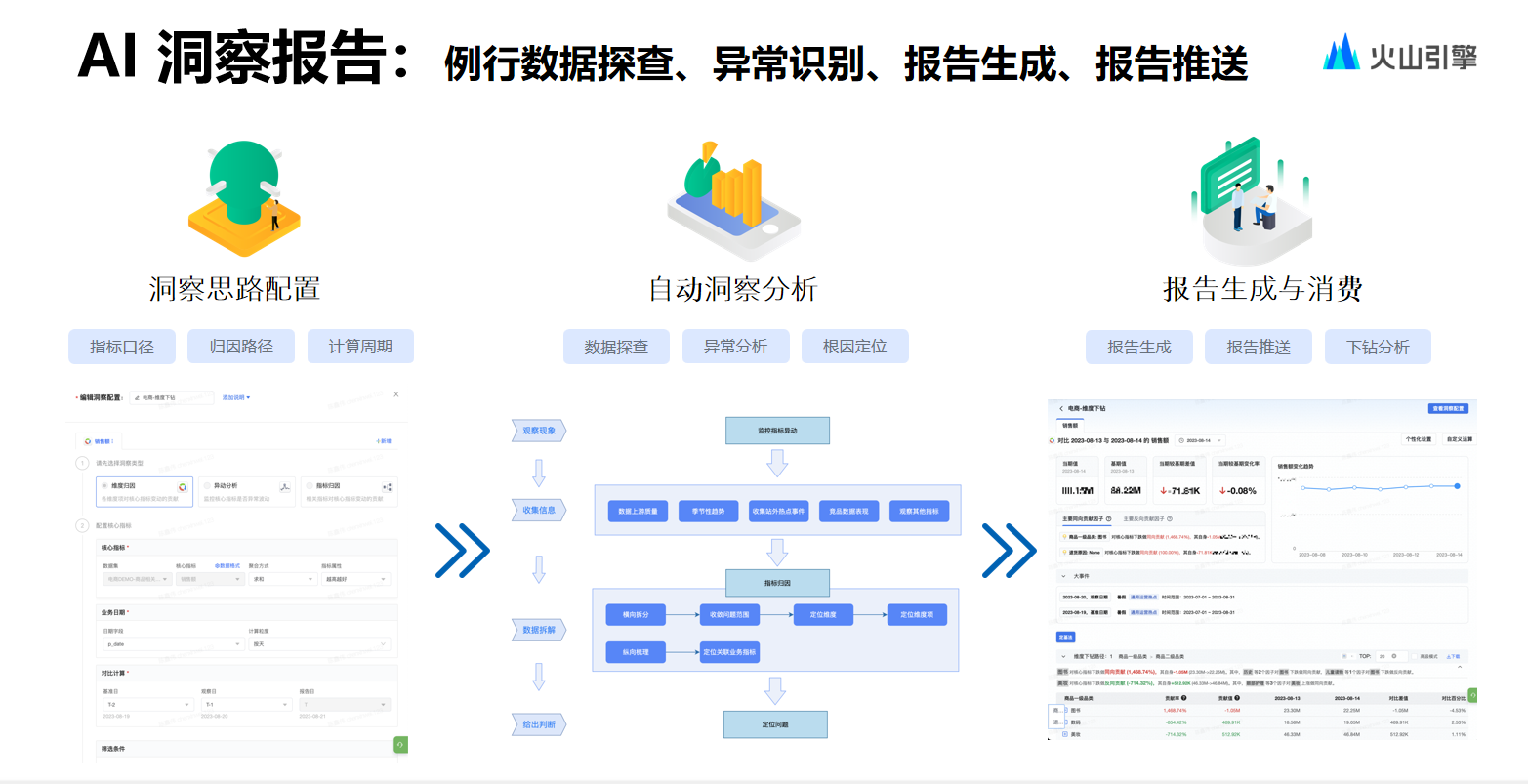
用戶歸因前進(jìn)行配置,比如選擇指標(biāo)歸因或維度歸因,選擇大致組合后便可生成洞察報(bào)告,洞察報(bào)告既可以在系統(tǒng)上查看,也可以推送給相應(yīng)的 IM。
此外,還有一種在內(nèi)部使用較多的歸因——指標(biāo)分析樹。
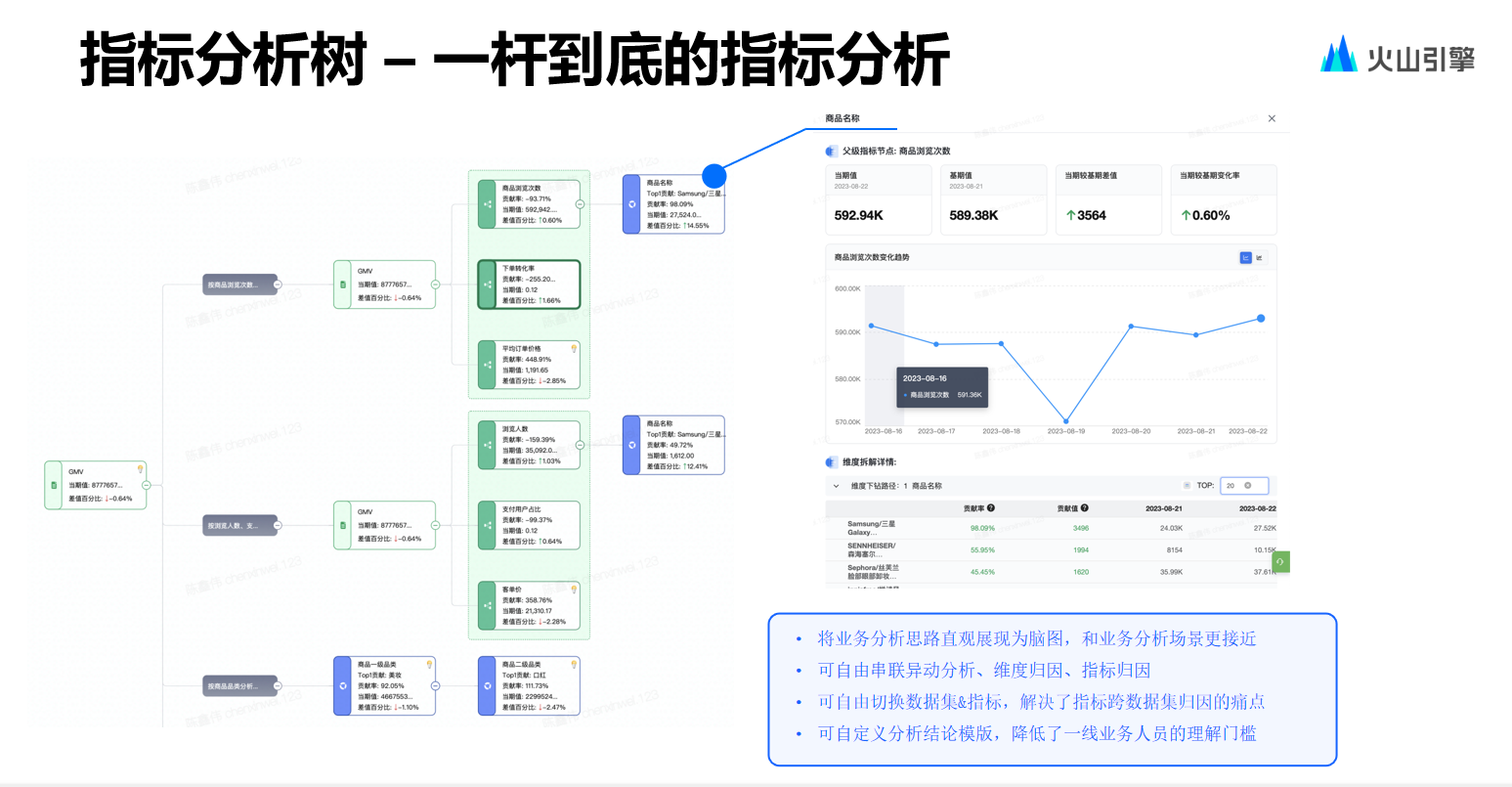
在集團(tuán)內(nèi)部,大家在進(jìn)行 OKR 對(duì)齊時(shí),指標(biāo)往往會(huì)形成類似指標(biāo)體系的東西,即:上級(jí)重視 GMV 等指標(biāo),而下級(jí)更關(guān)注 PV 等指標(biāo),這種差異便會(huì)形成樹狀指標(biāo)結(jié)構(gòu)。如果對(duì)于指標(biāo)存在疑問,就會(huì)進(jìn)行固化的基于維度的分析,其總體思路是將指標(biāo)分析過程進(jìn)行固化,確保在查看 OKR 或指標(biāo)時(shí),能夠清楚知道出現(xiàn)異常的板塊、維度和節(jié)點(diǎn)。
歸因功能從實(shí)現(xiàn)角度而言整體相對(duì)簡(jiǎn)單,難點(diǎn)主要在于產(chǎn)品設(shè)計(jì)與算法相關(guān)處理,而其在工程角度也是較為簡(jiǎn)單的問題。此外,異步的洞察報(bào)告和指標(biāo)分析數(shù)調(diào)度在實(shí)現(xiàn)時(shí),要盡量避免對(duì)在線查詢產(chǎn)生影響,要盡量減少占用在線查詢資源。
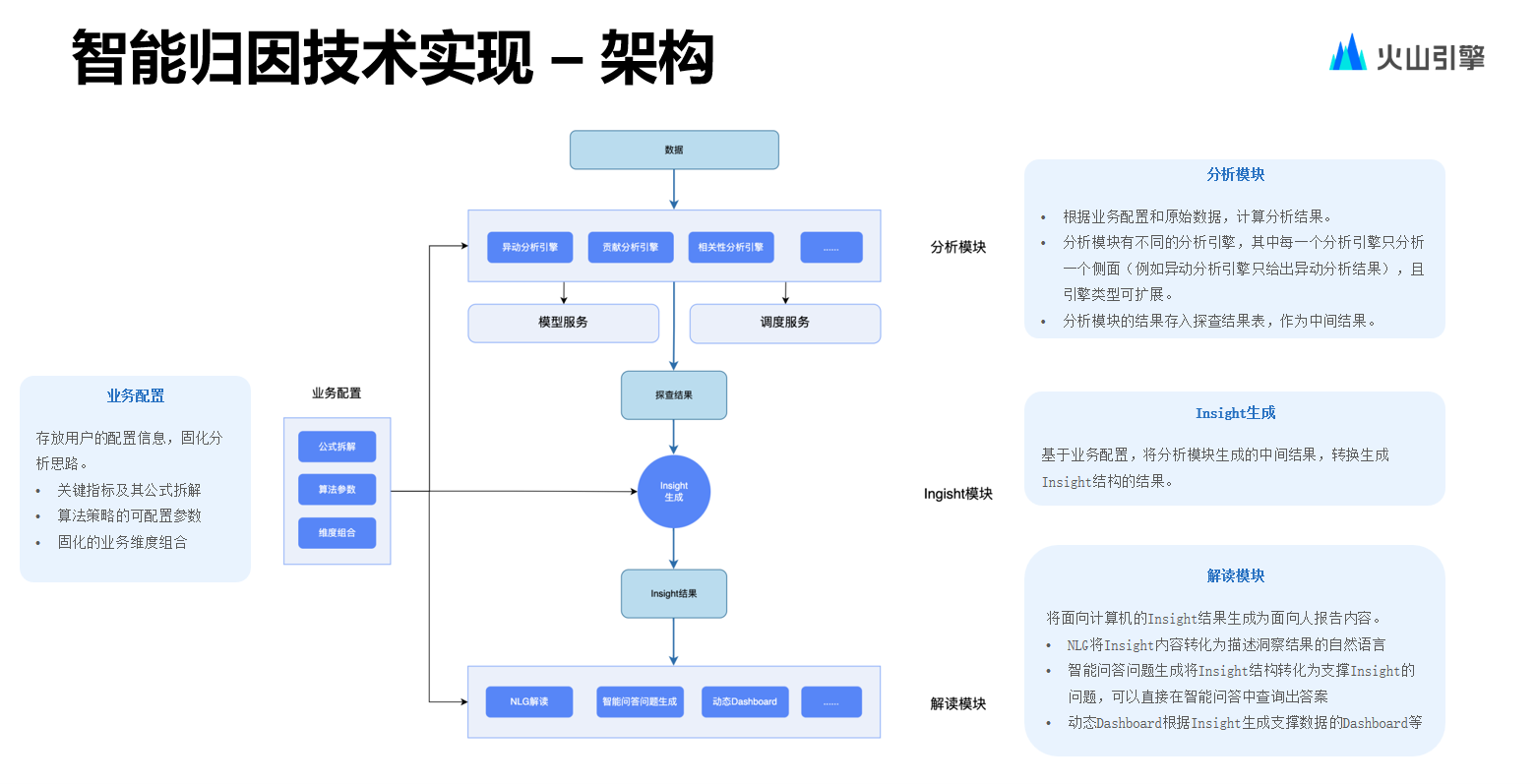
在積極開展指標(biāo)歸因相關(guān)工作時(shí),大模型出現(xiàn)了。隨后,團(tuán)隊(duì)投入了大量的時(shí)間去探索與大模型相關(guān)的能力,同時(shí)也耗費(fèi)了較多的資源。從結(jié)果方面來看,目前集團(tuán)內(nèi)部已有大幾千人成為 ABI 的 Copilot 常用用戶,因此整體而言取得了不錯(cuò)的成果。

從探索角度而言,團(tuán)隊(duì)開發(fā)了多樣化的場(chǎng)景,但落地結(jié)果有部分相對(duì)成功,也有部分相對(duì)失敗。
如今回顧那些不太成功的場(chǎng)景,都存在一個(gè)共性,即所生成內(nèi)容的質(zhì)量并非很高。也就是說,相對(duì)而言或許產(chǎn)品交互方面它們還有很大的改進(jìn)空間,但在內(nèi)容質(zhì)量方面的調(diào)優(yōu)往往較為困難。
例如,用戶期望大模型能幫助進(jìn)行歸因,告知數(shù)據(jù)為何不對(duì)或者接下來應(yīng)朝哪個(gè)方向去查看。
關(guān)于這方面的能力,團(tuán)隊(duì)最初將其上線的原因在于其表現(xiàn)實(shí)際上超出了預(yù)期。從開發(fā)者角度來看,特別容易以較低的預(yù)期來看待大模型相關(guān)事宜,覺得它能做到與自己一樣的事情就感覺它似乎表現(xiàn)得已經(jīng)不錯(cuò)了,但實(shí)際上從用戶解決問題的角度來看,往往生成的內(nèi)容質(zhì)量沒有那么高。所以在這一點(diǎn)上特別容易讓團(tuán)隊(duì)產(chǎn)生較為樂觀的預(yù)期,而這往往會(huì)導(dǎo)致落地效果或落地姿態(tài)不夠理想。
目前取得成功的案例存在一些共性特點(diǎn)。首先,如果功能是為了解決諸如用戶在解決問題過程中本身就需要去搜索資料的問題,與 ChatGPT 相結(jié)合往往能獲得較好的解決方式。
在代碼開發(fā)場(chǎng)景方面,團(tuán)隊(duì)產(chǎn)品功能內(nèi)部落地情況較好,包括此前列舉的 SQL 查詢,圍繞 ABI 所支持的高階 Notebook 做法。這些功能能夠取代用戶在網(wǎng)上搜索查看大量 Stack overflow 帖子,之后提煉代碼編輯思路的場(chǎng)景,而在大模型加持的代碼編輯器中,DataWind 提供了如解釋 SQL、優(yōu)化 SQL、生成注釋以及報(bào)錯(cuò)修復(fù)等一系列功能。
又或者說數(shù)據(jù)準(zhǔn)備的第一步:源數(shù)據(jù)的錄入。起初在錄入指標(biāo)時(shí),往往需要進(jìn)行諸多翻譯工作為指標(biāo)命名。
若是處于多語言環(huán)境,還需配置該指標(biāo)的外語名稱。對(duì)于這類問題,以往解決時(shí)通常需要查閱公開資料,查詢相關(guān)單詞的英文寫法等。而這部分的工作,大模型能夠有較為出色的表現(xiàn),能夠極大地節(jié)省用戶精力。
而在儀表盤的探索分析及解讀中,大模型能發(fā)揮的最大作用在于幫助用戶展開潤(rùn)色工作,因?yàn)橛脩艨赡苄枰杆俚貙?shù)據(jù)結(jié)果發(fā)送給上級(jí),而自己書寫解讀內(nèi)容可能會(huì)相對(duì)困難。在這一場(chǎng)景中,DataWind 除了對(duì)某一圖表進(jìn)行數(shù)據(jù)解釋外,還會(huì)推薦一些 follow up 問題,而這些 follow up 問題實(shí)則完全由 GPT 所推薦。
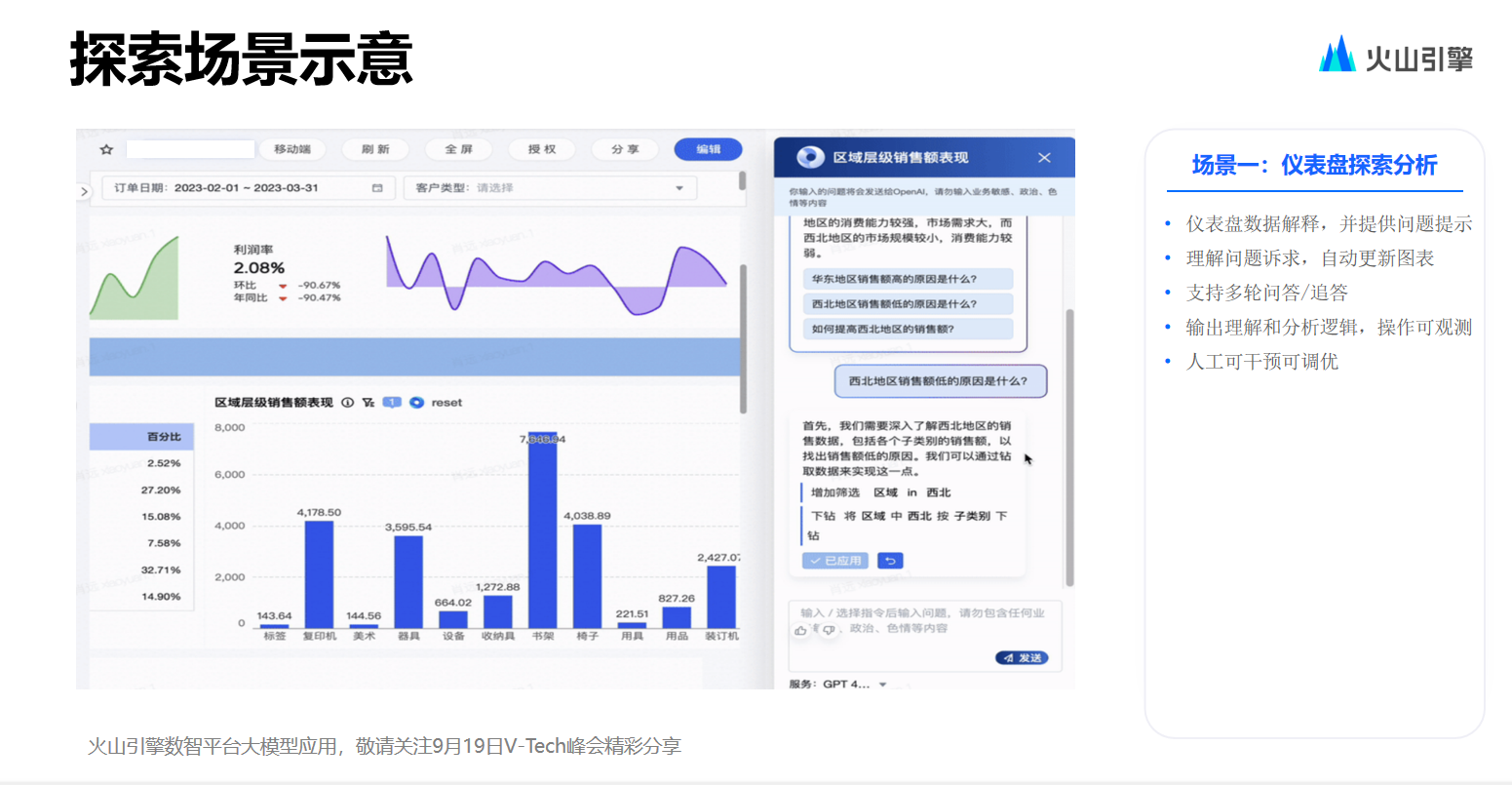
當(dāng)用戶點(diǎn)擊一個(gè)問題時(shí),它亦會(huì)描述接下來要進(jìn)行的操作,這也變相回應(yīng)了另一個(gè)問題,即如何讓用戶知曉模型后續(xù)的行為。因?yàn)槟壳爸陵P(guān)重要的一點(diǎn)是,以大模型在現(xiàn)階段的能力,其回答是無法做到百分百準(zhǔn)確的。
而在嚴(yán)肅場(chǎng)合,需要的是一個(gè)非常精準(zhǔn)的數(shù)字,用戶會(huì)非常想要了解其統(tǒng)計(jì)口徑是什么,它又是如何得出這個(gè)結(jié)論的。因此在落地場(chǎng)景中,一個(gè)極為重要的原則是必須讓用戶清楚大模型到底做了什么,或者說大模型做了哪些部分,以及接下來將如何處理這個(gè)請(qǐng)求,這個(gè)數(shù)據(jù)究竟是如何得來的,這一點(diǎn)十分關(guān)鍵,否則,即便模型準(zhǔn)確率能夠達(dá)到 95%以上,其在數(shù)據(jù)產(chǎn)品中的落地也較為困難。
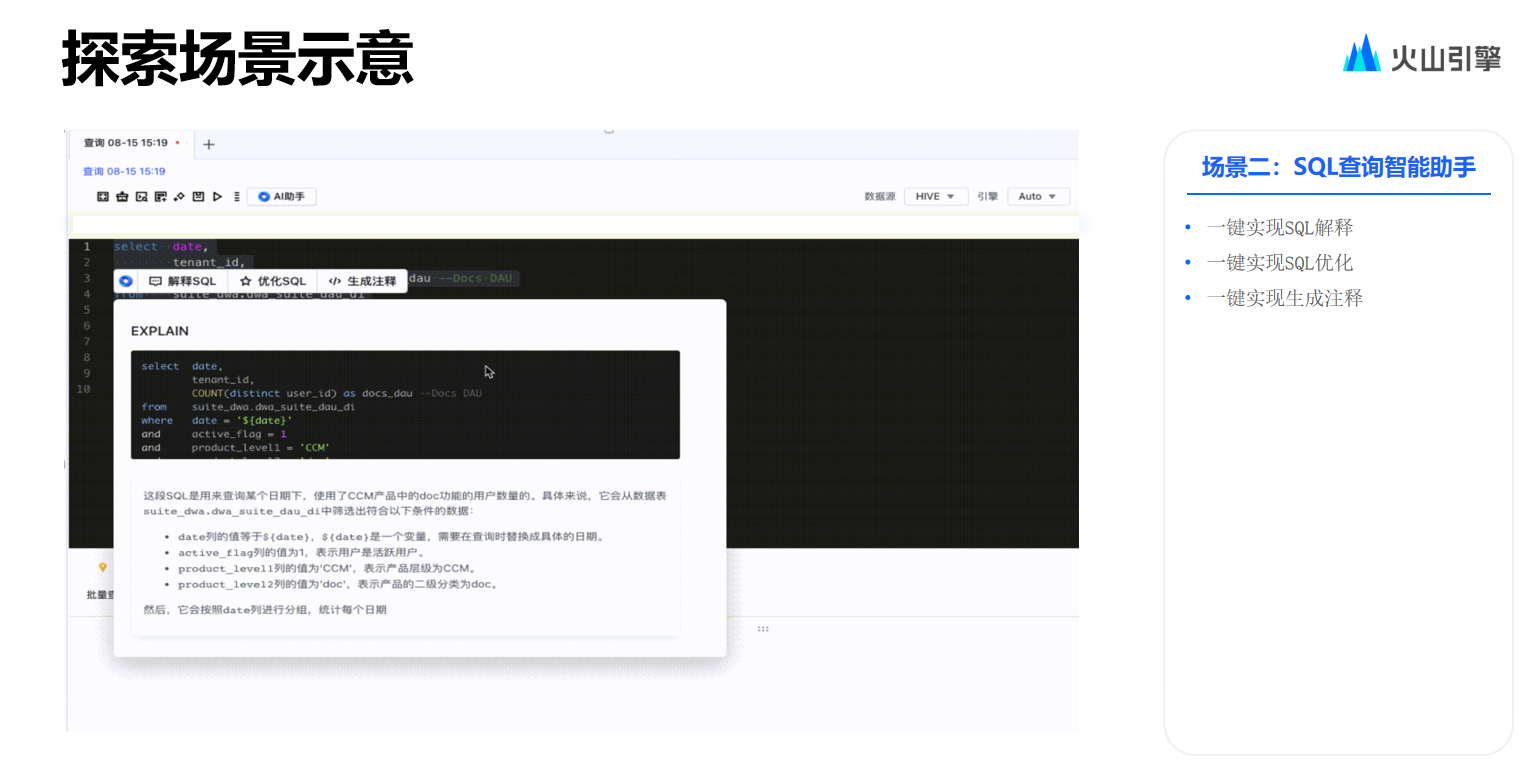
接著再來看一下 SQL 查詢的場(chǎng)景,本產(chǎn)品能夠進(jìn)行解釋以及優(yōu)化。在 editor 中可以運(yùn)用自然語言來幫助生成相應(yīng)的 SQL 以及與 notebook 相關(guān)的一些代碼。
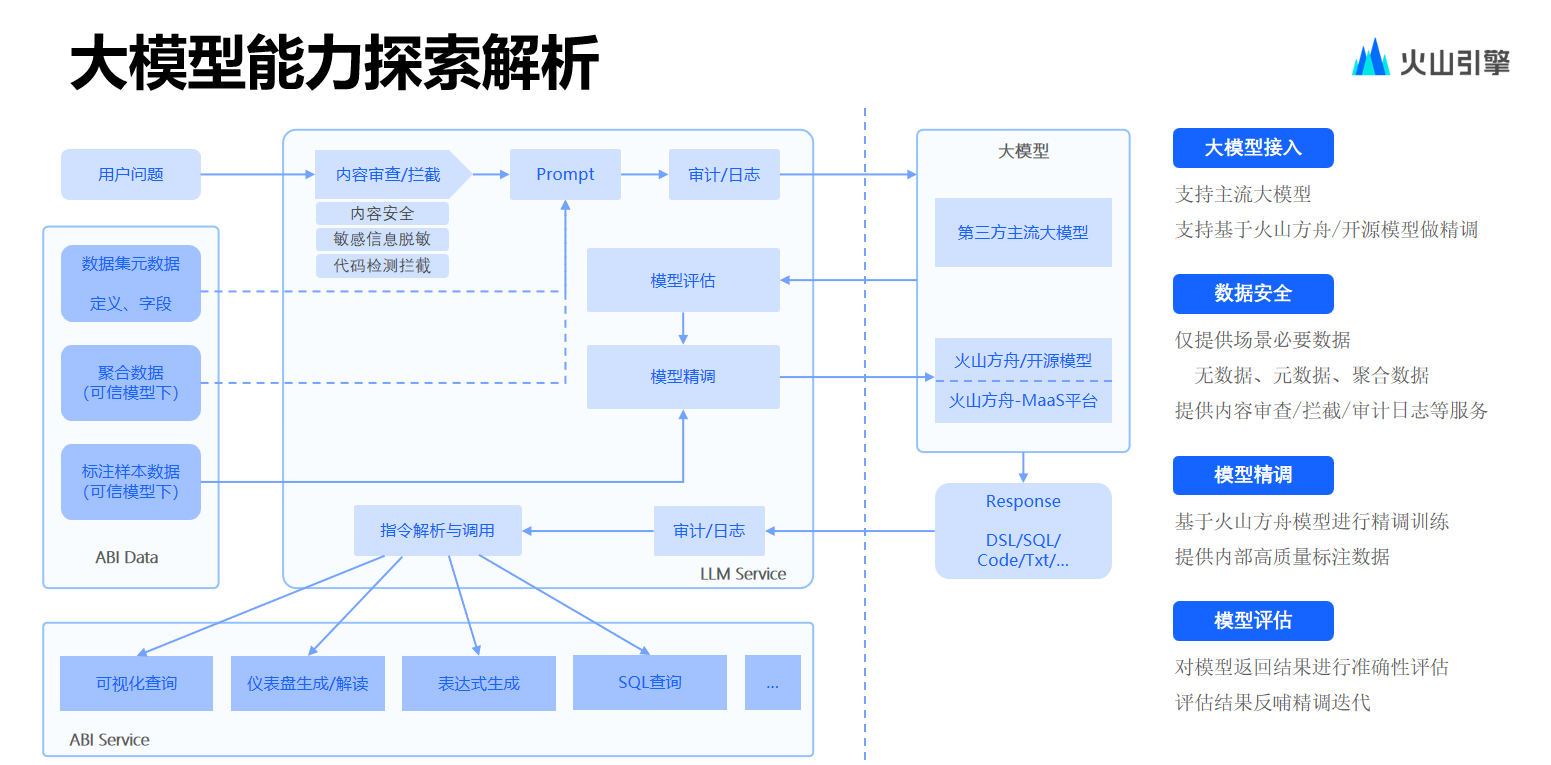
從實(shí)現(xiàn)角度而言。第一點(diǎn)便是合規(guī)與內(nèi)容審核問題。抖音集團(tuán)內(nèi)部實(shí)踐最初采用了 GPT 模型,進(jìn)行了多種嘗試,包括 GPT 3 的 tuning 等,對(duì)比后選擇了 GPT 4,同時(shí)也在努力對(duì)接公司自研大模型,因此在內(nèi)容審核方面較為吃力,例如:若認(rèn)為 table 的 schema 不那么敏感,而 table 的數(shù)據(jù)敏感,那么那些維值應(yīng)如何處理?是否需要進(jìn)行向量化匹配?這會(huì)涉及到一系列的技術(shù)和工程問題。
再如精調(diào)問題,究竟是否要采用模型精調(diào)以及何時(shí)采用?即便到目前內(nèi)部也未完全放棄模型精調(diào)這一路線,開發(fā)團(tuán)隊(duì)對(duì)于精調(diào)一事的理解更多是以空間換取時(shí)間,因?yàn)橛袝r(shí)團(tuán)隊(duì)會(huì)發(fā)現(xiàn)當(dāng)用戶將私域問題描述得極為詳盡時(shí)提示語過長(zhǎng),過長(zhǎng)的提示語一方面可能無法輸入,另一方面也可能影響整體使用效率。此時(shí)要通過部分精調(diào)的方式來減少需要提供的 prompt 數(shù)量。
總結(jié)與展望
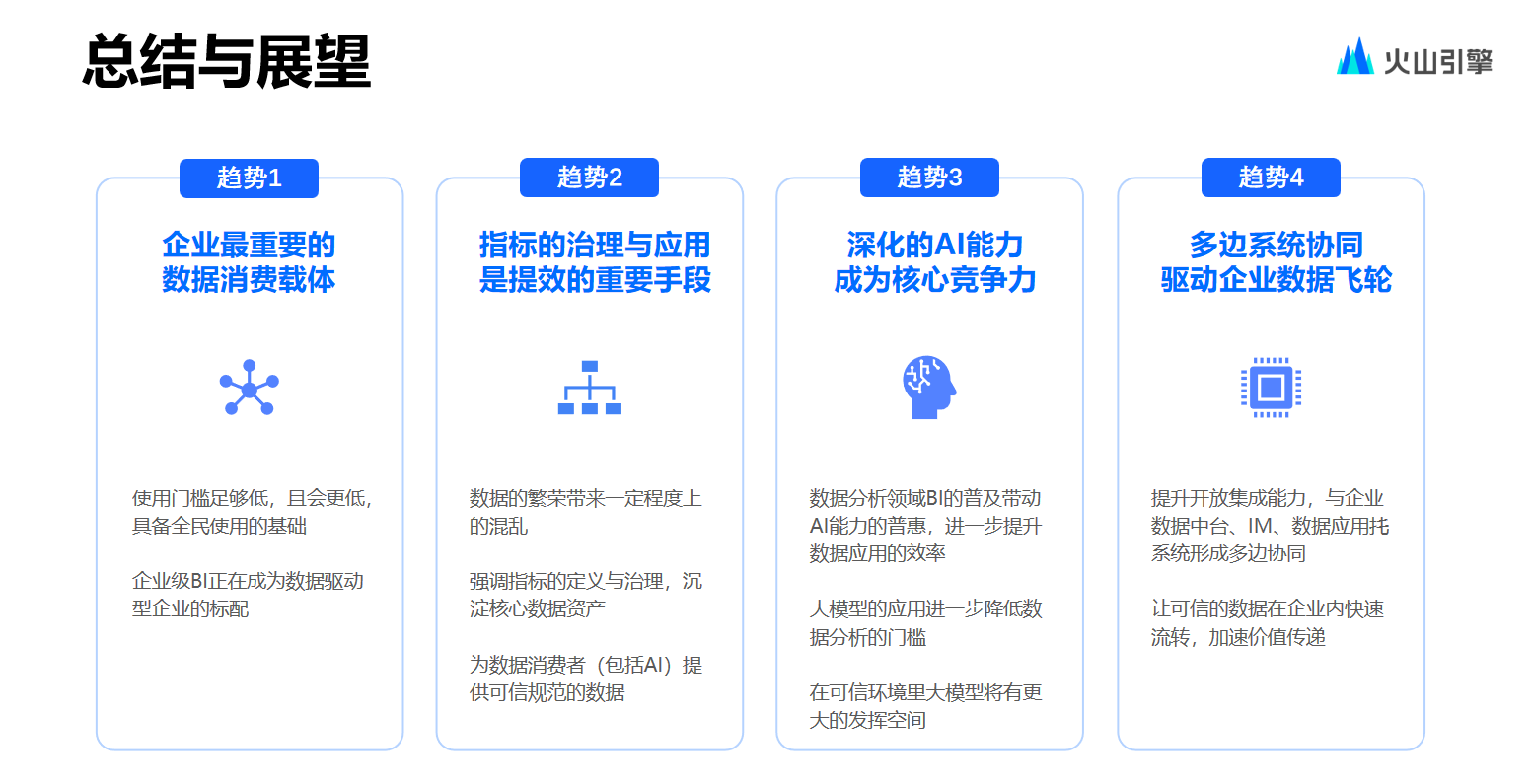
簡(jiǎn)單總結(jié)幾個(gè)未來展望的要點(diǎn):
一,企業(yè)級(jí) BI 正逐漸成為新趨勢(shì),曾經(jīng)的普遍情況是諸多業(yè)務(wù)部門各自購買 BI,而全公司或全員使用的 BI 在當(dāng)時(shí)并不重要,但如今其重要性愈發(fā)凸顯。
二,指標(biāo)治理以及 AI 能力也是至關(guān)重要的部分。
三,團(tuán)隊(duì)認(rèn)為數(shù)據(jù)消費(fèi)能夠推動(dòng)數(shù)據(jù)建設(shè),總體建設(shè)思路是將上層的數(shù)據(jù)消費(fèi)打造得極為繁榮,在相對(duì)繁榮之后,會(huì)持續(xù)向下層的數(shù)據(jù)建設(shè),如 ETL 部分、數(shù)倉部分以及數(shù)據(jù)湖部分提出新的訴求,從而帶動(dòng)下層基礎(chǔ)設(shè)施的建設(shè)。
點(diǎn)擊 火山引擎DataWind 了解更多

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)