
OLAP進階之“性能提升”
更多技術交流、求職機會,歡迎關注字節跳動數據平臺微信公眾號,回復【1】進入官方交流群
在數據處理和分析的領域,提升查詢效率始終是一項關鍵挑戰。對于 OLAP 來說,性能的關鍵需求在于能支持實時分析,應對復雜查詢,提供快速響應,并具備良好的可擴展性。這些方面,對于滿足高效、準確的數據分析需求至關重要。
火山引擎正式發布《云原生數據倉庫ByteHouse性能白皮書》,白皮書通過使用 SSB 100G、TPC-H 100G、TPC-DS 100G 數據集進行性能測試,展示出 ByteHouse 在查詢效率方面的顯著成果,并詳細介紹ByteHouse在實時數倉、復雜查詢等八大應用場景的高性能應用表現。
作為一款OLAP引擎,伴隨字節跳動各業務的發展,ByteHouse已經過數百個應用場景和數萬用戶錘煉,在2022年3月,部署規模已超過1萬8000臺,最大的集群規模在 2400 余個節點,管理總數據量超過700PB,并逐步在外部金融、泛互等場景應用和推廣。為了更好支持字節內外部大規模數據和復雜場景應用,性能一直以來是ByteHouse重點打磨的產品基本功。
SSB、TPC-H 和 TPC-DS 是常用于測試分析型數據庫/數據倉庫的數據集。在白皮書中,通過使用以上三種數據集進行性能測試,并以性能著稱的某開源OLAP為基準測試產品,ByteHouse在不同查詢項上都有顯著的性能提升。以TPC-H 數據集舉例,在相同硬件和軟件環境下, ByteHouse 查詢效率高于本次基準測試產品幾十倍。
背景
ByteHouse是字節跳動數據平臺自主研發的云原生數據倉庫產品,在開源ClickHouse引擎之上做了技術架構重構,實現了云原生環境的部署和運維管理、存儲計算分離、多租戶管理等功能,已通過火山引擎對外提供服務。在可擴展性、穩定性、可運維性、性能以及資源利用率方面,ByteHouse都有巨大的提升。
ByteHouse以提供高性能、高資源利用率、高穩定性、低運維成本為目標,進行了優化設計和工程實現,產品特性和優勢如下:
- 存儲計算分離:解決了全局元數據管理,過多小文件存儲性能差等等技術難題。在最小化性能損耗的情況下,實現存儲層與計算層的分離,獨立擴縮容。
- 新一代 MPP 架構:結合 Shared-nothing 的計算層以及 Shared-everything 的存儲層,有效避免了傳統 MPP 架構中的 Re-sharding 問題,同時保留了MPP并行處理能力。
- 數據一致性與事務支持。
- 計算資源隔離,讀寫分離:通過計算組(VW)概念,對宿主機硬件資源進行靈活切割分配,按需擴縮容。資源有效隔離,讀寫分開資源管理,任務之間互不影響,杜絕了大查詢打滿所有資源拖垮集群的現象。
- ANSI-SQL:SQL兼容性全面提升,支持ANSI-SQL 2011標準,TPC-DS測試集100%通過率。
- UDF:支持Python UDF/UDAF創建與管理,補足函數的可擴展性。(Java UDF/UDAF已在開發中)
- 自研優化器:自研Cost-Based Optimizer,優化多表JOIN等復雜查詢性能,性能提升若干倍。
產品能力上,在引擎外提供更加豐富的企業級功能和可視化管理界面:
- 庫表資產管理:控制臺建庫建表,管理元信息。
- 多租戶管理:支持多租戶模型,租戶間互相隔離,獨立計費。
- RBAC權限管理:支持庫、表、列級,讀、寫、資源管理等權限。通過角色進行管理。
- VW自動啟停,彈性擴展:計算資源按需分配,閑時關閉。降低總成本,提高資源使用率。
- 性能診斷:提供Query History和Query Profiler功能,幫助用戶自助地排查慢查詢的原因。
ByteHouse性能優化:復雜查詢、寬表查詢
ByteHouse來源于ClickHouse,但又基于字節跳動內部實踐場景經驗,進行了一系列升級。在性能層面,主要復雜查詢以及寬表查詢兩方面進行優化。
復雜查詢優化
其中相比單表查詢或者寬表查詢而言,復雜查詢主要包含較多的Agg join和嵌套子查詢等特征。在復雜查詢優化項中,相比于社區版ClickHouse,ByteHouse升級的能力包含自研優化器以及在引擎層新引入的exchange runtime Filiter模塊以及為提升并行化能力而做的一些重構工作。
優化一:RBO(基于規則的優化能力)
首先,自研優化器RBO,即基于規則的優化,包含列裁剪、分區裁剪、表達式簡化、子查詢解關聯、謂詞下推、冗余算子消除、Outer-Join 轉 Inner-Join、算子下推存儲、分布式算子拆分等常見的啟發式優化能力。
- 相對社區版ClickHouse,ByteHouse實現了完整的解關聯,從而確保tpcds所有查詢能夠運行。如下圖所示,一個customer表和一個含orders表的子查詢進行關聯,最后的計劃會展開成對應的join、agg和filter等算子。
- 另外,針對非等值join,相對于先outer join后再執行非等值過濾這種組合,非等值join可以直接在join算子中完成非等值判斷,從而提升了1倍的性能。
- 最后,針對很多通用的業務場景,RBO還實現了對多個列計算count distinct的優化,主要原理是基于復制的方式從而提升并行度來實現。
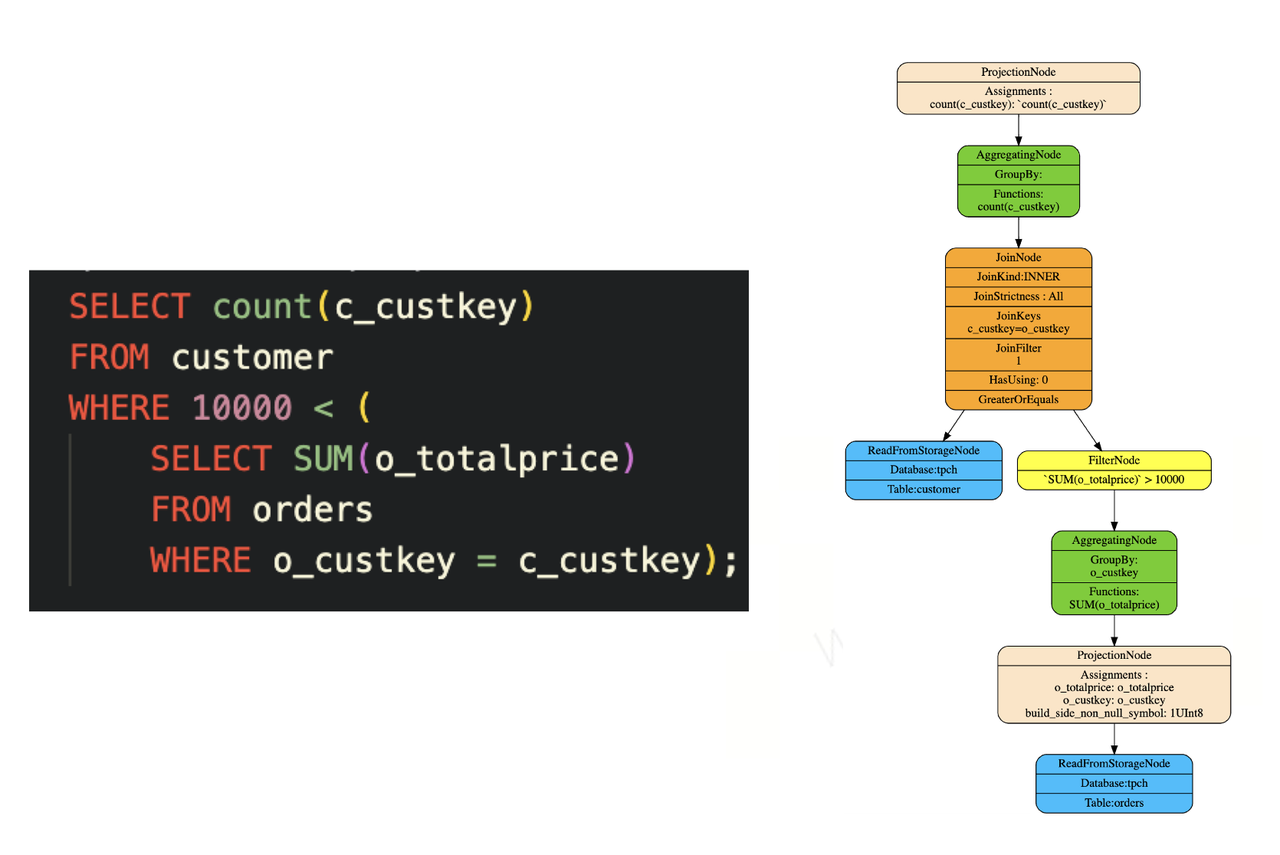
優化二:CBO(基于代價的優化能力)
在自研優化器CBO,即基于代價優化部分,ByteHouse主要基于Cascade搜索框架,從而可以邊生成物理計劃邊尋求最優解。并針對join order枚舉問題采用了Join graph partition的方式減少了重復計劃的生成從而提升搜索性能;另外代價則為基于統計信息生成。
在Join Recorder方面,針對10表級別規模的join recorder問題,ByteHouse能夠在秒級別全量枚舉并生成最優解,另外,針對大于10表的則使用了啟發式,ByteHouse還支持混合Outer Semi Anti Join的reorder功能。
在CTE層面,ByteHouse支持了Inline, shared及partial inline等不同粒度的代價計算,從而計算最優解。
除此之外,ByteHouse具備基于magic set placement能力,通過計算join過濾度代價來選擇下推到agg,從而減少agg計算熱點的能力。
優化三:分布式計劃生成方面推出了自研優化器
在生成計劃過程中,區別于業界主流的二階段方式,即先生成最優單機計劃再生成分布式計劃的方式。ByteHouse優化器融合了兩個階段,先展開所有分布式計劃,然后基于全局代價生成最優解,并減少shuffle。其中,ByteHouse也會通過表的元數據信息和屬性推論,利用數據分布來減少agg和join的shuffle開銷。
優化器生成的物理計劃往往按照數據重分布會拆解成多個計劃片段即plan segment,相比于社區版ClickHouse,除了優化器生成的物理計劃不同之外,plan segment之間數據的傳輸也是依賴我們新引入的exchange模塊能力。模塊分為兩層,數據傳輸層和算子層。
- 數據傳輸層支持同進程傳輸,基于隊列跨進程,基于 BRPC stream,并支持保序狀態碼傳輸、壓縮和連接池復用等功能。為了確保穩定性,連接池可以讓上下游 plan segment 在集群做數據 shuffle 的時候始終維持在固定數量的連接,從而提升穩定性。
- 在傳輸層之上,算子層提供了一對多的broadcast,多對多的repetition、多對一的gather、其進程內的round、 Robin 等算子。
此外,ByteHouse還實現了更多exchange性能相關優化,如盡量減少重復的序列化及載批等邏輯。
相對于社區對于join能力,ByteHouse提供了runtime filter能力,這是在執行引擎中動態構建filter的能力,例如在 Hash Join 的 Probe 階段前,提前過濾掉大部分不會參與 Join 的左表數據,從而減少數據傳輸和計算的開銷,提升性能。這里的Runtime Filter是在 Hash Join 的 Build 階段后,結合 Join Key 和 Hash表生成。此外,ByteHouse支持根據不同的場景生成最優的 RuntimeFilter,優化了 Runtime Filter 的生成和執行的流程。同時,也支持 Distributed 和 Local 的 RuntimeFilter,及自適應的 Shuffle-Aware 能力。
優化四:并行化重構
除了以上介紹的優化器、exchange和runtime filter能力外,ByteHouse也是一直朝著提升并行計算能力的方向持續在演進。
針對agg和join,社區版ClickHouse的解法通常不會考慮數據的分布特性,以及一些算子的聚合度特性,從而產生大量的無意義的blocking的中間結果的merge開銷以及join跨節點的shuffle開銷。
針對agg,ByteHouse實現了自適應的agg streaming能力,可以根據聚合度減少無意義的中間merge開銷。
另外,結合優化器,和bucket表能力,ByteHouse用了數據分布特性,大量減少了agg和join的shuffle開銷,從而提升了并行度。
寬表查詢優化項
針對社區ClickHouse典型寬表場景,ByteHouse做了全局字典、Zero copy以及Uncompress Cache優化。
首先,全局字典主要功能是通過全局字典編碼的方式將變長的字符串轉化為電長的數值。針對 AGG function 和 exchange 算子,不僅在單節點上單節點以,也可以在跨節點間直接進行這個編碼值的計算,以此提升計算效率。
其次,Zero copy是應對內存墻的一種優化方式,通過減少數據傳輸中引發的深拷貝開銷,盡量提升內存帶寬在真正計算上的使用。
最后,針對單節點上多線程同時并發訪問Uncompress cache引發常見的鎖競爭的現象,ByteHouse做了針對性優化,保證了Cache帶來的性能收益。
性能表現
以下是ByteHouse在標準數據集的性能表現。本次發布會主要聚焦100G 的規模。針對每項測試,ByteHouse和某款開源的 OLAP 引擎進行了性能對比。
- TPCDS 100G
從 TPC-DS 100G 的結果可以觀察到,經過測試發現在完成 TPC-DS 標準測試數據集的 99 個查詢中,ByteHouse比開源產品OLAP 引擎總體時間超出 6 倍多,并且開源產品部分語句無法正常執行。在兩者均完成查詢的結果中,開源產品與 ByteHouse 查詢時間相差 15.7 倍,其中Q53、Q63、Q82 等語句的查詢效率相差 200 倍左右。
針對TPC-DS 100G 數據集,涉及到前面的收益相關優化項,包括資源的優化器、 exchange 算子、 runtime filter 以及全局字典等。詳細的結果可以在ByteHouse性能白皮中仔細閱覽。
- TPCH 100G
針對 TPCH 100 數據集,在經過 TPCH 的標準測試數據集的 22 個查詢中,開源產品部分與給予無法正常執行,整體查詢周期很長,在兩者均完成查詢的結果中,開源產品與 ByteHouse 的查詢時間相差無數倍,其中Q3、Q5、 Q7 等語句的查詢效率相差 100 倍以上。相關 TPCH 相關的收益優化項包含優化器 exchange、 runtime filter以及前面提到的并行化重構和全局字典等。
- SSB Flat 100G 以及Standard SSB
公布的完整的SSB 測試結果,不僅是 13 條針對寬表的測試,還包另外 13 條在星狀模型場景下的進行多表關聯的測試。
首先從 13 條寬表查詢的結果來看, SSD 寬表測試的 13 個查詢中, ByteHouse 查詢性能全面超越開源產品,整體查詢性能達到該產品的 3.6 倍多。對其中涉及的收益相關的優化項包括優化器 exchange 全區字典 Zero copy 以及 Uncompressed Cache 。
除了以上的寬表查詢之外,針對標準的 SSB 多表關聯的查詢,從結果可以看出,在 13 個查詢中,開源產品最后 3 個查詢因為內存問題查詢失敗,整體查詢性能與ByteHouse相差較大,其中涉及的優化項包含優化器exchange、 runtime filter、全局字典等。
高性能場景之高并發點查
在大數據和實時分析的時代,在很多業務場景,比如廣告等,都對OLAP點查能力有強需求。高并發點查對于商業決策、市場分析、用戶行為研究場景中的使用體驗和查詢精準度都起到重要作用。
如果OLAP系統的高并發點查能力不足,就會存在響應時間慢等情況,在技術層面則體現為索引計算繁重、點查讀放大嚴重、執行鏈路冗長、鎖競爭激烈等問題,ByteHouse通過采用短鏈路的執行方式、建立unique table 點查索引、提升讀鏈路效率等方式進行優化
高并發瓶頸
- 索引計算繁重:ByteHouse在做索引計算時會引入很多表達式計算,導致比較高的CPU消耗,因此優化索引計算開銷是提升QPS水平的關鍵。
- 點查讀放大嚴重:在下圖中有很多decompress函數,對于通用的OLAP引擎,讀一行數據通常也需要讀取大量的block,再將block解壓反序列化成內存格式,需要消耗大量的CPU資源。在高并發的場景下,點查讀放大的問題更加突出。
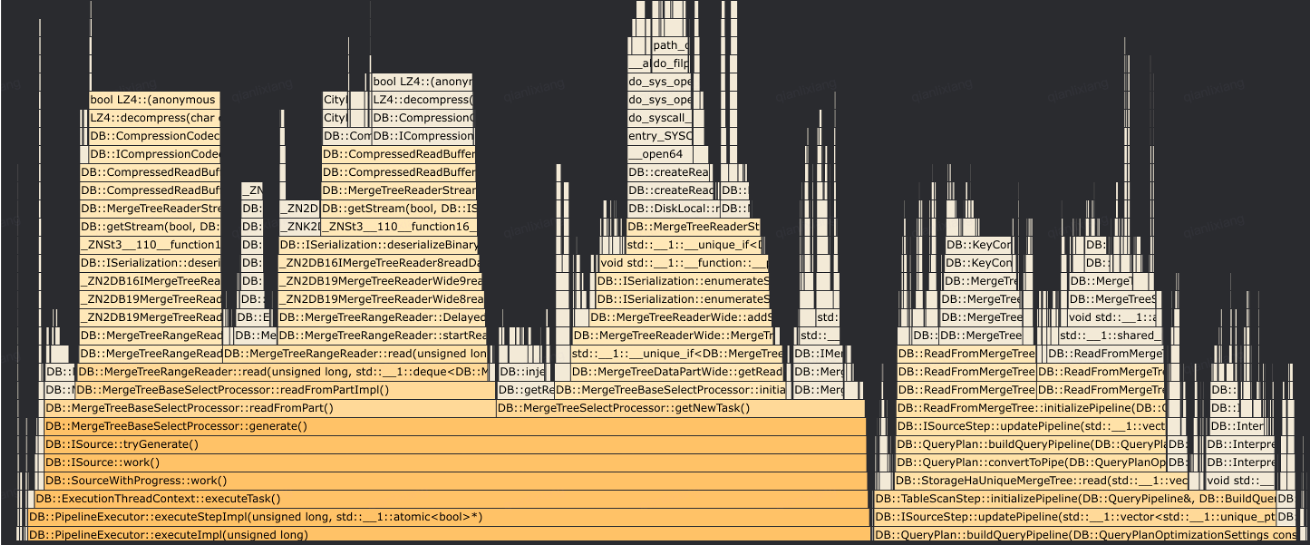
- 執行鏈路冗長:ByteHouse自研優化器的規則,眾多的 RBO 規則和CBO優化,導致執行鏈路非常長。
- 鎖競爭激烈:由于較長的執行鏈路中間有很多共享變量,在多線程環境下需要加鎖保護,導致鎖競爭激烈。
優化手段
優化一:更簡潔的短路執行計劃
首先,我們為高并發的點查場景設計一套更簡潔的短路執行計劃。
當執行計劃分析完后,如果query是一個點查場景,ByteHouse可以為其生成一個特定的優化的規則。
簡化后只保留簡單的幾個規則,例如:
- 把limit下推,刪除冗余的條件并精簡plan,將謂詞表達式下推到存儲層。
普通的query會生成執行計劃,分為兩個階段:階段一,segment 1下發到各個節點去執行,階段二 segment 0 匯聚各個節點的數據,這種計劃會帶來大量的 plan 序列化反序列化,網絡傳輸、數據匯總等一系列的開銷;而在點查場景中,可能存在點查只會命中一條數據,那么這一條數據勢必就會存在于某一個節點上,那么沒有必要把計劃發送到各個節點。為此,我們做了如下優化:
- 將兩階段的計劃合并成一個segment 計劃
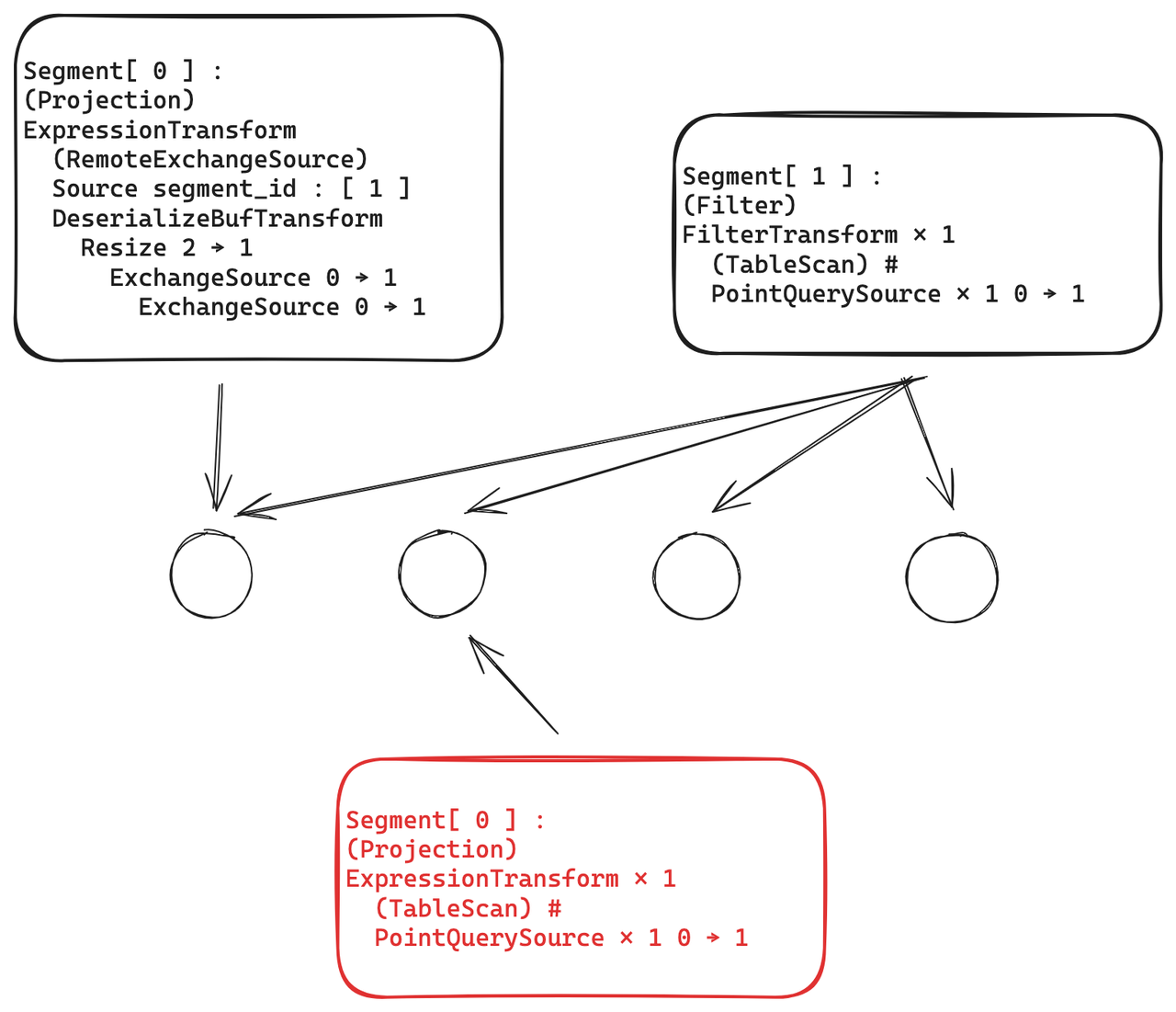
- ByteHouse在生成完計劃之后,會計算出計劃命中的節點,并將節點裁掉,將精簡的執行計劃發送到特定的節點。
優化二:基于 unique table 點查索引
完成執行計劃上的優化之后,在真正做查詢的時候,ByteHouse引入了一個基于unique table 的點查索引。
該索引為一個內存的結構(KV結構),k是檢查中所用到的謂詞值,value是行號,直接訪問點查索引就能得到對應的行號或者對應的mark。點查索引可以和行存復用,通過索引得到行號的集合后可以直接訪問對應行的數據。
優化三:高效的讀鏈路優化
讀鏈路中首先會進行分區的裁剪,和之前主鍵過濾一樣,分區的裁剪里面有大量的表達式的計算,為此ByteHouse做了更輕量的分區的裁剪,并基于分區裁剪和 unique index 的過濾的結果得到 part 和 mark 的值。針對 limit 可以下推的場景,ByteHouse在 mark 的粒度上建了一個 Min-Max 的索引,然后按照 Min-Max 索引做排序就可以通過 limit 值來判斷出真正需要讀的 mark 是哪些。這樣就可以只讀少量的mark,不必要讀所有篩選出來的 mark 再做過濾。
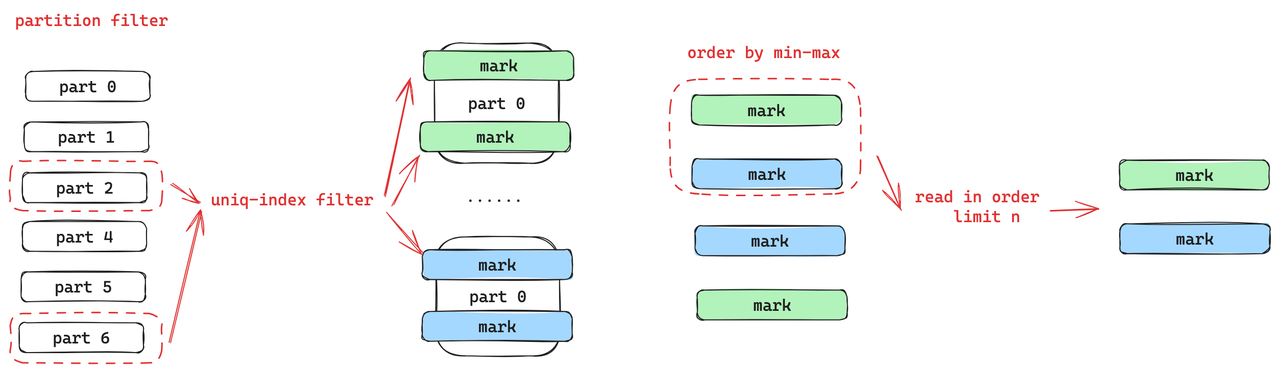
讀鏈路里面存在兩種格式,一種是列存的格式,一種是行存的格式。
- ByteHouse為列存的格式的底層做了一層 bucket cache,在多線程訪問mark 數據時能有效減少鎖競爭。
- 在訪問行存的時候,ByteHouse在行存的下一層做了一個基于行存的 cache,這會大大提高行存查詢的效率。
- 最后一個優化點是新語法prepared statement,它可以用來優化parser解析時間和queryplan 生成的時間。比如,ByteHouse會定義 prepared statement,然后在需要定義的query 里面去指定查詢的參數模板。當真正運行的時候,就可以通過 prepare statement 填充上它的值并做查詢。有了該查詢模板之后,parser解析時間和queryplan 生成的時間基本上可以被消除。
性能表現
- 測試環境:32core/128G/1T SSD
- 數據:100000000行數據
測試場景為 unique 表,點查query為用 unique 表的 key 為謂詞。下圖中展示了每個優化階段完成后對應的 QPS 變化,baseline 表示的是未進行任何優化時候的表現
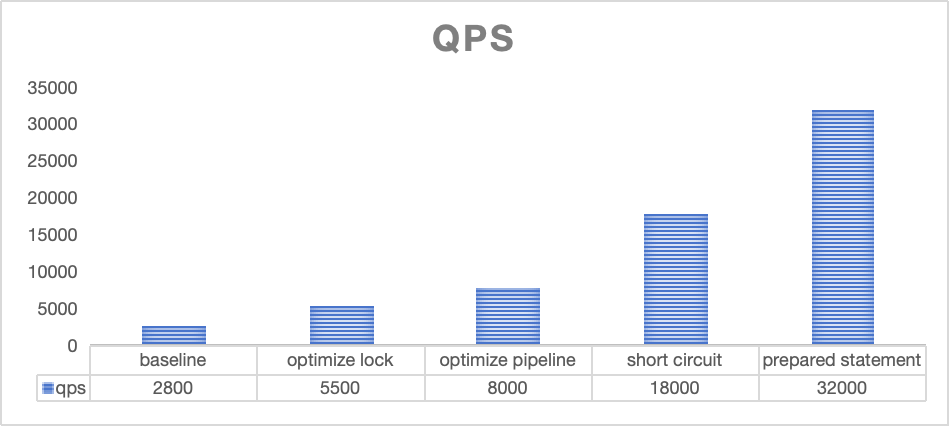
- 當做完鎖優化、pipeline 優化之后,性能達到 5, 500- 8, 000 QPS。
- 當引入了比較精簡的執行計劃之后,性能達到 18, 000 的QPS。
- 再將AST 解析和plan build 時間去掉之后,ByteHouse能獲得32000 QPS 的水平。
結語
不僅僅是技術層面的性能提升,ByteHouse在實時數倉、復雜查詢、寬表查詢、人群圈選、行為分析等八大場景中,也將高性能落地。其中,在人群圈選場景中,ByteHouse可以滿足大規模數據的分析和查詢需求,并具有一套用于解決集合的交并補計算的定制模型BitEngine,該模型能解決實時分析場景中的性能提升問題。相比于普通和Array或者用戶表方式,BitEngine在查詢速度上有10-50倍提升,解決了人群圈選中誤差大、實時性不強以及存儲成本高的痛點。
通過一系列技術優化手段,ByteHouse實現性能進一步提升,縮短查詢執行時間、優化資源利用,能應對更復雜的查詢場景,為用戶提供更流程的數據分析體驗。不僅僅是探索性能突破,ByteHouse也在持續拓展產品一體化、易用性、生態兼容性,為業務帶來更多的價值,推動各行各業數字化轉型。
#活動推薦#
限額50位 ByteHouse性能挑戰賽正式開啟!
● 活動時間:3月26日-4月26日截止
● 如果你對OLAP性能調優感興趣,如果你正在進行數據庫選型,如果你遇到數據庫性能瓶頸......
??參與性能復現和挑戰,即有機會獲取airpods、智能手表、機械鍵盤等大獎
添加小助手,回復“性能挑戰賽”立即報名



 浙公網安備 33010602011771號
浙公網安備 33010602011771號