
從 ClickHouse 到 ByteHouse:實時數(shù)據(jù)分析場景下的優(yōu)化實踐
 在打造 ByteHouse 的過程中,我們經(jīng)過了多年的探索與沉淀,本文將和大家分享字節(jié)跳動過去使用 ClickHouse 的兩個典型應(yīng)用與優(yōu)化案例。
在打造 ByteHouse 的過程中,我們經(jīng)過了多年的探索與沉淀,本文將和大家分享字節(jié)跳動過去使用 ClickHouse 的兩個典型應(yīng)用與優(yōu)化案例。
字節(jié)跳動旗下的企業(yè)級技術(shù)服務(wù)平臺火山引擎正式對外發(fā)布「ByteHouse」,解決開源技術(shù)上手難 & 試錯成本高的痛點,同時提供商業(yè)產(chǎn)品和技術(shù)支持服務(wù)。
作為國內(nèi)規(guī)模最大的 ClickHouse 用戶,目前字節(jié)跳動內(nèi)部的 ClickHouse 節(jié)點總數(shù)超過 1.5W 個。綜合來說,字節(jié)跳動廣泛的業(yè)務(wù)增長分析很多都建立在 ClickHouse 為基礎(chǔ)的查詢引擎上。
在打造 ByteHouse 的路程中,我們經(jīng)過了多年的探索與沉淀,本文將分享字節(jié)跳動過去使用 ClickHouse 的兩個典型應(yīng)用與優(yōu)化案例。
推薦系統(tǒng)實時指標
在字節(jié)跳動內(nèi)部“A/B 實驗”應(yīng)用非常廣泛,特別是在驗證推薦算法和功能優(yōu)化的效果方面。最初,公司內(nèi)部專門的 A/B 實驗平臺已經(jīng)提供了 T+1 的離線實驗指標,而推薦系統(tǒng)需要更快地觀察算法模型、或者某個功能的上線效果,因此需要一份能夠?qū)崟r反饋的數(shù)據(jù)作為補充:
-
能同時查詢聚合指標和明細數(shù)據(jù);
-
能支持多達幾百列的維度和指標,且場景靈活變化,會不斷增加;
-
可以高效地按 ID 過濾數(shù)據(jù);
-
需要支持一些機器學習和統(tǒng)計相關(guān)的指標計算(比如 AUC)。
01 - 技術(shù)選型
字節(jié)內(nèi)部有很多分析引擎,ClickHouse、 Druid、 Elastic Search、 Kylin 等,通過分析用戶需求后選擇了 ClickHouse:
- 能更快地觀察算法模型,沒有預(yù)計算所導致的高數(shù)據(jù)時延;
- ClickHouse 既適合聚合查詢,配合跳數(shù)索引后,對于明細點查性能也不錯;
- 字節(jié)自研的 ClickHouse 支持 Map 類型,支持動態(tài)變更的維度和指標,更加符合需求;
- BitSet 的過濾 Bloom Filter 是比較好的解決方案,ClickHouse 原生就有 BF 的支持;
- 字節(jié)自研的 ClickHouse 引擎已經(jīng)通過 UDF 實現(xiàn)了相關(guān)的能力,而且有比較好的擴展性。
每個產(chǎn)品都有自己合適的場景,但是對于當前場景的需求評估下,ClickHouse 更加合適。
方案對比
確認技術(shù)選型后,在如何實現(xiàn)部分,也有兩種方式:

最終方案及效果
由于外部寫入并不可控和技術(shù)棧上的原因,我們最終采用了 Kafka Engine 的方案,也就是 ClickHouse 內(nèi)置消費者去消費 Kafka。整體的架構(gòu)如圖:
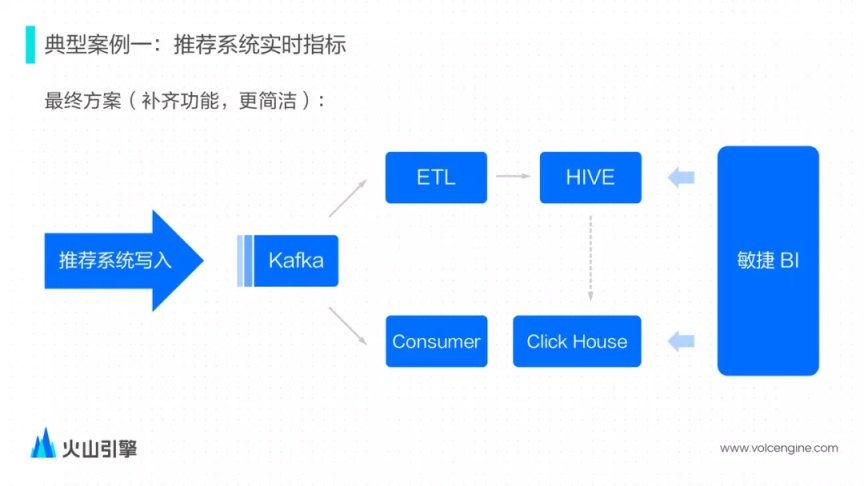
數(shù)據(jù)由推薦系統(tǒng)直接產(chǎn)生,寫入 Kafka——為了彌補缺少 Flink 的 ETL 能力,推薦系統(tǒng)做了相應(yīng)配合,修改 Kafka Topic 的消息格式直接適配 ClickHouse 表的 schema;
敏捷 BI 平臺也適配了一下實時的場景,可以支持交互式的查詢分析;
如果實時數(shù)據(jù)有問題,也可以從 Hive 把數(shù)據(jù)導入至 ClickHouse 中,除此之外,業(yè)務(wù)方還會將 1% 抽樣的離線數(shù)據(jù)導入過來做一些簡單驗證,1% 抽樣的數(shù)據(jù)一般會保存更久的時間。
除了技術(shù)選型和實現(xiàn)方案,我們在支持推薦系統(tǒng)的實時數(shù)據(jù)時遇到過不少問題,其中最大的問題隨著推薦系統(tǒng)產(chǎn)生的數(shù)據(jù)量越來越大,單個節(jié)點的消費能力也要求越來越大,主要碰到如下問題:
02- 挑戰(zhàn)與解決方案
問題一:寫入吞吐量不足
在有大量輔助跳數(shù)索引的場景下,索引的構(gòu)建嚴重影響寫入吞吐量。
解決方案——異步構(gòu)建索引
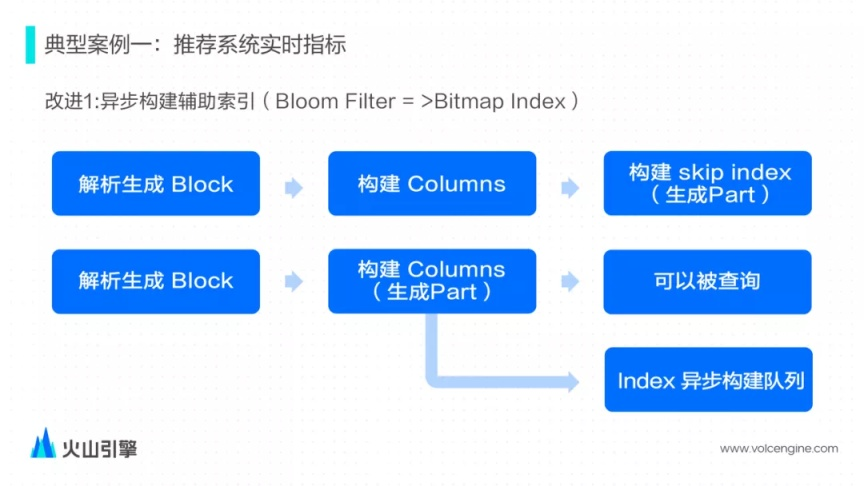
社區(qū)版本的實現(xiàn)里的具體邏輯如下:
-
解析輸入數(shù)據(jù)生成內(nèi)存中數(shù)據(jù)結(jié)構(gòu)的 Block;
-
然后切分 Block,并按照表的 schema 構(gòu)建 columns 數(shù)據(jù)文件;
-
最后掃描根據(jù) skip index schema 去構(gòu)建 skip index 文件。三個步驟完成之后才會算 Part 文件構(gòu)建完畢。
在需要保證構(gòu)建完 columns 數(shù)據(jù)之后用戶即可正常查詢的前提下,ByteHouse 同步完成前面兩步,第三步把構(gòu)建好的 Part 放入到一個異步索引構(gòu)建隊列中,由后臺線程構(gòu)建索引文件。
在改成異步后,整體的寫入吞吐量大概能提升 20%。
問題二:Kafka 消費能力不足
社區(qū)版本的 Kafka 表,內(nèi)部默認只會有一個消費者,這樣會比較浪費資源并且性能達不到性能要求。
嘗試優(yōu)化過程:
-
嘗試通過增大消費者的個數(shù)來增大消費能力,但社區(qū)的實現(xiàn)是由一個線程去管理多個的消費者,多個消費者消費到的數(shù)據(jù)最后僅能由一個輸出線程完成數(shù)據(jù)構(gòu)建,所以這里沒能完全利用上多線程和磁盤的潛力;
-
嘗試通過創(chuàng)建多張 Kafka Table 和 Materialized View 寫入同一張表,但是對于運維會比較麻煩。
解決方案——支持多線程消費

前面提到的優(yōu)化手段都不盡如人意,最后決定改造 Kafka Engine 在其內(nèi)部支持多個消費線程,簡單來說就是每一個線程它持有一個消費者,然后每一個消費者負責各自的數(shù)據(jù)解析、數(shù)據(jù)寫入,這樣的話就相當于一張表內(nèi)部同時執(zhí)行多個的 INSERT Query。
通過多線程實現(xiàn)多消費者同時消費寫入表,寫入性能達到接近于線性的提升。
問題三:出現(xiàn)故障無法保證數(shù)據(jù)完整性
在主備模式下,如果數(shù)據(jù)同時兩個節(jié)點都寫入,一旦一個節(jié)點出現(xiàn)故障,新啟的節(jié)點恢復過程中容易出現(xiàn)各種問題,包括性能下降,無法保證分片,最嚴重可能導致查詢結(jié)果不正確。
解決方案——確保主備模式下只會寫入一個主備其中一個節(jié)點
為了避免兩個節(jié)點消費這個數(shù)據(jù),改進版的 Kafka Engine 參考了 ReplicatedMergeTree 基于 ZooKeeper 的選主邏輯。對于每一對副本的一對消費者,會嘗試在 ZooKeeper 上完成選主邏輯,確保選舉成為主節(jié)點的消費者才能消費,另一個節(jié)點則會處于一個待機狀態(tài)。
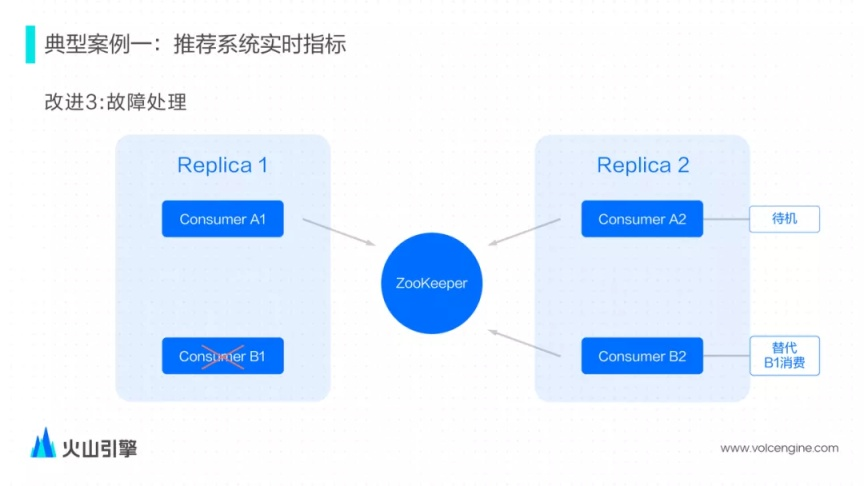
有了這樣的單節(jié)點消費機制, 系統(tǒng)會檢測 ReplicatedMergeTree 表數(shù)據(jù)是否完整,如果數(shù)據(jù)不完整則代表不能正常服務(wù),此時消費者會主動出讓 Leader,讓副本節(jié)點上成為消費者,也就是新寫入的數(shù)據(jù)并不會寫入到缺少數(shù)據(jù)的節(jié)點,對于查詢而言,由于查詢路由機制的原因也不會把 Query 路由到缺少數(shù)據(jù)的節(jié)點上,所以一直能查詢到最新的數(shù)據(jù)。
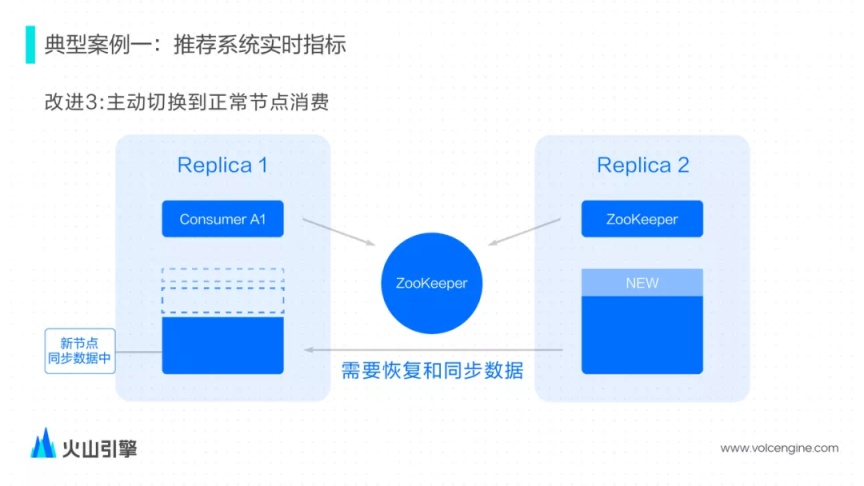
改進 Kafka Engine 確保主備模式下只有一個節(jié)點能消費數(shù)據(jù),即使出現(xiàn)節(jié)點故障在新節(jié)點恢復過程中同樣保障了解決了數(shù)據(jù)完整性的問題。
廣告投放實時數(shù)據(jù)
第二個典型案例關(guān)于廣告的投放數(shù)據(jù),一般是運營人員需要查看廣告投放的實時效果。由于業(yè)務(wù)的特點,當天產(chǎn)生的數(shù)據(jù)往往會涉及到多天的數(shù)據(jù)。
這套系統(tǒng)原來基于 Druid 實現(xiàn)的,Druid 在這個場景會有一些難點:

選擇了 ClickHouse 之后能解決 Druid 不足的地方,但還是有部分問題需要解決:
問題一:Buffer Engine 無法和 ReplicatedMergeTree 一起使用
社區(qū)提供了 Buffer Engine 為了解決單次寫入生成過多 Parts 的問題, 但是不太能配合 ReplicatedMergeTree 一起工作, 寫入不同 Replica 的 Buffer 僅緩存了各自節(jié)點上新寫入的數(shù)據(jù),導致查詢會出現(xiàn)不一致的情況。
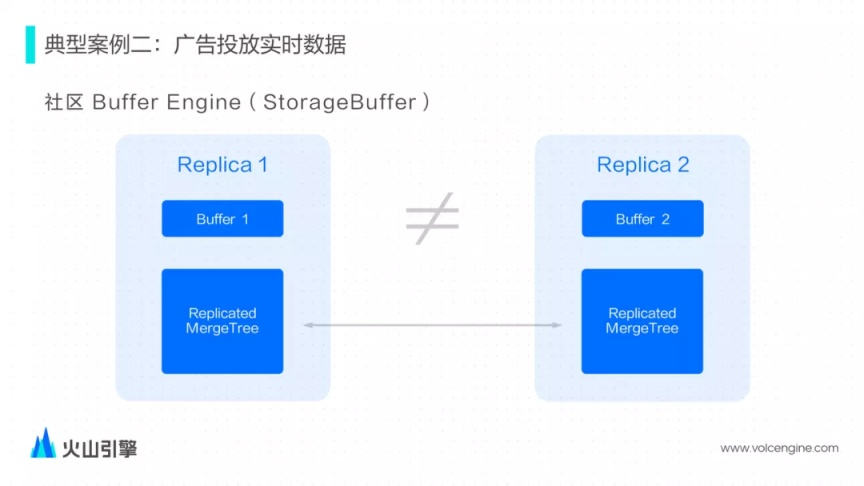
解決方案
改進了 Buffer Engine 做了如下的調(diào)整和優(yōu)化:
-
我們選擇將 Kafka/Buffer/MergeTree 三張表結(jié)合起來,提供的接口更加易用;
-
把 Buffer 內(nèi)置到 Kafka Engine 內(nèi)部, 作為 Kafka Engine 的選項可以開啟/關(guān)閉,使用更方便;
-
Buffer table 內(nèi)部類似 pipeline 模式處理多個 Block;
-
支持了 ReplicatedMergeTree 情況下的查詢。
首先確保一對副本僅有一個節(jié)點在消費,所以一對副本的兩個 Buffer 表,只有一個節(jié)點有數(shù)據(jù)。如果查詢發(fā)送到了沒有消費的副本,會額外構(gòu)建一個特殊的查詢邏輯,從另一個副本的 Buffer 表里讀取數(shù)據(jù)。
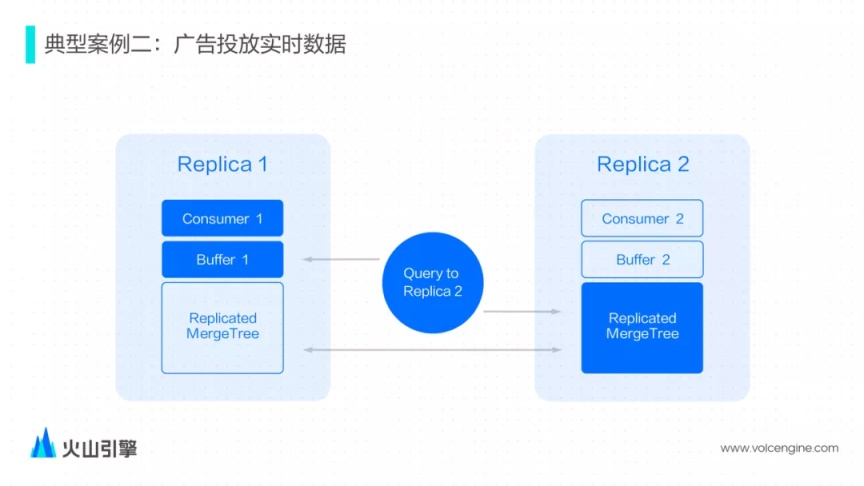
增強 Buffer Engine,解決了 Buffer Engine 和 ReplicatedMergeTree 同時使用下查詢一致性的問題。
問題二:出現(xiàn)宕機后可能會出現(xiàn)數(shù)據(jù)丟失后者重復消費的情況
ClickHouse 缺少事務(wù)支持。一批次寫入只寫入部分 Part 后出現(xiàn)宕機,因為沒有事務(wù)保障重啟后可能出現(xiàn)丟失或者重復消費的情況。
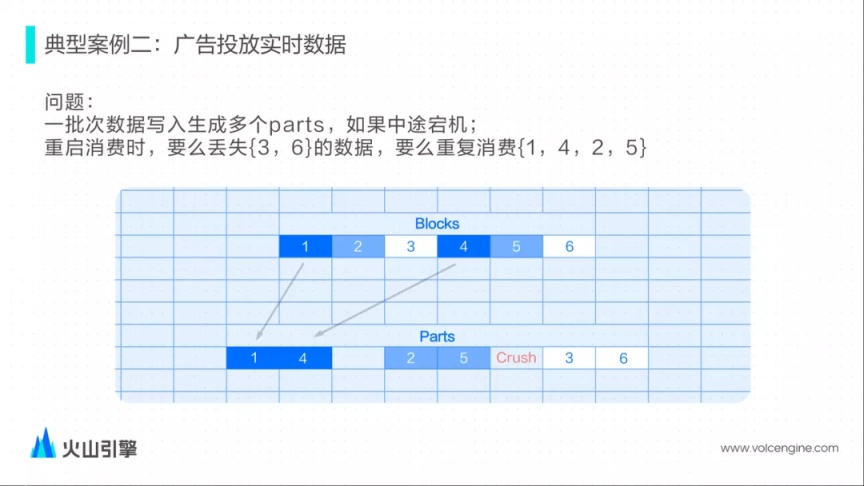
解決方案

參考了 Druid 的 KIS 方案自己管理 Kafka Offset,實現(xiàn)單批次消費/寫入的原子語義:實現(xiàn)上選擇將 Offset 和 Parts 數(shù)據(jù)綁定在一起,增強了消費的穩(wěn)定性。 每次消費時,會默認創(chuàng)建一個事務(wù),由事務(wù)負責把 Part 數(shù)據(jù)和 Offset 一同寫入磁盤中,如果出現(xiàn)失敗,事務(wù)會一起回滾 Offset 和寫入的 Part 然后重新消費。
確保了每次插入數(shù)據(jù)的原子性,增強了數(shù)據(jù)消費的穩(wěn)定性。
結(jié)語
實時數(shù)據(jù)分析是 ClickHouse 的優(yōu)勢場景,結(jié)合字節(jié)跳動實時數(shù)據(jù)場景的特點,我們對 ClickHouse 進行了優(yōu)化和改造,并將這些能力沉淀到了 ByteHouse 上。
ByteHouse 基于自研技術(shù)優(yōu)勢和超大規(guī)模的使用經(jīng)驗,為企業(yè)大數(shù)據(jù)團隊帶來新的選擇和支持,以應(yīng)對復雜多變的業(yè)務(wù)需求,高速增長的數(shù)據(jù)場景。
未來,ByteHouse 將不斷以字節(jié)和外部最佳實踐輸出行業(yè)用戶,幫助企業(yè)更好地構(gòu)建交互式大數(shù)據(jù)分析平臺,并更廣泛地與 ClickHouse 研發(fā)者社群共享經(jīng)驗,共同推動 ClickHouse 社區(qū)的發(fā)展。
火山引擎 ByteHouse
統(tǒng)一的大數(shù)據(jù)分析平臺。目前提供企業(yè)版和云數(shù)倉兩種版本,企業(yè)版是基于開源 ClickHouse 的企業(yè)級分析型數(shù)據(jù)庫,支持用戶交互式分析 PB 級別數(shù)據(jù),通過多種自研表引擎,靈活支持各類數(shù)據(jù)分析和應(yīng)用;云數(shù)倉版作為云原生的數(shù)據(jù)分析平臺,實現(xiàn)統(tǒng)一的離線和實時數(shù)據(jù)分析,并通過彈性擴展的計算層和分布式存儲層,有效降低企業(yè)大數(shù)據(jù)分析 TCO。[點擊申請體驗]
歡迎關(guān)注字節(jié)跳動數(shù)據(jù)平臺同名公眾號

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號