

神經網絡入門——神經元算法
◆版權聲明:本文出自胖喵~的博客,轉載必須注明出處。
轉載請注明出處:http://www.rzrgm.cn/by-dream/p/10497816.html
目前機器學習、深度學習在業界使用的越來越廣泛,做為一個有著技術追求的it人,我覺得有必要學習和了解一下這塊的知識,今天就從最簡單的單層神經網絡開始介紹。
在介紹人工神經網絡之前,首先認知下神經元。
神經元
不知道大家還有印象這個圖嗎?這個是出現在我們生物課本中的一幅圖。

一個神經元的組成基本就是上圖這些東西組成。
通常一個神經元具有多個樹突,主要用來接受傳入信息信息,信息通過軸突傳遞進來后經過一系列的計算(細胞核)最終產生一個信號傳遞到軸突,軸突只有一條,軸突尾端有許多軸突末梢可以給其他多個神經元傳遞信息。軸突末梢跟其他神經元的樹突產生連接,從而傳遞信號。這個連接的位置在生物學上叫做“突觸”。
也就是說一個神經元接入了多個輸入,最終只變成一個輸出,給到了后面的神經元,那么基于此,我們嘗試去構造一個類似的結構。
結構
神經元的樹突我們類比為多條輸入,而軸突可以類比為最終的輸出。
這里我們構造一個典型的神經元模型,該模型包含有3個輸入,1個輸出,以及中間的計算功能。
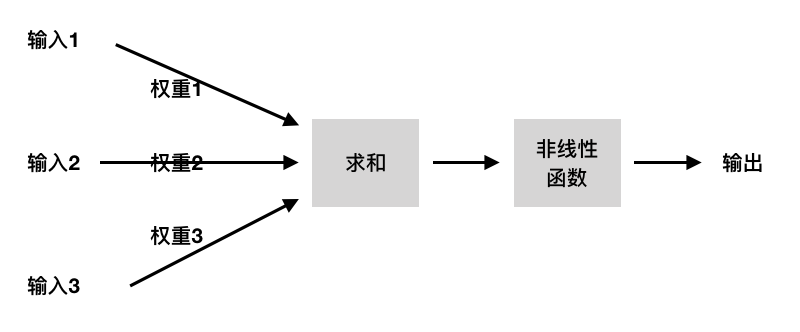
注意在每一個輸入的“連接”上,都有一個對應的“權值”。
說個通俗的例子來理解下權值。比如今天你要決定今是否要去看電影,可能要考慮這3個因素: 1、女朋友有沒有時間,2、有沒有好看的電影,3、今天工作忙不忙; 而這三個因素對于每個人來說權重都是不同的,因為有的人看重工作、有的人看重家人,不同的權重最終的結果也會不一樣。
因此權重的大小是比較關鍵的。而一個神經網絡的訓練算法就是讓權重的值調整到最佳,以便使得整個網絡的預測效果最好。
接下里,我們用數學的方式來表示一下神經元,我們定義 w為權重,x為輸入
$$ w = \begin{bmatrix} w_{1} \\ ... \\ w_{m} \end{bmatrix} , x = \begin{bmatrix} x_{1} \\ ... \\ x_{m} \end{bmatrix}$$
$$ z = w_{1} * x_{1} + ... + w_{m} * x_{m} $$
z輸入的總和,也就是這兩個矩陣的點乘,也叫內積。這里補充點數學知識。
?$$ z = w_{1} * x_{1} + ... + w_{m} * x_{m} = \sum\limits_{j=1}^{m} w_{j} * w_{j} = w^{T}*x $$
$\phi$(z) = { 1 if z>=θ; -1 otherwise
注意這里有一個閾值 θ ,閾值的確定也需要在訓練過程中進行完成。
那么如何進行訓練,這里的我們需要用到感知器(preceptron)算法,具體過程分為下面這么幾個步驟:
1、首先將權重向量w進行初始化,可以為0或者是[0,1]之間的隨機數;
2、將訓練樣本輸入感知器(計算內積后輸入激活函數得到最終結果),最后得到分類的結果(結果為1 或 -1);
3、根據分類的結果再次更新權重向量w;
前面提到激活函數是當z值大于一定的閾值? θ 后,才進行激活或者不激活。因此為了計算方便呢,我們再多加入一組向量,w0 和 x0 ,w 取 -θ ,x0 取 1;將其放到等式左邊,這樣當 z>0 的時候 激活函數輸出 1,而 z<0 激活函數輸出 -1。
$$ z = w_{0} * x_{0} + w_{1} * x_{1} + ... + w_{m} * x_{m} $$
$\phi$(z) = { 1 if z>=0; -1 otherwise
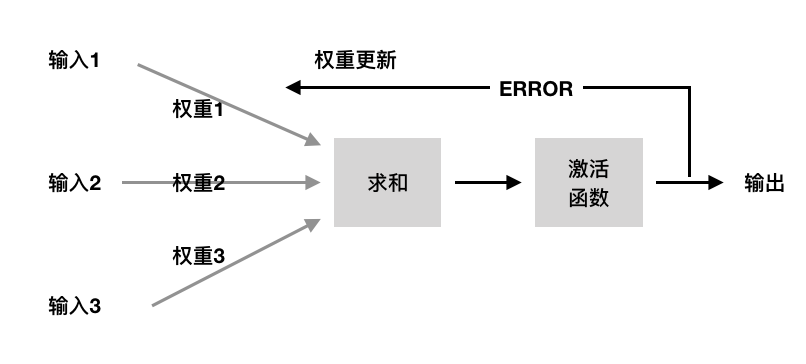
權重更新
好,前面所有的準備都已經完成,接下來我們看下剛才提到的第三步,權重向量的更新,其實也就是神經網絡訓練的過程:
權重的更新每一輪迭代 Wj = Wj+ ? ▽Wj
而 ▽Wj = η * ( y - y' ) * Xj
上式中 η 叫做學習率,是[0, 1]之間的一個小數,由我們自己定義;y是真實 的樣本分類,而 y’ 是感知器計算出來的分類。
我們可以簡單推導一下,當 y 和 y' 相等,?▽Wj 的值為0,Wj則不會更新。對應的意義就是真實和預測的結果是相同的,因此權重也不需要再更新了。
這里舉個例子 :
假設初始化 W = [ 0, 0, 0] , X = [1, 2, 3], 假設定義 η = 0.3,y = 1,y' = -1
▽W(1) = 0.3 * (1 - (-1)) * X(1) = 0.3*2*1 = 0.6; W(1) = W(1) + ▽W(1) = 0.6;
▽W(2) = 0.3 * (1 - (-1)) * X(2) = 0.3*2*2 = 1.2; W(2) = W(2) + ▽W(2) = 1.2;
▽W(3) = 0.3 * (1 - (-1)) * X(3) = 0.3*2*3 = 1.8; W(3) = W(3) + ▽W(3) = 1.8;
更新之后的向量 w = [0.6, 1.2, 1.8] 然后接著繼續計算,更新。
閾值更新
前面提到,我們將閾值經過變換后變成了 w0,再每一輪的迭代訓練過程中,w0也需要跟著一起更新。
最初w0 也需要初始化為0,因為x0等于1,因此 ▽W(0) = η * ( y - y' ) ;
這里很多人可能會和我開始有一樣的疑惑,閾值不是提前定義好的嗎?其實不是的,這里不斷的迭代,其實就是閥值計算的過程,和權重向量一樣,最終都是通過一輪一輪更新計算出來的,由于一開始我們設定的w0 = - θ,所以當最終我們的閥值更新出來后,-w0 就是我們學習出來的閥值。
看到上面的過程是否有些暈,從整體上看,其實就是這樣一個過程:
初始化權重向量和閾值,然后計算預測結果和真實結果是否存在誤差,有誤差就根據結果不斷的更新權重,直到權重計算的結果最終達到最佳,權重的值就是我們學習出的規律。
感知器目前的適用場景為線性可分的場景,就是用一條直線可以分割的二分類問題。
用python實現了上述過程,可以看下:
#-*- coding:utf-8 -*- # 簡單神經網絡 感知器 import numpy as np reload(sys) sys.setdefaultencoding("utf-8") class Perception(object): ''' eta: 學習率 η time: 訓練次數 w_: 權重向量 ''' def __init__(self, eta = 0.01, time=10): self.eta = eta self.time = time pass ''' 輸入訓練數據,X為輸入樣本向量,y對應樣本分類 X:shape[n_samples, n_features] X:[[1,2,3], [4,5,6]] n_samples : 2 n_features: 3 y:[1, -1] ''' def fit(self, X, y): # 初始化權重向量為0,加一為w0,也就是損失函數的閾值 self.w_ = np.zero[1 + X.shape[1]] self.errors_ = [] for _ in range(self.time): errors = 0 # x:[[1,2,3], [4,5,6]] # y:[1, -1] # zip(X,y) = [[1,2,3,1], [4,5,6.-1]] for xi, target in zip(X, y): # update = η * ( y - y' ) update = self.eta * (target - self.predict(xi)) # xi 為向量, 這里每個向量都會乘 self.w_[1:] += update * xi self.w_[0] += update; errors += int(update != 0.0) pass # 損失函數 def predict(self, X): # z = w1*x1+...+wj*xj + w0*1 z = np.dot(X, self.w_[1:]) + self.w_[0] # 損失函數 if z >= 0.0: return 1 else: return -1

 浙公網安備 33010602011771號
浙公網安備 33010602011771號