
數據采集與融合技術實踐--作業四
數據采集與融合技術作業四
??1.相關信息及鏈接
| 名稱 | 信息及鏈接 |
|---|---|
| 學號姓名 | 102202108 王露潔 |
| 本次作業要求鏈接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13288 |
| 作業①所在碼云鏈接 | https://gitee.com/wanglujieeee/crawl_project/tree/master/作業4.1 |
| 作業②所在碼云鏈接 | https://gitee.com/wanglujieeee/crawl_project/tree/master/作業4.2 |
| 作業③所在碼云鏈接 | 無 |
??2.作業內容
作業①:
??要求:熟練掌握 Selenium 查找HTML元素、爬取Ajax網頁數據、等待HTML元素等內容。 使用Selenium框架+ MySQL數據庫存儲技術路線爬取“滬深A股”、“上證A股”、“深證A股”3個板塊的股票數據信息。 候選網站:東方財富網:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
???MySQL數據庫存儲和輸出格式如下: 表頭英文命名例如:序號id,股票代碼:bStockNo……,由同學們自行定義設計

??解決思路及代碼實現
第一步,打開終端,連接數據庫,切換到stock_data數據庫,創建stock_2表,這里忘記插入序號列,后面又補上了。
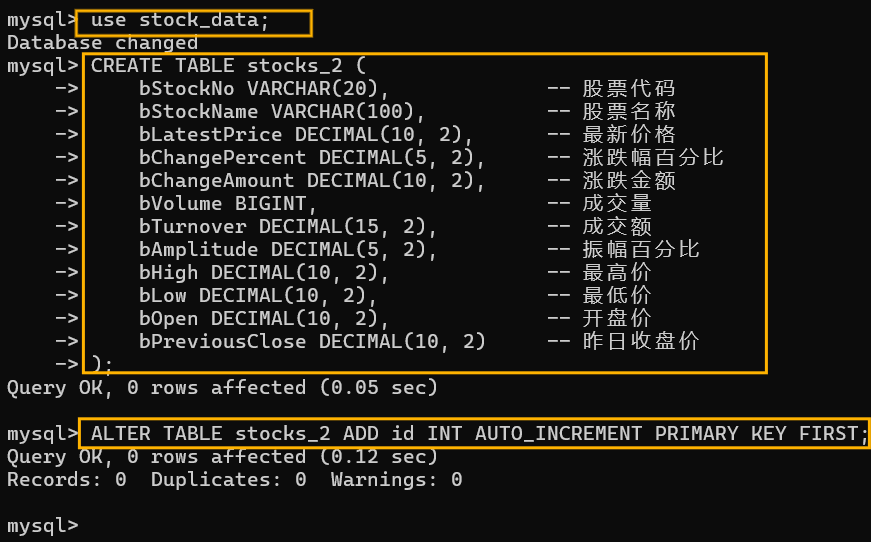
這里首先進行一些必要的庫的導入和數據庫的連接:
# 導入所需的庫
from selenium import webdriver # 用于網頁自動化控制的庫
from selenium.webdriver.common.by import By # 用于定位頁面元素的類
from selenium.webdriver.support.ui import WebDriverWait # 用于等待頁面元素加載的類
from selenium.webdriver.support import expected_conditions as EC # 用于等待頁面元素加載的條件
import mysql.connector # 用于連接MySQL數據庫的庫
import time # 用于時間處理的庫
# 數據庫連接設置
db_config = {
'user': 'root',
'password': '*********',#密碼保密
'host': 'localhost',
'database': 'stock_data'
}
下面是一個init_db()函數用于初始化數據庫連接,和一個insert_data()函數用于向數據庫插入數據:
# 初始化數據庫連接
def init_db():
conn = mysql.connector.connect(**db_config) # 創建數據庫連接
cursor = conn.cursor() # 創建游標對象
return conn, cursor # 返回連接對象和游標對象
# 插入數據到數據庫
def insert_data(cursor, conn, data):
sql = """
INSERT INTO stocks_2 (
bStockNo, bStockName, bLatestPrice, bChangePercent, bChangeAmount,
bVolume, bTurnover, bAmplitude, bHigh, bLow, bOpen, bPreviousClose
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, data) # 執行SQL插入語句
conn.commit() # 提交事務
接著是進行selelnium的配置:
# 配置 Selenium
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 設置無頭模式,不打開瀏覽器界面
driver = webdriver.Chrome(options=options) # 創建Chrome瀏覽器實例
wait = WebDriverWait(driver, 10) # 設置等待時間為10秒
這個clean_decimal()函數跟上次一樣,主要就是進行數據清洗,便于后續插入:
# 處理浮點數轉換的函數
def clean_decimal(value):
if not value:
return None
value = value.strip().replace(',', '') # 去除空格和逗號
try:
if '%' in value:
return float(value.replace('%', '')) / 100 # 處理百分比
elif '億' in value:
return float(value.replace('億', '')) * 1e8 # 處理億
elif '萬' in value:
return float(value.replace('萬', '')) * 1e4 # 處理萬
return float(value) # 直接轉換為浮點數
except ValueError:
return None # 轉換失敗返回None
下面是包含整個爬取數據的邏輯的函數scrape_data():
先創建了一個列表用于存儲數據;
使用顯示等待機制等待表格出現后使用xpath的方法定位到表格的所有行;
遍歷每一行,獲取每一行的每一個單元格并在清洗后賦值給相應的變量;
所有變量打包成一個元組,然后打印出來(可選),再插入到一開始創建的列表中;
最終返回一個數據列表,列表中包含該頁面整個表格的我們所選擇的數據。
# 爬取數據的函數
def scrape_data():
stock_data = [] # 初始化存儲數據的列表
# 等待表格加載并找到所有行
wait.until(EC.presence_of_element_located((By.XPATH, '//table//tr'))) # 等待表格出現
rows = driver.find_elements(By.XPATH, '//table//tr') # 獲取表格的所有行
for row in rows:
cols = row.find_elements(By.TAG_NAME, 'td') # 獲取每行的所有單元格
if len(cols) >= 14: # 如果單元格數量足夠
# 提取并清洗每個單元格的數據
bStockNo = cols[1].text.strip()
bStockName = cols[2].text.strip()
bLatestPrice = clean_decimal(cols[4].text.strip())
bChangePercent = clean_decimal(cols[5].text.strip())
bChangeAmount = clean_decimal(cols[6].text.strip())
bVolume = clean_decimal(cols[7].text.strip())
bTurnover = clean_decimal(cols[8].text.strip())
bAmplitude = clean_decimal(cols[9].text.strip())
bHigh = clean_decimal(cols[10].text.strip())
bLow = clean_decimal(cols[11].text.strip())
bOpen = clean_decimal(cols[12].text.strip())
bPreviousClose = clean_decimal(cols[13].text.strip())
# 將清洗后的數據打包成一個元組
stock_info = (
bStockNo, bStockName, bLatestPrice, bChangePercent, bChangeAmount,
bVolume, bTurnover, bAmplitude, bHigh, bLow, bOpen, bPreviousClose
)
# 打印每條數據
print(stock_info)
# 添加數據到列表中
stock_data.append(stock_info)
return stock_data # 返回數據列表
剛才的爬蟲函數一次只能爬取一個頁面的數據(即一個版塊的數據),而題目要求我們爬取三個板塊,這里就要用到下面的函數switch_section();
這個函數可以模擬點擊切換版塊;
首先用id來找到板塊的按鈕,再用click()方法進行模擬點擊;
最后強制等待頁面加載。
# 模擬點擊切換板塊
def switch_section(section_id):
section_tab = driver.find_element(By.ID, section_id) # 根據ID找到板塊切換按鈕
section_tab.click() # 點擊按鈕
time.sleep(3) # 等待頁面加載
下面的主函數main()展示了整個爬取和存儲過程:
用一個變量存儲所要爬取頁面的url;
用init_db()函數初始化數據庫并獲得數據庫連接和游標對象;
前面創建的Chrome瀏覽器實例driver使用get()方法訪問目標url;
首先爬取滬深A股板塊數據,調用scrape_data()函數即可返回一個包含所有行的數據的列表;
將數據一行一行插入到數據庫;
之后切換到上證A股板塊,使用的是switch_section()函數,切換成功后就可以按之前的方式爬取和存儲數據了,爬取深證A股板塊也是類似;
最后關閉游標,數據庫和瀏覽器實例。
# 主函數
def main():
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board" # 目標網頁URL
# 連接數據庫
conn, cursor = init_db() # 獲取數據庫連接和游標
try:
# 打開網頁
driver.get(url) # 訪問目標網頁
# 爬取滬深A股板塊數據
print("開始爬取滬深A股板塊數據...")
hs_data = scrape_data() # 爬取數據
for stock in hs_data:
insert_data(cursor, conn, stock) # 將數據插入數據庫
print("滬深A股數據爬取并存儲成功!")
# 切換到上證A股板塊并爬取數據
print("切換到上證A股板塊...")
switch_section("nav_sh_a_board") # 切換到上證A股
sz_data = scrape_data() # 爬取數據
for stock in sz_data:
insert_data(cursor, conn, stock) # 將數據插入數據庫
print("上證A股數據爬取并存儲成功!")
# 切換到深證A股板塊并爬取數據
print("切換到深證A股板塊...")
switch_section("nav_sz_a_board") # 切換到深證A股
zx_data = scrape_data() # 爬取數據
for stock in zx_data:
insert_data(cursor, conn, stock) # 將數據插入數據庫
print("深證A股數據爬取并存儲成功!")
except Exception as e:
print("爬取失敗:", e) # 捕獲異常并打印
finally:
cursor.close() # 關閉游標
conn.close() # 關閉數據庫連接
driver.quit() # 關閉瀏覽器實例
if __name__ == "__main__":
main() # 運行主函數
??運行結果截圖
這是控制臺的輸出(只截了一張):

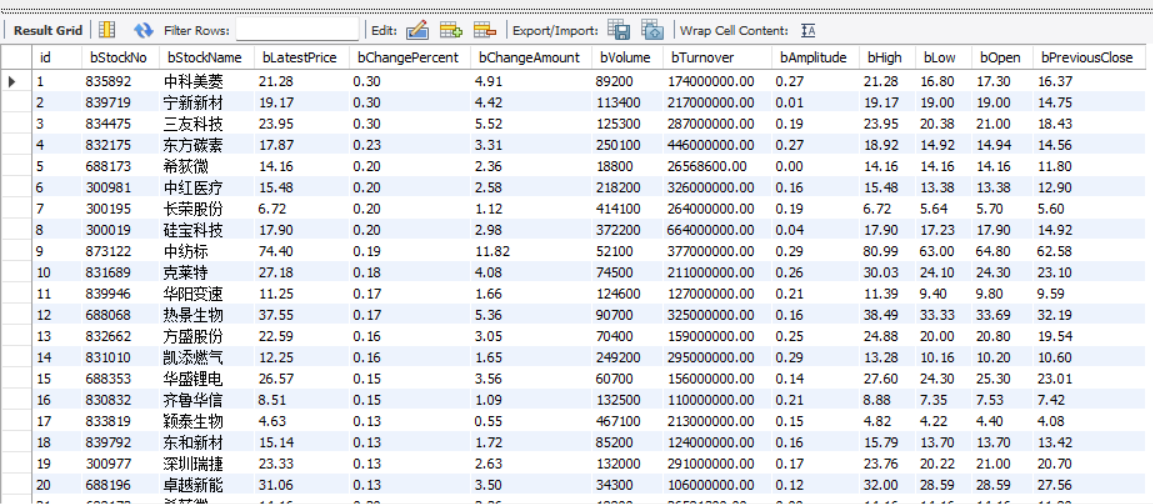
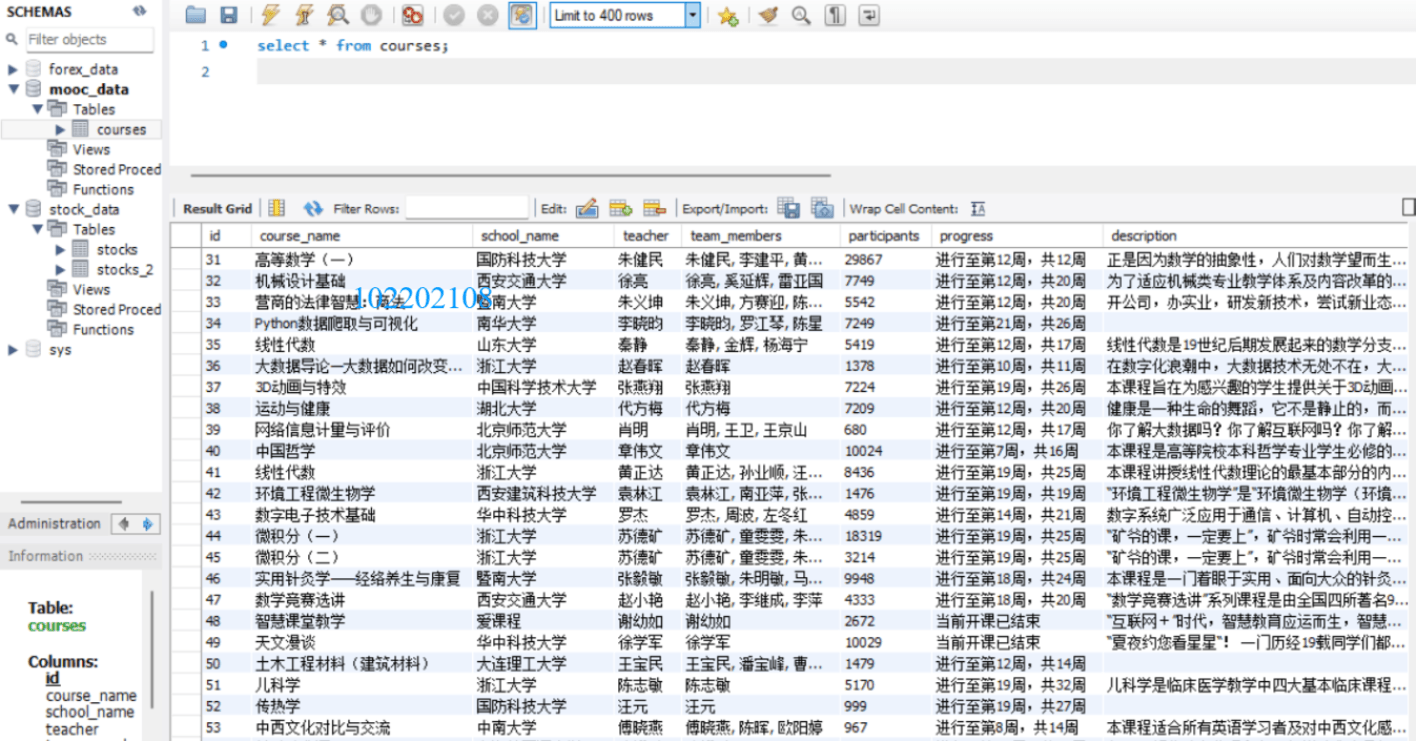
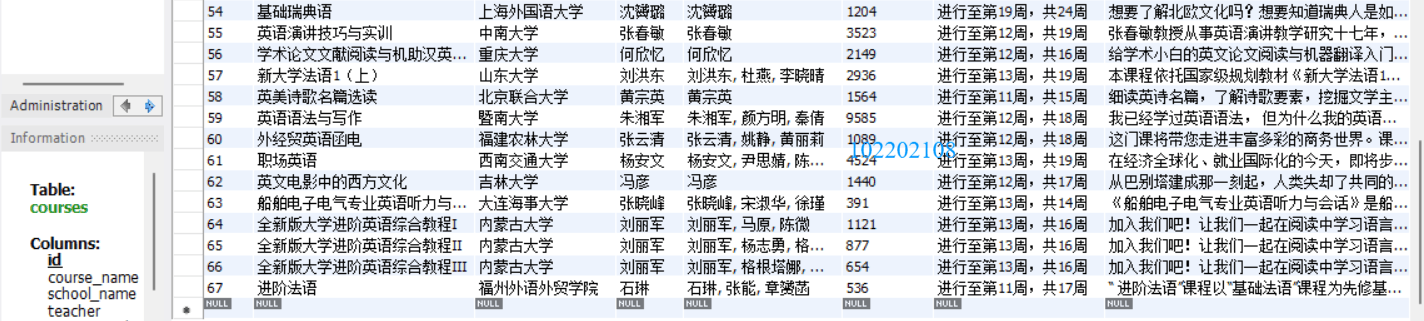
這是插入到數據庫的數據:
滬深A股:
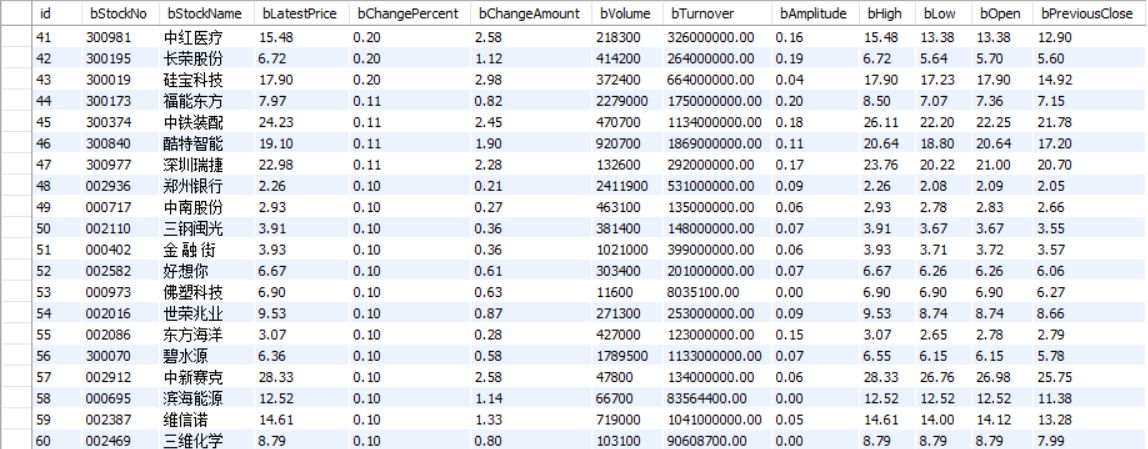
上證A股:

深證A股:
??心得體會
-->這個題目上次也有做,只不過上次是使用了selenium+scrapy框架的方式,我覺得這次會比上次稍微簡單一些。不同的地方是這里需要進行切換版塊然后爬取不同板塊的數據,解決方法就是找到頁面中版塊的位置進行模擬點擊的操作來進行板塊的切換,重點是點擊之后要添加等待機制,不然就會在頁面加載不全的時候就開始爬取數據,這樣當然會爬取失敗。我就是因為網絡太慢,一直超時,一直爬取不成功,然后就不停增加等待的時間,最后才爬取成功。而且我發現相同的代碼每次運行結果可能會成功也可能會失敗,只能說影響爬蟲結果的因素太多了。
作業②:
??要求:熟練掌握 Selenium 查找HTML元素、實現用戶模擬登錄、爬取Ajax網頁數據、等待HTML元素等內容。 使用Selenium框架+MySQL爬取中國mooc網課程資源信息(課程號、課程名稱、學校名稱、主講教師、團隊成員、參加人數、課程進度、課程簡介)。 候選網站:中國mooc網:https://www.icourse163.org
???MySQL數據庫存儲和輸出格式如下: MYSQL數據庫存儲和輸出格式 Gitee文件夾鏈接

??解決思路及代碼實現
下面僅展示一些重要的函數代碼:
首先是進行數據庫連接和創建表格,這也是比較常規的一個操作了;
# MySQL 配置
db_config = {
'user': 'root',
'password': 'Wlj98192188?',
'host': 'localhost',
'database': 'mooc_data'
}
# 初始化數據庫連接
def init_db():
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()
# 創建表格
cursor.execute("""
CREATE TABLE IF NOT EXISTS courses (
id INT AUTO_INCREMENT PRIMARY KEY,
course_name VARCHAR(255),
school_name VARCHAR(255),
teacher VARCHAR(255),
team_members TEXT,
participants INT,
progress VARCHAR(50),
description TEXT
)
""")
conn.commit()
return conn, cursor
下面是一個具有插入數據功能的函數insert_data():
只有一個要注意的點就是團隊成員是一個列表,不能直接插入到sql表格中,所以這里需要多加一個把列表轉換成字符串的步驟;
# 插入數據到數據庫
def insert_data(cursor, conn, data):
sql = """
INSERT INTO courses (
course_name, school_name, teacher, team_members,
participants, progress, description
) VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
try:
# 將團隊成員列表轉換為字符串
data = list(data)
if isinstance(data[3], list): # 檢查 team_members 是否為列表
data[3] = ', '.join(data[3]) # 使用逗號將成員名拼接成字符串
# 插入數據
cursor.execute(sql, tuple(data))
conn.commit()
print("成功插入一條數據")
except Exception as e:
conn.rollback()
print(f"插入數據失敗: {e}")
配置selenium(可能加了很多有的沒的):
# 配置 Selenium
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 無頭模式
driver = webdriver.Chrome(options=options)
wait = WebDriverWait(driver, 40)
driver.set_page_load_timeout(120) # 設置頁面加載超時時間
options.add_argument('--disable-gpu') # 禁用 GPU 加速
options.add_argument('--no-sandbox') # 禁用沙盒模式
options.add_argument('--disable-dev-shm-usage') # 禁用共享內存
options.add_argument('--disable-extensions') # 禁用擴展
下面這是一個模擬用戶登錄的函數login():
首先driver對象訪問界面的url,使用瀏覽器開發者工具找到登錄按鈕所在的標簽位置,然后進行點擊操作;
點擊登錄之后,會跳出一個登錄框,我們要在這個登錄框上定位到手機號和密碼的輸入框,然后使用send_keys()方法模擬輸入;
結果你會發現不管怎樣都定位不到輸入框,那是因為登錄框在該網頁的內嵌框架(iframe)里,我們需要切換到這個iframe內部才能與其中的元素進行交互,這里使用switch_to.frame()的方式;
輸入信息之后點擊登錄按鈕,我們將 WebDriver 的焦點從當前活動的 iframe 切換回最外層的文檔,以重新獲得對主文檔的訪問權限,這里使用switch_to.default_content();
最后注意這里每進行一步,都要模擬等待,因為頁面跳轉,加載等等都需要時間,搞不好就會出錯。
我這里還使用 driver.maximize_window() 方法將瀏覽器窗口最大化,以便能夠完整地看到頁面上的所有元素。
# 模擬登錄
def login():
url="https://www.icourse163.org"
driver.get(url)
login = driver.find_element(By.CLASS_NAME, "_3uWA6") # 查找登錄按鈕
login.click() # 點擊登錄按鈕
log=driver.find_element(By.TAG_NAME,"iframe")
driver.switch_to.frame(log) # 切換到登錄框
WebDriverWait(driver, 15, 0.5).until(
EC.presence_of_element_located((By.XPATH, "http://*[@id='login-form']/div"))) # 等待登錄框加載
username = driver.find_element(By.XPATH, "http://input[@id='phoneipt']")
username.send_keys("18120958838") # 輸入用戶名
time.sleep(2)
password = driver.find_element(By.XPATH, "http://input[@type='password' and @name='email' and contains(@class, 'j-inputtext')]")
password.send_keys("wlj98192188") # 輸入密碼
time.sleep(2)
button = driver.find_element(By.XPATH, "http://*[@id='submitBtn']")
button.click() # 點擊登錄按鈕
time.sleep(2)
driver.switch_to.default_content()
time.sleep(5)
driver.maximize_window()
time.sleep(3)
print("登錄成功,準備爬取課程信息...")
接著是爬取課程列表的一個主要的函數scrape_courses(),因為一開始出了很多錯誤,所有我加了很多打印語句用來調試,由于比較長,我把它分成了兩個部分來分析:
這個部分的大致功能就是模擬滑動條的滾動,來找到課程列表所在的位置(因為該頁面內容很多,只有向下滑動之后才能看到課程列表,也是只有列表可見之后才方便我們進行操作);
前面先是初始化數據庫,因為后面我是采用邊爬取數據邊存儲的方式進行的;
然后創建一個存儲課程數據的列表;
緊接著定義一些常量:每次滾動后的等待時間,最大滾動次數和滾動嘗試次數,方便后面直接使用;
用一個循環來完成一次次的滑動,只要滾動次數不超過最大次數,就會一直執行;
檢查目標元素(這是課程列表)是否加載到頁面,如果已經定位到,就執行:driver.execute_script("arguments[0].scrollIntoView(true);", target_element)滾動到目標元素;
這里execute_script 是 WebDriver 提供的一個方法,用于在當前頁面上執行任意的 JavaScript 代碼;
arguments[0].scrollIntoView(true) 是要執行的 JavaScript 代碼字符串。這里,arguments[0] 是傳遞給 execute_script 方法的第一個參數(在這個例子中是 target_element),它代表頁面上的一個元素。scrollIntoView 是該元素的一個方法,用于將該元素滾動到瀏覽器的可視區域內。true 參數表示在滾動時,如果元素不在視圖中,則盡可能平滑地滾動,并嘗試將元素的頂部與其最近的滾動祖先的可視區域的頂部對齊。
如果目標元素尚未加載,則繼續滾動,使用execute_script("window.scrollBy(0, 800);"),每次向下滾動 800 像素;
最后滾動次數達到上限就會退出這個循環。
# 爬取課程列表并進入每個課程的詳情頁
def scrape_courses():
# 初始化數據庫
conn, cursor = init_db()
print("開始!")
course_data_list = []
scroll_pause_time = 1 # 每次滾動后的等待時間
max_scroll_attempts = 50 # 最大滾動次數,防止無限循環
scroll_attempts = 0
while scroll_attempts < max_scroll_attempts:
try:
# 檢查目標元素是否加載到頁面
target_element = driver.find_element(By.XPATH, "http://div[@class='_15K5J']")
print("已經定位到目標元素")
# 滾動到目標元素
driver.execute_script("arguments[0].scrollIntoView(true);", target_element)
print("已經滾動到目標元素")
time.sleep(2) # 等待加載
break
except Exception:
# 如果目標元素尚未加載,則繼續滾動
driver.execute_script("window.scrollBy(0, 800);") # 每次向下滾動 800 像素
time.sleep(scroll_pause_time)
# 增加滾動嘗試次數
scroll_attempts += 1
print(f"滾動嘗試次數:{scroll_attempts}")
# 如果滾動嘗試達到最大次數,退出并報告
if scroll_attempts >= max_scroll_attempts:
print("已滾動多次仍未找到目標元素,退出")
這是函數的后半部分,主要作用就是進行每個課程詳情數據的爬取,其中調用了后面寫的一個函數scrape_course_details(driver)來進行具體數據的爬取;
首先就是定位到該頁面所有的課程并存儲成一個列表,然后對列表的每一個元素進行遍歷:同樣這里先滾動滑動條到可視區,再進行點擊;
由于點擊之后會打開一個新的窗口或標簽頁,所以我們需要確保這個新窗口或標簽頁確實已經打開,然后再進行下一步操作,這里用EC.number_of_windows_to_be(2)是等待打開的窗口數量達到2個;
這時我們使用driver.switch_to.window() 方法切換瀏覽器窗口,類似于登錄那邊用到的switch_to.frame()方法切換網頁的內外層框架,這里是切換標簽頁;
其參數driver.window_handles 是一個屬性,它返回當前會話中所有打開的窗口(或標簽頁)的句柄列表,因為Python中的列表索引是從0開始的,而 -1 表示列表中的最后一個元素。因此,driver.window_handles[-1] 將返回最近打開的窗口的句柄。
切換到課程詳情頁,調用scrape_course_details()函數,該函數會返回所爬取的課程數據,如果非空,就使用insert_data()函數將其插入到數據庫表格中;
每爬取完一門課程,就要關閉該課程詳情頁,再退回到課程列表。driver.close() 方法用于關閉當前活動的瀏覽器窗口(或標簽頁),這不會關閉整個瀏覽器應用程序,只是關閉當前正在與之交互的窗口。而需要注意區分driver.quit() 方法用于關閉所有與當前WebDriver會話相關聯的窗口,并結束WebDriver進程。
返回課程主頁就用switch_to.window(driver.window_handles[0]),索引為0表示第一個標簽頁;
頁面切換仍然要進行等待,為了以防萬一再重新獲取課程列表,就這樣遍歷完所有課程卡片。
# 找到課程卡片
course_cards = wait.until(EC.presence_of_all_elements_located((By.XPATH, "http://div[@class='_2mbYw commonCourseCardItem']")))
print("已經找到多張課程卡片")
for i, card in enumerate(course_cards):
try:
# 將課程滾動到可視區域并點擊
driver.execute_script("arguments[0].scrollIntoView();", card)
time.sleep(2)
card.click()
# 等待新窗口/標簽頁打開
WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(2))
driver.switch_to.window(driver.window_handles[-1])
print("已切換到課程詳情頁。")
# 點擊課程卡片進入詳情
time.sleep(10) # 等待頁面加載
# 解析課程詳情數據
course_data = scrape_course_details(driver)
if course_data:
# 插入數據到數據庫
insert_data(cursor, conn, (
course_data['course_name'],
course_data['school_name'],
course_data['teacher'],
course_data['team_members'],
course_data['participants'],
course_data['progress'],
course_data['description']
))
print("已成功存儲一條數據!")
# 關閉詳情頁并返回主頁面
driver.close()
driver.switch_to.window(driver.window_handles[0])
print("已返回主課程頁面。")
time.sleep(5) # 等待頁面加載
# 重新獲取課程列表
course_cards = wait.until(EC.presence_of_all_elements_located((By.XPATH, "http://div[@class='_2mbYw commonCourseCardItem']")))
except StaleElementReferenceException:
print("捕獲到 StaleElementReferenceException,重新加載課程列表")
if len(driver.window_handles) > 1:
driver.close()
driver.switch_to.window(driver.window_handles[0])
return course_data_list
下面就是具體的爬取課程數據的細節函數scrape_course_details(driver),也是比較長,其中也包括了頁面滾動操作(因為教師和團隊信息在頁面下方,只有滾動之后才能可視和爬取);
我設了多重等待機制,因為有時候頁面加載完成但是課程詳情可能還沒能完全加載,也容易讓我們爬取失敗;
后面是使用XPATH的方法來獲取課程名,學校名,參與人數,課程進度,課程簡介;進行頁面滾動后再來獲取教師名,團隊成員;
所有的標簽都是要打開瀏覽器開發者工具進行查看和分析的,最后返回課程數據;
這里主要就是要注意團隊成員的元素是多個值,需要提取每個團隊成員的名字形成一個列表,再返回;
def scrape_course_details(driver):
try:
# 確保頁面完全加載
WebDriverWait(driver, 30).until(
lambda d: d.execute_script('return document.readyState') == 'complete'
)
print("頁面完全加載完成")
# 等待課程詳情部分加載
WebDriverWait(driver, 30).until(
EC.visibility_of_element_located((By.XPATH, "http://div[@id='g-body']"))
)
print("課程詳情加載完成")
# 1. 獲取課程名
try:
course_name_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.XPATH, "http://span[@class='course-title f-ib f-vam']")
))
course_name = course_name_element.text
except TimeoutException:
course_name = "未知課程"
print(f"課程名: {course_name}")
# 2. 獲取學校名
try:
school_name = driver.find_element(By.XPATH,"http://div[@class='m-teachers']//a[@class='ga-click m-teachers_school-img f-ib']/img").get_attribute("alt")
except Exception:
school_name = "未知學校"
print(f"學校名: {school_name}")
# 3. 獲取參與人數
try:
participants_element = driver.find_element(By.XPATH, "http://span[@class='count']")
participants_text = participants_element.text if participants_element else "0"
participants = int("".join(filter(str.isdigit, participants_text)))
except Exception:
participants = 0
print(f"參與人數: {participants}")
# 4. 獲取課程進度
try:
progress_element = driver.find_element(By.XPATH, "http://span[@class='text']")
progress = progress_element.text if progress_element else "未知進度"
except Exception:
progress = "未知進度"
print(f"課程進度: {progress}")
# 5. 獲取課程簡介
try:
description_element = driver.find_element(By.XPATH, "http://div[@class='course-heading-intro_intro']")
description = description_element.text if description_element else "暫無簡介"
except Exception:
description = "暫無簡介"
print(f"課程簡介: {description}")
# 滾動查找目標元素
scroll_attempts = 0
max_scroll_attempts = 10 # 最大滾動次數
scroll_pause_time = 2 # 每次滾動后的等待時間
while scroll_attempts < max_scroll_attempts:
try:
# 嘗試查找目標元素
target_element = driver.find_element(By.XPATH, "http://div[@class='m-teachers_teacher-list']")
print("找到教師信息元素!")
# 滾動到目標元素
driver.execute_script("arguments[0].scrollIntoView(true);", target_element)
print("已經滾動到教師信息位置")
time.sleep(scroll_pause_time) # 等待頁面加載
break # 找到目標元素后退出循環
except Exception:
# 如果未找到目標元素,則向下滾動頁面
driver.execute_script("window.scrollBy(0, 800);") # 每次向下滾動 800 像素
print(f"未找到目標元素,嘗試向下滾動... 第 {scroll_attempts + 1} 次")
time.sleep(scroll_pause_time) # 等待頁面內容加載
scroll_attempts += 1 # 增加滾動次數
# 如果達到最大滾動次數
if scroll_attempts >= max_scroll_attempts:
print("滾動達到最大次數,未找到目標元素")
# 6. 獲取教師名
try:
teacher = driver.find_element(By.XPATH, "http://div[@class='m-teachers_teacher-list']//h3[@class='f-fc3']").text
except Exception:
teacher = "未知教師"
print(f"教師名: {teacher}")
# 7. 獲取團隊成員
try:
# 獲取團隊成員的元素列表
team_member_elements = driver.find_elements(By.XPATH,"http://div[@class='m-teachers_teacher-list']//h3[@class='f-fc3']")
# 提取每個團隊成員的名字
team_members = [member.text for member in team_member_elements]
# 如果列表為空,則沒有找到團隊成員
if not team_members:
team_members = "暫無團隊成員"
except Exception:
team_members = "暫無團隊成員"
print(f"團隊成員: {team_members}")
# 返回課程數據
course_data = {
"course_name": course_name,
"school_name": school_name,
"teacher": teacher,
"team_members": team_members,
"participants": participants,
"progress": progress,
"description": description,
}
print("課程數據:", course_data)
return course_data
except TimeoutException as e:
print(f"加載課程詳情失敗: 頁面加載超時,異常信息: {str(e)}")
return None
except Exception as e:
print(f"加載課程詳情時發生未知錯誤: {str(e)}")
return None
最后是主函數,由于前面的函數很復雜,所以這個主函數結構就比較簡單了;
初始化數據庫,登錄,爬取課程信息,最后關閉游標對象,數據庫連接和瀏覽器驅動。
def main():
# 初始化數據庫
conn, cursor = init_db()
login() # 登錄
try:
# 抓取課程信息并插入數據庫
print("開始爬取課程信息...")
scrape_courses()
print("數據存儲成功!")
except Exception as e:
print("爬取失敗:", e)
finally:
cursor.close()
conn.close()
driver.quit()
if __name__ == "__main__":
main()
??運行結果截圖
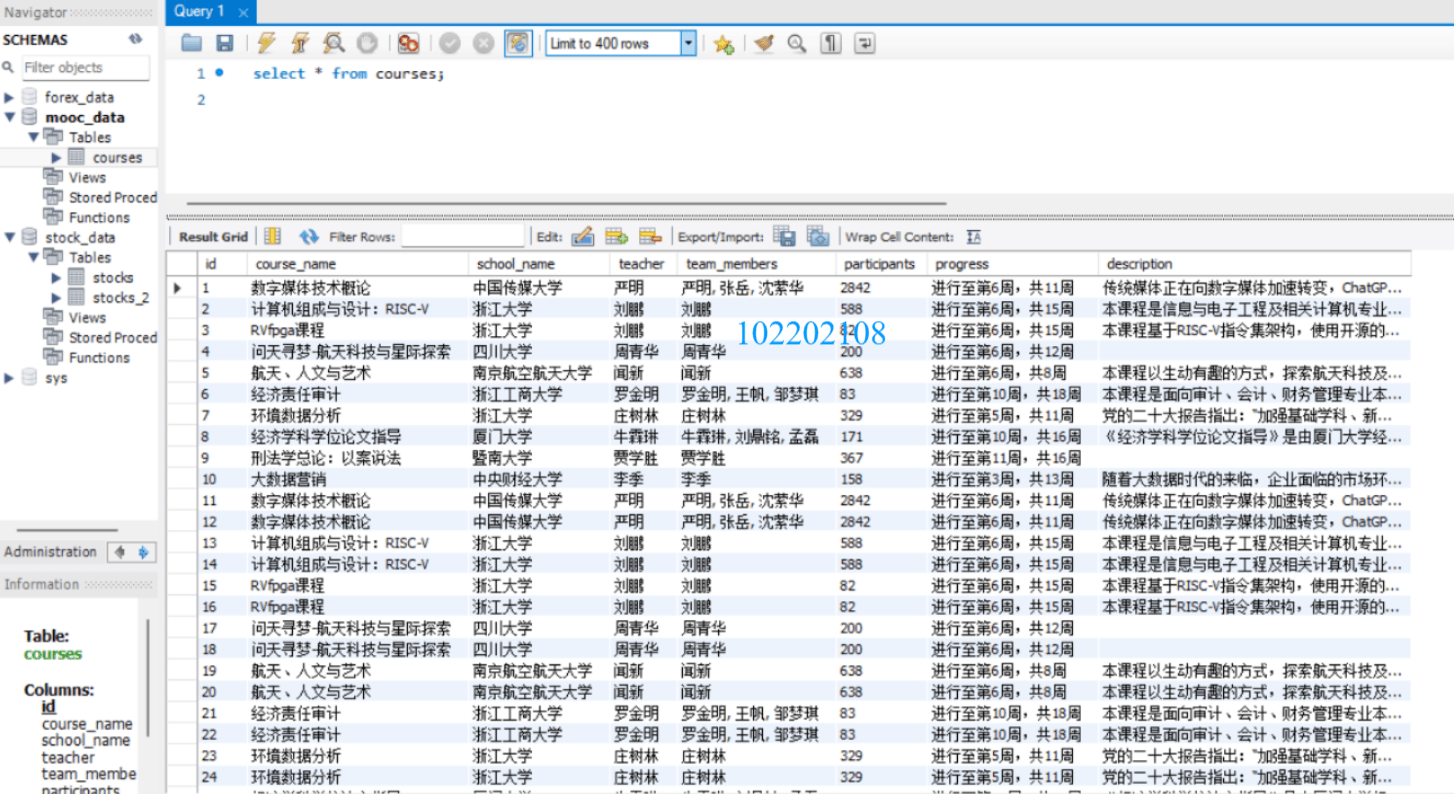
先是在控制臺的輸出信息(只截取一張),包含很多用于調試的語句,不用管它們:

再是在mysql數據庫中的數據:
??心得體會
-->別的不說,我在這道題上的感受頗多,因為真的花了很多時間,并且學到了很多東西。都快不知道該從哪里說起了,我大概花了三天(不加實踐課那天)。
-->第一天我盯著那看似“完美”的代碼(實則漏洞百出),一遍遍問gpt然后反復修改,結果啥也不是。我就取消了“無頭模式”,想看看到底怎么個事,只見它先是跳出谷歌瀏覽器的界面,緩慢地加載著慕課網站的信息,突然彈出一個登錄框,看來它已經成功找到了登錄按鈕并進行了點擊,正當我期待它繼續往下進行(找到手機號和密碼的輸入框并填入相關信息)的時候----它,不動了。我以為是網絡的問題,想著多等一會兒吧,此時我還抱著一絲期待,可最終等到的卻是頁面無情的閃退,只留下在原地愣住的我一個人。萬萬沒想到,我的代碼連登錄的關都沒過,那就不用談什么課程信息的爬取了,前面我還一直在觀察原html代碼,為的是更精準地定位到各個數據,現在看來有點多次一舉,畢竟連課程的封面都沒有見到。(……此處省略一萬字,畢竟找到真理的過程是很漫長的)那我最終是怎么發現問題出在哪里,又是怎么解決的呢?這也是我在此次作業中學到的第一個東西----網頁中的內嵌框架。
-->這是我第一次知道網頁中是包含iframe(內嵌框架)的,所以上面就是一直把瀏覽器的焦點定位在最外層的文檔,導致找不到手機號和密碼的輸入框。只有切換到這個iframe內部才能與其中的元素進行交互。好了現在發現問題了,那怎么解決呢?只需要現成的driver.switch_to.frame(frame_reference)這個方法,它可以直接切換瀏覽器焦點到某個iframe,那到底是哪個咧,只需將參數傳給它,frame_reference是iframe的引用,可以是通過各種定位策略得到的元素對象,也可以是iframe的索引。進行完這一步,就能成功找到輸入框和點擊“立即登錄”的按鈕了。不過還有,立即登錄后,登錄框會消失,一開始的主界面就會又出現在我們的面前,那就意味著我們現在必須讓瀏覽器的焦點回到這個主文檔上,以重新獲取訪問權限。driver.switch_to.default_content() 方法正是用于這個目的,直接使用即可,非常方便。總之一句話:“如果嘗試在沒有先切換到 iframe 的情況下與 iframe 內部的元素交互,或者在沒有切換回主文檔的情況下嘗試與主文檔中的元素交互,Selenium 將無法找到這些元素,并可能拋出 NoSuchElementException 異常。”
-->就這樣一天只解決了登錄的問題,登錄成功之后,我也并沒有爬取到想要的數據,這才有了下文。
-->好了,已經到第二天了,此時我突破了登錄大關,開始瞄準課程列表。我反復比對我的XPATH路徑和網頁實際的html文檔,但是似乎怎么都定位不到它,于是我又換了很多別的方法By.ID, By.CLASS_NAME等等,似乎都沒起作用。我又反復問gpt,它給我出了很多主意和修改方式,每次都信誓旦旦地跟我說 “這樣就能解決了。” “這次肯定能爬取到想要的數據了。”但是都沒有解決,我幾乎都快跟AI吵起來了,沒辦法,AI的確懂很多東西,但它不懂我的心,而我越是急越是沒法描述清楚,越是描述不清楚越是急。最終,我選擇放棄與它溝通,默默地點開了其他同學的博客(這通常都是沒有辦法的辦法),想看看到底問題出在哪里,翻閱數篇博客之后,我找到了問題所在,這是我這次作業學到的第二個東西----Selenium模擬頁面滾動。
-->在自動化測試或爬蟲任務中,模擬滾動頁面是一個常見的需求,沒辦法呀,我就是沒見過呀,不過現在我知道了,如果想要爬取的數據在視圖中不可見,那它即使存在于該界面之中,也是無法定位到的。那如何執行頁面的滾動,就是用類似于driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")的語句,execute_script()是允許driver執行JavaScript語句的方法,括號內放想要執行的JavaScript語句,這里就是"window.scrollTo(0, document.body.scrollHeight);",作用是將頁面滾動到底部,當然我不是需要滑動到底部,而是滑動到特定元素的位置。所以我就用了一個循環,每次先檢查要找的元素有沒有出現,如果沒有,就向下滑動固定的長度,再次檢查元素是否出現,直到找到元素或是滑動次數達到最大(這是我自己設置的,防止陷入死循環)。還有一個這次沒有用到但是也值得注意的點:如果頁面包含滾動條(比如在某個
-->hahaha!又是新的一天,直接進入正題:我明明點擊了課程封面,怎么結果感覺像是沒進去一樣呢,因為一條信息都沒爬到,我就在進行點擊操作的代碼下方加了一條測試語句來打印出進行點擊操作之后的html的內容,看看是不是我對元素的定位出現了問題。打印出的html代碼很長,我就慢慢在那里翻,越看越不對勁……最終恍然大悟:不對!這不是主頁的html文檔嗎?這里哪來的課程詳情的信息?難怪啥也爬不到!原來真的是沒進去呀!看來之前的懷疑是對的。我就很疑惑,以為是點擊沒有生效,又去問了gpt(我們和好了),來來回回折騰的很多次發現,點擊的確是沒錯的,錯的是其他的地方。這里點擊課程封面之后,它不是在原有的頁面上刷新內容,而是重新開了一個窗口,這我雖然是知道的,但我不知道的,也是本次作業學到的第三樣東西----driver在不同的瀏覽器窗口或標簽頁之間切換。
-->有了上面driver.switch_to.frame()做鋪墊,這個切換標簽頁也就不難理解了。其方式就用driver.switch_to.window() 方法,括號內是要傳入想要切換的窗口,通常用索引表示,driver.window_handles 會返回當前會話中所有打開的窗口(或標簽頁),索引從0開始,如果想切換到最近打開的窗口,就令索引等于-1即可。有打開就有關閉,driver.close() 方法用于關閉當前活動的瀏覽器窗口(或標簽頁),它不會關閉整個瀏覽器應用程序,只是關閉當前正在與之交互的窗口,這一點跟driver.quit()是不一樣的,需要特別注意。別忘了關閉標簽頁后,還要將driver切換到第一個主界面的窗口,然后進行下一個課程的點擊。
-->其實做到上面這一步時還沒有結束,后面錯誤多著呢,只是大的問題大概就這三個,這樣看還真的是一場充滿刺激的冒險呢!我現在已經是筋疲力竭了,確實被這道題的彎彎繞繞給整的頭暈目眩了,不過呢,它也讓我學到了很多新東西。最后的最后,我只想說:我對Selenium一!無!所!知!
作業③:
??要求:掌握大數據相關服務,熟悉Xshell的使用 完成文檔 華為云_大數據實時分析處理實驗手冊-Flume日志采集實驗(部分)v2.docx 中的任務,即為下面5個任務,具體操作見文檔。 環境搭建: 任務一:開通MapReduce服務 實時分析開發實戰: 任務一:Python腳本生成測試數據 任務二:配置Kafka 任務三: 安裝Flume客戶端 任務四:配置Flume采集數據
???輸出:實驗關鍵步驟或結果截圖。
??關鍵步驟及結果截圖
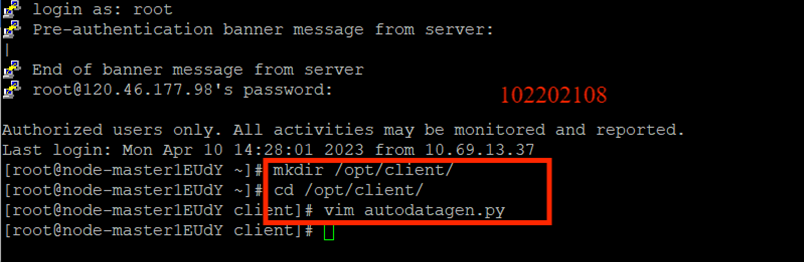
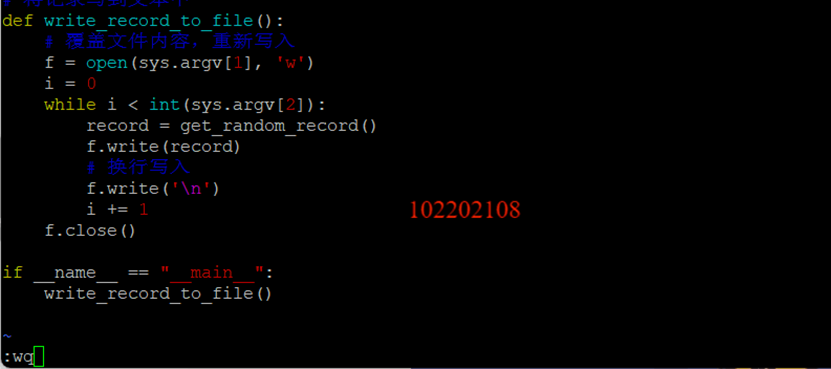
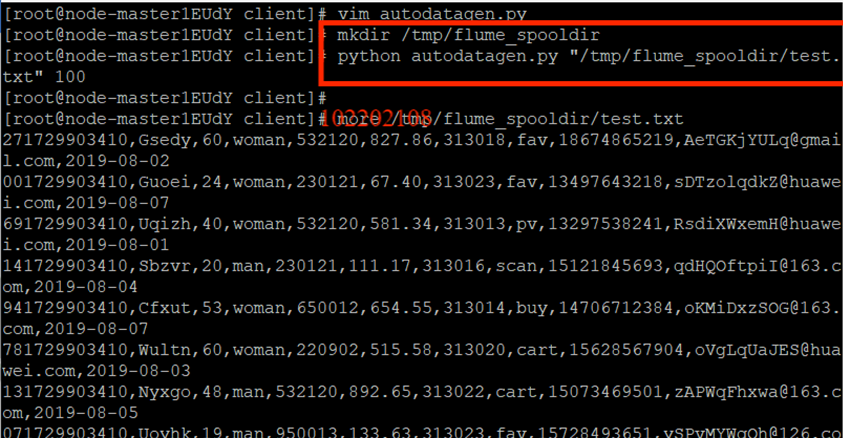
任務一:Python腳本生成測試數據
創建python腳本:
執行python腳本:
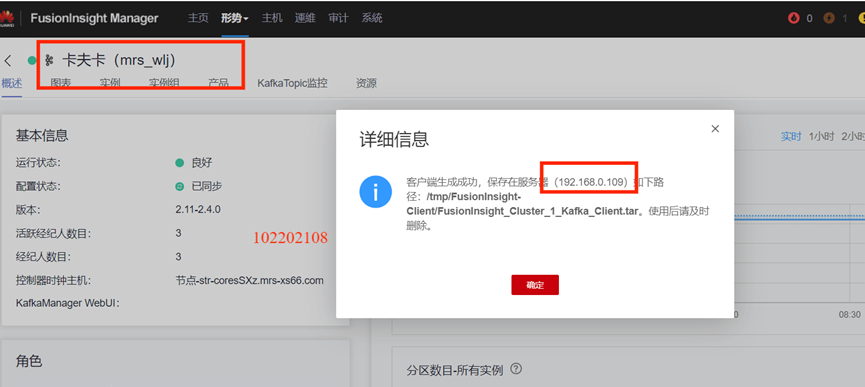
任務二:配置Kafka
下載安裝配置Kafka:
下載客戶端:
校驗下載的客戶端文件包:
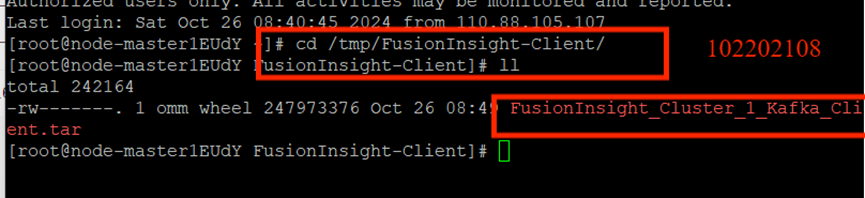
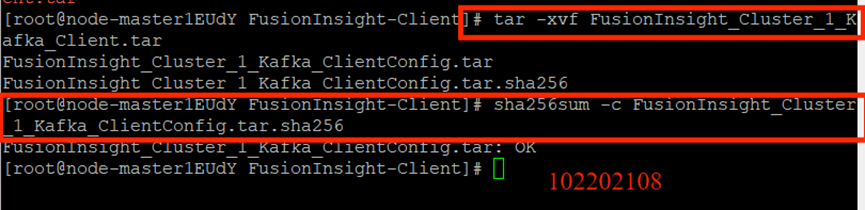
安裝Kafka運行環境:
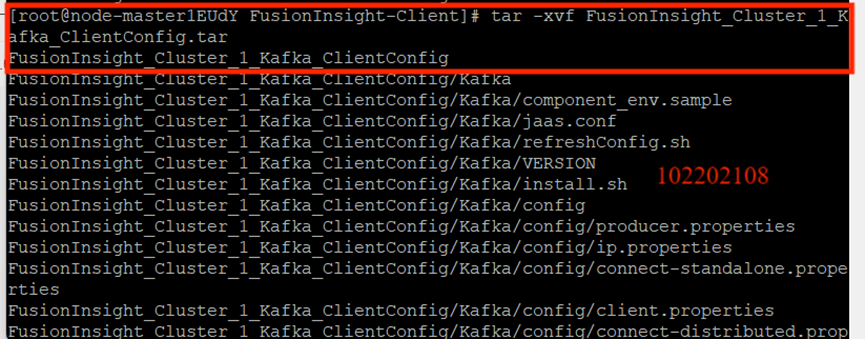
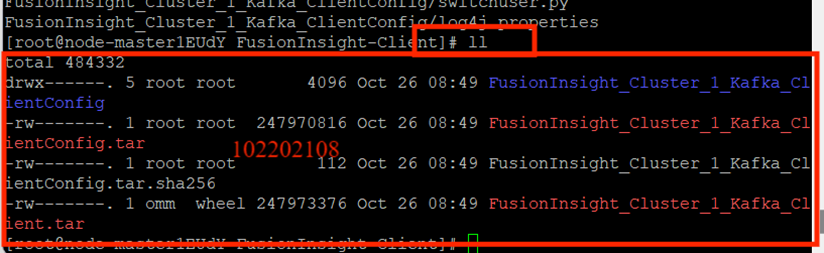
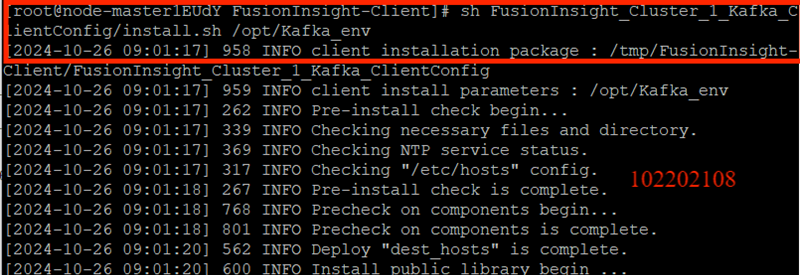
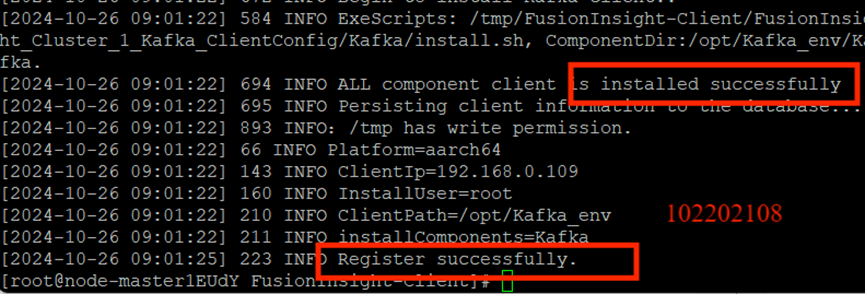

安裝Kafka客戶端:
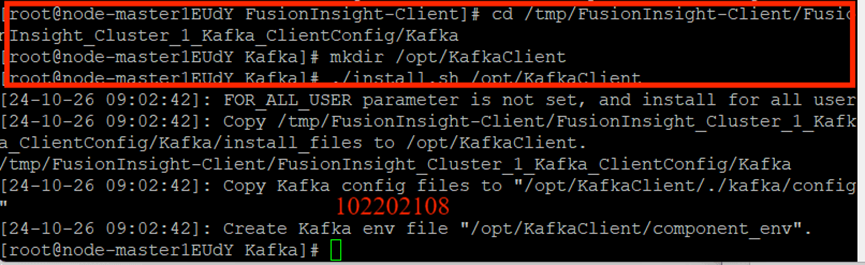
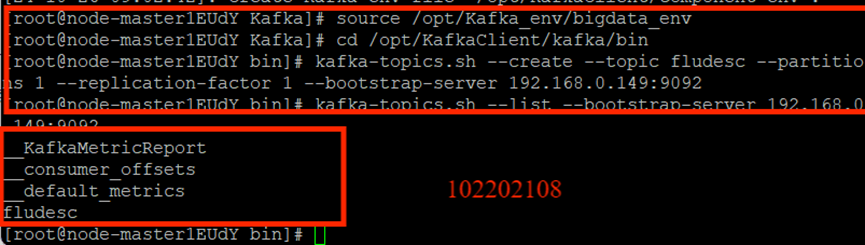
創建并查看topic:
任務三: 安裝Flume客戶端
下載客戶端文件包:

效驗文件包:


安裝Flume運行環境:
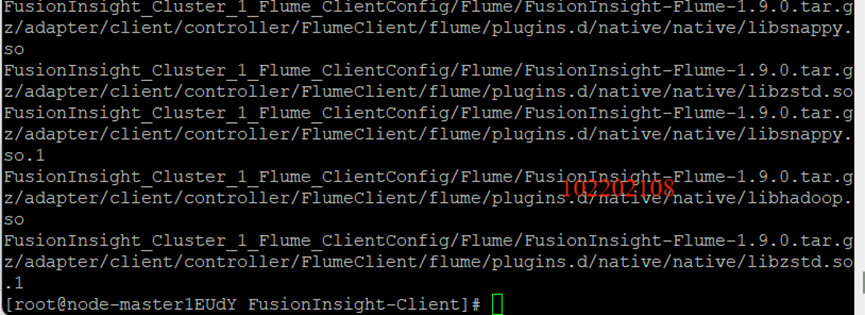
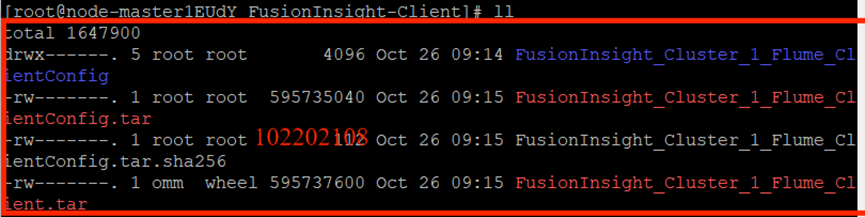
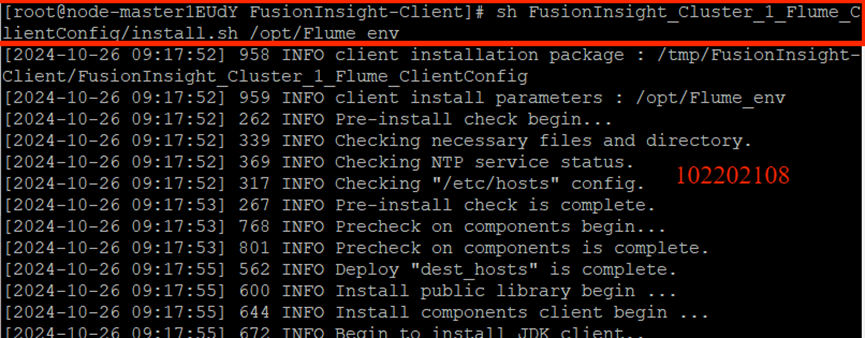


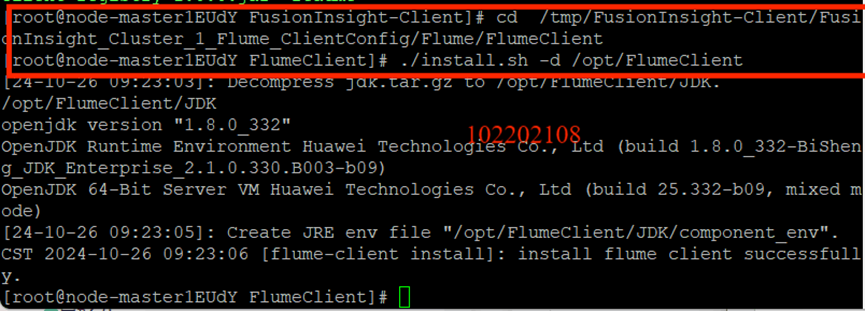
安裝Flume客戶端:
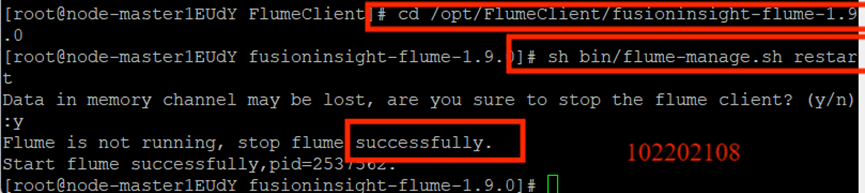
重啟Flume服務:
任務四:配置Flume采集數據
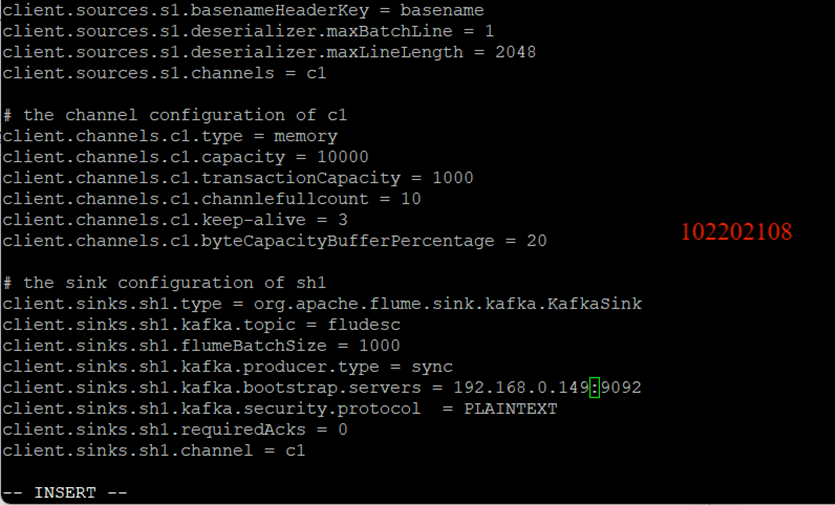
修改配置文件:
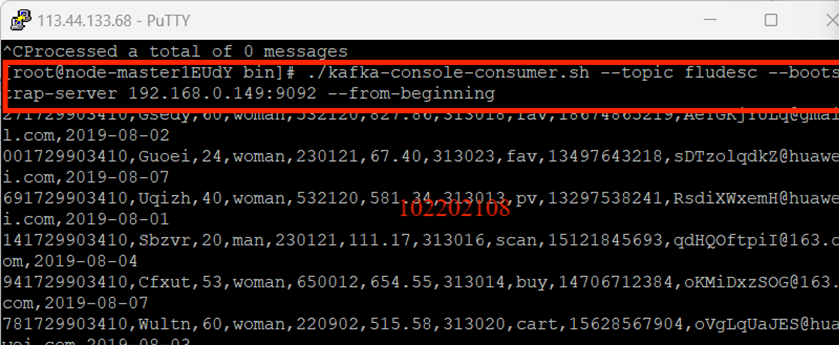
創建消費者消費數據:

??心得體會
這次實驗是我華為云平臺實驗做的最快的一次(只用了三個多小時),只不過后面刪除資源花了很長的時間(因為有些資源怎么都刪除不掉,只能聯系工程師)。這個實時數據分析實驗真的有點神奇,尤其是后面的大屏幕可視化的部分看起來很高級的樣子,我之前也有在學校的智慧食堂里看到類似實時數據分析的大屏幕,所以感覺這次的實驗的應用非常廣泛。只是我對很多地方的理解都不是很深,只是按照步驟一步一步做,最終得到了可視化的結果,但即使是這樣,也是bangbang的!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號