
Glusterfs之rpc模塊源碼分析(下)之RDMA over TCP的協(xié)議棧工作過(guò)程淺析
聲明:本文轉(zhuǎn)至IT168:因?yàn)镚lusterFS實(shí)現(xiàn)了IB網(wǎng)絡(luò)(RDMA協(xié)議,專用硬件網(wǎng)卡支持),當(dāng)時(shí)就在想普通的網(wǎng)卡能不能實(shí)現(xiàn),就找到一篇這樣的文章介紹,基于TCP協(xié)議來(lái)實(shí)現(xiàn)。!
附件 RDMA over TCP的協(xié)議棧工作過(guò)程淺析
第一節(jié) RDMA概述
隨著網(wǎng)絡(luò)帶寬和速度的發(fā)展和大數(shù)據(jù)量數(shù)據(jù)的遷移的需求,網(wǎng)絡(luò)帶寬增長(zhǎng)速度遠(yuǎn)遠(yuǎn)高于處理網(wǎng)絡(luò)流量時(shí)所必需的計(jì)算節(jié)點(diǎn)的能力和對(duì)內(nèi)存帶寬的需求,數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)已經(jīng)逐步成為計(jì)算和存儲(chǔ)技術(shù)的發(fā)展的瓶頸,迫切需要采用一種更高效的數(shù)據(jù)通訊架構(gòu)。
傳統(tǒng)的TCP/IP技術(shù)在數(shù)據(jù)包處理過(guò)程中,要經(jīng)過(guò)操作系統(tǒng)及其他軟件層,需要占用大量的服務(wù)器資源和內(nèi)存總線帶寬,所產(chǎn)生嚴(yán)重的延遲來(lái)自系統(tǒng)龐大的開(kāi)銷、數(shù)據(jù)在系統(tǒng)內(nèi)存、處理器緩存和網(wǎng)絡(luò)控制器緩存之間來(lái)回進(jìn)行復(fù)制移動(dòng),如圖1.1所示,給服務(wù)器的CPU和內(nèi)存造成了沉重負(fù)擔(dān)。特別是面對(duì)網(wǎng)絡(luò)帶寬、處理器速度與內(nèi)存帶寬三者的嚴(yán)重"不匹配性",更造成了網(wǎng)絡(luò)延遲效應(yīng)的加劇。處理器速度比內(nèi)存速度快得越多,等待相應(yīng)數(shù)據(jù)的延遲就越多。而且,處理每一數(shù)據(jù)包時(shí),數(shù)據(jù)必須在系統(tǒng)內(nèi)存、處理器緩存和網(wǎng)絡(luò)控制器緩存之間來(lái)回移動(dòng),因此延遲并不是一次性的,而是會(huì)對(duì)系統(tǒng)性能持續(xù)產(chǎn)生負(fù)面影響。
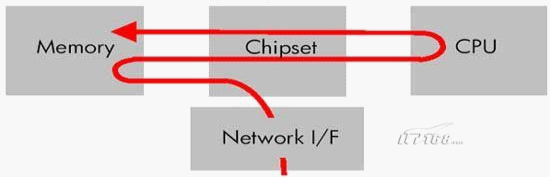
圖1.1 主機(jī)接收傳統(tǒng)以太網(wǎng)數(shù)據(jù)的典型數(shù)據(jù)流示意圖
這樣,以太網(wǎng)的低投入、低運(yùn)營(yíng)成本優(yōu)勢(shì)就難以體現(xiàn)。為充分發(fā)揮萬(wàn)兆位以太網(wǎng)的性能優(yōu)勢(shì),必須解決應(yīng)用性能問(wèn)題。系統(tǒng)不能以軟件方式持續(xù)處理以太網(wǎng)通信;主機(jī)CPU資源必須釋放專注于應(yīng)用處理。業(yè)界最初的解決方案是采用TCP/IP負(fù)荷減輕引擎(TOE)。TOE方案能提供系統(tǒng)性能,但協(xié)議處理不強(qiáng);它能使TCP通信更快速,但還達(dá)不到高性能網(wǎng)絡(luò)應(yīng)用的要求。解決這類問(wèn)題的關(guān)鍵,是要消除主機(jī)CPU中不必要的頻繁數(shù)據(jù)傳輸,減少系統(tǒng)間的信息延遲。
RDMA(Remote Direct Memory Access)全名是"遠(yuǎn)程直接數(shù)據(jù)存取",RDMA讓計(jì)算機(jī)可以直接存取其它計(jì)算機(jī)的內(nèi)存,而不需要經(jīng)過(guò)處理器耗時(shí)的傳輸,如圖1.2所示。RDMA是一種使一臺(tái)計(jì)算機(jī)可以直接將數(shù)據(jù)通過(guò)網(wǎng)絡(luò)傳送到另一臺(tái)計(jì)算機(jī)內(nèi)存中的特性,將數(shù)據(jù)從一個(gè)系統(tǒng)快速移動(dòng)到遠(yuǎn)程系統(tǒng)存儲(chǔ)器中,而不對(duì)操作系統(tǒng)造成任何影響,這項(xiàng)技術(shù)通過(guò)消除外部存儲(chǔ)器復(fù)制和文本交換操作,因而能騰出總線空間和CPU周期用于改進(jìn)應(yīng)用系統(tǒng)性能,從而減少對(duì)帶寬和處理器開(kāi)銷的需要,顯著降低了時(shí)延。
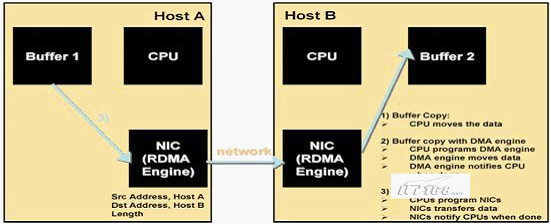
圖1.2 RDMA數(shù)據(jù)流傳輸示意圖
RDMA對(duì)以太網(wǎng)來(lái)說(shuō)還是"新生事物",但以不同形式存在已有十多年時(shí)間,它是Infiniband技術(shù)的基礎(chǔ)。產(chǎn)業(yè)標(biāo)準(zhǔn)API(應(yīng)用程序接口)使RDMA從技術(shù)走向?qū)崿F(xiàn)成為可能。其中包括用于低時(shí)延消息處理、成就高性能計(jì)算的MPI(消息通過(guò)接口),以及DAPL(直接接入供應(yīng)庫(kù))。后者包括兩部分:KDAPL和UDAPL,分別用于內(nèi)核和用戶(應(yīng)用程序)。Linux支持KDAPL,其它操作系統(tǒng)將來(lái)也有可能支持。RDMA在高性能計(jì)算環(huán)境廣為采納,在商務(wù)應(yīng)用領(lǐng)域很少,但如今大多應(yīng)用程序都能直接支持操作系統(tǒng),透過(guò)操作系統(tǒng)(如NFS)間接利用RDMA技術(shù)的優(yōu)勢(shì)是完全可能的。
第二節(jié)RDMA工作原理
RDMA是一種網(wǎng)卡技術(shù),采用該技術(shù)可以使一臺(tái)計(jì)算機(jī)直接將信息放入另一臺(tái)計(jì)算機(jī)的內(nèi)存中。通過(guò)最小化處理過(guò)程的開(kāi)銷和帶寬的需求降低時(shí)延。RDMA通過(guò)在網(wǎng)卡上將可靠傳輸協(xié)議固化于硬件,以及支持零復(fù)制網(wǎng)絡(luò)技術(shù)和內(nèi)核內(nèi)存旁路技術(shù)這兩種途徑來(lái)達(dá)到這一目標(biāo)。RDMA模型如圖2.1所示。

圖2.1 RDMA模型演變
零復(fù)制網(wǎng)絡(luò)技術(shù)使NIC可以直接與應(yīng)用內(nèi)存相互傳輸數(shù)據(jù),從而消除了在應(yīng)用內(nèi)存與內(nèi)核內(nèi)存之間復(fù)制數(shù)據(jù)的需要。
內(nèi)核內(nèi)存旁路技術(shù)使應(yīng)用程序無(wú)需執(zhí)行內(nèi)核內(nèi)存調(diào)用就可向網(wǎng)卡發(fā)送命令。在不需要任何內(nèi)核內(nèi)存參與的條件下,RDMA請(qǐng)求從用戶空間發(fā)送到本地NIC并通過(guò)網(wǎng)絡(luò)發(fā)送給遠(yuǎn)程NIC,這就減少了在處理網(wǎng)絡(luò)傳輸流時(shí)內(nèi)核內(nèi)存空間與用戶空間之間環(huán)境切換的次數(shù)。
當(dāng)一個(gè)應(yīng)用程序執(zhí)行RDMA讀/寫(xiě)請(qǐng)求時(shí),系統(tǒng)并不執(zhí)行數(shù)據(jù)復(fù)制動(dòng)作,這就減少了處理網(wǎng)絡(luò)通信時(shí)在內(nèi)核空間和用戶空間上下文切換的次數(shù)。在不需要任何內(nèi)核內(nèi)存參與的條件下,RDMA請(qǐng)求從運(yùn)行在用戶空間中的應(yīng)用中發(fā)送到本地 NIC(網(wǎng)卡),然后經(jīng)過(guò)網(wǎng)絡(luò)傳送到遠(yuǎn)程NIC。請(qǐng)求完成既可以完全在用戶空間中處理(通過(guò)輪詢用戶級(jí)完成排列),或者在應(yīng)用一直睡眠到請(qǐng)求完成時(shí)的情況下通過(guò)內(nèi)核內(nèi)存處理。
RDMA操作使應(yīng)用可以從一個(gè)遠(yuǎn)程應(yīng)用的內(nèi)存中讀數(shù)據(jù)或向這個(gè)內(nèi)存寫(xiě)數(shù)據(jù)。RDMA操作用于讀寫(xiě)操作的遠(yuǎn)程虛擬內(nèi)存地址包含在RDMA消息中傳送,遠(yuǎn)程應(yīng)用程序要做的只是在其本地網(wǎng)卡中注冊(cè)相應(yīng)的內(nèi)存緩沖區(qū)。遠(yuǎn)程節(jié)點(diǎn)的CPU在整個(gè)RDMA操作中并不提供服務(wù),因此沒(méi)有帶來(lái)任何負(fù)載。通過(guò)類型值(鍵值)的使用,一個(gè)應(yīng)用程序能夠在遠(yuǎn)程應(yīng)用程序?qū)λM(jìn)行隨機(jī)訪問(wèn)的情況下保護(hù)它的內(nèi)存。
發(fā)布RDMA操作的應(yīng)用程序必須為它試圖訪問(wèn)的遠(yuǎn)程內(nèi)存指定正確的類型值,遠(yuǎn)程應(yīng)用程序在本地網(wǎng)卡中注冊(cè)內(nèi)存時(shí)獲得這個(gè)類型值。發(fā)布RDMA的應(yīng)用程序也必須確定遠(yuǎn)程內(nèi)存地址和該內(nèi)存區(qū)域的類型值。遠(yuǎn)程應(yīng)用程序會(huì)將相關(guān)信息通知給發(fā)布RDMA的應(yīng)用程序,這些信息包括起始虛擬地址、內(nèi)存大小和該內(nèi)存區(qū)域的類型值。在發(fā)布RDMA的應(yīng)用程序能夠?qū)υ搩?nèi)存區(qū)域進(jìn)行RDMA操作之前,遠(yuǎn)程應(yīng)用程序應(yīng)將這些信息通過(guò)發(fā)送操作傳送給發(fā)布RDMA的應(yīng)用程序。
第三節(jié)RDMA 操作類型
具備RNIC(RDMA-aware network interface controller)網(wǎng)卡的設(shè)備,不論是目標(biāo)設(shè)備還是源設(shè)備的主機(jī)處理器都不會(huì)涉及到數(shù)據(jù)傳輸操作,RNIC網(wǎng)卡負(fù)責(zé)產(chǎn)生RDMA數(shù)據(jù)包和接收輸入的RDMA數(shù)據(jù)包,從而消除傳統(tǒng)操作中多余的內(nèi)存復(fù)制操作。
RDMA協(xié)議提供以下4種數(shù)據(jù)傳輸操作,除了RDMA讀操作不會(huì)產(chǎn)生RDMA消息,其他操作都會(huì)產(chǎn)生一條RDMA消息。
RDMA Send操作;
Send operation;
Send with invalidate operation;
Send with solicited event;
Send with solicited event and invalidate;
RDMA Write操作;
RDMA Read操作;
Terminate操作。
第四節(jié) RDMA over TCP
以太網(wǎng)憑借其低投入、后向兼容、易升級(jí)、低運(yùn)營(yíng)成本優(yōu)勢(shì)在目前網(wǎng)絡(luò)互連領(lǐng)域內(nèi)占據(jù)統(tǒng)治地位,目前主流以太網(wǎng)速率是100 Mb/s和1000 Mb/s,下一代以太網(wǎng)速率將會(huì)升級(jí)到10 Gb/s。將RDMA特性增加到以太網(wǎng)中,將會(huì)降低主機(jī)處理器利用率,增加以太網(wǎng)升級(jí)到10 Gb/s的優(yōu)點(diǎn),消除由于升級(jí)到10 Gb/s而引入巨大開(kāi)銷的弊端,允許數(shù)據(jù)中心在不影響整體性能的前提下拓展機(jī)構(gòu),為未來(lái)擴(kuò)展需求提供足夠的靈活性。
RDMA over TCP協(xié)議將數(shù)據(jù)直接在兩個(gè)系統(tǒng)的應(yīng)用內(nèi)存之間進(jìn)行交互,對(duì)操作系統(tǒng)內(nèi)核幾乎沒(méi)有影響,并且不需要臨時(shí)復(fù)制到系統(tǒng)內(nèi)存的操作,數(shù)據(jù)流如圖4.1所示。

圖4.1 RDMA over TCP (Ethernet)數(shù)據(jù)流示意圖
RDMA over TCP協(xié)議能夠工作在標(biāo)準(zhǔn)的基于TCP/IP協(xié)議的網(wǎng)絡(luò),如目前在各個(gè)數(shù)據(jù)中心廣泛使用的以太網(wǎng)。注意:RDMA over TCP并沒(méi)有指定物理層信息,能夠工作在任何使用TCP/IP協(xié)議的網(wǎng)絡(luò)上層。RDMA over TCP允許很多傳輸類型來(lái)共享相同的物理連接,如網(wǎng)絡(luò)、I/O、文件系統(tǒng)、塊存儲(chǔ)和處理器之間的消息通訊。
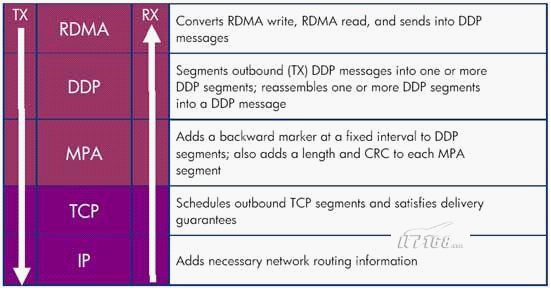
圖4.2 RDMA over TCP (Ethernet)協(xié)議棧
圖4.2是RDMA over TCP (Ethernet)的協(xié)議棧,最上面三層構(gòu)成iWARP協(xié)議族,用來(lái)保證高速網(wǎng)絡(luò)的互操作性。
RDMA層協(xié)議負(fù)責(zé)根據(jù)RDMA寫(xiě)操作、RDMA讀操作轉(zhuǎn)換成RDMA消息,并將RDMA消息傳向Direct Data Placement (DDP)層。DDP層協(xié)議負(fù)責(zé)將過(guò)長(zhǎng)的RDMA消息分段封裝成DDP數(shù)據(jù)包繼續(xù)向下轉(zhuǎn)發(fā)到Marker-based, Protocol-data-unit-Aligned (MPA)層。MPA層在DDP數(shù)據(jù)段的固定間隔位置增加一個(gè)后向標(biāo)志、長(zhǎng)度以及CRC校驗(yàn)數(shù)據(jù),構(gòu)成MPA數(shù)據(jù)段。TCP層負(fù)責(zé)對(duì)TCP數(shù)據(jù)段進(jìn)行調(diào)度,確保發(fā)包能夠順利到達(dá)目標(biāo)位置。IP層則在數(shù)據(jù)包中增加必要的網(wǎng)絡(luò)路由數(shù)據(jù)信息。
DDP層的PDU段的長(zhǎng)度是固定的,DDP層含有一個(gè)成幀機(jī)制來(lái)分段和組合數(shù)據(jù)包,將過(guò)長(zhǎng)的RDMA消息分段封裝為DDP消息,處理過(guò)程如圖4.3所示。

圖4.3 DDP層拆分RDMA消息示意圖
DDP數(shù)據(jù)段是DDP協(xié)議數(shù)據(jù)傳輸?shù)淖钚?shù)據(jù)單元,包含DDP協(xié)議頭和ULP載荷。DDP協(xié)議頭包含ULP數(shù)據(jù)的最終目的地址的位置和相關(guān)控制信息。DDP層將ULP數(shù)據(jù)分段的原因之一就是TCP載荷的最大長(zhǎng)度限制。DDP的數(shù)據(jù)傳輸模式分為2種:tagged buffer方式和untagged buffer方式。tagged buffer方式一般應(yīng)用于大數(shù)據(jù)量傳輸,例如磁盤I/O、大數(shù)據(jù)結(jié)構(gòu)等;而untagged buffer方式一般應(yīng)用于小的控制信息傳輸,例如:控制消息、I/O狀態(tài)信息等。
MPA層在DDP層傳遞下來(lái)的DDP消息中,MPA層通過(guò)增加MPA協(xié)議頭、標(biāo)志數(shù)據(jù)以及CRC校驗(yàn)數(shù)據(jù)構(gòu)成FPDU(framed PDU )數(shù)據(jù)段,處理過(guò)程如圖4.4所示。
MPA層便于對(duì)端網(wǎng)絡(luò)適配器設(shè)備能夠快速定位DDP協(xié)議頭數(shù)據(jù),根據(jù)DDP協(xié)議頭內(nèi)設(shè)置的控制信息將數(shù)據(jù)直接置入相應(yīng)的應(yīng)用內(nèi)存區(qū)域。MPA層具備錯(cuò)序校正能力,通過(guò)使能DDP,MPA避免內(nèi)存復(fù)制的開(kāi)銷,減少處理亂序數(shù)據(jù)包和丟失數(shù)據(jù)包時(shí)對(duì)內(nèi)存的需求。MPA將FPDU數(shù)據(jù)段傳送給TCP層處理。
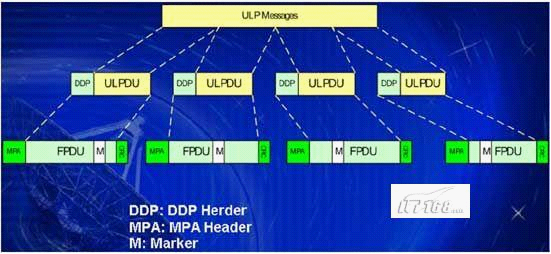
圖4.4 MPA層拆分DDP消息示意圖
TCP層將FPDU數(shù)據(jù)段拆放置在TCP數(shù)據(jù)段中,確保每個(gè)TCP數(shù)據(jù)段中都包含1個(gè)單獨(dú)的FDPU。MPA接收端重新組裝為完整的FPDU,驗(yàn)證數(shù)據(jù)完整性,將無(wú)用的信息段去除,然后將完整的DDP消息發(fā)送到DDP層進(jìn)行處理。DDP 允許DDP數(shù)據(jù)段中的ULP協(xié)議(Upper Layer Protocol)數(shù)據(jù),例如應(yīng)用消息或磁盤I/O數(shù)據(jù),不需要經(jīng)過(guò)ULP的處理而直接放置在目的地址的內(nèi)存中,即使DDP數(shù)據(jù)段亂序也不影響這種操作。
第五節(jié)RDMA標(biāo)準(zhǔn)組織
2001年10月,Adaptec、Broadcom、Cisco、Dell、EMC、HP、IBM、Intel、Microsoft和NetApp公司宣布成立"遠(yuǎn)程直接內(nèi)存訪問(wèn)(RDMA)聯(lián)盟"。RDMA聯(lián)盟是個(gè)獨(dú)立的開(kāi)放組織,其制定實(shí)施能提供TCP/IP RDMA技術(shù)的產(chǎn)品所需的體系結(jié)構(gòu)規(guī)范,鼓勵(lì)其它技術(shù)公司積極參與新規(guī)范的制定。該聯(lián)盟將負(fù)責(zé)為整個(gè)RDMA解決方案制定規(guī)范,包括RDMA、DDP(直接數(shù)據(jù)放置)和TCP/IP分幀協(xié)議。
RDMA聯(lián)盟是Internet工程任務(wù)組(IETF)的補(bǔ)充,IETF是由網(wǎng)絡(luò)設(shè)計(jì)師、運(yùn)營(yíng)商、廠商和研究公司組成的大型國(guó)際組織。其目的是推動(dòng)Internet體系結(jié)構(gòu)的發(fā)展,并使Internet的運(yùn)作更加順暢。RDMA聯(lián)盟的成員公司和個(gè)人都是IETF的積極參與者。另外,IETF還認(rèn)識(shí)到了RDMA在可行網(wǎng)絡(luò)方案中的重要性,并計(jì)劃在以后幾個(gè)月里成立"Internet協(xié)議套件RDMA"工作組。RDMA聯(lián)盟協(xié)議規(guī)定,聯(lián)盟將向相應(yīng)的IETF工作組提交規(guī)范草案,供IETF考慮。
TCP/IP RDMA體系結(jié)構(gòu)規(guī)范的1.0版本于2002年10月由RDMA聯(lián)盟成員發(fā)布, TCP/IP RDMA的最終規(guī)范將由RDMA聯(lián)盟的業(yè)界合作伙伴及相應(yīng)的業(yè)界標(biāo)準(zhǔn)組織派出的代表共同確定。RDMA聯(lián)盟官方網(wǎng)址:http://www.rdmaconsortium.org。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)