
你應該懂的AI大模型(十三) 之 推理框架
?
在大語言模型(LLM)技術爆發的今天,從 ChatGPT 到開源的 LLaMA、Qwen 系列,模型能力不斷突破,但將這些 “智能大腦” 落地到實際業務中,卻面臨著效率、成本和部署復雜度的三重挑戰。此時,大模型推理框架成為了連接理論與實踐的關鍵橋梁。
一、什么是大模型推理框架
大模型推理框架是專門優化預訓練大模型 “推理階段” 的工具集,專注于解決模型部署中的效率、成本和工程化問題。與訓練框架(如 PyTorch、TensorFlow)不同,推理框架不參與模型參數的學習過程,而是聚焦于如何讓訓練好的模型在生產環境中更快速、更經濟、更穩定地響應請求。?
簡單來說,訓練框架負責 “教會模型思考”,而推理框架負責 “讓模型高效地回答問題”。
二、推理框架的核心作用
推理框架的核心作用?
1、提升響應速度?
未經優化的大模型推理可能需要數秒甚至數十秒才能生成結果,而推理框架通過注意力機制優化(如 PagedAttention)、動態批處理等技術,可將延遲壓縮至毫秒級,滿足實時交互場景需求?
2、降低資源消耗?
大模型動輒數十億甚至千億參數,原生推理需占用數十 GB 顯存。推理框架通過量化技術(如 INT4/INT8)、KV 緩存優化等手段,可將顯存占用降低 50%-75%,同時支持單 GPU 部署更大模型。?
3、簡化工程落地?
提供開箱即用的 API 服務(REST/gRPC)、負載均衡、動態擴縮容等功能,將復雜的分布式推理邏輯封裝成簡單接口,讓開發者無需深入底層優化即可部署高可用服務。?
4、適配多樣化場景?
支持云服務器、邊緣設備、端側終端等多環境部署,兼容 NVIDIA GPU、AMD GPU、CPU 甚至專用 AI 芯片(如昇騰),滿足不同企業的硬件條件。
三、主流大模型推理框架
目前市場上的推理框架可分為 “通用型”(適配多模型和硬件)和 “專用型”(針對特定場景深度優化),以下是企業級項目中最常用的幾種:?
1. vLLM:高吞吐量的開源明星?
由 UC Berkeley 團隊開發的 vLLM,憑借其創新的PagedAttention 技術(借鑒操作系統內存分頁機制管理 KV 緩存)成為開源社區的焦點。?
核心優勢:?
-
支持動態批處理(Continuous Batching),吞吐量是原生 Hugging Face Transformers 的 10-20 倍;?
-
無縫兼容 Hugging Face 模型格式,LLaMA、Mistral、Qwen 等主流模型可直接部署;?
-
輕量級設計,單條命令即可啟動服務,適合快速測試和生產部署。?
適用場景:高并發 API 服務(如客服機器人、內容生成平臺),尤其適合 NVIDIA GPU 環境。?
2. Text Generation Inference(TGI):Hugging Face 生態的官方選擇?
作為 Hugging Face 推出的推理框架,TGI 深度集成了 Transformers、Tokenizers 等工具鏈,是開源模型部署的 “嫡系” 方案。?
核心優勢:?
-
支持張量并行(多 GPU 拆分模型),輕松部署 13B/70B 等大模型;?
-
內置日志、監控和 A/B 測試工具,便于企業級運維;?
-
原生支持流式輸出(Stream),優化對話交互體驗。?
適用場景:依賴 Hugging Face 生態的企業,或需要快速部署開源模型進行驗證的場景。?
3. TensorRT-LLM:NVIDIA 硬件的性能王者?
NVIDIA 官方推出的 TensorRT-LLM 是基于 TensorRT 引擎的大模型推理優化框架,專為 NVIDIA GPU 打造。?
核心優勢:?
-
采用編譯型優化(將模型轉為 TensorRT 引擎),延遲比 vLLM 低 30%-50%;?
-
支持 INT4/INT8 量化和稀疏性優化,在 H100/A100 等高端 GPU 上性能極致;?
-
提供 C++/Python 接口,支持多模型并行策略。?
適用場景:對延遲敏感的工業級場景(如金融風控、實時對話),需依賴 NVIDIA GPU。?
4. LMDeploy:輕量高效的多場景適配者?
LMDeploy 以 “輕量、高效、多場景兼容” 為特色,尤其對國產模型支持友好。?
核心優勢:?
-
支持 INT4/INT8/FP16 多種精度,可在消費級 GPU(如 RTX 3090)甚至 CPU 上部署;?
-
提供模型轉換、量化、服務部署全鏈路工具,降低工程門檻;?
-
適配 Qwen、LLaMA、Baichuan 等主流模型,國產模型優化更精細。?
適用場景:資源受限的邊緣設備、多模型混合部署場景,或國產模型優先的企業。?
5. DeepSpeed-Inference:超大規模模型的分布式專家?
由 Microsoft 和華盛頓大學聯合開發的 DeepSpeed-Inference,專為千億級參數模型設計。?
核心優勢:?
-
支持張量并行、管道并行等多種分布式策略,可拆分 100B + 參數模型;?
-
集成 ZeRO 優化技術,減少多 GPU 通信開銷;?
-
兼容 PyTorch 生態,便于與訓練流程銜接。?
適用場景:需要部署超大規模模型(如 GPT-3 175B、LLaMA 70B)的企業,需多 GPU 集群支持。
四、推理框架的核心差異與選型維度
不同框架的差異主要體現在技術路線、硬件適配和功能側重上,企業選型時需關注以下維度:?
1. 性能指標:延遲 vs 吞吐量?
-
低延遲優先:TensorRT-LLM(編譯優化)> vLLM(PagedAttention)> TGI;?
-
高吞吐量優先:vLLM(動態批處理)> TGI > LMDeploy;?
-
顯存效率:LMDeploy(量化優化)> TensorRT-LLM(INT4)> vLLM。?
2. 硬件兼容性?
-
NVIDIA GPU 專屬:TensorRT-LLM(性能最佳)、vLLM(兼容性好);?
-
跨硬件支持:LMDeploy(CPU/GPU/ 邊緣設備)、ONNX Runtime(多芯片適配);?
-
國產芯片適配:LMDeploy(昇騰支持)、ONNX Runtime(寒武紀 / 地平線插件)。?
3. 模型兼容性?
-
開源模型全覆蓋:TGI(Hugging Face 生態)、vLLM(主流模型);?
-
國產模型優化:LMDeploy(Qwen/Baichuan)> TGI > TensorRT-LLM;?
-
超大規模模型:DeepSpeed-Inference(100B + 參數)> TensorRT-LLM(張量并行)。?
4. 部署復雜度?
-
快速上手:vLLM(單命令啟動)、TGI(Docker 一鍵部署);?
-
工業級部署:TensorRT-LLM(需編譯模型)、DeepSpeed-Inference(分布式配置);?
-
輕量部署:LMDeploy(資源占用低)、ONNX Runtime(跨平臺打包)。
五、使用LMdeploy部署模型
筆者使用的是Autodl服務器,因此需要做個SSH隧道。
5.1配置Conda環境
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy modelscope gradio partial-json-parser
export LMDEPLOY_USE_MODELSCOPE=True驗證lmdeploy安裝--
lmdeploy --version5.2下載模型
5.3模型轉換
LMDeploy 推薦使用 convert 命令將模型轉換為高效推理格式:
lmdeploy convert qwen3 Qwen3-7B-Chat --dst-path qwen3-7b-chat-lmdeploy轉換后的模型將存儲在 qwen3-7b-chat-lmdeploy 目錄,包含優化后的權重和配置文件。
此項非必選。
5.4啟動推理服務
lmdeploy serve api_server /root/autodl-tmp/ddq/Qwen/Qwen3-4B --reasoning-parser qwen-qwq --server-port 23333 --session-len 8192-
mdeploy serve api_server:LMDeploy 的核心命令,用于啟動 API 服務端 -
/tmp/code/models/Qwen3-0.6B:指定 Qwen3-0.6B 模型的本地路徑 -
--reasoning-parser qwen-qwq:指定使用 Qwen 系列的qwq推理解析器,適配 Qwen 模型的對話格式和推理邏輯 -
--server-port 23333:設置 API 服務監聽的端口為 23333(默認通常是 8000) -
--session-len 8192:設置會話上下文長度為 8192 tokens,控制模型能處理的歷史對話 + 當前查詢的總長度
執行這條命令后,LMDeploy 會加載指定的 Qwen3-0.6B 模型,并在本地 23333 端口啟動一個 HTTP API 服務,你可以通過發送 HTTP 請求與模型進行交互。
5.4.1 生產環境部署(本文實驗未使用這種部署方式)
1、docker部署
# 拉取 LMDeploy 鏡像
docker pull kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/lmdeploy:latest
# 啟動容器
docker run -d --gpus all \
-p 8000:8000 \
-v /path/to/qwen3-7b-chat-lmdeploy:/model \
kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/lmdeploy \
lmdeploy serve api_server /model --server-port 80002、在 Kubernetes 中部署(使用 Arena)
arena serve custom \
--name=lmdeploy-qwen3 \
--version=v1 \
--gpus=1 \
--replicas=1 \
--restful-port=8000 \
--readiness-probe-action="tcpSocket" \
--readiness-probe-action-option="port: 8000" \
--readiness-probe-option="initialDelaySeconds: 60" \ # Qwen3啟動較慢,延長初始檢查時間
--readiness-probe-option="periodSeconds: 30" \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/lmdeploy:latest \
--data=qwen3-model:/model/Qwen3-7B-Chat \ # 掛載模型數據卷
"lmdeploy serve api_server /model/Qwen3-7B-Chat --server-port 8000"5.4.2 通過MobaXterm建立SSH隧道
筆者喜歡在vscode中使用remote插件直接進行端口轉發,因為筆者沒有那么多服務器管理的需求,這個習慣因人而已。
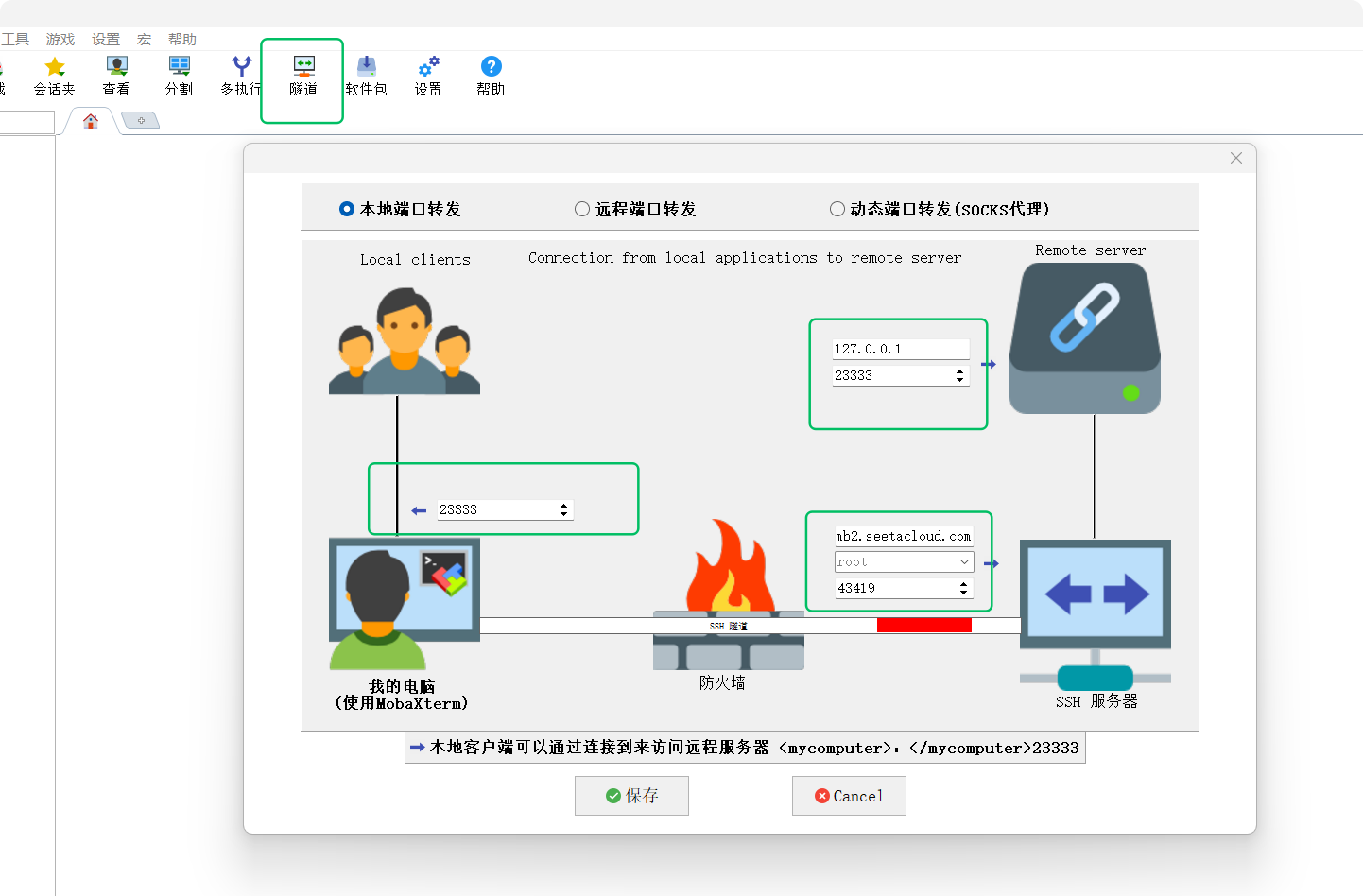

5.4.3 在CherryStudio中測試隧道效果
![]()

?

 浙公網安備 33010602011771號
浙公網安備 33010602011771號