
你應該懂的AI大模型(八)之 微調 之 增量微調
一、什么是微調
1.1、什么是微調?為什么要做微調?
模型微調(Fine-tuning)指的是將一個預訓練好的模型(通常在大規模通用數據集上訓練)針對特定任務或領域進行優化的過程。
那么什么是預訓練好的模型呢?
預訓練好的模型(Pre-trained Model)是指在大規模通用數據集上經過預先訓練,具備基礎特征提取能力的機器學習模型。這類模型無需針對具體任務從零訓練,而是作為 “起點”,通過微調(Fine-tuning)快速適配不同場景。
講的通俗一點就是:只調整模型的一部分結構(參數),為了讓模型能夠適應當前的任務,就只調整一部分就足夠了。
至于為什么要做微調,說白了就是我想白嫖模型已經訓練好的部分參數,以此縮短自己訓練模型的時間。
模型微調分為:
-
全量微調
- 對模型的所有參數進行微調
- 效果最好
- 消耗的算力資源大
-
局部微調
- 只調整某些或者某部分參數
- 對算力要求一般
-
增量微調
- 通過新增參數的方式完成微調,把新的知識存儲在新增的參數中
- 效果一般
微調之后模型一定會變得更強嗎?
不一定,一般百億參數以下的參數可以考慮微調。但是對于大模型而言微調之后效果可能會變得更差了。
1.2、增量微調
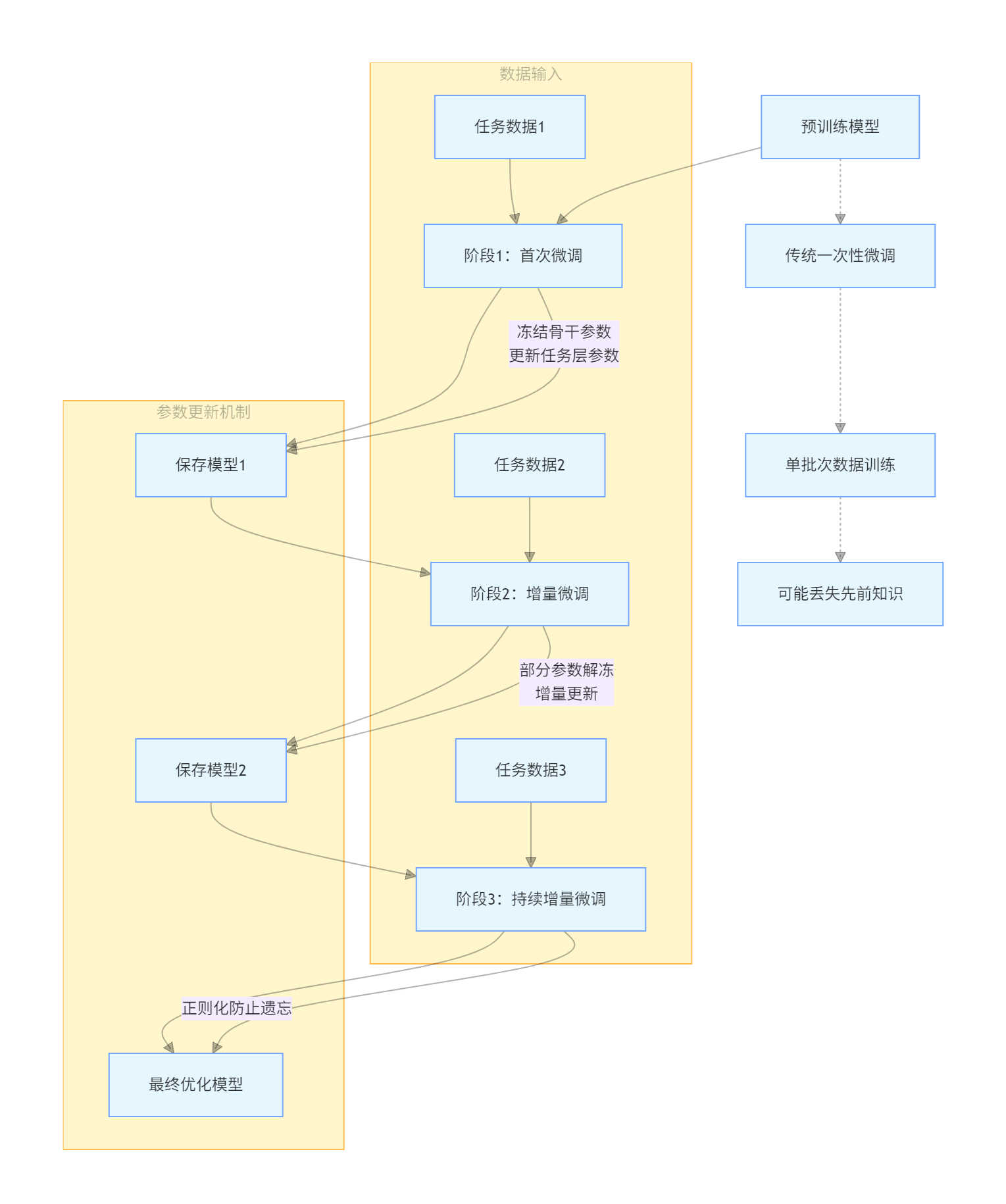
增量微調是在原有的模型的基礎上增加一段邏輯,并通過訓練保存最后的訓練參數。
增量微調的本質是 **“有控制地進化模型”:通過新增模塊或調整部分參數,讓模型在保留舊能力的同時學會新技能,最終保存的是新舊能力融合后的參數 **。這種方式既節省資源(不用從頭訓練),又能應對動態變化的場景(如新數據、新任務不斷出現)。
增量微調的實現方式
-
增加新模塊(類似 “加裝插件”)
- 例如:在預訓練的語言模型后增加一個 “情感分析層”,專門學習判斷文本的褒貶(新增邏輯不影響原有模型結構)。
- 訓練:固定原有模型參數,只訓練新增的情感層,保存時只更新情感層的參數。
-
調整部分參數(類似 “修改局部程序”)
- 例如:在圖像分類模型中,發現對 “貓” 的識別準確率低,解凍并微調與 “貓特征” 相關的卷積層參數(如耳朵、尾巴的檢測模塊)。
- 訓練:凍結大部分參數,只更新與 “貓” 相關的少量參數,保存時只改動這部分參數。
-
混合方式(既加新模塊又調舊參數)
- 例如:在預訓練的翻譯模型中,新增一個 “領域術語校正層”,同時微調編碼器的最后幾層,讓模型更好地處理醫學翻譯。
- 訓練:先固定原有模型訓練新增層,再解凍部分舊層聯合訓練,保存時更新所有參與訓練的參數。
為什么要用增量微調?
- 數據不是一下子全有的:比如電商平臺的用戶評價,每天都會新增,模型需要每天 “學一點新評價”,同時記住之前的評價規律。
- 任務會慢慢變復雜:比如翻譯模型先學中英翻譯,后來要加中日翻譯,增量微調能讓它同時精通多門語言,而不是學了日語就忘了英語。
- 省算力省時間:不用每次都把整個模型重新訓練一遍,就像你復習功課只需要重點看新內容,不用把所有書再讀一遍。
增量微調的過程如下圖:
二、從設計模型開始
2.1、先了解模型開發的邏輯
AI 項目的開發過程:
- 準備數據
- 構建設計模型
- 模型訓練
- 評估測試
- 打包部署
2.2、設計模型
在本文中設計模型與定義數據集的過程與上文中的模型開發過程有所顛倒,不用過于糾結,在實際項目中這兩個過程也是有可能同步進行的。
'''
我們以Bert模型為基座,進行增量微調,在原來模型的基礎上加上以下邏輯進行微調訓練
'''
from transformers import BertModel
import torch
#定義設備信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
#加載預訓練模型
pretrained = BertModel.from_pretrained(r"D:\PycharmProjects\disanqi\demo_5\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE)
print(pretrained)
#定義下游任務(增量模型)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#設計全連接網絡,實現二分類任務
self.fc = torch.nn.Linear(768,2)
def forward(self,input_ids,attention_mask,token_type_ids):
#凍結Bert模型的參數,讓其不參與訓練
with torch.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#增量模型參與訓練
out = self.fc(out.last_hidden_state[:,0])
return out
2.3 、自定義數據集
'''
我們訓練模型的時候需要區分數據屬于哪個部分,分別是train、test、validation
'''
#自定義數據集
from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
def __init__(self,split):
#從磁盤加載數據
self.dataset = load_from_disk(r"D:\XXX\XXX\XXXX\XXXX\XXXX")
if split == 'train':
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset["test"]
elif split == "validation":
self.dataset = self.dataset["validation"]
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
text = self.dataset[item]['text']
label = self.dataset[item]['label']
return text,label
if __name__ == '__main__':
dataset = MyDataset("test")
for data in dataset:
print(data)
2.4、寫一個模型訓練類
#模型訓練
import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer,AdamW
#定義設備信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#定義訓練的輪次
EPOCH= 30000
token = BertTokenizer.from_pretrained(r"D:\PycharmProjects\disanqi\demo_5\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
def collate_fn(data):
sents = [i[0]for i in data]
label = [i[1] for i in data]
#編碼
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
truncation=True,
max_length=500,
padding="max_length",
return_tensors="pt",
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
labels = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,labels
#創建數據集
train_dataset = MyDataset("train")
train_loader = DataLoader(
dataset=train_dataset,
batch_size=100,
shuffle=True,
#舍棄最后一個批次的數據,防止形狀出錯
#比如我們有 100 條數據,每次去 10條,10 次能取完,如果99條數據,最后一次形狀就會發生變化。因此我們要舍棄
drop_last=True,
#對加載進來的數據進行編碼
collate_fn=collate_fn
)
if __name__ == '__main__':
#開始訓練
print(DEVICE)
model = Model().to(DEVICE)
#定義優化器
optimizer = AdamW(model.parameters())
#定義損失函數
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(train_loader):
#將數據存放到DEVICE上
input_ids, attention_mask, token_type_ids, labels = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),labels.to(DEVICE)
#前向計算(將數據輸入模型,得到輸出)
out = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#根據輸出,計算損失
loss = loss_func(out,labels)
#根據損失,優化參數
optimizer.zero_grad()
loss.backward()
optimizer.step()
#每隔5個批次輸出訓練信息
if i%5==0:
out = out.argmax(dim=1)
acc = (out==labels).sum().item()/len(labels)
print(f"epoch:{epoch},i:{i},loss:{loss.item()},acc:{acc}")
#每訓練完一輪,保存一次參數
#一輪就是把所有數據都訓練一遍,批次是一次取多少數據
torch.save(mode l.state_dict(),f"params/{epoch}_bert.pth")
print(epoch,"參數保存成功!")
三、看懂微調結果
3.1、前向計算、反向傳播
1、前向計算:從輸入到輸出的信息傳遞
- 計算預測結果:將輸入數據通過網絡的各層計算,最終得到預測輸出。
- 數據流動方向:輸入層 → 隱藏層 → 輸出層,逐層計算每個神經元的輸出。
2、反向傳播:從誤差到參數更新的梯度傳遞
- 計算梯度:根據預測誤差,計算每個參數(權重和偏置)對誤差的影響程度(梯度)。
- 參數更新:基于梯度,使用優化算法(如 SGD、Adam)更新參數,減小誤差。
3.2、梯度下降
神經網絡預測的過程基于一個簡單的公式:z = dot(w,x) + b
公式中的x代表著輸入特征向量,假設只有3個特征,那么x就可以用(x1,x2,x3)來表示。w表示權重,它對應于每個輸入特征,代表了每個特征的重要程度。b表示閾值[yù zhí],用來影響預測結果。z就是預測結果。公式中的dot()函數表示將w和x進行向量相乘。
損失函數用來衡量預測算法算的怎么樣的函數,損失函數運算后的結果越大,那么預測就與實際結果偏差越大,即預測精度不高。即損失函數運算之后得出的值越大帶邊精度越低,即結果越不好。努力讓損失函數的值變得越小就是讓結果變得越準確。
所以模型的結果是不是準確就是w和b決定的,那么神經網絡學習的目的就是找到合適的w和b,找到合適的w和b的算法就叫梯度下降,記住梯度下降就是個名字,不要管為什么叫這個名字。
因此在上面的訓練代碼中每訓練完一輪就保存一次參數,在訓練過程中損失在下降、精度在提升就代表我們的訓練沒有問題,訓練模型的時候我們微調的就是層次和批次。
四、模型評估
4.1 、欠擬合與過擬合
欠擬合(Underfitting)和過擬合(Overfitting)是機器學習模型訓練中常見的兩種不理想狀態。
-
欠擬合:模型無法捕捉數據中的規律,對訓練數據和測試數據的表現都很差。
-
過擬合:模型過度學習訓練數據中的細節和噪聲,導致在訓練集上表現好,但在測試集上表現差。
形象比喻
- 欠擬合:學生 “沒學明白”,連課本例題都做不對。
- 過擬合:學生 “死記硬背”,只記住了課本例題的答案,遇到新題目就不會做。
- 欠擬合是模型 “能力不足”,需要增強模型復雜度和特征表達。
- 過擬合是模型 “學太細”,需要約束模型并增加數據多樣性。
一旦模型過擬合了,基本就等于訓練廢了,很難補救。
4.2、訓練集、驗證集、測試集
- 訓練集: 模型訓練時用的數據,等于模型學習的“教材”;
- 驗證集:訓練中的評估,判斷模型是否過擬合了;
- 測試集:完成訓練之后評測用的,用來出評估報告。
在實際開發中驗證集和測試集經常使用一個,比例一般是9:1、8:2、7:3。要特別注意的是三個數據集之間不能有數據重疊,否則就是作弊了。
4.3、模型評估
模型評估使用的是反向傳播算法,損失在下降、精度在上漲代表模型的訓練就是沒有問題的,其實我們評估模型訓練的結果看的不是那一輪次的具體結果而是看的趨勢,趨勢向好偶有噪聲,不能說明模型訓練的不好。
在實際做項目中我們要向客戶明確的一件事是:模型訓練的數據應該是提前準備好的,而不是我在訓練的過程中再去加數據,

 浙公網安備 33010602011771號
浙公網安備 33010602011771號