
你應(yīng)該懂的AI大模型(六)之 transformers
一、Transformer與transformers
結(jié)論:Transformer是模型架構(gòu),transfortmers是庫。
問:為什么我們要知道Transformer與transformers呢?
答:千問大模型和DeepSeek都是Transformer架構(gòu)的,transformers庫就是為這個(gè)架構(gòu)而生的,各位覺著我們不了解它倆能行么?
(以上結(jié)論筆者的說法可能不準(zhǔn)確,但請(qǐng)不要急著給筆者科普,筆者搜一下能知道的比諸君噴的更準(zhǔn)確,但是在這里為了讓看文章的同學(xué)好理解,筆者就先這么說罷,想要更多了解Transfomer詳細(xì)內(nèi)容請(qǐng)自行找論文看,筆者自覺講不明白,搬運(yùn)一堆論文概念看不懂也沒啥用,諸君以為呢?)
Transformer 模型(技術(shù)架構(gòu))由 Google 在 2017 年論文《Attention Is All You Need》中提出的一種深度學(xué)習(xí)架構(gòu),基于自注意力機(jī)制(Self-Attention),徹底摒棄了傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)結(jié)構(gòu)。
在Transformer模型中,原始文本 → 分詞器(Tokenization)→ 編碼器(Encoder)→ 解碼器(Decoder)→ 輸出(經(jīng)分詞器轉(zhuǎn)換回文本):
-
分詞器(Tokenization)是整個(gè)流程的起點(diǎn):分詞器的作用是將輸入文本分割成Token,這些Token可以是單詞、字符、短語等。常見的分詞策略包括按詞切分(Word-based)、按字符切分(Character-based)和按子詞切分(Subword)等方法?,供編碼器(Encoder)處理。
-
編碼器(Encoder)**:**將輸入編碼處理為帶有注意力信息的連續(xù)表示,可以將編碼器堆疊N次使得每一層都有機(jī)會(huì)學(xué)習(xí)不同的注意力表示,從而提高Transformer的預(yù)測(cè)能力。
再好懂點(diǎn)就是將輸入序列轉(zhuǎn)換為上下文感知的語義表示,使模型能夠理解每個(gè) token 在全局語境中的含義。再直白點(diǎn)就是我們給模型一個(gè)漢字“白”,模型輸出“白”“天”倆字,要比輸出”白“”大“兩個(gè)完全不搭噶的字靠譜,就是干這個(gè)事兒。
-
解碼器(Decoder)是生成環(huán)節(jié)的核心:根據(jù)編碼器的語義表示,逐詞生成目標(biāo)文本。
-
分詞器(Tokenization)也是輸出的終點(diǎn):解碼器生成的 token ID 需通過分詞器的
decode()方法還原為人類可讀的文本。
transformers 庫(工具包)由 Hugging Face 團(tuán)隊(duì)開發(fā)的 Python 庫,全稱為transformers(小寫),提供了對(duì) Transformer 架構(gòu)模型的預(yù)訓(xùn)練權(quán)重、模型架構(gòu)和任務(wù)工具的統(tǒng)一接口。它的設(shè)計(jì)目標(biāo)是簡(jiǎn)化 Transformer 模型的使用,讓研究者和開發(fā)者能夠快速應(yīng)用最先進(jìn)的 NLP 技術(shù)。
建議各位眼熟一下分詞器(Tokenization)、 編碼器(Encoder)、 解碼器(Decoder)這幾個(gè)單詞,后面有用。
二、AutoModel與AutoModelForCausalLM
二者都是transformers庫中的類,都是加載模型的類。
AutoModel 是一個(gè)通用模型類,設(shè)計(jì)用來加載和運(yùn)行各種預(yù)訓(xùn)練模型。它不包含特定任務(wù)的頭部(例如分類頭),提供了預(yù)訓(xùn)練模型的基本架構(gòu),但沒有針對(duì)特定任務(wù)進(jìn)行優(yōu)化。
AutoModelForCausalLM,基于AutoModelForCausalLM。用于因果語言建模(Causal Language Modeling)。因果語言建模是指給定之前的詞或字符序列,模型預(yù)測(cè)文本序列中下一個(gè)詞或字符的任務(wù)。這種模型廣泛應(yīng)用于生成式任務(wù),如對(duì)話系統(tǒng)、文本續(xù)寫、摘要生成等。
(這里看不懂就算,能知道是個(gè)加載模型的類就行,我們用AutoModelForCausalLM)
在實(shí)際應(yīng)用中,選擇哪種模型類取決于任務(wù)需求。如果任務(wù)是文本生成或因果語言建模,`AutoModelForCausalLM` 更合適;而其他類型的 NLP 任務(wù),如文本分類或序列標(biāo)注,選`AutoModel`可能更合適 。
三、 AutoTokenizer
AutoTokenizer 是 Hugging Face Transformers 庫中的一個(gè)實(shí)用工具類,它提供了一種通用接口來加載與預(yù)訓(xùn)練模型對(duì)應(yīng)的分詞器(Tokenizer)。AutoTokenizer可以根據(jù)預(yù)訓(xùn)練模型名稱(如 "bert-base-uncased"),自動(dòng)選擇對(duì)應(yīng)的分詞器類(如 BertTokenizer)。建議搞不清狀況的情況下就使用AutoTokenizer。
上文中我們知道了分詞器是做什么的,我們以Bert模型為例,“窗前明月光”這句詩,在經(jīng)過分詞處理后就變成了[床][前][明][月][光]這幾個(gè)漢字對(duì)應(yīng)的字典編碼。
四、pipeline
沒錯(cuò),如你所想,這就是管道。熟悉linux的同學(xué)如你所想~
?Transformers Pipeline? 是Hugging Face Transformers 庫提供的一個(gè)高級(jí) API,旨在簡(jiǎn)化自然語言處理(NLP)、計(jì)算機(jī)視覺(CV)和多模態(tài)任務(wù)的實(shí)現(xiàn)流程。其核心功能包括數(shù)據(jù)預(yù)處理、模型調(diào)用和結(jié)果后處理的三部分整合,用戶只需輸入數(shù)據(jù)即可直接獲得最終結(jié)果。
五、從一段代碼來看
這段代碼中筆者以下載到本地的Bert模型為例,詳細(xì)看一下我們上面降到transforms庫的具體使用。
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 設(shè)置具體包含 config.json(即模型配置文件) 的目錄,路一直到模型配置文件的父級(jí)
model_dir = r"D:/XXX/XXX/XXXmodel/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f"
# 加載模型和分詞器
model = AutoModelForCausalLM.from_pretrained(model_dir,is_decoder=True)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# 使用加載的模型和分詞器創(chuàng)建生成文本的 pipeline
# 如果你想使用GPU環(huán)境,device參數(shù)配置為cuda
generator = pipeline("text-generation", model=model, tokenizer=tokenizer,device='cpu')
# 生成文本
output = generator("你好,我是一款語言模型,", max_length=50, num_return_sequences=1)
# output = generator("你好,我是一款語言模型,", max_length=50, num_return_sequences=1, truncation=True, clean_up_tokenization_spaces=False)
'''
output = generator(
"你好,我是一款語言模型,",#生成文本的輸入種子文本(prompt)。模型會(huì)根據(jù)這個(gè)初始文本,生成后續(xù)的文本
max_length=50,#指定生成文本的最大長(zhǎng)度。這里的 50 表示生成的文本最多包含 50 個(gè)標(biāo)記(tokens)
num_return_sequences=2,#參數(shù)指定返回多少個(gè)獨(dú)立生成的文本序列。值為 1 表示只生成并返回一段文本。
truncation=True,#該參數(shù)決定是否截?cái)噍斎胛谋疽赃m應(yīng)模型的最大輸入長(zhǎng)度。如果 True,超出模型最大輸入長(zhǎng)度的部分將被截?cái)啵蝗绻?False,模型可能無法處理過長(zhǎng)的輸入,可能會(huì)報(bào)錯(cuò)。
temperature=0.7,#該參數(shù)控制生成文本的隨機(jī)性。值越低,生成的文本越保守(傾向于選擇概率較高的詞);值越高,生成的文本越多樣(傾向于選擇更多不同的詞)。0.7 是一個(gè)較為常見的設(shè)置,既保留了部分隨機(jī)性,又不至于太混亂。
top_k=50,#該參數(shù)限制模型在每一步生成時(shí)僅從概率最高的 k 個(gè)詞中選擇下一個(gè)詞。這里 top_k=50 表示模型在生成每個(gè)詞時(shí)只考慮概率最高的前 50 個(gè)候選詞,從而減少生成不太可能的詞的概率。
top_p=0.9,#該參數(shù)(又稱為核采樣)進(jìn)一步限制模型生成時(shí)的詞匯選擇范圍。它會(huì)選擇一組累積概率達(dá)到 p 的詞匯,模型只會(huì)從這個(gè)概率集合中采樣。top_p=0.9 意味著模型會(huì)在可能性最強(qiáng)的 90% 的詞中選擇下一個(gè)詞,進(jìn)一步增加生成的質(zhì)量。
clean_up_tokenization_spaces=True#該參數(shù)控制生成的文本中是否清理分詞時(shí)引入的空格。如果設(shè)置為 True,生成的文本會(huì)清除多余的空格;如果為 False,則保留原樣。默認(rèn)值即將改變?yōu)?False,因?yàn)樗芨玫乇A粼嘉谋镜母袷健?)
'''
print(output)
輸出結(jié)果如下:

大家可以猜一猜為什么后面有這么多點(diǎn)?那是因?yàn)槲覀冋f了生成長(zhǎng)度為50。
六、一起看看bert模型文件
讀到這里大家肯定很好奇筆者在上面代碼中下載到本地的模型到底長(zhǎng)什么樣子,模型里面都有什么文件,接下里以bert模型為例,我們來看一下模型里面都有哪些文件。
上圖是筆者在本地加載的模型文件,有用的文件都在snapshots文件夾下。其中:
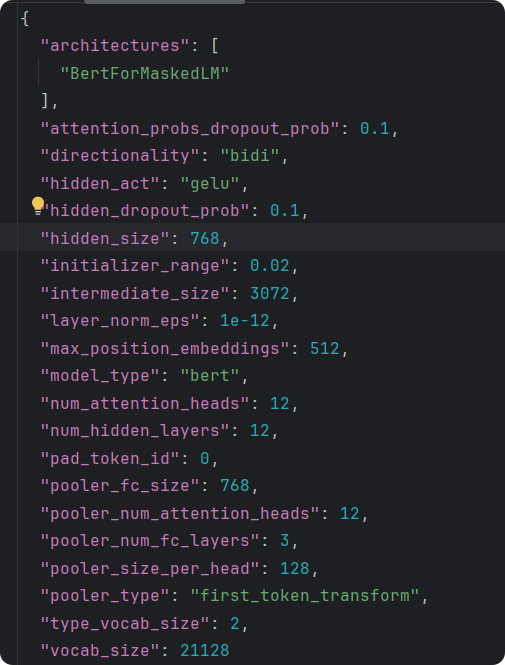
config.json是模型的配置文件,對(duì)模型做了簡(jiǎn)單說明,說明了模型的頭、模型的結(jié)構(gòu)、模型的參數(shù)。其中vocab_size說明模型最多能識(shí)別21128個(gè)字符。
special_tokens文件中包含的特殊字符,UNK就是未識(shí)別的字符串,即超出2128個(gè)字符外的識(shí)別不了的。
tokenizer_config是分詞器的配置文件。
vocab.txt是字典文件,存儲(chǔ)模型能識(shí)別出的字符。一句話在分詞器處理之后,編碼器先轉(zhuǎn)碼成字典中的數(shù)字即位置編碼大模型會(huì)把每次字轉(zhuǎn)換為字典的索引(注意這里還不是向量化)。(中文分詞和英文不一樣,英文分詞是一個(gè)單詞一分,中文是一個(gè)漢字一分)
七、你還需要知道的概念
這里的每一個(gè)名次都適合拿出來水一篇文章啊,筆者還是太懶了。~
7.1、HuggingFace
一個(gè)下載模型的社區(qū)。。。。
HuggingFace 最初成立于 2016 年,最初以聊天機(jī)器人開發(fā)起步,后來逐漸轉(zhuǎn)型為專注于開源機(jī)器學(xué)習(xí)框架和模型的平臺(tái)。如今,它已成為全球 AI 開發(fā)者社區(qū)的核心樞紐之一,致力于降低 AI 技術(shù)的使用門檻,推動(dòng)技術(shù)民主化。transformers庫、Datastes庫都是他家出的。
Model Hub 收錄了數(shù)萬種預(yù)訓(xùn)練模型,覆蓋 NLP、計(jì)算機(jī)視覺、語音處理等多個(gè)領(lǐng)域。開發(fā)者可直接下載、微調(diào)或部署模型,無需重復(fù)訓(xùn)練,大幅節(jié)省時(shí)間和計(jì)算資源。
7.2、CUDA
CUDA(Compute Unified Device Architecture)是由 NVIDIA 開發(fā)的并行計(jì)算平臺(tái)和編程模型,旨在利用 NVIDIA 圖形處理器(GPU)的強(qiáng)大算力加速計(jì)算任務(wù)。它打破了 GPU 傳統(tǒng)上僅用于圖形渲染的局限,讓開發(fā)者能夠通過編寫特定代碼,將 GPU 作為高效的并行計(jì)算處理器使用。
CUDA 是 NVIDIA GPU 算力釋放的關(guān)鍵技術(shù),它將 GPU 從圖形處理器拓展為通用計(jì)算平臺(tái),通過 CUDA開發(fā)者能夠以相對(duì)低的成本實(shí)現(xiàn)高性能計(jì)算,加速復(fù)雜任務(wù)的落地,其生態(tài)(如支持的框架、庫和工具)也在持續(xù)擴(kuò)展,成為現(xiàn)代計(jì)算基礎(chǔ)設(shè)施的重要組成部分。
7.3、Annaconda
筆者用它來管理python環(huán)境,在實(shí)際開發(fā)中不同的項(xiàng)目一般用不同的python環(huán)境。
Anaconda 是一個(gè)開源的Python/R 數(shù)據(jù)分析和科學(xué)計(jì)算平臺(tái),由 Continuum Analytics 開發(fā)(現(xiàn)屬 Anaconda, Inc.)。它本質(zhì)上是一個(gè)集成環(huán)境,內(nèi)置了數(shù)百個(gè)常用的數(shù)據(jù)科學(xué)、機(jī)器學(xué)習(xí)庫,并通過包管理工具(如 conda)和環(huán)境管理功能,解決了開發(fā)者在配置開發(fā)環(huán)境時(shí)面臨的依賴沖突、版本兼容等痛點(diǎn)。
7.4、pytroch
PyTorch 是一個(gè)開源的深度學(xué)習(xí)框架,基于 Python 語言構(gòu)建,由 Facebook AI Research(FAIR)團(tuán)隊(duì)開發(fā)并維護(hù)。它提供了靈活的張量計(jì)算(Tensor Computation)和動(dòng)態(tài)計(jì)算圖(Dynamic Computational Graph)功能,廣泛應(yīng)用于自然語言處理(NLP)、計(jì)算機(jī)視覺(CV)、語音識(shí)別等領(lǐng)域。
Transformers 庫本身是一個(gè)框架無關(guān)的庫,它支持多種深度學(xué)習(xí)后端(如 PyTorch、TensorFlow、JAX)。但在實(shí)際使用中,PyTorch 常被作為默認(rèn)后端。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)