
你應該懂的AI大模型(三)之 RAG
從本篇開始筆者會盡量多使用一些英文縮寫和單詞,不是筆者為了裝X,是為了大家在后面遇到的時候不至于被別人裝到。
一、什么是RAG
1.1 大模型的局限性
大模型的知識不是實時的,比如現在《藏海傳》已經完結了,但是我問deepseek給我的回答卻是:
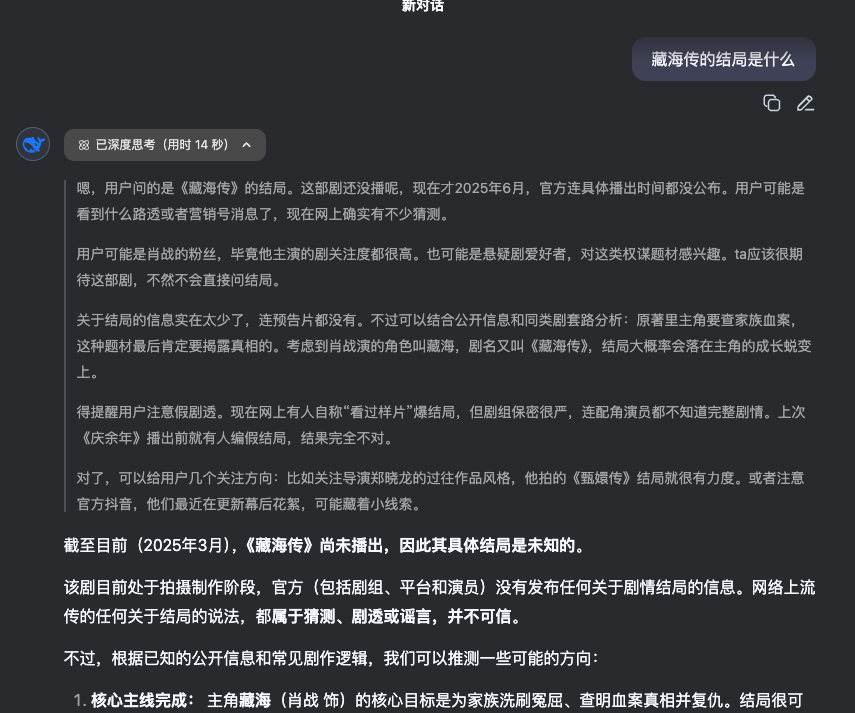
除了知識不是實時的之外,大模型可能也不知道你當前所在業務領域的知識。這就是大模型目前所固有的局限性。
1.2 檢索增強生成
為了解決大模型所固有的局限性,就有了 RAG(Retereval Augmented Generation),通過檢索的方法來增強模型的能力。
ps:筆者不知道哪種讀法是對的,有的讀 RAG 的英文字母,筆者有認識的大佬讀[r?ɡ],即 ruai ge,筆者覺著跟隨者大佬讀應該更能裝到。)
我們現在使用的 LLM(Large Language Model)是通過海量文本數據訓練得來,能夠理解和生成人類語言。也就是說當我們問大模型問題的時候大模型會從它先有的知識中得出答案回答我們,但是如果我們問一些時事或者專業領域問題的時候大模型沒有這部分知識,那么大模型就有可能會自由發揮來回答我們問題,因此我們引入 RAG 相當于給大模型進行一場開卷考試,當我們問問題的時候,大模型會“先翻書”再回答問題。
其實這就相當于給LLM戴上了緊箍咒。強制要求回答問題必須從給定的知識庫中檢索到的內容生成答案,不讓LLM憑空想象捏造答案,大大降低了模型出現幻覺的概率。

二、RAG系統的基本搭建流程

在上圖中有兩個比較新的東西,一個是Embedding模型和VectorDB,解釋以下這兩個概念:
- Embedding模型,即嵌入式模型,它的作用是將非結構化的數據(如文本、圖像、音頻)轉換成可計算的數值向量;
- Vector DB:向量數據庫,顧名思義可以理解為存儲Embedding生成的向量數據的數據庫。
拋開這兩個概念,RAG搭建的過程可以總結為以下四步:
1、文檔加載,按照一定的條件和規則將文檔切割成片段;
2、將切割的文本片段灌入檢索引擎;
3、封裝檢索接口;
4、構建調用流程:Query->檢索->Prompt->LLM->回復
三、向量檢索
3.1、什么是向量
向量是一種有大小和方向的數學對象。它可以表示為從一個點到另一個點的有向線段。例如,二維空間中的向量可以表示為 (x,y),表示從原點 (0,0) 到點 (x,y) 的有向線段。
從數學的角度看,向量是一個“有方向和大小的東西”,可以用數字坐標來描述。在計算機世界中,我們可以把向量簡單地理解為一組“有意義的數字”,用來表示事物的特征。

例如我們描述一只貓的可以描述為有胡須、有毛、會喵喵叫,這些信息轉換成向量就可以用一堆數字來表述[有胡須:0.981,有毛:0.193,會喵喵叫:0.453],每個數字都代表一個特征,這樣貓的特性就被向量化了,就能被計算機檢索出來。
文本向量就是將文本轉成一組N維的浮點數,即文本向量又叫Embeddings,向量之間可以計算距離,距離的遠近對應語義相似度的大小。

PS:文本向量是怎么計算得到的,這不是本文能講解明白的,不是筆者不想寫,是想要把這個話題拿來寫著實是有點難度。
3.2、向量間的相似度計算
向量的相似性通常通過計算向量之間的距離來比較。 距離越小,相似性越高。常用的算法比如余弦距離和歐式距離來判斷向量距離。
假設我們有兩個文本的向量:
文本1:“我感冒了” → 向量為 [0.82, 0.61, 0.97]
文本2:“我流感了” → 向量為 [0.90, 0.73, 0.98]
通過余弦相似度公式計算余弦相似性,結果越接近1,說明兩個文本的語義高度相似。

歐氏距離:越小越相似。
余弦距離:越大越相似,余弦值越大夾角越小,距離越近。
3.3、向量數據庫
Embedding Modle(嵌入模型)負責計算向量,向量數據庫負責存儲和比較向量。向量數據庫是專門為向量檢索設計的中間件!
讀到這里大家可能會覺著向量數據真厲害,簡直可以秒殺傳統的關系型數據庫,在這里告訴大家:
- 向量數據庫的意義是快速的檢索;
- 向量數據庫本身不生成向量,向量是由 Embedding 模型產生的;
- 向量數據庫與傳統的關系型數據庫是互補的,不是替代關系,在實際應用中根據實際需求經常同時使用。
大家不要盲目迷信學習大模型我們帶來的新的技術視野。
下面為大家列舉幾個常見的向量數據庫,這些向量數據庫的特點大家可自行總結:
- Chroma
- Deep Lake (Activeloop)
- Elasticsearch & OpenSearch(沒想到吧,Elasticsearch也支持向量檢索)
- Faiss (Facebook AI Similarity Search)
- LanceDB
- Milvus
- Pinecone
- PgVector (PostgreSQL 擴展)
- Qdrant
- ScaNN (Scalable Nearest Neighbors)
3.4、認識幾個Embedding模型
建議大家去HuggingFace上瞅瞅吧。。。正好不知道的同學可以了解下HuggingFace是啥,除了HuggingFace還可以逛逛阿里的魔塔社區。
四、其他可以裝到的話題
4.1、企業中落地RAG常用的向量數據庫
milvus和Qdrant。
4.2、大模型的兩個流派
RAG派和上下文窗口擴大派,這兩派的論調大家自行搜索查看就好。
在筆者看來,目前做項目能夠簡單落地的還就是RAG。
4.3、Hybird Search 混合檢索
在實際生產中,傳統的關鍵字檢索(稀疏表示)與向量檢索(稠密表示)各有優劣。舉個具體例子,比如文檔中包含很長的專有名詞,關鍵字檢索往往更精準而向量檢索容易引入概念混淆。所以,有時候我們需要結合不同的檢索算法,來達到比單一檢索算法更優的效果。這就是混合檢索。
4.4、處理PDF文檔中的表格
PDF中的表格我們怎么處理抽取,大家放心,我們能遇到的問題,大佬們肯定早就碰到了,因此有很多面向RAG的文檔解析輔助工具:
- PyMuPDF: PDF 文件處理基礎庫,帶有基于規則的表格與圖像抽取(不準)
- RAGFlow: 一款基于深度文檔理解構建的開源 RAG 引擎,支持多種文檔格式(火爆)
- Unstructured.io: 一個開源+SaaS形式的文檔解析庫,支持多種文檔格式
- LlamaParse:付費 API 服務,由 LlamaIndex 官方提供,解析不保證100%準確,實測偶有文字丟失或錯位發生
- Mathpix:付費 API 服務,效果較好,可解析段落結構、表格、公式等,貴!
五、GraphRAG
通過知識圖譜來增減檢索,即在檢索中利用圖譜的關聯性捕捉深層語義,彌補依賴向量相似度的不足。特點是小公司玩不起,都是大公司在玩。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號