
分類器案例
模型復雜程度
一、常見衡量指標
- 參數數量(Number of Parameters)
- 模型包含的可學習參數越多,復雜度越高。
- 例如:
- 線性回歸:參數個數 = 特征維數 + 1
- 深度神經網絡:每層權重矩陣大小 × 層數
- 例子:ResNet-18(約1100萬參數) vs. GPT-3(1750億參數)
- 模型容量(Model Capacity)
- 表示模型擬合各種函數的能力。
- 高容量模型可以逼近更復雜的數據分布,但也更容易過擬合。
- VC維(Vapnik–Chervonenkis Dimension)
- 理論上衡量模型的表達能力:能將多少樣本點任意劃分。
- VC維越高,模型越復雜。
- 網絡深度與寬度(Depth & Width)
- 深度:層數增加 → 表達更復雜的特征組合。
- 寬度:每層神經元數量多 → 捕獲更多模式信息。
- 正則化強度(Regularization Strength)
- L1/L2正則、Dropout、權重衰減等會有效降低模型復雜度。
二、復雜度與性能的關系
| 復雜度 | 優點 | 缺點 |
|---|---|---|
| 低(簡單模型) | 易解釋、訓練快、泛化強 | 可能欠擬合 |
| 適中 | 擬合能力強、泛化良好 | 需要調參 |
| 高(復雜模型) | 強擬合能力、可逼近復雜函數 | 易過擬合、計算量大 |
三、調控模型復雜度的方法
- 減少/增加網絡層數或神經元數
- 使用正則化(L1、L2、Dropout、早停等)
- 特征選擇或降維(PCA、特征重要性篩選)
- 模型剪枝或量化(減少冗余參數)
- 交叉驗證確定合適復雜度
四、形象理解
可以把模型復雜度比作“畫畫的筆”:
- 一支簡單的筆(線性模型)只能畫直線;
- 一套彩筆(多層神經網絡)可以畫出復雜圖案;
- 但筆太多又亂用,就容易“涂花”(過擬合)。
訓練過程
定義模型
根據觀察,寶可夢比數碼寶貝的線條要簡單,所有將圖片轉換成線條,根據線條的白色像素多少來判斷

Loss 函數
這次為什么選擇 Error rate ,因為簡單直觀,正確輸出 0 ,錯誤輸出 1

\(h^{all}\) 在Data(all)上一定小于 \(h^{train}\) ,因為 all 是所有數據訓練出來的,train 只是抽出來的部分數據,但是在其他數據集上不一定比 \(h^{train}\)小
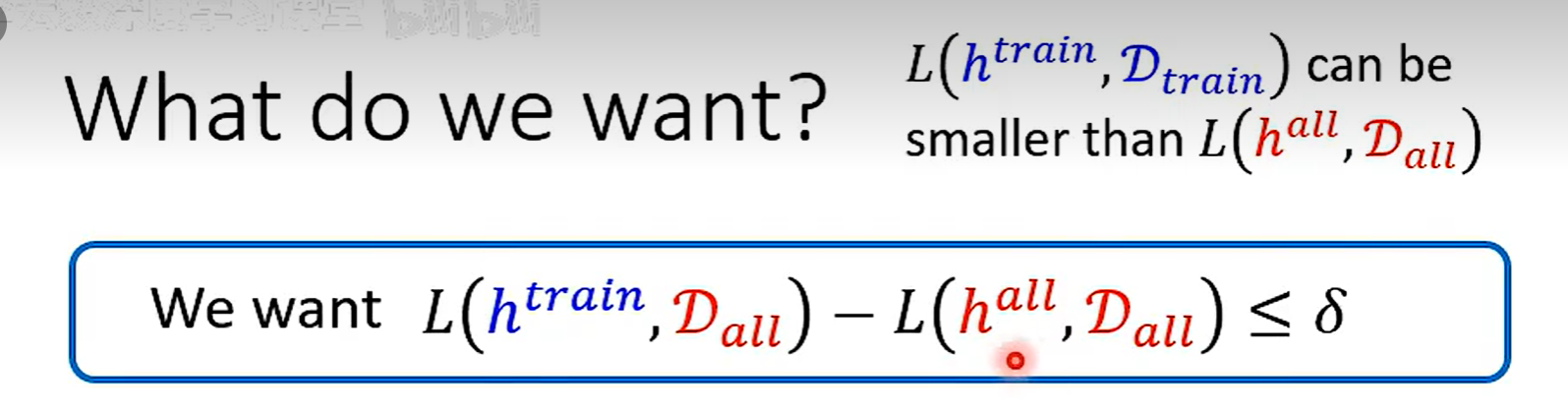
找到一個 h 在Data(train) 和Data(all)上的Loss差不多,兩個就會比較接近

訓練資料好壞
這個理論不常用,因為這個是個上限,一般 H 都會很大,算出來的一般都會大于 1
N 訓練集數
H 參數能選擇的個數
\(\epsilon\) 自己定義的參數

|H| 越小,N 越大,訓練集越好
但是H很小的時候,All 里面不一定有很好的 h 了,雖然痕接近,但是都很差
N一般收集到的資料有限


 浙公網安備 33010602011771號
浙公網安備 33010602011771號