Raft協議深度解析:RocketMQ中基于DLedger的日志主從復制
本文所涉及的注釋源碼:bigcoder84/dledger
Raft 協議主要包含兩個部分:Leader選舉和日志復制。
前面我們在 Raft協議深度解析:RocketMQ中的自動Leader選舉與故障轉移 一文中已經詳細介紹了DLedger如何實現Leader選舉的,而本文主要聚焦于Leader選舉完成后的日志復制的過程。
一. RocketMQ DLedger 存儲實現
說起日志的復制,就必須要從日志存儲實現說起,它約束著Raft每一個結點如何存儲數據。下面先介紹一次Raft存儲的核心實現類:
1.1 存儲實現核心類
-
DLedgerStore:存儲抽象類,該類有如下核心抽象方法:
- getMemberState: 獲取節點狀態機
- appendAsLeader:向主節點追加日志(數據)
- appendAsFollower:向從節點廣播日志(數據)
- get:根據日志下標查找日志
- getLedgerEndTerm:獲取Leader節點當前最大的投票輪次
- getLedgerEndIndex:獲取Leader節點下一條日志寫入的日志序號
- truncate:刪除日志
- getFirstLogOfTargetTerm:從endIndex開始,向前追溯targetTerm任期的第一個日志
- updateLedgerEndIndexAndTerm:更新 Leader 節點維護的ledgerEndIndex和ledgerEndTerm
- startup:啟動存儲管理器
- shutdown:關閉存儲管理器
-
DLedgerMemoryStore:DLedger基于內存實現的日志存儲實現類。
-
DLedgerMmapFileStore:基于文件內存映射機制的存儲實現,核心屬性如下:
- ledgerBeforeBeginIndex:日志的起始序號
- ledgerBeforeBeginTerm:日志起始的投票輪次
- ledgerEndIndex:下一條日志下標(序號)
- ledgerEndTerm:當前最大的投票輪次
-
DLedgerConfig:DLedger的配置信息
RocketMQ DLedger的上述核心類與RocketMQ存儲模塊的對應關系
| RocketMQ存儲模塊 | DLedger存儲模塊 | 描述 |
|---|---|---|
| MappedFile | DefaultMmapFile | 表示一個物理文件 |
| MappedFileQueue | MmapFileList | 表示邏輯上連續多個物理文件 |
| DefaultMessageStore | DLedgerMmapFileStore | 存儲實現類 |
| CommitLog#FlushCommitLogService | DLedgerMmapFileStore#FlushDataService | 實現文件刷盤機制 |
| DefaultMessageStore#CleanCommitLogService | DLedgerMmapFileStore#CleanSpaceService | 清理過期文件 |
1.2 數據存儲協議
RocketMQ DLedger數據存儲協議如下圖:

-
magic:魔數,4字節。
-
size:條目總長度,包含header(協議頭)+body(消息體),占4字節。
-
index:當前條目的日志序號,占8字節。
-
term:條目所屬的投票輪次,占8字節。
-
pos:條目的物理偏移量,類似CommitLog文件的物理偏移量,占8字節。
-
channel:保留字段,當前版本未使用,占4字節。
-
chain crc:當前版本未使用,占4字節。
-
body crc:消息體的CRC校驗和,用來區分數據是否損壞,占4字節。
-
body size:用來存儲消息體的長度,占4個字節。
-
body:消息體的內容。
RocketMQ DLedger 中日志實例用 DLedgerEntry 表示:
public class DLedgerEntry {
public final static int POS_OFFSET = 4 + 4 + 8 + 8;
public final static int HEADER_SIZE = POS_OFFSET + 8 + 4 + 4 + 4;
public final static int BODY_OFFSET = HEADER_SIZE + 4;
private int magic = DLedgerEntryType.NORMAL.getMagic();
private int size;
private long index;
private long term;
private long pos; //used to validate data
private int channel; //reserved
private int chainCrc; //like the block chain, this crc indicates any modification before this entry.
private int bodyCrc; //the crc of the body
private byte[] body;
}
解碼流程參考:io.openmessaging.storage.dledger.entry.DLedgerEntryCoder#decode(java.nio.ByteBuffer, boolean):
public static DLedgerEntry decode(ByteBuffer byteBuffer, boolean readBody) {
DLedgerEntry entry = new DLedgerEntry();
entry.setMagic(byteBuffer.getInt());
entry.setSize(byteBuffer.getInt());
entry.setIndex(byteBuffer.getLong());
entry.setTerm(byteBuffer.getLong());
entry.setPos(byteBuffer.getLong());
entry.setChannel(byteBuffer.getInt());
entry.setChainCrc(byteBuffer.getInt());
entry.setBodyCrc(byteBuffer.getInt());
int bodySize = byteBuffer.getInt();
if (readBody && bodySize < entry.getSize()) {
byte[] body = new byte[bodySize];
byteBuffer.get(body);
entry.setBody(body);
}
return entry;
}
1.3 索引存儲協議
RocketMQ DLedger索引的存儲協議如下圖:
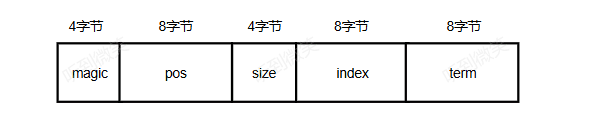
存儲協議中各個字段的含義如下。
- magic:魔數。
- pos:條目的物理偏移量,類似CommitLog文件的物理偏移量,占8字節。
- size:條目長度。
- index:當前條目的日志序號,占8字節。
- term:條目所屬的投票輪次,占8字節。
索引條目采用定長的方式進行的存儲,目的是為了加速日志條目的查找的速度。
我們假設一種場景需要查詢 index 下標對應的日志數據,由于日志條目時變長的,如果沒有索引文件,我們需要在索引文件上一個一個條目的去遍歷查找,這樣的效率很低。
有了索引文件后,我們可以通過 index * 32 找到Index所對應的索引存儲的物理偏移量,這樣我們可以輕松獲取日志索引中存儲的索引所處理的物理偏移量pos,然后通過日志的物理偏移量就可以直接獲取到日志記錄了。
RocketMQ DLedger 中索引實例用 DLedgerIndexEntry 表示:
public class DLedgerIndexEntry {
private int magic;
private long position;
private int size;
private long index;
private long term;
}
解碼流程參考:io.openmessaging.storage.dledger.entry.DLedgerEntryCoder#decodeIndex:
public static DLedgerIndexEntry decodeIndex(ByteBuffer byteBuffer) {
DLedgerIndexEntry indexEntry = new DLedgerIndexEntry();
indexEntry.setMagic(byteBuffer.getInt());
indexEntry.setPosition(byteBuffer.getLong());
indexEntry.setSize(byteBuffer.getInt());
indexEntry.setIndex(byteBuffer.getLong());
indexEntry.setTerm(byteBuffer.getLong());
return indexEntry;
}
二. RocketMQ DLedger主從切換之日志追加
Raft協議負責組主要包含兩個步驟:Leader選舉和日志復制。使用Raft協議的集群在向外提供服務之前需要先在集群中進行Leader選舉,推舉一個主節點接受客戶端的讀寫請求。Raft協議負責組的其他節點只需要復制數據,不對外提供服務。當Leader節點接受客戶端的寫請求后,先將數據存儲在Leader節點上,然后將日志數據廣播給它的從節點,只有超過半數的節點都成功存儲了該日志,Leader節點才會向客戶端返回寫入成功。
2.1 日志追加流程概述
Leader節點處理日志寫入請求的入口為DLedgerServer的handleAppend()方法:
// io.openmessaging.storage.dledger.DLedgerServer#handleAppend
@Override
public CompletableFuture<AppendEntryResponse> handleAppend(AppendEntryRequest request) throws IOException {
try {
// 如果請求目的節點不是當前節點,返回錯誤
PreConditions.check(memberState.getSelfId().equals(request.getRemoteId()), DLedgerResponseCode.UNKNOWN_MEMBER, "%s != %s", request.getRemoteId(), memberState.getSelfId());
// 如果請求的集群不是當前節點所在的集群,則返回錯誤
PreConditions.check(memberState.getGroup().equals(request.getGroup()), DLedgerResponseCode.UNKNOWN_GROUP, "%s != %s", request.getGroup(), memberState.getGroup());
// 如果當前節點不是leader節點,則拋出異常
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
PreConditions.check(memberState.getTransferee() == null, DLedgerResponseCode.LEADER_TRANSFERRING);
long currTerm = memberState.currTerm();
// 消息的追加是一個異步的過程,會將內容暫存到內存隊列中。首先檢查內存隊列是否已滿,如果已滿則向客戶端返回錯誤碼,表示本次發送失敗。如果未滿,
// 則先將數據追加到Leader節點的PageCache中,然后轉發到Leader的所有從節點,最后Leader節點等待從節點日志復制結果。
if (dLedgerEntryPusher.isPendingFull(currTerm)) {
AppendEntryResponse appendEntryResponse = new AppendEntryResponse();
appendEntryResponse.setGroup(memberState.getGroup());
appendEntryResponse.setCode(DLedgerResponseCode.LEADER_PENDING_FULL.getCode());
appendEntryResponse.setTerm(currTerm);
appendEntryResponse.setLeaderId(memberState.getSelfId());
return AppendFuture.newCompletedFuture(-1, appendEntryResponse);
}
AppendFuture<AppendEntryResponse> future;
if (request instanceof BatchAppendEntryRequest) {
BatchAppendEntryRequest batchRequest = (BatchAppendEntryRequest) request;
if (batchRequest.getBatchMsgs() == null || batchRequest.getBatchMsgs().isEmpty()) {
throw new DLedgerException(DLedgerResponseCode.REQUEST_WITH_EMPTY_BODYS, "BatchAppendEntryRequest" +
" with empty bodys");
}
// 將消息追加到Leader節點中
future = appendAsLeader(batchRequest.getBatchMsgs());
} else {
// 將消息追加到Leader節點中
future = appendAsLeader(request.getBody());
}
return future;
} catch (DLedgerException e) {
LOGGER.error("[{}][HandleAppend] failed", memberState.getSelfId(), e);
AppendEntryResponse response = new AppendEntryResponse();
response.copyBaseInfo(request);
response.setCode(e.getCode().getCode());
response.setLeaderId(memberState.getLeaderId());
return AppendFuture.newCompletedFuture(-1, response);
}
}
第一步:驗證請求的合理性。
- 如果請求目的節點不是當前節點,返回錯誤。
- 如果請求的集群不是當前節點所在的集群,則返回錯誤。
- 如果當前節點不是leader節點,則拋出異常。
第二步:消息的追加是一個異步過程,會將內容暫存到內存隊列中。首先檢查內存隊列是否已滿,如果已滿則向客戶端返回錯誤碼,表示本次消息發送失敗。如果隊列未滿,則先將數據追加到Leader節點的PageCache中,然后轉發給Leader的所有從節點,最后Leader節點等待從節點日志復制的結果。
// io.openmessaging.storage.dledger.DLedgerServer#appendAsLeader(java.util.List<byte[]>)
public AppendFuture<AppendEntryResponse> appendAsLeader(List<byte[]> bodies) throws DLedgerException {
// 判斷當前節點是否是Leader,如果不是則報錯
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
// 消息不能為空
if (bodies.size() == 0) {
return AppendFuture.newCompletedFuture(-1, null);
}
AppendFuture<AppendEntryResponse> future;
StopWatch watch = StopWatch.createStarted();
DLedgerEntry entry = new DLedgerEntry();
long totalBytes = 0;
if (bodies.size() > 1) {
long[] positions = new long[bodies.size()];
// 追加多個消息
for (int i = 0; i < bodies.size(); i++) {
totalBytes += bodies.get(i).length;
DLedgerEntry dLedgerEntry = new DLedgerEntry();
dLedgerEntry.setBody(bodies.get(i));
entry = dLedgerStore.appendAsLeader(dLedgerEntry);
positions[i] = entry.getPos();
}
// only wait last entry ack is ok
future = new BatchAppendFuture<>(positions);
} else {
DLedgerEntry dLedgerEntry = new DLedgerEntry();
totalBytes += bodies.get(0).length;
dLedgerEntry.setBody(bodies.get(0));
// 底層調用 appendAsLeader 追加日志
entry = dLedgerStore.appendAsLeader(dLedgerEntry);
future = new AppendFuture<>();
}
final DLedgerEntry finalResEntry = entry;
final AppendFuture<AppendEntryResponse> finalFuture = future;
final long totalBytesFinal = totalBytes;
finalFuture.handle((r, e) -> {
if (e == null && r.getCode() == DLedgerResponseCode.SUCCESS.getCode()) {
Attributes attributes = DLedgerMetricsManager.newAttributesBuilder().build();
// 監控上報
DLedgerMetricsManager.appendEntryLatency.record(watch.getTime(TimeUnit.MICROSECONDS), attributes);
DLedgerMetricsManager.appendEntryBatchCount.record(bodies.size(), attributes);
DLedgerMetricsManager.appendEntryBatchBytes.record(totalBytesFinal, attributes);
}
return r;
});
Closure closure = new Closure() {
@Override
public void done(Status status) {
AppendEntryResponse response = new AppendEntryResponse();
response.setGroup(DLedgerServer.this.memberState.getGroup());
response.setTerm(DLedgerServer.this.memberState.currTerm());
response.setIndex(finalResEntry.getIndex());
response.setLeaderId(DLedgerServer.this.memberState.getLeaderId());
response.setPos(finalResEntry.getPos());
response.setCode(status.code.getCode());
finalFuture.complete(response);
}
};
dLedgerEntryPusher.appendClosure(closure, finalResEntry.getTerm(), finalResEntry.getIndex());
return finalFuture;
}
日志追加時會有兩種模式:單條追加和批量追加。appendAsLeader 方法主要將兩種模式的追加進行統一封裝,最后調用 DLedgerStore#appendAsLeader 將日志存儲到指定位置。
2.2 Leader節點日志存儲
Leader節點的數據存儲主要由DLedgerStore的appendAsLeader() 方法實現。DLedger提供了基于內存和基于文件兩種持久化實現,本節重點關注基于文件的存儲實現方法,其實現類為 DLedgerMmapFileStore。
// io.openmessaging.storage.dledger.store.file.DLedgerMmapFileStore#appendAsLeader
@Override
public DLedgerEntry appendAsLeader(DLedgerEntry entry) {
// 第一步:判斷當前節點是否是Leader,如果不是則報錯
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
// 第二步:判斷磁盤是否已滿
PreConditions.check(!isDiskFull, DLedgerResponseCode.DISK_FULL);
// 從本地線程變量中獲取一個存儲數據用的ByteBuffer和一個存儲索引用的ByteBuffer。存儲數據用的ByteBuffer大小為4MB,存儲索引用的ByteBuffer大小為64B。
ByteBuffer dataBuffer = localEntryBuffer.get();
ByteBuffer indexBuffer = localIndexBuffer.get();
// 對客戶端發來的日志進行編碼,并將編碼后的日志數據寫入ByteBuffer中。
DLedgerEntryCoder.encode(entry, dataBuffer);
int entrySize = dataBuffer.remaining();
// 鎖定狀態機
synchronized (memberState) {
// 再一次判斷是否是Leader節點
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER, null);
PreConditions.check(memberState.getTransferee() == null, DLedgerResponseCode.LEADER_TRANSFERRING, null);
// 為當前日志條目設置序號、投票輪次等信息
long nextIndex = ledgerEndIndex + 1;
entry.setIndex(nextIndex);
entry.setTerm(memberState.currTerm());
// 將當前日志(包括序號、投票輪次等)寫入索引ByteBuffer中。
DLedgerEntryCoder.setIndexTerm(dataBuffer, nextIndex, memberState.currTerm(), entry.getMagic());
// 計算消息的起始物理偏移量,與CommitLog文件的物理偏移量設計思想相同
long prePos = dataFileList.preAppend(dataBuffer.remaining());
entry.setPos(prePos);
PreConditions.check(prePos != -1, DLedgerResponseCode.DISK_ERROR, null);
// 將該偏移量寫入數據ByteBuffer中
DLedgerEntryCoder.setPos(dataBuffer, prePos);
for (AppendHook writeHook : appendHooks) {
writeHook.doHook(entry, dataBuffer.slice(), DLedgerEntry.BODY_OFFSET);
}
// 調用DataFileList的append方法,將日志追加到PageCache中,此時數據還沒有刷寫到硬盤中。
long dataPos = dataFileList.append(dataBuffer.array(), 0, dataBuffer.remaining());
PreConditions.check(dataPos != -1, DLedgerResponseCode.DISK_ERROR, null);
PreConditions.check(dataPos == prePos, DLedgerResponseCode.DISK_ERROR, null);
DLedgerEntryCoder.encodeIndex(dataPos, entrySize, DLedgerEntryType.NORMAL.getMagic(), nextIndex, memberState.currTerm(), indexBuffer);
// 將索引的ByteBuffer寫入PageCache中
long indexPos = indexFileList.append(indexBuffer.array(), 0, indexBuffer.remaining(), false);
PreConditions.check(indexPos == entry.getIndex() * INDEX_UNIT_SIZE, DLedgerResponseCode.DISK_ERROR, null);
if (LOGGER.isDebugEnabled()) {
LOGGER.info("[{}] Append as Leader {} {}", memberState.getSelfId(), entry.getIndex(), entry.getBody().length);
}
// 日志序號+1
ledgerEndIndex++;
// 記錄當前最大的投票輪次
ledgerEndTerm = memberState.currTerm();
updateLedgerEndIndexAndTerm();
return entry;
}
}
在該方法中,主要執行以下邏輯:
- 檢查Leader狀態:首先,方法檢查當前節點是否是集群中的Leader節點,如果不是則拋出錯誤。
- 檢查磁盤空間:接著,檢查磁盤是否已滿,如果已滿則拋出錯誤。
- 獲取緩沖區:從本地線程變量中獲取用于存儲數據和索引的ByteBuffer,數據緩沖區大小為4MB,索引緩沖區大小為64B。
- 編碼日志條目:將傳入的日志條目進行編碼,并寫入數據ByteBuffer中。
- 設置日志條目信息:在同步塊中,再次檢查Leader狀態,確保沒有發生領導者轉移。然后為日志條目設置索引、投票輪次等信息。
- 計算物理偏移量:計算日志條目的起始物理偏移量,并設置到日志條目中。
- 執行寫入鉤子:如果有注冊的寫入鉤子(AppendHook),則執行這些鉤子。
- 追加數據到PageCache:將編碼后的數據追加到PageCache中,需要注意此時數據尚未寫入硬盤。
- 編碼索引信息:將索引信息編碼,包括數據位置、日志大小、日志類型、索引和投票輪次。
- 寫入索引到PageCache:將索引信息追加到索引文件列表的PageCache中。
- 日志和索引位置檢查:檢查索引寫入的位置是否正確。
- 更新日志存儲狀態:更新日志的結束索引和投票輪次,并將這些信息持久化。
- 返回日志條目:最后,方法返回追加的日志條目。
日志追加到Leader節點的PageCache后,將異步轉發給它所有的從節點,然后等待各從節點的反饋,并對這些反饋結果進行仲裁,只有集群內超過半數的節點存儲了該條日志,Leader節點才可以向客戶端返回日志寫入成功,日志的復制將在后面詳細介紹,在介紹Leader節點如何等待從節點復制、響應ACK之前,我們再介紹一下與存儲相關的兩個核心方法:DataFileList的preAppend()與append()方法。
2.2.1 DataFileList#preAppend
DataFileList的preAppend()方法為預寫入,主要是根據當前日志的長度計算該條日志的物理偏移量:
// io.openmessaging.storage.dledger.store.file.MmapFileList#preAppend(int, boolean)
/**
* 日志預寫入,主要是根據當前日志的長度計算該條日志的物理偏移量,該方法主要處理寫入動作處于文件末尾的場景。
* 因為會存在日志寫入時,當前文件容納不下的情況,如果出現這種情況會新建一個新的文件,并返回新文件的起始位置作為寫入位置。
*
* @param len 需要申請的長度
* @param useBlank 是否需要填充
* @return
*/
public long preAppend(int len, boolean useBlank) {
// 獲取邏輯文件中最后一個物理文件
MmapFile mappedFile = getLastMappedFile();
if (null == mappedFile || mappedFile.isFull()) {
mappedFile = getLastMappedFile(0);
}
if (null == mappedFile) {
LOGGER.error("Create mapped file for {}", storePath);
return -1;
}
int blank = useBlank ? MIN_BLANK_LEN : 0;
if (len + blank > mappedFile.getFileSize() - mappedFile.getWrotePosition()) {
// 如果當前文件剩余空間已不足以存放一條消息
if (blank < MIN_BLANK_LEN) {
// 如果當前文件剩余的空間少于MIN_BLANK_LEN,將返回-1,表 示存儲錯誤,需要人工干預,正常情況下是不會出現這種情況的,
// 因為寫入一條消息之前會確保能容納待寫入的消息,并且還需要空余MIN_BLANK_LEN個字節,因為一個獨立的物理文件,
// 默認會填充文件結尾魔數(BLANK_MAGIC_CODE)。
LOGGER.error("Blank {} should ge {}", blank, MIN_BLANK_LEN);
return -1;
} else {
// 如果空余空間大于MIN_BLANK_LEN,會首先寫入文件結尾魔數(4字節),然后將該文件剩余的字節數寫入接下來的4個字節,表示該文件全部用完。
// 后面創建一個新文件,使得當前日志能夠寫入新的文件中。
ByteBuffer byteBuffer = ByteBuffer.allocate(mappedFile.getFileSize() - mappedFile.getWrotePosition());
byteBuffer.putInt(BLANK_MAGIC_CODE);
byteBuffer.putInt(mappedFile.getFileSize() - mappedFile.getWrotePosition());
if (mappedFile.appendMessage(byteBuffer.array())) {
//need to set the wrote position
// 將寫指針置入文件末尾,這樣在下一次調用 getLastMappedFile 方法時就會創建一個新的文件
mappedFile.setWrotePosition(mappedFile.getFileSize());
} else {
LOGGER.error("Append blank error for {}", storePath);
return -1;
}
// 如果文件以寫滿,這里會創建一個新的文件,
mappedFile = getLastMappedFile(0);
if (null == mappedFile) {
LOGGER.error("Create mapped file for {}", storePath);
return -1;
}
}
}
// 如果當前文件有剩余的空間容納當前日志,則返回待寫入消息的物理起始偏移量
return mappedFile.getFileFromOffset() + mappedFile.getWrotePosition();
}
- 如果當前文件剩余的空間少于MIN_BLANK_LEN,將返回-1,表示存儲錯誤,需要人工干預,正常情況下是不會出現這種情況的,因為寫入一條消息之前會確保能容納待寫入的消息,并且還需要空余 MIN_BLANK_LEN 個字節,因為一個獨立的物理文件,默認會填充文件結尾魔數(BLANK_MAGIC_CODE)。
- 如果空余空間大于MIN_BLANK_LEN,會首先寫入文件結尾魔數(4字節),然后將該文件剩余的字節數寫入接下來的4個字節,表示該文件全部用完。然后創建一個新的文件,并返回新文件的起始位置,表示這條日志寫入新文件起始位置。
2.2.2 DataFileList#append
//io.openmessaging.storage.dledger.store.file.MmapFileList#append(byte[], int, int, boolean)
public long append(byte[] data, int pos, int len, boolean useBlank) {
if (preAppend(len, useBlank) == -1) {
return -1;
}
MmapFile mappedFile = getLastMappedFile();
long currPosition = mappedFile.getFileFromOffset() + mappedFile.getWrotePosition();
// 追加數據至文件末尾
if (!mappedFile.appendMessage(data, pos, len)) {
LOGGER.error("Append error for {}", storePath);
return -1;
}
return currPosition;
}
// io.openmessaging.storage.dledger.store.file.DefaultMmapFile#appendMessage(byte[], int, int)
/**
* Content of data from offset to offset + length will be written to file.
*
* @param offset The offset of the subarray to be used.
* @param length The length of the subarray to be used.
*/
@Override
public boolean appendMessage(final byte[] data, final int offset, final int length) {
int currentPos = this.wrotePosition;
if ((currentPos + length) <= this.fileSize) {
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
byteBuffer.position(currentPos);
byteBuffer.put(data, offset, length);
WROTE_POSITION_UPDATER.addAndGet(this, length);
return true;
}
return false;
}
三. RocketMQ DLedger 主從切換之日志復制
Leader節點首先將客戶端發送過來的日志按照指定格式存儲在Leader節點上,但此時并不會向客戶端返回寫入成功,而是需要將日志轉發給它的所有從節點,只有超過半數的節點都存儲了該條日志,Leader節點才會向客戶端返回日志寫入成功。
日志的復制主要包括如下3個步驟:
- Leader節點將日志推送到從節點。
- 從節點收到Leader節點推送的日志并存儲,然后向Leader節點匯報日志復制結果。
- Leader節點對日志復制進行仲裁,如果成功存儲該條日志的節點超過半數,則向客戶端返回寫入成功。
3.1 日志復制設計理念
3.1.1 日志編號
為了方便對日志進行管理與辨別,Raft協議對每條日志進行編號,每一條消息到達主節點時會生成一個全局唯一的遞增號,這樣可以根據日志序號來快速判斷日志中的數據在主從復制過程中是否保持一致,在 DLedger 的實現中對應 DLedgerMemoryStore 中的 ledgerBeforeBeginIndex、ledgerEndIndex,分別表示當前節點最小的日志序號與最大的日志序號,下一條日志的序號為ledgerEndIndex+1。
3.1.2 日志追加與提交機制
Leader節點收到客戶端的數據寫入請求后,先通過解析請求提取數據,構建日志對象,并生成日志序號,用seq表示。然后將日志存儲到Leader節點內,將日志廣播(推送)給其所有從節點。這個過程存在網絡延時,如果客戶端向主節點查詢日志序號為seq的日志,日志已經存儲在Leader節點中了,直接返回給客戶端顯然是有問題的,這是因為網絡等原因導致從節點未能正常存儲該日志,導致數據不一致,該如何避免出現這個問題呢?
為了解決上述問題,DLedger引入了已提交指針(committedIndex)。當主節點收到客戶端的請求時,先將數據進行存儲,此時數據是未提交的,這一過程被稱為日志追加(已在第四節中介紹了),此時該條日志對客戶端不可見,只有當集群內超過半數的節點都將日志追加完成后,才會更新committedIndex指針,該條日志才會向客戶端返回寫入成功。一條日志被提交成功的充分必要條件是已超過集群內半數節點成功追加日志。
3.1.3 保證日志一致性
一個擁有3個節點的Raft集群,只需要主節點和其中一個從節點成功追加日志,就可以認為是成功提交了日志,客戶端即可通過主節點訪問該日志。因為部分數據存在延遲,所以在DLedger的實現中,讀寫請求都將由Leader節點負責。那么落后的從節點如何再次跟上集群的進度呢?
DLedger的實現思路是按照日志序號向從節點源源不斷地轉發日志,從節點接收日志后,將這些待追加的數據放入一個待寫隊列。從節點并不是從掛起隊列中處理一個個追加請求的,而是先查找從節點當前已追加的最大日志序號,用ledgerEndIndex表示,然后嘗試追加ledgerEndIndex+1的日志,根據日志序號從待寫隊列中查找日志,如果該隊列不為空,并且待寫日志不在待寫隊列中,說明從節點未接收到這條日志,發生了數據缺失。從節點在響應主節點的append請求時會告知數據不一致,然后主節點的日志轉發線程狀態變更為COMPARE,向該從節點發送COMPARE命令,用來比較主從節點的數據差異。根據比較出的差異重新從主節點同步數據或刪除從節點上多余的數據,最終達到一致。同時,主節點也會對推送超時的消息發起重推,盡最大可能幫助從節點及時更新到主節點的數據。
3.2 日志復制類設計體系
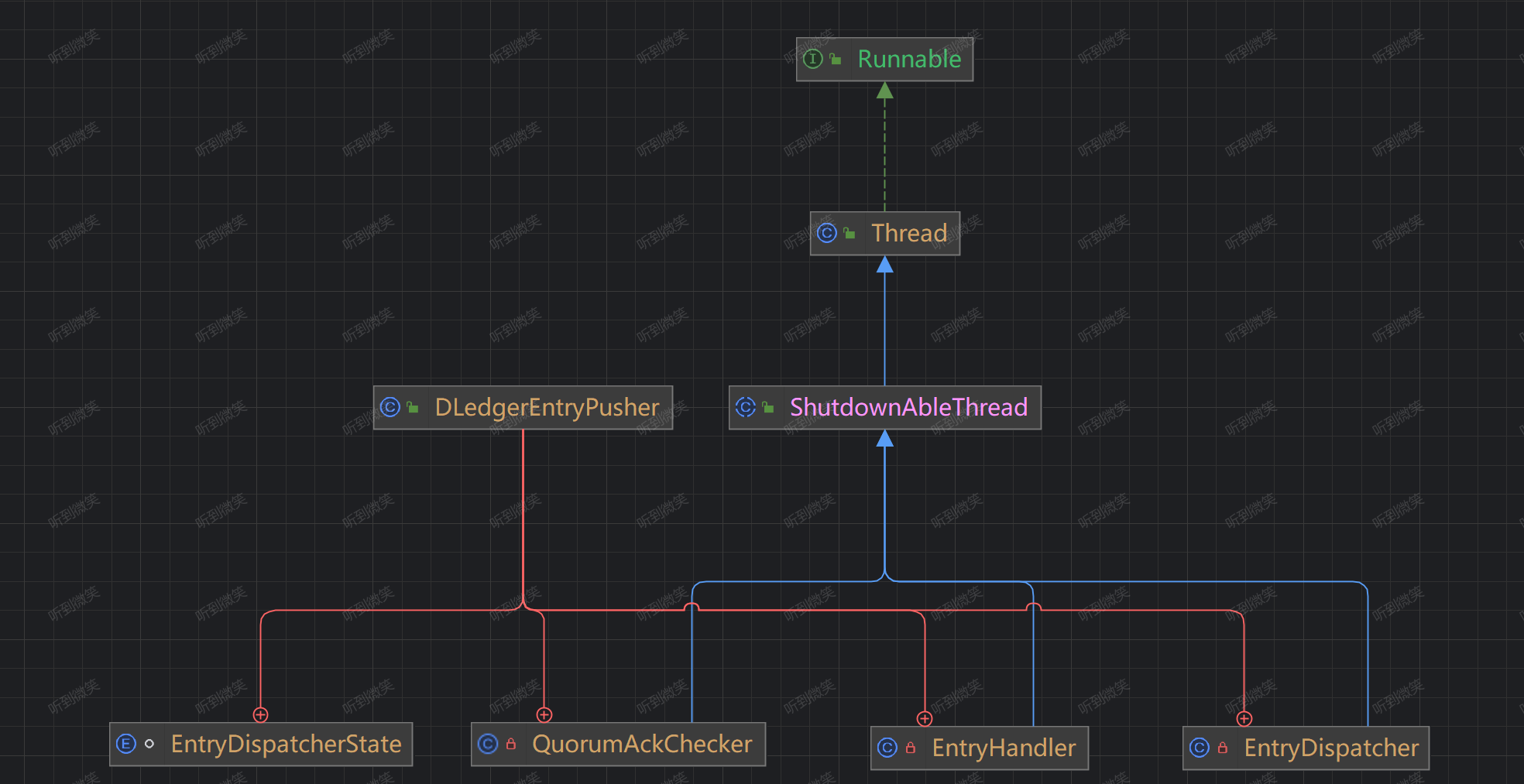
DledgerEntryPusher 是 DLedger 日志轉發與處理核心類,該類構建如下3個對象,每一個對象對應一個線程,復制處理不同的事情:
-
EntryDispatcher:日志轉發線程,當前節點為主節點時追加。
-
QuorumAckChecker:日志追加ACK投票仲裁線程,當前節點為主節點時激活。
-
EntryHandler:日志接收處理線程,當節點為從節點時激活。
DLedger的日志復制使用推送模式,其核心入口為DLedgerEntryPusher,下面逐一介紹上述核心類及核心屬性:
public class DLedgerEntryPusher {
private static final Logger LOGGER = LoggerFactory.getLogger(DLedgerEntryPusher.class);
/**
* 多副本相關配置。
*/
private final DLedgerConfig dLedgerConfig;
/**
* 存儲實現類。
*/
private final DLedgerStore dLedgerStore;
/**
* 節點狀態機。
*/
private final MemberState memberState;
/**
* RPC 服務實現類,用于集群內的其他節點進行網絡通訊。
*/
private final DLedgerRpcService dLedgerRpcService;
/**
* 每個節點基于投票輪次的當前水位線標記。
* 用于記錄從節點已復制的日志序號
*/
private final Map<Long/*term*/, ConcurrentMap<String/*peer id*/, Long/*match index*/>> peerWaterMarksByTerm = new ConcurrentHashMap<>();
/**
* 正在處理的 apend 請求的回調函數。放在這里的index所指向的日志是待確認的日志,也就是說客戶端目前正處在阻塞狀態,等待從節點接收日志。
*
* 當日志寫入Leader節點后,會異步將日志發送給Follower節點,當集群中大多數節點成功寫入該日志后,會回調這里暫存的回調函數,從而返回客戶端成功寫入的狀態。
*/
private final Map<Long/*term*/, ConcurrentMap<Long/*index*/, Closure/*upper callback*/>> pendingClosure = new ConcurrentHashMap<>();
/**
* 從節點上開啟的線程,用于接收主節點的 push 請求(append、commit)。
*/
private final EntryHandler entryHandler;
/**
* 日志追加ACK投票仲裁線程,用于判斷日志是否可提交,當前節點為主節點時激活
*/
private final QuorumAckChecker quorumAckChecker;
/**
* 日志請求轉發器,負責向從節點轉發日志,主節點為每一個從節點構建一個EntryDispatcher,EntryDispatcher是一個線程
*/
private final Map<String/*peer id*/, EntryDispatcher/*entry dispatcher for each peer*/> dispatcherMap = new HashMap<>();
/**
* 當前節點的ID
*/
private final String selfId;
/**
* 通過任務隊列修改狀態機狀態,保證所有修改狀態機狀態的任務按順序執行
*/
private StateMachineCaller fsmCaller;
}
通常了解一個類需要從其構造函數開始,我們先看一下DLedgerEntryPusher的構造函數:
public DLedgerEntryPusher(DLedgerConfig dLedgerConfig, MemberState memberState, DLedgerStore dLedgerStore,
DLedgerRpcService dLedgerRpcService) {
this.dLedgerConfig = dLedgerConfig;
this.selfId = this.dLedgerConfig.getSelfId();
this.memberState = memberState;
this.dLedgerStore = dLedgerStore;
this.dLedgerRpcService = dLedgerRpcService;
// 為每一個Follower節點創建一個EntryDispatcher線程,復制向Follower節點推送日志
for (String peer : memberState.getPeerMap().keySet()) {
if (!peer.equals(memberState.getSelfId())) {
dispatcherMap.put(peer, new EntryDispatcher(peer, LOGGER));
}
}
this.entryHandler = new EntryHandler(LOGGER);
this.quorumAckChecker = new QuorumAckChecker(LOGGER);
}
這里主要是根據集群的配置,為每一個從節點創建一個 EntryDispatcher 轉發線程,即每一個從節點的日志轉發相互不干擾。
接下來我們看一下 startup 方法:
// io.openmessaging.storage.dledger.DLedgerEntryPusher#startup
public void startup() {
// 啟動 EntryHandler,負責接受Leader節點推送的日志,如果節點不是Follower節點現成也會啟動,但是不會執行任何邏輯,直到身份變成Follower節點。
entryHandler.start();
// 啟動 日志追加ACK投票仲裁線程,用于判斷日志是否可提交,當前節點為Leader節點時激活
quorumAckChecker.start();
// 啟動 日志分發線程,用于向Follower節點推送日志,當前節點為Leader節點時激活
for (EntryDispatcher dispatcher : dispatcherMap.values()) {
dispatcher.start();
}
}
在 EntryDispatcher 啟動時會啟動三類線程:
- EntryDispatcher:日志請求轉發器,負責向從節點轉發日志,主節點為每一個從節點構建一個 EntryDispatcher 線程,每個從節點獨立發送互不干擾;
- QuorumAckChecker:日志追加ACK投票仲裁線程,用于判斷日志是否可提交,當前節點為主節點時激活;
- EntryHandler:從節點上開啟的線程,用于接收主節點的 push 請求(append、commit);
需要注意的是由于節點身份的不同所生效的線程類型也并不相同,你如如果是Follower節點,那就只有 EntryHandler 現成生效,沒有生效的線程會間隔1ms進行空轉,這樣做的目的是當節點身份發生變化時能及時反應。
3.3 日志轉發(Leader向Follower發送日志)
3.3.1 EntryDispatcher核心屬性
日志轉發由 EntryDispatcher 實現,EntryDispatcher 有如下核心屬性:
private class EntryDispatcher extends ShutdownAbleThread {
/**
* 向從節點發送命令的類型
*/
private final AtomicReference<EntryDispatcherState> type = new AtomicReference<>(EntryDispatcherState.COMPARE);
/**
* 上一次發送commit請求的時間戳。
*/
private long lastPushCommitTimeMs = -1;
/**
* 目標節點ID
*/
private final String peerId;
/**
* 已寫入的日志序號
*/
private long writeIndex = DLedgerEntryPusher.this.dLedgerStore.getLedgerEndIndex() + 1;
/**
* the index of the last entry to be pushed to this peer(initialized to -1)
*/
private long matchIndex = -1;
private final int maxPendingSize = 1000;
/**
* Leader節點當前的投票輪次
*/
private long term = -1;
/**
* Leader節點ID
*/
private String leaderId = null;
/**
* 上次檢測泄露的時間,所謂泄露,指的是掛起的日志請求數量超過了maxPendingSize。
*/
private long lastCheckLeakTimeMs = System.currentTimeMillis();
/**
* 記錄日志的掛起時間,key表示日志的序列(entryIndex),value表示掛起時間戳。
*/
private final ConcurrentMap<Long/*index*/, Pair<Long/*send timestamp*/, Integer/*entries count in req*/>> pendingMap = new ConcurrentHashMap<>();
/**
* 需要批量push的日志數據
*/
private final PushEntryRequest batchAppendEntryRequest = new PushEntryRequest();
private long lastAppendEntryRequestSendTimeMs = -1;
/**
* 配額。
*/
private final Quota quota = new Quota(dLedgerConfig.getPeerPushQuota());
.........
}
3.3.2 推送請求類型
在詳細介紹日志轉發流程之前,先介紹一下主節點向從節點發送推送請求的類型,在 PushEntryRequest.Type 中定義,可選值如下:
// io.openmessaging.storage.dledger.protocol.PushEntryRequest.Type
public enum Type {
APPEND,
COMMIT,
COMPARE,
TRUNCATE,
INSTALL_SNAPSHOT
}
- APPEND:將日志條目追加到從節點。
- COMMIT:通常Leader節點會將提交的索引附加到append請求, 如果append請求很少且分散,Leader節點將發送一個單獨的請求來通 知從節點提交索引。
- COMPARE:如果Leader節點發生變化,新的Leader節點需要與它的從節點日志條目進行比較,以便截斷從節點多余的數據。
- TRUNCATE:如果Leader節點通過索引完成日志對比后,發現從節點存在多余的數據(未提交的數據),則 Leader 節點將發送 TRUNCATE給它的從節點,刪除多余的數據,實現主從節點數據一致性。
- INSTALL_SNAPSHOT:將從節點數據存入快照。
3.3.3 Leader節點日志轉發入口
EntryDispatcher 是一個線程類,繼承自 ShutdownAbleThread,其 run() 方法會循環執行 doWork() 方法:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#doWork
@Override
public void doWork() {
try {
// 檢查當前節點狀態
if (checkNotLeaderAndFreshState()) {
waitForRunning(1);
return;
}
switch (type.get()) {
// 根據類型,做不同的操作
case COMPARE:
doCompare();
break;
case TRUNCATE:
doTruncate();
break;
case APPEND:
doAppend();
break;
case INSTALL_SNAPSHOT:
doInstallSnapshot();
break;
case COMMIT:
doCommit();
break;
}
waitForRunning(1);
} catch (Throwable t) {
DLedgerEntryPusher.LOGGER.error("[Push-{}]Error in {} writeIndex={} matchIndex={}", peerId, getName(), writeIndex, matchIndex, t);
changeState(EntryDispatcherState.COMPARE);
DLedgerUtils.sleep(500);
}
}
該方法主要完成如下兩件事。
-
檢查當前節點的狀態,確定當前節點狀態是否可以發送 append、compare、truncate 請求。
-
根據當前轉發器的狀態向從節點發送 append、compare、truncate 請求。
checkAndFreshState()方法不只是簡單地檢測一下狀態,而是會根據運行狀態改變日志轉發器的狀態,從而驅動轉發器是發送 append 請求還是發送compare請求,下面詳細看一下該方法的實現細節:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#checkNotLeaderAndFreshState
private boolean checkNotLeaderAndFreshState() {
if (!memberState.isLeader()) {
// 如果當前節點的狀態不是Leader則直接返回。
return true;
}
if (term != memberState.currTerm() || leaderId == null || !leaderId.equals(memberState.getLeaderId())) {
// 如果日志轉發器(EntryDispatcher)的投票輪次為空或與狀態機的投票輪次不相等,
// 將日志轉發器的term、leaderId與狀態機同步,即發送compare請求。這種情況通常
// 是由于集群觸發了重新選舉,當前節點剛被選舉成 Leader節點。
synchronized (memberState) {
if (!memberState.isLeader()) {
return true;
}
PreConditions.check(memberState.getSelfId().equals(memberState.getLeaderId()), DLedgerResponseCode.UNKNOWN);
logger.info("[Push-{}->{}]Update term: {} and leaderId: {} to new term: {}, new leaderId: {}", selfId, peerId, term, leaderId, memberState.currTerm(), memberState.getLeaderId());
term = memberState.currTerm();
leaderId = memberState.getSelfId();
// 改變日志轉發器的狀態,該方法非常重要
changeState(EntryDispatcherState.COMPARE);
}
}
return false;
}
如果當前節點的狀態不是Leader則直接返回;如果日志轉發器(EntryDispatcher)的投票輪次為空或與狀態機的投票輪次不相等,這種情況通常是由于集群觸發了重新選舉,當前節點剛被選舉成 Leader節點,此時需要將日志轉發器的term、leaderId與狀態機同步,然后將同步模式改為Compare,目的是讓新上任的Leader節點尋找自己與Follower節點的共識點在哪,說白了就是找到其他 Follower 節點多余未提交的的日志Index,為后續 truncate 請求做鋪墊。
changeState改變日志轉發器的狀態,該方法非常重要,我們來看一下狀態轉換過程中需要處理的核心邏輯:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#changeState
private synchronized void changeState(EntryDispatcherState target) {
logger.info("[Push-{}]Change state from {} to {}, matchIndex: {}, writeIndex: {}", peerId, type.get(), target, matchIndex, writeIndex);
switch (target) {
case APPEND:
resetBatchAppendEntryRequest();
break;
case COMPARE:
if (this.type.compareAndSet(EntryDispatcherState.APPEND, EntryDispatcherState.COMPARE)) {
writeIndex = dLedgerStore.getLedgerEndIndex() + 1;
pendingMap.clear();
}
break;
default:
break;
}
type.set(target);
}
3.3.4 Leader節點發送Compare請求(doCompare)
日志轉發器EntryDispatcher的初始狀態為 COMPARE,當一個節點被選舉為Leader后,日志轉發器的狀態同樣會先設置為COMPARE,Leader節點先向從節點發送該請求的目的是比較主、從節點之間數據的差異,以此確保發送主從切換時不會丟失數據,并且重新確定待轉發的日志序號。
通過EntryDispatcher的doWork()方法可知,如果節點狀態為COMPARE,會調用 doCompare() 方法。doCompare()方法內部代碼都是while(true)包裹,在查看其代碼時注意其退出條件:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#doCompare
/**
* 該方法用于Leader節點向從節點發送Compare請求,目的是為了找到與從節點的共識點,
* 也就是找到從節點未提交的日志Index,從而實現刪除從節點未提交的數據。
*
* @throws Exception
*/
private void doCompare() throws Exception {
// 注意這里是while(true),所以需要注意循環退出條件
while (true) {
if (checkNotLeaderAndFreshState()) {
break;
}
// 判斷請求類型是否為Compare,如果不是則退出循環
if (this.type.get() != EntryDispatcherState.COMPARE) {
break;
}
// ledgerEndIndex== -1 表示Leader中沒有存儲數據,是一個新的集群,所以無需比較主從是否一致
if (dLedgerStore.getLedgerEndIndex() == -1) {
break;
}
// compare process start from the [nextIndex -1]
PushEntryRequest request;
// compareIndex 代表正在比對的索引下標,對比前一條日志,term 和 index 是否一致
long compareIndex = writeIndex - 1;
long compareTerm = -1;
if (compareIndex < dLedgerStore.getLedgerBeforeBeginIndex()) {
// 需要比較的條目已被壓縮刪除,只需更改狀態即可安裝快照
changeState(EntryDispatcherState.INSTALL_SNAPSHOT);
return;
} else if (compareIndex == dLedgerStore.getLedgerBeforeBeginIndex()) {
compareTerm = dLedgerStore.getLedgerBeforeBeginTerm();
request = buildCompareOrTruncatePushRequest(compareTerm, compareIndex, PushEntryRequest.Type.COMPARE);
} else {
// 獲取正在比對的日志信息
DLedgerEntry entry = dLedgerStore.get(compareIndex);
PreConditions.check(entry != null, DLedgerResponseCode.INTERNAL_ERROR, "compareIndex=%d", compareIndex);
// 正在比對的日志所處的選舉輪次
compareTerm = entry.getTerm();
request = buildCompareOrTruncatePushRequest(compareTerm, entry.getIndex(), PushEntryRequest.Type.COMPARE);
}
CompletableFuture<PushEntryResponse> responseFuture = dLedgerRpcService.push(request);
PushEntryResponse response = responseFuture.get(3, TimeUnit.SECONDS);
PreConditions.check(response != null, DLedgerResponseCode.INTERNAL_ERROR, "compareIndex=%d", compareIndex);
PreConditions.check(response.getCode() == DLedgerResponseCode.INCONSISTENT_STATE.getCode() || response.getCode() == DLedgerResponseCode.SUCCESS.getCode()
, DLedgerResponseCode.valueOf(response.getCode()), "compareIndex=%d", compareIndex);
// fast backup algorithm to locate the match index
if (response.getCode() == DLedgerResponseCode.SUCCESS.getCode()) {
// 證明找到了與Follower節點的共識點
matchIndex = compareIndex;
// 此時更新這個Follower節點的水位線
updatePeerWaterMark(compareTerm, peerId, matchIndex);
// 將發送模式改成truncate,以將從節點的未提交的日志刪除
changeState(EntryDispatcherState.TRUNCATE);
return;
}
// 證明在compareIndex日志上,Follower與當前Leader所處選舉輪次并不一致,證明從節點這條日志是需要被刪除,然后才會將主節點已提交的日志再次同步到follower上
if (response.getXTerm() != -1) {
// response.getXTerm() != -1 代表當前對比index 所處的任期和Leader節點不一致,
// 此時 response.getXIndex() 返回的是當前對比任期在從節點結束的位置,所以將指針移到從節點在當前輪次的結束處,再次進行對比。
writeIndex = response.getXIndex();
} else {
// response.getXTerm() == -1 代表從節點上的 leaderEndIndex 比當前對比的index小,
// 則把對比指針,移到從節點末尾的 leaderEndIndex上
writeIndex = response.getEndIndex() + 1;
}
}
}
在該方法中首先是對基本狀態做了一些校驗:
- 如果當前節點的狀態不是 Leader 則退出循環;
- 判斷請求類型是否為 Compare,如果不是則退出循環;
- ledgerEndIndex== -1 表示Leader中沒有存儲數據,是一個新的集群,所以無需比較主從是否一致;
然后構建當前正在比對的compareIndex所對應的日志的所處輪次信息,將compareIndex對應的存儲輪次發送給Follower節點后,Follower節點會對比自己與Leader在相同的Index上的存儲輪次信息是否相同:
- 如果相同則證明此條日志與Leader節點保持一致,返回SUCCESS,此時則證明找到了共識點,將狀態改成truncate模式以刪除從節點多余日志;
- 如果不同會有兩種情況:
- 主節點發送的index在從節點上還不存在,這樣從節點會將自己的末尾指針返回給Leader,Leader會從Follower節點的末尾指針重新開始對比;
- 主節點發送的index在從節點上存在,但是所處的輪次并不一致,證明從節點這條日志是需要被刪除,Follower節點會找到Leader對比輪次所在的最后一個日志索引并返回給Leader,Leader會從這個索引位置繼續開始對比,直到找對最終的共識點。
3.3.5 Leader節點發送truncate請求(doTruncate)
Leader節點在發送compare請求后,得知與從節點的數據存在差異,將向從節點發送truncate請求,指示從節點應該將truncateIndex 及以后的日志刪除:
//io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#doTruncate
/**
* 發起truncate請求,用于刪除Follower節點未提交的日志
* @throws Exception
*/
private void doTruncate() throws Exception {
// 檢測當前狀態是否為Truncate
PreConditions.check(type.get() == EntryDispatcherState.TRUNCATE, DLedgerResponseCode.UNKNOWN);
// 刪除共識點以后得所有日志,truncateIndex代表刪除的起始位置
long truncateIndex = matchIndex + 1;
logger.info("[Push-{}]Will push data to truncate truncateIndex={}", peerId, truncateIndex);
// 構建truncate請求
PushEntryRequest truncateRequest = buildCompareOrTruncatePushRequest(-1, truncateIndex, PushEntryRequest.Type.TRUNCATE);
// 發送請求,等待Follower響應
PushEntryResponse truncateResponse = dLedgerRpcService.push(truncateRequest).get(3, TimeUnit.SECONDS);
PreConditions.check(truncateResponse != null, DLedgerResponseCode.UNKNOWN, "truncateIndex=%d", truncateIndex);
PreConditions.check(truncateResponse.getCode() == DLedgerResponseCode.SUCCESS.getCode(), DLedgerResponseCode.valueOf(truncateResponse.getCode()), "truncateIndex=%d", truncateIndex);
// 更新 lastPushCommitTimeMs 時間
lastPushCommitTimeMs = System.currentTimeMillis();
// 將狀態改為Append,Follower節點的多余日志刪除完成后,就需要Leader節點同步數據給Follower了
changeState(EntryDispatcherState.APPEND);
}
該方法的實現比較簡單,主節點構建truncate請求包并通過網絡向從節點發送請求,從節點在收到請求后會清理多余的數據,使主從節點數據保持一致。日志轉發器在處理完truncate請求后,狀態將變更為APPEND,開始向從節點轉發日志。
3.3.6 Leader節點向Follower節點推送日志(doAppend)
Leader節點在確認主從數據一致后,開始將新的消息轉發到從節點。doAppend()方法內部的邏輯被包裹在while(true)中,故在查看其代碼時應注意退出條件:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#doAppend
private void doAppend() throws Exception {
while (true) {
if (checkNotLeaderAndFreshState()) {
break;
}
// 第一步:校驗當前狀態是否是Append,如果不是則退出循環
if (type.get() != EntryDispatcherState.APPEND) {
break;
}
// 第二步:檢查從節點未接收的第一個append請求是否超時,如果超時,則重推
doCheckAppendResponse();
// 第三步:writeIndex表示當前已追加到從節點的日志序號。通常情況下,主節點向從節點發送append請求時會帶上主節點已提交的指針,
// 但如果append請求發送不頻繁,pending請求超過其隊列長度(默認為1萬字節)時,會阻止數據的追加,
// 此時有可能會出現writeIndex大于leaderEndIndex的情況
if (writeIndex > dLedgerStore.getLedgerEndIndex()) {
if (this.batchAppendEntryRequest.getCount() > 0) {
sendBatchAppendEntryRequest();
} else {
doCommit();
}
break;
}
// check if now not entries in store can be sent
if (writeIndex <= dLedgerStore.getLedgerBeforeBeginIndex()) {
logger.info("[Push-{}]The ledgerBeginBeginIndex={} is less than or equal to writeIndex={}", peerId, dLedgerStore.getLedgerBeforeBeginIndex(), writeIndex);
changeState(EntryDispatcherState.INSTALL_SNAPSHOT);
break;
}
// 第四步:檢測pendingMap(掛起的請求數量)是否發生泄露,正常來說發送給從節點的請求如果成功響應就會從pendingMap中移除,這里是一種兜底操作
// 獲取當前節點的水位線(已成功append請求的日志序號),如果掛起請求的日志序號小于水位線,則丟棄,并記錄最后一次檢查的時間戳
if (pendingMap.size() >= maxPendingSize || DLedgerUtils.elapsed(lastCheckLeakTimeMs) > 1000) {
long peerWaterMark = getPeerWaterMark(term, peerId);
for (Map.Entry<Long, Pair<Long, Integer>> entry : pendingMap.entrySet()) {
if (entry.getKey() + entry.getValue().getValue() - 1 <= peerWaterMark) {
// 被Follower節點成功接收的日志條目需要從pendingMap中移除
pendingMap.remove(entry.getKey());
}
}
lastCheckLeakTimeMs = System.currentTimeMillis();
}
if (pendingMap.size() >= maxPendingSize) {
// 第五步:如果掛起的請求數仍然大于閾值,則再次檢查這些請求是否超時(默認超時時間為1s),如果超時則會觸發重發機制
doCheckAppendResponse();
break;
}
// 第六步:循環同步數據至從節點,方法內部會優化,會按照配置收集一批需要發送的日志,等到到達發送閾值則一起發送,而不是一條條發送
long lastIndexToBeSend = doAppendInner(writeIndex);
if (lastIndexToBeSend == -1) {
break;
}
// 第七步:移動寫指針
writeIndex = lastIndexToBeSend + 1;
}
}
-
第一步:再次判斷節點狀態,確保當前節點是Leader節點并且日志轉發器內部的狀態為APPEND。
-
第二步:檢查從節點未接收的第一個append請求是否超時,如果超時,則重推。
-
第三步:writeIndex表示當前已追加到從節點的日志序號。通常情況下,主節點向從節點發送append請求時會帶上主節點已提交的指針,但如果append請求發送不頻繁,pending請求超過其隊列長度(默認為1萬字節)時,會阻止數據的追加,此時有可能會出現writeIndex 大于leaderEndIndex的情況,需要單獨發送commit請求,并檢查 append 請求響應。
-
第四步:檢測pendingMap(掛起的請求數量)是否發生泄露,正常來說發送給從節點的請求如果成功響應就會從pendingMap中移除,這里是一種兜底操作。獲取當前節點的水位線(已成功append請求的日志序號),如果掛起請求的日志序號小于水位線,則丟棄,并記錄最后一次檢查的時間戳。
-
第五步:如果掛起的請求數仍然大于閾值,則再次檢查這些請求是否超時(默認超時時間為1s),如果超時則會觸發重發機制
-
第六步:循環同步數據至從節點,方法內部會優化,會按照配置收集一批需要發送的日志,等到到達發送閾值則一起發送,而不是一條條發送。
-
第七步:移動寫指針。
3.3.6.1 日志推送
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#doAppendInner
/**
* 將條目追加到follower,將其追加到內存中,直到達到閾值,才會真正發送給Follower
*
* @param index 從哪個索引追加
* @return 最后一個要追加的條目的索引
* @throws Exception
*/
private long doAppendInner(long index) throws Exception {
// 從磁盤中讀取將要發送的日志信息
DLedgerEntry entry = getDLedgerEntryForAppend(index);
if (null == entry) {
// means should install snapshot
logger.error("[Push-{}]Get null entry from index={}", peerId, index);
changeState(EntryDispatcherState.INSTALL_SNAPSHOT);
return -1;
}
// 流控檢查
checkQuotaAndWait(entry);
batchAppendEntryRequest.addEntry(entry);
// 檢查此次操作是否真正觸發發送動作
if (!dLedgerConfig.isEnableBatchAppend() || batchAppendEntryRequest.getTotalSize() >= dLedgerConfig.getMaxBatchAppendSize()
|| DLedgerUtils.elapsed(this.lastAppendEntryRequestSendTimeMs) >= dLedgerConfig.getMaxBatchAppendIntervalMs()) {
// 未開啟批量發送 或者 批量發送數量超過閾值 或者 上一次發送時間超過1s
// 發送日志
sendBatchAppendEntryRequest();
}
// 返回最后一個要追加的索引
return entry.getIndex();
}
-
第一步:獲取磁盤中讀取將要發送的日志信息。
-
第二步:進行日志推送流控檢查,如果觸發流控,現成就會阻塞等待下一個時間窗口(滑動窗口限流)。
-
第三步:發送日志
//io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#sendBatchAppendEntryRequest
/**
* 執行真正的日志發送操作,將Leader節點的日志發送到Follower節點
* @throws Exception
*/
private void sendBatchAppendEntryRequest() throws Exception {
// 設置committedIndex,這樣Follower節點收到Append請求后能夠順道更新自己的committedIndex
batchAppendEntryRequest.setCommitIndex(memberState.getCommittedIndex());
// 此次批量發送的第一條日志的下標
final long firstIndex = batchAppendEntryRequest.getFirstEntryIndex();
// 此次批量發送的最后一條日志的下標
final long lastIndex = batchAppendEntryRequest.getLastEntryIndex();
// 當前發送日志所處的選舉輪次
final long lastTerm = batchAppendEntryRequest.getLastEntryTerm();
// 此次批量發送的日志數量
final long entriesCount = batchAppendEntryRequest.getCount();
// 此次批量發送的日志大小
final long entriesSize = batchAppendEntryRequest.getTotalSize();
StopWatch watch = StopWatch.createStarted();
// 通過dLedgerRpcService發送日志
CompletableFuture<PushEntryResponse> responseFuture = dLedgerRpcService.push(batchAppendEntryRequest);
// 將請求加入pendingMap,用于后續檢查超時,一旦請求正常返回則刪除這條記錄
pendingMap.put(firstIndex, new Pair<>(System.currentTimeMillis(), batchAppendEntryRequest.getCount()));
responseFuture.whenComplete((x, ex) -> {
try {
PreConditions.check(ex == null, DLedgerResponseCode.UNKNOWN);
DLedgerResponseCode responseCode = DLedgerResponseCode.valueOf(x.getCode());
switch (responseCode) {
case SUCCESS:
// Follower節點返回成功
// 監控指標上報
Attributes attributes = DLedgerMetricsManager.newAttributesBuilder().put(LABEL_REMOTE_ID, this.peerId).build();
DLedgerMetricsManager.replicateEntryLatency.record(watch.getTime(TimeUnit.MICROSECONDS), attributes);
DLedgerMetricsManager.replicateEntryBatchCount.record(entriesCount, attributes);
DLedgerMetricsManager.replicateEntryBatchBytes.record(entriesSize, attributes);
// 發送成功后,刪除掛起請求記錄。
pendingMap.remove(firstIndex);
if (lastIndex > matchIndex) {
// 更新 matchIndex
matchIndex = lastIndex;
// 更新當前Follower的水位線
updatePeerWaterMark(lastTerm, peerId, matchIndex);
}
break;
case INCONSISTENT_STATE:
logger.info("[Push-{}]Get INCONSISTENT_STATE when append entries from {} to {} when term is {}", peerId, firstIndex, lastIndex, term);
// 從節點返回INCONSISTENT_STATE,說明Follower節點的日志和Leader節點的不一致,需要重新比較
changeState(EntryDispatcherState.COMPARE);
break;
default:
logger.warn("[Push-{}]Get error response code {} {}", peerId, responseCode, x.baseInfo());
break;
}
} catch (Throwable t) {
logger.error("Failed to deal with the callback when append request return", t);
}
});
// 更新 上一次發送commit請求的時間戳。
lastPushCommitTimeMs = System.currentTimeMillis();
// 清空請求緩存
batchAppendEntryRequest.clear();
}
3.3.6.2 日志推送的流控機制
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryDispatcher#checkQuotaAndWait
/**
* 在checkQuotaAndWait方法中,如果當前待發送的日志條目數量超過了最大允許的待發送數量(maxPendingSize),
* 則會檢查流控。如果觸發了流控(validateNow返回true),則會記錄警告信息,并根據leftNow方法返回的剩余時間進行等待。
* @param entry
*/
private void checkQuotaAndWait(DLedgerEntry entry) {
// 如果剩余發送的日志條目數量小于最大允許的待發送日志數量,則跳過流控檢查
if (dLedgerStore.getLedgerEndIndex() - entry.getIndex() <= maxPendingSize) {
return;
}
// 記錄當前時間窗口的日志條目數量。如果當前時間窗口是新的(即timeVec中的記錄不是當前秒),則重置該窗口的計數;如果是同一時間窗口,則累加日志條目數量
quota.sample(entry.getSize());
// 檢查當前時間窗口是否已達到最大限制。如果是,則返回true,表示觸發了流控。
if (quota.validateNow()) {
// 計算當前時間窗口剩余的時間(毫秒),如果已達到最大限制,則可能需要等待直到下一個時間窗口開始。
long leftNow = quota.leftNow();
logger.warn("[Push-{}]Quota exhaust, will sleep {}ms", peerId, leftNow);
DLedgerUtils.sleep(leftNow);
}
}
在前面介紹日志推送流程中,會在通過網絡發送之前,調用 checkQuotaAndWait 進行一定的流控操作,流控是使用的滑動窗口實現的,在該方法中首先會記錄當前時間窗口的日志條目數量。如果當前時間窗口是新的(即timeVec中的記錄不是當前秒),則重置該窗口的計數;如果是同一時間窗口,則累加日志條目數量。然后計算當前時間窗口剩余的時間(毫秒),如果已達到最大限制,則可能需要等待直到下一個時間窗口開始。
其中 Quota 中核心屬性如下:
public class Quota {
/**
* 在指定時間窗口內允許的最大日志條目數量。
*/
private final int max;
/**
* 一個數組,用于存儲每個時間窗口的日志條目數量。
*/
private final int[] samples;
/**
* 一個數組,記錄每個時間窗口的開始時間(秒)。
*/
private final long[] timeVec;
/**
* 窗口數量
*/
private final int window;
}
3.3.6.3 日志推送的重試機制
/**
* Leader節點在向從節點轉發日志后,會存儲該日志的推送時間戳到pendingMap,
* 當pendingMap的積壓超過1000ms時會觸發重推機制,該邏輯封裝在當前方法中
* @throws Exception
*/
private void doCheckAppendResponse() throws Exception {
// 獲取從節點已復制的日志序號
long peerWaterMark = getPeerWaterMark(term, peerId);
// 嘗試獲取從節點已復制序號+1的記錄,如果能找到,說明從服務下一條需要追加的消息已經存儲在主節點中,
// 接著在嘗試推送,如果該條推送已經超時,默認超時時間為1s,調用doAppendInner重新推送
Pair<Long, Integer> pair = pendingMap.get(peerWaterMark + 1);
if (pair == null)
return;
long sendTimeMs = pair.getKey();
if (DLedgerUtils.elapsed(sendTimeMs) > dLedgerConfig.getMaxPushTimeOutMs()) {
// 發送如果超時,則重置writeIndex指針,重發消息
batchAppendEntryRequest.clear();
writeIndex = peerWaterMark + 1;
logger.warn("[Push-{}]Reset write index to {} for resending the entries which are timeout", peerId, peerWaterMark + 1);
}
}
如果因網絡等原因,主節點在向從節點追加日志時失敗,該如何保證從節點與主節點一致呢?從上文我們可以得知,Leader節點在向 從節點轉發日志后,會存儲該日志的推送時間戳到pendingMap,當pendingMap的積壓超過1000ms時會觸發重推機制,將writeIndex指針重置為超時的Index上。
3.3.7 日志轉發整體流程
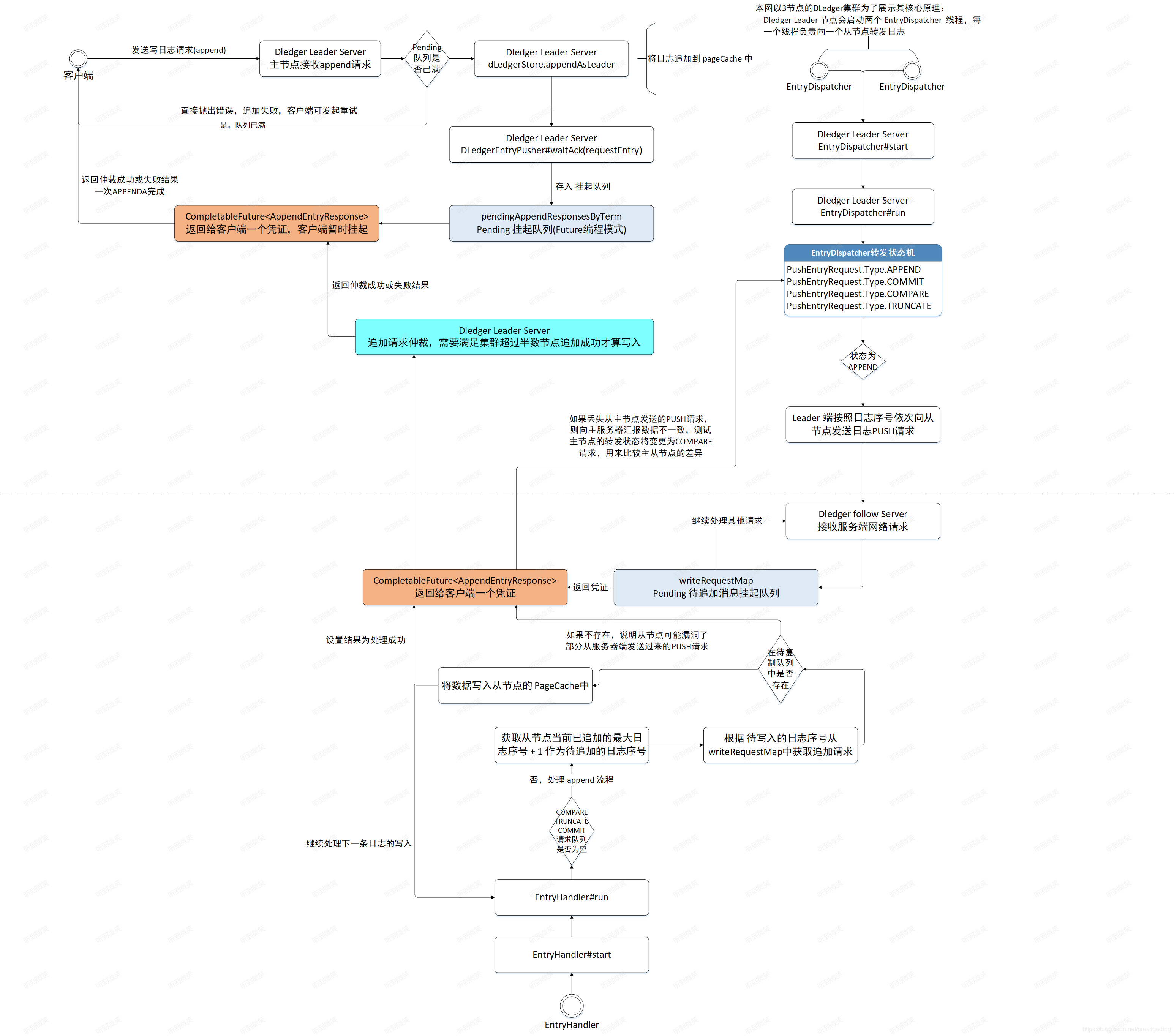
3.4 日志復制(Follower節點接收日志并存儲)
Leader節點實時向從節點轉發消息,從節點接收到日志后進行存儲,然后向Leader節點反饋復制進度,從節點的日志接收主要由EntryHandler實現。
3.4.1 EntryHandler核心屬性
//io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryHandler
/**
* 從節點收到Leader節點推送的日志并存儲,然后向Leader節點匯報日志復制結果。
* This thread will be activated by the follower.
* Accept the push request and order it by the index, then append to ledger store one by one.
*/
private class EntryHandler extends ShutdownAbleThread {
/**
* 上一次檢查主服務器是否有推送消息的時間戳。
*/
private long lastCheckFastForwardTimeMs = System.currentTimeMillis();
/**
* append請求處理隊列。
*/
ConcurrentMap<Long/*index*/, Pair<PushEntryRequest/*request*/, CompletableFuture<PushEntryResponse/*complete future*/>>> writeRequestMap = new ConcurrentHashMap<>();
/**
* COMMIT、COMPARE、TRUNCATE相關請求的處理隊列。
*/
BlockingQueue<Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>>>
compareOrTruncateRequests = new ArrayBlockingQueue<>(1024);
}
3.4.2 Follower日志復制入口
從節點收到Leader節點的推送請求后(無論是APPEND、COMMIT、COMPARE、TRUNCATE),由EntryHandler的handlePush()方法執行:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryHandler#handlePush
/**
* 處理Leader節點發送到當前Follower節點的請求
* @param request
* @return
* @throws Exception
*/
public CompletableFuture<PushEntryResponse> handlePush(PushEntryRequest request) throws Exception {
// The timeout should smaller than the remoting layer's request timeout
CompletableFuture<PushEntryResponse> future = new TimeoutFuture<>(1000);
switch (request.getType()) {
case APPEND:
PreConditions.check(request.getCount() > 0, DLedgerResponseCode.UNEXPECTED_ARGUMENT);
long index = request.getFirstEntryIndex();
// 將請求放入隊列中,由doWork方法異步處理
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> old = writeRequestMap.putIfAbsent(index, new Pair<>(request, future));
if (old != null) {
// 表示重復推送
logger.warn("[MONITOR]The index {} has already existed with {} and curr is {}", index, old.getKey().baseInfo(), request.baseInfo());
future.complete(buildResponse(request, DLedgerResponseCode.REPEATED_PUSH.getCode()));
}
break;
case COMMIT:
synchronized (this) {
// 將commit放入請求隊列,由doWork方法異步處理
if (!compareOrTruncateRequests.offer(new Pair<>(request, future))) {
logger.warn("compareOrTruncateRequests blockingQueue is full when put commit request");
future.complete(buildResponse(request, DLedgerResponseCode.PUSH_REQUEST_IS_FULL.getCode()));
}
}
break;
case COMPARE:
case TRUNCATE:
// 如果是compare或truncate請求,則清除append隊列中所有的請求
writeRequestMap.clear();
synchronized (this) {
// 并將 compare或truncate 請求放入隊列中,由doWork方法異步處理
if (!compareOrTruncateRequests.offer(new Pair<>(request, future))) {
logger.warn("compareOrTruncateRequests blockingQueue is full when put compare or truncate request");
future.complete(buildResponse(request, DLedgerResponseCode.PUSH_REQUEST_IS_FULL.getCode()));
}
}
break;
default:
logger.error("[BUG]Unknown type {} from {}", request.getType(), request.baseInfo());
future.complete(buildResponse(request, DLedgerResponseCode.UNEXPECTED_ARGUMENT.getCode()));
break;
}
wakeup();
return future;
}
handlePush()方法的主要職責是將處理請求放入隊列,由doWork()方法從處理隊列中拉取任務進行處理。
- 如果是append請求,將請求放入writeRequestMap集合,如果已存在該條日志的推送請求,表示Leader重復推送,則返回狀態碼REPEATED_PUSH。
- 如果是commit請求,將請求存入compareOrTruncateRequests 請求處理隊列。
- 如果是compare或truncate請求,將待追加隊列writeRequestMap清空,并將請求放入compareOrTruncateRequests請求隊列,由doWork()方法進行異步處理。
3.4.3 EntryHandler任務分發機制
EntryHandler的handlePush()方法主要是接收請求并將其放入隊列的處理隊列,而doWork()方法是從指定隊列中獲取待執行任務。
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryHandler#doWork
@Override
public void doWork() {
try {
// 第一步:校驗是否是Follower節點
if (!memberState.isFollower()) {
clearCompareOrTruncateRequestsIfNeed();
waitForRunning(1);
return;
}
// deal with install snapshot request first
Pair<InstallSnapshotRequest, CompletableFuture<InstallSnapshotResponse>> installSnapshotPair = null;
this.inflightInstallSnapshotRequestLock.lock();
try {
if (inflightInstallSnapshotRequest != null && inflightInstallSnapshotRequest.getKey() != null && inflightInstallSnapshotRequest.getValue() != null) {
installSnapshotPair = inflightInstallSnapshotRequest;
inflightInstallSnapshotRequest = new Pair<>(null, null);
}
} finally {
this.inflightInstallSnapshotRequestLock.unlock();
}
if (installSnapshotPair != null) {
handleDoInstallSnapshot(installSnapshotPair.getKey(), installSnapshotPair.getValue());
}
// 第二步:處理 TRUNCATE、COMPARE、COMMIT 請求
if (compareOrTruncateRequests.peek() != null) {
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = compareOrTruncateRequests.poll();
PreConditions.check(pair != null, DLedgerResponseCode.UNKNOWN);
switch (pair.getKey().getType()) {
case TRUNCATE:
handleDoTruncate(pair.getKey().getPreLogIndex(), pair.getKey(), pair.getValue());
break;
case COMPARE:
handleDoCompare(pair.getKey(), pair.getValue());
break;
case COMMIT:
handleDoCommit(pair.getKey().getCommitIndex(), pair.getKey(), pair.getValue());
break;
default:
break;
}
return;
}
long nextIndex = dLedgerStore.getLedgerEndIndex() + 1;
// 從請求隊列中獲取這一個日志索引所對應的請求
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = writeRequestMap.remove(nextIndex);
if (pair == null) {
// 檢查追加請求是否丟失
checkAbnormalFuture(dLedgerStore.getLedgerEndIndex());
// 如果下一個日志索引不在隊列中,則證明主節點還沒有把這條日志推送過來,此時我們等待
waitForRunning(1);
// 如果這一個索引在隊列中不存在,則退出。等待下一次檢查
return;
}
PushEntryRequest request = pair.getKey();
// 執行日志追加
handleDoAppend(nextIndex, request, pair.getValue());
} catch (Throwable t) {
DLedgerEntryPusher.LOGGER.error("Error in {}", getName(), t);
DLedgerUtils.sleep(100);
}
}
}
- 第一步:如果當前節點的狀態不是從節點,則跳出
- 第二步:如果compareOrTruncateRequests隊列不為空,優先處理COMMIT、COMPARE、TRUNCATE等請求。值得注意的是,這里使用的是peek、poll等非阻塞方法,所以隊列為空不會阻塞線程使得append請求能夠正常處理。
- 第三步:處理日志追加append請求,根據當前節點 已存儲的最大日志序號計算下一條待寫日志的日志序號,從待寫隊列 中獲取日志的處理請求。如果能查找到對應日志的追加請求,則執行doAppend()方法追加日志;如果從待寫隊列中沒有找到對應的追加請 求,則調用checkAbnormalFuture檢查追加請求是否丟失。
3.4.4 compare請求響應
從上文得知,Leader節點首先會向從節點發送compare請求,以此比較兩者的數據是否存在差異,這一步由EntryHandler的handleDoCompare()方法實現
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryHandler#handleDoCompare
/**
* Follower端處理Leader端發起的Compare請求
*
* @param request
* @param future
* @return
*/
private CompletableFuture<PushEntryResponse> handleDoCompare(PushEntryRequest request,
CompletableFuture<PushEntryResponse> future) {
try {
PreConditions.check(request.getType() == PushEntryRequest.Type.COMPARE, DLedgerResponseCode.UNKNOWN);
// Leader端發來需要對比的日志索引值
long preLogIndex = request.getPreLogIndex();
// Leader端Index日志所處的任期
long preLogTerm = request.getPreLogTerm();
if (preLogTerm == -1 && preLogIndex == -1) {
// leader節點日志為空,則直接返回
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
return future;
}
if (dLedgerStore.getLedgerEndIndex() >= preLogIndex) {
long compareTerm = 0;
// 找到指定Index在當前節點的日志中的任期
if (dLedgerStore.getLedgerBeforeBeginIndex() == preLogIndex) {
// 如果查找的Index剛好是當前節點存儲的第一條日志,則不用讀取磁盤獲取日志任期
compareTerm = dLedgerStore.getLedgerBeforeBeginTerm();
} else {
// 從磁盤中讀取日志內容,然后獲取到日志任期
DLedgerEntry local = dLedgerStore.get(preLogIndex);
compareTerm = local.getTerm();
}
if (compareTerm == preLogTerm) {
// 如果任期相同,則認為Follower節點的日志和Leader節點是相同的,也就證明找到了共識點
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
return future;
}
// 如果任期不相同,則從preLogIndex開始,向前追溯compareTerm任期的第一個日志
DLedgerEntry firstEntryWithTargetTerm = dLedgerStore.getFirstLogOfTargetTerm(compareTerm, preLogIndex);
PreConditions.check(firstEntryWithTargetTerm != null, DLedgerResponseCode.INCONSISTENT_STATE);
PushEntryResponse response = buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode());
// 設置Leader節點對比的Index在當前節點所處的任期
response.setXTerm(compareTerm);
// 設置Leader節點對比任期,在當前節點最大的index值
response.setXIndex(firstEntryWithTargetTerm.getIndex());
future.complete(response);
return future;
}
// dLedgerStore.getLedgerEndIndex() < preLogIndex,代表Leader想要對比的日志在當前節點不存咋,則返回當前節點的endIndex
PushEntryResponse response = buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode());
response.setEndIndex(dLedgerStore.getLedgerEndIndex());
future.complete(response);
} catch (Throwable t) {
logger.error("[HandleDoCompare] preLogIndex={}, preLogTerm={}", request.getPreLogIndex(), request.getPreLogTerm(), t);
future.complete(buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
return future;
}
該方法最終目的是為了找到Leader節點和當前Follower節點的共識點,在該方法中會對比Leader端發來的Index對應選舉任期和當前Follower節點這個Index對應的選舉任期是否相同,會有如下情況:
- Leader想要對比的Index在Follower節點不存在:則Follower節點返回當前節點 ledgerEndIndex 給Leader,意思是讓Leader節點從我自己的最末尾Index進行對比。
- Leader想要對比Index在Follower節點中存在:
- Index對應的任期相同:意味著找到了共識點,返回SUCCESS。這樣Leader節點就會從這個共識點刪除從節點多余的日志,然后重新追加日志。
- Index對應的任期不同:從preLogIndex開始,向前追溯從節點Index所處任期的第一個日志。這樣Leader節點就會從這個點重新開始對比,這也可以看到日志對比并不是一個日志一個日志依次對比,這樣做效率會很低,當遇到任期不一致的情況時,Follower節點就會跳過當前任期,對比前一個任期日志是否一致。
3.4.5 truncate請求響應
Leader節點與從節點進行數據對比后,如果發現數據有差異,將計算出需要截斷的日志序號,發送truncate請求給從節點,從節點對多余的日志進行截斷:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryHandler#handleDoTruncate
/**
* 該方法時Follower節點收到Leader節點的Truncate請求所執行的方法
* @param truncateIndex
* @param request
* @param future
* @return
*/
private CompletableFuture<PushEntryResponse> handleDoTruncate(long truncateIndex, PushEntryRequest request,
CompletableFuture<PushEntryResponse> future) {
try {
logger.info("[HandleDoTruncate] truncateIndex={}", truncateIndex);
PreConditions.check(request.getType() == PushEntryRequest.Type.TRUNCATE, DLedgerResponseCode.UNKNOWN);
// 刪除truncateIndex之后的日志
long index = dLedgerStore.truncate(truncateIndex);
PreConditions.check(index == truncateIndex - 1, DLedgerResponseCode.INCONSISTENT_STATE);
// 刪除成功,則返回成功
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
// 更新本地的已提交索引,如果Leader已提交索引大于本地的最大索引,則證明本地的所有日志都處于已提交狀態,反之則更新已提交索引為Leader的已提交索引
long committedIndex = request.getCommitIndex() <= dLedgerStore.getLedgerEndIndex() ? request.getCommitIndex() : dLedgerStore.getLedgerEndIndex();
// 更新狀態機中的已提交索引
if (DLedgerEntryPusher.this.memberState.followerUpdateCommittedIndex(committedIndex)) {
// todo 該方法待定
DLedgerEntryPusher.this.fsmCaller.onCommitted(committedIndex);
}
} catch (Throwable t) {
logger.error("[HandleDoTruncate] truncateIndex={}", truncateIndex, t);
future.complete(buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
return future;
}
Follower節點在收到Leader節點發來的truncate請求后,會將truncateIndex及以后得所有日志全部刪除,并更新本地已提交日志的索引指針。而日志的刪除操作是由 DLedgerMmapFileStore#truncate 實現的:
// io.openmessaging.storage.dledger.store.file.DLedgerMmapFileStore#truncate(long)
@Override
public long truncate(long truncateIndex) {
// 如果需要刪除的index在ledgerEndIndex之后,直接返回ledgerEndIndex,不用繼續執行刪除流程
if (truncateIndex > this.ledgerEndIndex) {
return this.ledgerEndIndex;
}
// 獲取truncateIndex所對應的日志
DLedgerEntry firstTruncateEntry = this.get(truncateIndex);
// 獲取物理偏移量
long truncateStartPos = firstTruncateEntry.getPos();
synchronized (this.memberState) {
// 加鎖后再次比較,如果需要刪除的index在ledgerEndIndex之后,直接返回ledgerEndIndex,不用繼續執行刪除流程
if (truncateIndex > this.ledgerEndIndex) {
return this.ledgerEndIndex;
}
//從物理文件中刪除指定物理偏移量之后的數據
dataFileList.truncateOffset(truncateStartPos);
if (dataFileList.getMaxWrotePosition() != truncateStartPos) {
LOGGER.warn("[TRUNCATE] truncate for data file error, try to truncate pos: {}, but after truncate, max wrote pos: {}, now try to rebuild", truncateStartPos, dataFileList.getMaxWrotePosition());
PreConditions.check(dataFileList.rebuildWithPos(truncateStartPos), DLedgerResponseCode.DISK_ERROR, "rebuild data file truncatePos=%d", truncateStartPos);
}
// 重置數據文件的寫指針
reviseDataFileListFlushedWhere(truncateStartPos);
// 刪除索引文件對應的數據
long truncateIndexFilePos = truncateIndex * INDEX_UNIT_SIZE;
indexFileList.truncateOffset(truncateIndexFilePos);
if (indexFileList.getMaxWrotePosition() != truncateIndexFilePos) {
LOGGER.warn("[TRUNCATE] truncate for index file error, try to truncate pos: {}, but after truncate, max wrote pos: {}, now try to rebuild", truncateIndexFilePos, indexFileList.getMaxWrotePosition());
PreConditions.check(dataFileList.rebuildWithPos(truncateStartPos), DLedgerResponseCode.DISK_ERROR, "rebuild index file truncatePos=%d", truncateIndexFilePos);
}
// 重置索引文件的寫指針
reviseIndexFileListFlushedWhere(truncateIndexFilePos);
// update store end index and its term
if (truncateIndex == 0) {
// truncateIndex == 0 代表清除所有數據
ledgerEndTerm = -1;
ledgerEndIndex = -1;
} else {
// 刪除后更新 ledgerEndTerm、ledgerEndIndex
SelectMmapBufferResult endIndexBuf = indexFileList.getData((truncateIndex - 1) * INDEX_UNIT_SIZE, INDEX_UNIT_SIZE);
ByteBuffer buffer = endIndexBuf.getByteBuffer();
DLedgerIndexEntry indexEntry = DLedgerEntryCoder.decodeIndex(buffer);
ledgerEndTerm = indexEntry.getTerm();
ledgerEndIndex = indexEntry.getIndex();
}
}
LOGGER.info("[TRUNCATE] truncateIndex: {}, after truncate, ledgerEndIndex: {} ledgerEndTerm: {}", truncateIndex, ledgerEndIndex, ledgerEndTerm);
return ledgerEndIndex;
}
3.4.6 append請求響應
Leader節點與從節點進行差異對比,截斷從節點多余的數據文件后,會實時轉發日志到從節點,具體由EntryHandler的handleDoAppend()方法實現:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryHandler#handleDoAppend
private void handleDoAppend(long writeIndex, PushEntryRequest request,
CompletableFuture<PushEntryResponse> future) {
try {
PreConditions.check(writeIndex == request.getFirstEntryIndex(), DLedgerResponseCode.INCONSISTENT_STATE);
for (DLedgerEntry entry : request.getEntries()) {
// 將日志信息存儲的Follower節點上
dLedgerStore.appendAsFollower(entry, request.getTerm(), request.getLeaderId());
}
// 返回成功響應。
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
// 計算已提交指針
long committedIndex = Math.min(dLedgerStore.getLedgerEndIndex(), request.getCommitIndex());
if (DLedgerEntryPusher.this.memberState.followerUpdateCommittedIndex(committedIndex)) {
// 更新已提交指針
DLedgerEntryPusher.this.fsmCaller.onCommitted(committedIndex);
}
} catch (Throwable t) {
logger.error("[HandleDoAppend] writeIndex={}", writeIndex, t);
future.complete(buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
}
將從Leader節點的日志追加到從節點,具體調用DLedgerStore的appendAsFollower()方法實現,其實現細節與服務端追加日志的流程基本類似,只是少了日志轉發這個流程。然后使用Leader節點的已提交指針更新從節點的已提交指針,即append請求會附帶有commit請求的效果。
3.4.7 從節點日志復制異常檢測機制
收到Leader節點的append請求后,從節點首先會將這些寫入請求 存儲在writeRequestMap處理隊列中,從節點并不是直接從該隊列中獲取一個待寫入處理請求進行數據追加,而是查找當前節點已存儲的最大日志序號leaderEndIndex,然后加1得出下一條待追加的日志序號nextIndex。如果該日志序號在writeRequestMap中不存在日志推送請求,則有可能是因為發生了推送請求丟失,在這種情況下,需要進行異常檢測,以便盡快恢復異常,使主節點與從節點最終保持一致性。
// io.openmessaging.storage.dledger.DLedgerEntryPusher.EntryHandler#checkAbnormalFuture
/**
* 檢查append請求是否丟失leader向follower推送的日志,并記錄推送的索引。
* 但在以下情況下,推送可能會停止:
* 1. 如果追隨者異常關閉,其日志結束索引可能會比之前更小。這時,領導者可能會推送快進條目,并一直重試。
* 2. 如果最后一個確認應答丟失,并且沒有新消息傳入,領導者可能會重試推送最后一條消息,但追隨者會忽略它。
*
* @param endIndex
*/
private void checkAbnormalFuture(long endIndex) {
if (DLedgerUtils.elapsed(lastCheckFastForwardTimeMs) < 1000) {
// 上次檢查距離現在不足1s,則跳過檢查
return;
}
lastCheckFastForwardTimeMs = System.currentTimeMillis();
if (writeRequestMap.isEmpty()) {
// 當前沒有積壓的append的請求,可以證明主節點沒有推送新的日志,所以不用檢查
return;
}
// 執行檢查
checkAppendFuture(endIndex);
}
/**
*
* @param endIndex 從節點當前存儲的最大日志序號
*/
private void checkAppendFuture(long endIndex) {
long minFastForwardIndex = Long.MAX_VALUE;
for (Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair : writeRequestMap.values()) {
// 批量發送的第一條日志的index
long firstEntryIndex = pair.getKey().getFirstEntryIndex();
// 批量發送最后一條日志的index
long lastEntryIndex = pair.getKey().getLastEntryIndex();
// 清除舊的推送請求
if (lastEntryIndex <= endIndex) {
try {
for (DLedgerEntry dLedgerEntry : pair.getKey().getEntries()) {
// 如果接收的日志和當前存儲的日志所屬選舉輪次并不一致,則響應INCONSISTENT_STATE錯誤碼
PreConditions.check(dLedgerEntry.equals(dLedgerStore.get(dLedgerEntry.getIndex())), DLedgerResponseCode.INCONSISTENT_STATE);
}
// 否則,響應成功
pair.getValue().complete(buildResponse(pair.getKey(), DLedgerResponseCode.SUCCESS.getCode()));
logger.warn("[PushFallBehind]The leader pushed an batch append entry last index={} smaller than current ledgerEndIndex={}, maybe the last ack is missed", lastEntryIndex, endIndex);
} catch (Throwable t) {
logger.error("[PushFallBehind]The leader pushed an batch append entry last index={} smaller than current ledgerEndIndex={}, maybe the last ack is missed", lastEntryIndex, endIndex, t);
pair.getValue().complete(buildResponse(pair.getKey(), DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
// 清除舊的的請求
writeRequestMap.remove(pair.getKey().getFirstEntryIndex());
continue;
}
// 如果待追加的日志序號等于endIndex+1,即從節點當前存儲的最大日志序號加1,表示從節點下一條期望追加的日志Leader節點已經推送過來了
if (firstEntryIndex == endIndex + 1) {
return;
}
// 清除超時的推送請求
TimeoutFuture<PushEntryResponse> future = (TimeoutFuture<PushEntryResponse>) pair.getValue();
if (!future.isTimeOut()) {
continue;
}
// 記錄最小的推送的索引
if (firstEntryIndex < minFastForwardIndex) {
minFastForwardIndex = firstEntryIndex;
}
}
// 主要處理待追加日志的序號大于endIndex+1的情況,可以認為有追加積壓
if (minFastForwardIndex == Long.MAX_VALUE) {
return;
}
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = writeRequestMap.remove(minFastForwardIndex);
if (pair == null) {
return;
}
// 此時,返回錯誤碼,讓Leader轉變為Compare模式,重新尋找共識點
logger.warn("[PushFastForward] ledgerEndIndex={} entryIndex={}", endIndex, minFastForwardIndex);
pair.getValue().complete(buildResponse(pair.getKey(), DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
3.4.8 日志復制整體流程
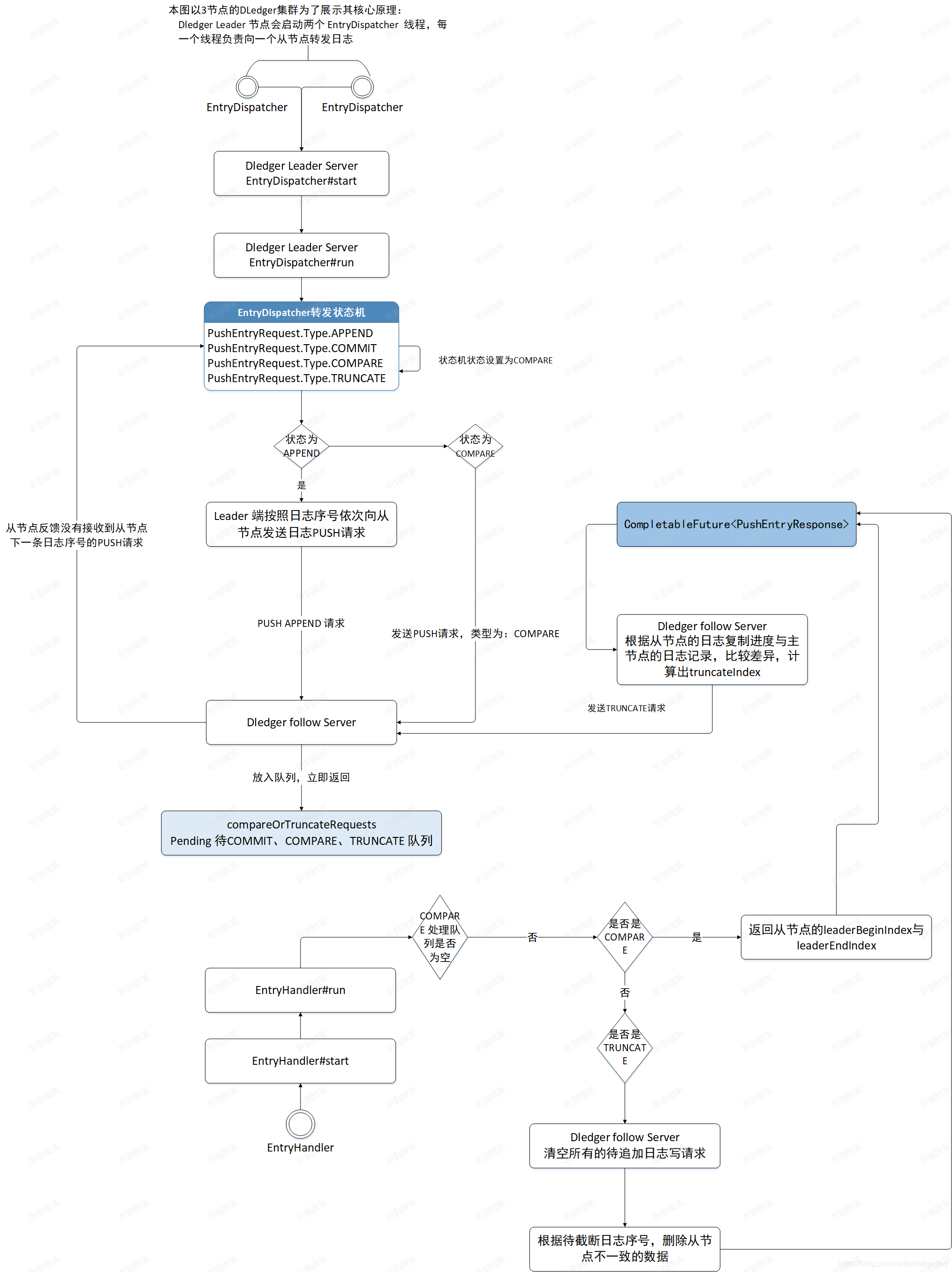
3.5 日志復制仲裁
Raft協議判斷一條日志寫入成功的標準是集群中超過半數的節點存儲了該日志,Leader節點首先存儲數據,然后異步向它所有的從節點推送日志。不需要所有的從節點都返回日志追加成功才認為是成功寫入,故Leader節點需要對返回結果進行仲裁,這部分功能主要由 QuorumAckChecker 實現:
// io.openmessaging.storage.dledger.DLedgerEntryPusher.QuorumAckChecker#doWork
@Override
public void doWork() {
try {
if (DLedgerUtils.elapsed(lastPrintWatermarkTimeMs) > 3000) {
logger.info("[{}][{}] term={} ledgerBeforeBegin={} ledgerEnd={} committed={} watermarks={} appliedIndex={}",
memberState.getSelfId(), memberState.getRole(), memberState.currTerm(), dLedgerStore.getLedgerBeforeBeginIndex(), dLedgerStore.getLedgerEndIndex(), memberState.getCommittedIndex(), JSON.toJSONString(peerWaterMarksByTerm), memberState.getAppliedIndex());
lastPrintWatermarkTimeMs = System.currentTimeMillis();
}
// 當前節點所處輪次
long currTerm = memberState.currTerm();
checkTermForPendingMap(currTerm, "QuorumAckChecker");
checkTermForWaterMark(currTerm, "QuorumAckChecker");
// clear pending closure in old term
if (pendingClosure.size() > 1) {
for (Long term : pendingClosure.keySet()) {
if (term == currTerm) {
continue;
}
for (Map.Entry<Long, Closure> futureEntry : pendingClosure.get(term).entrySet()) {
logger.info("[TermChange] Will clear the pending closure index={} for term changed from {} to {}", futureEntry.getKey(), term, currTerm);
// 如果是之前的輪次,則調用請求完成回調,調用后,被hold住的請求會被釋放
futureEntry.getValue().done(Status.error(DLedgerResponseCode.EXPIRED_TERM));
}
pendingClosure.remove(term);
}
}
// clear peer watermarks in old term
if (peerWaterMarksByTerm.size() > 1) {
for (Long term : peerWaterMarksByTerm.keySet()) {
if (term == currTerm) {
continue;
}
logger.info("[TermChange] Will clear the watermarks for term changed from {} to {}", term, currTerm);
// 清除老的選舉周期中從節點的水位線
peerWaterMarksByTerm.remove(term);
}
}
// clear the pending closure which index <= applyIndex
if (DLedgerUtils.elapsed(lastCheckLeakTimeMs) > 1000) {
checkResponseFuturesElapsed(DLedgerEntryPusher.this.memberState.getAppliedIndex());
lastCheckLeakTimeMs = System.currentTimeMillis();
}
if (DLedgerUtils.elapsed(lastCheckTimeoutTimeMs) > 1000) {
// clear the timeout pending closure should check all since it can timeout for different index
checkResponseFuturesTimeout(DLedgerEntryPusher.this.memberState.getAppliedIndex() + 1);
lastCheckTimeoutTimeMs = System.currentTimeMillis();
}
if (!memberState.isLeader()) {
// 如果不是Leader節點,則返回,不再繼續執行生效的邏輯了。
waitForRunning(1);
return;
}
// 從這里開始的邏輯都是Leader節點中才會執行的
// 更新當前節點的水位線
updatePeerWaterMark(currTerm, memberState.getSelfId(), dLedgerStore.getLedgerEndIndex());
// 計算所有節點水位線的中位數,那么理論上比這個中位數小的index來說都已經存儲在集群中大多數節點上了。
Map<String, Long> peerWaterMarks = peerWaterMarksByTerm.get(currTerm);
List<Long> sortedWaterMarks = peerWaterMarks.values()
.stream()
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
long quorumIndex = sortedWaterMarks.get(sortedWaterMarks.size() / 2);
// advance the commit index
// we can only commit the index whose term is equals to current term (refer to raft paper 5.4.2)
if (DLedgerEntryPusher.this.memberState.leaderUpdateCommittedIndex(currTerm, quorumIndex)) {
// 更新已提交的索引,此時只更新了Leader的 CommittedIndex指針,從節點的CommittedIndex會在后面‘
// DLedgerEntryPusher.EntryDispatcher 發送Append請求和Commit請求中得到更新
DLedgerEntryPusher.this.fsmCaller.onCommitted(quorumIndex);
} else {
// If the commit index is not advanced, we should wait for the next round
waitForRunning(1);
}
} catch (Throwable t) {
DLedgerEntryPusher.LOGGER.error("Error in {}", getName(), t);
DLedgerUtils.sleep(100);
}
}
四. 總結
本文詳細闡述了 RocketMQ DLedger 中的日志復制流程。
日志復制的設計理念包括:為每條日志編號以便管理與辨別;引入已提交指針來避免數據不一致問題,只有超過半數節點追加完成才向客戶端返回寫入成功;通過向從節點源源不斷轉發日志,并處理從節點落后時的數據同步與刪除,保證日志一致性。
日志復制類的設計體系中,DledgerEntryPusher 是核心類,構建了 EntryDispatcher、QuorumAckChecker 和 EntryHandler 三個對象,分別對應不同線程,處理不同任務。
日志復制流程如下:
- Leader 節點將日志推送到從節點:
- 日志轉發由
EntryDispatcher實現,其具有多種推送請求類型,初始狀態為COMPARE。 doCompare方法用于 Leader 向從節點發送COMPARE請求以比較數據差異,找到共識點后狀態變更為TRUNCATE。doTruncate方法處理發送TRUNCATE請求,指示從節點刪除多余日志,處理完成后狀態變更為APPEND。doAppend方法在確認主從數據一致后向從節點推送日志,內部有流控和重試機制。
- 日志轉發由
- 從節點收到 Leader 節點推送的日志并存儲,然后向 Leader 節點匯報日志復制結果:
- 從節點的日志接收由
EntryHandler實現,其通過handlePush方法接收請求并放入相應隊列,doWork方法進行任務分發處理。 handleDoCompare方法響應 Leader 的COMPARE請求,尋找共識點。handleDoTruncate方法響應TRUNCATE請求,刪除多余日志。handleDoAppend方法響應APPEND請求,追加日志。- 還具有異常檢測機制,檢查從節點日志復制是否異常。
- 從節點的日志接收由
- Leader 節點對日志復制進行仲裁:主要由
QuorumAckChecker實現,計算所有節點水位線的中位數,根據結果更新已提交索引。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號