Raft協議深度解析:RocketMQ中的自動Leader選舉與故障轉移
本文所涉及的注釋源碼:bigcoder84/dledger
RocketMQ 4.5版本之前,可以采用主從架構進行集群部署,但是如果 master 節點掛掉,不能自動在集群中選舉出新的 master 節點,需要人工介入,在4.5版本之后提供了 DLedger 模式,DLedger 是 Open Messaging 發布的一個基于 Raft 協議實現的Java類庫,可以方便引用到系統中,滿足其高可用、高可靠、強一致的需求,其中在 RocketMQ 中作為消息 Broker 存儲高可用實現的一種解決方案。使用Raft算法,如果 master 節點出現故障,可以自動選舉出新的 master 進行切換。
在閱讀本文之前,建議先仔細了解Raft協議的思路,具體可移步至:深度解析 Raft 分布式一致性協議
一. Raft協議概述
在分布式系統應用中,高可用、一致性是經常面臨的問題,針對不同的應用場景,我們會選擇不同的架構方式,比如master-slave、基于ZooKeeper 選主。隨著時間的推移,出現了基于Raft算法自動選主的方式,Raft 是在 Paxos 的基礎上,做了一些簡化和限制,大大簡化了算法的復雜度。Raft協議是目前分布式領域一個非常重要的一致性協議,RocketMQ 的主從切換機制也是介于Raft協議實現的。Raft 協議主要包含兩個部分:Leader選舉和日志復制。
1.1 Leader選舉
Raft協議的核心思想是在一個復制組內選舉一個Leader節點,后續統一由Leader節點處理客戶端的讀寫請求,從節點只是從Leader節點復制數據,即一個復制組在接收客戶端的讀寫請求之前,要先從復制組中選擇一個Leader節點,這個過程稱為Leader選舉。
Raft協議的選舉過程如下:
- 各個節點的初始狀態為Follower,每個節點會設置一個計時器,每個節點的計時時間是150~300ms的一個隨機值。
- 節點的計時器到期后,狀態會從Follower變更為Candidate, 進入該狀態的節點會發起一輪投票,首先為自己投上一票,然后向集群中的其他節點發起“拉票”,期待得到超過半數的選票支持。
- 當集群內的節點收到投票請求后,如果該節點本輪未進行投票,則投贊成票,否則投反對票,然后返回結果并重置計時器繼續倒數計時。如果計算器到期,則狀態會由Follower變更為Candidate。
- 當集群內的節點收到投票請求后,如果該節點本輪未進行投票,則投贊成票,否則投反對票,然后返回結果并重置計時器繼續倒數計時。如果計算器到期,則狀態會由Follower變更為Candidate。
- 主節點會定時向集群內的所有從節點發送心跳包。從節點在收到心跳包后重置計時器,這是主節點維持其“統治地位”的手段。因為從節點一旦計時器到期,就會從Follower變更為Candidate,以此來嘗試發起新一輪選舉。
Raft是一個分布式領域的一致性協議,只是一個方法論,需要使用者根據協議描述通過編程語言具體實現。
1.2 日志復制
客戶端向DLedger集群發起一個寫數據請求,Leader節點收到寫請求后先將數據存入Leader節點,然后將數據廣播給它所有的從節點。從節點收到Leader節點的數據推送后對數據進行存儲,然后向主節點匯報存儲的結果。Leader節點會對該日志的存儲結果進行仲裁,如果超過集群數量的一半都成功存儲了該數據,則向客戶端返回寫入成功,否則向客戶端返回寫入失敗。
本文主要分析 DLedger 中 Leader 選舉的原理,日志復制模塊可移步至:
二. DLedger概述
2.1 DLedger是什么
DLedger 定位是一個工業級的 Java Library,可以友好地嵌入各類 Java 系統中,滿足其高可用、高可靠、強一致的需求,和這一定位比較接近的是 Ratis。
Ratis 是一個典型的"日志 + 狀態機"的實現,雖然其狀態機可以自定義,卻仍然不滿足消息領域的需求。 在消息領域,如果根據日志再去構建“消息狀態機”,就會產生 Double IO 的問題,造成極大的資源浪費,因此,在消息領域,是不需要狀態機的,日志和消息應該是合二為一。
相比于 Ratis,DLedger 只提供日志的實現,只擁有日志寫入和讀出的接口,且對順序讀出和隨機讀出做了優化,充分適應消息系統消峰填谷的需求。
DLedger 的純粹日志寫入和讀出,使其精簡而健壯,總代碼不超過4000行,測試覆蓋率高達70%。而且這種原子化的設計,使其不僅可以充分適應消息系統,也可以基于這些日志去構建自己的狀態機,從而適應更廣泛的場景。
綜上所述,DLedger 是一個基于 Raft 實現的、高可靠、高可用、強一致的 Commitlog 存儲 Library。
DLedger 的實現大體可以分為以下兩個部分:
1.選舉 Leader
2.復制日志
其整體架構如下圖:
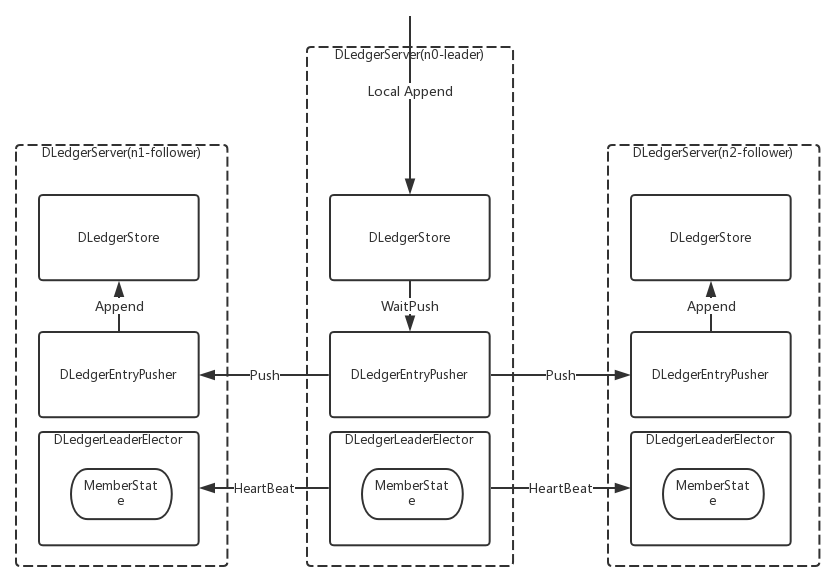
后文我們將詳細介紹 DLedger 的實現細節以及它是如何整合進RocketMQ中使得RocketMQ集群也能擁有分布式強一致性集群模式。
2.2 DLedger應用
在 Apache RocketMQ 中,DLedger 不僅被直接用來當做消息存儲,也被用來實現一個嵌入式的 KV 系統,以存儲元數據信息。
2.2.1 DLedger 作為 RocketMQ 的消息存儲
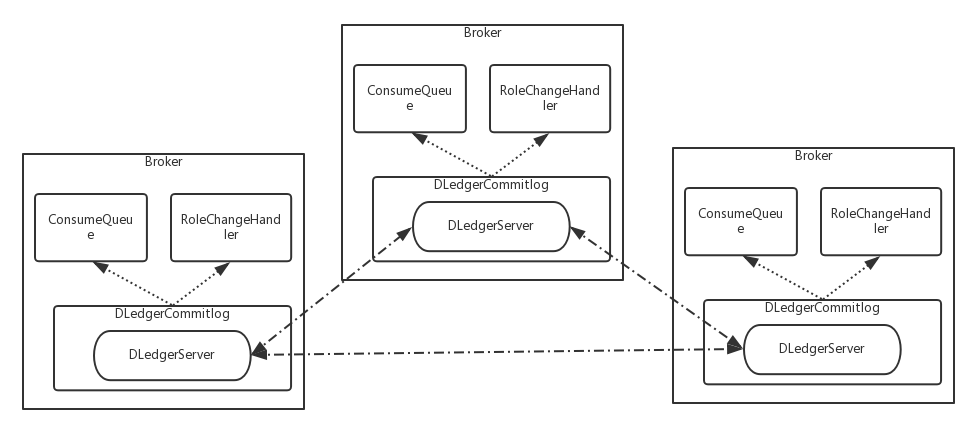
- DLedgerCommitlog 用來代替現有的 Commitlog 存儲實際消息內容,它通過包裝一個 DLedgerServer 來實現復制;
- 依靠 DLedger 的直接存取日志的特點,消費消息時,直接從 DLedger 讀取日志內容作為消息返回給客戶端;
- 依靠 DLedger 的 Raft 選舉功能,通過 RoleChangeHandler 把角色變更透傳給 RocketMQ 的Broker,從而達到主備自動切換的目標;
2.2.2 利用 DLedger 實現一個高可用的嵌入式 KV 存儲
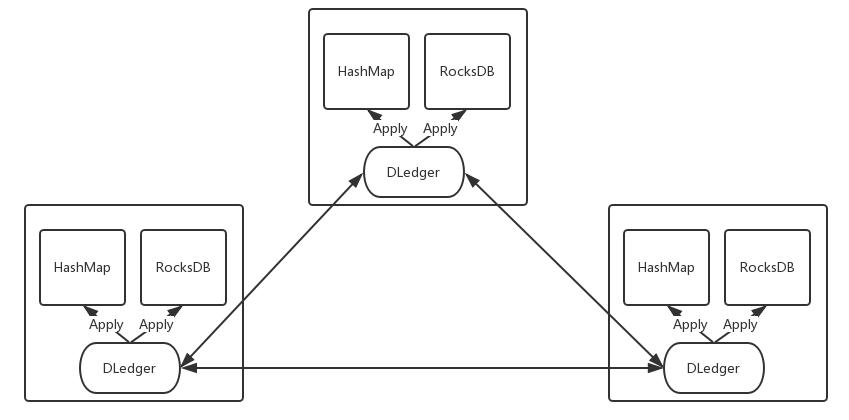
- DLedger 用來存儲 KV 的增刪改日志;
- 通過將日志一條條 Apply 到本地 Map,比如 HashMap 或者 第三方 的 RocksDB等;
三. RocketMQ DLedger Leader選舉流程
RocketMQ 實現Raft協議Leader選舉,其代碼并不在 RocketMQ 工程中,而是在 openmessaging 標準中。
DLedger選主模塊中主要涉及如下類:
-
DLedgerConfig:主從切換模塊相關的配置信息
-
DLedgerClientProtocol:DLedger客戶端協議。
-
DLedgerRaftProtocol:DLedger Raft協議。
-
DLedgerClientProtocolHandler:DLedger客戶端協議處理器。
-
DLedgerProtocolHandler:DLedger服務端協議處理器。
-
DLedgerRpcService:DLedger節點之前的網絡通信,默認基于Netty實現,默認實現類為DLedgerRpcNettyService。
-
DLedgerLeaderElector:基于Raft協議的Leader選舉類(重點)。
-
DLedgerServer:基于Raft協議的集群內節點的封裝類。
3.1 DLedgerLeaderElector核心類及核心屬性
/**
* 基于Raft協議的Leader選舉類
*/
public class DLedgerLeaderElector {
private static final Logger LOGGER = LoggerFactory.getLogger(DLedgerLeaderElector.class);
/**
* 隨機數生成器,對應Raft協議中選舉超時時間,是一個隨機數
*/
private final Random random = new Random();
/**
* 配置參數
*/
private final DLedgerConfig dLedgerConfig;
/**
* 節點狀態機
*/
private final MemberState memberState;
/**
* RPC服務,實現向集群內的節點發送心跳包、投票的RPC。默認是基于Netty實現的:DLedgerRpcNettyService
*/
private final DLedgerRpcService dLedgerRpcService;
//as a server handler
//record the last leader state
/**
* 上次收到心跳包的時間戳
*/
private volatile long lastLeaderHeartBeatTime = -1;
/**
* 上次發送心跳包的時間戳
*/
private volatile long lastSendHeartBeatTime = -1;
/**
* 上次成功收到心跳包的時間戳
*/
private volatile long lastSuccHeartBeatTime = -1;
/**
* 一個心跳包的周期,默認為2s
*/
private int heartBeatTimeIntervalMs = 2000;
/**
* 允許最大的n個心跳周期內未收到心跳包,狀態為Follower的節點只有超過maxHeartBeatLeak *
* heartBeatTimeIntervalMs的時間內未收到主節點的心跳包,才會重新
* 進入Candidate狀態,進行下一輪選舉。
*/
private int maxHeartBeatLeak = 3;
//as a client
/**
* 下一次可發起投票的時間,如果當前時間小于該值,說明計時器未過期,此時無須發起投票
*/
private long nextTimeToRequestVote = -1;
/**
* 是否應該立即發起投票。
* 如果為true,則忽略計時器,該值默認為false。作用是在從節點
* 收到主節點的心跳包,并且當前狀態機的輪次大于主節點輪次(說明
* 集群中Leader的投票輪次小于從節點的輪次)時,立即發起新的投票
* 請求
*/
private volatile boolean needIncreaseTermImmediately = false;
/**
* 最小的發送投票間隔時間,默認為300ms
*/
private int minVoteIntervalMs = 300;
/**
* 最大的發送投票間隔時間,默認為1000ms。
*/
private int maxVoteIntervalMs = 1000;
/**
* 注冊的節點狀態處理器,通過addRoleChangeHandler方法添加
*/
private final List<RoleChangeHandler> roleChangeHandlers = new ArrayList<>();
private VoteResponse.ParseResult lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
/**
* 上一次投票的開銷
*/
private long lastVoteCost = 0L;
/**
* 狀態機管理器
*/
private final StateMaintainer stateMaintainer;
private final TakeLeadershipTask takeLeadershipTask = new TakeLeadershipTask();
}
3.2 選舉狀態管理器初始化
通過DLedgerLeaderElector的startup()方法啟動狀態管理機:
public void startup() {
/**
* stateMaintainer是Leader選舉內部維護的狀態機,即維護節
* 點狀態在Follower、Candidate、Leader之間轉換,需要先調用其
* start()方法啟動狀態機。
*/
stateMaintainer.start();
for (RoleChangeHandler roleChangeHandler : roleChangeHandlers) {
// 依次啟動注冊的角色轉換監聽器,即內部狀態機的狀態發生變更后的事件監聽器,是Leader選舉的功能擴展點
roleChangeHandler.startup();
}
}
實現關鍵點如下:
-
stateMaintainer是Leader選舉內部維護的狀態機,即維護節點狀態在Follower、Candidate、Leader之間轉換,需要先調用其start()方法啟動狀態機。
-
依次啟動注冊的角色轉換監聽器,即內部狀態機的狀態發生變更后的事件監聽器,是Leader選舉的功能擴展點。
StateMaintainer的父類為ShutdownAbleThread,繼承自Thread,故調用其start()方法最終會調用run()方法:
//io.openmessaging.storage.dledger.common.ShutdownAbleThread#run
@Override
public void run() {
while (running.get()) {
try {
doWork();
} catch (Throwable t) {
if (logger != null) {
logger.error("Unexpected Error in running {} ", getName(), t);
}
}
}
latch.countDown();
}
StateMaintainer狀態機的實現要點就是 “無限死循環”調用doWork()方法,直到該狀態機被關閉。doWork() 方法在 ShutdownAbleThread 被聲明為抽象方法,具體由各個子類實現,我們將目光投向StateMaintainer的doWork()方法:
public class StateMaintainer extends ShutdownAbleThread {
public StateMaintainer(String name, Logger logger) {
super(name, logger);
}
@Override
public void doWork() {
try {
// 如果當前節點參與Leader選舉,則調用maintainState()方法驅動狀態機,并且每一次驅動狀態機后休息10ms
if (DLedgerLeaderElector.this.dLedgerConfig.isEnableLeaderElector()) {
DLedgerLeaderElector.this.refreshIntervals(dLedgerConfig);
DLedgerLeaderElector.this.maintainState();
}
sleep(10);
} catch (Throwable t) {
DLedgerLeaderElector.LOGGER.error("Error in heartbeat", t);
}
}
}
如果當前節點參與Leader選舉,則調用maintainState()方法驅動狀態機,并且每一次驅動狀態機后休息10ms。
private void maintainState() throws Exception {
// 如果是leader狀態
if (memberState.isLeader()) {
// leader狀態、主節點,該狀態下需要定時向從節點發送心跳包,用于傳播數據、確保其領導地位
maintainAsLeader();
} else if (memberState.isFollower()) {
// follower狀態,該狀態下會開啟定時器,嘗試進入Candidate狀態,以便發起投票選舉,一旦收到主節點的心跳包,則重置定時器
maintainAsFollower();
} else {
// Candidate(候選者)狀態,該狀態下的節點會發起投票,嘗試選擇自己為主節點,選舉成功后,不會存在該狀態下的節點
maintainAsCandidate();
}
}
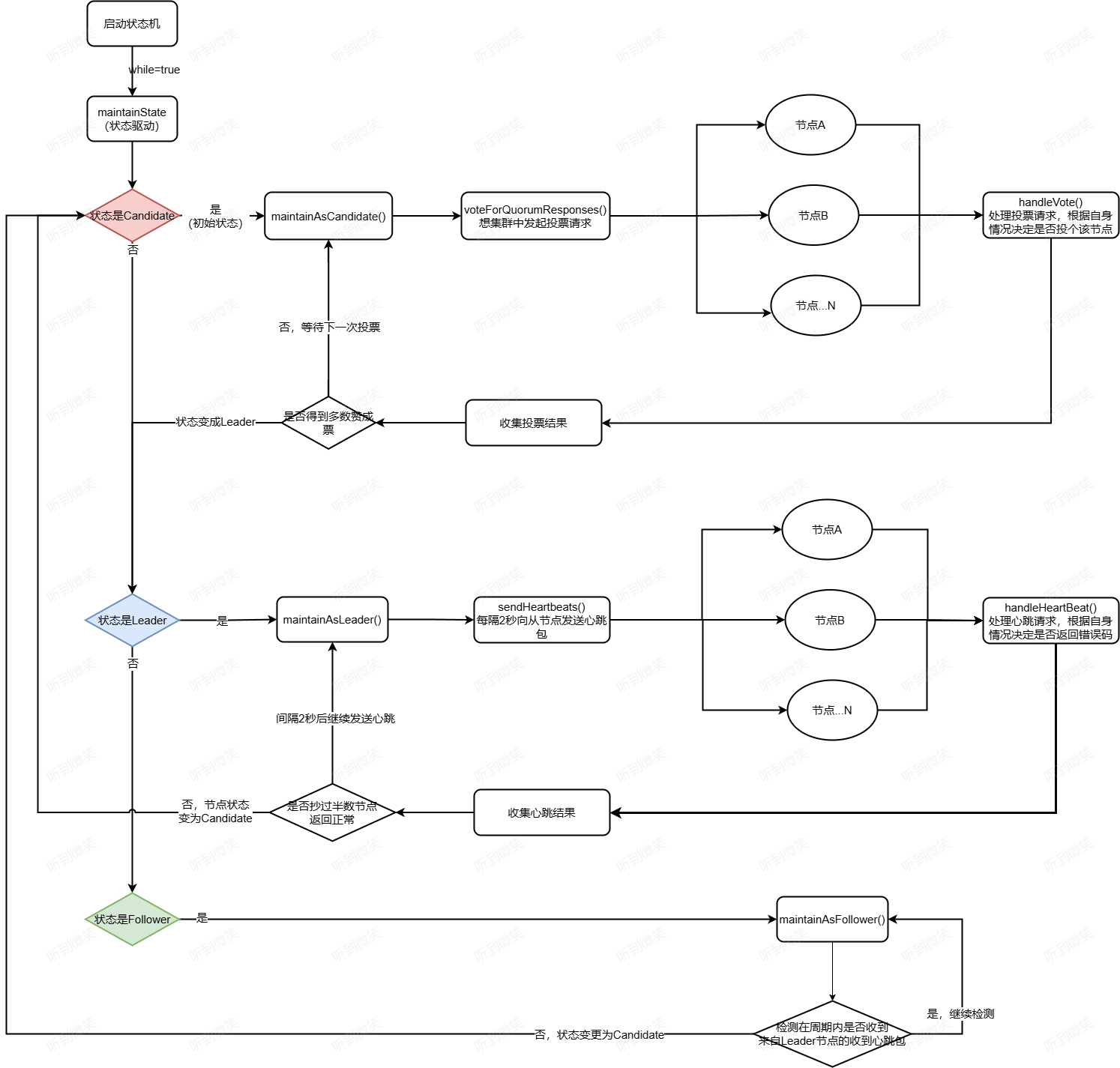
狀態機的驅動實現思路比較簡單,就是根據狀態機當前狀態對應的方法,在該狀態下檢測狀態機是否滿足狀態變更的條件,如果滿足則變更狀態。接下來對上述3個方法進行詳細介紹,幫助讀者理解節點在各個狀態時需要處理的核心邏輯。為便于理解,先給出在3個狀態下需要處理的核心邏輯點。
- Leader:領導者、主節點,該狀態下需要定時向從節點發送心跳包,用于傳播數據、確保其領導地位。
- Follower:從節點,該狀態下會開啟定時器,嘗試進入Candidate狀態,以便發起投票選舉,一旦收到主節點的心跳包,則重置定時器。
- Candidate:候選者,該狀態下的節點會發起投票,嘗試選擇自己為主節點,選舉成功后,不會存在該狀態下的節點。
3.3 選舉狀態機狀態流轉
MemberState的初始化,發現其初始狀態為Candidate。接下來深入學習maintainAsCandidate()方法,以此探究實現原理。
3.3.1 maintainAsCandidate
根據狀態機的流轉代碼可知,當集群中節點的狀態為Candidate時會執行該方法,處于該狀態的節點會發起投票請求。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
// 下一次可發起投票的時間,如果當前時間小于該值,說明計時器未過期,此時無須發起投票
if (System.currentTimeMillis() < nextTimeToRequestVote && !needIncreaseTermImmediately) {
return;
}
// 投票輪次
long term;
// Leader節點當前的投票輪次。
long ledgerEndTerm;
// 當前日志的最大序列,即下一條日志的開始index
long ledgerEndIndex;
if (!memberState.isCandidate()) {
return;
}
第一步,先介紹幾個變量的含義。
- long nextTimeToRequestVote:下一次可發起投票的時間,如果當前時間小于該值,說明計時器未過期,此時無須發起投票。
- long needIncreaseTermImmediately:是否應該立即發起投票。如果為true,則忽略計時器,該值默認為false。作用是在從節點收到主節點的心跳包,并且當前狀態機的輪次大于主節點輪次(說明 集群中Leader的投票輪次小于從節點的輪次)時,立即發起新的投票 請求。
- long term:投票輪次。
- long ledgerEndTerm:Leader節點當前的投票輪次。
- long ledgerEndIndex:當前節點日志的最大序列號,即下一條日志的開始index。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
synchronized (memberState) {
// 雙重校驗鎖,對狀態機加鎖后再次校驗狀態機狀態是否為Candidate,既保證了并發性能,又能解決并發安全問題
if (!memberState.isCandidate()) {
return;
}
if (lastParseResult == VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT || needIncreaseTermImmediately) {
long prevTerm = memberState.currTerm();
term = memberState.nextTerm();
LOGGER.info("{}_[INCREASE_TERM] from {} to {}", memberState.getSelfId(), prevTerm, term);
lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
} else {
// 如果上一次的投票結果不是WAIT_TO_VOTE_NEXT,則投票輪次依然為狀態機內部維護的投票輪次。
term = memberState.currTerm();
}
ledgerEndIndex = memberState.getLedgerEndIndex();
ledgerEndTerm = memberState.getLedgerEndTerm();
}
第二步:初始化team、ledgerEndIndex、ledgerEndTerm屬性,其實現關鍵點如下:
投票輪次的初始化機制:如果上一次的投票結果為WAIT_TO_VOTE_NEXT(等待下一輪投票)或應該立即發起投票,則通過狀態機獲取新一輪投票的序號,默認在當前輪次遞增1,并將lastParseResult更新為WAIT_TO_REVOTE(等待投票)。
如果上一次的投票結果不是WAIT_TO_VOTE_NEXT,則投票輪次依然為狀態機內部維護的投票輪次。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
if (needIncreaseTermImmediately) {
// 如果needIncreaseTermImmediately為true,則重置該標
//記位為false,并重新設置下一次投票超時時間,其實現邏輯為當前時
//間戳+上次投票的開銷+最小投票間隔之間的隨機值,這里是Raft協議
//的一個關鍵點,即每個節點的投票超時時間引入了隨機值
nextTimeToRequestVote = getNextTimeToRequestVote();
needIncreaseTermImmediately = false;
return;
}
第三步:如果 needIncreaseTermImmediately 為 true,則重置該標記位為 false,并重新設置下一次投票超時時間,其實現邏輯為當前時間戳+上次投票的開銷+最小投票間隔之間的隨機值,這里是Raft協議 的一個關鍵點,即每個節點的投票超時時間引入了隨機值。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
// 向集群其他節點發起投票請求求,并等待各個節點的響應結果。
final List<CompletableFuture<VoteResponse>> quorumVoteResponses = voteForQuorumResponses(term, ledgerEndTerm, ledgerEndIndex);
第四步:向集群內的其他節點發起投票請求,并等待各個節點的響應結果。在這里我們先將其當作黑盒,詳細過程我們在后文闡述。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
// 已知的最大投票輪次
final AtomicLong knownMaxTermInGroup = new AtomicLong(term);
// 所有投票數
final AtomicInteger allNum = new AtomicInteger(0);
// 有效投票數
final AtomicInteger validNum = new AtomicInteger(0);
// 贊成票數量
final AtomicInteger acceptedNum = new AtomicInteger(0);
// 未準備投票的節點數量,如果對端節點的投票輪次小于發起投票的輪次,則認為對端未準備好,對端節點使用本輪次進入Candidate狀態。
final AtomicInteger notReadyTermNum = new AtomicInteger(0);
// 發起投票的節點的ledgerEndTerm小于對端節點的個數
final AtomicInteger biggerLedgerNum = new AtomicInteger(0);
// 是否已經存在Leader
final AtomicBoolean alreadyHasLeader = new AtomicBoolean(false);
在進行投票結果仲裁之前,先介紹幾個局部變量的含義:
- knownMaxTermInGroup:已知的最大投票輪次
- allNum:所有投票數
- validNum:有效投票數
- acceptedNum:贊成票數量
- notReadyTermNum:未準備投票的節點數量,如果對端節點的投票輪次小于發起投票的輪次,則認為對端未準備好,對端節點使用本輪次進入Candidate狀態。
- biggerLedgerNum:發起投票的節點的ledgerEndTerm小于對端節點的個數
- alreadyHasLeader:是否已經存在Leader
上述變量值都來自當前節點向集群內其他節點發送投票請求的響應結果,即投票與響應投票。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
CountDownLatch voteLatch = new CountDownLatch(1);
for (CompletableFuture<VoteResponse> future : quorumVoteResponses) {
future.whenComplete((VoteResponse x, Throwable ex) -> {
try {
if (ex != null) {
throw ex;
}
LOGGER.info("[{}][GetVoteResponse] {}", memberState.getSelfId(), JSON.toJSONString(x));
if (x.getVoteResult() != VoteResponse.RESULT.UNKNOWN) {
validNum.incrementAndGet();
}
synchronized (knownMaxTermInGroup) {
switch (x.getVoteResult()) {
case ACCEPT:
// 贊成票(acceptedNum)加1,只有得到的贊成票超過集群節點數量的一半才能成為Leader。
acceptedNum.incrementAndGet();
break;
case REJECT_ALREADY_HAS_LEADER:
// 拒絕票,原因是集群中已經存在Leaer節點了。alreadyHasLeader設置為true,無須再判斷其他投票結果了,結束本輪投票。
alreadyHasLeader.compareAndSet(false, true);
break;
case REJECT_TERM_SMALL_THAN_LEDGER:
// 拒絕票,原因是自己維護的term小于遠端維護的ledgerEndTerm。如果對端的team大于自己的
// team,需要記錄對端最大的投票輪次,以便更新自己的投票輪次
case REJECT_EXPIRED_VOTE_TERM:
// 拒絕票,原因是自己維護的投票輪次小于遠端維護的投票輪次,并且更新自己維護的投票輪次
if (x.getTerm() > knownMaxTermInGroup.get()) {
knownMaxTermInGroup.set(x.getTerm());
}
break;
case REJECT_EXPIRED_LEDGER_TERM:
// 拒絕票,原因是自己維護的ledgerTerm小于對端維護的ledgerTerm,此種情況下需要增加計數器
//biggerLedgerNum的值。
case REJECT_SMALL_LEDGER_END_INDEX:
// 拒絕票,原因是對端的ledgerTeam與自己維護的ledgerTeam相等,但自己維護的
//dedgerEndIndex小于對端維護的值,這種情況下需要增加biggerLedgerNum計數器的值。
biggerLedgerNum.incrementAndGet();
break;
case REJECT_TERM_NOT_READY:
// 拒絕票,原因是對端的投票輪次小于自己的投票輪次,即對端還未準備好投票。此時對端節點使用自己
// 的投票輪次進入Candidate狀態。
notReadyTermNum.incrementAndGet();
break;
case REJECT_ALREADY_VOTED:
// 拒絕票,原因是已經投給了其他節點
case REJECT_TAKING_LEADERSHIP:
default:
break;
}
}
if (alreadyHasLeader.get()
|| memberState.isQuorum(acceptedNum.get())
|| memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) {
voteLatch.countDown();
}
} catch (Throwable t) {
LOGGER.error("vote response failed", t);
} finally {
allNum.incrementAndGet();
if (allNum.get() == memberState.peerSize()) {
// 統計完成后調用countDown,喚醒被阻塞的主線程
voteLatch.countDown();
}
}
});
}
第五步:統計投票結果,后續會根據投票結果決定是否可以成為Leader,從而決定當前節點的狀態,具體實現邏輯如下:
-
ACCEPT:贊成票(acceptedNum)加1,只有得到的贊成票超過集群節點數量的一半才能成為Leader。
-
REJECT_ALREADY_HAS_LEADER:拒絕票,原因是集群中已經存在Leaer節點了。alreadyHasLeader設置為true,無須再判斷其他投票結果了,結束本輪投票。
-
REJECT_TERM_SMALL_THAN_LEDGER:拒絕票,原因是自己維護的term小于遠端維護的ledgerEndTerm。如果對端的 term 大于自己的 term,需要記錄對端最大的投票輪次,以便更新自己的投票輪次。
-
REJECT_EXPIRED_VOTE_TERM:拒絕票,原因是自己維護的投票輪次小于遠端維護的投票輪次,并且更新自己維護的投票輪次。
-
REJECT_EXPIRED_LEDGER_TERM:拒絕票,原因是自己維護的 ledgerTerm 小于對端維護的 ledgerTerm ,此種情況下需要增加計數器biggerLedgerNum的值。
-
REJECT_SMALL_LEDGER_END_INDEX:拒絕票,原因是對端的ledgerTeam與自己維護的ledgerTeam相等,但自己維護的dedgerEndIndex小于對端維護的值,這種情況下需要增加biggerLedgerNum計數器的值。
-
REJECT_TERM_NOT_READY:拒絕票,原因是對端的投票輪次小于自己的投票輪次,即對端還未準備好投票。此時對端節點使用自己的投票輪次進入Candidate狀態。
-
REJECT_ALREADY_VOTED:拒絕票,原因是已經投給了其他節點。
-
REJECT_TAKING_LEADERSHIP:拒絕票,原因是對端的投票輪次和自己相等,但是對端節點的ledgerEndIndex比自己的ledgerEndIndex大,這意味著對端節點的日志比自己更新。Raft協議中規定,節點不能將自己手中票額投給比自己日志落后的節點。
每個 candidate 必須在 RequestVote RPC 中攜帶自己本地日志的最新 (term, index),如果 follower 發現這個 candidate 的日志還沒有自己的新,則拒絕投票給該 candidate。
Candidate 想要贏得選舉成為 leader,必須得到集群大多數節點的投票,那么它的日志就一定至少不落后于大多數節點。又因為一條日志只有復制到了大多數節點才能被 commit,因此能贏得選舉的 candidate 一定擁有所有 committed 日志。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
try {
// 因為投票結果的統計是異步的,這里等待投票結果統計完成。
voteLatch.await(2000 + random.nextInt(maxVoteIntervalMs), TimeUnit.MILLISECONDS);
} catch (Throwable ignore) {
}
第六步:前面在獲取投票響應時是在CompletableFuture.whenComplete中實現的,統計過程是異步完成的,所以這里需要等待投票結果統計完成。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsCandidate
// 投票耗時
lastVoteCost = DLedgerUtils.elapsed(startVoteTimeMs);
VoteResponse.ParseResult parseResult;
if (knownMaxTermInGroup.get() > term) {
// 如果對端的投票輪次大于當前節點維護的投票輪次,則先重置
// 投票計時器,然后在定時器到期后使用對端的投票輪次重新進入
//Candidate狀態。
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote();
changeRoleToCandidate(knownMaxTermInGroup.get());
} else if (alreadyHasLeader.get()) {
// 如果集群內已經存在Leader節點,當前節點將繼續保持
//Candidate狀態,重置計時器,但這個計時器還需要增加
//heartBeatTimeIntervalMs*maxHeartBeatLeak,其中
//heartBeatTimeIntervalMs為一次心跳間隔時間,maxHeartBeatLeak為
//允許丟失的最大心跳包。增加這個時間是因為集群內既然已經存在
//Leader節點了,就會在一個心跳周期內發送心跳包,從節點在收到心
//跳包后會重置定時器,即阻止Follower節點進入Candidate狀態。這樣
//做的目的是在指定時間內收到Leader節點的心跳包,從而驅動當前節
//點的狀態由Candidate向Follower轉換
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote() + (long) heartBeatTimeIntervalMs * maxHeartBeatLeak;
} else if (!memberState.isQuorum(validNum.get())) {
// 如果收到的有效票數未超過半數,則重置計時器并等待重新投
//票,注意當前狀態為WAIT_TO_REVOTE,該狀態下的特征是下次投票時
//不增加投票輪次。
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote();
} else if (!memberState.isQuorum(validNum.get() - biggerLedgerNum.get())) {
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote() + maxVoteIntervalMs;
} else if (memberState.isQuorum(acceptedNum.get())) {
// 如果得到的贊同票超過半數,則成為Leader節點,
parseResult = VoteResponse.ParseResult.PASSED;
} else if (memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) {
// 如果得到的贊成票加上未準備投票的節點數超過半數,則立即
//發起投票,故其結果為REVOTE_IMMEDIATELY。
parseResult = VoteResponse.ParseResult.REVOTE_IMMEDIATELY;
} else {
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote();
}
lastParseResult = parseResult;
LOGGER.info("[{}] [PARSE_VOTE_RESULT] cost={} term={} memberNum={} allNum={} acceptedNum={} notReadyTermNum={} biggerLedgerNum={} alreadyHasLeader={} maxTerm={} result={}",
memberState.getSelfId(), lastVoteCost, term, memberState.peerSize(), allNum, acceptedNum, notReadyTermNum, biggerLedgerNum, alreadyHasLeader, knownMaxTermInGroup.get(), parseResult);
if (parseResult == VoteResponse.ParseResult.PASSED) {
LOGGER.info("[{}] [VOTE_RESULT] has been elected to be the leader in term {}", memberState.getSelfId(), term);
// 調用changeRoleToLeader方法驅動狀態機向Leader狀態轉換。
changeRoleToLeader(term);
}
第七步:根據投票結果進行仲裁,從而驅動狀態機:
-
如果對端的投票輪次大于當前節點維護的投票輪次,則先重置投票計時器,然后在定時器到期后使用對端的投票輪次重新進入Candidate狀態。
-
如果集群內已經存在Leader節點,當前節點將繼續保持 Candidate 狀態,重置計時器,但這個計時器還需要增加
heartBeatTimeIntervalMs*maxHeartBeatLeak,其中heartBeatTimeIntervalMs為一次心跳間隔時間,maxHeartBeatLeak為允許丟失的最大心跳包。增加這個時間是因為集群內既然已經存在Leader節點了,就會在一個心跳周期內發送心跳包,從節點在收到心跳包后會重置定時器,即阻止Follower節點進入Candidate狀態。這樣做的目的是在指定時間內收到Leader節點的心跳包,從而驅動當前節點的狀態由Candidate向Follower轉換 -
如果收到的有效票數未超過半數,則重置計時器并等待重新投票,注意當前狀態為WAIT_TO_REVOTE,該狀態下的特征是下次投票時不增加投票輪次。
-
如果得到的贊同票超過半數,則成為Leader節點。
-
如果得到的贊成票加上未準備好投票的節點數超過半數,則立即發起投票,故其結果為REVOTE_IMMEDIATELY,因為此處沒有更新 nextTimeToRequestVote 字段,所以下次進入循環又會進入投票邏輯。
maintainAsCandidate()方法的流程就介紹到這里了,下面介紹maintainAsLeader()方法。
3.3.2 maintainAsLeader
經過 maintainAsCandidate 投票選舉被其他節點選舉為Leader后, 在該狀態下會執行maintainAsLeader()方法,其他節點的狀態還是Candidate,并在計時器過期后,又嘗試發起選舉。接下來重點分析成為Leader節點后,該節點會做些什么。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsLeader
private void maintainAsLeader() throws Exception {
if (DLedgerUtils.elapsed(lastSendHeartBeatTime) > heartBeatTimeIntervalMs) {
// 如果當前時間與上一次發送心跳包的間隔時間大于一個心跳包周期(默認為2s),則進入心跳包發送處理邏輯,否則忽略。
long term;
String leaderId;
synchronized (memberState) {
if (!memberState.isLeader()) {
// 如果當前狀態機的狀態已經不是Leader,則忽略。
//stop sending
return;
}
term = memberState.currTerm();
leaderId = memberState.getLeaderId();
// 記錄本次發送心跳包的時間戳。
lastSendHeartBeatTime = System.currentTimeMillis();
}
// 調用sendHeartbeats()方法向集群內的從節點發送心跳包
sendHeartbeats(term, leaderId);
}
}
Leader狀態的節點主要按固定頻率向集群內的其他節點發送心跳包,實現細節如下:
- 如果當前時間與上一次發送心跳包的間隔時間大于一個心跳包周期(默認為2s),則進入心跳包發送處理邏輯,否則忽略。
- 如果當前狀態機的狀態已經不是Leader,則忽略。
- 記錄本次發送心跳包的時間戳。
- 調用sendHeartbeats()方法向集群內的從節點發送心跳包。該方法我們在后文詳細介紹。
3.3.3 maintainAsFollower
Candidate狀態的節點在收到Leader節點發送的心跳包后,狀態變更為Follower,我們先來看在Follower狀態下,節點會做些什么:
//io.openmessaging.storage.dledger.DLedgerLeaderElector#maintainAsFollower
private void maintainAsFollower() {
// 如果節點在maxHeartBeatLeak個心跳包(默認為3個)周期內未收
// 到心跳包,則將狀態變更為Candidate。從這里也不得不佩服RocketMQ
// 在性能方面如此追求極致,即在不加鎖的情況下判斷是否超過了2個心
// 跳包周期,減少加鎖次數,提高性能。
if (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > 2L * heartBeatTimeIntervalMs) {
synchronized (memberState) {
if (memberState.isFollower() && DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > (long) maxHeartBeatLeak * heartBeatTimeIntervalMs) {
LOGGER.info("[{}][HeartBeatTimeOut] lastLeaderHeartBeatTime: {} heartBeatTimeIntervalMs: {} lastLeader={}", memberState.getSelfId(), new Timestamp(lastLeaderHeartBeatTime), heartBeatTimeIntervalMs, memberState.getLeaderId());
// 將節點狀態更改為 Candidate
changeRoleToCandidate(memberState.currTerm());
}
}
}
}
如果節點在maxHeartBeatLeak個心跳包(默認為3個)周期內未收到心跳包,則將狀態變更為Candidate。從這里也不得不佩服RocketMQ 在性能方面如此追求極致,即在不加鎖的情況下判斷是否超過了2個心跳包周期,減少加鎖次數,提高性能。
上面3個方法就是狀態機在當前狀態下執行的處理邏輯,主要是結合當前實際的運行情況將狀態機進行驅動,例如調用changeRoleToCandidate() 方法將自身狀態變更為 Candidate,調用 changeRoleToLeader() 方法將狀態變更為 Leader,調用 changeRoleToFollower() 方法將狀態變更為 Follower。這3個方法的實現類似,接下來以 changeRoleToLeader() 方法為例進行講解。
3.3.4 changeRoleToLeader
當狀態機從Candidate狀態變更為Leader節點后會調用該方法,即當處于Candidate狀態的節點在得到集群內超過半數節點的支持后將進入該狀態,我們來看該方法的實現細節:
// io.openmessaging.storage.dledger.DLedgerLeaderElector#changeRoleToLeader
public void changeRoleToLeader(long term) {
synchronized (memberState) {
if (memberState.currTerm() == term) {
memberState.changeToLeader(term);
lastSendHeartBeatTime = -1;
// 執行節點變換擴展點代碼
handleRoleChange(term, MemberState.Role.LEADER);
LOGGER.info("[{}] [ChangeRoleToLeader] from term: {} and currTerm: {}", memberState.getSelfId(), term, memberState.currTerm());
} else {
LOGGER.warn("[{}] skip to be the leader in term: {}, but currTerm is: {}", memberState.getSelfId(), term, memberState.currTerm());
}
}
}
首先更新狀態機(MemberState)的角色為Leader,并設置leaderId為當前節點的ID,然后調用 handleRoleChange 方法觸發角色狀態轉換事件,從而執行擴展點的邏輯代碼。
選舉狀態機狀態的流轉就介紹到這里,在上面的流程中我們忽略了兩個重要的過程:發起投票請求與投票請求響應、發送心跳包與心跳包響應,接下來重點介紹這兩個過程
3.4 發送投票請求與處理投票請求
節點的狀態為Candidate時會向集群內的其他節點發起投票請求(個人認為理解為拉票更好),向對方詢問是否愿意選舉“我”為Leader,對端節點會根據自己的情況對其投贊成票或拒絕票,如果投拒絕票,還會給出拒絕的原因,具體由voteForQuorumResponses()、handleVote()這兩個方法實現,接下來我們分別對這兩個方法進行詳細分析
3.4.1 voteForQuorumResponses(發起投票請求)
// io.openmessaging.storage.dledger.DLedgerLeaderElector#voteForQuorumResponses
/**
* 異步向集群其他節點發起投票請求求,并等待各個節點的響應結果
* @param term
* @param ledgerEndTerm
* @param ledgerEndIndex
* @return
* @throws Exception
*/
private List<CompletableFuture<VoteResponse>> voteForQuorumResponses(long term, long ledgerEndTerm,
long ledgerEndIndex) throws Exception {
List<CompletableFuture<VoteResponse>> responses = new ArrayList<>();
for (String id : memberState.getPeerMap().keySet()) {
VoteRequest voteRequest = new VoteRequest();
voteRequest.setGroup(memberState.getGroup());
voteRequest.setLedgerEndIndex(ledgerEndIndex);
voteRequest.setLedgerEndTerm(ledgerEndTerm);
voteRequest.setLeaderId(memberState.getSelfId());
voteRequest.setTerm(term);
voteRequest.setRemoteId(id);
voteRequest.setLocalId(memberState.getSelfId());
CompletableFuture<VoteResponse> voteResponse;
if (memberState.getSelfId().equals(id)) {
// 如果投票人是自己,則直接調用handleVote()方法處理投票請求,并返回處理結果。
voteResponse = handleVote(voteRequest, true);
} else {
//async
// 如果投票人不是自己,則調用dLedgerRpcService.vote()方法發起投票請求,并返回處理結果。
voteResponse = dLedgerRpcService.vote(voteRequest);
}
responses.add(voteResponse);
}
return responses;
}
各參數含義如下。
-
long term:發起投票節點當前維護的投票輪次。
-
long ledgerEndTerm:發起投票節點當前維護的最大投票輪次。
-
long ledgerEndIndex:發起投票節點維護的最大日志條目索引。
遍歷集群內的所有節點,依次構建投票請求并通過網絡異步發送到對端節點,發起投票節點會默認為自己投上一票,投票邏輯被封裝在handleVote()方法中。
3.4.2 handleVote(響應投票請求)
因為一個節點可能會收到多個節點的“拉票”請求,存在并發問 題,所以需要引入synchronized機制,鎖定狀態機memberState對象。接下來我們詳細了解其實現邏輯:
// io.openmessaging.storage.dledger.DLedgerLeaderElector#handleVote
if (!memberState.isPeerMember(request.getLeaderId())) {
// 如果拉票的節點不是集群已知的成員,則直接拒絕拉票
LOGGER.warn("[BUG] [HandleVote] remoteId={} is an unknown member", request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNKNOWN_LEADER));
}
if (!self && memberState.getSelfId().equals(request.getLeaderId())) {
// 如果不是自己給自己拉票,但是拉票節點的ID和自己又一致,則直接拒絕拉票。(異常情況,配置有誤,才會走入此分支)
LOGGER.warn("[BUG] [HandleVote] selfId={} but remoteId={}", memberState.getSelfId(), request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNEXPECTED_LEADER));
}
第一步:先進行一些基礎校驗。
- 檢查此次拉票請求是否是集群中的一直節點,如果不是則決絕拉票。
- 如果不是自己給自己拉票,但是拉票節點的ID和自己又一致,則直接拒絕拉票。(異常情況,配置有誤,才會走入此分支)
// io.openmessaging.storage.dledger.DLedgerLeaderElector#handleVote
if (request.getLedgerEndTerm() < memberState.getLedgerEndTerm()) {
// 如果拉票節點的ledgerEndTerm小于當前節點的ledgerEndTerm,則直接拒絕拉票。
// 原因是發起投票節點的日志復制進度比當前節點低,這種情況是不能成為主節點的,否則會造成數據丟失。
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_LEDGER_TERM));
} else if (request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && request.getLedgerEndIndex() < memberState.getLedgerEndIndex()) {
// 如果拉票節點的ledgerEndTerm等于當前節點的ledgerEndTerm,但是ledgerEndIndex小于當前節點的ledgerEndIndex,則直接拒絕拉票
// 原因同樣是發起投票節點的日志復制進度比當前節點低,這種情況是不能成為主節點的,否則會造成數據丟失。
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_SMALL_LEDGER_END_INDEX));
}
if (request.getTerm() < memberState.currTerm()) {
// 發起投票節點的投票輪次小于當前節點的投票輪次:投拒絕票,也就是說在Raft協議中,term越大,越有話語權。
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_VOTE_TERM));
} else if (request.getTerm() == memberState.currTerm()) {
// 發起投票節點的投票輪次等于當前節點的投票輪次:說明兩者都處在同一個投票輪次中,地位平等,接下來看該節點是否已經投過票。
if (memberState.currVoteFor() == null) {
// 當前還未投票
} else if (memberState.currVoteFor().equals(request.getLeaderId())) {
// 當前已經投過該節點了
} else {
if (memberState.getLeaderId() != null) {
// 如果該節點已存在Leader節點,則拒絕并告知已存在Leader節點
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_HAS_LEADER));
} else {
// 如果該節點還未有Leader節,如果發起投票節點的投票輪次小于ledgerEndTerm,則以同樣
//的理由拒絕點,但已經投了其他節點的票,則拒絕請求節點,并告知已投票。
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_VOTED));
}
}
} else {
// 發起投票節點的投票輪次大于當前節點的投票輪次:拒絕發起投票節點的投票請求,并告知對方自己還未準備投票,會使用發起投票節點的投票輪次立即進入Candidate狀態。
//stepped down by larger term
changeRoleToCandidate(request.getTerm());
needIncreaseTermImmediately = true;
//only can handleVote when the term is consistent
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_NOT_READY));
}
if (request.getTerm() < memberState.getLedgerEndTerm()) {
// 如果發起投票節點的投票輪次小于ledgerEndTerm,則拒絕
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.getLedgerEndTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_SMALL_THAN_LEDGER));
}
if (!self && isTakingLeadership() && request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && memberState.getLedgerEndIndex() >= request.getLedgerEndIndex()) {
// 如果發起投票節點的ledgerEndTerm等于當前節點的ledgerEndTerm,并且ledgerEndIndex大于等于發起投票節點的ledgerEndIndex,因為這意味著當前節點的日志雖然和發起投票節點在同一輪次,但是當前節點的日志比投票發起者的更新,所以拒絕拉票。
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TAKING_LEADERSHIP));
}
// 投票給請求節點
memberState.setCurrVoteFor(request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.ACCEPT));
}
第二步:根據發起投票節點、當前響應節點維護的投票輪次進行投票仲裁,投票仲裁有如下情況:
- 如果發起投票節點的 ledgerEndTerm 小于當前節點 ledgerEndTerm,說明發起投票節點的日志復制進度比當前節點低,這種情況是不能成為主節點的,否則會造成數據丟失。所以這種情況會投反對票。
- 如果發起投票節點和當前節點的 ledgerEndTerm 相等,但是發起投票節點的 ledgerEndIndex 小于當前節點 ledgerEndIndex,這同樣說明發起投票節點的日志復制進度比當前節點低,所以拒絕投票。
- 發起投票節點的投票輪次小于當前節點的投票輪次:投拒絕票,也就是說在Raft協議中,term越大,越有話語權。
- 起投票節點的投票輪次等于當前節點的投票輪次:說明兩者都處在同一個投票輪次中,地位平等,接下來看該節點是否已經投過票。如果該節點已經投過其他節點,則拒絕。
- 發起投票節點的投票輪次大于當前節點的投票輪次,則拒絕投票請求,并告知對方自己還未準備好投票,會使用發起投票節點的投票輪次立即進入Candidate狀態。
- 如果發起投票節點的投票輪次小于ledgerEndTerm,則拒絕。
- 如果發起投票節點的ledgerEndTerm等于當前節點的ledgerEndTerm,并且ledgerEndIndex大于等于發起投票節點的ledgerEndIndex,因為這意味著當前節點的日志雖然和發起投票節點在同一輪次,但是當前節點的日志比投票發起者的更新,所以拒絕拉票。
- 如果以上校驗都通過,則將自己的這一票投給這一個投票發起者。
3.5 發送心跳包與處理心跳包
經過幾輪投票,其中一個節點會被推舉出來成為Leader節點。Leader節點為了維持其領導地位,會定時向從節點發送心跳包,接下來我們重點看心跳包的發送與響應
3.5.1 sendHeartbeats
// io.openmessaging.storage.dledger.DLedgerLeaderElector#sendHeartbeats
/**
* 向集群內從節點發送心跳包
* @param term
* @param leaderId
* @throws Exception
*/
private void sendHeartbeats(long term, String leaderId) throws Exception {
// 集群內節點個數
final AtomicInteger allNum = new AtomicInteger(1);
// 收到成功響應的節點個數
final AtomicInteger succNum = new AtomicInteger(1);
// 收到對端沒有準備好反饋的節點數量
final AtomicInteger notReadyNum = new AtomicInteger(0);
// 當前集群中各個節點維護的最大的投票輪次
final AtomicLong maxTerm = new AtomicLong(-1);
// 是否存在leader節點不一致的情況
final AtomicBoolean inconsistLeader = new AtomicBoolean(false);
// 用于等待異步請求結果
final CountDownLatch beatLatch = new CountDownLatch(1);
介紹一下局部變量的含義:
- allNum:集群內節點個數
- succNum:收到成功響應的節點個數
- notReadyNum:收到對端沒有準備好反饋的節點數量
- maxTerm:當前集群中各個節點維護的最大的投票輪次
- inconsistLeader:是否存在leader節點不一致的情況
- beatLatch:用于等待異步請求結果
// io.openmessaging.storage.dledger.DLedgerLeaderElector#sendHeartbeats
for (String id : memberState.getPeerMap().keySet()) {
if (memberState.getSelfId().equals(id)) {
continue;
}
HeartBeatRequest heartBeatRequest = new HeartBeatRequest();
heartBeatRequest.setGroup(memberState.getGroup());
heartBeatRequest.setLocalId(memberState.getSelfId());
heartBeatRequest.setRemoteId(id);
heartBeatRequest.setLeaderId(leaderId);
heartBeatRequest.setTerm(term);
CompletableFuture<HeartBeatResponse> future = dLedgerRpcService.heartBeat(heartBeatRequest);
future.whenComplete((HeartBeatResponse x, Throwable ex) -> {
try {
if (ex != null) {
memberState.getPeersLiveTable().put(id, Boolean.FALSE);
throw ex;
}
// 當收到一個節點的響應結果后觸發回調函數,統計響應結果
switch (DLedgerResponseCode.valueOf(x.getCode())) {
case SUCCESS:
succNum.incrementAndGet();
break;
case EXPIRED_TERM:
// 節點的投票輪次,小于從節點的投票輪次
maxTerm.set(x.getTerm());
break;
case INCONSISTENT_LEADER:
// 從節點已經有了新的主節點
inconsistLeader.compareAndSet(false, true);
break;
case TERM_NOT_READY:
// 從節點未準備好
notReadyNum.incrementAndGet();
break;
default:
break;
}
// 根據錯誤碼,判斷節點是否存活
if (x.getCode() == DLedgerResponseCode.NETWORK_ERROR.getCode())
memberState.getPeersLiveTable().put(id, Boolean.FALSE);
else
memberState.getPeersLiveTable().put(id, Boolean.TRUE);
// 如果收到SUCCESS的從節點數量超過集群節點的半數,喚醒主線程,
if (memberState.isQuorum(succNum.get())
|| memberState.isQuorum(succNum.get() + notReadyNum.get())) {
beatLatch.countDown();
}
} catch (Throwable t) {
LOGGER.error("heartbeat response failed", t);
} finally {
allNum.incrementAndGet();
if (allNum.get() == memberState.peerSize()) {
// 如果收到所有從節點響應,喚醒主線程,
beatLatch.countDown();
}
}
});
}
- 遍歷集群中所有的節點,構建心跳數據包并異步向集群內的從節點發送心跳包,心跳包中主要包含Raft復制組名、當前節點ID、遠程節點ID、當前集群中的leaderId、當前節點維護的投票輪次。
- 當收到一個節點的響應結果后觸發回調函數,統計響應結果,先介紹一下對端節點的返回結果。
- SUCCESS:心跳包成功響應。
- EXPIRED_TERM:節點的投票輪次小于從節點的投票輪次。
- INCONSISTENT_LEADER:從節點已經有了新的主節點。
- TERM_NOT_READY:從節點未準備好。
- 根據錯誤碼,判斷節點是否存活。
如果收到SUCCESS的從節點數量超過集群節點的半數,或者收到集群內所有節點的響應結果后調用CountDownLatch的countDown()方法從而喚醒了主線程,則繼續執行后續流程。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#sendHeartbeats
if (maxTerm.get() > term) {
// 如果從節點的選舉周期大于當前節點,則立即將當前節點的狀態更改為Candidate
LOGGER.warn("[{}] currentTerm{} is not the biggest={}, deal with it", memberState.getSelfId(), term, maxTerm.get());
changeRoleToCandidate(maxTerm.get());
return;
}
if (memberState.isQuorum(succNum.get())) {
// 如果當前Leader節點收到超過集群半數節點的認可(SUCCESS),表示集群狀態正常,則正常按照心跳包間隔發送心跳包。
lastSuccHeartBeatTime = System.currentTimeMillis();
} else {
LOGGER.info("[{}] Parse heartbeat responses in cost={} term={} allNum={} succNum={} notReadyNum={} inconsistLeader={} maxTerm={} peerSize={} lastSuccHeartBeatTime={}",
memberState.getSelfId(), DLedgerUtils.elapsed(startHeartbeatTimeMs), term, allNum.get(), succNum.get(), notReadyNum.get(), inconsistLeader.get(), maxTerm.get(), memberState.peerSize(), new Timestamp(lastSuccHeartBeatTime));
if (memberState.isQuorum(succNum.get() + notReadyNum.get())) {
// 如果當前Leader節點收到SUCCESS的響應數加上未準備投票的節點數超過集群節點的半數,則立即發送心跳包。
lastSendHeartBeatTime = -1;
} else if (inconsistLeader.get()) {
// 如果leader變成了其他節點,則將當前節點狀態更改為Candidate。
changeRoleToCandidate(term);
} else if (DLedgerUtils.elapsed(lastSuccHeartBeatTime) > (long) maxHeartBeatLeak * heartBeatTimeIntervalMs) {
// 最近成功發送心跳的時間戳超過最大允許的間隔時間,則將當前節點狀態更改為Candidate。
changeRoleToCandidate(term);
}
}
心跳響應結果有下列情況:
- 如果從節點的選舉周期大于當前節點,則立即將當前節點的狀態更改為Candidate
- 如果當前Leader節點收到超過集群半數節點的認可(SUCCESS),表示集群狀態正常,則正常按照心跳包間隔發送心跳包。
- 如果當前Leader節點收到SUCCESS的響應數加上未準備投票的節點數超過集群節點的半數,則立即發送心跳包。
- 如果leader變成了其他節點,則將當前節點狀態更改為Candidate。
- 最近成功發送心跳的時間戳超過最大允許的間隔時間,則將當前節點狀態更改為Candidate。
3.5.2 handleHeartBeat
該方法是從節點在收到主節點的心跳包后的響應邏輯。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#handleHeartBeat
/**
* 該方法時從節點在收到主節點心跳包后的響應邏輯
* @param request
* @return
* @throws Exception
*/
public CompletableFuture<HeartBeatResponse> handleHeartBeat(HeartBeatRequest request) throws Exception {
if (!memberState.isPeerMember(request.getLeaderId())) {
LOGGER.warn("[BUG] [HandleHeartBeat] remoteId={} is an unknown member", request.getLeaderId());
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.UNKNOWN_MEMBER.getCode()));
}
if (memberState.getSelfId().equals(request.getLeaderId())) {
LOGGER.warn("[BUG] [HandleHeartBeat] selfId={} but remoteId={}", memberState.getSelfId(), request.getLeaderId());
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.UNEXPECTED_MEMBER.getCode()));
}
這一部分代碼做了一些基礎的校驗,校驗收到的這個請求是否是當前集群中的節點。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#handleHeartBeat
if (request.getTerm() < memberState.currTerm()) {
// 如果Leader節點發出的心跳的任期小于當前節點的任期,則返回EXPIRED_TERM,這樣主節點會立即變成Candidate狀態
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode()));
} else if (request.getTerm() == memberState.currTerm()) {
if (request.getLeaderId().equals(memberState.getLeaderId())) {
// 如果Leader發出的心跳任期和自己的任期相同,則更新lastLeaderHeartBeatTime,表示收到心跳包,并更新lastLeaderHeartBeatTime
lastLeaderHeartBeatTime = System.currentTimeMillis();
return CompletableFuture.completedFuture(new HeartBeatResponse());
}
}
第一步:如果發送心跳包的節點(Leader節點)的投票輪次小于從節點的投票輪次,返回EXPIRED_TERM,告知對方它的投票輪次已經過期,需要重新進入選舉。如果Leader節點的投票輪次與當前從節點的投票輪次相同,并且發送心跳包的節點(Leader節點)是當前從節點的主節點,則返回成功。這一步中的校驗并沒有加鎖,目的是為了提高并發性能。
// io.openmessaging.storage.dledger.DLedgerLeaderElector#handleHeartBeat
//abnormal case
//hold the lock to get the latest term and leaderId
synchronized (memberState) {
if (request.getTerm() < memberState.currTerm()) {
// 再一次判斷一次,防止在第一次判斷后,節點狀態發生了變化
// 如果Leader節點發出的心跳的任期小于當前節點的任期,則返回EXPIRED_TERM,這樣主節點會立即變成Candidate狀態
return CompletableFuture.completedFuture(new HeartBeatResponse().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode()));
} else if (request.getTerm() == memberState.currTerm()) {
if (memberState.getLeaderId() == null) {
// 當前節點還不知道誰是Leader時,收到心跳包,則將leader節點設置為該心跳發送的節點
changeRoleToFollower(request.getTerm(), request.getLeaderId());
return CompletableFuture.completedFuture(new HeartBeatResponse());
} else if (request.getLeaderId().equals(memberState.getLeaderId())) {
// 如果Leader發出的心跳任期和自己的任期相同,則更新lastLeaderHeartBeatTime,表示收到心跳包,并更新lastLeaderHeartBeatTime
lastLeaderHeartBeatTime = System.currentTimeMillis();
return CompletableFuture.completedFuture(new HeartBeatResponse());
} else {
// 心跳發送的LeaderId和當前節點LeaderId并不一致,則返回INCONSISTENT_LEADER,這樣主節點會立即變成Candidate狀態
//this should not happen, but if happened
LOGGER.error("[{}][BUG] currTerm {} has leader {}, but received leader {}", memberState.getSelfId(), memberState.currTerm(), memberState.getLeaderId(), request.getLeaderId());
return CompletableFuture.completedFuture(new HeartBeatResponse().code(DLedgerResponseCode.INCONSISTENT_LEADER.getCode()));
}
} else {
// 如果心跳中的任期大于當前節點的任期,則將自己的狀態更改為Candidate,并進入新的任期選舉狀態,
// 并返回TERM_NOT_READY,這樣主節點可能會立即再發一次心跳
changeRoleToCandidate(request.getTerm());
needIncreaseTermImmediately = true;
//TOOD notify
return CompletableFuture.completedFuture(new HeartBeatResponse().code(DLedgerResponseCode.TERM_NOT_READY.getCode()));
}
}
第二步:通常情況下第一步將直接返回,本步驟主要用于處理異常情況,需要加鎖以確保線程安全,核心處理邏輯如下:
- 如果發送心跳包的節點(Leader節點)的投票輪次小于當前從節點的投票輪次,返回EXPIRED_TERM,告知對方它的投票輪次已經過期,需要重新進入選舉,對端節點將會立即變為Candidate狀態。
- 如果發送心跳包的節點的投票輪次等于當前從節點的投票輪次,需要根據當前從節點維護的leaderId來繼續判斷下列情況:
- 當前節點還不知道誰是Leader時,收到心跳包,則將leader節點設置為該心跳發送的節點
- 如果Leader發出的心跳任期和自己的任期相同,則更新lastLeaderHeartBeatTime,表示收到心跳包,并更新lastLeaderHeartBeatTime。
- 如果當前從節點的維護的主節點ID與發送心跳包的節點ID不同, 說明集群中存在另外一個Leader節點,則返回INCONSISTENT_LEADER,對端節點將進入Candidate狀態
- 如果心跳中的任期大于當前節點的任期,則將自己的狀態更改為Candidate,并進入新的任期選舉狀態,并返回TERM_NOT_READY,這樣主節點可能會立即再發一次心跳。
3.6 整體流程
至此,我們從源碼的角度分析了DLedger是如何實現Raft選主功能的,以及如何在一個節點發生宕機后進行主從切換。
四. 總結
本文深入剖析了DLedger,一個基于Raft協議實現的Java類庫,它在RocketMQ 4.5版本中被引入,用以解決分布式系統中的高可用性和數據一致性問題。DLedger的核心功能之一是Leader選舉,該過程確保了在任何節點故障的情況下,系統能夠自動且迅速地選出新的Leader節點,以維持服務的連續性和穩定性。
DLedger的Leader選舉機制遵循Raft協議,包含以下幾個關鍵步驟:
- 初始化與狀態轉換:每個節點初始狀態為Follower。在一定時間后,如果未收到Leader的心跳,Follower將轉換為Candidate狀態,并發起投票。
- 隨機計時器:為避免同時發起選舉,每個節點的選舉超時時間是隨機的。
- 投票過程:Candidate節點向集群中的其他節點發送投票請求,并根據收到的響應來確定是否贏得選舉。
- 日志復制:一旦Candidate贏得選舉,成為Leader,它將負責處理所有寫請求,并將日志條目復制到所有從節點。
- 心跳機制:Leader定期向所有Follower發送心跳包,以維持其領導地位,并確保Follower不會轉換為Candidate。
- 角色變更處理:在選舉過程中,節點可能需要從Follower轉換為Candidate,或從Candidate轉換為Leader,DLedger通過內部狀態機管理這些轉換。
本文參考至:《RocketMQ技術內幕 第二版》

 浙公網安備 33010602011771號
浙公網安備 33010602011771號