深入理解Docker原理
本文參考轉載至:《深入剖析Kubernetes - 張磊》
更過優秀博文請關注:https://blog.bigcoder.cn
容器技術的核心功能,就是通過約束和修改進程的動態表現,從而為其創造出一個“邊界”。對于 Docker 等大多數 Linux 容器來說,Cgroups 技術是用來制造約束的主要手段,而Namespace 技術則是用來修改進程視圖的主要方法。你可能會覺得 Cgroups 和 Namespace 這兩個概念很抽象,別擔心,接下來我們一起動手實踐一下,你就很容易理解這兩項技術了。
一. Namespace
假設你已經有了一個 Linux 操作系統上的 Docker 項目在運行,比如我的環境是 Ubuntu 16.04和 Docker CE 18.05。
接下來,讓我們首先創建一個容器來試試。
$ docker run -it busybox /bin/sh
/ #
這個命令是 Docker 項目最重要的一個操作,即大名鼎鼎的 docker run。而 -it 參數告訴了 Docker 項目在啟動容器后,需要給我們分配一個文本輸入 / 輸出環境,也就是 TTY,跟容器的標準輸入相關聯,這樣我們就可以和這個 Docker 容器進行交互了。而/bin/sh 就是我們要在 Docker 容器里運行的程序。
所以,上面這條指令用大白話來將就是:請幫我啟動一個容器,在容器里執行 /bin/sh,并且給我分配一個命令行終端跟這個容器交互。這樣,我的 Ubuntu 16.04 機器就變成了一個宿主機,而一個運行著 /bin/sh 的容器,就跑在了這個宿主機里面。
上面的例子和原理,如果你已經玩過 Docker,一定不會感到陌生。此時,如果我們在容器里執行一下 ps 指令,就會發現一些更有趣的事情:
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
7 root 0:00 ps
可以看到,我們在 Docker 里最開始執行的 /bin/sh,就是這個容器內部的第 1 號進程(PID=1),而這個容器里一共只有兩個進程在運行。這就意味著,前面執行的 /bin/sh,以及我們剛剛執行的 ps,已經被 Docker 隔離在了一個跟宿主機完全不同的世界當中。這究竟是怎么做到呢?
本來,每當我們在宿主機上運行了一個 /bin/sh 程序,操作系統都會給它分配一個進程編號,比如 PID=100。這個編號是進程的唯一標識,就像員工的工牌一樣。所以 PID=100,可以粗略地理解為這個 /bin/sh 是我們公司里的第 100 號員工,而第 1 號員工就自然是比爾 · 蓋茨這樣統領全局的人物。
而現在,我們要通過 Docker 把這個 /bin/sh 程序運行在一個容器當中。這時候,Docker 就會在這個第 100 號員工入職時給他施一個“障眼法”,讓他永遠看不到前面的其他 99 個員工,更看不到比爾 · 蓋茨。這樣,他就會錯誤地以為自己就是公司里的第 1 號員工。
這種機制,其實就是對被隔離應用的進程空間做了手腳,使得這些進程只能看到重新計算過的進程編號,比如 PID=1。可實際上,他們在宿主機的操作系統里,還是原來的第 100 號進程。
這種技術,就是 Linux 里面的 Namespace 機制。而 Namespace 的使用方式也非常有意思:它其實只是 Linux 創建新進程的一個可選參數。我們知道,在 Linux 系統中創建線程的系統調用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
這個系統調用就會為我們創建一個新的進程,并且返回它的進程號 pid。而當我們用 clone() 系統調用創建一個新進程時,就可以在參數中指定 CLONE_NEWPID 參數,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
這時,新創建的這個進程將會“看到”一個全新的進程空間,在這個進程空間里,它的 PID 是1。之所以說“看到”,是因為這只是一個“障眼法”,在宿主機真實的進程空間里,這個進程的 PID 還是真實的數值,比如 100。
當然,我們還可以多次執行上面的 clone() 調用,這樣就會創建多個 PID Namespace,而每個Namespace 里的應用進程,都會認為自己是當前容器里的第 1 號進程,它們既看不到宿主機里真正的進程空間,也看不到其他 PID Namespace 里的具體情況。
而除了我們剛剛用到的 PID Namespace,Linux 操作系統還提供了 Mount、UTS、IPC、Network 和 User 這些 Namespace,用來對各種不同的進程上下文進行“障眼法”操作。
比如,Mount Namespace,用于讓被隔離進程只看到當前 Namespace 里的掛載點信息;Network Namespace,用于讓被隔離進程看到當前 Namespace 里的網絡設備和配置。這,就是 Linux 容器最基本的實現原理了。
經常有人將Docker容器技術成為虛擬化技術,實際上這種說法是不嚴謹的,
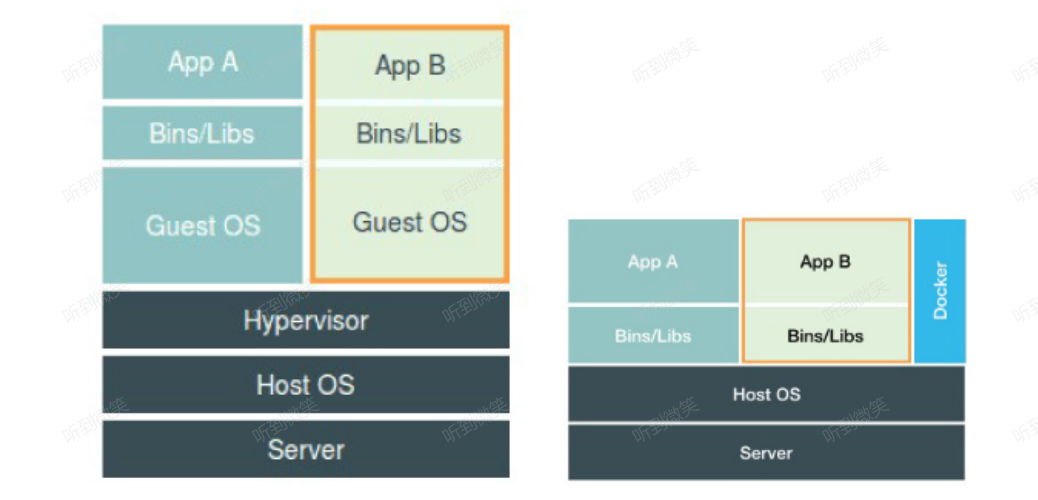
上圖是虛擬化技術與容器技術的對比圖,在這個對比圖里,我們應該把 Docker 畫在跟應用同級別并且靠邊的位置。這意味著,用戶運行在容器里的應用進程,跟宿主機上的其他進程一樣,都由宿主機操作系統統一管理,只不過這些被隔離的進程擁有額外設置過的 Namespace 參數。而 Docker 項目在這里扮演的角色,更多的是旁路式的輔助和管理工作。
這是因為,使用虛擬化技術作為應用沙盒,就必須要由 Hypervisor 來負責創建虛擬機,這個虛擬機是真實存在的,并且它里面必須運行一個完整的 Guest OS 才能執行用戶的應用進程。這就不可避免地帶來了額外的資源消耗和占用。根據實驗,一個運行著 CentOS 的 KVM 虛擬機啟動后,在不做優化的情況下,虛擬機自己就需要占用 100~200 MB 內存。此外,用戶應用運行在虛擬機里面,它對宿主機操作系統的調用就不可避免地要經過虛擬化軟件的攔截和處理,這本身又是一層性能損耗,尤其對計算資源、網絡和磁盤 I/O 的損耗非常大。
而相比之下,容器化后的用戶應用,卻依然還是一個宿主機上的普通進程,這就意味著這些因為虛擬化而帶來的性能損耗都是不存在的;而另一方面,使用 Namespace 作為隔離手段的容器并不需要單獨的 Guest OS,這就使得容器額外的資源占用幾乎可以忽略不計。
不過,有利就有弊,基于 Linux Namespace 的隔離機制相比于虛擬化技術也有很多不足之處,其中最主要的問題就是:隔離得不徹底。首先,既然容器只是運行在宿主機上的一種特殊的進程,那么多個容器之間使用的就還是同一個宿主機的操作系統內核。盡管你可以在容器里通過 Mount Namespace 單獨掛載其他不同版本的操作系統文件,比如CentOS 或者 Ubuntu,但這并不能改變共享宿主機內核的事實。這意味著,如果你要在Windows 宿主機上運行 Linux 容器,或者在低版本的 Linux 宿主機上運行高版本的 Linux 容器,都是行不通的。
而相比之下,擁有硬件虛擬化技術和獨立 Guest OS 的虛擬機就要方便得多了。最極端的例子是,Microsoft 的云計算平臺 Azure,實際上就是運行在 Windows 服務器集群上的,但這并不妨礙你在它上面創建各種 Linux 虛擬機出來。
其次,在 Linux 內核中,有很多資源和對象是不能被 Namespace 化的,最典型的例子就是:時間。這就意味著,如果你的容器中的程序使用 settimeofday(2) 系統調用修改了時間,整個宿主機的時間都會被隨之修改,這顯然不符合用戶的預期。相比于在虛擬機里面可以隨便折騰的自由度,在容器里部署應用的時候,“什么能做,什么不能做”,就是用戶必須考慮的一個問題。
此外,由于上述問題,尤其是共享宿主機內核的事實,容器給應用暴露出來的攻擊面是相當大的,應用“越獄”的難度自然也比虛擬機低得多。所以,在生產環境中,沒有人敢把運行在物理機上的 Linux 容器直接暴露到公網上。
二. Cgroups
Linux Cgroups 的全稱是 Linux Control Group。它最主要的作用,就是限制一個進程組能夠使用的資源上限,包括 CPU、內存、磁盤、網絡帶寬等等。
在 Linux 中,Cgroups 給用戶暴露出來的操作接口是文件系統,即它以文件和目錄的方式組織在操作系統的 /sys/fs/cgroup 路徑下。在 Ubuntu 16.04 機器里,我可以用 mount 指令把它們展示出來,這條命令是:
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_cls,net_prio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpu,cpuacct)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,rdma)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
可以看到,在 /sys/fs/cgroup 下面有很多諸如 cpuset、cpu、 memory 這樣的子目錄,也叫子系統。這些都是我這臺機器當前可以被 Cgroups 進行限制的資源種類。而在子系統對應的資源種類下,你就可以看到該類資源具體可以被限制的方法。比如,對 CPU 子系統來說,我們就可以看到如下幾個配置文件,這個指令是:
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpuacct.usage cpuacct.usage_percpu_user cpu.cfs_quota_us cpu.stat release_agent
cgroup.procs cpuacct.usage_all cpuacct.usage_sys cpu.rt_period_us docker system.slice
cgroup.sane_behavior cpuacct.usage_percpu cpuacct.usage_user cpu.rt_runtime_us init.scope tasks
cpuacct.stat cpuacct.usage_percpu_sys cpu.cfs_period_us cpu.shares notify_on_release user.slice
如果熟悉 Linux CPU 管理的話,你就會在它的輸出里注意到 cfs_period 和 cfs_quota 這樣的關鍵詞。這兩個參數需要組合使用,可以用來限制進程在長度為 cfs_period 的一段時間內,只能被分配到總量為 cfs_quota 的 CPU 時間。
而這樣的配置文件又如何使用呢?
你需要在對應的子系統下面創建一個目錄,比如,我們現在進入 /sys/fs/cgroup/cpu 目錄下:
$ cd /sys/fs/cgroup/cpu
$ mkdir container
$ ls container/
cgroup.clone_children cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user cpu.rt_period_us cpu.stat
cgroup.procs cpuacct.usage_all cpuacct.usage_percpu_user cpu.cfs_period_us cpu.rt_runtime_us notify_on_release
cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys cpu.cfs_quota_us cpu.shares tasks
這個目錄就稱為一個“控制組”。你會發現,操作系統會在你新創建的 container 目錄下,自動生成該子系統對應的資源限制文件。
現在,我們在后臺執行這樣一條腳本:
$ while : ; do : ; done &
[1] 1176365
顯然,它執行了一個死循環,可以把計算機的 CPU 吃到 100%,根據它的輸出,我們可以看到這個腳本在后臺運行的進程號(PID)是 226。這樣,我們可以用 top 指令來確認一下 CPU 有沒有被打滿:
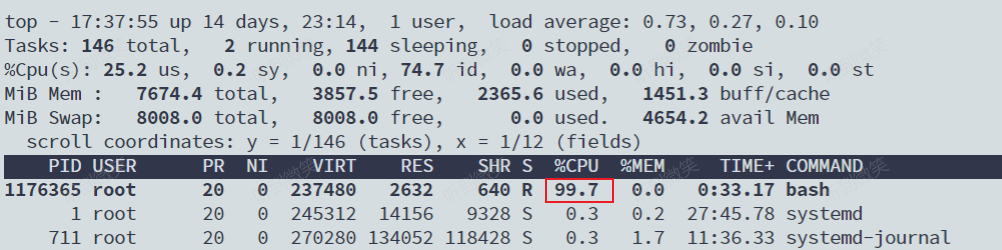
而此時,我們可以通過查看 container 目錄下的文件,看到 container 控制組里的 CPU quota還沒有任何限制(即:-1),CPU period 則是默認的 100 ms(100000 us):
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
接下來,我們可以通過修改這些文件的內容來設置限制。比如,向 container 組里的 cfs_quota 文件寫入 20 ms(20000 us):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
結合前面的介紹,你應該能明白這個操作的含義,它意味著在每 100 ms 的時間里,被該控制組限制的進程只能使用 20 ms 的 CPU 時間,也就是說這個進程只能使用到 20% 的 CPU 帶寬。
接下來,我們把被限制的進程的 PID 寫入 container 組里的 tasks 文件,上面的設置就會對該進程生效了:
$ echo 1176365 > /sys/fs/cgroup/cpu/container/tasks
我們可以用 top 指令查看一下:
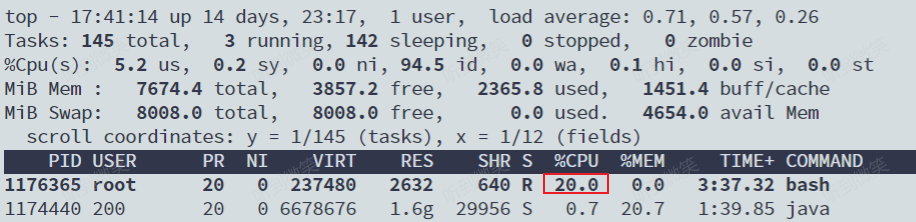
可以看到,計算機的 CPU 使用率立刻降到了 20%(%Cpu0 : 20.3 us)。
除 CPU 子系統外,Cgroups 的每一項子系統都有其獨有的資源限制能力,比如:
- blkio,為塊設備設定I/O 限制,一般用于磁盤等設備;
- cpuset,為進程分配單獨的 CPU 核和對應的內存節點;
- memory,為進程設定內存使用的限制。
Linux Cgroups 的設計還是比較易用的,簡單粗暴地理解呢,它就是一個子系統目錄加上一組資源限制文件的組合。而對于 Docker 等 Linux 容器項目來說,它們只需要在每個子系統下面,為每個容器創建一個控制組(即創建一個新目錄),然后在啟動容器進程之后,把這個進程的 PID 填寫到對應控制組的 tasks 文件中就可以了。
而至于在這些控制組下面的資源文件里填上什么值,就靠用戶執行 docker run 時的參數指定了,比如這樣一條命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在啟動這個容器后,我們可以通過查看 Cgroups 文件系統下,CPU 子系統中,“docker”這個控制組里的資源限制文件的內容來確認:
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
這就意味著這個 Docker 容器,只能使用到 20% 的 CPU 帶寬
跟 Namespace 的情況類似,Cgroups 對資源的限制能力也有很多不完善的地方,被提及最多的自然是 /proc 文件系統的問題。
眾所周知,Linux 下的 /proc 目錄存儲的是記錄當前內核運行狀態的一系列特殊文件,用戶可以通過訪問這些文件,查看系統以及當前正在運行的進程的信息,比如 CPU 使用情況、內存占用率等,這些文件也是 top 指令查看系統信息的主要數據來源。
但是,你如果在容器里執行 top 指令,就會發現,它顯示的信息居然是宿主機的 CPU 和內存數據,而不是當前容器的數據。造成這個問題的原因就是,/proc 文件系統并不知道用戶通過 Cgroups 給這個容器做了什么樣的資源限制,即:/proc 文件系統不了解 Cgroups 限制的存在。
在生產環境中,這個問題必須進行修正,否則應用程序在容器里讀取到的 CPU 核數、可用內存等信息都是宿主機上的數據,這會給應用的運行帶來非常大的困惑和風險。這也是在企業中,容器化應用碰到的一個常見問題,也是容器相較于虛擬機另一個不盡如人意的地方。
三. 容器鏡像
Linux 容器最基礎的兩種技術:Namespace 和 Cgroups。希望此時,你已經徹底理解了“容器的本質是一種特殊的進程”這個最重要的概念。而正如我前面所說的,Namespace 的作用是“隔離”,它讓應用進程只能看到該 Namespace內的“世界”;而 Cgroups 的作用是“限制”,它給這個“世界”圍上了一圈看不見的墻。這么一折騰,進程就真的被“裝”在了一個與世隔絕的房間里,而這些房間就是 PaaS 項目賴以生存的應用“沙盒”。
可是,還有一個問題不知道你有沒有仔細思考過:這個房間四周雖然有了墻,但是如果容器進程低頭一看地面,又是怎樣一副景象呢?換句話說,容器里的進程看到的文件系統又是什么樣子的呢?
可能你立刻就能想到,這一定是一個關于 Mount Namespace 的問題:容器里的應用進程,理應看到一份完全獨立的文件系統。這樣,它就可以在自己的容器目錄(比如 /tmp)下進行操作,而完全不會受宿主機以及其他容器的影響。
下面,我們不妨使用它來驗證一下剛剛提到的問題。
#define _GNU_SOURCE
#include <sys/mount.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] =
{
"/bin/bash", NULL
};
int container_main(void* arg)
{
printf("Container - inside the container!\n");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent - start a container!\n");
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWNS | SIGCHLD, NULL);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
這段代碼的功能非常簡單:在 main 函數里,我們通過 clone() 系統調用創建了一個新的子進程container_main,并且聲明要為它啟用 Mount Namespace(即:CLONE_NEWNS 標志)。
而這個子進程執行的,是一個“/bin/bash”程序,也就是一個 shell。所以這個 shell 就運行在了 Mount Namespace 的隔離環境中。
我們來一起編譯一下這個程序:
$ gcc -o ns ns.c
$ ./ns
Parent - start a container!
Container - inside the container!
這樣,我們就進入了這個“容器”當中。可是,如果在“容器”里執行一下 ls 指令的話,我們就會發現一個有趣的現象: /tmp 目錄下的內容跟宿主機的內容是一樣的。也就是說:即使開啟了 Mount Namespace,容器進程看到的文件系統也跟宿主機完全一樣。
ls /tmp
# 你會看到宿主機的很多文件
這是怎么回事呢?
仔細思考一下,你會發現這其實并不難理解:Mount Namespace 修改的,是容器進程對文件系統“掛載點”的認知。但是,這也就意味著,只有在“掛載”這個操作發生之后,進程的視圖才會被改變。而在此之前,新創建的容器會直接繼承宿主機的各個掛載點。
這時,你可能已經想到了一個解決辦法:創建新進程時,除了聲明要啟用 Mount Namespace之外,我們還可以告訴容器進程,有哪些目錄需要重新掛載,就比如這個 /tmp 目錄。于是,我們在容器進程執行前可以添加一步重新掛載 /tmp 目錄的操作:
int container_main(void* arg)
{
printf("Container - inside the container!\n");
mount("none", "/tmp", "tmpfs", 0, "");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
可以看到,在修改后的代碼里,我在容器進程啟動之前,加上了一句mount(“none”,“/tmp”, “tmpfs”, 0, “”) 語句。就這樣,我告訴了容器以 tmpfs(內存盤)格式,重新掛載了/tmp 目錄。
這段修改后的代碼,編譯執行后的結果又如何呢?我們可以試驗一下:
$ gcc -o ns ns.c
$ ./ns
Parent - start a container!
Container - inside the container!
$ ls /tmp
#這一次/tmp目錄下為空
可以看到,這次 /tmp 變成了一個空目錄,這意味著重新掛載生效了。我們可以用 mount -l 檢、查一下:
$ mount -l | grep tmpfs

可以看到,容器里的 /tmp 目錄是以 tmpfs 方式單獨掛載的。
更重要的是,因為我們創建的新進程啟用了 Mount Namespace,所以這次重新掛載的操作,只在容器進程的 Mount Namespace 中有效。如果在宿主機上用 mount -l 來檢查一下這個掛載,你會發現它是不存在的:
# 在宿主機上
$ mount -l | grep tmpfs
這就是 Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它對容器進程視圖的改變,一定是伴隨著掛載操作(mount)才能生效。
可是,作為一個普通用戶,我們希望的是一個更友好的情況:每當創建一個新容器時,我希望容器進程看到的文件系統就是一個獨立的隔離環境,而不是繼承自宿主機的文件系統。怎么才能做到這一點呢?
不難想到,我們可以在容器進程啟動之前重新掛載它的整個根目錄“/”。而由于 Mount Namespace 的存在,這個掛載對宿主機不可見,所以容器進程就可以在里面隨便折騰了。
在 Linux 操作系統里,有一個名為 chroot 的命令可以幫助你在 shell 中方便地完成這個工作。顧名思義,它的作用就是幫你“change root file system”,即改變進程的根目錄到你指定的位置。它的用法也非常簡單。
假設,我們現在有一個 $HOME/test 目錄,想要把它作為一個 /bin/bash 進程的根目錄。
首先,創建一個 test 目錄和幾個 lib 文件夾:
$ mkdir -p $HOME/test
$ mkdir -p $HOME/test/{bin,lib64,lib}
$ cd $T
然后,把 bash 命令拷貝到 test 目錄對應的 bin 路徑下:
$ cp -v /bin/{bash,ls} $HOME/test/bin
接下來,把 bash 命令需要的所有 so 文件,也拷貝到 test 目錄對應的 lib 路徑下。找到 so 文件可以用 ldd 命令:
$ T=$HOME/test
$ list="$(ldd /bin/ls | egrep -o '/lib.*\.[0-9]')"
$ for i in $list; do cp -v "$i" "${T}${i}"; done
最后,執行 chroot 命令,告訴操作系統,我們將使用 $HOME/test 目錄作為 /bin/bash 進程的根目錄:
$ chroot $HOME/test /bin/bash
這時,你如果執行 “ls /”,就會看到,它返回的都是 $HOME/test 目錄下面的內容,而不是宿主機的內容。
更重要的是,對于被 chroot 的進程來說,它并不會感受到自己的根目錄已經被“修改”成$HOME/test 了。
這種視圖被修改的原理,是不是跟我之前介紹的 Linux Namespace 很類似呢?
為了能夠讓容器的這個根目錄看起來更“真實”,我們一般會在這個容器的根目錄下掛載一個完整操作系統的文件系統,比如 Ubuntu16.04 的 ISO。這樣,在容器啟動之后,我們在容器里通過執行 “ls /” 查看根目錄下的內容,就是 Ubuntu 16.04 的所有目錄和文件。而這個掛載在容器根目錄上、用來為容器進程提供隔離后執行環境的文件系統,就是所謂的“容器鏡像”。它還有一個更為專業的名字,叫作:rootfs(根文件系統)。
所以,一個最常見的 rootfs,或者說容器鏡像,會包括如下所示的一些目錄和文件,比如/bin,/etc,/proc 等等:
$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
而你進入容器之后執行的 /bin/bash,就是 /bin 目錄下的可執行文件,與宿主機的 /bin/bash完全不同。
現在,你應該可以理解,對 Docker 項目來說,它最核心的原理實際上就是為待創建的用戶進程:
- 啟用 Linux Namespace 配置;
- 設置指定的 Cgroups 參數;
- 切換進程的根目錄(Change Root)。
這樣,一個完整的容器就誕生了。不過,Docker 項目在最后一步的切換上會優先使用pivot_root 系統調用,如果系統不支持,才會使用 chroot。這兩個系統調用雖然功能類似,但是也有細微的區別,這一部分小知識就交給你課后去探索了
另外,需要明確的是,rootfs 只是一個操作系統所包含的文件、配置和目錄,并不包括操作系統內核。在 Linux 操作系統中,這兩部分是分開存放的,操作系統只有在開機啟動時才會加載指定版本的內核鏡像。所以說,rootfs 只包括了操作系統的“軀殼”,并沒有包括操作系統的“靈魂”。同一臺機器上的所有容器,都共享宿主機操作系統的內核。
這就意味著,如果你的應用程序需要配置內核參數、加載額外的內核模塊,以及跟內核進行直接的交互,你就需要注意了:這些操作和依賴的對象,都是宿主機操作系統的內核,它對于該機器上的所有容器來說是一個“全局變量”,牽一發而動全身。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號