數據湖&湖倉一體簡介
1 簡介
術語
數據庫
數據庫是“按照數據結構來組織、存儲和管理數據的倉庫”。
廣義上的數據庫,在20世紀60年代已經在計算機中應用了。但這個階段的數據庫結構主要是層次或網狀的,且數據和程序之間具備非常強的依賴性,應用較為有限。
現在通常所說的數據庫指的是關系型數據庫。關系數據庫是指采用了關系模型來組織數據的數據庫,其以行和列的形式存儲數據,具有結構化程度高,獨立性強,冗余度低等優點。1970年關系型數據庫的誕生,真正徹底把軟件中的數據和程序分開來,成為主流計算機系統不可或缺的組成部分。關系型數據庫已經成為目前數據庫產品中最重要的一員,幾乎所有的數據庫廠商新出的數據庫產品都支持關系型數據庫,即使一些非關系數據庫產品也幾乎都有支持關系數據庫的接口。
關系型數據庫的主要用于聯機事務處理OLTP(On-Line Transaction Processing)主要進行基本的、日常的事務處理,例如銀行交易等場景。
數據倉庫
隨著數據庫的大規模應用,使信息行業的數據爆炸式的增長。為了研究數據之間的關系,挖掘數據隱藏的價值,人們越來越多的需要使用聯機分析處理OLAP(On-Line Analytical Processing)進行數據分析,探究一些深層次的關系和信息。但是不同的數據庫之間很難做到數據共享,數據之間的集成與分析也存在非常大的挑戰。
為解決企業的數據集成與分析問題,數據倉庫之父比爾·恩門于1990年提出數據倉庫(Data Warehouse)。數據倉庫主要功能是將OLTP經年累月所累積的大量數據,通過數據倉庫特有的數據儲存架構進行OLAP,最終幫助決策者能快速有效地從大量數據中,分析出有價值的信息,提供決策支持。自從數據倉庫出現之后,信息產業就開始從以關系型數據庫為基礎的運營式系統慢慢向決策支持系統發展。
數據倉庫VS數據庫
數據倉庫相比數據庫,主要有以下兩個特點:
-
數據倉庫是面向主題集成的。數據倉庫是為了支撐各種業務而建立的,數據來自于分散的操作型數據。因此需要將所需數據從多個異構的數據源中抽取出來,進行加工與集成,按照主題進行重組,最終進入數據倉庫。
-
數據倉庫主要用于支撐企業決策分析,所涉及的數據操作主要是數據查詢。因此數據倉庫通過表結構優化、存儲方式優化等方式提高查詢速度、降低開銷。
| 維度 | 數據倉庫 | 數據庫 |
|---|---|---|
| 應用場景 | OLAP | OLTP |
| 數據來源 | 多數據源 | 單數據源 |
| 數據標準化 | 非標準化Schema | 高度標準化的靜態Schema |
| 數據讀取優勢 | 針對讀操作進行優化 | 針對寫操作進行優化 |
數據湖
在企業內部,數據是一類重要資產已經成為了共識。隨著企業的持續發展,數據不斷堆積,企業希望把生產經營中的所有相關數據都完整保存下來,進行有效管理與集中治理,挖掘和探索數據價值。
數據湖就是在這種背景下產生的。數據湖是一個集中存儲各類結構化和非結構化數據的大型數據倉庫,它可以存儲來自多個數據源、多種數據類型的原始數據,數據無需經過結構化處理,就可以進行存取、處理、分析和傳輸。數據湖能幫助企業快速完成異構數據源的聯邦分析、挖掘和探索數據價值。
數據湖的本質,是由“數據存儲架構+數據處理工具”組成的解決方案。
-
數據存儲架構:要有足夠的擴展性和可靠性,可以存儲海量的任意類型的數據,包括結構化、半結構化和非結構化數據。
-
數據處理工具,則分為兩大類:
-
第一類工具,聚焦如何把數據“搬到”湖里。包括定義數據源、制定數據同步策略、移動數據、編制數據目錄等。
-
第二類工具,關注如何對湖中的數據進行分析、挖掘、利用。數據湖需要具備完善的數據管理能力、多樣化的數據分析能力、全面的數據生命周期管理能力、安全的數據獲取和數據發布能力。如果沒有這些數據治理工具,元數據缺失,湖里的數據質量就沒法保障,最終會由數據湖變質為數據沼澤。
-
隨著大數據和AI的發展,數據湖中數據的價值逐漸水漲船高,價值被重新定義。數據湖能給企業帶來多種能力,例如實現數據的集中式管理,幫助企業構建更多優化后的運營模型,也能為企業提供其他能力,如預測分析、推薦模型等,這些模型能刺激企業能力的后續增長。
數據倉庫與數據湖
數據湖和 數據倉庫 之所以相似,是因為它們都存儲和處理數據,但每個都具有自己的專長,因此都有自己的用例。正因如此,企業級組織通常會在其分析生態系統中納入數據湖和數據倉庫。這兩個存儲庫協同工作,形成一個安全的端到端系統,用于存儲、處理數據并更快獲得見解。
數據湖從各種源(業務應用程序、移動應用、IoT 設備、社交媒體或流媒體)中捕獲關系型數據和非關系型數據,在讀取數據前無需定義數據的結構或架構。讀取時的架構可確保任何類型的數據都可以以原始格式存儲。因此,數據湖可以容納任何規模的各種數據類型,從結構化數據到半結構化數據,再到非結構化數據均可容納。其靈活和可縮放的性質使得它們對于使用不同類型的計算處理工具(如 Apache Spark 或 Azure 機器學習)執行復雜形式的數據分析至關重要。
相比之下,數據倉庫在本質上是關系型倉庫。結構或架構會根據業務和產品要求進行建模或預定義,而這些要求又針對 SQL 查詢操作進行精選、合規和優化。數據庫可容納所有結構類型的數據(包括原始和未處理的數據),而數據倉庫則存儲根據特定目的處理和轉換的數據,這些數據可用于支持分析或操作報告。這使得數據倉庫非常適合于生成更標準化的 BI 分析,或為已定義的業務用例提供服務。
| 數據湖 | 數據倉庫 | |
|---|---|---|
| 類型 | 結構化、半結構化、非結構化 | 結構化 |
| 關系型、非關系型 | 關系型 | |
| 架構 | 讀取時的架構 | 寫入時的架構 |
| 格式 | 原始、未篩選 | 已處理、已審核 |
| 源 | 大數據、IoT、社交媒體、流數據 | 應用程序、業務、事務數據、批處理報告 |
| 可伸縮性 | 輕松縮放,成本低 | 完成縮放很困難且成本高昂 |
| 用戶 | 數據科學家、數據工程師 | 數據倉庫專業人員、業務分析師 |
| 用例 | 機器學習、預測分析、實時分析 | 核心報告、BI |
湖倉一體/LakeHouse/數據湖屋
傳統的數據湖盡管有許多優點,但并非沒有缺點。由于數據湖可以容納來自各種源的所有類型的數據,因此可能會出現與質量控制、數據損壞和分區不當相關的問題。管理不佳的數據湖不僅會影響數據完整性,而且還可能導致瓶頸、性能緩慢和安全風險。這就是數據湖屋發揮作用的地方。
湖倉一體,又被稱為Lake House,其出發點是通過數據倉庫和數據湖的打通和融合,讓數據流動起來,減少重復建設。Lake House架構最重要的一點,是實現數據倉庫和數據湖的數據/元數據無縫打通和自由流動。湖里的“顯性價值”數據可以流到倉里,甚至可以直接被數倉使用;而倉里的“隱性價值”數據,也可以流到湖里,低成本長久保存,供未來的數據挖掘使用。
數據湖屋通過直接在云數據湖上添加 增量湖存儲層增量湖存儲層 來應對傳統數據湖的挑戰。該存儲層提供靈活的分析體系結構,可處理 ACID(原子性、一致性、隔離性和持久性)事務,以實現數據可靠性、流集成和高級功能(如數據版本控制和架構強制)。這樣可以在湖上進行一系列分析活動,并且完全不會影響核心數據一致性。雖然湖屋的需求取決于需求的復雜程度,但其靈活性和范圍使其成為許多企業組織的最佳解決方案。
| 數據湖 | 湖倉一體/LakeHouse/數據湖屋 | |
|---|---|---|
| 類型 | 結構化、半結構化、非結構化 | 結構化、半結構化、非結構化 |
| 關系型、非關系型 | 關系型、非關系型 | |
| 架構 | 讀取時的架構 | 讀取時的架構、寫入時的架構 |
| 格式 | 原始、未篩選、已處理、已精選 | 原始、未篩選、已處理、已精選、增量格式化文件 |
| 源 | 大數據、IoT、社交媒體、流數據 | 大數據、IoT、社交媒體、流數據、應用程序、業務、事務數據、批處理報告 |
| 可伸縮性 | 輕松縮放,成本低 | 輕松縮放,成本低 |
| 用戶 | 數據科學家 | 業務分析師、數據工程師、數據科學家 |
| 用例 | 機器學習、預測分析 | 核心報告、BI、機器學習、預測分析 |
相關企業
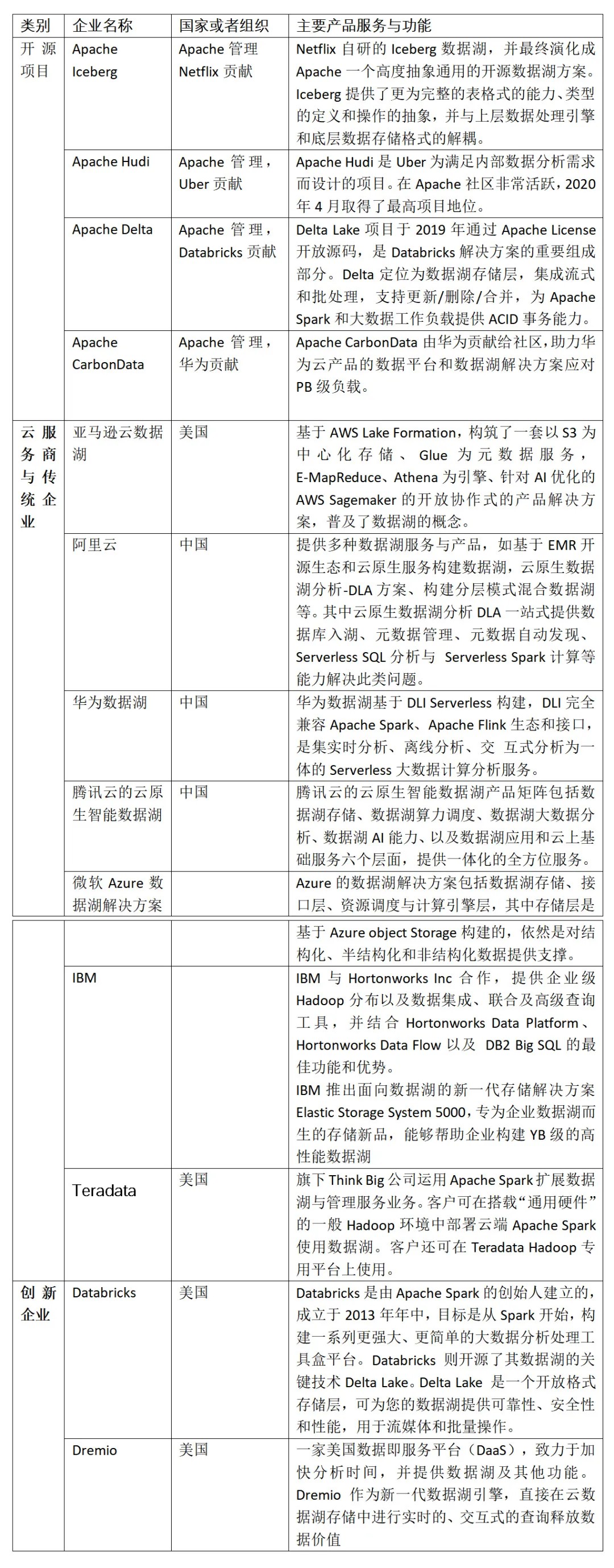
2 開源數據湖組件
市面上流行的三大開源數據湖方案分別為:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商業化上取得巨大成功,所以由其背后商業公司 Databricks 推出的 Delta 也顯得格外亮眼。Apache Hudi 是由 Uber 的工程師為滿足其內部數據分析的需求而設計的數據湖項目,它提供的 fast upsert/delete 以及 compaction 等功能可以說是精準命中廣大人民群眾的痛點,加上項目各成員積極地社區建設,包括技術細節分享、國內社區推廣等等,也在逐步地吸引潛在用戶的目光。Apache Iceberg 目前看則會顯得相對平庸一些,簡單說社區關注度暫時比不上 Delta,功能也不如 Hudi 豐富,但卻是一個野心勃勃的項目,因為它具有高度抽象和非常優雅的設計,為成為一個通用的數據湖方案奠定了良好基礎。
特性對比
三個引擎的初衷場景并不完全相同
-
Hudi 為了 incremental 的 upserts
-
Iceberg 定位于?性能的分析與可靠的數據管理
-
Delta 定位于流批?體的數據處理。
這種場景的不同也造成了三者在設計上的差別。尤其是 Hudi,其設計與另外兩個相?差別更為明顯。
Delta、Hudi、Iceberg三個開源項?中,Delta和Hudi跟Spark的代碼深度綁定,尤其是寫?路徑。這兩個項?設計之初,都基本上把Spark作為他們的默認計算引擎了。?Apache Iceberg的?向?常堅定,宗旨就是要做?個通?化設計的Table Format。
Iceberg完美的解耦了計算引擎和底下的存儲系統,便于多樣化計算引擎和?件格式,很好的完成了數據湖架構中的Table Format這?層的實現,因此也更容易成為Table Format層的開源事實標準。另???,Apache Iceberg也在朝著流批?體的數據存儲層發展,manifest和snapshot的設計,有效地隔離不同transaction的變更,?常?便批處理和增量計算。并且,Apache Flink已經是?個流批?體的計算引擎,?者都可以完美匹配,合?打造流批?體的數據湖架構。

Hudi
Hudi 是一個流式數據湖平臺,提供 ACID 功能,支持實時消費增量數據、離線批量更新數據,并且可以通過 Spark、Flink、Presto 等計算引擎進行查詢。
Hudi 表由 timeline 和 file group兩大項構成。Timeline 由一個個 commit 構成,一次寫入過程對應時間線中的一個 commit,記錄本次寫入修改的文件。相較于傳統數倉,Hudi 要求每條記錄必須有唯一的主鍵,并且同分區內,相同主鍵只存在在一個 file group 中。底層存儲由多個 file group 構成,有其特定的 file ID。File group 內的文件分為 base file 和 log file, log file 記錄對 base file 的修改,通過 compaction 合并成新的 base file,多個版本的 base file 會同時存在。在表的更新方面,Hudi 表分為 COW 和 MOR 兩種類型:
-
COW 表: 適用于離線批量更新場景,對于更新數據,會先讀取舊的 base file,然后合并更新數據,生成新的 base file。
-
MOR 表:適用于實時高頻更新場景,更新數據會直接寫入 log file 中,讀時再進行合并。為了減少讀放大的問題,會定期合并 log file 到 base file 中。
對于更新數據,Hudi 通過索引快速定位數據所屬的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 Bucket Index 尚未合并到主分支。
-
字節跳動基于Hudi的優化方案:https://developer.volcengine.com/articles/7220345269954003004
技術內容

IceBerg
Iceberg 是一種適用于 HDFS 或者對象存儲的表格式,把底層的 Parquet、ORC 等數據文件組織成一張表,向上層的 Spark,Flink 計算引擎提供表層面的語義,作用類似于 Hive Meta Store,但是和 Hive Meta Store 相比:
-
Iceberg 能避免 File Listing 的開銷;
-
也能夠提供更豐富的語義,包括 Schema 演進、快照、行級更新、 ACID 增量讀等。
Iceberg 相較于 Hive 表是基于設計的文件組織形式實現的上述優點,和 Hive Metastore 把元數據存在 MySQL 上的數據庫不一樣, Iceberg 是把元數據以文件的形式存在 HDFS 或對象存儲上。最上層的 Catalog 也就是表的目錄指向了每個表當前版本對應的 Metadata File,由于 Iceberg 使用 MVCC,所以每次對表的變更都會產生一個新版本的 Metadata File。
3 湖倉一體
湖倉一體是指融合數據湖與數據倉庫的優勢,形成一體化、開放式數據處理平臺的技術。通過湖倉一體技術,可使得數據處理平臺底層支持多數據類型統一存儲,實現數據在數據湖、數據倉庫之間無縫調度和管理,并使得上層通過統一接口進行訪問查詢和分析。
企業需求的驅動下,數據湖與數據倉庫在原本的范式之上向其限制范圍擴展,逐漸形成了“湖上建倉”與“倉外掛湖”兩種湖倉一體實現路徑。湖上建倉和倉外掛湖雖然出發點不同,但最終湖倉一體的目標一致。
湖上建倉
解決數據湖限制的新系統開始出現,LakeHouse是一種結合了數據湖和數據倉庫優勢的新范式。LakeHouse使用新的系統設計:直接在用于數據湖的低成本存儲上實現與數據倉庫中類似的數據結構和數據管理功能。如果你現在需要重新設計數據倉庫,鑒于現在存儲(以對象存儲的形式)廉價且高可靠,不妨可以使用LakeHouse。
-
數據倉庫:數倉這樣的一種數據存儲架構,它主要存儲的是以關系型數據庫組織起來的結構化數據。數據通過轉換、整合以及清理,并導入到目標表中。在數倉中,數據存儲的結構與其定義的schema是強匹配的。
-
數據湖:數據湖這樣的一種數據存儲結構,它可以存儲任何類型的數據,包括像圖片、文檔這樣的非結構化數據。數據湖通常更大,其存儲成本也更為廉價。存儲其中的數據不需要滿足特定的schema,數據湖也不會嘗試去將特定的schema施行其上。相反的是,數據的擁有者通常會在讀取數據的時候解析schema(schema-on-read),當處理相應的數據時,將轉換施加其上。
當初許多的公司往往同時會搭建數倉、數據湖這兩種存儲架構,一個大的數倉和多個小的數據湖。這樣,數據在這兩種存儲中就會有肯定的冗余。
Data Lakehouse的出現試圖去交融數倉和數據湖這兩者之間的差別,通過將數倉構建在數據湖上,使得存儲變得更為便宜和彈性,同時lakehouse能夠有效地提升數據質量,減小數據冗余。在lakehouse的構建中,ETL起了非常重要的作用,它能夠將未經規整的數據湖層數據轉換成數倉層結構化的數據。Data Lakehouse概念是由Databricks在此文[1]中提出的,在提出概念的同時,也列出了如下一些特性:
-
事務支持:Lakehouse可以處理多條不同的數據管道。這意味著它可以在不破壞數據完整性的前提下支持并發的讀寫事務。
-
模式執行和治理(Schema enforcement and governance):LakeHouse應該有一種可以支持模式執行和演進、支持DW模式的范式(如star/snowflake-schemas)。該系統應該能夠推理數據完整性,并具有健壯的治理和審計機制。
-
Schemas:數倉會在所有存儲其上的數據上施加Schema,而數據湖則不會。Lakehouse的架構可以根據應用的需求為絕大多數的數據施加schema,使其標準化。
-
BI支持:LakeHouse可以直接在源數據上使用BI工具。這樣可以提高數據新鮮度,減少等待時間,降低必須同時在數據湖和數據倉庫中操作兩個數據副本的成本
-
存儲與計算分離:這意味著存儲和計算使用單獨的集群,因此這些系統能夠支持更多用戶并發和更大數據量。一些現代數據倉庫也具有此屬性。
-
報表以及分析應用的支持:報表和分析應用都可以使用這一存儲架構。Lakehouse里面所保存的數據經過了清理和整合的過程,它可以用來加速分析。同時相比于數倉,它能夠保存更多的數據,數據的時效性也會更高,能顯著提升報表的質量。
-
數據類型擴展:數倉僅可以支持結構化數據,而Lakehouse的結構可以支持更多不同類型的數據,包括文件、視頻、音頻和系統日志。
-
端到端的流式支持:Lakehouse可以支持流式分析,從而能夠滿足實時報表的需求,實時報表在現在越來越多的企業中重要性在逐漸提高。
-
開放性:Lakehouse在其構建中通常會使Iceberg,Hudi,Delta Lake等組件,首先這些組件是開源開放的,其次這些組件采用了Parquet,ORC這樣開放兼容的存儲格式作為下層的數據存儲格式,因此不同的引擎,不同的語言都可以在Lakehouse上進行操作
Lakehouse的概念最早是由Databricks所提出的,而其他的類似的產品有Azure Synapse Analytics。Lakehouse技術仍然在發展中,因此上面所述的這些特性也會被不斷的修訂和改進。

案例-AWS-智能湖倉

案例-Databricks –Delta Lake
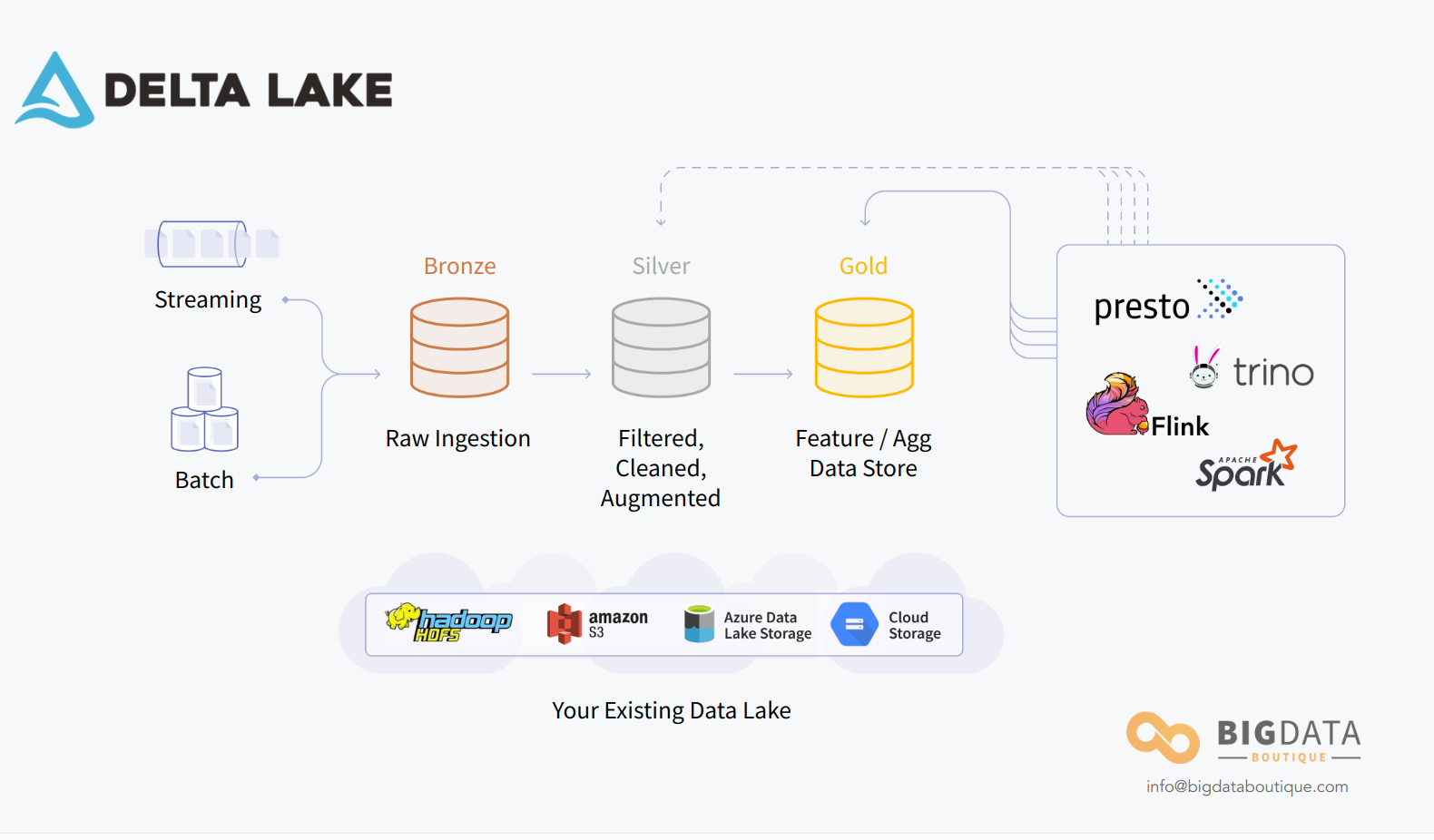
倉外掛湖
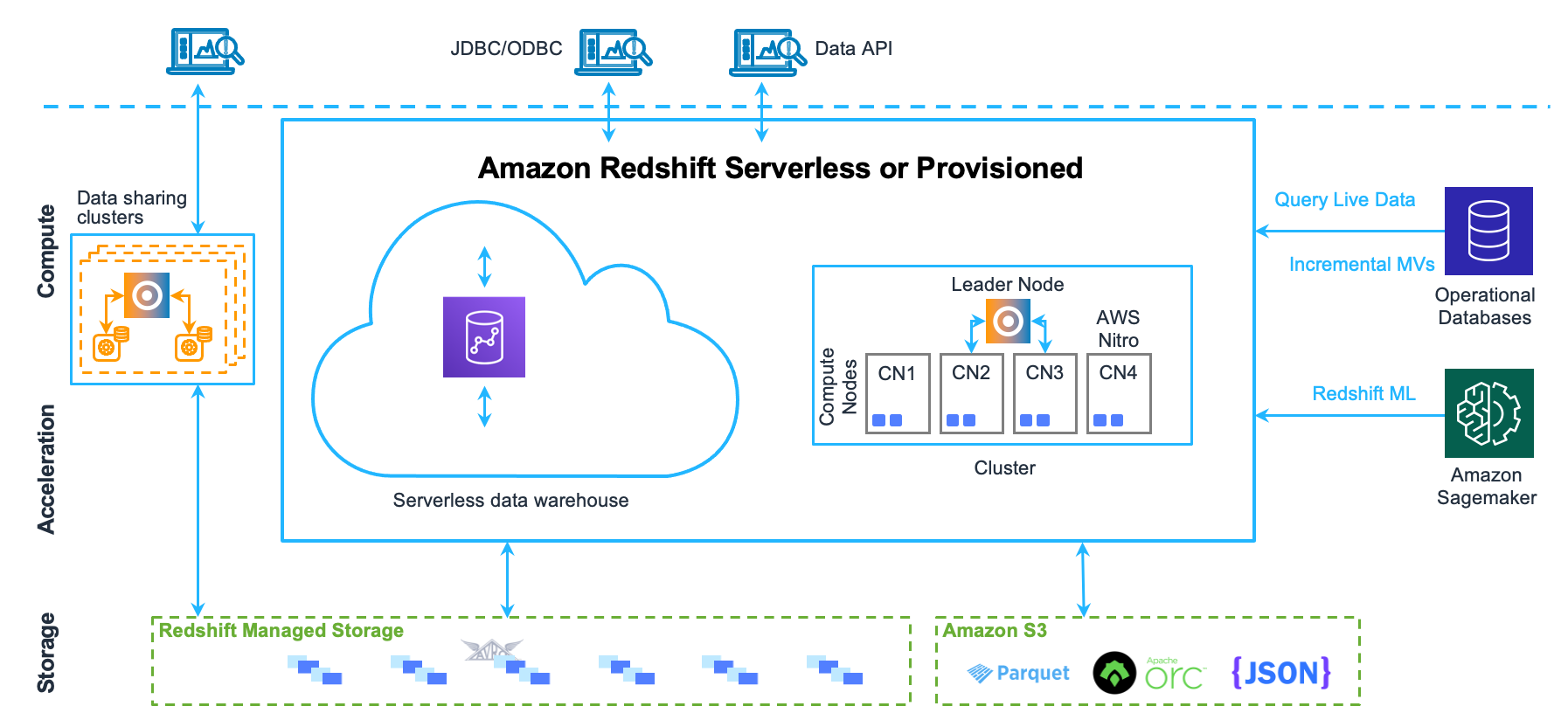
倉外掛湖是指以 MPP 數據庫為基礎,使用可插拔架構,通過開放接口對接外部存儲實現統一存儲,在存儲底層共享一份數據,計算、存儲完全分離,實現從強管理到兼容開放存儲和多引擎。代表產品: Snowflake、AWS Redshift、阿里云 MaxCompute/Hologres 湖倉一體。
MPP 數據庫技術體系,從關系型數據庫演進而來,對事務一致性、聯機分析處理性能都有較好的支撐,但在分析場景方面存在較大的局限性,主要以結構化數據分析為主,無法支撐半/非結構化數據存儲、實時計算、機器學習等場景。所以實現途徑中,實現方向為增加存儲能力,提升查詢引擎效率。
總的來看,“倉外掛湖”路徑本質是在倉的基礎上增加湖的多類型存儲等能力,需解決以下五大技術難點:
-
一是統一元數據管理。打通不同數據系統,具備數據共享和跨庫分析的能力,并支持互聯互通、計算下推、協同計算,實現數據多平之間透明流動。倉外掛湖路徑目前主要是將對接外部存儲如Hadoop、對象存儲等的元數據進行采集,統一存儲、管理。
-
二是存儲開放性。倉外掛湖路徑的存儲開放性主要表現在:存儲介質兼容方面,將非數倉自身存儲如 Hadoop、云對象存儲等的數據納入管理;數據格式方面,采用開放、標準化的數據格式,既包含Hudi、 Iceberg、Delta Lake 等開放格式,也包括 Parquet、ORC、CSV 等存儲格式的支持。
-
三是擴展查詢引擎。倉外掛湖路徑保留原 MPP 計算引擎計算能力的基礎之上,主要是增加批處理和實時數據處理的能力。其中批處理方面是融合更輕量級、高效率的計算能力,而實時處理方面則是通過微批以及增量計算的方式,增強流的計算能力。
-
四是存算分離。倉外掛湖需進行存算分離架構改造,而傳統的 MPP 存算耦合架構,不具備云原生能力。目前,倉外掛湖路徑主要基于存算分離架構改造后的云原生 MPP 數據庫實現。
-
五是彈性伸縮。基于 K8S、Docker 等容器化技術對 MPP 體系的組件、服務進行容器化改造。目前該路徑有實現計算層、存儲層彈性伸縮,少量產品實現了根據業務負載自動彈性伸縮計算資源。
案例-阿里-湖倉一體

案例-AWS Redshift
4 企業案例
騰訊
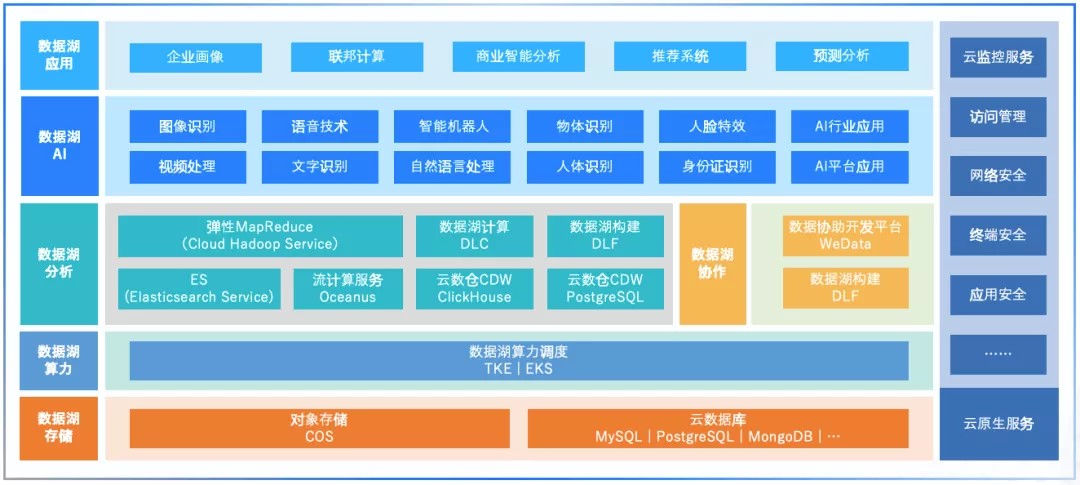
阿里-湖倉一體

 浙公網安備 33010602011771號
浙公網安備 33010602011771號