
《A Novel Table-to-Graph Generation Approach for Document-Level Joint Entity and Relation Extraction》閱讀筆記
文檔級(jí)關(guān)系抽取(DocRE)的目的是從文檔中提取實(shí)體之間的關(guān)系,這對(duì)于知識(shí)圖譜構(gòu)建等應(yīng)用非常重要。然而,現(xiàn)有的方法通常需要預(yù)先識(shí)別出文檔中的實(shí)體及其提及,這與實(shí)際應(yīng)用場(chǎng)景不一致。為了解決這個(gè)問(wèn)題,本文提出了一種新穎的表格到圖生成模型(TAG),它能夠在文檔級(jí)別上同時(shí)抽取實(shí)體和關(guān)系。TAG的核心思想是在提及之間構(gòu)建一個(gè)潛在的圖,其中不同類型的邊反映了不同的任務(wù)信息,然后利用關(guān)系圖卷積網(wǎng)絡(luò)(RGCN)對(duì)圖進(jìn)行信息傳播。此外,為了減少錯(cuò)誤傳播的影響,本文在解碼階段采用了層次聚類算法,將任務(wù)信息從提及層反向傳遞到實(shí)體層。在DocRED數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,TAG顯著優(yōu)于以前的方法,達(dá)到了當(dāng)前的最佳性能。
1 Introduction
關(guān)系抽取(RE):從自然語(yǔ)言文本中抽取實(shí)體之間的語(yǔ)義關(guān)系,并將其表示為結(jié)構(gòu)化的三元組。
句子級(jí)RE:在單個(gè)句子的范圍內(nèi),抽取句子中實(shí)體對(duì)之間的關(guān)系。
DocRE:在多個(gè)句子的范圍內(nèi),利用跨句子的語(yǔ)義推理,抽取文檔中實(shí)體對(duì)之間的關(guān)系。
大部分現(xiàn)有的DocRE方法只關(guān)注抽取關(guān)系,這些方法假設(shè)實(shí)體及其對(duì)應(yīng)的提及已經(jīng)預(yù)先給定。
流水線方法
流水線框架是一種用于DocRE的方法,該框架首先將整個(gè)任務(wù)劃分為提及抽取(ME)、共指消解(COREF)和實(shí)體關(guān)系抽取(RE)三個(gè)子任務(wù),然后使用單獨(dú)的模型逐步進(jìn)行每個(gè)任務(wù)(Zaporojets等人, 2021)。然而,該框架的缺點(diǎn)在于它忽略了子任務(wù)之間的潛在依賴性,影響了模型的性能。
早期的聯(lián)合考慮子任務(wù)的方法
一些早期的聯(lián)合考慮子任務(wù)的方法,如(Eberts等人, 2021; Xu等人,2022)仍然將COREF和RE任務(wù)分別建模,導(dǎo)致在編碼和解碼階段可能產(chǎn)生的偏差。一方面,這類方法仍然存在信息共享不足的問(wèn)題。它們要么完全依賴于共享的語(yǔ)言模型(如BERT)(Eberts等人,2021),要么只考慮從RE到COREF的單向信息流,忽略了其他跨任務(wù)的依賴性(Xu等人, 2022)。另一方面,這類方法大多采用流水線風(fēng)格的解碼,即先識(shí)別提及范圍并形成實(shí)體簇,然后對(duì)每對(duì)實(shí)體進(jìn)行關(guān)系分類。流水線風(fēng)格的解碼不僅耗時(shí),而且面臨著錯(cuò)誤傳播的問(wèn)題。實(shí)體提及抽取的結(jié)果可能影響關(guān)系抽取的性能,并導(dǎo)致級(jí)聯(lián)錯(cuò)誤。Xu等人(2022)引入一個(gè)正則化項(xiàng)來(lái)緩解這個(gè)問(wèn)題,但是問(wèn)題仍然沒(méi)有完全解決。
本文提出了TAG,將COREF和RE兩個(gè)任務(wù)融合為一個(gè)表格填充任務(wù)的方法,使用一個(gè)表格填充器對(duì)原始文本進(jìn)行編碼,并在粗粒度上生成提及和關(guān)系的候選集合。為了表示共指和關(guān)系的信息,本文動(dòng)態(tài)地構(gòu)建了兩個(gè)圖結(jié)構(gòu),其中節(jié)點(diǎn)是提及,邊的權(quán)重由表格填充器的置信度得分決定。此外,本文還在提及層面上建立了一個(gè)句法圖,以緩解長(zhǎng)距離依賴問(wèn)題,并顯式地引入句法信息。本文將這三個(gè)圖視為三種不同類型的邊,并利用關(guān)系圖卷積網(wǎng)絡(luò)(RGCN)來(lái)在細(xì)粒度上捕捉任務(wù)之間的隱含依賴關(guān)系。本文的粗到細(xì)的方法利用了豐富的節(jié)點(diǎn)表示,通過(guò)語(yǔ)義和句法鏈接傳遞信息,這與之前僅從語(yǔ)言模型中共享范圍表示的多任務(wù)系統(tǒng)不同。本文還采用了一個(gè)直觀的假設(shè),即同一實(shí)體簇中的提及應(yīng)該與其他實(shí)體形成相似的關(guān)系鏈接,并將層次聚類算法(HAC)應(yīng)用到提及聚類中,以利用關(guān)系信息來(lái)提升共指消解的性能,從而避免錯(cuò)誤傳播的風(fēng)險(xiǎn)。本文在廣泛使用的DocRE基準(zhǔn)數(shù)據(jù)集DocRED上進(jìn)行了實(shí)驗(yàn),結(jié)果表明,本文提出的TAG模型顯著優(yōu)于現(xiàn)有的方法,并達(dá)到了新的最佳水平。本文還在DocRED的一個(gè)修訂版本Re-DocRED上報(bào)告了聯(lián)合實(shí)體和關(guān)系抽取的第一個(gè)結(jié)果,為未來(lái)的研究提供了一個(gè)新的基準(zhǔn)。
2 Problem Formulation
DocRE的任務(wù)是,給定一個(gè)包含L個(gè)單詞的文檔D,端到端地同時(shí)提取所有實(shí)體和關(guān)系。因?yàn)槟硞€(gè)實(shí)體可能在文檔中以不同的形式多次出現(xiàn),所以提取過(guò)程涉及到以下三個(gè)子任務(wù):
-
提及抽取(ME):從原始文檔中抽取所有可能的實(shí)體范圍
![]() 的任務(wù),其中一個(gè)范圍是指一個(gè)連續(xù)的單詞序列。
的任務(wù),其中一個(gè)范圍是指一個(gè)連續(xù)的單詞序列。 -
共指消解(COREF):是將文檔中的局部提及分組為實(shí)體簇
![]()
![]() ,其中,
,其中,![]() 。
。 -
關(guān)系抽取(RE):在預(yù)定義的關(guān)系集合
![]() (
(![]() 代表沒(méi)有關(guān)系)中,預(yù)測(cè)實(shí)體對(duì)之間的關(guān)系子集,其中,實(shí)體對(duì)為
代表沒(méi)有關(guān)系)中,預(yù)測(cè)實(shí)體對(duì)之間的關(guān)系子集,其中,實(shí)體對(duì)為![]() 。
。
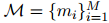 的任務(wù),其中一個(gè)范圍是指一個(gè)連續(xù)的單詞序列。
的任務(wù),其中一個(gè)范圍是指一個(gè)連續(xù)的單詞序列。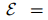
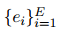 ,其中,
,其中,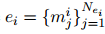 。
。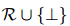 (
( 代表沒(méi)有關(guān)系)中,預(yù)測(cè)實(shí)體對(duì)之間的關(guān)系子集,其中,實(shí)體對(duì)為
代表沒(méi)有關(guān)系)中,預(yù)測(cè)實(shí)體對(duì)之間的關(guān)系子集,其中,實(shí)體對(duì)為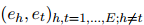 。
。與以前的工作不同,本文將COREF和RE兩個(gè)任務(wù)用表格填充框架來(lái)建模,即對(duì)每對(duì)提及![]() 進(jìn)行多分類。本文維護(hù)一個(gè)表格
進(jìn)行多分類。本文維護(hù)一個(gè)表格![]() 來(lái)表示提及對(duì),并使用一個(gè)共享的表示來(lái)處理兩個(gè)任務(wù)。對(duì)于表格中的每個(gè)單元格,本文分別為其分配COREF標(biāo)簽
來(lái)表示提及對(duì),并使用一個(gè)共享的表示來(lái)處理兩個(gè)任務(wù)。對(duì)于表格中的每個(gè)單元格,本文分別為其分配COREF標(biāo)簽![]() 和RE標(biāo)簽
和RE標(biāo)簽![]() 。對(duì)于COREF,用1/0表示一對(duì)提及是否屬于同一個(gè)實(shí)體。對(duì)于RE,將實(shí)體級(jí)別的標(biāo)簽轉(zhuǎn)換為提及級(jí)別的標(biāo)簽,其中提及對(duì)
。對(duì)于COREF,用1/0表示一對(duì)提及是否屬于同一個(gè)實(shí)體。對(duì)于RE,將實(shí)體級(jí)別的標(biāo)簽轉(zhuǎn)換為提及級(jí)別的標(biāo)簽,其中提及對(duì)![]() 與其所屬實(shí)體
與其所屬實(shí)體![]() 具有相同的關(guān)系,且
具有相同的關(guān)系,且![]() 。
。
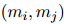 進(jìn)行多分類。本文維護(hù)一個(gè)表格
進(jìn)行多分類。本文維護(hù)一個(gè)表格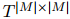 來(lái)表示提及對(duì),并使用一個(gè)共享的表示來(lái)處理兩個(gè)任務(wù)。對(duì)于表格中的每個(gè)單元格,本文分別為其分配COREF標(biāo)簽
來(lái)表示提及對(duì),并使用一個(gè)共享的表示來(lái)處理兩個(gè)任務(wù)。對(duì)于表格中的每個(gè)單元格,本文分別為其分配COREF標(biāo)簽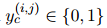 和RE標(biāo)簽
和RE標(biāo)簽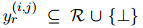 。對(duì)于COREF,用1/0表示一對(duì)提及是否屬于同一個(gè)實(shí)體。對(duì)于RE,將實(shí)體級(jí)別的標(biāo)簽轉(zhuǎn)換為提及級(jí)別的標(biāo)簽,其中提及對(duì)
。對(duì)于COREF,用1/0表示一對(duì)提及是否屬于同一個(gè)實(shí)體。對(duì)于RE,將實(shí)體級(jí)別的標(biāo)簽轉(zhuǎn)換為提及級(jí)別的標(biāo)簽,其中提及對(duì)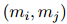 與其所屬實(shí)體
與其所屬實(shí)體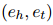 具有相同的關(guān)系,且
具有相同的關(guān)系,且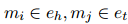 。
。3 Methodology
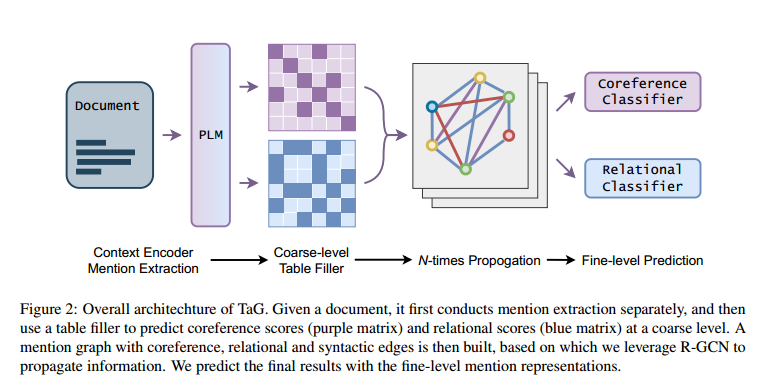
3.1 Mention Extractor
考慮到DocRE任務(wù)中重疊提及的情況較少,本文為了提高效率,采用了一種序列標(biāo)注(sequence-based)的方式來(lái)抽取提及。該方法使用BIO標(biāo)簽來(lái)標(biāo)記提及的開(kāi)始、內(nèi)部和結(jié)束位置,相比于基于跨度的方法,雖然犧牲了一些表達(dá)能力,但是降低了時(shí)間復(fù)雜度,只需要線性時(shí)間就可以完成。本文借鑒了Devlin等人(2019)的工作,先用預(yù)訓(xùn)練語(yǔ)言模型(PLM)對(duì)文檔中的詞進(jìn)行向量化,然后用一個(gè)分類器對(duì)每個(gè)詞進(jìn)行BIO標(biāo)簽的分配,用![]() 表示抽取出的所有提及。
表示抽取出的所有提及。
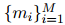 表示抽取出的所有提及。
表示抽取出的所有提及。3.2 Table-to-Graph Generation
3.2.1 Biaffine Table Filler
給定一個(gè)文檔![]() 和相應(yīng)的提及集
和相應(yīng)的提及集![]() ,本文用表格的方式來(lái)表示每對(duì)提及,借鑒了實(shí)體標(biāo)記策略(Baldini Soares等人,2019),在每個(gè)提及的首尾添加一個(gè)特殊符號(hào)“*”。接著用一個(gè)獨(dú)立的預(yù)訓(xùn)練語(yǔ)言模型(PLM)來(lái)獲取上下文表示
,本文用表格的方式來(lái)表示每對(duì)提及,借鑒了實(shí)體標(biāo)記策略(Baldini Soares等人,2019),在每個(gè)提及的首尾添加一個(gè)特殊符號(hào)“*”。接著用一個(gè)獨(dú)立的預(yù)訓(xùn)練語(yǔ)言模型(PLM)來(lái)獲取上下文表示![]() 和多頭注意力
和多頭注意力![]() :
:
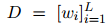 和相應(yīng)的提及集
和相應(yīng)的提及集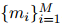 ,本文用表格的方式來(lái)表示每對(duì)提及,借鑒了實(shí)體標(biāo)記策略(Baldini Soares等人,2019),在每個(gè)提及的首尾添加一個(gè)特殊符號(hào)“*”。接著用一個(gè)獨(dú)立的預(yù)訓(xùn)練語(yǔ)言模型(PLM)來(lái)獲取上下文表示
,本文用表格的方式來(lái)表示每對(duì)提及,借鑒了實(shí)體標(biāo)記策略(Baldini Soares等人,2019),在每個(gè)提及的首尾添加一個(gè)特殊符號(hào)“*”。接著用一個(gè)獨(dú)立的預(yù)訓(xùn)練語(yǔ)言模型(PLM)來(lái)獲取上下文表示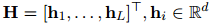 和多頭注意力
和多頭注意力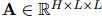 :
: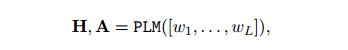
式中,A為最后一層Transformer的多頭注意矩陣。
將起始標(biāo)記為“*”的嵌入作為提及嵌入,為了捕獲提及對(duì)![]() 的相關(guān)上下文,應(yīng)用本地化上下文池技術(shù)來(lái)計(jì)算上下文嵌入
的相關(guān)上下文,應(yīng)用本地化上下文池技術(shù)來(lái)計(jì)算上下文嵌入![]() (Zhou等人, 2021):
(Zhou等人, 2021):
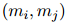 的相關(guān)上下文,應(yīng)用本地化上下文池技術(shù)來(lái)計(jì)算上下文嵌入
的相關(guān)上下文,應(yīng)用本地化上下文池技術(shù)來(lái)計(jì)算上下文嵌入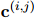 (Zhou等人, 2021):
(Zhou等人, 2021):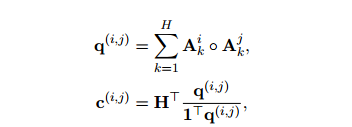
式中,![]() 代表哈達(dá)瑪積,
代表哈達(dá)瑪積,![]() 分別是第k個(gè)注意力頭中
分別是第k個(gè)注意力頭中![]() 的注意權(quán)值,
的注意權(quán)值,![]() 由對(duì)
由對(duì)![]() 和
和![]() 都有高度關(guān)注的詞聚合而成,因此可能對(duì)它們都很重要。
都有高度關(guān)注的詞聚合而成,因此可能對(duì)它們都很重要。
 代表哈達(dá)瑪積,
代表哈達(dá)瑪積,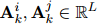 分別是第k個(gè)注意力頭中
分別是第k個(gè)注意力頭中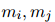 的注意權(quán)值,
的注意權(quán)值,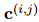 由對(duì)
由對(duì)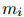 和
和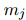 都有高度關(guān)注的詞聚合而成,因此可能對(duì)它們都很重要。
都有高度關(guān)注的詞聚合而成,因此可能對(duì)它們都很重要。定義![]() 作為PLM中
作為PLM中![]() 和
和![]() 的隱藏特征,首先將
的隱藏特征,首先將![]() 和
和![]() 投影為頭尾特征:
投影為頭尾特征:
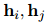 作為PLM中和的隱藏特征,首先將和投影為頭尾特征:
作為PLM中和的隱藏特征,首先將和投影為頭尾特征: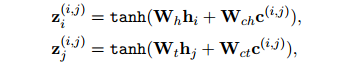
式中,![]() 都是可訓(xùn)練參數(shù)。
都是可訓(xùn)練參數(shù)。
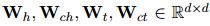 都是可訓(xùn)練參數(shù)。
都是可訓(xùn)練參數(shù)。采用雙仿射注意力機(jī)制將提及特征轉(zhuǎn)換為表示共指消解或關(guān)系鏈接的標(biāo)量分?jǐn)?shù)表![]()
![]() :
:
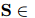
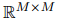 :
: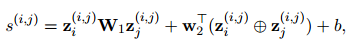
式中,![]() 都是可訓(xùn)練參數(shù),
都是可訓(xùn)練參數(shù),![]() 表示向量串聯(lián),分別用共享表示
表示向量串聯(lián),分別用共享表示![]() 預(yù)測(cè)得到共指消解分?jǐn)?shù)
預(yù)測(cè)得到共指消解分?jǐn)?shù)![]() 和關(guān)系抽取分?jǐn)?shù)
和關(guān)系抽取分?jǐn)?shù)![]() ,具體來(lái)說(shuō),如果RE標(biāo)記
,具體來(lái)說(shuō),如果RE標(biāo)記![]() ,則
,則![]() 被標(biāo)記為1,否則為0。
被標(biāo)記為1,否則為0。
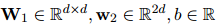 都是可訓(xùn)練參數(shù),
都是可訓(xùn)練參數(shù), 表示向量串聯(lián),分別用共享表示
表示向量串聯(lián),分別用共享表示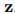 預(yù)測(cè)得到共指消解分?jǐn)?shù)
預(yù)測(cè)得到共指消解分?jǐn)?shù)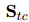 和關(guān)系抽取分?jǐn)?shù)
和關(guān)系抽取分?jǐn)?shù)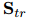 ,具體來(lái)說(shuō),如果RE標(biāo)記
,具體來(lái)說(shuō),如果RE標(biāo)記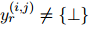 ,則
,則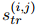 被標(biāo)記為1,否則為0。
被標(biāo)記為1,否則為0。3.2.2 Latent Graph Construction
Coreference and Relational Graphs.
在得到共指消解和關(guān)系分?jǐn)?shù)![]() ,
, ![]() 后,對(duì)每個(gè)表的列進(jìn)行規(guī)范化:
后,對(duì)每個(gè)表的列進(jìn)行規(guī)范化:
, 后,對(duì)每個(gè)表的列進(jìn)行規(guī)范化:
本文將![]() 和
和![]() 作為前面模塊預(yù)測(cè)的共指消解和關(guān)系鏈接的動(dòng)態(tài)加權(quán)圖,每個(gè)單元格
作為前面模塊預(yù)測(cè)的共指消解和關(guān)系鏈接的動(dòng)態(tài)加權(quán)圖,每個(gè)單元格![]() 代表有向邊的權(quán)值
代表有向邊的權(quán)值![]() 。
。
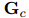 和
和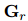 作為前面模塊預(yù)測(cè)的共指消解和關(guān)系鏈接的動(dòng)態(tài)加權(quán)圖,每個(gè)單元格
作為前面模塊預(yù)測(cè)的共指消解和關(guān)系鏈接的動(dòng)態(tài)加權(quán)圖,每個(gè)單元格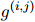 代表有向邊的權(quán)值
代表有向邊的權(quán)值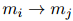 。
。Syntactic Graph.
現(xiàn)有的提及圖模型往往忽略了句法信息,導(dǎo)致模型難以捕捉長(zhǎng)期依賴關(guān)系。為了解決這個(gè)問(wèn)題,本文構(gòu)建了語(yǔ)法圖,在提及圖中明確地引入句法信息,使模型能夠在精細(xì)的級(jí)別上學(xué)習(xí)長(zhǎng)期依賴關(guān)系。為了構(gòu)建語(yǔ)法圖,需要考慮兩個(gè)方面:一是如何將句法信息轉(zhuǎn)換為圖結(jié)構(gòu),二是如何在圖結(jié)構(gòu)上進(jìn)行信息傳播。本文考慮了幾種可選的方法來(lái)實(shí)現(xiàn)這兩個(gè)方面。例如,一種直觀的解決方案是將單詞的依賴樹(shù)轉(zhuǎn)移到圖中,其中提及是節(jié)點(diǎn),依賴關(guān)系是邊。這種方法可以保留句子內(nèi)部的句法結(jié)構(gòu),但是無(wú)法捕捉句子之間的句法關(guān)系。本文參考了以前的作品(Christopoulou等人, 2019;Zeng等人, 2020),并采用了一種基于共現(xiàn)的方法,即使用雙向邊將同一句子中的所有提及連接起來(lái),從而增強(qiáng)句子內(nèi)部的語(yǔ)義關(guān)聯(lián)。
3.2.3 Propagating Information with R-GCN
COREF和RE是兩個(gè)重要的信息抽取任務(wù),它們可以從文本中識(shí)別實(shí)體和實(shí)體之間的關(guān)系。然而,現(xiàn)有的方法往往分別處理這兩個(gè)任務(wù),忽略了它們之間的交互和語(yǔ)法信息的作用。為了解決這個(gè)問(wèn)題,本文提出了一個(gè)信息傳播模塊,它可以考慮COREF和RE任務(wù)之間的交互,并結(jié)合顯式語(yǔ)法信息,從而改進(jìn)提及表示。具體來(lái)說(shuō),本文提出了一種基于潛在圖的方法,它可以將提及圖上的三種不同類型的邊(分別對(duì)應(yīng)COREF、RE和語(yǔ)法)進(jìn)行統(tǒng)一建模。本文的模型可以利用不同類型的邊來(lái)聚合鄰居特征,從而增強(qiáng)提及的語(yǔ)義和結(jié)構(gòu)信息。為了在提及圖上應(yīng)用關(guān)系圖卷積網(wǎng)絡(luò),本文設(shè)計(jì)了一個(gè)更新過(guò)程,它可以根據(jù)邊的類型和權(quán)值來(lái)調(diào)整不同鄰居的貢獻(xiàn)。本文的模型可以初始化節(jié)點(diǎn)嵌入為提及的隱藏特征,然后通過(guò)多層的信息傳播來(lái)更新提及表示。與以前的方法不同,本文的模塊可以并行集成跨任務(wù)信息,并提取兩個(gè)任務(wù)的相關(guān)提及特征,從而實(shí)現(xiàn)更有效的信息抽取。
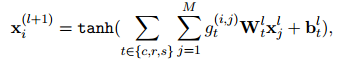
3.2.4 Classifier
經(jīng)過(guò)N次傳播后,本文使用優(yōu)化后的提及嵌入![]() 和上下文嵌入
和上下文嵌入![]() 來(lái)預(yù)測(cè)COREF得分
來(lái)預(yù)測(cè)COREF得分![]() 和RE得分
和RE得分![]() :
:
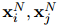 和上下文嵌入
和上下文嵌入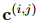 來(lái)預(yù)測(cè)COREF得分
來(lái)預(yù)測(cè)COREF得分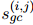 和RE得分
和RE得分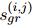 :
: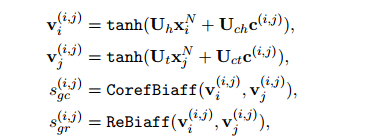
式中,![]() 都是可訓(xùn)練參數(shù),n維的雙仿函數(shù)定義為:
都是可訓(xùn)練參數(shù),n維的雙仿函數(shù)定義為:
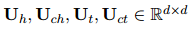 都是可訓(xùn)練參數(shù),n維的雙仿函數(shù)定義為:
都是可訓(xùn)練參數(shù),n維的雙仿函數(shù)定義為: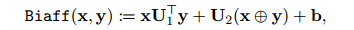
式中,![]() 是可訓(xùn)練參數(shù), 在COREF任務(wù)中,
是可訓(xùn)練參數(shù), 在COREF任務(wù)中,![]() ;在RE任務(wù)中,
;在RE任務(wù)中,![]() 。為了實(shí)現(xiàn)多標(biāo)簽分類的動(dòng)態(tài)閾值,引入了一個(gè)虛擬類TH,根據(jù)Zhou等人(2021)的方法來(lái)學(xué)習(xí)它的分?jǐn)?shù)。在測(cè)試階段,將分?jǐn)?shù)高于TH類的關(guān)系類型預(yù)測(cè)為輸出
。為了實(shí)現(xiàn)多標(biāo)簽分類的動(dòng)態(tài)閾值,引入了一個(gè)虛擬類TH,根據(jù)Zhou等人(2021)的方法來(lái)學(xué)習(xí)它的分?jǐn)?shù)。在測(cè)試階段,將分?jǐn)?shù)高于TH類的關(guān)系類型預(yù)測(cè)為輸出![]() 。如果沒(méi)有任何關(guān)系類型的分?jǐn)?shù)高于TH類,就認(rèn)為分類器沒(méi)有找到任何關(guān)系,返回
。如果沒(méi)有任何關(guān)系類型的分?jǐn)?shù)高于TH類,就認(rèn)為分類器沒(méi)有找到任何關(guān)系,返回![]() 。
。
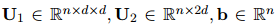 是可訓(xùn)練參數(shù), 在COREF任務(wù)中,
是可訓(xùn)練參數(shù), 在COREF任務(wù)中,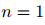 ;在RE任務(wù)中,
;在RE任務(wù)中,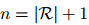 。為了實(shí)現(xiàn)多標(biāo)簽分類的動(dòng)態(tài)閾值,引入了一個(gè)虛擬類TH,根據(jù)Zhou等人(2021)的方法來(lái)學(xué)習(xí)它的分?jǐn)?shù)。在測(cè)試階段,將分?jǐn)?shù)高于TH類的關(guān)系類型預(yù)測(cè)為輸出
。為了實(shí)現(xiàn)多標(biāo)簽分類的動(dòng)態(tài)閾值,引入了一個(gè)虛擬類TH,根據(jù)Zhou等人(2021)的方法來(lái)學(xué)習(xí)它的分?jǐn)?shù)。在測(cè)試階段,將分?jǐn)?shù)高于TH類的關(guān)系類型預(yù)測(cè)為輸出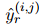 。如果沒(méi)有任何關(guān)系類型的分?jǐn)?shù)高于TH類,就認(rèn)為分類器沒(méi)有找到任何關(guān)系,返回
。如果沒(méi)有任何關(guān)系類型的分?jǐn)?shù)高于TH類,就認(rèn)為分類器沒(méi)有找到任何關(guān)系,返回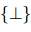 。
。3.3 Training
Table Encoder.
給定提及對(duì)![]() ,表格編碼器預(yù)測(cè)它們之間的COREF和RE鏈接,用標(biāo)量分?jǐn)?shù)
,表格編碼器預(yù)測(cè)它們之間的COREF和RE鏈接,用標(biāo)量分?jǐn)?shù)![]() 表示。對(duì)于共指消解鏈接,直接使用COREF標(biāo)簽
表示。對(duì)于共指消解鏈接,直接使用COREF標(biāo)簽![]() 作為金標(biāo)準(zhǔn)。對(duì)于關(guān)系抽取鏈接,定義
作為金標(biāo)準(zhǔn)。對(duì)于關(guān)系抽取鏈接,定義![]() ,表示是否存在任何關(guān)系
,表示是否存在任何關(guān)系![]() ,其中
,其中![]() 。用sigmoid函數(shù)σ將
。用sigmoid函數(shù)σ將![]() 轉(zhuǎn)換為概率,并用二元交叉熵?fù)p失
轉(zhuǎn)換為概率,并用二元交叉熵?fù)p失![]() 進(jìn)行優(yōu)化。
進(jìn)行優(yōu)化。
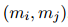 ,表格編碼器預(yù)測(cè)它們之間的COREF和RE鏈接,用標(biāo)量分?jǐn)?shù)
,表格編碼器預(yù)測(cè)它們之間的COREF和RE鏈接,用標(biāo)量分?jǐn)?shù)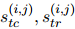 表示。對(duì)于共指消解鏈接,直接使用COREF標(biāo)簽
表示。對(duì)于共指消解鏈接,直接使用COREF標(biāo)簽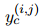 作為金標(biāo)準(zhǔn)。對(duì)于關(guān)系抽取鏈接,定義
作為金標(biāo)準(zhǔn)。對(duì)于關(guān)系抽取鏈接,定義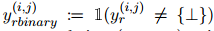 ,表示是否存在任何關(guān)系
,表示是否存在任何關(guān)系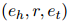 ,其中
,其中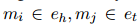 。用sigmoid函數(shù)σ將
。用sigmoid函數(shù)σ將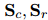 轉(zhuǎn)換為概率,并用二元交叉熵?fù)p失
轉(zhuǎn)換為概率,并用二元交叉熵?fù)p失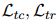 進(jìn)行優(yōu)化。
進(jìn)行優(yōu)化。Coreference Resolution.
細(xì)粒度共指消解(fine-level coreference resolution)的訓(xùn)練目標(biāo)和標(biāo)簽與表格編碼器(table encoder)中的共指鏈接預(yù)測(cè)(coreference link prediction)是一致的。唯一的區(qū)別是它使用優(yōu)化后的提及表示(refined mention representations)作為輸入。用![]() 表示損失函數(shù)。
表示損失函數(shù)。
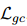 表示損失函數(shù)。
表示損失函數(shù)。Relation Extraction.
對(duì)于提及對(duì)![]() ,本文將關(guān)系集合
,本文將關(guān)系集合![]() 分為兩個(gè)子集:正集
分為兩個(gè)子集:正集![]() 包含了存在于
包含了存在于![]() 之間的關(guān)系
之間的關(guān)系![]() ,負(fù)集
,負(fù)集![]() 包含了不存在于
包含了不存在于![]() 之間的關(guān)系。使用自適應(yīng)閾值損失函數(shù)來(lái)學(xué)習(xí)關(guān)系抽取分類器:
之間的關(guān)系。使用自適應(yīng)閾值損失函數(shù)來(lái)學(xué)習(xí)關(guān)系抽取分類器:
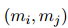 ,本文將關(guān)系集合
,本文將關(guān)系集合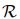 分為兩個(gè)子集:正集
分為兩個(gè)子集:正集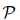 包含了存在于之間的關(guān)系
包含了存在于之間的關(guān)系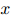 ,負(fù)集
,負(fù)集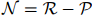 包含了不存在于之間的關(guān)系。使用自適應(yīng)閾值損失函數(shù)來(lái)學(xué)習(xí)關(guān)系抽取分類器:
包含了不存在于之間的關(guān)系。使用自適應(yīng)閾值損失函數(shù)來(lái)學(xué)習(xí)關(guān)系抽取分類器: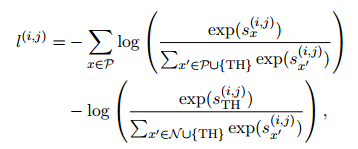
對(duì)所有提及對(duì)進(jìn)行求和,計(jì)算細(xì)級(jí)關(guān)系提取損失![]() 。
。
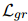 。
。最后,對(duì)TAG進(jìn)行聯(lián)合優(yōu)化
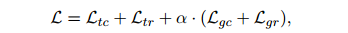
其中![]() 是平衡粗級(jí)和細(xì)級(jí)損失的超參數(shù)。
是平衡粗級(jí)和細(xì)級(jí)損失的超參數(shù)。
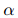 是平衡粗級(jí)和細(xì)級(jí)損失的超參數(shù)。
是平衡粗級(jí)和細(xì)級(jí)損失的超參數(shù)。3.4 Decoding
為了避免管道解碼固有的錯(cuò)誤傳播問(wèn)題,本文設(shè)計(jì)了一種解碼算法,使上游任務(wù)(COREF)能夠有效地利用下游任務(wù)信息(RE)。
Entity Cluster Decoding.

本文根據(jù)算法1中描述的層次聚類算法(HAC)來(lái)解碼實(shí)體簇。HAC的核心是計(jì)算兩個(gè)簇![]() 和
和![]() 之間的距離
之間的距離![]() 。將
。將![]() 分解為兩部分:共指消解距離
分解為兩部分:共指消解距離![]() 和關(guān)系距離
和關(guān)系距離![]() 。使用平均鏈接法來(lái)計(jì)算
。使用平均鏈接法來(lái)計(jì)算![]() ,公式如下:
,公式如下:
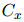 和
和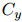 之間的距離
之間的距離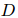 。將分解為兩部分:共指消解距離
。將分解為兩部分:共指消解距離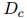 和關(guān)系距離
和關(guān)系距離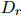 。使用平均鏈接法來(lái)計(jì)算,公式如下:
。使用平均鏈接法來(lái)計(jì)算,公式如下: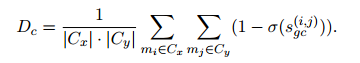
在訓(xùn)練階段,如果![]() 和
和![]() 屬于同一實(shí)體,那么對(duì)于所有的
屬于同一實(shí)體,那么對(duì)于所有的![]() ,真實(shí)的關(guān)系標(biāo)簽
,真實(shí)的關(guān)系標(biāo)簽![]() 和
和![]() 是相同的。因此,對(duì)于一個(gè)訓(xùn)練良好的模型,同一實(shí)體簇中的提及應(yīng)該與其他實(shí)體建立相似的關(guān)系鏈接。本文利用這一線索作為COREF和RE之間的聯(lián)系。讓預(yù)測(cè)的RE標(biāo)簽
是相同的。因此,對(duì)于一個(gè)訓(xùn)練良好的模型,同一實(shí)體簇中的提及應(yīng)該與其他實(shí)體建立相似的關(guān)系鏈接。本文利用這一線索作為COREF和RE之間的聯(lián)系。讓預(yù)測(cè)的RE標(biāo)簽![]() 是一個(gè)
是一個(gè)![]() -維的0-1向量,其中每一位表示一種關(guān)系類型的存在。定義關(guān)系向量
-維的0-1向量,其中每一位表示一種關(guān)系類型的存在。定義關(guān)系向量![]() 為
為
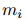 和
和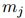 屬于同一實(shí)體,那么對(duì)于所有的
屬于同一實(shí)體,那么對(duì)于所有的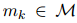 ,真實(shí)的關(guān)系標(biāo)簽
,真實(shí)的關(guān)系標(biāo)簽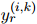 和
和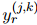 是相同的。因此,對(duì)于一個(gè)訓(xùn)練良好的模型,同一實(shí)體簇中的提及應(yīng)該與其他實(shí)體建立相似的關(guān)系鏈接。本文利用這一線索作為COREF和RE之間的聯(lián)系。讓預(yù)測(cè)的RE標(biāo)簽
是相同的。因此,對(duì)于一個(gè)訓(xùn)練良好的模型,同一實(shí)體簇中的提及應(yīng)該與其他實(shí)體建立相似的關(guān)系鏈接。本文利用這一線索作為COREF和RE之間的聯(lián)系。讓預(yù)測(cè)的RE標(biāo)簽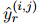 是一個(gè)
是一個(gè)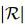 -維的0-1向量,其中每一位表示一種關(guān)系類型的存在。定義關(guān)系向量
-維的0-1向量,其中每一位表示一種關(guān)系類型的存在。定義關(guān)系向量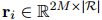 為
為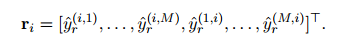
使用每個(gè)簇中的提及對(duì)之間的平均漢明距離作為![]() :
:
: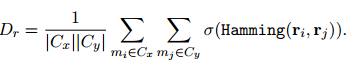
4 Experiments
4.1 Setup
Dataset.
-
DocRED
-
Re-DocRED ( 在Re-DocRED上報(bào)告了第一個(gè)聯(lián)合提取結(jié)果)
Metrics.
......
4.2 Overall Performance
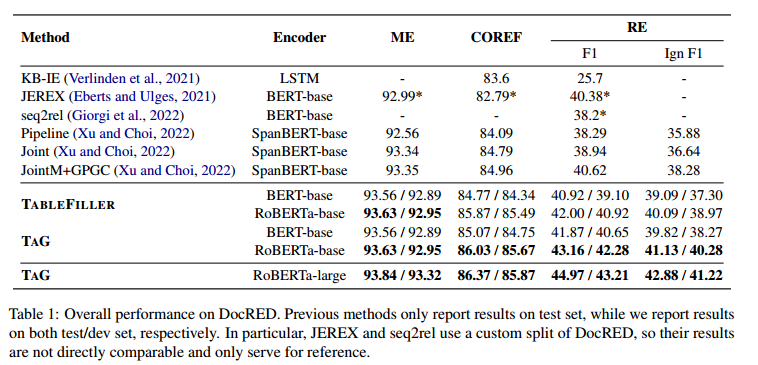
本文對(duì)TAG與其他一些用于聯(lián)合實(shí)體和關(guān)系抽取的基線方法進(jìn)行了比較。早期的方法使用LSTM作為上下文編碼器。在此基礎(chǔ)上,Verlinden等人(2021)提出了KB-IE。該方法將知識(shí)庫(kù)(維基百科和維基數(shù)據(jù))的背景信息集成到聯(lián)合IE模型中。最近的方法通常對(duì)PLM進(jìn)行微調(diào),以學(xué)習(xí)更豐富的特征。Xu等人(2022)實(shí)現(xiàn)了標(biāo)準(zhǔn)的流水線方法,以及具有共享編碼器和聯(lián)合損失的聯(lián)合方法。他們還提出了JointM+GPGC,實(shí)現(xiàn)了從RE到COREF的單向信息流。Eberts等人(2021)提出了JEREX,結(jié)合了多實(shí)例學(xué)習(xí),提高了RE的性能。Giorgi等人(2022)開(kāi)發(fā)了一種帶有復(fù)制機(jī)制的序列到序列模型,seq2rel,性能較差,但效率更高。此外,本文還設(shè)計(jì)了一個(gè)強(qiáng)大的基線方法,TableFiller。它消除了圖形模塊,采用了簡(jiǎn)單的啟發(fā)式解碼算法。它只包含一個(gè)提及提取器,一個(gè)雙仿射編碼器和一個(gè)分類器。
表1比較了TAG與其他基線方法在DocRED上的整體性能。可以觀察到,![]() 略微優(yōu)于先前的方法,建立了一個(gè)有競(jìng)爭(zhēng)力的基礎(chǔ)。這證明了表格填充框架的有效性。
略微優(yōu)于先前的方法,建立了一個(gè)有競(jìng)爭(zhēng)力的基礎(chǔ)。這證明了表格填充框架的有效性。![]() 進(jìn)一步在所有三個(gè)子任務(wù)上一致改進(jìn)了它。按照Xu等人(2022)的做法,本文用同樣大小的更強(qiáng)大的變體
進(jìn)一步在所有三個(gè)子任務(wù)上一致改進(jìn)了它。按照Xu等人(2022)的做法,本文用同樣大小的更強(qiáng)大的變體![]() 替換了
替換了![]() 。
。![]()
![]() 在測(cè)試集上相對(duì)于SOTA顯著提高了1.07的COREF F1和2.54/2.85的RE F1/Ign F1。這表明TAG更能捕捉文檔級(jí)上下文中的重要信息,以及跨不同子任務(wù)的信息。本文還展示了
在測(cè)試集上相對(duì)于SOTA顯著提高了1.07的COREF F1和2.54/2.85的RE F1/Ign F1。這表明TAG更能捕捉文檔級(jí)上下文中的重要信息,以及跨不同子任務(wù)的信息。本文還展示了![]() ,探索了聯(lián)合抽取性能的邊界。它分別在測(cè)試集上達(dá)到了93.84的ME F1,86.37的COREF F1和44.97/42.88的RE F1/Ign F1。
,探索了聯(lián)合抽取性能的邊界。它分別在測(cè)試集上達(dá)到了93.84的ME F1,86.37的COREF F1和44.97/42.88的RE F1/Ign F1。
 略微優(yōu)于先前的方法,建立了一個(gè)有競(jìng)爭(zhēng)力的基礎(chǔ)。這證明了表格填充框架的有效性。
略微優(yōu)于先前的方法,建立了一個(gè)有競(jìng)爭(zhēng)力的基礎(chǔ)。這證明了表格填充框架的有效性。 進(jìn)一步在所有三個(gè)子任務(wù)上一致改進(jìn)了它。按照Xu等人(2022)的做法,本文用同樣大小的更強(qiáng)大的變體
進(jìn)一步在所有三個(gè)子任務(wù)上一致改進(jìn)了它。按照Xu等人(2022)的做法,本文用同樣大小的更強(qiáng)大的變體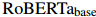 替換了
替換了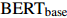 。
。
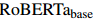 在測(cè)試集上相對(duì)于SOTA顯著提高了1.07的COREF F1和2.54/2.85的RE F1/Ign F1。這表明TAG更能捕捉文檔級(jí)上下文中的重要信息,以及跨不同子任務(wù)的信息。本文還展示了
在測(cè)試集上相對(duì)于SOTA顯著提高了1.07的COREF F1和2.54/2.85的RE F1/Ign F1。這表明TAG更能捕捉文檔級(jí)上下文中的重要信息,以及跨不同子任務(wù)的信息。本文還展示了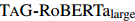 ,探索了聯(lián)合抽取性能的邊界。它分別在測(cè)試集上達(dá)到了93.84的ME F1,86.37的COREF F1和44.97/42.88的RE F1/Ign F1。
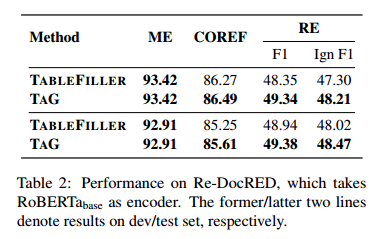
,探索了聯(lián)合抽取性能的邊界。它分別在測(cè)試集上達(dá)到了93.84的ME F1,86.37的COREF F1和44.97/42.88的RE F1/Ign F1。表2顯示了TABLEFILLER和TAG在Re-DocRED上的性能。與DocRED相比,它們?cè)诠仓赶夥矫姹憩F(xiàn)相似,但在關(guān)系抽取方面有很大的提升。這與之前的發(fā)現(xiàn)(Tan等人,2022)一致。關(guān)于架構(gòu)上的差異,TAG在開(kāi)發(fā)集和測(cè)試集上的所有子任務(wù)中都一致優(yōu)于TABLEFILLER,突出了TAG對(duì)于文檔級(jí)聯(lián)合抽取的有效性。
4.3 Analysis on Reasoning Skills
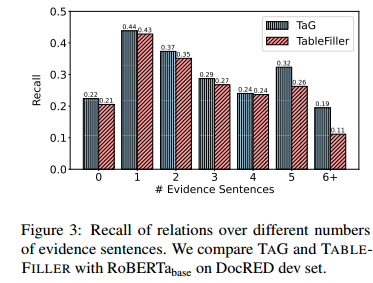
文檔級(jí)關(guān)系抽取需要具備豐富的推理能力,包括常識(shí)推理和邏輯推理(Yao et al., 2019)。證據(jù)句子的數(shù)量是區(qū)分不同推理類型的一個(gè)重要指標(biāo)。為了展示TAG方法的優(yōu)勢(shì),本文將根據(jù)證據(jù)句子的數(shù)量,將關(guān)系召回率可視化在圖3中。對(duì)于沒(méi)有證據(jù)句子的關(guān)系實(shí)例,只能依靠預(yù)訓(xùn)練語(yǔ)言模型的知識(shí)或訓(xùn)練語(yǔ)料庫(kù)中的信息來(lái)推斷。TAG方法在這種情況下比TABLEFILLER方法提高了1.8%的召回率,它們使用的是相同的編碼器,這說(shuō)明了TAG方法具有更強(qiáng)的常識(shí)推理能力。此外,TAG方法也在需要2-4個(gè)證據(jù)句子的關(guān)系上持續(xù)領(lǐng)先于TABLEFILLER方法,這些關(guān)系涉及到共指實(shí)體指稱的區(qū)分或橋接實(shí)體的邏輯推理。這反映了圖模塊和解碼算法對(duì)共指推理和多跳邏輯推理的有效性。最后,TAG方法在需要5個(gè)或更多證據(jù)句子的關(guān)系上顯著提升了召回率(5個(gè)句子為6.0%,6個(gè)以上句子為8.3%),表現(xiàn)出了TAG方法在復(fù)雜邏輯推理上的優(yōu)勢(shì)。
4.4 The Impact of Graph Propagation
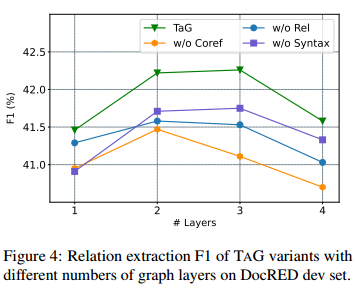
圖4顯示了不同類型的邊對(duì)關(guān)系抽取F1分?jǐn)?shù)的影響,其中-Coref、-Rel和-Syntax分別表示去除共指、關(guān)系和句法邊。從圖中可以看出,所有模型的F1分?jǐn)?shù)在2/3層圖時(shí)達(dá)到最高,然后迅速下降。本文認(rèn)為,層數(shù)越深,有利于信息在更大范圍內(nèi)傳播,但是梯度消失問(wèn)題會(huì)削弱這一優(yōu)勢(shì)。此外,所有消融模型的表現(xiàn)都不如TAG全通道模型,說(shuō)明各種類型的邊都對(duì)提高推理能力有正面作用。層數(shù)和邊的類型對(duì)RE F1有重要影響,而對(duì)共指消解的影響則相對(duì)較小。
4.5 Effectiveness of Decoding
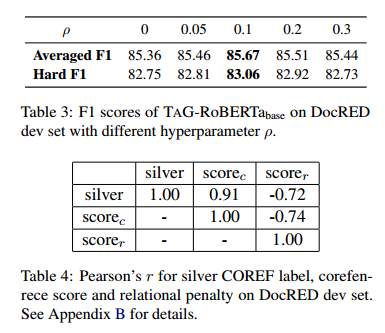
本文提出了一種實(shí)體聚類解碼算法,以提高共指消解的性能。表3展示了在不同的平衡超參數(shù)ρ下,該算法與MUC、B3和CEAF?4的平均F1分?jǐn)?shù)和硬實(shí)體級(jí)F1分?jǐn)?shù)的對(duì)比。結(jié)果表明,當(dāng)ρ = 0.1時(shí),該算法達(dá)到了最優(yōu)的表現(xiàn),兩個(gè)指標(biāo)的F1分?jǐn)?shù)均比原來(lái)提高了0.3%。雖然引入關(guān)系距離Dr使得HAC解碼算法的性能有所提升,但并沒(méi)有達(dá)到預(yù)期的效果。同時(shí),調(diào)整ρ的值對(duì)結(jié)果的影響也不大。這些發(fā)現(xiàn)說(shuō)明,共指消解對(duì)于不同的設(shè)置具有較強(qiáng)的魯棒性。為了探究這種現(xiàn)象的原因,本文對(duì)銀標(biāo)COREF標(biāo)簽和預(yù)測(cè)分?jǐn)?shù)之間的相關(guān)性進(jìn)行了分析,結(jié)果如表4所示。可以看出,關(guān)系懲罰和銀標(biāo)標(biāo)簽之間的相關(guān)性為-0.72,顯著低于共指分?jǐn)?shù)和銀標(biāo)標(biāo)簽之間的相關(guān)性。這種強(qiáng)烈的關(guān)聯(lián)部分解釋了前面的結(jié)果。它也表明,Dr只是一個(gè)較弱的優(yōu)化信號(hào),而過(guò)高的ρ值可能會(huì)降低COREF的性能。
5 Related Works
......
6 Conclusion
本文提出了一種名為TAG的表格到圖生成模型,它能夠從文檔中同時(shí)抽取出實(shí)體和關(guān)系。與傳統(tǒng)方法不同,本文采用了一個(gè)表格填充的框架,將共指消解和關(guān)系抽取兩個(gè)任務(wù)融合在一起,并通過(guò)粗到細(xì)的策略實(shí)現(xiàn)了這兩個(gè)子任務(wù)之間的信息共享。為了避免錯(cuò)誤傳播的問(wèn)題,本文在解碼階段對(duì)HAC算法進(jìn)行了改進(jìn),利用關(guān)系抽取的預(yù)測(cè)結(jié)果來(lái)提升共指消解的效果。在廣泛使用的DocRED數(shù)據(jù)集上的實(shí)驗(yàn)表明,TAG模型顯著優(yōu)于現(xiàn)有的方法。進(jìn)一步的分析也驗(yàn)證了本文模型中各個(gè)模塊的有效性。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)