
《REBEL Relation Extraction By End-to-end Language generation》閱讀筆記
相關(guān)概念:
1.What is natural language understanding (NLU)?
Natural language understanding (NLU) is a branch of artificial intelligence (AI) that uses computer software to understand input in the form of sentences using text or speech. NLU enables human-computer interaction by analyzing language versus just words.
NLU enables computers to understand the sentiments expressed in a natural language used by humans, such as English, French or Mandarin, without the formalized syntax of computer languages. NLU also enables computers to communicate back to humans in their own languages.
A basic form of NLU is called parsing, which takes written text and converts it into a structured format for computers to understand. Instead of relying on computer language syntax, NLU enables a computer to comprehend and respond to human-written text.
One of the main purposes of NLU is to create chat- and voice-enabled bots that can interact with people without supervision. Many startups, as well as major IT companies, such as Amazon, Apple, Google and Microsoft, either have or are working on NLU projects and language models.
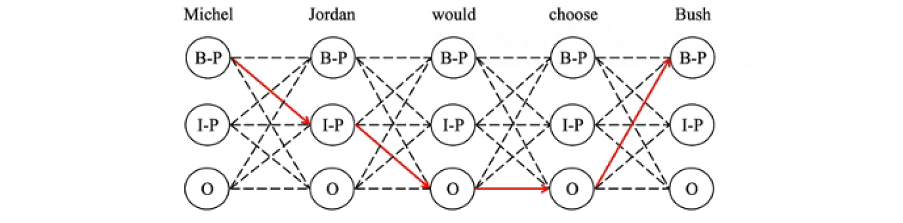
2.What are BIO and BILOU?
BIO and BILOU encodings represent the most popular encoding schemas. The BIO encoding schema is presented in Fig., where B denotes the beginning of a segment, I represents the inside of a segment, including the ending word, and O stands for the word that does not belong to any segment.
(B - 'beginning';I - 'inside';L - 'last';O - 'outside';U - 'unit')
3.What is the exposure bias?
Exposure bias refers to the train-test discrep- ancy that seemingly arises when an autoregres- sive generative model uses only ground-truth contexts at training time but generated ones at test time.
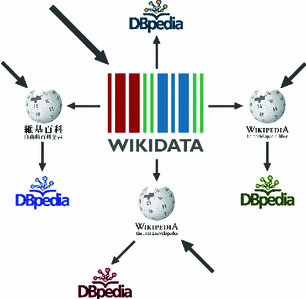
4.What is the difference between Wikidata and DBpedia?
In more detail, DBpedia periodically retrieves information from the different chapters of Wikipedia by using statistic and data mining techniques, whereas Wikidata provides structured data to Wikipedia in real time (see Fig.)
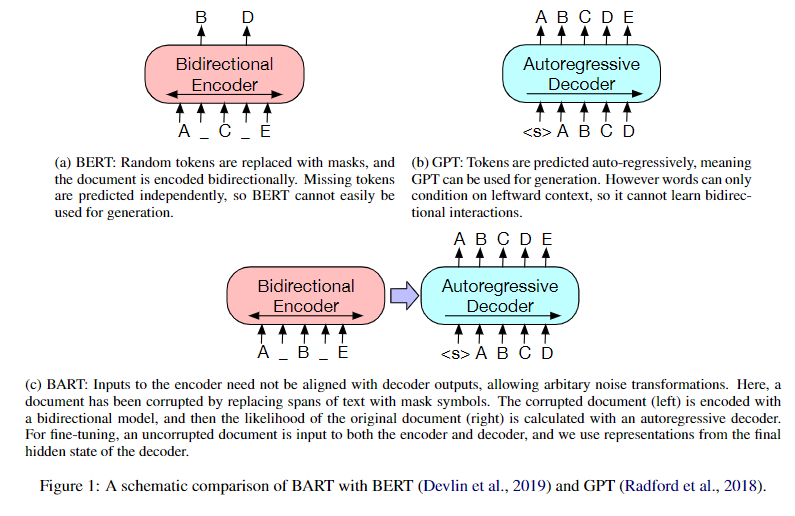
5.BERT、GPT和BART的區(qū)別。
-
BERT模型是僅使用Transformer-Encoder結(jié)構(gòu)的預(yù)訓(xùn)練語言模型(具備雙向語言理解能力的卻不具備做生成任務(wù)的能力)。
-
GPT模型是僅使用Transformer-Decoder結(jié)構(gòu)的預(yù)訓(xùn)練語言模型(擁有自回歸特性的卻不能更好地從雙向理解語言)。
-
BART模型是使用Transformer模型整體結(jié)構(gòu)的預(yù)訓(xùn)練語言模型(在自然語言理解任務(wù)上表現(xiàn)沒有下降,并且在自然語言生成任務(wù)上有明顯的提高)。
6.什么叫做自回歸?
自回歸,全稱自回歸模型(Autoregressive model,簡稱AR模型),是統(tǒng)計上一種處理時間序列的方法, 是用同一變量之前各期的表現(xiàn)情況,來預(yù)測該變量自己本期的表現(xiàn)情況。 因為這不是用來預(yù)測其他變量,而是用來預(yù)測自己,所以叫做自回歸。
摘要
關(guān)系抽取是信息抽取的一個重要任務(wù),它可以從原始文本中抽取出實體之間的關(guān)系三元組,為知識庫、事實檢查和其他應(yīng)用提供支持。然而,這通常需要一個多步驟的流程,可能會導(dǎo)致錯誤的累積或者只能處理少數(shù)幾種關(guān)系類型。為了解決這些問題,本文提出了一個端到端的關(guān)系抽取模型REBEL,它是一個自回歸的seq2seq模型。seq2seq模型已經(jīng)在語言生成和NLU任務(wù)上表現(xiàn)出優(yōu)異的性能,例如實體鏈接等。本文展示了如何通過將關(guān)系三元組轉(zhuǎn)換為一個文本序列來簡化關(guān)系抽取的問題,并且使用BART作為seq2seq模型的基礎(chǔ),使得REBEL能夠抽取超過200種不同的關(guān)系類型。
1 Introduction
關(guān)系抽取:
-
從給定的文本中提取實體之間的語義關(guān)系,把非結(jié)構(gòu)化原始文本轉(zhuǎn)換為結(jié)構(gòu)化數(shù)據(jù),組成關(guān)系三元組(ei,rij,ej),這些數(shù)據(jù)可用于一系列下游任務(wù)和應(yīng)用程序,例如知識庫的構(gòu)建等。
傳統(tǒng)關(guān)系抽取被視為一個兩步問題:
-
使用命名實體識別(NER)從文中抽取實體。
-
使用關(guān)系分類(RC)判斷提取的實體之間是否存在關(guān)系。
傳統(tǒng)關(guān)系抽取所面臨的問題:
-
識別哪些實體真正共享一個關(guān)系可能會成為瓶頸,因為這需要額外的步驟,例如負(fù)抽樣和注釋等。
端到端方法是一個多任務(wù)的方法,可以同時處理上述兩個任務(wù),即讓一個模型同時在兩個目標(biāo)上進(jìn)行訓(xùn)練。
端到端方法所面臨的問題:
-
通常比較復(fù)雜,有一些專注于任務(wù)的元素,需要根據(jù)關(guān)系或?qū)嶓w類型的數(shù)量進(jìn)行適應(yīng)。
-
不夠靈活,無法處理不同性質(zhì)的文本(句子級別與文檔級別)或領(lǐng)域。
-
通常需要很長的訓(xùn)練時間,以便對新數(shù)據(jù)進(jìn)行微調(diào)。
本文提出了一種將關(guān)系抽取視為seq2seq任務(wù)的自回歸方法(REBEL, Relation Extraction By End-to-end Language generation),以及一個利用自然語言推理模型得到的大規(guī)模遠(yuǎn)程監(jiān)督數(shù)據(jù)集(REBEL)。REBEL是一個簡單而有效的端到端關(guān)系抽取模型,它將三元組作為文本序列來處理。它利用一個大的銀色數(shù)據(jù)集對一個Transformer(BART)進(jìn)行預(yù)訓(xùn)練,然后在幾個周期內(nèi)微調(diào),在多個RE基準(zhǔn)上取得最佳的性能。它的簡單性也使得它能夠靈活地適應(yīng)不同的領(lǐng)域和更長的文本。由于在微調(diào)階段仍然使用預(yù)訓(xùn)練的模型權(quán)重,因此不需要重新訓(xùn)練模型特定的組件,節(jié)省了訓(xùn)練時間。此外,REBEL不僅可以用于關(guān)系抽取,還可以用于關(guān)系分類,達(dá)到與其他方法相當(dāng)?shù)慕Y(jié)果。本文提供了REBEL的模型代碼和預(yù)訓(xùn)練權(quán)重,它可以抽取超過200種關(guān)系類型,也可以很容易地在新的RE和RC數(shù)據(jù)集上進(jìn)行微調(diào)。
2 Related work
2.1 Relation Extraction
關(guān)系抽取與關(guān)系分類的定義:
-
RC(Relation Classification):從給定上下文中兩個實體之間進(jìn)行關(guān)系分類。
-
RE(Relation Extraction ):從原始文本中提取實體之間關(guān)系三元組,沒有給定實體,也稱為端到端關(guān)系提取。
關(guān)系抽取的方法:
-
流水線技術(shù)(pipeline):早期的工作利用CNN、LSTM挖掘語義關(guān)系,并對給定的實體進(jìn)行關(guān)系分類。 目前已有工作開始使用transformer模型。
-
早期的端到端方法:對輸入文本中所有單詞對進(jìn)行分類,使用表格表示或表格填充,將任務(wù)轉(zhuǎn)化為填充一個表格(關(guān)系)的格子,其中行和列是輸入中的單詞。
-
利用聯(lián)合訓(xùn)練的流水線技術(shù):聯(lián)合訓(xùn)練NER和RC,比如Eberts and Ulges (2021)使用了一個流水線方法(文檔級RE),聯(lián)合訓(xùn)練了一個多任務(wù)模型,利用共指消解在實體級別而不是提及級別進(jìn)行操作。
關(guān)系抽取是一個重要的任務(wù),但是由于缺乏統(tǒng)一的基準(zhǔn)和任務(wù)定義,導(dǎo)致了不同的數(shù)據(jù)集和評估方法,使得模型之間的比較變得困難。Taillé等人(2020)分析了目前存在的不同問題,并且嘗試建立一個RE的評估框架,以實現(xiàn)系統(tǒng)之間的公平對比。本文將遵循他們的指導(dǎo),除非特別說明,否則使用嚴(yán)格的評估,即只有當(dāng)頭實體和尾實體以及關(guān)系和實體類型(如果數(shù)據(jù)集中有的話)均被正確抽取(即完全與注釋重疊)時,才認(rèn)為一個關(guān)系是正確的。
2.2 Seq2seq and Relation Extraction
流水線技術(shù)和表格填充方法面臨的挑戰(zhàn):
-
它們通常假設(shè)每個實體對之間最多有一種關(guān)系類型,而且多分類方法不考慮其他的預(yù)測。例如,它們可能預(yù)測同一個頭實體有兩個“出生日期”,或者預(yù)測一些不兼容的關(guān)系。此外,它們需要推斷所有可能的實體對,這可能會變得計算代價昂貴。
使用Seq2seq方法來進(jìn)行RE(Zeng等人,2018, 2020; Nayak和Ng, 2020)可以有效地解決一些問題。這些方法可以利用解碼機制來避免重復(fù)輸出相同的實體,以及根據(jù)之前的預(yù)測來調(diào)整未來的解碼,從而隱含地消除不一致的預(yù)測。
Seq2seq方法存在的問題:
-
Zhang等人(2020)指出,將三元組轉(zhuǎn)換為文本序列需要一個線性化的過程,而這個過程可能是有些隨意的,比如按照字母順序。Zeng等人(2019)對這個問題進(jìn)行了研究,他們使用了強化學(xué)習(xí)來確定三元組的抽取順序。
-
由于在訓(xùn)練過程中,預(yù)測總是依賴于正確的輸出,seq2seq方法會受到暴露偏差的影響。Zhang等人(2020)提出了一個樹解碼的方法,可以緩解這個問題,同時仍然保持了seq2seq方法的自回歸性質(zhì)。
seq2seq Transformer模型,例如BART(Lewis等人,2020)或T5(Raffel等人,2020),已經(jīng)被應(yīng)用于NLU任務(wù),如實體鏈接(Cao等人,2021)、AMR解析(Bevilacqua等人,2021)、語義角色標(biāo)注(Blloshmi等人,2021)或詞義消歧(Bevilacqua等人,2020)等。通過將這些任務(wù)重新定義為seq2seq任務(wù),這些模型不僅展現(xiàn)了優(yōu)異的性能,還體現(xiàn)了seq2seq模型的靈活性,它們不需要依賴于預(yù)先定義的實體集合,而是利用解碼機制,可以輕松地處理新的或未見過的實體。
本文提出了一個編碼器-解碼器的模型,它可以解決一些之前的seq2seq方法在RE上遇到的問題。它利用注意力機制來處理長距離的依賴和對之前解碼的輸出的關(guān)注(或忽略)。它還設(shè)計了一種新的三元組線性化方法,保證了三元組的順序是一致的,使得模型能夠更好地利用編碼的輸入和解碼的輸出。
3 REBEL
-
使用BART-large(Lewis et al., 2020)作為基礎(chǔ)模型,將關(guān)系抽取和分類視為一個生成任務(wù),輸出輸入文本中存在的每個三元組。
-
輸入:編碼器接收輸入數(shù)據(jù)序列,即數(shù)據(jù)集中的文本。
-
輸出:解碼器產(chǎn)生輸出數(shù)據(jù)序列,即線性化的三元組。
-
預(yù)訓(xùn)練模型:BART。
-
損失函數(shù):Cross-Entropy。
在一個翻譯任務(wù)中,teacher forcing利用兩種語言的文本對,通過將解碼的文本依賴于輸入。在訓(xùn)練時,編碼器接收一種語言的文本,解碼器接收另一種語言的文本,在每個位置輸出下一個token的預(yù)測。
在本文的方法中,將一個包含實體以及它們之間隱含的關(guān)系的原始輸入句子,翻譯為一組明確指代這些關(guān)系的三元組。因此,需要將三元組表達(dá)為一個token序列,由模型進(jìn)行解碼。本文設(shè)計了一種可逆的線性化方法,使用特殊的token,使得模型能夠以三元組的形式輸出文本中的關(guān)系,同時最小化需要解碼的token的數(shù)量。
如果x是輸入句子,y是根據(jù)第3.1節(jié)中解釋的方法將x中的關(guān)系線性化的結(jié)果,那么REBEL的任務(wù)是給定x,自回歸地生成y:
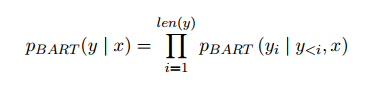
通過在這樣一個任務(wù)上微調(diào)BART,使用與摘要或機器翻譯中相同的交叉熵?fù)p失,最大化給定輸入文本生成線性化三元組的對數(shù)似然。
3.1 Triplets linearization
-
<triplet>標(biāo)記了一個新的三元組的開始,后面跟著一個新的頭實體。
-
<subj>標(biāo)記了頭實體的結(jié)束和尾實體的開始。
-
<obj>標(biāo)記了尾實體的結(jié)束和頭實體與尾實體之間關(guān)系的開始。
本文采用了一種新的三元組線性化方法,它按照實體在輸入文本中出現(xiàn)的順序來排序和分組三元組。對于每個頭實體,先輸出它與文本中第一個出現(xiàn)的尾實體之間的關(guān)系,然后輸出它與其他尾實體之間的關(guān)系。不需要每次都重復(fù)頭實體的名字,這樣可以縮短解碼文本的長度。當(dāng)一個頭實體的所有關(guān)系都輸出完畢后,開始輸出文本中下一個頭實體的關(guān)系,直到所有的三元組都被線性化。
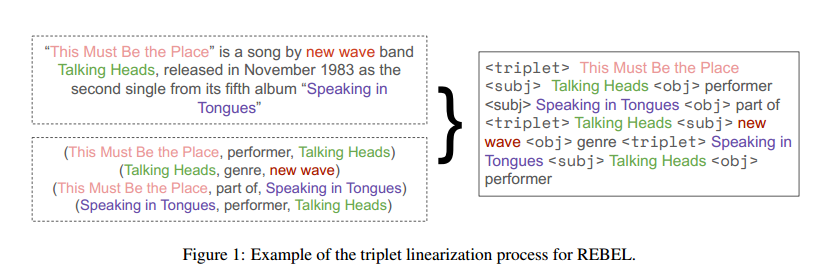

如上圖所示,同一個頭實體“This Must Be the Place”對應(yīng)兩個尾實體、兩個關(guān)系。
依據(jù)本文的方法,可以通過特殊的token來恢復(fù)原始的三元組。在RE數(shù)據(jù)集中,三元組中不僅包含實體,還包含實體類型,需要模型一起預(yù)測。為了實現(xiàn)這一點,可以對算法1做一些修改,用不同的token來表示不同的實體類型,如<per>或<org>,分別代表人或組織,來替換<subj>和<obj>,并用它們來標(biāo)記實體的類型。
3.2 REBEL dataset
自回歸變換模型,如BART或T5,在不同的生成任務(wù)(如翻譯或摘要),表現(xiàn)得很好,但一方面,它們需要大量的數(shù)據(jù)來訓(xùn)練;另一方面,端到端的關(guān)系抽取數(shù)據(jù)集是稀缺的,通常很小。
T-REx數(shù)據(jù)集(Elsahar 2018):為了解決大規(guī)模的RE數(shù)據(jù)集的缺乏,一種方法是從DBpedia摘要中抽取實體和關(guān)系,但是這種方法的注釋質(zhì)量有些問題。首先,由于使用了一個過時的實體鏈接工具(Daiber等人,2013),導(dǎo)致了實體消歧的錯誤。這樣就會影響到基于這些實體的關(guān)系抽取,造成關(guān)系的缺失或錯誤。其次,這種方法大多數(shù)情況下是通過假設(shè)兩個實體在文本中的共現(xiàn)就意味著它們之間存在關(guān)系,而這種假設(shè)并不一定成立。
REBEL數(shù)據(jù)集:本文通過擴展他們的流程來克服這些問題,創(chuàng)建了一個大的銀色數(shù)據(jù)集,用于REBEL的預(yù)訓(xùn)練。首先,使用wikiextractor (Attardi, 2015)提取Wikipedia摘要,即每個Wikipedia頁面目錄前的部分。然后使用wikimapper,將文本中作為超鏈接的實體、日期和值,鏈接到Wikidata實體。接著,從Wikidata中抽取出這些實體之間存在的所有關(guān)系,作為三元組的標(biāo)注。該流程可以使用任何語言的Wikipedia dump,支持多語言的關(guān)系抽取;使用多核處理和SQL來處理Wikidata dump,避免了內(nèi)存問題,提高了抽取效率;使用了最新的實體鏈接工具,減少了實體消歧的錯誤,提高了關(guān)系抽取的質(zhì)量。
從Wikidata中抽取關(guān)系的方法并不總是能夠反映文本中的真實關(guān)系。Elsahar等人(2018)認(rèn)為這種方法可以得到高質(zhì)量的數(shù)據(jù),但是實際上,對于一些常見的關(guān)系,如國家或配偶,這種方法會產(chǎn)生很多噪聲。本文也發(fā)現(xiàn)了這種方法的一些注釋問題。本文利用一個預(yù)訓(xùn)練的RoBERTa (Liu等人,2019)自然語言推理(NLI)模型來解決這個問題,并使用它來過濾那些不是由Wikipedia文本所蘊含的關(guān)系。對于每個三元組,輸入包含兩個實體的Wikipedia摘要中的文本以及三元組(主語+關(guān)系+賓語,用<sep>標(biāo)記分隔)。
本文的數(shù)據(jù)抽取流程雖然不是完美的,可能會保留一些噪聲的關(guān)系,或者遺漏一些文本中存在的關(guān)系,但是它可以自動地收集大量的實體和關(guān)系作為銀色數(shù)據(jù)集,這對于訓(xùn)練本文的模型是足夠的。本文的RE數(shù)據(jù)集創(chuàng)建工具被命名為cRocoDiLe。
4 Experimental Setup
數(shù)據(jù)集:4個RE數(shù)據(jù)集;1個RC數(shù)據(jù)集;預(yù)訓(xùn)練數(shù)據(jù)集。
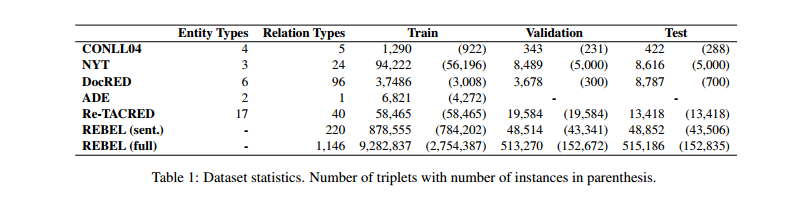
評估指標(biāo):Recall、Precision、micro-F1。評估策略參考Taillé et al. (2020)。
5 Results
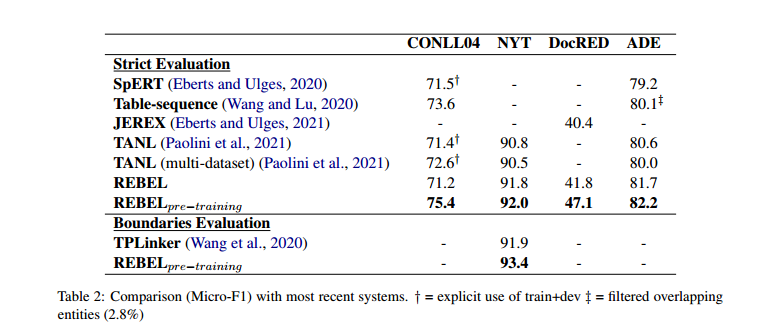
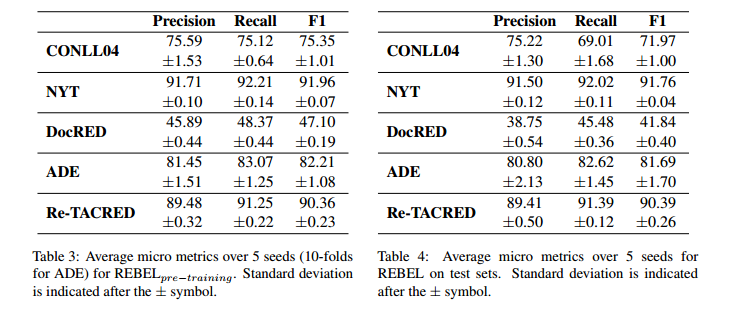
使用有預(yù)訓(xùn)練的REBEL比沒有使用預(yù)訓(xùn)練的REBEL效果好。
在句子級上進(jìn)行預(yù)訓(xùn)練的REBEL在DocRED上的表現(xiàn)仍然具有競爭力。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號