【Python】模擬登錄上海西南某高校校園網(wǎng) (jaccount)
好久沒寫東西了,最近學習了一下模擬登錄,以校園網(wǎng)為例,作一記錄。
去年的時候寫過一篇模擬登錄的文章,用的是登錄后的cookies,這種操作比較傻瓜,也不智能,不夠自動化,本質還是手動登錄。
這次我嘗試把登錄過程用python進行,預先提供賬號、密碼即可。
眾所周知(本校兄弟姐妹),本校所有身份認證現(xiàn)已完全由jaccount進行,只要通過了這一層驗證,就相當于登錄成功了。

以登錄校園郵箱為例,先分析一下登錄流程:
- 輸入郵箱網(wǎng)址
mail....edu.cn - 跳轉到jaccount驗證頁
- 輸入賬號、密碼、驗證碼登錄
- 跳轉回郵箱頁面,登錄完成
難點分析:
- 跳轉過程中有哪些數(shù)據(jù)需要攜帶?
- 驗證碼如何獲取?如何識別?
剛開始想用requests解決所有問題,直到試了許多次也未能成功解決登錄跳轉的問題,只好放棄,轉用更簡單的selenium。selenium是一款可見即可得的自動化測試工具,在爬蟲上用起來十分方便,它通過模擬人實際的操作實現(xiàn)對瀏覽器的控制,比如輸入、點擊、拖動等事件。
依次按照上述流程,進行編碼(完整代碼見文末):
步驟一、打開瀏覽器,輸入郵箱網(wǎng)址
browser.get('https://mail.sjtu.edu.cn')
此時,會彈出瀏覽器,自動打開該網(wǎng)頁,當然,也會自動跳轉到jaccount驗證頁面。
步驟二、輸入賬號、密碼、驗證碼
賬號、密碼都比較好搞定,自己預設好就行了。然后通過開發(fā)者工具定位文本框位置,由以下命令可以輸入到相應的文本框內。

input_user = browser.find_element_by_id('user')
input_user.send_keys(user)
input_pass = browser.find_element_by_id('pass')
input_pass.send_keys(pswd)
麻煩的還是驗證碼。首先要找到驗證碼圖片源,再通過OCR工具進行識別。
通過分析,發(fā)現(xiàn)驗證碼是由https://jaccount.sjtu.edu.cn/jaccount/captcha這個站點生成的。要獲取到正確的驗證碼,需要傳入相應的uuid參數(shù),以及cookies。OCR工具目前比較好用的是tesseract,所幸我們這個驗證碼比較簡單,識別率很高。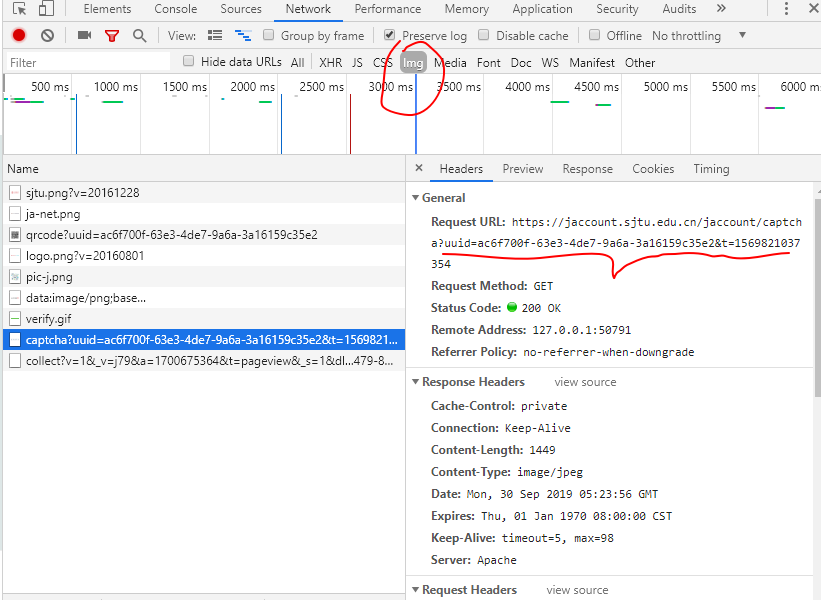
通過對源碼進行搜索,終于找到uuid了,就在這個登錄表單里,通過xpath獲取一下,拿到value
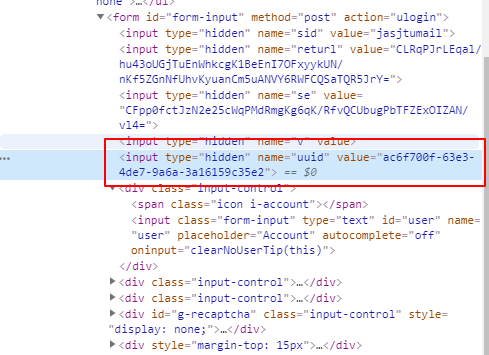
uuid = browser.find_element_by_xpath('//form/input[@name="uuid"]')
params = {
'uuid': uuid.get_attribute('value')
}
此處為了便捷,我使用requests進行驗證碼下載,而selenium的cookies也和requests不同,selenium是比較完整的信息,如下:
[{'domain': 'mail.sjtu.edu.cn', 'httpOnly': True, 'name': 'JSESSIONID', 'path': '/', 'secure': False, 'value': '12l9qesot3vw61sz8brl8i74ir'}, {'domain': 'mail.sjtu.edu.cn', 'httpOnly': True, 'name': 'ZM_AUTH_TOKEN', 'path': '/', 'secure': False, 'value': '0_7b1bfd5665cabda2816d04d7e4f8438022c54538_69643d33363a35373935373238652d346539362d346434372d383837332d6331666264356130343337643b6578703d31333a313536393836323130303632323b747970653d363a7a696d6272613b753d313a613b7469643d31303a323134323231343838363b76657273696f6e3d31333a382e382e395f47415f333031393b'}, {'domain': '.sjtu.edu.cn', 'expiry': 1569818955, 'httpOnly': False, 'name': '_gat', 'path': '/', 'secure': False, 'value': '1'}, {'domain': '.sjtu.edu.cn', 'expiry': 1569905295, 'httpOnly': False, 'name': '_gid', 'path': '/', 'secure': False, 'value': 'GA1.3.452166840.1569818896'}, {'domain': '.sjtu.edu.cn', 'expiry': 1632890895, 'httpOnly': False, 'name': '_ga', 'path': '/', 'secure': False, 'value': 'GA1.3.1066557857.1569818896'}]
而我們傳入requests的只需要cookie名字和值即可,故可通過字典推導式,生成requests所需的cookies:
cookies = browser.get_cookies()
cookies = {i["name"]: i["value"] for i in cookies}
這樣一來就可以獲取驗證碼了,
response = requests.get(captcha_url, cookies=cookies, params=params)
with open('img.jpeg', 'wb+') as f:
f.writelines(response)
這樣驗證碼就被保存到img.jpeg文件中,識別驗證碼只需要以下兩行代碼即可:
image = Image.open('img.jpeg')
code = pytesseract.image_to_string(image)
最后,輸入驗證碼,并確定,就可以跳轉回登錄后的郵箱界面。
input_code = browser.find_element_by_id('captcha')
input_code.send_keys(code)
input_code.send_keys(Keys.ENTER)
如果你用的是可視化瀏覽器,這時候就可以看到自己的郵箱了。
可以再看看當前的url,是不是已經(jīng)跳轉回郵箱的url了呢?
print(browser.current_url)
成功登錄之后,要爬取什么東西都很簡單了,比如課程表、好大學在線的課件等等~
完整代碼
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import requests
import pytesseract
from PIL import Image
browser = webdriver.Chrome()
url = "https://mail.sjtu.edu.cn/"
captcha_url = "https://jaccount.sjtu.edu.cn/jaccount/captcha"
user = 'ben'
pswd = '********'
def get_captcha(captcha_url, cookies, params):
response = requests.get(captcha_url, cookies=cookies, params=params)
with open('img.jpeg', 'wb+') as f:
f.writelines(response)
try:
browser.get(url)
cookies = browser.get_cookies()
cookies = {i["name"]: i["value"] for i in cookies}
uuid = browser.find_element_by_xpath('//form/input[@name="uuid"]')
params = {
'uuid': uuid.get_attribute('value')
}
get_captcha(captcha_url, cookies, params)
image = Image.open('img.jpeg')
code = pytesseract.image_to_string(image)
print(code)
input_user = browser.find_element_by_id('user')
input_user.send_keys(user)
input_pass = browser.find_element_by_id('pass')
input_pass.send_keys(pswd)
input_code = browser.find_element_by_id('captcha')
input_code.send_keys(code)
input_code.send_keys(Keys.ENTER)
print(browser.current_url)
finally:
print('success!')

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號