HTTP權威指南閱讀筆記四:連接管理
HTTP通信是由TCP/IP承載的,HTTP緊挨著TCP,位于其上層,所以HTTP事務的性能很大程度上取決于底層TCP通道的性能。
HTTP事務的時延
如圖:
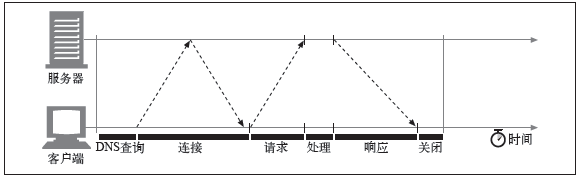
HTTP事務的時延有以下幾種主要原因。
(1)客戶端首先需要根據URI確定Web服務器的IP地址和端口號。如果最近沒有對URI中的主機名進行訪問,通過DNS解析系統將URI中的主機名轉換成一個IP地址可能要花費數十秒的時間。
(2)接下來,客戶端會向服務器發送一條TCP連接請求,并等待服務器回送一個請求接受應答。每條新的TCP連接都會有連接建立時延。這個值通常最多只有一兩秒種,但如果有數百個HTTP事務的話,這個值會快速地疊加上去。
(3)一旦連接建立起來了,客戶端就會通過新建立的TCP管道來發送HTTP請求。數據到達時,Web服務器會從TCP連接中讀取請求報文,并對請求進行處理。因特網傳輸請求報文,以及服務器處理請求報文都需要時間。
(4)然后,Web服務器會回送HTTP響應,這也需要花費時間。
這些TCP網絡時延的大小取決于硬件速度、網絡和服務器的負載,請求和響應報文的尺寸,以及客戶端和服務器之間的距離。TCP協議的技術復雜性也會對時延產生巨大的影響。
性能聚焦區域
會對HTTP產生影響、最常見的TCP相關時延包括:
(1)TCP連接建立握手:HTTP事務越小,TCP連接建立握手所花時間占的比例就越大。
(2)TCP慢啟動擁塞控制:TCP連接會隨著時間進行自我“調諧”,起初會限制連接的最大速度,如果數據傳輸成功,會隨著時間的推移提高傳輸速度,主要用于防止因特網的突然過載和擁塞。由于存在這種擁塞控制特性,所以新連接的傳輸速度會比已經交換過一定量數據的、“已調諧”連接慢一些。
(3)數據聚集的Nagle算法:TCP有一個數據流接口,應用程序可以通過它將任意尺寸的數據放入TCP棧中——即使一次只放一個字節也可以。所以如果TCP發送了大量包含少數數據的分組,網絡的性能就會嚴重下降。Nagle算法試圖在發送一個分組前,將大量TCP數據綁定在一起,以提高網絡效率。這個算法會引發幾種HTTP性能問題。首先,小的HTTP報文可能無法填滿一個分組,可能會因為等待那些永遠不會到來的額外數據而產生時延。其次,Nagle算法與延遲確認之間的交互存在問題——Nagle算法會阻止數據的發送,直到有確認的分組抵達為止,但確認分組自身會被延遲確認算法延遲100~200毫秒。HTTP應用程序常常會在自己的棧中設置參數TCP_NODEALY,禁止Nagle算法,提高性能。如果要這么做的話,一定要確保會向TCP寫入大塊的數據,這樣就不會產生一堆小分組。
(4)用于捎帶確認的TCP延遲確認算法:每個TCP段都有一個序列號和數據完整性校驗和。每個段的接收者收到完整的段時,都會向發送者回送小的確認分組。如果發送者沒有在指定的窗口時間內收到確認信息,發送者就認為分組已被破壞或損毀,并重發數據。由于確認報文很小,所以TCP允許在發往相同方向的輸出數據分組中對其進行“捎帶”。為了增加確認報文找到同向傳輸數據分組的可能性,很多TCP棧都實現了一種“延遲確認”算法。延遲確認算法會在一個特定的窗口時間(通常是100~200毫秒)內將輸出確認存放在緩沖區中,以錄找能夠捎帶它的輸出數據分組。如果在那個時間段內沒有輸出數據分組,就將確認信息放在單獨的分組中傳送。但是HTTP具有雙峰特征的請求——應答行為降低了捎帶信息的可能。當希望有相反方向回傳分組的時候,偏偏沒有那么多。通常,延遲確認算法會引入相當大的時延。根據所使用操作系統的不同,可以調整或禁止延遲確認算法。
(5)TIME_WAIT時延和端口耗盡:當某個TCP端點關閉TCP連接時,會在內存中維護一個小的控制塊,用來記錄最近所關閉連接的IP地址和端口號。這類信息只會維持一小段時間,通常是所估計的最大分端使用期的兩倍(稱為2MSL,通常為2分鐘)左右,以確保在這段時間內不會創建具有相同地址和端口號的新連接。實際上這個算法可以防止在兩分鐘內創建、關閉并重新創建兩個具有相同IP 地址和端口號的連接。由于可用源端口的數量有限(比如60000個),而且在2MSL秒(比如120秒)內連接是無法重用的,連接速率就被限定在了60000/120 = 500 次/秒。超過這個數字,就會因端口耗盡而失敗。要修正這個問題,可以把2MSL設置為一個較小的值,或增加客戶端負載生成機器的數量,或確保客戶端和服務器在循環使用幾個虛擬IP 地址以增加更多的連接組合。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號