
系統(tǒng)復雜度之【高性能】
今天我們來談一談系統(tǒng)復雜度的根源之【高性能】
對性能的不懈追求一直是人類科技持續(xù)發(fā)展的核心動力。例如計算機,從電子管計算機到晶體管計算機,再到集成電路計算機,運算性能從每秒幾次提高到每秒幾億次。然而,隨著性能的提升,相應的方法和系統(tǒng)復雜度也逐漸增加。現(xiàn)代計算機CPU集成了數(shù)億顆晶體管,其邏輯復雜度和制造難度與最初的晶體管計算機相比,已經(jīng)有了天壤之別。
軟件系統(tǒng)也呈現(xiàn)出類似的現(xiàn)象。近幾十年來,軟件系統(tǒng)性能得到了飛速發(fā)展,從最初的計算機僅能進行簡單科學計算,到如今Google能支撐每秒幾萬次的搜索。與此同時,軟件系統(tǒng)規(guī)模從單臺計算機擴展到上萬臺計算機;從最初的單用戶單任務的字符界面DOS操作系統(tǒng),發(fā)展到現(xiàn)在的多用戶多任務的Windows 10圖形操作系統(tǒng)。
當然,技術進步帶來的性能提升,并不一定伴隨著復雜度的增長。例如,硬件存儲從紙帶、磁帶、磁盤發(fā)展到SSD,并未明顯增加系統(tǒng)復雜度。這是因為新技術逐步淘汰舊技術,我們可以直接使用新技術,而無需擔心系統(tǒng)復雜度的提升。只有那些不是用來取代舊技術,而是開拓全新領域的技術,才會給軟件系統(tǒng)帶來復雜性,因為軟件系統(tǒng)在設計時需要在這些技術之間進行判斷、選擇或組合。就像汽車的發(fā)明不能取代火車,飛機的出現(xiàn)也不能完全替代火車,所以在我們出行時,需要權衡選擇汽車、火車還是飛機,這個選擇過程相對復雜,涉及價格、時間、速度、舒適度等諸多因素。
軟件系統(tǒng)中性能提升帶來的復雜度主要體現(xiàn)在兩個方面:一方面是單臺計算機內(nèi)部為實現(xiàn)高性能所產(chǎn)生的復雜度;另一方面是多臺計算機集群為實現(xiàn)高性能所引發(fā)的復雜度。
單機復雜度
計算機內(nèi)部復雜度的關鍵在于操作系統(tǒng)。計算機性能的發(fā)展基本上是由硬件,尤其是CPU性能的發(fā)展所驅動的。著名的“摩爾定律”預測CPU處理能力每18個月翻一番;而充分發(fā)揮硬件性能的關鍵便是操作系統(tǒng)。因此,操作系統(tǒng)也是隨著硬件的發(fā)展而發(fā)展的,作為軟件系統(tǒng)的運行環(huán)境,操作系統(tǒng)的復雜度直接決定了軟件系統(tǒng)的復雜度。
操作系統(tǒng)與性能最相關的便是進程和線程。最早的計算機實際上是沒有操作系統(tǒng)的,僅具有輸入、計算和輸出功能。用戶輸入一個指令后,計算機完成操作。然而,大部分時間計算機都在等待用戶輸入指令,這種處理性能顯然是低效的,因為人的輸入速度遠不及計算機的運算速度。
為解決手工操作帶來的低效,批處理操作系統(tǒng)應運而生。簡單來說,批處理是先將要執(zhí)行的指令預先編寫好(寫到紙帶、磁帶、磁盤等),形成一個指令清單,即我們常說的“任務”。將任務交給計算機執(zhí)行,批處理操作系統(tǒng)負責讀取“任務”中的指令清單并進行處理。這樣,計算機執(zhí)行過程中無需等待人工操作,從而大大提高性能。
盡管批處理程序大大提升了處理性能,但它存在一個明顯的缺點:計算機一次只能執(zhí)行一個任務。如果某個任務需要從I/O設備(例如磁帶)讀取大量數(shù)據(jù),在I/O操作過程中,CPU實際上是空閑的,而這段空閑時間本可以用于其他計算。
為進一步提升性能,人們發(fā)明了“進程”,將一個任務對應到一個進程,每個任務都有自己獨立的內(nèi)存空間,進程間互不相關,由操作系統(tǒng)進行調(diào)度。當時的CPU尚無多核和多線程概念,為實現(xiàn)多進程并行運行,采用了分時方式,即將CPU時間劃分成許多片段,每個片段僅執(zhí)行某個進程中的指令。盡管從操作系統(tǒng)和CPU角度看仍為串行處理,但由于CPU處理速度極快,用戶感覺上是多進程并行處理。
多進程要求每個任務都有獨立的內(nèi)存空間,進程間互不相關,但從用戶角度看,若兩個任務在運行過程中能夠通信,則任務設計會更加靈活高效。為解決這個問題,各種進程間通信方式應運而生,包括管道、消息隊列、信號量、共享存儲等。
多進程使多任務能夠并行處理,但仍存在缺陷,單個進程內(nèi)部僅能串行處理。實際上,許多進程內(nèi)部的子任務并不要求嚴格按時間順序執(zhí)行,也需要并行處理。例如,一個餐館管理進程,排位、點菜、買單、服務員調(diào)度等子任務必須并行處理,否則可能出現(xiàn)因某客人買單時間較長(如信用卡刷不出來)而導致其他客人無法點菜的情況。為解決這一問題,人們發(fā)明了線程,線程是進程內(nèi)部的子任務,但這些子任務共享同一份進程數(shù)據(jù)。為保證數(shù)據(jù)的正確性,又發(fā)明了互斥鎖機制。有了多線程后,操作系統(tǒng)調(diào)度的最小單位變成了線程,而進程則成為操作系統(tǒng)分配資源的最小單位。
盡管多進程多線程讓多任務并行處理的性能大大提升,但本質上仍為分時系統(tǒng),無法實現(xiàn)時間上真正的并行。解決這一問題的方法是讓多個CPU同時執(zhí)行計算任務,從而實現(xiàn)真正意義上的多任務并行。目前這樣的解決方案有三種:SMP(對稱多處理器結構)、NUMA(非一致存儲訪問結構)和MPP(海量并行處理結構)。其中,SMP是我們最常見的,當前流行的多核處理器即采用SMP方案。
如今的操作系統(tǒng)發(fā)展已經(jīng)相當成熟,若要完成一個高性能的軟件系統(tǒng),需要考慮多進程、多線程、進程間通信、多線程并發(fā)等技術點。然而,這些技術并非最新的就是最好的,也不是非此即彼的選擇。在進行架構設計時,需要投入大量精力來結合業(yè)務進行分析、判斷、選擇和組合,這一過程同樣頗為復雜。舉一個簡單的例子:Nginx可以采用多進程或多線程,JBoss則采用多線程;Redis采用單進程,而Memcache則采用多線程,盡管這些系統(tǒng)都實現(xiàn)了高性能,但其內(nèi)部實現(xiàn)卻大相徑庭。
集群的復雜度
盡管計算機硬件性能迅速發(fā)展,但與業(yè)務發(fā)展速度相比,仍顯得力不從心,特別是進入互聯(lián)網(wǎng)時代后,業(yè)務發(fā)展速度遠超硬件發(fā)展速度。例如:
2016年“雙11”支付寶每秒峰值達到12萬筆支付。
2017年春節(jié)微信紅包收發(fā)紅包每秒達到76萬個。
要支持如支付和紅包等復雜業(yè)務,單機性能無論如何都無法支撐。因此,必須采用機器集群的方式來實現(xiàn)高性能。例如,支付寶和微信這類規(guī)模的業(yè)務系統(tǒng),后臺系統(tǒng)的機器數(shù)量均達到了萬臺級別。
通過大量機器提升性能,并非僅僅是增加機器那么簡單。讓多臺機器協(xié)同完成高性能任務是一項復雜的任務。以下針對常見的幾種方式進行簡要分析:
1.任務分配
任務分配意味著每臺機器都能處理完整的業(yè)務任務,將不同任務分配給不同機器執(zhí)行。為實現(xiàn)有效的任務分配,負載均衡技術應運而生。負載均衡可以通過硬件或軟件實現(xiàn),其目標是將任務平均分配到各個機器上,確保系統(tǒng)資源得到充分利用,從而提高整體性能。
2.數(shù)據(jù)分片
數(shù)據(jù)分片是指將數(shù)據(jù)切分成多個部分,每個部分分配到一個或多個機器上。這種方式可以實現(xiàn)數(shù)據(jù)的水平擴展,提高數(shù)據(jù)處理能力。例如,數(shù)據(jù)庫分片技術可以將一個大型數(shù)據(jù)庫分割成多個小型數(shù)據(jù)庫,每個小型數(shù)據(jù)庫承擔部分數(shù)據(jù)處理任務。
3.數(shù)據(jù)副本
為提高數(shù)據(jù)可靠性和可用性,可在多臺機器上創(chuàng)建數(shù)據(jù)的副本。當一臺機器出現(xiàn)故障時,其他具有數(shù)據(jù)副本的機器可以立即接管服務,確保業(yè)務不間斷。數(shù)據(jù)副本技術在分布式存儲系統(tǒng)中尤為重要,如分布式文件系統(tǒng)、分布式數(shù)據(jù)庫等。
4.任務并行
任務并行是指將一個大任務分解成多個小任務,并在多臺機器上同時執(zhí)行。這種方式可以顯著減少任務執(zhí)行時間,提高處理能力。例如,MapReduce是一種著名的任務并行計算模型,可以將大數(shù)據(jù)處理任務分解成多個小任務,在集群中并行執(zhí)行,最后將結果匯總輸出。
總之,集群技術為應對業(yè)務需求提供了強大的支持,但實現(xiàn)高性能集群需要考慮任務分配、數(shù)據(jù)分片、數(shù)據(jù)副本、任務并行等多種技術,并根據(jù)具體業(yè)務需求進行合理選擇和組合。隨著云計算的普及,集群技術將更加成熟,未來亦可期待更多創(chuàng)新和發(fā)展。
我從最簡單的一臺服務器變兩臺服務器開始,來講任務分配帶來的復雜性,整體架構示意圖如下。
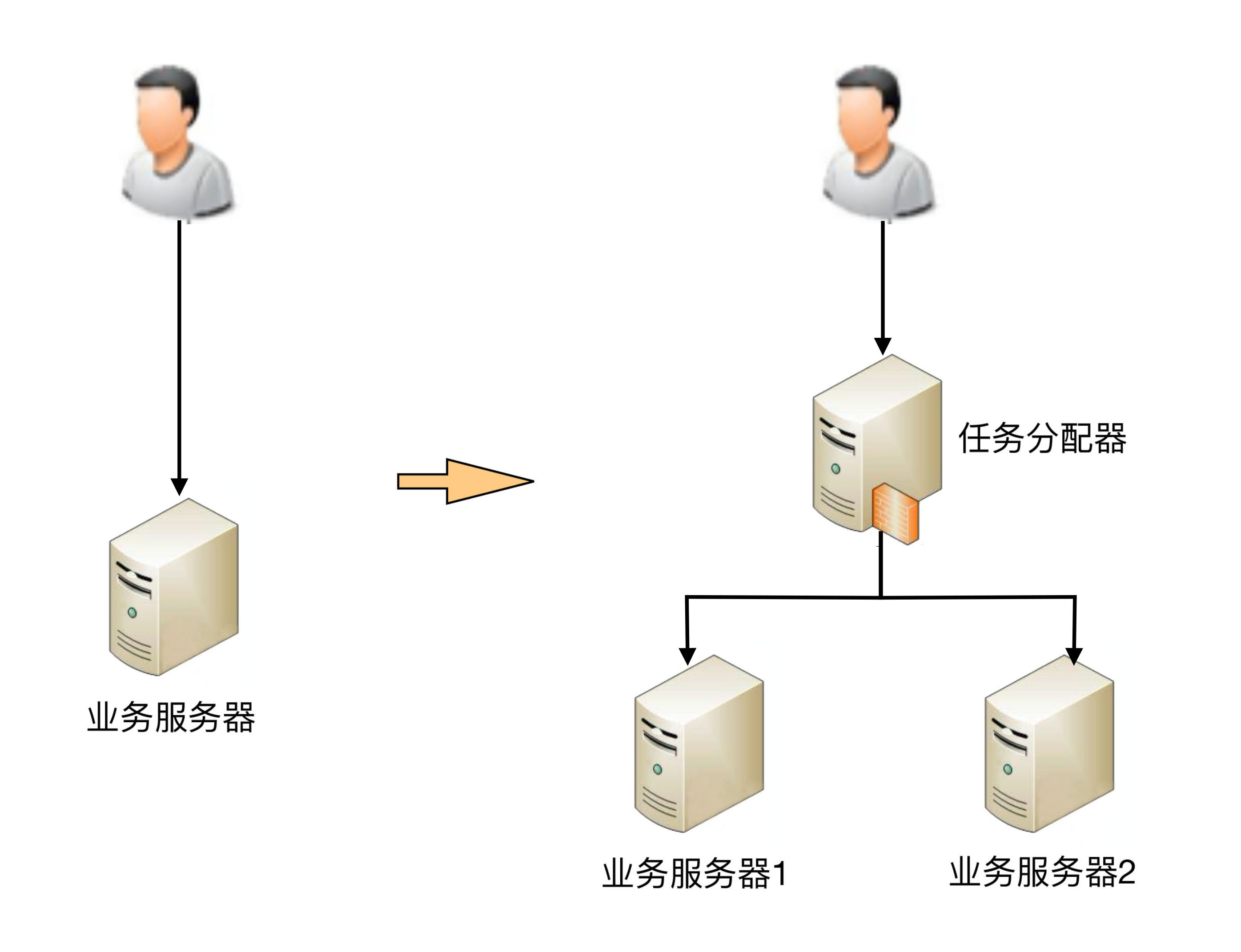
從圖中可以看到,1臺服務器演變?yōu)?臺服務器后,架構上明顯要復雜多了,主要體現(xiàn)在:
需要增加一個任務分配器,這個分配器可能是硬件網(wǎng)絡設備(例如,F(xiàn)5、交換機等),可能是軟件網(wǎng)絡設備(例如,LVS),也可能是負載均衡軟件(例如,Nginx、HAProxy),還可能是自己開發(fā)的系統(tǒng)。選擇合適的任務分配器也是一件復雜的事情,需要綜合考慮性能、成本、可維護性、可用性等各方面的因素。
任務分配器和真正的業(yè)務服務器之間有連接和交互(即圖中任務分配器到業(yè)務服務器的連接線),需要選擇合適的連接方式,并且對連接進行管理。例如,連接建立、連接檢測、連接中斷后如何處理等。
任務分配器需要增加分配算法。例如,是采用輪詢算法,還是按權重分配,又或者按照負載進行分配。如果按照服務器的負載進行分配,則業(yè)務服務器還要能夠上報自己的狀態(tài)給任務分配器。
這一大段描述,即使你可能還看不懂,但也應該感受到其中的復雜度了,更何況還要真正去實踐和實現(xiàn)。
上面這個架構只是最簡單地增加1臺業(yè)務機器,我們假設單臺業(yè)務服務器每秒能夠處理5000次業(yè)務請求,那么這個架構理論上能夠支撐10000次請求,實際上的性能一般按照8折計算,大約是8000次左右。
如果我們的性能要求繼續(xù)提高,假設要求每秒提升到10萬次,上面這個架構會出現(xiàn)什么問題呢?是不是將業(yè)務服務器增加到25臺就可以了呢?顯然不是,因為隨著性能的增加,任務分配器本身又會成為性能瓶頸,當業(yè)務請求達到每秒10萬次的時候,單臺任務分配器也不夠用了,任務分配器本身也需要擴展為多臺機器,這時的架構又會演變成這個樣子。
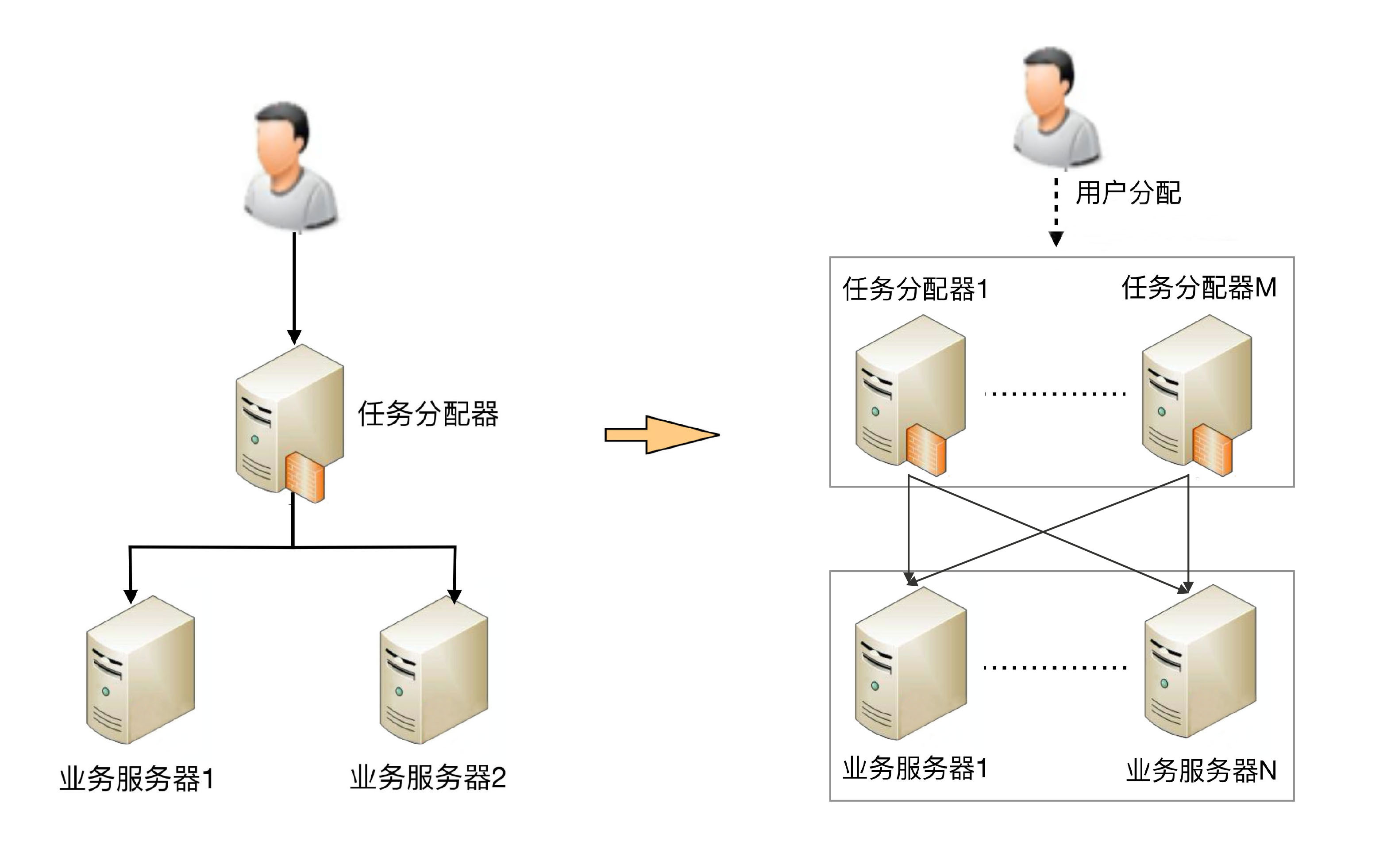
這個架構比2臺業(yè)務服務器的架構要復雜,主要體現(xiàn)在:
任務分配器從1臺變成了多臺(對應圖中的任務分配器1到任務分配器M),這個變化帶來的復雜度就是需要將不同的用戶分配到不同的任務分配器上(即圖中的虛線“用戶分配”部分),常見的方法包括DNS輪詢、智能DNS、CDN(Content Delivery Network,內(nèi)容分發(fā)網(wǎng)絡)、GSLB設備(Global Server Load Balance,全局負載均衡)等。
任務分配器和業(yè)務服務器的連接從簡單的“1對多”(1臺任務分配器連接多臺業(yè)務服務器)變成了“多對多”(多臺任務分配器連接多臺業(yè)務服務器)的網(wǎng)狀結構。
機器數(shù)量從3臺擴展到30臺(一般任務分配器數(shù)量比業(yè)務服務器要少,這里我們假設業(yè)務服務器為25臺,任務分配器為5臺),狀態(tài)管理、故障處理復雜度也大大增加。
上面這兩個例子都是以業(yè)務處理為例,實際上“任務”涵蓋的范圍很廣, 可以指完整的業(yè)務處理,也可以單指某個具體的任務。例如,“存儲”“運算”“緩存”等都可以作為一項任務,因此存儲系統(tǒng)、運算系統(tǒng)、緩存系統(tǒng)都可以按照任務分配的方式來搭建架構。此外,“任務分配器”也并不一定只能是物理上存在的機器或者一個獨立運行的程序,也可以是嵌入在其他程序中的算法,例如Memcache的集群架構。
2.任務分解
通過任務分配的方式,我們能夠突破單臺機器處理性能的瓶頸,通過增加更多的機器來滿足業(yè)務的性能需求,但如果業(yè)務本身也越來越復雜,單純只通過任務分配的方式來擴展性能,收益會越來越低。例如,業(yè)務簡單的時候1臺機器擴展到10臺機器,性能能夠提升8倍(需要扣除機器群帶來的部分性能損耗,因此無法達到理論上的10倍那么高),但如果業(yè)務越來越復雜,1臺機器擴展到10臺,性能可能只能提升5倍。造成這種現(xiàn)象的主要原因是業(yè)務越來越復雜,單臺機器處理的性能會越來越低。為了能夠繼續(xù)提升性能,我們需要采取第二種方式: 任務分解。
繼續(xù)以上面“任務分配”中的架構為例,“業(yè)務服務器”如果越來越復雜,我們可以將其拆分為更多的組成部分,我以微信的后臺架構為例。
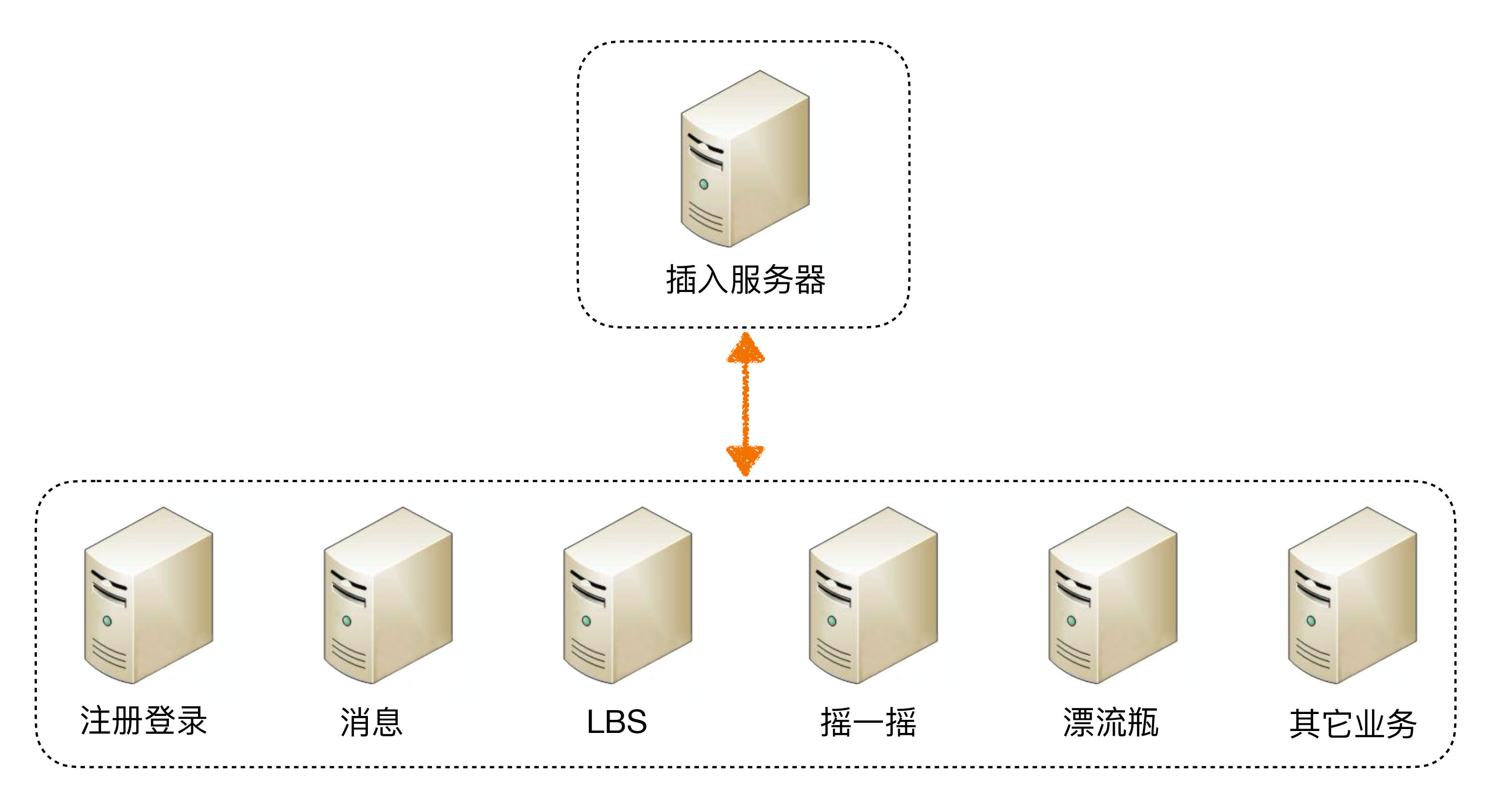
通過上面的架構示意圖可以看出,微信后臺架構從邏輯上將各個子業(yè)務進行了拆分,包括:接入、注冊登錄、消息、LBS、搖一搖、漂流瓶、其他業(yè)務(聊天、視頻、朋友圈等)。
通過這種任務分解的方式,能夠把原來大一統(tǒng)但復雜的業(yè)務系統(tǒng),拆分成小而簡單但需要多個系統(tǒng)配合的業(yè)務系統(tǒng)。從業(yè)務的角度來看,任務分解既不會減少功能,也不會減少代碼量(事實上代碼量可能還會增加,因為從代碼內(nèi)部調(diào)用改為通過服務器之間的接口調(diào)用),那為何通過任務分解就能夠提升性能呢?
主要有幾方面的因素:
簡單的系統(tǒng)更加容易做到高性能
系統(tǒng)的功能越簡單,影響性能的點就越少,就更加容易進行有針對性的優(yōu)化。而系統(tǒng)很復雜的情況下,首先是比較難以找到關鍵性能點,因為需要考慮和驗證的點太多;其次是即使花費很大力氣找到了,修改起來也不容易,因為可能將A關鍵性能點提升了,但卻無意中將B點的性能降低了,整個系統(tǒng)的性能不但沒有提升,還有可能會下降。
可以針對單個任務進行擴展
當各個邏輯任務分解到獨立的子系統(tǒng)后,整個系統(tǒng)的性能瓶頸更加容易發(fā)現(xiàn),而且發(fā)現(xiàn)后只需要針對有瓶頸的子系統(tǒng)進行性能優(yōu)化或者提升,不需要改動整個系統(tǒng),風險會小很多。以微信的后臺架構為例,如果用戶數(shù)增長太快,注冊登錄子系統(tǒng)性能出現(xiàn)瓶頸的時候,只需要優(yōu)化登錄注冊子系統(tǒng)的性能(可以是代碼優(yōu)化,也可以簡單粗暴地加機器),消息邏輯、LBS邏輯等其他子系統(tǒng)完全不需要改動。
既然將一個大一統(tǒng)的系統(tǒng)分解為多個子系統(tǒng)能夠提升性能,那是不是劃分得越細越好呢?例如,上面的微信后臺目前是7個邏輯子系統(tǒng),如果我們把這7個邏輯子系統(tǒng)再細分,劃分為100個邏輯子系統(tǒng),性能是不是會更高呢?
其實不然,這樣做性能不僅不會提升,反而還會下降,最主要的原因是如果系統(tǒng)拆分得太細,為了完成某個業(yè)務,系統(tǒng)間的調(diào)用次數(shù)會呈指數(shù)級別上升,而系統(tǒng)間的調(diào)用通道目前都是通過網(wǎng)絡傳輸?shù)姆绞剑阅苓h比系統(tǒng)內(nèi)的函數(shù)調(diào)用要低得多。我以一個簡單的圖示來說明。
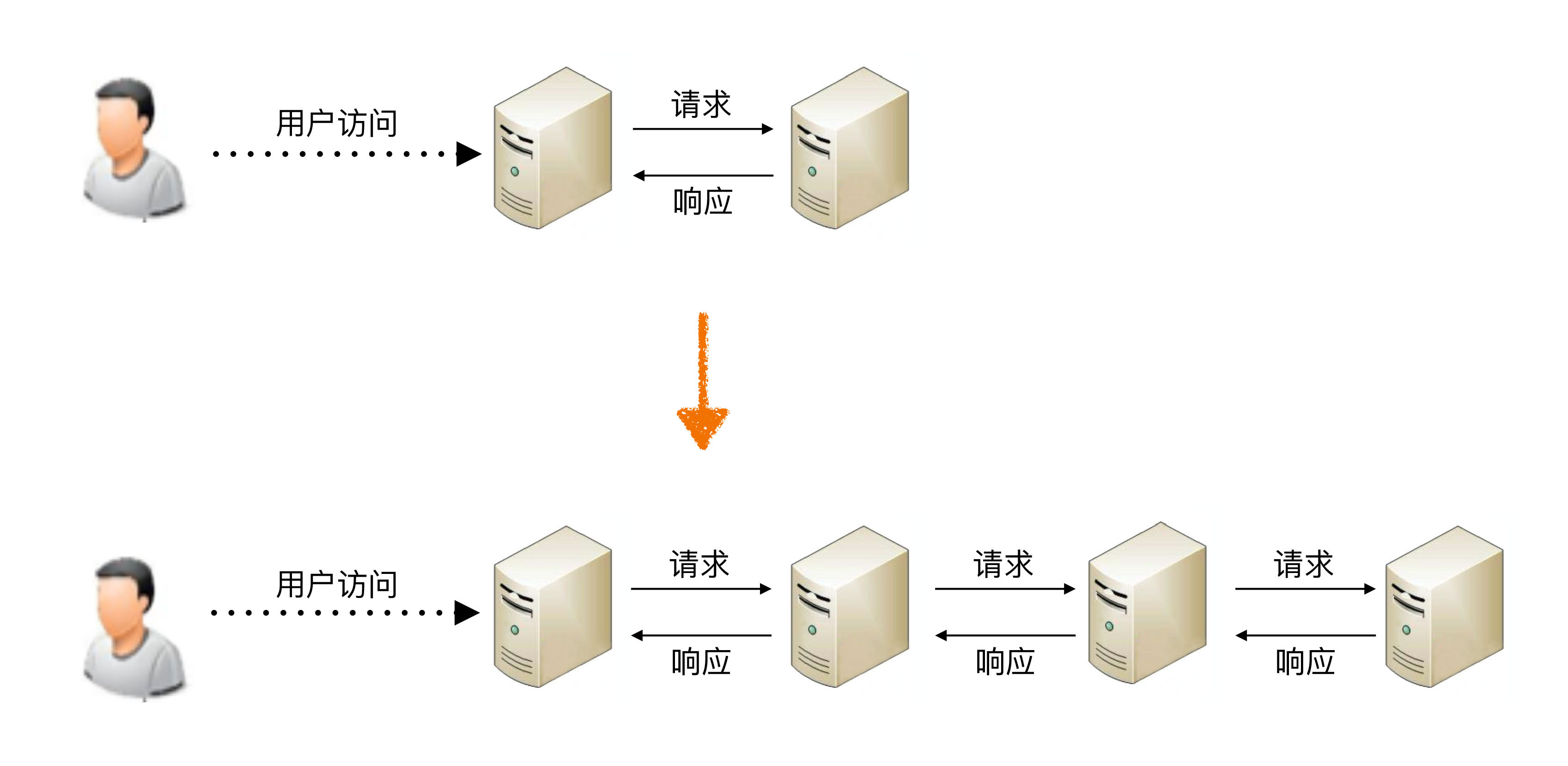
從圖中可見,當系統(tǒng)拆分為2個子系統(tǒng)時,用戶訪問需要1次系統(tǒng)間請求和1次響應;當系統(tǒng)拆分為4個子系統(tǒng)時,系統(tǒng)間請求次數(shù)從1次增加到3次;若繼續(xù)拆分為100個子系統(tǒng),為完成某次用戶訪問,系統(tǒng)間請求次數(shù)將達到99次。
為簡化描述,我們抽象出一個最簡模型:假設這些系統(tǒng)通過IP網(wǎng)絡連接,在理想情況下,一次請求和響應在網(wǎng)絡上耗時為1ms,業(yè)務處理本身耗時為50ms。我們還假設系統(tǒng)拆分對單個業(yè)務請求性能沒有影響。因此,當系統(tǒng)拆分為2個子系統(tǒng)時,處理一次用戶訪問耗時為51ms;而系統(tǒng)拆分為100個子系統(tǒng)時,處理一次用戶訪問耗時竟然達到了149ms。
盡管在一定程度上,系統(tǒng)拆分有助于提升業(yè)務處理性能,但性能提升是有限的。當系統(tǒng)未拆分時,業(yè)務處理耗時為50ms,系統(tǒng)拆分后業(yè)務處理耗時不可能僅為1ms。因為業(yè)務處理性能仍然受限于業(yè)務邏輯本身,而在業(yè)務邏輯沒有發(fā)生重大變化的情況下,理論上性能具有一個上限。系統(tǒng)拆分可以讓性能接近這一極限,但無法突破它。因此,任務分解所帶來的性能收益具有一定的度,任務分解不是越細越好。對于架構設計而言,如何把握這一粒度便顯得至關重要。
小結
今天我向你講述了軟件系統(tǒng)中高性能帶來的復雜度主要體現(xiàn)的兩方面;
一是單臺計算機內(nèi)部為了高性能帶來的復雜度; 二是多臺計算機集群為了高性能帶來的復雜度

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號