

使用uint64_t批量比較短字符串
記錄一下從開源代碼里學來的短字符串比較優化。
這個優化只適用于長度在八字節以下的字符串,且只適用于優化相等比較。
原理
想要判斷字符串相等,常見的有利用strcmp、利用字符串的hash或者利用正則表達式等。
就速度而言strcmp > hash > 正則,而靈活性上正則 > hash ≈ strcmp。
字符串的相等性比較可以說是程序運行中的熱點,因此用于比較字符串的各種函數也是性能優化中的重點,這使得strcmp在通用場景下有著相當不錯的性能表現。
不過在細分場景上strcmp就有點心有余而力不足了。我們要討論的場景就是這種細分場景:兩個字符串長度相同且都小于等于八字節。
在這個場景下,絕大多數字符串比較函數都是選擇逐字節循環比較的,這個策略其實沒有問題,少量數據以固定模式進行循環處理,對于現代cpu來說是個很容易吃到緩存優化的操作,因此速度不會落下風。
但這個方案仍然需要多次比較數據,這是一個瓶頸,我們要講的優化就是針對減少比較次數這一點進行的。
考慮兩個八字節長度的字符串hello123和hello124,如果用逐字節比較的辦法,最壞情況下我們需要比較8次。想要減少比較次數我們就得每次比較兩個字節以上的數據,甚至是一次就處理全部的八個字節。
碰巧的是現代的x86和ARM芯片上還真有這種一次比較八字節數據的指令,只不過這些指令比較的是64位整數值而不是字符串。我們的優化措施就是利用這些指令來比較字符串內容。
所以現在的問題變成了怎么把字符串轉換成整數值。很多讀者應該會立即想到hash,但這里用hash是不合適的,hash本身需要處理每一個字符,而且需要添加很多額外的運算,在以前的博客里我測試過在處理短字符串時它的性能是不及strcmp的。而現在我們要實現比strcmp更快的方法,hash自然是不適用的。
剩下只有一種途徑了,64位整數正好需要八字節內存,我們的字符串也正好是八字節,所以我們可以考慮把字符串的二進制數據整個復制給整數。這個做法其實在c/c++系統編程里很常見,但對于習慣了go/js的人來說可能有些陌生了:
uint64_t string2uint64(const char *str)
{
uint64_t res = 0;
memcpy((void*)&res, (const void*)str, sizeof(uint64_t));
return res;
}
為了代碼盡量簡短,我用了c-style的類型轉換。這個函數其實不安全,想象一下str沒有8字節長的情景,這個函數會越界訪問。這段代碼也不夠類型安全。
string2uint64要求字符串必須有至少8字節長度,所以對于不足8字節的字符串,調用的時候得補足:
string2uint64("hello123") // 正好8字節
string2uint64("hell\0\0\0\0") // 補了4個0
而且長度的計量單位是字節,因此碰到漢字這種不管什么編碼基本都是多字節存儲的內容,這個函數也很容易出錯。
如果覺得補0很麻煩,實際上我們也有簡化手段:使用memccpy。這個函數可以在找到指定字符的時候停止復制,因此我們只要讓它找到字符串結尾的0就可以阻止越界訪問了:
uint64_t string2uint64Unalign(const char *str)
{
uint64_t res = 0;
memccpy((void*)&res, (const void*)str, 0, sizeof(uint64_t));
return res;
}
注意兩個版本我都采用了復制而不是直接把字符串的指針轉換成uint64_t*,因為后者是真正的踩在了語言標準的紅線上,而且也沒辦法像string2uint64Unalign那樣處理長度對齊。
在把字符串轉換成整數之后,我們就可以用比較整數的方式比較字符串了:
strcmp("hello", "world") == 0 || strcmp("hello", "Hello") == 0 || strcmp("hello", "hello") == 0;
// 等價于
const auto value = string2uint64("hello\0\0\0");
value == string2uint64("world\0\0\0") || value == string2uint64("Hello\0\0\0") || value == string2uint64("hello\0\0\0");
注意為了補足長度而填充進去的0。
可以自己寫個測試代碼看看兩個函數生成的整數值,具體的值會和字節序有關,但只要每個字符串都按相同的字節序進行處理,就不會有問題:
int main()
{
std::cout << string2uint64("hello123") << '\n';
std::cout << string2uint64Unalign("hello123") << '\n';
std::cout << string2uint64("hell\0\0\0\0") << '\n';
std::cout << string2uint64Unalign("hell") << '\n';
}
// 輸出
3689065399400031592
3689065399400031592
1819043176
1819043176
性能測試
理解了原理,現在該看看性能了。
有經驗的讀者應該會有兩個擔心的點,第一個在于一次memcpy的內存復制開銷是否會成為性能殺手,第二個在于memccpy做了額外的檢測會不會導致執行速度減慢。
我也有這些擔心,所以我設計了一個性能測試。測試使用隨機生成的8字節長度的字符串,然后讓兩種優化方法和strcmp每次都就行八次匹配,只有最后一次會得到相等的結果。這樣我們可以讓字符串相等的判斷邏輯盡量處理足夠多的字符內容,以便模擬日常開發中的場景。
用隨機生成字符串是有講究的,因為用字符串常量編譯器會在編譯時就進行計算導致結果沒有意義。這不能怪編譯器,因為字符串比較操作實在太常用所以必須抓住一切機會就行優化。隨機生成比較用的數據暫時能阻止編譯器的優化。
生成隨機字符串的代碼我直接讓AI寫了,AI很適合生成這種只用一兩次的閱后即焚的小型函數:
std::string generateRandomString(std::size_t length = 8) {
const std::string charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789";
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> distrib(0, charset.size() - 1);
std::string result;
result.reserve(length);
for (std::size_t i = 0; i < length; ++i) {
result += charset[distrib(gen)];
}
return result;
}
寫的確實很一般,但勉強能用。測試部分當然是我手寫的,這塊代碼很簡單:
void bench_strcmp(benchmark::State &state)
{
const char *target = "hello123";
std::vector<std::string> data;
for (int i = 0; i < 7; ++i) {
data.push_back(generateRandomString());
}
data.push_back("hello123");
for (auto _ : state) {
for (const auto &str: data) {
benchmark::DoNotOptimize(strcmp(target, str.c_str()) == 0);
}
}
}
BENCHMARK(bench_strcmp);
void bench_fast(benchmark::State &state)
{
const char *target = "hello123";
const uint64_t v = string2uint64(target);
std::vector<std::string> data;
for (int i = 0; i < 7; ++i) {
data.push_back(generateRandomString());
}
data.push_back("hello123");
for (auto _ : state) {
for (const auto &str: data) {
benchmark::DoNotOptimize(v == string2uint64(str.c_str()));
}
}
}
BENCHMARK(bench_fast);
void bench_not_need_align(benchmark::State &state)
{
const char *target = "hello123";
std::vector<std::string> data;
for (int i = 0; i < 7; ++i) {
data.push_back(generateRandomString());
}
data.push_back("hello123");
const uint64_t v = string2uint64Unalign(target);
for (auto _ : state) {
for (const auto &str: data) {
benchmark::DoNotOptimize(v == string2uint64Unalign(str.c_str()));
}
}
}
BENCHMARK(bench_not_need_align);
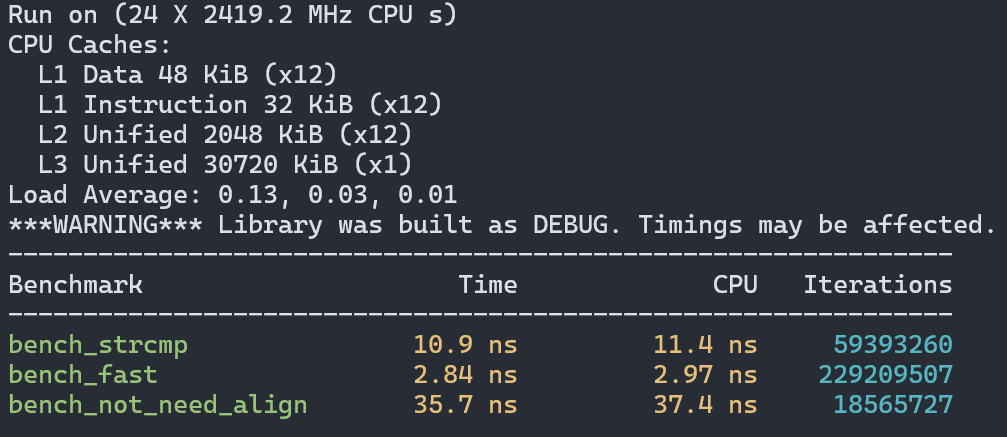
首先是在Intel CPU的Linux上使用GCC的測試結果:
接著是在Intel cpu的Windows上使用msvc編譯器的結果:

最后是Apple M4上使用clang的結果:
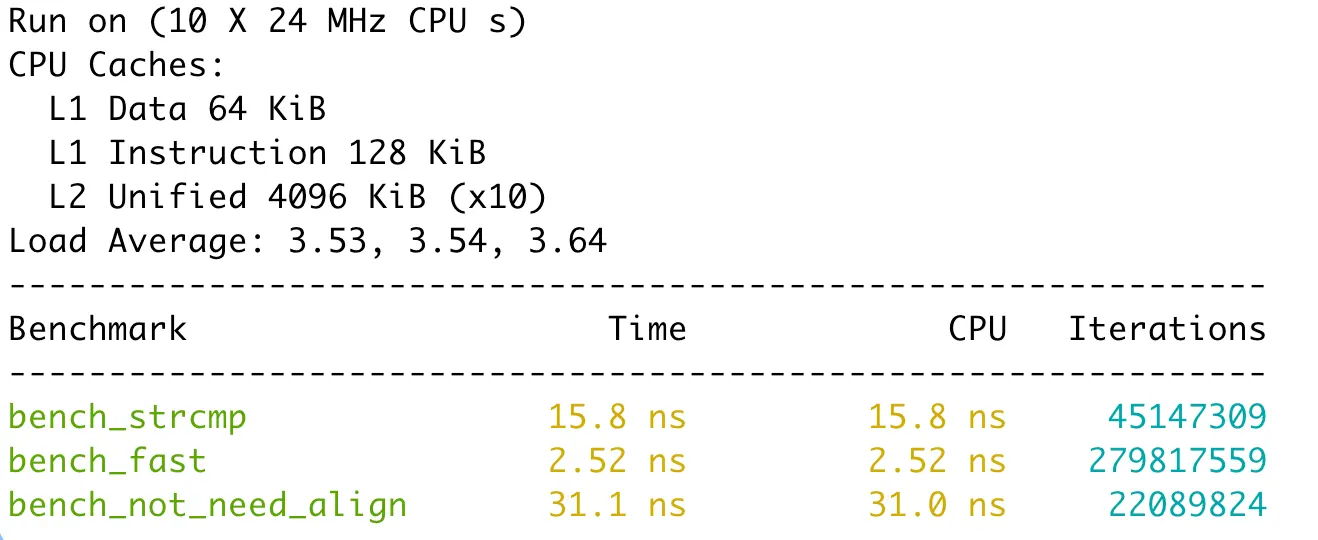
所有編譯器都采用了最高級別的優化(gcc/clang使用-O3,msvc使用/O2)。
可以看到一次內存復制并不會成為性能瓶頸,反而讓性能獲得了至少3倍的提升。但memccpy確實成了性能殺手,每個結果里都比用strcmp慢至少一倍。
結論就是如果比較的字符串長度都是8字節,那么使用string2uint64是最好的,只要有一個條件不滿足,那么就改用strcmp。你問我為啥沒測試需要補零的場景,其實我測過,不管怎么補都會比memccpy慢得多,所以沒有放出來的價值。
其他語言中的效果
其他語言指的是go語言,python/js/lua沒提過直接操作底層對象內存數據的接口,而rust又對類型安全和內存安全有嚴格的限制(使用unsafe能繞過一部分但最好別這么做),那就只有go能試試了。
實現方法采用的是*byte強轉*uint64然后解引用獲取數值。雖然c++里不許這么干,但golang里是可以的,但往大里說這是對unsafe的濫用:
func str2uint64(s string) uint64 {
p := unsafe.StringData(s)
up := (*uint64)(unsafe.Pointer(p))
return *up
}
golang中沒有memccpy,前面我們也測過自動探測字符串邊界的辦法很慢,因此這里就省略了。
這個函數也和c++版本的一樣,字符串必須是八字節長,否則會panic。
性能測試采用和c++一樣的策略,測試版本是golang 1.24.5:
func BenchmarkStrcmp(b *testing.B) {
data := make([]string, 0, 8)
for range 7 {
data = append(data, GenerateRandomString(8))
}
data = append(data, "hello123")
for b.Loop() {
for i, s := range data {
a := strings.Compare("hello123", s) == 0
if i < 7 && a {
panic("error")
}
}
}
}
func BenchmarkEqual(b *testing.B) {
data := make([]string, 0, 8)
for range 7 {
data = append(data, GenerateRandomString(8))
}
data = append(data, "hello123")
for b.Loop() {
for i, s := range data {
a := s == "hello123"
if i < 7 && a {
panic("error")
}
}
}
}
func BenchmarkFast(b *testing.B) {
data := make([]string, 0, 8)
for range 7 {
data = append(data, GenerateRandomString(8))
}
data = append(data, "hello123")
v := str2uint64("hello123")
for b.Loop() {
for i, s := range data {
a := v == str2uint64(s)
if i < 7 && a {
panic("error")
}
}
}
}
遺憾的是效果并不理想:
cpu: Intel(R) Core(TM) i7-14650HX
BenchmarkStrcmp-24 52009516 22.81 ns/op 0 B/op 0 allocs/op
BenchmarkEqual-24 286688548 4.218 ns/op 0 B/op 0 allocs/op
BenchmarkFast-24 150709956 7.951 ns/op 0 B/op 0 allocs/op
我們的方法比直接使用==慢了接近一倍。原因其實很簡單,go的編譯器已經做過字符串轉數字再比較的操作了。因此==節省了很多邊界檢查和轉換操作,速度更快。go編譯器也沒有采用我們這種強轉類型的做法,而是使用了移位操作和位運算來組合每一個字節到最終的整數值,這也是為什么它的速度比我們的cpp版本慢一些的原因。go使用位運算拼接整數的目的在于可以讓比較的操作數可以有不同的長度,不足的部分默認都是0,這還免除了我們使用memccpy導致的性能下降,是比較smart的。除了更快,編譯器優化的版本比我們自己實現的更安全,不用擔心panic。
go直接優化的字符串長度還可以超過8字節,因為它會檢測平臺是否支持一次可以加載超過8字節數據的指令。在c++里想這么做得費很大一番功夫,因此我沒有實現這種功能。
雖說我們在go中手動實現優化的效果不理想,但這也從側面證明我們的思路是對的——別的語言也采納了這種優化。
總結
其實不止是優化固定長度的字符串比較,將二進制數據轉換成整數進行批量處理其實是一種丐版的“SIMD”,所以這個技巧你可以在很多開源項目里發現,比如go對字符串相等判斷的優化,又比如google開發的swisstable中在目標環境上不支持SIMD時會使用整數類型合并多個元素的tag進行批量處理,例子還可以舉出很多。
最后我還是得提醒一下,這個方案有一定的安全風險,以及優化前要用性能測試找瓶頸,優化后要用性能測試做驗證,切記。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號