

golang遍歷處理map時的常見性能陷阱
最近一直在重構(gòu)優(yōu)化老系統(tǒng),所以性能優(yōu)化相關(guān)的文章會比較多。
這次的是有關(guān)循環(huán)處理map時的性能優(yōu)化。預(yù)分配內(nèi)存之類的大家都知道的就不多說了,今天來講點(diǎn)大伙不知道的。
要講的一共有三點(diǎn),而且都和循環(huán)處理map有關(guān)。
不要用for-range循環(huán)清空map
這里要討論的“清空”是指刪除map中所有鍵值對,但保留map里已分配的內(nèi)存供下次復(fù)用。
如果只是想釋放map并且不再需要復(fù)用,那么map1 = nil或者map2 = map[T]U{}就足夠了。
內(nèi)置函數(shù)delete可以幫我們實(shí)現(xiàn)刪除鍵值對但保留它們在map中的內(nèi)存空間,通常我們會這么寫:
for key := range Map1 {
delete(Map1, key)
}
這種模式化的代碼太常見,以至于go編譯器專門對其做了優(yōu)化,只要形式上符合上述代碼片段的,編譯器都會把循環(huán)優(yōu)化成runtime.mapclear(Map1),使用runtime內(nèi)置的map清理函數(shù)將map清空,這比靠循環(huán)遍歷刪除要快很多倍。
看到這里你可能會說這不是挺好嗎,為什么不讓用了呢?
因?yàn)楝F(xiàn)在有更好的替代方案了——內(nèi)置函數(shù)clear。
clear應(yīng)用在map上時本身就會調(diào)用runtime.mapclear(...),在性能上和循環(huán)方法大致一樣而且只快不慢。因?yàn)閮烧咦罱K生成代碼差不多,性能測試也就沒多大意義了,所以這里不做性能測試。
clear還有另一個好處,它更容易讓包含它的函數(shù)被內(nèi)聯(lián)。
這是什么意思呢?go的編譯器實(shí)際上在編譯時要分很多個步驟,粗略地講go代碼在真正開始生成機(jī)器碼之前,得先經(jīng)過內(nèi)聯(lián) -> 逃逸分析 -> 語法樹改寫這樣幾個階段。上文說的for循環(huán)刪除優(yōu)化在語法樹改寫這個階段完成。
這就帶來了一個問題,相比一個簡單的clear函數(shù)調(diào)用,編譯器認(rèn)為for循環(huán)這種操作更“重量級”,一個函數(shù)擁有的“重”操作越多,那么這個函數(shù)被內(nèi)聯(lián)優(yōu)化的可能性就越小。
我們看個例子:
func RangeClearMap() {
for k := range bigMap {
delete(bigMap, k)
}
for k := range bigPtrMap {
delete(bigPtrMap, k)
}
for k := range smallMap {
delete(smallMap, k)
}
for k := range smallPtrMap {
delete(smallPtrMap, k)
}
for k := range bigMapIntKey {
delete(bigMapIntKey, k)
}
for k := range bigPtrMapIntKey {
delete(bigPtrMapIntKey, k)
}
for k := range smallMapIntKey {
delete(smallMapIntKey, k)
}
for k := range smallPtrMapIntKey {
delete(smallPtrMapIntKey, k)
}
}
func BuiltinClearMap() {
clear(bigMap)
clear(bigPtrMap)
clear(smallMap)
clear(smallPtrMap)
clear(bigMapIntKey)
clear(bigPtrMapIntKey)
clear(smallMapIntKey)
clear(smallPtrMapIntKey)
}
同樣是清空8個map,一個用循環(huán),一個用內(nèi)置函數(shù)。我們看下內(nèi)聯(lián)分析的結(jié)果:

其中cost就是衡量一個函數(shù)里的操作有多“重”的數(shù)值標(biāo)準(zhǔn),超過一定的cost,函數(shù)就無法內(nèi)聯(lián)。可以看到,使用循環(huán)會比使用clear內(nèi)置函數(shù)重整整四倍。雖然最后因?yàn)閮蓚€函數(shù)都很簡單所以被內(nèi)聯(lián)展開,但碰上更復(fù)制一點(diǎn)的函數(shù),顯然使用clear能有更多的冗余。
盡管編譯器最終會把兩者優(yōu)化成一樣的對runtime的map清理函數(shù)的調(diào)用,但對for循環(huán)的優(yōu)化在內(nèi)聯(lián)處理之后,因此for不僅讓代碼更長,也更容易錯失內(nèi)聯(lián)優(yōu)化的機(jī)會,而失去內(nèi)聯(lián)優(yōu)化進(jìn)而會影響逃逸分析從而損失更多性能,你可以在我以前的博客里看到內(nèi)聯(lián)和逃逸分析對內(nèi)聯(lián)的影響。
clear()是go1.21添加的,因此只要你在用的go版本大于等于1.21,我推薦你盡量使用clear而不是for-range循環(huán)來清空map。
遍歷訪問map時的陷阱
遍歷處理map中的元素也是常見操作,不過不像循環(huán)刪除,編譯器在這種代碼上并沒有什么優(yōu)化。
最常見的寫法是這樣的:
for key, value := range Map1 {
func1(key, value)
func2(key, value)
}
這時候,一部分開發(fā)者會覺得每次循環(huán)都得復(fù)制一次value,尤其是1.22開始循環(huán)變量每輪都是新變量,這種操作是不是會很慢也很占用內(nèi)存?畢竟在遍歷slice的時候確實(shí)有這些問題,那么能不能采用優(yōu)化slice遍歷的相同方法來優(yōu)化map遍歷呢:
for key := range Map1 {
func1(key, Map1[key])
func2(key, Map1[key])
}
現(xiàn)在不用復(fù)制value了,性能應(yīng)該獲得提升了吧?真的是這樣嗎?
我說過很多次,性能優(yōu)化不能靠想象,要靠benchmark來說話,所以我們來做個性能測試。
我們測試大value和小value在兩種循環(huán)下的表現(xiàn),另外還會額外測試一下map里存放指針的情況,測試用的value類型主要是下面兩種:
// 128字節(jié)
type BigObject struct {
n1, n2, n3, n4, n5, n6, n7, n8, n9, n10 int64
s1, s2, s3 string
}
// 32字節(jié)
type SmallObject struct {
n1, n2 int64
s1 string
}
我們一共分8種case進(jìn)行測試:
var (
bigMap = map[string]BigObject{}
bigPtrMap = map[string]*BigObject{}
smallMap = map[string]SmallObject{}
smallPtrMap = map[string]*SmallObject{}
)
func init() {
for i := range int64(100) {
strKey := fmt.Sprintf("Key:%03d", i)
bigMap[strKey] = NewBigObject()
bigPtrMap[strKey] = NewBigObjectPtr()
smallMap[strKey] = NewSmallObject()
smallPtrMap[strKey] = NewSmallObjectPtr()
}
}
每個map里都填充100個元素,元素的值隨機(jī)生成,不過我限制了字符串都是等長的,這是為了結(jié)果的準(zhǔn)確性。
測試也比較簡單:
func BenchmarkBigObjectLoopCopy(b *testing.B) {
for b.Loop() {
for _, v := range bigMap {
if v.n1 == 0 || v.n2 == 0 {
panic("error")
}
}
}
}
func BenchmarkBigObjectPtrLoopCopy(b *testing.B) {
for b.Loop() {
for _, v := range bigPtrMap {
if v.n1 == 0 || v.n2 == 0 {
panic("error")
}
}
}
}
func BenchmarkBigObjectLoopKey(b *testing.B) {
for b.Loop() {
for k := range bigMap {
if bigMap[k].n1 == 0 || bigMap[k].n2 == 0 {
panic("error")
}
}
}
}
func BenchmarkBigObjectPtrLoopKey(b *testing.B) {
for b.Loop() {
for k := range bigPtrMap {
if bigPtrMap[k].n1 == 0 || bigPtrMap[k].n2 == 0 {
panic("error")
}
}
}
}
func BenchmarkSmallObjectLoopCopy(b *testing.B) {
for b.Loop() {
for _, v := range smallMap {
if v.n1 == 0 || v.n2 == 0 {
panic("error")
}
}
}
}
func BenchmarkSmallObjectPtrLoopCopy(b *testing.B) {
for b.Loop() {
for _, v := range smallPtrMap {
if v.n1 == 0 || v.n2 == 0 {
panic("error")
}
}
}
}
func BenchmarkSmallObjectLoopKey(b *testing.B) {
for b.Loop() {
for k := range smallMap {
if smallMap[k].n1 == 0 || smallMap[k].n2 == 0 {
panic("error")
}
}
}
}
func BenchmarkSmallObjectPtrLoopKey(b *testing.B) {
for b.Loop() {
for k := range smallPtrMap {
if smallPtrMap[k].n1 == 0 || smallPtrMap[k].n2 == 0 {
panic("error")
}
}
}
}
8種case就是大value的map和小value的分別用k,v := range map遍歷和只用key遍歷,看看性能差異。
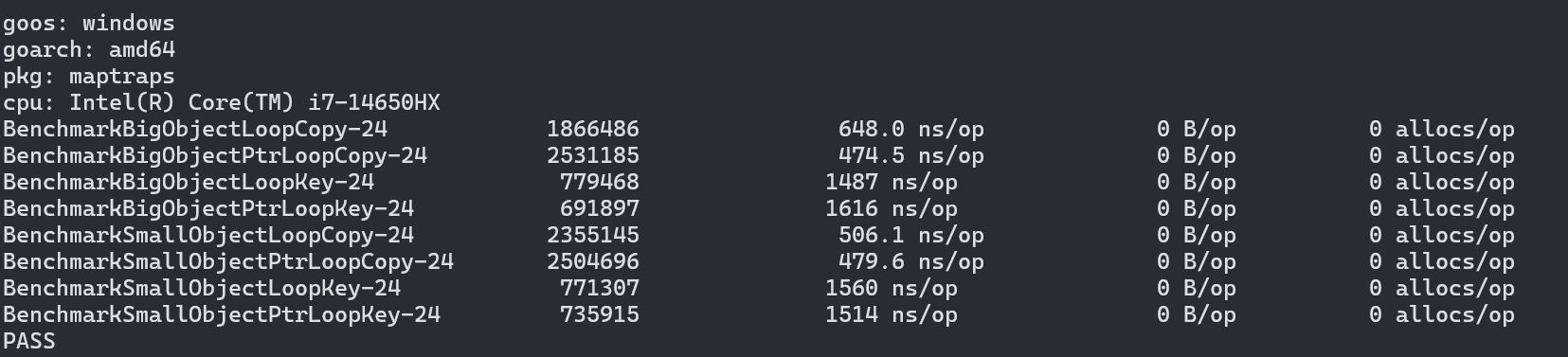
結(jié)果很是讓人詫異,自認(rèn)為的不需要復(fù)制value所以訪問更快的結(jié)論是錯的,而且錯的離譜:復(fù)制value的做法性能是只用key遍歷的3倍!
為啥會這樣呢?因?yàn)槟愕暨M(jìn)hashmap的陷阱里了,我就直接說原因了:
- 以
for k,v := range m遍歷map時,鍵值對是被順序訪問的,這對緩存命中和cpu的模式預(yù)測更友好,性能會比用key進(jìn)行hash的隨機(jī)訪問要好; - 使用
m[k]訪問時需要計(jì)算key的hash,這一步是比較耗費(fèi)計(jì)算資源的,哪怕新版本換了swissmap之后也一樣,而for-range循環(huán)不需要計(jì)算hash值。hash計(jì)算對性能的影響可以看我這篇博客講解。
這兩點(diǎn)就是hashmap的陷阱,本來在少量多次或者隨機(jī)查找等模式下算不上太大的問題,但在循環(huán)遍歷的情形下影響就會放大,最后導(dǎo)致出現(xiàn)3倍以上的性能差異。
所以當(dāng)你要遍歷處理每一個value的時候,最好用for k,v := range m或者for _,v := range m。
不過也有例外:如果你的value比較大,你需要遍歷key,符合過濾條件的key的value才需要處理,這種時候那些無用的復(fù)制就會成為性能絆腳石了。不過還是老話,先做benchmark再談優(yōu)化。
復(fù)制map時的性能陷阱
最后一個性能陷阱埋在復(fù)制map時。
這里說的“復(fù)制”是淺復(fù)制,把鍵值對復(fù)制到一個新map里去,里面的指針或者slice都是淺拷貝的。
還是先上常見寫法,實(shí)際上在1.21之前你也只能這么寫:
m2 := make(map[T]U, len(m1))
for k, v := range m1 {
m2[k] = v
}
編譯器同樣也不會對這種代碼有特殊優(yōu)化,循環(huán)會老老實(shí)實(shí)地執(zhí)行。
到了1.21,我們可以用maps.Clone做一樣的事情,而且這個標(biāo)準(zhǔn)庫函數(shù)也會在底層調(diào)用runtime里的專用map復(fù)制函數(shù),性能杠杠的。
我們準(zhǔn)備一下性能測試,map樣本沿用上一節(jié)里的:
func BenchmarkMapClone(b *testing.B) {
b.Run("range-smallMap", func(b *testing.B) {
for b.Loop() {
m := make(map[string]SmallObject, len(smallMap))
for k, v := range smallMap {
m[k] = v
}
}
})
b.Run("range-smallPtrMap", func(b *testing.B) {
for b.Loop() {
m := make(map[string]*SmallObject, len(smallPtrMap))
for k, v := range smallPtrMap {
m[k] = v
}
}
})
b.Run("range-bigMap", func(b *testing.B) {
for b.Loop() {
m := make(map[string]BigObject, len(bigMap))
for k, v := range bigMap {
m[k] = v
}
}
})
b.Run("range-bigPtrMap", func(b *testing.B) {
for b.Loop() {
m := make(map[string]*BigObject, len(bigPtrMap))
for k, v := range bigPtrMap {
m[k] = v
}
}
})
b.Run("clone-smallMap", func(b *testing.B) {
for b.Loop() {
maps.Clone(smallMap)
}
})
b.Run("clone-smallPtrMap", func(b *testing.B) {
for b.Loop() {
maps.Clone(smallPtrMap)
}
})
b.Run("clone-bigMap", func(b *testing.B) {
for b.Loop() {
maps.Clone(bigMap)
}
})
b.Run("clone-bigPtrMap", func(b *testing.B) {
for b.Loop() {
maps.Clone(bigPtrMap)
}
})
}
在這里如果你用的go版本是1.24,那么你會踩到第一個陷阱,對沒錯,我說了有三種陷阱,沒說只有三個哦。
1.24的maps.clone實(shí)現(xiàn)有問題,會有嚴(yán)重的性能回退,所以你可以看到它和循環(huán)復(fù)制性能沒有差距,甚至有時候還更慢一點(diǎn):
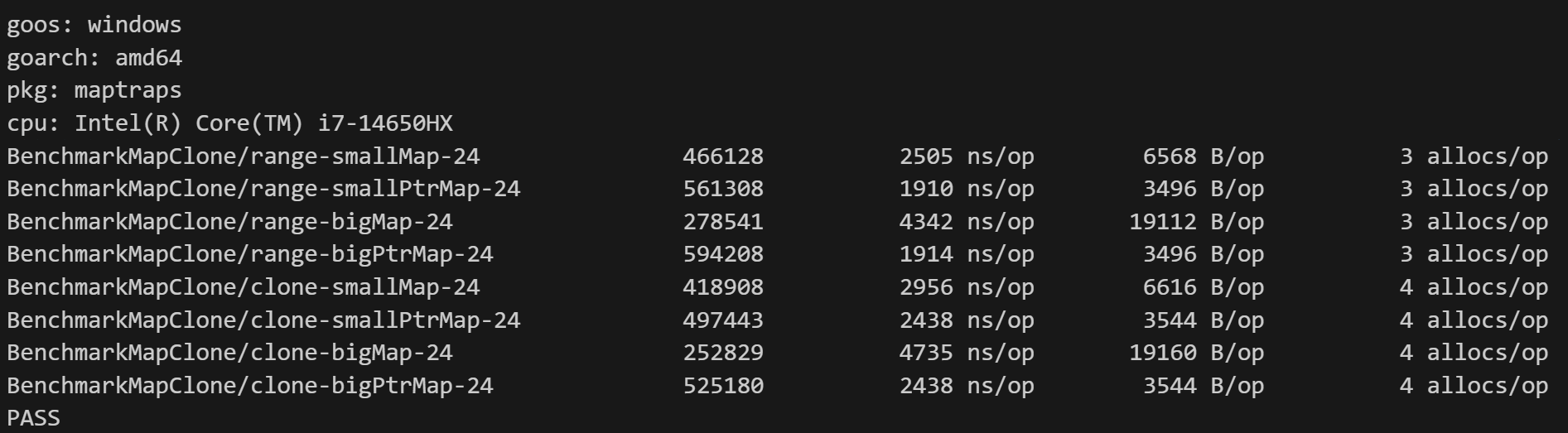
具體是什么樣的問題我就不深入講解了,因?yàn)槭峭祽袑?dǎo)致的很無聊的問題。好在這個問題會在1.25修復(fù),修復(fù)代碼已經(jīng)在主分支上了,因此我們可以用go version go1.25-devel_3fd729b2a1 Sat May 24 08:48:53 2025 -0700 windows/amd64來測試:
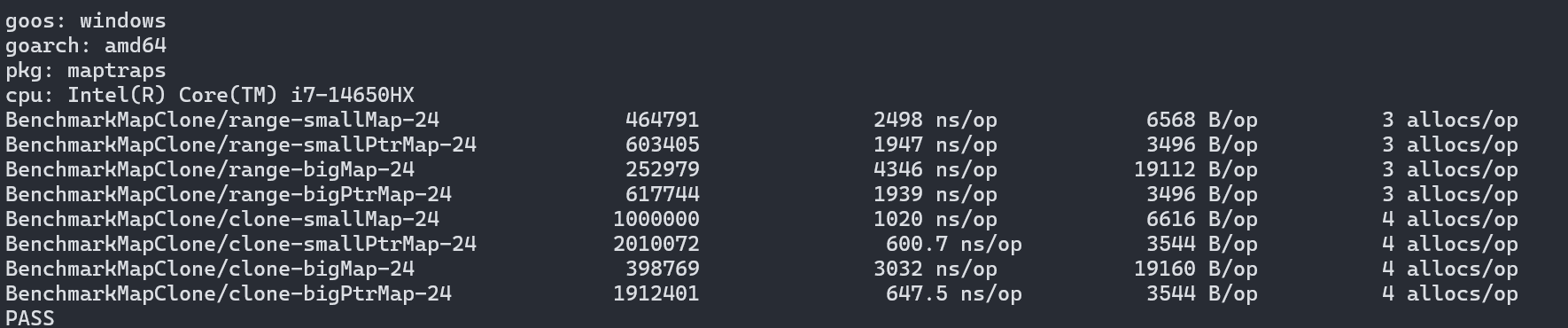
修復(fù)后結(jié)果就和1.22以及1.23一樣了。總得來說maps.Clone雖然多浪費(fèi)了一點(diǎn)內(nèi)存,但速度是循環(huán)復(fù)制的1.5~3倍。
所以要復(fù)制map的時候,盡量去用maps.Clone,這樣就能避開循環(huán)復(fù)制慢這第二個陷阱。
總結(jié)
golang果然還是那個golang,大道至簡的外皮下往往暗藏殺機(jī)。
真要說什么原則的話,那就是如果有對應(yīng)的標(biāo)準(zhǔn)庫函數(shù)/內(nèi)置函數(shù),那就用,盡量少在map上直接用循環(huán)。
還有我說過無數(shù)次的,性能優(yōu)化要靠benchmark,切記不要依賴經(jīng)驗(yàn)去預(yù)判,陷阱二就是我用benchmark找出來的“預(yù)判”失誤。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號