
頂會論文解讀:時序數(shù)據(jù)庫 Apache IoTDB 中的時序數(shù)據(jù)壓縮優(yōu)化【VLDB 2025】
 時序數(shù)據(jù)庫 Apache IoTDB 頂會論文獲中國信通院數(shù)據(jù)庫應(yīng)用創(chuàng)新實驗室深度解讀!
時序數(shù)據(jù)庫 Apache IoTDB 頂會論文獲中國信通院數(shù)據(jù)庫應(yīng)用創(chuàng)新實驗室深度解讀!
時序數(shù)據(jù)庫 Apache IoTDB 頂會論文獲中國信通院數(shù)據(jù)庫應(yīng)用創(chuàng)新實驗室深度解讀!以下為詳解原文:
本文對清華大學(xué)王建民教授團隊、中國人民大學(xué)杜小勇教授團隊、天謀科技等機構(gòu)聯(lián)合發(fā)表的 VLDB 2025論文《Improving Time Series Data Compression in Apache IoTDB》進行解讀。該論文首次將同態(tài)壓縮(Homomorphic Compression, HC)理論引入時間序列領(lǐng)域,并提出了一個名為 CompressIoTDB 的新型框架,旨在解決傳統(tǒng)時間序列數(shù)據(jù)庫中壓縮與查詢性能之間的核心矛盾。通過在壓縮數(shù)據(jù)上直接執(zhí)行查詢,該工作顯著提升了查詢吞吐量并降低了資源消耗。
一、引言:壓縮與查詢的困境及同態(tài)壓縮的破局
在物聯(lián)網(wǎng)(IoT)、金融、工業(yè)監(jiān)控等關(guān)鍵領(lǐng)域,時間序列數(shù)據(jù)正以前所未有的規(guī)模爆炸式增長。為了有效管理存儲成本和網(wǎng)絡(luò)傳輸帶寬,壓縮技術(shù)已成為Apache IoTDB、InfluxDB等現(xiàn)代時間序列數(shù)據(jù)庫(TSDB)的標配。然而,這種優(yōu)化并非沒有代價。傳統(tǒng)數(shù)據(jù)庫系統(tǒng)在處理查詢時,普遍遵循一種“先解壓、后查詢”的模式,這在處理大規(guī)模數(shù)據(jù)集時會引入顯著的計算開銷,形成嚴重的性能瓶頸。
論文通過分析Apache IoTDB的數(shù)據(jù)處理流程,精準地揭示了這一核心矛盾。

圖 1:Apache IoTDB 中的物聯(lián)網(wǎng)數(shù)據(jù)處理
如圖1a所示,IoTDB的數(shù)據(jù)處理管線首先對來自各類應(yīng)用的高頻、冗余、規(guī)律的時間序列數(shù)據(jù)進行輕量級壓縮(如RLE),再結(jié)合通用壓縮(如LZ4)存入其專有的TsFile文件格式。這一策略極大地降低了存儲需求,例如,鐵路系統(tǒng)每日產(chǎn)生的5TB原始數(shù)據(jù),通過TsFile可壓縮高達95%。然而,當執(zhí)行查詢時,系統(tǒng)必須將這些數(shù)據(jù)完全解壓回內(nèi)存,才能進行后續(xù)的計算。圖1b的性能測試結(jié)果直觀地量化了這一開銷:盡管壓縮將磁盤使用量減少了90%以上,但由于解壓縮引入的CPU計算成本,查詢延遲反而增加了15.8%。

為打破這一困境,論文引入了同態(tài)壓縮(Homomorphic Compression, HC)這一變革性方案。HC的核心思想是允許直接在壓縮數(shù)據(jù)上執(zhí)行計算,從而徹底消除解壓縮步驟。將其應(yīng)用于時間序列數(shù)據(jù)管理,可以帶來三大核心優(yōu)勢:
1.降低查詢延遲:通過繞過整個解壓縮過程,直接在壓縮表示上進行計算,從根本上減少了查詢執(zhí)行時間。
2.提升資源效率:在查詢的全生命周期中保持數(shù)據(jù)壓縮狀態(tài),顯著降低了內(nèi)存占用,使系統(tǒng)能夠在有限的資源下處理更大規(guī)模的數(shù)據(jù)集,增強了可擴展性。
3.提供原則性的設(shè)計方法:HC提供了一個堅實的數(shù)學(xué)理論框架,將系統(tǒng)設(shè)計從依賴經(jīng)驗的、零散的優(yōu)化,轉(zhuǎn)變?yōu)橐环N有形式化保證的、系統(tǒng)性的方法論。
基于此,本文的核心目標為開發(fā)一個專為時間序列數(shù)據(jù)量身定制的新型HC框架——CompressIoTDB,并將其深度集成到Apache IoTDB中,以驗證其在真實世界場景下的性能優(yōu)勢。
二、核心挑戰(zhàn):為何現(xiàn)有同態(tài)壓縮不適用于時序數(shù)據(jù)庫
盡管同態(tài)壓縮(HC)的理論已相對成熟,但將其直接應(yīng)用于時間序列數(shù)據(jù)庫(TSDB)卻面臨著一系列獨特的挑戰(zhàn)。這些挑戰(zhàn)源于時間序列數(shù)據(jù)本身的復(fù)雜特性以及TSDB系統(tǒng)的特定需求,現(xiàn)有通用的HC方法并未能充分解決這些問題。
挑戰(zhàn)一:時間序列數(shù)據(jù)的獨特復(fù)雜性
現(xiàn)有HC方法通常將數(shù)據(jù)視為通用的字節(jié)流,缺乏對時間序列數(shù)據(jù)內(nèi)在結(jié)構(gòu)和語義的理解,這導(dǎo)致了所謂的“語義鴻溝”。
-
依賴時間戳的查詢模式:TSDB的核心查詢,如基于時間的聚合、滑動窗口函數(shù)和時間戳對齊連接,都高度依賴于數(shù)據(jù)的時序關(guān)系。一個通用的HC系統(tǒng)或許能在壓縮文本中查找子串,但它無法理解“計算一小時窗口內(nèi)的平均值”這類具有時間語義的操作。它缺乏直接在壓縮域中處理時間維度信息的能力。
-
高比例的空值(Null):在物聯(lián)網(wǎng)場景中,由于設(shè)備離線、采樣頻率不一致等原因,數(shù)據(jù)中可能包含高達90%的空值。TSDB通常使用高效的空值位圖(null bitmap)來管理這些缺失值。而通用的HC方法忽略了這種復(fù)雜的元數(shù)據(jù)管理,無法在保持數(shù)據(jù)壓縮的同時正確地處理和恢復(fù)空值,這對于查詢的正確性至關(guān)重要。
挑戰(zhàn)二:壓縮算法的失配
TSDB的性能與壓縮效率緊密相關(guān),因此它們傾向于使用為時間序列數(shù)據(jù)特征專門優(yōu)化的輕量級、無損壓縮算法。
-
TSDB的偏好:常用的算法包括行程長度編碼(RLE)、字典編碼(Dictionary Encoding)以及基于差分的編碼(如Ts_2Diff)。這些算法能夠高效地利用時序數(shù)據(jù)中值的重復(fù)性或平穩(wěn)變化的特性。
-
現(xiàn)有HC的局限:相比之下,現(xiàn)有的HC研究更多地集中在通用壓縮算法上,如LZW。這些算法雖然通用,但并未針對時序數(shù)據(jù)的特點進行優(yōu)化,更重要的是,它們對TSDB中復(fù)雜的查詢算子(如聚合、過濾)的同態(tài)計算支持非常有限。
挑戰(zhàn)三:缺乏針對TSDB的統(tǒng)一框架
盡管在流處理系統(tǒng)等領(lǐng)域已有直接在壓縮數(shù)據(jù)上計算的探索,但TSDB的場景有其本質(zhì)區(qū)別。
-
不同的設(shè)計優(yōu)先級:流處理系統(tǒng)通常優(yōu)先考慮低延遲,可能會犧牲壓縮率;而TSDB需要同時兼顧高壓縮率(以存儲海量歷史數(shù)據(jù))和高效的查詢性能。
-
不同的數(shù)據(jù)范圍:流處理系統(tǒng)通常操作于較小的時間窗口,而TSDB則需要支持對跨越數(shù)年、規(guī)模龐大的歷史數(shù)據(jù)進行批量分析。
綜上所述,將HC成功應(yīng)用于TSDB,需要的不僅僅是算法的簡單移植,而是一個能夠彌合“語義鴻溝”的全新框架。這個框架必須能夠理解并直接在壓縮域中操作時間序列的核心語義(時間、值、空值),同時與TSDB常用的輕量級壓縮方案深度集成。
三、理論框架:為時序數(shù)據(jù)定制的同態(tài)查詢模型
為了系統(tǒng)性地解決上述挑戰(zhàn),論文首先構(gòu)建了一個堅實的理論框架,為在壓縮時間序列數(shù)據(jù)上進行查詢提供了形式化的定義和性能保證。這個框架不僅證明了方法的正確性,更重要的是,它為后續(xù)的系統(tǒng)設(shè)計提供了原則性的指導(dǎo)。

然而,僅僅正確是不夠的,一個“好”的同態(tài)查詢還必須是高效的。為此,論文進一步提出了兩個關(guān)鍵性質(zhì):
- 直接同態(tài)查詢 (Direct HQ):一個理想的同態(tài)查詢應(yīng)該完全在壓縮數(shù)據(jù)上進行,不涉及任何中間解壓步驟。這是實現(xiàn)最高效率的目標。


表 1:運算符編碼組件矩陣

最終,論文給出了一個關(guān)鍵的性能保證:對于那些在查詢過程中數(shù)據(jù)量單調(diào)遞減的典型查詢,一個采用有效同態(tài)查詢和有效輔助信息恢復(fù)的系統(tǒng),其總成本必然低于傳統(tǒng)的“先解壓、后查詢”系統(tǒng)。該證明將總成本分解為數(shù)據(jù)解壓、輔助信息恢復(fù)和算子計算三個部分,并論證了同態(tài)方法在這三方面均具有優(yōu)勢,從而在理論上鎖定了性能收益。
四、CompressIoTDB系統(tǒng):架構(gòu)與核心設(shè)計
在上述理論框架的指導(dǎo)下,論文設(shè)計并實現(xiàn)了CompressIoTDB,一個深度集成于Apache IoTDB查詢層的新型同態(tài)壓縮查詢框架。該系統(tǒng)通過模塊化的設(shè)計,實現(xiàn)了對壓縮時間序列數(shù)據(jù)的高效、直接處理。

圖 2:CompressIoTDB 框架
如圖2所示,CompressIoTDB的整體架構(gòu)由三大核心模塊構(gòu)成,它們協(xié)同工作,共同完成從SQL解析到結(jié)果返回的整個流程。
核心模塊
1.數(shù)據(jù)結(jié)構(gòu)模塊 (Data Structure Module):這是整個系統(tǒng)的基石。該模塊定義了核心的數(shù)據(jù)結(jié)構(gòu)CompColumn,它作為壓縮數(shù)據(jù)在內(nèi)存中的統(tǒng)一表示和訪問接口。此外,還包括Compression Offset Index和HintIndex等輔助結(jié)構(gòu),為上層算子提供高效的數(shù)據(jù)定位能力。

3.優(yōu)化模塊 (Optimization Module):該模塊包含了一系列系統(tǒng)級的優(yōu)化措施,旨在進一步提升查詢性能和效率。主要包括延遲解壓 (Late Decompression)和動態(tài)輔助信息管理 (Dynamic Auxiliary Management),分別用于降低數(shù)據(jù)讀取和預(yù)處理的開銷。
系統(tǒng)工作流程
當一個SQL查詢請求到達IoTDB時,CompressIoTDB的處理流程可分為三個主要階段:
1.加載與構(gòu)建:查詢所需的數(shù)據(jù)塊(Chunk)從存儲層的TsFile文件中被加載到內(nèi)存。此時,優(yōu)化模塊介入:系統(tǒng)采用延遲解壓策略,只對數(shù)據(jù)進行第一層通用解壓(如LZ4),而保持其輕量級壓縮格式(如RLE)。同時,通過動態(tài)輔助信息管理技術(shù),高效地處理空值和刪除標記。最終,這些經(jīng)過初步處理的壓縮數(shù)據(jù)被構(gòu)建成內(nèi)存中的CompColumn對象。
2.同態(tài)執(zhí)行:查詢計劃中的各個算子由算子模塊中的同態(tài)算子實現(xiàn)。這些算子直接在輸入的CompColumn對象上進行計算。重要的是,算子之間傳遞的中間結(jié)果仍然是CompColumn對象,從而確保數(shù)據(jù)在整個查詢執(zhí)行管線中都保持壓縮狀態(tài),最大化地減少了內(nèi)存占用和數(shù)據(jù)移動。
3.結(jié)果返回:當查詢執(zhí)行完畢,最終的結(jié)果CompColumn會根據(jù)客戶端的要求被解壓成標準格式,然后返回給用戶。
通過這種設(shè)計,CompressIoTDB將復(fù)雜的壓縮感知邏輯封裝在了數(shù)據(jù)結(jié)構(gòu)和算子模塊內(nèi)部,為上層查詢引擎提供了一個透明、高效的執(zhí)行環(huán)境。
五、核心數(shù)據(jù)結(jié)構(gòu)CompColumn:壓縮數(shù)據(jù)的高效抽象
CompColumn是CompressIoTDB系統(tǒng)中最核心的技術(shù)創(chuàng)新,它不僅是一個數(shù)據(jù)容器,更是一種架構(gòu)模式,旨在通過抽象來解耦查詢邏輯與底層物理數(shù)據(jù)表示。這種設(shè)計使得整個系統(tǒng)變得模塊化、可擴展且易于維護。
設(shè)計理念
在傳統(tǒng)數(shù)據(jù)庫中,查詢算子(如AVG())通常假設(shè)數(shù)據(jù)是以未壓縮的、可隨機訪問的數(shù)組形式存在的。如果要讓它支持多種壓縮格式,一種糟糕的實現(xiàn)方式是在算子內(nèi)部寫滿if/else分支來處理不同格式,這會導(dǎo)致代碼臃腫且難以維護。
CompColumn采用了更優(yōu)雅的面向?qū)ο笤O(shè)計。它繼承自IoTDB中通用的Column抽象類,為所有上層算子提供了一套統(tǒng)一的接口,如getObject(position)。算子只需要針對這個通用接口編程一次,而將處理不同壓縮格式的復(fù)雜性下沉到CompColumn的具體實現(xiàn)中。這樣,無論是RLE、字典編碼還是其他未來可能支持的壓縮算法,對于上層算子來說都是透明的。
CompColumn的內(nèi)部結(jié)構(gòu)

圖 3:RLE 的 CompColumn 示例
如圖3所示,一個CompColumn對象內(nèi)部主要包含以下幾個部分:
-
values數(shù)組:這是存儲壓縮數(shù)據(jù)的主體。它不是一個簡單的值數(shù)組,而是一個由“壓縮塊”(Compression Blocks)組成的數(shù)組。對于RLE編碼,每個壓縮塊就是一個Column對象,代表一個行程(run),如(value, length)。
-
compressionOffsetIndex (壓縮偏移量索引):這是實現(xiàn)對壓縮數(shù)據(jù)進行高效隨機訪問的關(guān)鍵。由于壓縮數(shù)據(jù)(尤其是RLE)本質(zhì)上是順序訪問的,我們無法像普通數(shù)組那樣通過index * size來直接定位。該索引存儲了一個映射關(guān)系,記錄了每個壓縮塊在邏輯上的起始位置。例如,coIndex = 17表示第四個壓縮塊(values)對應(yīng)于原始未壓縮序列的第17個位置。

以圖3為例,當需要訪問邏輯位置為18的數(shù)據(jù)時,系統(tǒng)首先通過compressionOffsetIndex定位到包含該位置的壓縮塊。通過查找,發(fā)現(xiàn)coIndex = 17而coIndex = 22,因此目標位置18落在第四個壓縮塊values的范圍內(nèi)。由于該塊是RLE編碼的值為7的行程,系統(tǒng)便可直接返回7。如果下一次訪問是位置19,hintIndex(此時為3)將幫助系統(tǒng)立即在同一壓縮塊內(nèi)定位,避免了重復(fù)的索引查找。
通過這種設(shè)計,CompColumn將壓縮數(shù)據(jù)的復(fù)雜性完美地封裝起來,為上層提供了一個行為上類似未壓縮列、但性能和內(nèi)存占用遠優(yōu)于后者的強大對象。
六、同態(tài)算子實現(xiàn):在壓縮域直接計算
基于CompColumn提供的統(tǒng)一接口,CompressIoTDB實現(xiàn)了一整套同態(tài)查詢算子。這些算子的核心設(shè)計原則是充分利用壓縮數(shù)據(jù)的結(jié)構(gòu)特性來避免不必要的計算,從而實現(xiàn)比在解壓數(shù)據(jù)上操作更高的效率。
典型算子實現(xiàn)
-
過濾算子 (Filter):過濾操作被下推到壓縮數(shù)據(jù)層。對于RLE編碼的數(shù)據(jù),過濾條件只需對每個行程(run)的值檢查一次,而不是對行程中的每個數(shù)據(jù)點重復(fù)檢查。例如,對于一個包含1000個重復(fù)值5的行程,WHERE value > 3的判斷只需執(zhí)行一次。對于字典編碼,過濾條件直接應(yīng)用于字典表,快速生成一個匹配的ID位圖,然后用該位圖高效地過濾整個數(shù)據(jù)列。
-
聚合算子 (Aggregation):聚合計算采用增量更新的方式。算子在內(nèi)部維護一個狀態(tài)累加器(如count, sum, sum_of_squares用于計算方差)。當處理RLE編碼的數(shù)據(jù)時,對于每個行程(value, length),狀態(tài)的更新可以通過數(shù)學(xué)公式一次性完成,而不是循環(huán)length次。

圖 4:基于RLE數(shù)據(jù)的同態(tài)聚合

-
時間戳連接算子 (Timestamp-based Join):在TSDB中,連接通常是基于時間戳對齊的。對于未對齊的數(shù)據(jù),連接過程可能會引入空值。CompressIoTDB的同態(tài)連接算子通過動態(tài)編碼來處理這種情況:它不會將整個列解壓來插入空值,而是在壓縮表示中直接插入一個“空值行程”,或者調(diào)整現(xiàn)有行程的長度,從而在不破壞數(shù)據(jù)壓縮結(jié)構(gòu)的前提下完成連接操作。
-
切片算子 (Slicing):該算子用于處理LIMIT和OFFSET子句,是實現(xiàn)大數(shù)據(jù)分批處理的關(guān)鍵。它利用CompColumn的Compression Offset Index和HintIndex快速定位到切片的起始和結(jié)束邊界,然后僅提取相關(guān)的壓縮塊,并重建一個新的、更小的CompColumn作為結(jié)果,整個過程高效且內(nèi)存友好。
運行示例
為了更具體地展示同態(tài)查詢流程,論文提供了一個完整的示例:SELECT s/2 FROM series WHERE s>3 OFFSET 11 LIMIT 4,作用于圖3所示的RLE編碼數(shù)據(jù)。
1.構(gòu)建與過濾:首先,數(shù)據(jù)被加載并構(gòu)建成CompColumn。在此過程中,WHERE s>3的過濾條件被下推。值為3的行程被丟棄,值為(3, 4, 5, 3)的非行程塊被過濾為(4, 5)。最終,構(gòu)建出的CompColumn的values為(8, (4,5), 7),其coIndex為(0, 9, 11, 16)。
2.表達式計算:接著,s/2的表達式被應(yīng)用。對于行程(9, 8),計算只需執(zhí)行一次8/2=4。對于非行程塊(2, (4,5)),計算逐個進行,得到(2, 2.5)。最終values變?yōu)?4, (2, 2.5), 3.5)。
3.切片操作:最后執(zhí)行OFFSET 11 LIMIT 4。系統(tǒng)利用coIndex和hintIndex快速定位到邏輯偏移量11(對應(yīng)coIndex),并計算出結(jié)束位置15。通過對壓縮塊進行精確的切割和重組,最終得到一個只包含(2.5, 3.5)兩個值的CompColumn,其coIndex也相應(yīng)地被重構(gòu)為(0, 1, 5)。
這個例子清晰地展示了數(shù)據(jù)如何在整個查詢流程中保持壓縮狀態(tài),以及各個同態(tài)算子如何協(xié)同工作,高效地完成復(fù)雜的查詢?nèi)蝿?wù)。
七、系統(tǒng)級優(yōu)化:進一步提升查詢效率
除了核心的CompColumn和同態(tài)算子,CompressIoTDB還引入了兩項關(guān)鍵的系統(tǒng)級優(yōu)化,以解決真實世界TSDB運維中的實際問題,并進一步壓榨查詢性能。這兩項優(yōu)化都遵循一個共同的設(shè)計哲學(xué):將數(shù)據(jù)的解壓或轉(zhuǎn)換操作推遲到絕對必要的最后一刻。
優(yōu)化一:動態(tài)輔助信息管理 (Dynamic Auxiliary Management)
- 問題背景:在生產(chǎn)環(huán)境中,數(shù)據(jù)并非總是整潔的。對齊的時間序列(多個傳感器共享一個時間戳列)會因數(shù)據(jù)缺失而產(chǎn)生大量空值,這些空值通常由一個獨立的位圖(bitmap)來管理。此外,為了提高寫入性能,刪除操作通常采用“懶刪除”(lazy deletion),即只在一個刪除列表中記錄要刪除數(shù)據(jù)的位置,而不立即進行物理刪除。在查詢時,傳統(tǒng)方法需要先解壓數(shù)據(jù),然后根據(jù)位圖和刪除列表恢復(fù)出完整的邏輯視圖,這個過程開銷巨大且破壞了數(shù)據(jù)的壓縮結(jié)構(gòu)。
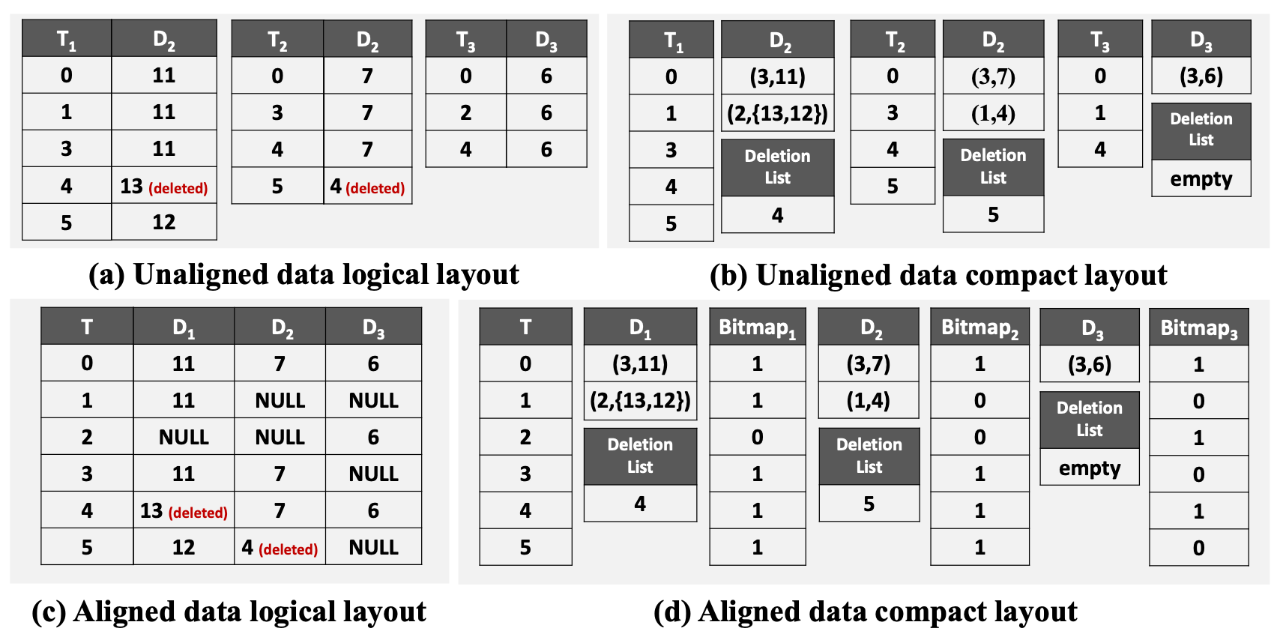
圖 5:使用RLE的緊湊布局示例
- 解決方案:CompressIoTDB采用了一種“動態(tài)編碼”策略來應(yīng)對這一挑戰(zhàn)。它不會將數(shù)據(jù)完全解壓,而是在壓縮域中直接對數(shù)據(jù)結(jié)構(gòu)進行修改。如圖5所示,當需要應(yīng)用空值位圖時,系統(tǒng)會分析位圖和RLE行程的對應(yīng)關(guān)系,然后智能地將連續(xù)的空值合并成一個新的“空值行程”插入到CompColumn中,或者將非連續(xù)的空值所在的小段數(shù)據(jù)退化為未壓縮形式。同樣,對于懶刪除,系統(tǒng)會直接調(diào)整受影響的RLE行程的長度,而不是遍歷刪除每一個點。這種方式在保持數(shù)據(jù)緊湊的同時,正確地恢復(fù)了數(shù)據(jù)的邏輯視圖。
優(yōu)化二:針對TsFile的延遲解壓 (Late Decompression)
- 問題背景:Apache IoTDB的存儲文件TsFile采用了一種雙層壓縮策略:首先使用輕量級算法(如RLE)對列數(shù)據(jù)進行編碼,然后將編碼后的數(shù)據(jù)頁(Page)再用一個通用的重量級壓縮算法(如LZ4、Snappy)進行二次壓縮。原始的IoTDB在讀取數(shù)據(jù)時,會一次性將整個數(shù)據(jù)塊(Chunk)的兩層壓縮全部解開,即使查詢可能只需要其中的一小部分數(shù)據(jù),這造成了大量的CPU資源浪費。
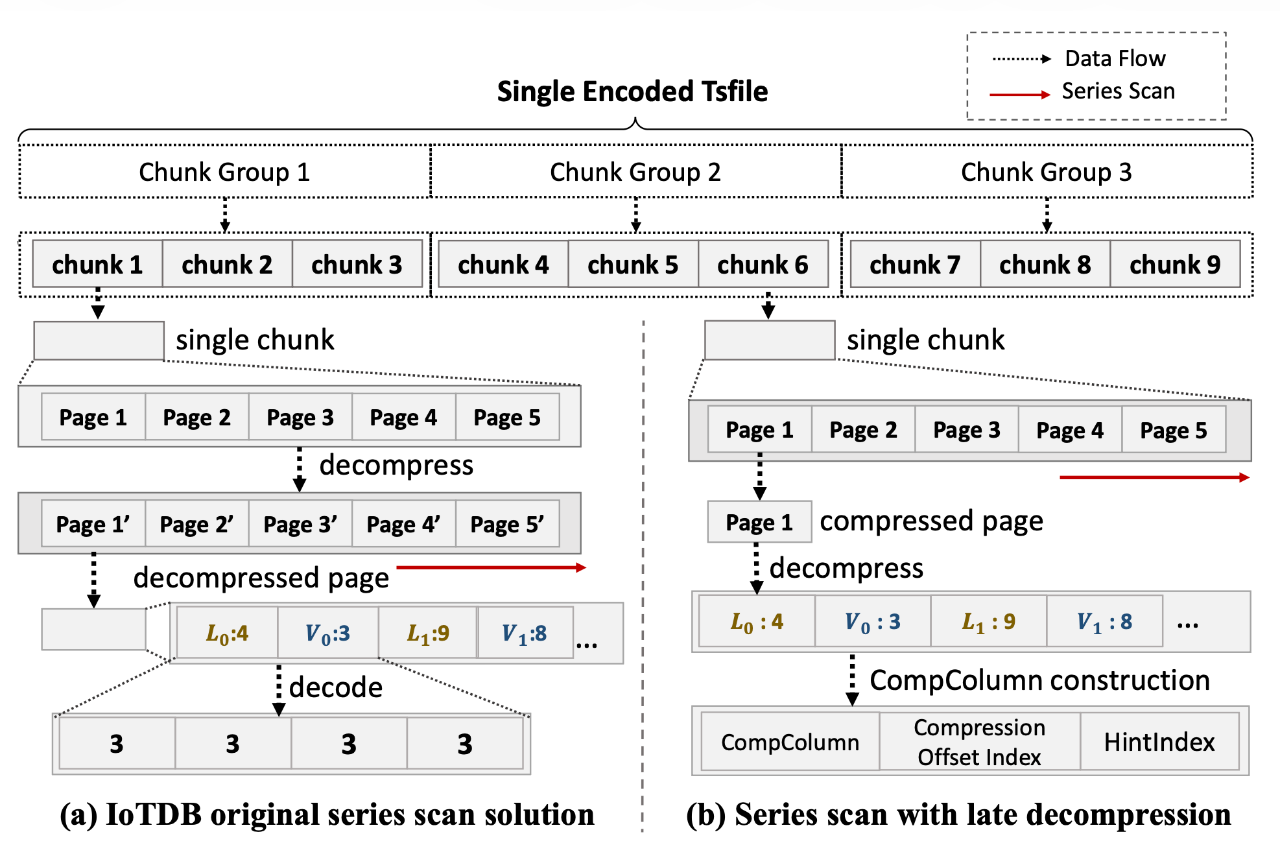
圖 6:后期減壓策略示意圖
- 解決方案:CompressIoTDB的延遲解壓策略徹底改變了這一流程。如圖6所示,當從磁盤讀取數(shù)據(jù)塊時,系統(tǒng)只在內(nèi)存中保留其經(jīng)過通用壓縮(LZ4壓縮)的狀態(tài)。在查詢執(zhí)行的系列掃描(Series Scan)階段,系統(tǒng)會逐頁(Page by Page)迭代。只有當某個特定的頁面真正被訪問到時,系統(tǒng)才會對其進行通用的LZ4解壓。更關(guān)鍵的是,解壓出的數(shù)據(jù)(此時仍是RLE等輕量級編碼格式)會直接被用于構(gòu)建CompColumn,完全跳過了第二層輕量級解壓的步驟。這一優(yōu)化確保了只有被查詢所需的數(shù)據(jù)才會被解壓,并且只解壓必要的層次,極大地降低了CPU開銷,尤其是在高選擇性(只查詢少量數(shù)據(jù))的查詢中效果顯著。
這兩項優(yōu)化體現(xiàn)了系統(tǒng)設(shè)計者對IoTDB底層架構(gòu)的深刻理解,它們通過精巧的設(shè)計,將同態(tài)壓縮的理念與現(xiàn)有存儲格式的特性完美結(jié)合,實現(xiàn)了性能的進一步飛躍。
八、實驗評估:驗證CompressIoTDB的性能優(yōu)勢
為了全面驗證CompressIoTDB的性能,論文進行了一系列詳盡的實驗評估。實驗設(shè)計覆蓋了真實世界數(shù)據(jù)集和多種變化的合成數(shù)據(jù)集,并與多個基線進行了對比。
實驗設(shè)置
- 基線方法:
1.Uncompressed:數(shù)據(jù)不進行任何壓縮,直接存儲和查詢。
2.IoTDB:原始的Apache IoTDB,采用“先解壓、后查詢”模式。
3.CompressIoTDB-NoLate:禁用了延遲解壓優(yōu)化的CompressIoTDB版本,用于評估該項優(yōu)化的具體貢獻。
-
數(shù)據(jù)集:使用了五個來自不同領(lǐng)域的真實世界數(shù)據(jù)集(天氣、電力、智能電網(wǎng)等)以及由標準測試工具IoT-benchmark生成的具有不同數(shù)據(jù)特征(重復(fù)率、數(shù)據(jù)規(guī)模)的合成數(shù)據(jù)集。
-
查詢負載:設(shè)計了10個代表真實應(yīng)用場景的查詢,涵蓋了過濾、聚合、表達式計算和窗口函數(shù)等多種操作。
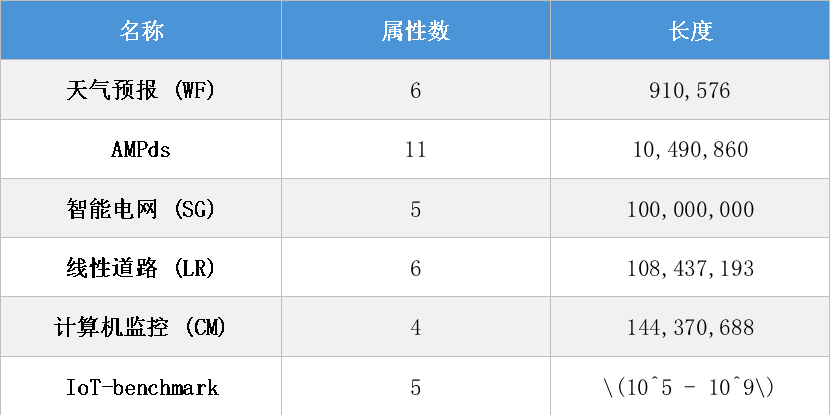
表 2:數(shù)據(jù)集

表 3:查詢
核心實驗結(jié)果
- 真實世界數(shù)據(jù)集上的總體性能
![信通院VLDB 2025論文圖17-20251028]()
圖 7:真實世界數(shù)據(jù)集上的延遲情況


圖 8:真實世界數(shù)據(jù)集的 CPR
在五個真實數(shù)據(jù)集上,CompressIoTDB表現(xiàn)出色,與原始IoTDB相比,平均查詢延遲降低了33.1%,即吞吐量提升了53.4%。與完全不壓縮的基線相比,也獲得了20.3%的延遲降低。實驗還發(fā)現(xiàn),性能提升的幅度與數(shù)據(jù)集的壓縮率(CPR)正相關(guān)(如圖8所示),數(shù)據(jù)壓縮得越好,同態(tài)查詢的優(yōu)勢越明顯。此外,延遲解壓優(yōu)化本身就貢獻了平均14.5%的延遲降低,證明了其有效性。
- 宏基準測試(IoT-benchmark)
![信通院VLDB 2025論文圖19-20251028]()
圖 9:不同重復(fù)率下的吞吐量


圖 10:不同序列長度數(shù)據(jù)集上的加速比

圖 11:多選擇性查詢的性能
注:數(shù)值表示相對于基線方法的加速比;“--” 表示超時情況。
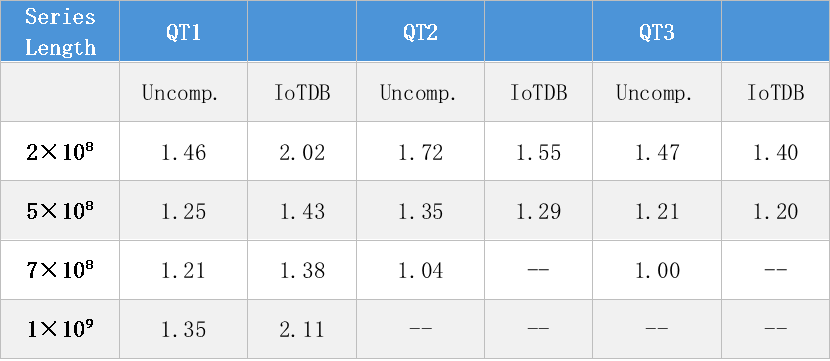
表 4:不同序列長度數(shù)據(jù)集的微觀分析
通過控制變量,實驗深入分析了系統(tǒng)在不同條件下的表現(xiàn):
1.不同重復(fù)率:如圖9所示,隨著數(shù)據(jù)重復(fù)率的提高,RLE編碼效率增加,CompressIoTDB的性能優(yōu)勢也隨之急劇增長,最高可比IoTDB快75.5%。

3.不同查詢選擇率:如圖11所示,在低選擇率(只查詢少量數(shù)據(jù))的查詢中,CompressIoTDB的優(yōu)勢最為明顯,最高可比IoTDB快42.9%。這主要歸功于延遲解壓策略,它避免了為獲取少量數(shù)據(jù)而解壓整個數(shù)據(jù)塊的巨大浪費。
- 微觀分析與消融研究
![信通院VLDB 2025論文圖24-20251028]()
圖 12:HintIndex 的影響


圖 13:執(zhí)行時間細分

表 5:CompColumn 的內(nèi)存使用量(GB)
為了探究性能提升的根本原因,實驗還進行了更細粒度的分析:
1.執(zhí)行時間分解:如圖13所示,CompressIoTDB在“數(shù)據(jù)塊讀取”階段(得益于傳輸壓縮數(shù)據(jù))和“算子執(zhí)行”階段(得益于同態(tài)計算)都取得了數(shù)量級的加速。雖然“系列掃描”階段因承擔了延遲解壓的任務(wù)而耗時占比增加,但其絕對時間仍遠低于IoTDB的總解壓時間。
2.HintIndex的有效性:如圖12所示,消融研究證實,HintIndex這一看似簡單的優(yōu)化平均帶來了11.7%的性能提升,證明了其在加速順序掃描中的重要作用。
3.內(nèi)存使用:如表5所示,CompColumn的內(nèi)存表示比IoTDB中解壓后的數(shù)據(jù)平均節(jié)省了20%的內(nèi)存空間,在數(shù)據(jù)重復(fù)率高時節(jié)省效果尤為顯著。
綜合所有實驗結(jié)果,論文從宏觀到微觀,從真實場景到極限測試,全方位地證明了CompressIoTDB框架在提升查詢性能、降低資源消耗和增強系統(tǒng)可擴展性方面的巨大優(yōu)勢。
九、結(jié)論與啟示
本文對《Improving Time Series Data Compression in Apache IoTDB》進行了深入解讀。該論文通過將同態(tài)壓縮理論創(chuàng)造性地應(yīng)用于時間序列領(lǐng)域,成功地解決了長期困擾TSDB的壓縮效率與查詢性能之間的內(nèi)在矛盾。
核心貢獻總結(jié)
1.提出時序同態(tài)查詢理論:首次為在壓縮時間序列數(shù)據(jù)上進行查詢構(gòu)建了形式化的理論模型,為系統(tǒng)的正確性和有效性提供了數(shù)學(xué)保證。
2.設(shè)計并實現(xiàn)CompressIoTDB框架:在Apache IoTDB中實現(xiàn)了一個端到端的同態(tài)查詢框架,展示了該理論在真實系統(tǒng)中的可行性與巨大潛力。
3.創(chuàng)造CompColumn數(shù)據(jù)結(jié)構(gòu):設(shè)計了CompColumn這一高效、模塊化的壓縮數(shù)據(jù)抽象,它成功地解耦了查詢邏輯與底層壓縮細節(jié),是整個系統(tǒng)得以實現(xiàn)的關(guān)鍵。
4.實現(xiàn)系統(tǒng)級優(yōu)化:通過動態(tài)輔助信息管理和延遲解壓等優(yōu)化,解決了空值、懶刪除、雙層壓縮等實際工程挑戰(zhàn),使系統(tǒng)在真實場景中表現(xiàn)穩(wěn)健。
這項工作的影響深遠。它不僅為Apache IoTDB帶來了顯著的性能提升(平均53.4%的吞吐量增長和20%的內(nèi)存節(jié)省),更重要的是,它為構(gòu)建新一代“壓縮感知”數(shù)據(jù)庫系統(tǒng)提供了一份寶貴的藍圖。論文中展示的架構(gòu)模式,特別是CompColumn的設(shè)計思想,具有很強的普適性,可以被借鑒到其他列式存儲或分析型數(shù)據(jù)庫中。
通過在理論、系統(tǒng)和工程實踐三個層面上的全面創(chuàng)新,CompressIoTDB描繪了一個未來,在這個未來中,數(shù)據(jù)可以始終以其最緊湊、最高效的形式存在于存儲、傳輸和計算的每一個環(huán)節(jié),從而將大規(guī)模數(shù)據(jù)分析的性能和效率推向一個新的高度。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號