
高性能計算-CUDA性能優化-transpose
1.介紹
- 對 2048 * 512 矩陣轉置,使用NCU進行性能分析,并進行性能優化。測試環境 CUDA 12.8,顯卡 5070。
2. Native: 二維 Block
- 二維block,一個線程處理一個元素
點擊查看代碼
//native:二維block,一個線程處理一個元素
//矩陣 M * N
template<uint32_t M,uint32_t N>
__global__ void kernel_transpose_native(float *arr,float *out)
{
uint32_t gidx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t gidy = blockIdx.y * blockDim.y + threadIdx.y;
if(gidx<N && gidy<M)
out[gidx*M+gidy] = arr[gidy*N+gidx];
}
- blockSize: 64 * 8

- 計算吞吐量 12.8% 和存儲 pipeline 吞吐量 49.5%;

- global 從 L1 數據讀入 4sector/request,一個warp 請求 128B,即 4sector,正常;
- 問題:global 寫入數據 32sector/request,一個warp 有 32個 sector,邏輯寫入數據量/物理寫入數據量=13107232B/104857632B,寫入效率只有 12.5%。
- 優化方案:考慮增加寫回數據的訪存合并度,減少 sector 數量。

- 目前未能解答:L2 與 DRAM 寫回數據為什么沒有數據流動??
3. 二維 Block + 共享內存
- 介紹:考慮到一次內存事務請求 128B,使用二維block(32,32),正好一個blcok讀取的數據可以增加緩存命中,數據放在共享內存
點擊查看代碼
//blocksize: BM * BN
template<uint32_t M,uint32_t N,uint32_t BM,uint32_t BN>
__global__ void kernel_transpose_SM(float *arr,float *out)
{
uint32_t tidx = threadIdx.x;
uint32_t tidy = threadIdx.y;
uint32_t gidx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t gidy = blockIdx.y * blockDim.y + threadIdx.y;
__shared__ float blockShared[BM][BN];
if(gidy<M && gidx<N)
{
blockShared[tidy][tidx] = arr[gidy*N+gidx];
__syncthreads();
out[gidx*M+gidy] = blockShared[tidy][tidx];
}
}
- 備注: 設置 native kernel 為baseline

- 計算單元吞吐量 14.3%,提升 11.62%;存儲 pipeline 吞吐量 30.2%,下降39%;SM active Cycle(SM至少有一個 active warp 的時鐘周期數量)提升 60.7%,其余指標都大幅降低。
- 分析:native blockSize 為 64 * 8=512,tile blockSize 為 32 * 32=1024 過大會導致 SM active Cycle 指標提升。
- 問題1:存儲吞吐指標下降。
- 問題2:耗時增加 63%。
-
共享內存數據讀進來只使用一次,沒有使用共享內存的必要;并且會帶來 bank conflict 問題,設置 block 8 * 8的 bank conflict情況嚴重于32 * 32的 baseline, 如下圖:

-
blockSize: (8, 8),使用共享內存作為 baseLine與不使用共享內存比較:
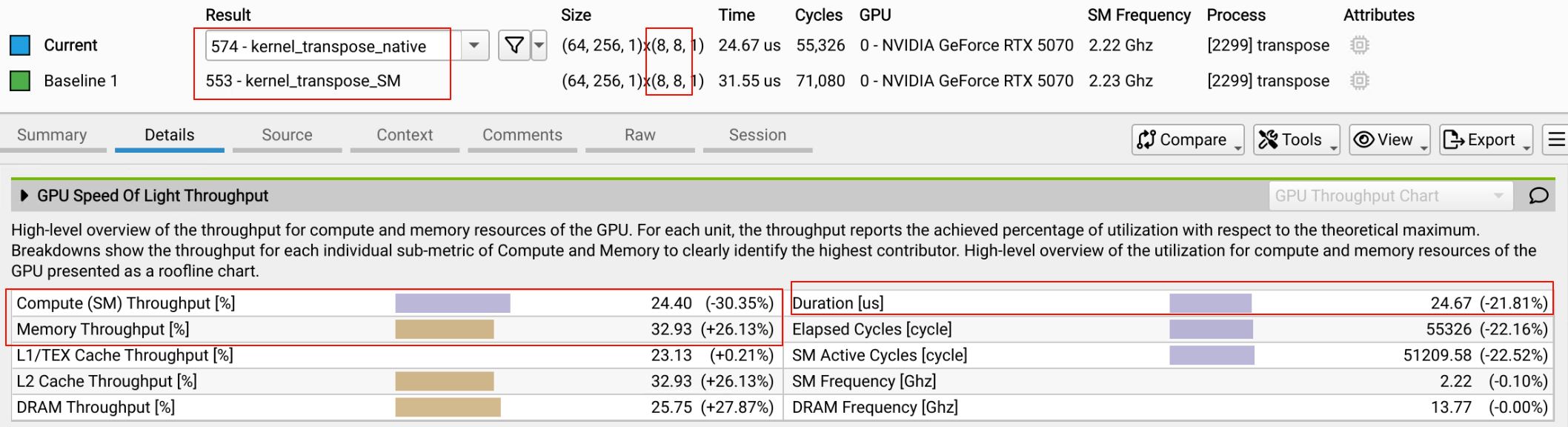
- 不使用共享內存耗時減少24%,計算單元吞吐量 24.4%,下降30%;存儲 pipeline 吞吐量 32.9%,提升 26%;
- 共享內存的 bank conflict 負面影響消除;
4. 二維 Block 不使用共享內存的對比測試
-
blockSize: (8, 8)對比(32, 32)的計算單元吞吐量 35.4%,提升148.8%;存儲 pipeline 吞吐量 34.58%,提升14.47%;性能大幅增加,應使用較小的 blocksize,增加并行度;如下圖:

-
blockSize: (8, 8)的數據寫回合并度大大增加,sectors 減少了75%,如下圖:

-
不同 blockSize的耗時對比:

- (8, 8) 效率最高
5. 二維Block + 線程Tile_float4
- warp shape 對讀寫單個物理 sector 利用率的影響:
- warp (8, 4) 排布:讀可以每個sector合并訪存;寫每個sector 有一半數據是多余的,每個sector 無法合并訪存;
- warp (4, 8) 排布:寫可以每個sector合并訪存;讀每個sector 有一半數據是多余的,每個sector 無法合并訪存。
- 為了實現讀寫單個物理 sector 的合并訪存,單個warp應在 X Y 兩個方向上都有 8(32B)的倍數個待處理數據,
- 實現了三個版本:
tile + float4, 源數據直接寫入目標地址: kernel_transpose_tile_FL4;
tile + float4, 使用寄存器中轉,每個線程獲取部分數據就寫入: kernel_transpose_tile_FL4_2;
tile + float4,, 使用寄存器中轉,每個線程獲取全部數據后再寫入,kernel_transpose_tile_FL4_3:
- 詳見代碼
點擊查看代碼
//強轉優先級大于 []
#define CAST_FLOAT4(pointer) reinterpret_cast<float4*>(pointer)
//2維block + tile(float4 單個線程處理 4*4 的數據)
//源數據直接寫入目標地址
//blocksize: BM * BN
template<uint32_t M,uint32_t N,uint32_t BM,uint32_t BN>
__global__ void kernel_transpose_tile_FL4(float *arr,float *out)
{
uint32_t gidx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t gidy = blockIdx.y * blockDim.y + threadIdx.y;
if(gidy<<2 <M && gidx<<2 <N)
{
//取源數據地址
float4 *srcTemp[4];
//循環獨立,可指令級并行
#pragma unroll
for(int i=0;i<4;i++)
srcTemp[i] = CAST_FLOAT4(arr+((gidy<<2) + i)*N + (gidx<<2));
//重組數據
CAST_FLOAT4(out+((gidx<<2))*M + (gidy<<2))[0] = make_float4(srcTemp[0]->x,srcTemp[1]->x,srcTemp[2]->x,srcTemp[3]->x);
CAST_FLOAT4(out+((gidx<<2)+1)*M + (gidy<<2))[0] = make_float4(srcTemp[0]->y,srcTemp[1]->y,srcTemp[2]->y,srcTemp[3]->y);
CAST_FLOAT4(out+((gidx<<2)+2)*M + (gidy<<2))[0] = make_float4(srcTemp[0]->z,srcTemp[1]->z,srcTemp[2]->z,srcTemp[3]->z);
CAST_FLOAT4(out+((gidx<<2)+3)*M + (gidy<<2))[0] = make_float4(srcTemp[0]->w,srcTemp[1]->w,srcTemp[2]->w,srcTemp[3]->w);
}
}
//二維block + tile(float4 單個線程處理 4*4 的數據)
//使用寄存器中轉數據的寫法
template<uint32_t M,uint32_t N,uint32_t BM,uint32_t BN>
__global__ void kernel_transpose_tile_FL4_2(float *arr,float *out)
{
uint32_t gidx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t gidy = blockIdx.y * blockDim.y + threadIdx.y;
if(gidy<<2 <M && gidx<<2 <N)
{
//取源數據
float srcTemp[4][4];
//循環獨立,可指令級并行
#pragma unroll
for(int i=0;i<4;i++)
CAST_FLOAT4(&srcTemp[i])[0] = CAST_FLOAT4(arr+((gidy<<2) + i)*N + (gidx<<2))[0];
//重組數據
float4 resultTemp[4];
#pragma unroll
for(int i=0;i<4;i++)
{
resultTemp[i] = make_float4(srcTemp[0][i],srcTemp[1][i],srcTemp[2][i],srcTemp[3][i]);
CAST_FLOAT4(out+((gidx<<2)+i)*M + (gidy<<2))[0] = resultTemp[i];
}
}
}
//二維block + tile(float4 單個線程處理 4*4 的數據)
//使用寄存器中轉數據的寫法,拆分循環
template<uint32_t M,uint32_t N,uint32_t BM,uint32_t BN>
__global__ void kernel_transpose_tile_FL4_3(float *arr,float *out)
{
uint32_t gidx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t gidy = blockIdx.y * blockDim.y + threadIdx.y;
if(gidy<<2 <M && gidx<<2 <N)
{
//取源數據
float srcTemp[4][4];
//循環獨立,可指令級并行
#pragma unroll
for(int i=0;i<4;i++)
CAST_FLOAT4(&srcTemp[i])[0] = CAST_FLOAT4(arr+((gidy<<2) + i)*N + (gidx<<2))[0];
//重組數據
float4 resultTemp[4];
#pragma unroll
for(int i=0;i<4;i++)
resultTemp[i] = make_float4(srcTemp[0][i],srcTemp[1][i],srcTemp[2][i],srcTemp[3][i]);
#pragma unroll
for(int i=0;i<4;i++)
CAST_FLOAT4(out+((gidx<<2)+i)*M + (gidy<<2))[0] = resultTemp[i];
}
}
- 每個kernel 執行4輪,blockSize(8,8),NC 總體數據如下:
- 第二種實現,每個線程獲取部分數據就寫入的計算單元和內存吞吐量較高。
- block 處理總數據量不變: 32 * 32,kernel_transpose_tile_FL4_2 計算單元吞吐量為25.5%,提升183%;內存吞吐量為52.7,提升39%。

- 每個kernel 執行4輪,blockSize(32,32),NC 總體數據如下:
- 仍是第二種實現的計算單元和內存吞吐量稍高。
- 對比kernel_transpose_tile_FL4_2,一個 block 處理數據從 1024 增加到 16384,計算單元吞吐量下降 34%,存儲吞吐量下降 22%,帶來了性能下降。

- 測試 block(8,4),結果強制分配為 block(8,8) [后經查閱,此處是默認值64,也可以修改blockSize的大小],blockSize 最小為64,結果如下圖:

- 仍是 block(8, 8)的耗時低 8% 。
6. 二維 Block + 線程tile_float2
- 以上線程tile處理 4 * 4 的數據,單個線程處理數據量較多,線程數較少,導致訪存延遲無法隱藏,考慮減少每個線程處理數據量;
- 實現:一個線程處理 (2, 2)的數據;
點擊查看代碼
//二維block + tile(float2 單個線程處理 2*2 的數據)
//使用寄存器中轉數據的寫法
template<uint32_t M,uint32_t N,uint32_t BM,uint32_t BN>
__global__ void kernel_transpose_tile_FL2(float *arr,float *out)
{
uint32_t gidx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t gidy = blockIdx.y * blockDim.y + threadIdx.y;
if(gidy<<1 <M && gidx<<1 <N)
{
//取源數據
float srcTemp[2][2];
//循環獨立,可指令級并行
#pragma unroll
for(int i=0;i<2;i++)
CAST_FLOAT2(&srcTemp[i])[0] = CAST_FLOAT2(arr+((gidy<<1) + i)*N + (gidx<<1))[0];
//重組數據
float2 resultTemp[2];
#pragma unroll
for(int i=0;i<2;i++)
{
resultTemp[i] = make_float2(srcTemp[0][i],srcTemp[1][i]);
CAST_FLOAT2(out+((gidx<<1)+i)*M + (gidy<<1))[0] = resultTemp[i];
}
}
}
- 與float4 版本比較相同 blockSize(8, 8),block 處理不同數據量的對比,如下圖:


- float2 比 float4 計算單元吞吐量提升 33%, 存儲 pipeline 吞吐量基本持平;DRAM 吞吐降低 35.8%;float2 耗時增加 27% ;
- 與float4 版本比較 block 處理相同數據量1024,float4 blockSize(8,8),float2 blockSize(16,16),如下圖:

- 單個block 處理相同數據量 float2 比 float4 耗時增加 44%;float2 計算單元和存儲 pipeline 吞吐量提升;DRAM 吞吐量下降 43%。
- 分析 float4 提升的主要原因是 DRAM 的吞吐量增加;
- float2 指令停滯指標有改善,最大影響因子 Stall Long Scoreboard 從 16 cycle 降低為 9.5 cycle。

6. 總結
- 使用較小的 blockSize 可以增加并行度;
- 使用不同的 blockSize 對讀寫訪存的 sector 利用率不一樣,應該做計算取合適的大小。
- 其他的優化方法:
- 單個線程處理 1row 2col;

 浙公網安備 33010602011771號
浙公網安備 33010602011771號