
高性能計算-GPU并行掃描(28)
1. 掃描概念
- 對數組arr[N]掃描就是得到數組prefix[N],每個元素是之前arr元素的求和.
- 開掃描定義:
prefix1[N] = { arr[0], arr[0]+arr[1], ..., arr[0]+arr[1]+arr[N-1] } - 閉掃描定義:
prefix2[N] = { 0, arr[0], arr[0]+arr[1], ..., arr[0]+arr[1]+arr[N-12}
2. Hillis steele 掃描算法
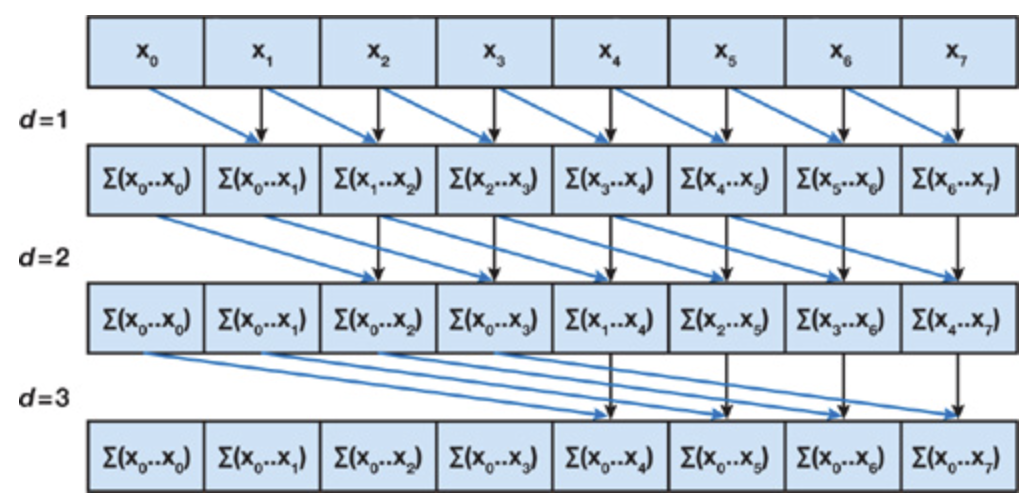
(1)一種閉掃描算法。基礎的Hillis steele 掃描算法只能掃描單塊,步驟復雜度為 O(logN),任務復雜度為 O(N*logN-(N-1)).
(2)基礎版算法介紹:假設步長為s每次迭代 >=s的線程參與計算,本線程id作為被加數,往前 -s 索引為加數
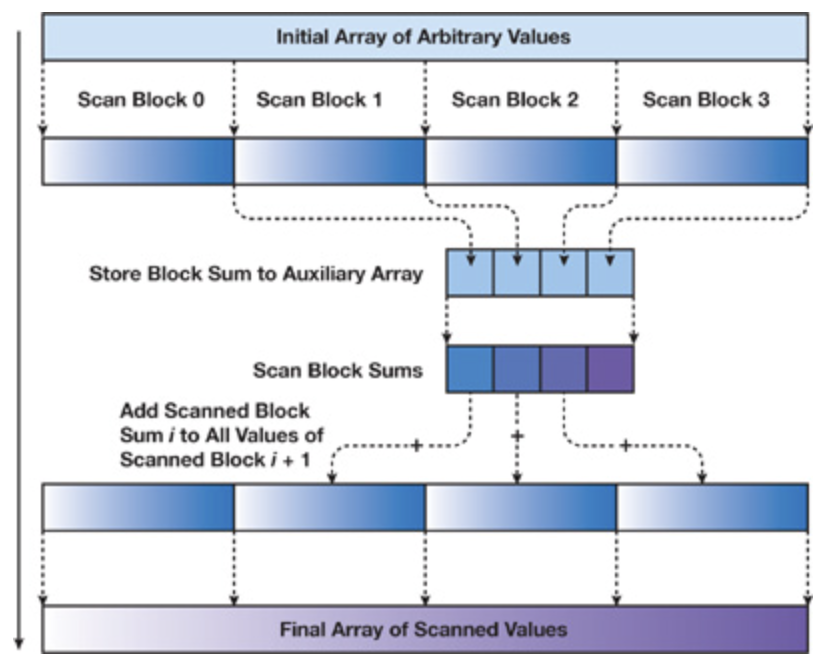
(3)支持任意block倍數長度的數據輸入,介紹:a) 掃描block:按blocksize劃分數據,每個block處理一個數據塊,塊內進行掃描,輸出規約結果數組,并將最后一個塊內和元素按 blockid 保存到輔助數組;
b) 遞歸閉掃描輔助數組:遞歸為了將塊內求和輔助數組的結果加到塊內掃描結果上,需要掃描輔助數組,如果輔助數組大于256那么要考慮輔助數組遞歸掃描;直到輔助數組被掃描求和數組block為1,掃描結束,反向依次彈棧把求和數組加到 block+1 的掃描結果數組上。
(4)優化:共享內存使用雙buffer,讀寫分離,避免讀寫 bank沖突
(5)代碼:
/*
任意長度掃描,單塊掃描使用Hillis Steele算法,使用double buffer避免讀寫bank沖突;默認輸入數據長度是blockSize的倍數
*/
#include "common.h"
#include <stdio.h>
#define BlockSize 512
//單塊掃描函數, in 輸入數據, out 掃描結果, len1 掃描數據長度,sum block求和數組,len2 sum數組大小
__global__ void kernel_BlockScan(int *in,int * out,int len1,int *sum,int len2)
{
//取單塊數據到共享內存,使用雙buffer,讀寫分離,避免讀寫bank沖突
__shared__ int arrShared[2*BlockSize];
int bid = blockIdx.x; //塊id
int tid = blockIdx.x * blockDim.x + threadIdx.x; //全局線程id
int tbid = threadIdx.x; //塊內線程id
int write = 0; //初始化第0個buff write
int read = 1; //初始化第1個buff read
if(tid<len1)
{
//共享內存read buffer數據初始化
arrShared[read*BlockSize + tbid] = in[tid];
__syncthreads();
for(int s=1;s<BlockSize;s<<=1)
{
// Hillis Steele算法:索引大于步長的線程參與計算,對應位置上的倍加數+塊內前面步長位置的加數
if(tbid>=s)
{
//被加數索引
int id = read*BlockSize + tbid;
arrShared[write*BlockSize + tbid] = arrShared[id] + arrShared[id -s];
}
else//否則保留上一輪計算的前綴和
arrShared[write*BlockSize + tbid] = arrShared[read*BlockSize + tbid];
//每循環一次,讀寫buffer區域交換
__syncthreads();
write = 1 - write;
read = 1- read;
}
// 將block計算結果賦值給out
out[tid] = arrShared[read*BlockSize + tbid];
//將塊內求和按塊索引號放求和數組
if(tbid==(BlockSize-1))
sum[bid] = arrShared[read*BlockSize + tbid];
}
}
//對第一輪掃描結果后處理函數,len 數據總長度
__global__ void handPost(int* first,int len,int *second)
{
int tid = blockDim.x * blockIdx.x + threadIdx.x;
int bid = blockIdx.x;
int tbid = threadIdx.x; //塊內線程id
//從第二塊開始加上前一個塊的sum值
if(bid>0 && tid<len)
{
//取出被加數
__shared__ int temp;
if(tbid==0)
temp = second[bid-1];
__syncthreads();
first[tid] += temp;
}
}
//輸入分塊掃描分配及后處理函數,輸出結果的空間在外面分配
//這里第一二輪掃描都使用該函數遞歸調用,n輸入數據長度
void scan(int *in,int *arrResult,int n)
{
int GridSize = (n-1)/BlockSize + 1;
printf("gridSize:%d\n",GridSize);
int *arrResultFirstSum;
CudaSafeCall(cudaMalloc((void**)&arrResultFirstSum,GridSize*sizeof(int)));
kernel_BlockScan<<<GridSize,BlockSize,2*BlockSize*sizeof(int)>>>(in,arrResult,n,arrResultFirstSum,GridSize);
CudaCheckError();
//循環掃描遞歸終止條件:假如第一次掃描gridsize=4096大于256,組要循環掃描到 gridsize==1,block的和需要被handpost處理累加到后面
if(GridSize==1)
{
cudaFree(arrResultFirstSum);
return;
}
//遞歸掃描:對本輪計算結果和的數組進行掃描
int *arrResultSecond;
//cudaMalloc 隱式同步
CudaSafeCall(cudaMalloc((void**)&arrResultSecond,GridSize*sizeof(int)));
scan(arrResultFirstSum,arrResultSecond,GridSize);
//空流核函數隱式同步
// cudaDeviceSynchronize();
//將本輪掃描結果數組的索引+1作為第一次掃描結果按blockIdx.x的索引作為塊內掃描結果的加數,得到最終掃描結果arrResult
handPost<<<GridSize,BlockSize,sizeof(int)>>>(arrResult,n,arrResultSecond);
CudaCheckError();
//cudafree是隱式同步
CudaSafeCall(cudaFree(arrResultFirstSum));
CudaSafeCall(cudaFree(arrResultSecond));
return;
}
int main(int argc ,char** argv)
{
int N = 1<<20; //數據規模
if(argc>1)
N = 1 << atoi(argv[1]);
//cpu串行計算
int *arrHost = (int*)calloc(N,sizeof(int));
int *resultHost = (int*)calloc(N,sizeof(int));
int *resultFD = (int*)calloc(N,sizeof(int));
float cpuTime = 0.0;
initialDataInt(arrHost,N);
double start = cpuSecond();
//閉掃描
//初始化第一個元素,避免循環內有判斷,cpu分支預測錯誤
resultHost[0] = arrHost[0];
for(int i=1;i<N;i++)
resultHost[i] = resultHost[i-1] + arrHost[i];
double end = cpuSecond();
cpuTime = (end - start)*1000;
//gpu計算
int *arrD;
int *resultD;
float gpuTime = 0.0;
CudaSafeCall(cudaMalloc((void**)&arrD,N*sizeof(int)));
CudaSafeCall(cudaMalloc((void**)&resultD,N*sizeof(int)));
cudaEvent_t startD,endD;
CudaSafeCall(cudaEventCreate(&startD));
CudaSafeCall(cudaEventCreate(&endD));
CudaSafeCall(cudaMemcpy(arrD,arrHost,N*sizeof(int),cudaMemcpyHostToDevice));
cudaEventRecord(startD);
scan(arrD,resultD,N);
CudaCheckError();
cudaEventRecord(endD);
cudaEventSynchronize(endD);
CudaSafeCall(cudaMemcpy(resultFD,resultD,N*sizeof(int),cudaMemcpyDeviceToHost));
cudaEventElapsedTime(&gpuTime,startD,endD);
cudaEventDestroy(startD);
cudaEventDestroy(endD);
//結果比對
checkResultInt(resultHost,resultFD,N);
free(arrHost);
free(resultHost);
free(resultFD);
CudaSafeCall(cudaFree(arrD));
CudaSafeCall(cudaFree(resultD));
printf("數據規模 %d kB,cpu串行耗時 %.3f ms ;gpu 單個block使用Hillis Steele 掃描(double buffer)計算耗時 %.3f ms,加速比為 %.3f .\n",N>>10,cpuTime,gpuTime,cpuTime/gpuTime);
return 0;
}
3. Blelloch掃描算法
(1)一種開掃描算法。基礎的 Blelloch掃描算法,只能處理單塊數據。步驟復雜度為 O(2logN),任務復雜度為 O(2N)。
(2)基礎版算法介紹:a) 規約:對塊進行規約,每次循更新計算結果的位置的數值,其他數值不變。
b) 清零和散出:
- 清零:最后一個元素置為0
- 散出:假設數據長度為blocksize ,迭代循環步長為 s = blocksize/2 ,最后一個元素 E1,與向前s的元素 E2相加,結果放在 E1位置,并將原數據 E1放在 E2位置;每輪循環步長減半。


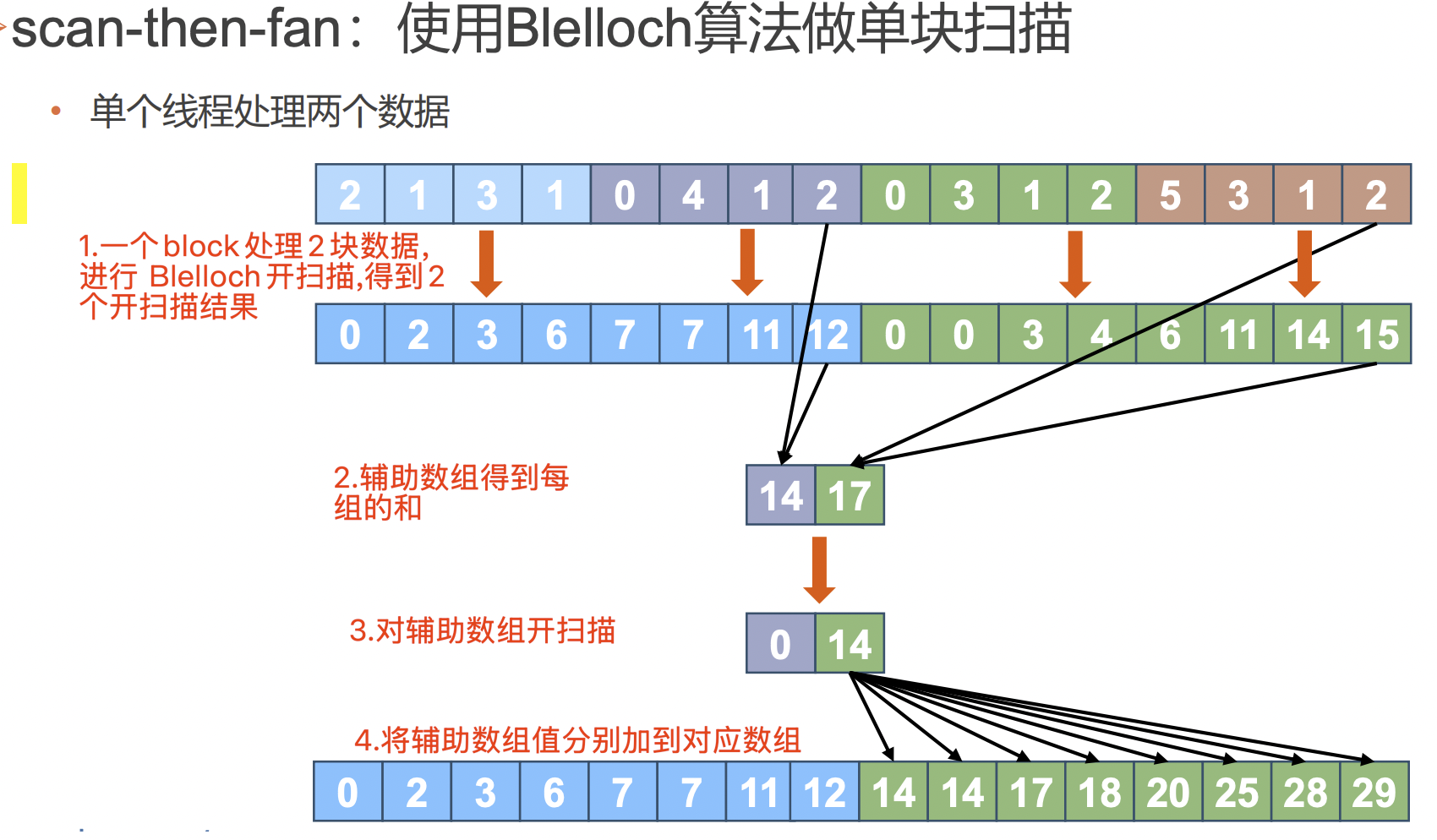
(3)支持任意block倍數長度的數據輸入,介紹:
a)開掃描block:按blocksize劃分數據,每個block處理一個數據塊,塊內進行掃描,輸出前綴和和塊內求和結果輔助數組
b) 遞歸開掃描輔助數組:遞歸為了將塊內求和輔助數組的結果加到塊內掃描結果上,需要掃描輔助數組,如果輔助數組大于256那么要考慮輔助數組遞歸掃描;直到輔助數組被掃描求和數組block為1,掃描結束,反向依次彈棧把求和數組加到對應 block前綴數組上(此處與Hillis steele不同)。
(4)優化
- 塊內共享內存每個warp后添加一個padding位,避免訪存 bank沖突
- 掃描核函數內規約和散出階段根據步長計算需要線程的數量,只讓小于該數量的塊內線程id參與計算
(5)代碼
/*
使用blelloch 算法對任意長度(blocksize的倍數)做開掃描
// 優化:
1.存放數據:共享內存每32個數據添加一個padding,避免 bank沖突;
2.讀取數據:handPost 現成處理的數據
3.掃描核函數內規約和散出階段根據步長計算需要線程的數量,只讓小于該數量的塊內線程id參與計算
*/
#include "common.h"
#include <stdio.h>
#define BlockSize 512
#define WarpSize 32
#define ADD_PADDING_MEM(A) ((A)+((A)>>5)) //根據原數據的索引計算機padding 后的索引;或者輸入原數據大小,獲取padding后的大小
//單塊掃描函數, in 輸入數據, out 掃描結果, len1 掃描數據長度,sum block求和數組,len2 sum數組大小
__global__ void kernel_BlockScan(int *in,int * out,int len1,int *sum,int len2)
{
int bid = blockIdx.x;
// int tid = blockIdx.x * blockDim.x + threadIdx.x;
int btid = threadIdx.x;
//取數據到共享內存,一個塊計算2個快的數據
//優化:每32個數據添加一個padding數據位,防止bank沖突
__shared__ int arrShared[ADD_PADDING_MEM(2*BlockSize)];
//每個線程取第一個數
if(2*(BlockSize*bid+btid) < len1)
arrShared[ADD_PADDING_MEM(2*btid)] = in[2*(BlockSize*bid+btid)];
//取第二個數
if(2*(BlockSize*bid+btid)+1 < len1)
arrShared[ADD_PADDING_MEM(2*btid+1)] = in[2*(BlockSize*bid+btid)+1];
//保留最后一個值,避免最后再次訪存
int lastValue = 0;
//如果用其他線程保存數據,應先同步,保證最后一個線程訪存之后再保存
if(btid == BlockSize-1)
lastValue = arrShared[ADD_PADDING_MEM(2*BlockSize-1)];
__syncthreads();
//規約
//優化:減少線程束分化,由于計算的結果保存原共享內存,計算數據的位置分配計算線程從0號開始,將計算結果放入對應位置,節約了線程束的需求
for(int s=1;s<=BlockSize;s<<=1)
{
//根據步長計算本輪需要的線程數量
if(btid<(2*BlockSize)/(2*s))
{
// 根據步長和計算線程索引,得到被加數索引
int index = 2*s*(btid+1)-1;
//減少線程束優化,根據需要的線程數量
if(index<2*BlockSize)
arrShared[ADD_PADDING_MEM(index)] += arrShared[ADD_PADDING_MEM(index-s)];
}
//防止空閑線程進行下一輪計算
__syncthreads();
}
//最后一個結果清0
if(btid == 0)
arrShared[ADD_PADDING_MEM(2*BlockSize-1)] = 0;
__syncthreads();
// down sweep
for(int s=BlockSize;s>0;s>>=1)
{
//根據步長計算本輪需要的線程數量
if(btid<(2*BlockSize)/(2*s))
{
//根基 btid和步長計算出被加數索引
int index = 2*s*(btid+1)-1;
int addSecondIndex = ADD_PADDING_MEM(index);
int addFirstIndex = ADD_PADDING_MEM(index-s);
int temp = arrShared[addSecondIndex];
arrShared[addSecondIndex] += arrShared[addFirstIndex];
arrShared[addFirstIndex] = temp;
}
//防止空閑線程進行下一輪計算
__syncthreads();
}
//保存開掃描結果
//保存線程對應第一個位置數據
int addFirstIndex = 2*(bid*BlockSize+btid);
int addSecondIndex = addFirstIndex+1;
out[addFirstIndex] = arrShared[ADD_PADDING_MEM(2*btid)];
out[addSecondIndex] = arrShared[ADD_PADDING_MEM(2*btid+1)];
//block求和結果放入輔助數組
if(btid == BlockSize-1)
sum[bid] = lastValue + arrShared[ADD_PADDING_MEM(2*BlockSize-1)];
}
//對第一輪掃描結果后處理函數,len 數據總長度
__global__ void handPost(int* first,int len,int *second)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int btid = threadIdx.x;
int bid = blockIdx.x;
int wid = tid/WarpSize; //warpid
int wtid = tid%WarpSize; //warp內線程id
//開掃描輔助數組第一個值為0,該索引塊不參與計算
if(bid>0)
{
//這里有bank沖突:如果一個線程處理相鄰數據,0和16線程在bank0和bank1雙路沖突
//優化: 一個warp計算兩個warp大小的數據,一個線程取的兩個數據偏移warp大小,可以避免bank沖突
__shared__ int secondValue;
if(btid==0)
secondValue = second[bid];
__syncthreads();
first[wid*2*WarpSize+wtid] += secondValue;
first[wid*2*WarpSize+wtid+WarpSize] += secondValue;
}
//沒有依賴可以不同步
}
//輸入分塊掃描分配及后處理函數,輸出結果的空間在外面分配
//這里第一二輪掃描都使用該函數遞歸調用,n輸入數據長度
void scan(int *in,int *arrResult,int n)
{
int GridSize = (n-1)/(2*BlockSize) + 1;
// printf("gridSize:%d\n",GridSize);
int *arrResultFirstSum;
CudaSafeCall(cudaMalloc((void**)&arrResultFirstSum,GridSize*sizeof(int)));
kernel_BlockScan<<<GridSize,BlockSize,ADD_PADDING_MEM(2*BlockSize)*sizeof(int)>>>(in,arrResult,n,arrResultFirstSum,GridSize);
CudaCheckError();
//循環掃描遞歸終止條件:假如第一次掃描gridsize=4096大于256,組要循環掃描到 gridsize==1,block的和需要被handpost處理累加到后面
if(GridSize==1)
{
cudaFree(arrResultFirstSum);
return;
}
//二次掃描:對本輪計算結果和的數組進行開掃描
int *arrResultSecond;
//cudaMalloc 隱式同步
CudaSafeCall(cudaMalloc((void**)&arrResultSecond,GridSize*sizeof(int)));
scan(arrResultFirstSum,arrResultSecond,GridSize);
//空流核函數隱式同步
// cudaDeviceSynchronize();
//將二輪開掃描結果按數組索引加到對應索引塊的第一輪掃描結果上,得到最終掃描結果arrResult
handPost<<<GridSize,BlockSize,sizeof(int)>>>(arrResult,n,arrResultSecond);
CudaCheckError();
//cudafree是隱式同步
CudaSafeCall(cudaFree(arrResultFirstSum));
CudaSafeCall(cudaFree(arrResultSecond));
return;
}
int main(int argc ,char** argv)
{
int N = 1<<20; //數據規模
if(argc>1)
N = 1 << atoi(argv[1]);
//cpu串行計算
int *arrHost = (int*)calloc(N,sizeof(int));
int *resultHost = (int*)calloc(N,sizeof(int));
int *resultFD = (int*)calloc(N,sizeof(int));
initialDataInt(arrHost,N);
double start = cpuSecond();
//閉掃描
//初始化第一個元素,避免循環內有判斷,cpu分支預測錯誤
resultHost[0] = 0;
for(int i=1;i<N;i++)
resultHost[i] = resultHost[i-1] + arrHost[i-1];
double cpuTime = (cpuSecond()-start)*1000;
//gpu計算
int *arrD;
int *resultD;
float gpuTime = 0.0;
CudaSafeCall(cudaMalloc((void**)&arrD,N*sizeof(int)));
CudaSafeCall(cudaMalloc((void**)&resultD,N*sizeof(int)));
cudaEvent_t startD,endD;
CudaSafeCall(cudaEventCreate(&startD));
CudaSafeCall(cudaEventCreate(&endD));
CudaSafeCall(cudaMemcpy(arrD,arrHost,N*sizeof(int),cudaMemcpyHostToDevice));
cudaEventRecord(startD);
scan(arrD,resultD,N);
CudaCheckError();
cudaEventRecord(endD);
cudaEventSynchronize(endD);
CudaSafeCall(cudaMemcpy(resultFD,resultD,N*sizeof(int),cudaMemcpyDeviceToHost));
cudaEventElapsedTime(&gpuTime,startD,endD);
cudaEventDestroy(startD);
cudaEventDestroy(endD);
//結果比對
checkResultInt(resultHost,resultFD,N);
free(arrHost);
free(resultHost);
free(resultFD);
CudaSafeCall(cudaFree(arrD));
CudaSafeCall(cudaFree(resultD));
printf("數據規模 %d kB,cpu串行耗時 %.3f ms ;gpu 單個block使用Blelloch 掃描計算耗時 %.3f ms,加速比為 %.3f .\n",N>>10,cpuTime,gpuTime,cpuTime/gpuTime);
return 0;
}
4. 測試數據
| 掃描算法 | 串行(ms) | gpu并行(ms) | 加速比 |
|---|---|---|---|
| Hillis steele (0.1M數據) | 0.003 | 0.2 | 0.015 |
| Blelloch (0.1M數據) | 0.005 | 0.131 | 0.038 |
| thrust庫 (0.1M數據) | - | 0.16 | 0.025 |
| Hillis steele (1M數據) | 5.363 | 1.947 | 2.754 |
| Blelloch (1M數據) | 5.593 | 2.047 | 2.732 |
| thrust庫 (1M數據) | - | 0.39 | 13.850 |
| Hillis steele (25M數據) | 146.608 | 10.376 | 14.129 |
| Blelloch (25M數據) | 149.882 | 11.981 | 12.510 |
| thrust庫 (25M數據) | - | 0.62 | 238.000 |
備注:thrust 的時間包主機與GPU的內存拷貝,測試代碼不包含內存拷貝耗時。
5. 結果分析
(1) Hillis steele 比 Belloch掃描算法的效率分析,Hillis steele的任務復雜度大于Blelloch,Blelloch的步驟復雜度大于Hillis steele:
掃描算法 步驟復雜度 任務復雜度 Hillis steele O(logN) O(N*logN-(N-1)) Blelloch O(2logN) O(2N)
(2) 耗時分析
- 當數據量較小時串行效率最高,
- 當數據量較大時 Hillis steele 比 Belloch算法更高效,并且cuda thrust的效率極高
(3) 算法選擇策略:
- 理論上:當數據規模大于核心數量時,應選用任務總量少,步驟多的算法比如 Blelloch ;當數據規模小于核心數量時應選用計算任務總量多,將計算分攤到更多的核心上,步驟少的算法比如 Hillis steele。
- 實際測試中:無論數據規模大還是小 Hillis steele 都比 Belloch 算法高效,使用 nvprof 分析后發現 Belloch 掃描核函數的步驟過多,對效率影響較大,應進一步改進。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號