
你的ChatBI(問數)準確率不到50%?帶你深度拆解90%準確率的高德ChatBI案例
 看完你就會明白,那些準確率90%的ChatBI產品,背后到底做對了什么。
看完你就會明白,那些準確率90%的ChatBI產品,背后到底做對了什么。
"我們的ChatBI上線半個月,準確率不到50%,老板問我們是不是在做假demo..."
如果你在做ChatBI,或正在評估要不要上ChatBI,相信你遇到過類似問題。
很多團隊以為"ChatBI就是用大模型做自然語言到SQL的轉換"。
有時還會被領導質疑:"找個開源項目3天就能搞定,你們怎么用了這么久?"
幾度陷入自我懷疑…
要知道,單純依賴開源項目做ChatBI,就像指望買輛車就能參加F1比賽。
前不久我研究了高德準確率接近90%的ChatBI方案,和他們對另外10%的完整兜底方案。
這篇文章不僅帶你掃盲ChatBI的基礎,還會帶你深度拆解高德案例。
告訴你為什么只靠text2sql注定走不通,以及如何構建真正可用的ChatBI系統。
看完你就會明白,那些準確率90%的ChatBI產品,背后到底做對了什么。
做了這么多ChatBI項目,我發現:很多人對ChatBI的理解有偏差。
ChatBI分為Chat和BI。
BI,Business Intelligence。
大家第一反應都是"商業智能",高大上,但太抽象。
Business,除了"商業",也指"業務"。
學校有學校的業務,政府有政府的業務,都算Business。
Intelligence除了"智能",還有"情報"的意思。
比如C.I.A,
所以我更傾向于把BI理解為"業務情報"。
情報的本質是提供"洞察",那業務情報的本質就是提供"業務洞察"。比如:
電商平臺的運營人員,每天面對海量的銷售數據、用戶行為數據。
如果只盯著這些原始數據看,很難發現什么規律。
BI系統對這些數據做"采集、存儲、處理"等一系列處理,最后生成可視化圖表。
運營就能發現:哪個品類表現突出、哪個渠道轉化率下滑、用戶什么時間最活躍。
這些發現,就是業務洞察。
BI是"通過業務情報,輔助人獲得業務洞察的系統",Chat是"聊天",
因此,ChatBI是"通過聊天的方式來獲取業務洞察的系統"。
傳統BI只能看圖表,ChatBI可以直接聊。
以往,使用傳統BI,業務部門想了解數據,得找技術部門:
業務:"幫我做個報表,看看上月各品類銷售情況。"
技術:"好,明天給你。"
業務:"我很急…"
技術:"大家都很急…你們pk看誰更急…"
業務:"…"
現在通過ChatBI,業務直接問系統:"上月哪個品類賣得最好?",系統立即給出答案和相關圖表。
但關鍵在這里:別把ChatBI簡單理解為"自然語言查數據庫"或者"text2sql"。
Chat是使用BI成果的交互方式,真正決定業務洞察效果的,還是背后的BI能力。
數據治理做得怎么樣?指標體系建得是否合理?這些基礎工作才是關鍵。
與其把精力都放在text2sql的技術實現上,不如多花點時間在數據基礎建設上。
畢竟,再智能的對話交互,也無法從混亂的基礎數據中,給出你滿意的答案。
ChatBI從來不只text2sql,真正的挑戰在BI。
每年年初,公司各部門都會提數據分析需求。
市場部:"我要看每個省份門店銷售排行、同比增長、客流變化。"
運營部:"做個庫存預警儀表盤,超7天未動銷要提醒。"
聽起來合理,但這些需求通過郵件、OA、例會,零散匯集到IT部門后,問題就來了。BI項目經理要和數據分析師開需求評審會:梳理優先級、指標定義、可行性...光是怎么算"同比增長",就能討論半天。
需求討論后,數據工程師要去各系統找數據。
"訂單、銷售明細→ POS系統"
"門店、商品信息→ ERP系統"
"會員活躍度→ CRM系統"
"庫存變動→ WMS系統"
這里稍微微解釋一下這幾個系統的作用:
POS系統:處理門店收銀和銷售交易,記錄每筆買賣
ERP系統:統一管理企業核心資源,如商品、門店、財務、采購等基礎信息
CRM系統:管理客戶資料、消費行為、會員等級和營銷活動,提升客戶忠誠度
WMS系統:管理商品入庫、出庫、庫存和倉庫作業,確保庫存準確高效
每個系統數據庫結構不同,接口文檔也不都齊全。
數據工程師要一個個對接,整理表名、字段含義。
然后開發ETL腳本:凌晨4點定時任務,從源系統抽取數據,第一次全量,后續增量,存入數據倉庫。
然后,真正的問題才剛剛開始。
數據搬過來發現:訂單表有重復,產品編碼歷史上變更過,時間格式不統一,某些字段為空...臟數據層出不窮。
數據開發團隊要用SQL腳本清洗:去重、補全、類型統一、邏輯校驗。每步都要小心,生怕出錯。
還要分層管理,ODS、DWD、DWS、ADS...光記住這些縮寫就夠頭疼。

改一個字段,影響十幾個下游表是常事。
BI建模師要設計主題數據模型。
比如"地區-門店-商品-日期"四維度銷售事實表,配上商品、門店、員工維表。
還要定義指標口徑:"銷售額=售價×數量-折扣"。別小看這個公式,光"折扣"怎么計算,業務方就能爭論好幾輪。
有經驗的建模師會預留擴展字段,因為他們知道:業務需求永遠在變。
BI工程師開發可視化報表
比如,銷售排行TOP10、品類趨勢、庫存預警...
設計初版后收集業務反饋,然后反復改:
"這個顏色不好看"、"能加個篩選條件嗎"、"響應能快點嗎"...
每次修改都要重新測試,確保不影響其他功能。
上線后還要設置定時任務:每日凌晨跑腳本生成日報,月初匯總推送管理層...
你以為這就結束了?這只是開始。
比如,區域經理:"報表數據異常,銷售額平時幾萬今天只有幾十。"
數據團隊排查發現:"業務系統同步延遲,統計時數據不完整。"
然后和業務IT調整同步策略。
比如,業務部門又有新需求,BI團隊評估排期,然后整個流程重新再走一遍。
以上,總結出BI本身的主要流程如下:
1、業務部門提出數據分析需求。
2、數據工程團隊定期或實時采集業務系統數據,清洗后統一入數倉。
3、數據分析團隊與業務部門反復溝通,基于實際業務場景定義標準的數據模型、指標及統計口徑。
4、BI開發團隊基于這些模型開發和迭代報表、儀表盤,過程中持續收集業務反饋。
5、最終,通過自動化調度實現報表數據的定期或實時更新,保障各層級數據使用人員及時掌握業務動態。
6、BI團隊、數據團隊繼續接受隨時提出的反饋,排查問題、評估新需求能否實現、排期…
這就是傳統BI:責任分工清晰,流程規范,但嚴重依賴人工,自動化有限。
很多時候,業務真正想要的是"告訴我銷售為什么下降了?",或者了解一下"某個指標是如何統計的?"
但得到的卻是一堆需要自己解讀的圖表,指標統計口徑更是只有問技術人員才能知道,而技術人員不是那么有空的。
而ChatBI的出現,讓我們終于可以用聊天的方式和數據交流。
不用記術語、操作步驟,不需要等長開發周期,像和朋友聊天一樣說出疑問,就能得到答案。
這是從"人適應工具"到"工具理解人"的轉變。
ChatBI帶來的新可能
以前:寫需求郵件→ 開例會解釋 → 你說A我聽成B → 再拉人解釋
現在:直接問"本月庫存報警最多的門店有哪些?" → 10秒內得到報表和分析
以前開發新報表要排隊半個月,現在簡單的數據探索、圖表調整、指標變換,只要會打字就行。
想換個角度?隨時切換:"去年和今年差異最大的省份是哪個?"AI立即幫你做趨勢對比。
以前BI報表滿屏專業詞匯縮寫,業務同事經常問"這活躍用戶到底怎么算的?"
現在ChatBI能把復雜指標翻譯成人話,業務小白也能看懂。
遇到臨時想法,不用寫需求文檔排隊,提出來立馬有反饋。這對業務效率的提升是肉眼可見的。
ChatBI讓我們終于能用"人話"和數據對話了。
ChatBI還做不了什么?
數據基礎設施仍需人工。比如,后臺數據接口對接、源頭數據質量治理、表字段歷史變更梳理、源系統更新適配。
AI不可能憑空變出你想要的數據,底層的硬活臟活,還得有人干。
企業級建模需要專家。比如,復雜的數據倉庫建模、跨部門數據定義標準、業務規則的最終拍板。
每家企業業務都不同,AI能建議,但最終決策還得人來做。
權限安全必須人工把控。比如,數據訪問權限設計、不同用戶可見范圍控制、數據安全策略制定。
數據絕不能"放飛自我",這塊AI幫不上忙。
ChatBI讓數據分析變得"接地氣"了,每個人都能隨手問、天天用,探索的主動權回到業務手里。但基礎設施和數據治理這些"水電煤",還得靠專業團隊。只有兩邊配合,企業才能真正享受到聊天式分析的敏捷體驗。
ChatBI不是替代數據團隊,而是他們數據治理成果的價值放大器。
ChatBI自身面臨的挑戰
即使BI基礎已經做得很好,想實現ChatBI,仍然要解決這些技術難題:
數據規模
企業級BI系統動輒幾百上千張表,每張表幾十上百個字段。
這些信息全塞給大模型?就算最新的長上下文模型也會消化不良。
時間語義
用戶說"近三年"、"去年同期"、"今年Q1",人類很容易理解,但讓系統準確解析就復雜了。
時間基準點、業務日歷、財務年度...這些都需要準確建模。
專業術語
每個行業、每家公司都有自己的"黑話":財務說"應收賬款周轉率"、銷售說"漏斗轉化"、運營說"留存曲線"。
這些概念背后往往有復雜的計算邏輯和業務規則。
我見過一個零售企業,光"有效客戶"就有三套不同定義,分別用于不同業務場景。
實體對齊
用戶說"北京地區",數據庫里存的可能是:"110000"(行政編碼)、"Beijing"(英文)、"BJ"(簡稱)。
用戶說"小米手機",系統里可能是"MI_PHONE"或品牌編碼"1001"。
多系統集成環境下,同一概念在不同系統中表示方式完全不同。
復雜推理
最難的是復雜查詢推理。
用戶問"哪個地區的高價值客戶增長最快",系統需要:
-定義"高價值客戶"標準
-跨客戶表、訂單表、地區表關聯查詢
-計算不同時間段增長率
-排序篩選結果
這種多步推理對模型邏輯能力要求很高,每一步出錯都影響最終結果。
ChatBI的核心難點不在Chat,而在于如何讓機器真正理解業務。
技術棧可以選擇,算法可以優化,但業務理解需要時間積累和不斷調試。
這也是為什么很多團隊選擇先從簡單查詢開始,逐步擴展到復雜分析。
不要指望一上來就做到100%準確率,先解決60%的常見查詢,剩下的再找方案,但必須找方案。
以上,科普部分就這么多。我終于可以開始聊高德是如何做到90%的準確率了。
高德團隊認為:"沒有一步到位的完美方案,不要想著一上來就解決所有問題。"
他們用"靈活性"和"復雜度"兩個維度,將業務場景分成四個象限:
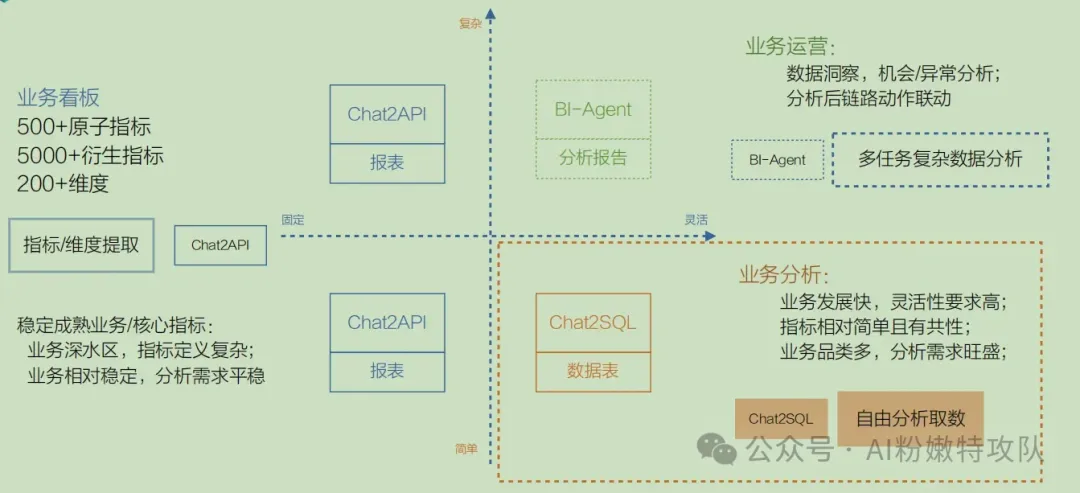
固定場景(第二、三象限)用Chat2API
Chat2SQL在復雜的指標統計下,會涉及"多表關聯","嵌套查詢","復雜計算公式",導致生成正確sql的概率很低。
Chat2API將復雜邏輯封裝在后端服務中,還可通過緩存提高響應速度,對外接口往簡單去設計,提高生成正確接口參數的概率。
不管簡單還是復雜,業務穩定的場景都用Chat2API。
靈活簡單場景(第四象限)用Chat2SQL
比如,臨時增加的指標,雖然沒有提前存儲,但可簡單統計得出,則使用Chat2SQL。
如果用Chat2API,則每次需求變化都要開發新接口:
查看代碼
# 今天的需求:按地區查詢銷售額
@app.route('/sales/by-region')
def sales_by_region(region):
return db.query(f
"
SELECT SUM(amount) FROM sales WHERE region='{region}'
"
)
# 明天的需求:按時間+地區查詢
@app.route('/sales/by-region-time') # 又要新增API
def sales_by_region_time(region, start_date, end_date):
return db.query(f
"
SELECT SUM(amount) FROM sales WHERE region='{region}' AND date BETWEEN '{start_date}' AND '{end_date}'
"
)
# 后天的需求:還要加上產品類型...
# API數量爆炸!而采用Chat2SQL可靈活應對:
查看代碼
-- 今天:按地區查詢
SELECT SUM(amount) FROM sales WHERE region = '華東';
-- 明天:按時間+地區查詢
SELECT SUM(amount) FROM sales
WHERE region = '華東' AND date >= '2024-07-01';
-- 后天:再加產品類型
SELECT SUM(amount) FROM sales
WHERE region = '華東'
AND date >= '2024-07-01'
AND product_type = '電子產品';臨時查詢、簡單統計場景用Chat2SQL。
靈活且復雜的場景(第一象限),用Agent
對于復雜邏輯的,比如問一些為什么、怎么做、怎么選類似的場景,通常需要多步驟推理。
這不是Chat2API、Chat2SQL這種一次調用/查詢,一次生成能搞定的事情。
通過Agent可以在Chat2API、Chat2SQL以及其它tools基礎上,靈活組合、多輪調用,然后綜合所有結果,得到最終答案。
用戶問:"為什么A產品的銷量下降了?"
僅用Chat2API或Chat2SQL,無法實現。
舉個例子:
查看代碼
# 用Chat2API,需要預設所有可能的API組合
# 但用戶的需求可能是這些的任意組合!
# 且只能調用預設的API,無法進行下一步執行
{
"apis": [
"sales-trend-analysis",
"competitor-analysis",
"market-factor-analysis",
"recommendation-engine",
]
}
# 用Chat2SQL,只能查到數據,然后呢?SQL無法進行下一步分析...
SELECT sales FROM products WHERE name='A'再看看如果用Agent:
為了簡化Agent過程,這里把問題收窄,加入時間維度“6月比5月”。
用戶問:"為什么A產品6月比5月銷量下降了?"
首先,Agent會思考到需要搞清楚具體下降了多少;
然后,Agent會調用SQL查詢工具獲取5月和6月的銷量數據;
接著,Agent發現5月1000件,6月800件,下降了20%;
然后,Agent判斷20%的下降已經超出正常波動范圍,需要深入分析。
接著,Agent思考:這個下降是我們獨有的問題,還是整個市場都在下降? 然后,Agent先調用年同比分析工具,發現去年6月是950件,今年確實下降了。
但這還不夠,Agent又調用市場趨勢分析工具,發現整個行業實際上增長了2%。
為了進一步確認,Agent還查了競品數據,發現競品B增長8%,競品C持平,競品D增長3%。
這下Agent明白了:市場整體向好,競品表現不錯,問題確實出在自己身上。
然后,Agent開始拆解問題。
Agent知道"銷量=訪客數×轉化率×客單價",于是調用銷售漏斗分析工具。 結果顯示訪客數從10000降到8500(下降15%),轉化率從5%降到4.7%(下降6%),客單價沒變。
Agent分析這些數據后推理:訪客大幅下降但轉化率相對穩定,說明來的人還是愿意買的,產品本身沒問題,主要是來的人少了。
這通常是流量獲取的問題。
于是,Agent調用流量來源分析工具,發現付費廣告流量下降了35%,而自然搜索和社交媒體流量都在增長5%。
問題鎖定了:是廣告流量出了問題。
Agent繼續深挖,調用廣告投放分析工具,發現6月的廣告預算從50萬減少到35萬,下降了30%,但廣告的點擊率和轉化率都保持穩定。
最后,Agent驗證整個邏輯鏈:廣告預算削減30%導致廣告曝光減少,進而使付費流量下降35%,總訪客減少15%,最終銷量下降20%。
Agent得出結論:根本原因是廣告預算被削減,解決方案就是恢復廣告預算,預計恢復后7月銷量可以回升到950件。
以上只是示例,具體什么效果,取決我們在Agent上的各種選型和改進策略,以及業務規則、基礎數據的完善程度。
具體到Agent策略、機制、主流框架的使用等,后面會專門寫文章講。
這就是高德90%準確率的第一個思路:"不同場景用不同策略,而不是一套算法解決所有問題。"
高德數據分析場景中面臨的ChatBI挑戰
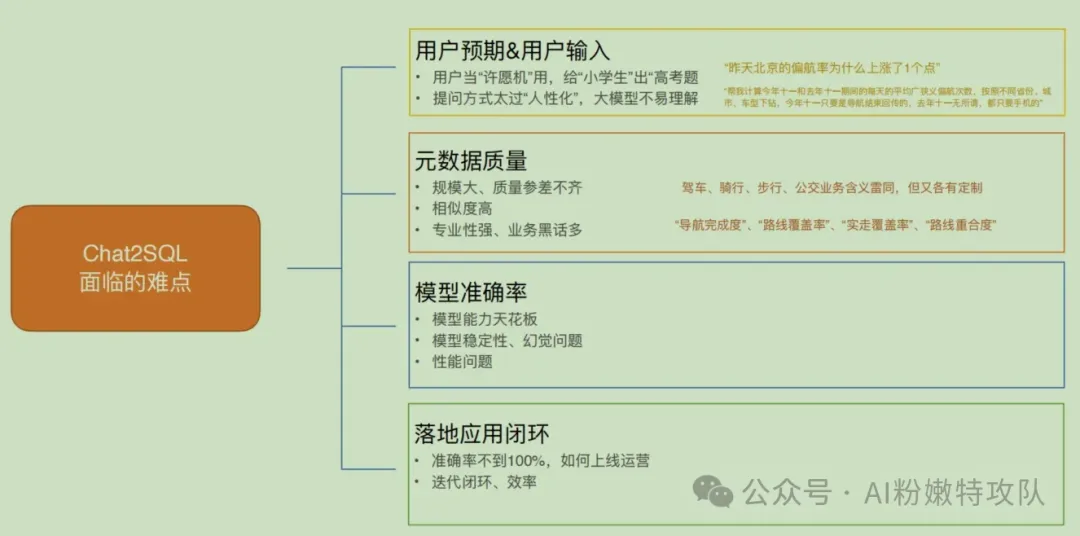
1. Chat2SQL目前僅達到"小學生"水平,但用戶總會問"高考題"。
用戶不管你能力如何,該問的還是會問。
這就是為什么要用四象限策略,讓Chat2SQL只處理它能處理好的簡單場景。
2. 元數據質量參差不齊
現實中的數據表結構有很多歷史遺留問題。
不同表或業務線的字段定義規范不一致。
有的描述清晰、口徑統一,有的描述模糊、計算規則不明確。
同名字段在不同場景下含義可能完全不同。
3. 相似字段的語義陷阱
"駕車完成率":完整用完一次導航的占比;
"駕車成功率":成功到達目的地的占比。
聽起來差不多,但統計口徑完全不同,業務含義差異很大。
4. 專業術語的理解困難
像"導航完成度"、"路線覆蓋率"、"實走覆蓋率"這些專業術語,模型缺乏足夠上下文時很容易理解錯誤。
5. 模型幻覺問題
生成稍微復雜的SQL時,可能出現:自己造字段、造表別名、造查詢條件。
6. 結果一致性問題
同一個問題,模型可能生成不同SQL,導致結果不同,甚至完全矛盾。
7.錯誤率10%,依然影響用戶使用
理論上90%準確率聽起來不錯,但實際業務中:
每100個查詢就有10個是錯的,用戶往往不知道哪個是錯的。
8.用戶發現問題后,往往希望能立即解決
為了不被動響應,需要主動監控查詢質量,收集用戶反饋,持續迭代優化。
面對這些挑戰,高德團隊的思路很清晰:
用戶輸入無法控制,通過路由分發來使用不同象限的策略;
模型能力有天花板,交給大模型廠商迭代,模型只會越來越強;
剩下的關鍵戰場,就是“元數據質量”和“反饋迭代”。
這就是高德90%準確率的第二個思路:“把有限的精力投入到能控制的關鍵環節。”
那高德怎么做元數據的?
剛做ChatBI的團隊,往往認為只要把表結構這種元數據喂給大模型,就能生成各種想要的查詢sql。
而傳統表結構信息對ChatBI遠遠不夠。
就像讓新同事直接上手復雜業務查詢,只給一份表結構說明,他也是一頭霧水。
以"上周用戶導航UV是多少"為例,模型需要理解:
- 導航UV是什么?對應哪個字段?
- 時間范圍如何定義?
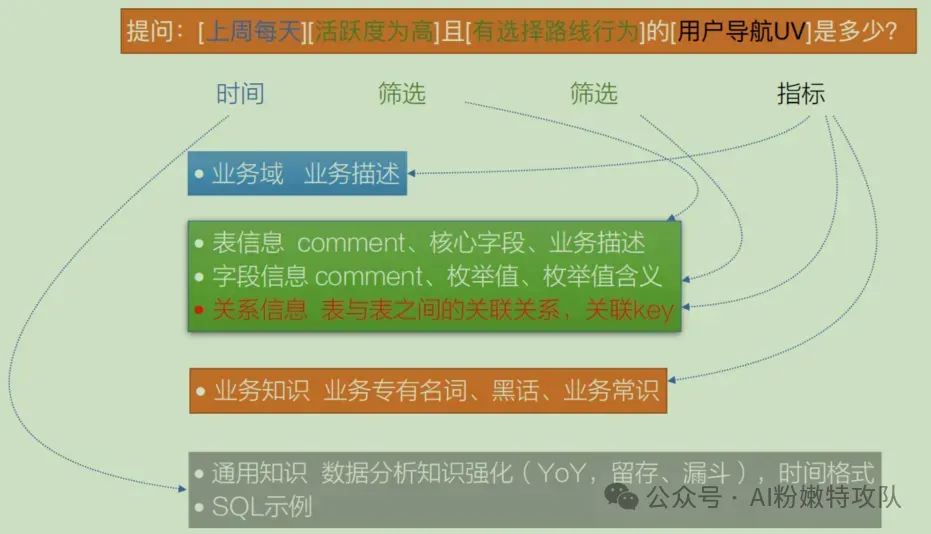
高德團隊設計了四層元數據:
1. 業務域層,快速定位場景
識別這是導航業務、搜索業務還是路況業務。
2. 表結構層,提供數據基礎
表業務含義、字段取值范圍、關聯關系(決定多表查詢準確性)。
3. 業務知識層,處理專業術語和"黑話"
像"導航UV"這種導航業務特有概念,沒有專門解釋,模型可能理解成網站導航。
4. 通用知識層、標準化常用概念
數據分析常用概念、時間格式定義。
用戶提問后,大致會經過下面5步,來得到生成sql需要的上下文:
- 分析指標項,識別所屬業務域
- 分析查詢對象和篩選條件,在業務域范圍內確定需要的表和字段
- 匹配業務知識,根據指標項找到對應的業務解釋
- 標準化通用概念,如時間條件的標準取值
- 上下文生成,將以上信息與用戶問題一起給模型生成SQL
做個簡單總結:
一般方式:只提供表結構 + 用戶問題 → 模型生成SQL
高德方式:業務域 + 表結構 + 業務知識 + 通用知識 + 用戶問題 → 模型生成SQL
模型本身能力有限,但通過精心設計的多層元數據,可大幅提升它對業務的理解能力。
這是高德90%準確率的第三個思路:“比起讓模型更聰明,不如給更多上下文。”
嘗試過Chat2SQL的應該都有感觸:在生成多表關聯的sql方面,準確率很低。
因此,為了降低查詢復雜度,通常把多張相關表的字段,構建成一張物理寬表,查詢時直接查單表,避免復雜關聯。
而物理寬表的問題在于:
存儲成本高:字段多、數據量大
維護成本高:底表變化或寬表更改都要重新刷全表
針對這個問題,高德團隊提出了“虛擬寬表”的思路。
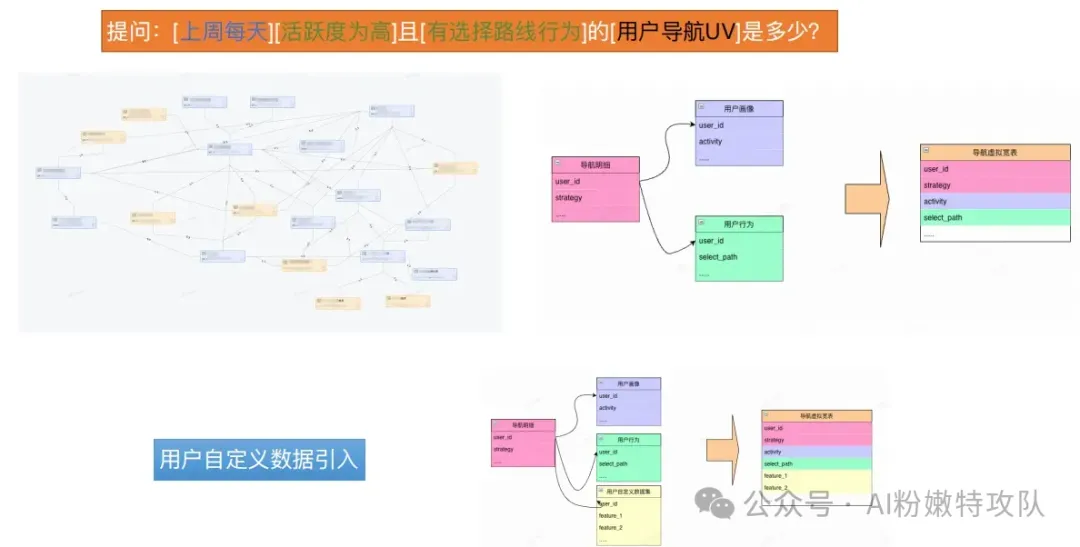
把"多張底表怎么拼、口徑怎么取、權限怎么控"預先寫成可查詢的"視圖"。
虛擬寬表帶來的優勢很明顯:
1. 不用自己寫復雜join、最新分區、去重邏輯
2. 口徑統一,大家都用同一套視圖,統計標準一致
3. 行列權限與脫敏內置到視圖中,統一控制
4. 底表變更或接入自定義特征,只改視圖即可
5. 需要時,仍可對熱點查詢進行物化提速
比如,用戶問:“最近7天各導航策略的活躍用戶數?”
數據工程師一次性創建虛擬寬表:
查看代碼
CREATE VIEW vw_nav_virtual_wide AS
SELECT
a.user_id, a.strategy, a.ds,
p.activity, -- 從用戶畫像取活躍度
b.select_path, -- 從用戶行為取選擇路徑
c.custom_label -- 預留自定義特征掛接點
FROM nav_detail a
LEFT JOIN user_profile p ON a.user_id = p.user_id
LEFT JOIN user_behavior b ON a.user_id = b.user_id
LEFT JOIN custom_features c ON a.user_id =c.user_id;--靈活擴展點 那么,AI只需要生成下面這個簡單的單表查詢sql
查看代碼
SELECT strategy, custom_label, COUNT(DISTINCT user_id) AS dau
FROM vw_nav_virtual_wide
WHERE ds >= current_date - 7 AND custom_label IS NOT NULL
GROUP BY strategy, custom_label;如果要對寬表添加新業務字段,單獨更新custom_features 表即可,
視圖會自動包含新字段,無需改底表或重新建模。
相比物理寬表,虛擬寬表避免了:大規模冗余存儲、變更響應慢、數據治理困難。
這就是高德90%準確率的第四個思路:“一個完美平衡'物理寬表簡單但同步困難'和'關聯查詢靈活但生成困難'的方案。”
元數據、虛擬寬表等基礎設施就緒后,高德開始了ChatBI的三階段演化之路。
第一階段:人怎么寫SQL,就用COT(思維鏈)教大模型怎么寫

把所有信息(同義詞映射、時間規則、表結構信息、業務口徑定義),塞進一個巨大的prompt,期望模型一步到位寫出SQL。
就像讓一個人同時做翻譯、建模、寫代碼,任何環節出錯都會影響最終結果,規則越加越容易產生沖突。
比如,用戶問:”帝都昨兒訂單多少?“
模型需同時完成:
- "帝都" → "Beijing"
- "昨兒" → 日期
- 選表、聚合、過濾
任一步掉鏈子就失敗。
這個階段的準確率一般能達到60%就很不錯了。
而且維護困難、對提示詞敏感,經常改動提示詞后原來正常的地方又出錯了。
但好處是,可以快速跑通系統。
第二階段:引入單Agent + 設計原子工具
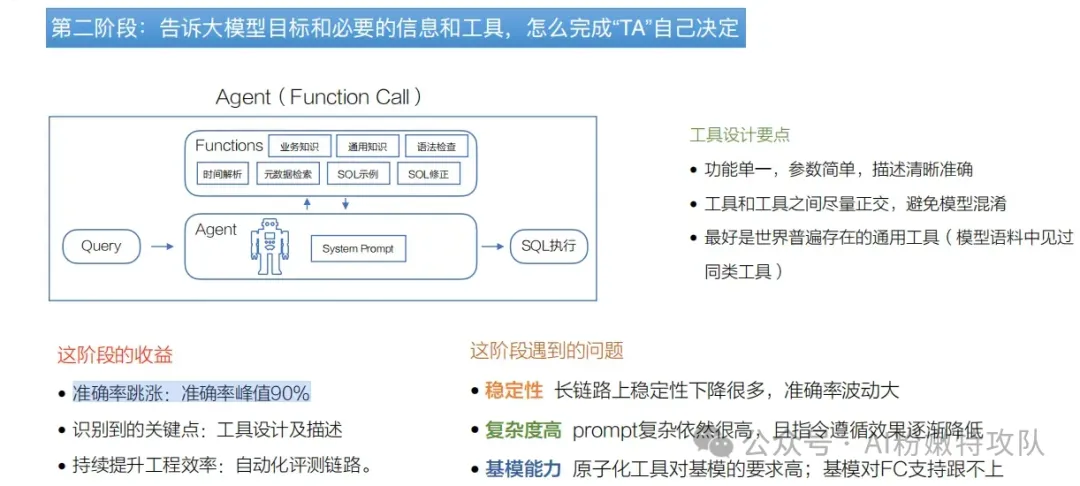
給模型設計一箱工具,模型只負責任務理解、規劃和工具選擇,具體執行邏輯由各個工具負責。
不過仍有痛點:
復雜問題導致工具調用鏈路變長,準確率峰值波動;
原子工具的提示詞依然會膨脹;
對規劃與參數一致性要求上升,穩定性需要繼續優化。
這個階段每個工具只負責自己的邏輯,且工具錯誤在工具間被隔離,端到端準確率峰值突破到90%,但也常有波動。
第三階段:設計分子化工具+引入多Agent

將多個相關的原子級工具(元數據檢索、語法檢查、示例檢索等)與特定提示詞組合,封裝成專門的SQL生成Agent。
這種方式的優勢在于:
保持了調用多種工具的靈活性;
通過專門提示詞降低單個Agent認知復雜度;
不再需要一個Agent掌握幾十上百個工具;
讓每個Agent專注使用相關的幾個工具,分工更明確、出錯率更低
同時,這個階段設計了三種不同策略的SQL生成Agent,通過一個獨立的SQL仲裁Agent選擇最佳方案執行。

策略1:Query Plan CoT(查詢計劃)
按人的習慣將任務分解成三個關鍵步驟:
”確定要使用的表”、”在表上做計數、過濾或匹配操作“、”通過選擇適當的列返回最終結果”。
策略2:Divide and Conquer CoT(分治)
將復雜問題分解成較小的子問題,先分別生成偽SQL查詢(強調邏輯正確而非語義正確),然后組裝起來生成最終可執行的SQL。
策略3:Example Generation(示例生成)
將用戶需求、相關表字段、篩選邏輯,以及與用戶需求相似的SQL示例給模型(去除特定業務信息)。
舉個例子,用戶問:"找出2023年北京客戶的平均訂單金額"
策略1:Query Plan CoT(查詢計劃)
1. 分析出需要 orders 表和 customers 表,通過 customer_id 關聯;
2. 分析出需要過濾:city = '北京'、order_date 在2023年;
3. 分析出需要聚合:計算 total_amount 的平均值;
4. 分析出需要返回“平均訂單金額”;
5. 生成SQL:
查看代碼
SELECT AVG(o.total_amount) as avg_amount
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE c.city = '北京' AND YEAR(o.order_date) = 2023;策略2:Divide and Conquer CoT(分治)
查看代碼
一、分解成子問題,用偽SQL表達
-- 子問題1:獲取北京客戶,偽SQL1:
SELECT 客戶編號 FROM 客戶表 WHERE 城市 ='北京'
--子問題2:獲取2023年訂單,偽SQL2:
SELECT 訂單編號, 客戶編號, 訂單金額 FROM 訂單表
WHEREYEAR(訂單日期) =2023
--子問題3:合并并計算平均值,偽SQL3:
SELECTAVG(訂單金額)
FROM 訂單表
WHERE 客戶編號 IN (SELECT 客戶編號 FROM 客戶表 WHERE 城市 ='北京')
ANDYEAR(訂單日期) =2023
二、匯總生成最終SQL
SELECTAVG(o.total_amount) as avg_amount
FROM orders o
WHERE o.customer_id IN (
SELECT customer_id FROM customers WHERE city ='北京')
ANDYEAR(o.order_date) = 2023;策略3:Example Generation(根據上下文+sql示例生成)
提供給模型的信息:
(1)用戶的需求是要“計算特定城市特定年份的平均訂單金額”
(2)相似SQL示例(去除具體業務信息)
查看代碼
-- 示例: 地區+時間篩選的聚合查詢
SELECTAVG(訂單表.金額字段) FROM 訂單表
JOIN 客戶表 ON 訂單表.客戶ID = 客戶表.客戶ID
WHERE 客戶表.地區字段 ='某城市' ANDYEAR(訂單表.日期字段) = 某年份;模型基于示例生成最終SQL:
查看代碼
SELECT AVG(o.total_amount) as avg_amount
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE c.city ='北京'
ANDYEAR(o.order_date) = 2023;最后,由一個仲裁Agent從三個不同策略的Agent分別生成的SQL中,選出一個最合適的來執行,而且這個獨立的仲裁Agent只會選擇一條最合理的sql,不會對這條sql做任何修改。
這就是高德90%準確率的第五個思路:“通過多個不同SQL生成Agent之間相互補充,將準確率峰值穩定在接近90%的狀態。”
回顧一下高德ChatBI演化的三個階段:
第一階段:通過prompt + 數據基礎設施建設,快速達到60分水平的ChatBI;
第二階段:通過引入Agent和原子工具,拆解復雜prompt,降低錯誤率,達到90分峰值水平;
第三階段:通過引入多Agent和分子工具,增加流程穩定性,降低Agent認知復雜度,將準確率穩定在峰值水平。
以上,就是高德90%準確率的思路。
那剩下的10%的錯誤率可以不管嗎?答案是不能。
在生產環境,90%準確率意味著每10個查詢就有1個出錯,用戶體驗仍不夠理想。
高德的理念是:“與其讓AI攻克這10%,不如用人機協同。”
通過有限合理地提高人的參與度,來彌補這10%的問題。

首先,在用戶輸入前,提供“提問助手引導”,從源頭減少奇怪的問題輸入;
然后,在回答過程中,給出SQL的邏輯解釋,讓用戶明白SQL是在干什么;
最后,在產出結果后,提供人工介入通道,用戶無法判斷SQL準確性或對結算結果有疑義時,可以申請人工介入,確保用戶總是能走完需求閉環,同時收集用戶反饋數據,為系統持續優化提供素材。
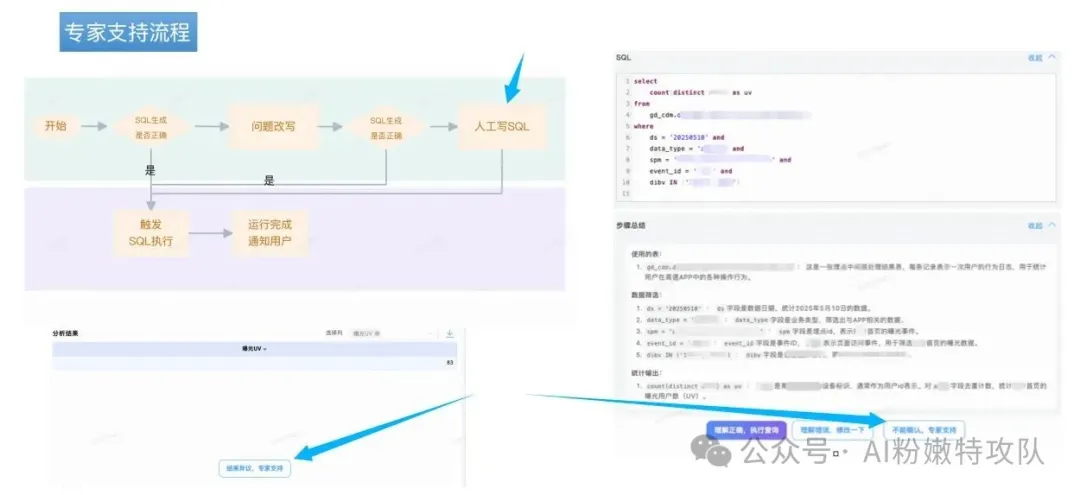 這是高德90%準確率的第六個思路:“不是讓AI做到100%完美,而是讓整個系統達到100%可用。”
這是高德90%準確率的第六個思路:“不是讓AI做到100%完美,而是讓整個系統達到100%可用。”
基于元數據、Agent等構建ChatBI的核心技術思路拆解完畢。
持續優化迭代方面,除了收集用戶反饋,高德也提出了ChatBI的主動評測原則。
1)重視評測集的構建
用真實用戶的問法 + 基礎能力模塊(例如時間解析類、地理范圍類、業務口徑類)測試案例來搭建評測數據集。
注意保持鮮度(定期更新)、做難度劃分(簡單/中等/困難分類)。
就像考試要有標準答案一樣,我們需要收集各種真實問題和標準SQL,這樣才能客觀衡量系統好不好用。
2)自動化冒煙測試
模擬真實環境,讓系統自己跑一遍,看結果對不對;
特別關注大模型生成SQL的準確性和穩定性。
人工測試太慢,自動化能快速發現問題,確保每次改動都不會把系統搞壞。
3)自動化歸因分析
SQL生成出錯時,自動分析是哪個環節的問題(召回、生成、還是中途某個步驟)
不用人工一個個排查,系統告訴你"問題出在第幾步",Bug修復效率顯著提升。
想要持續達到高準確率,就要建立持續優化的機制。
到此,高德目前的所有思路都拆解完了,回顧一下:
- 四象限策略:不同復雜度問題用不同方案解決
- 多層元數據:讓AI理解業務而不只是數據
- 虛擬寬表:降低多表關聯查詢復雜度的同時控制數據更新的復雜度
- 三階段演化:從60%到90%的漸進式優化路徑
- 多Agent協作:三種策略并行+仲裁選擇最優方案
- 人機協同:用有限人工介入補齊最后10%
高德90%準確率的本質:不是單一技術突破,而是系統工程的勝利。
最后,是高德數據團隊下一步優化方向。
方向一:Graph-RAG + NER,優化召回精準度
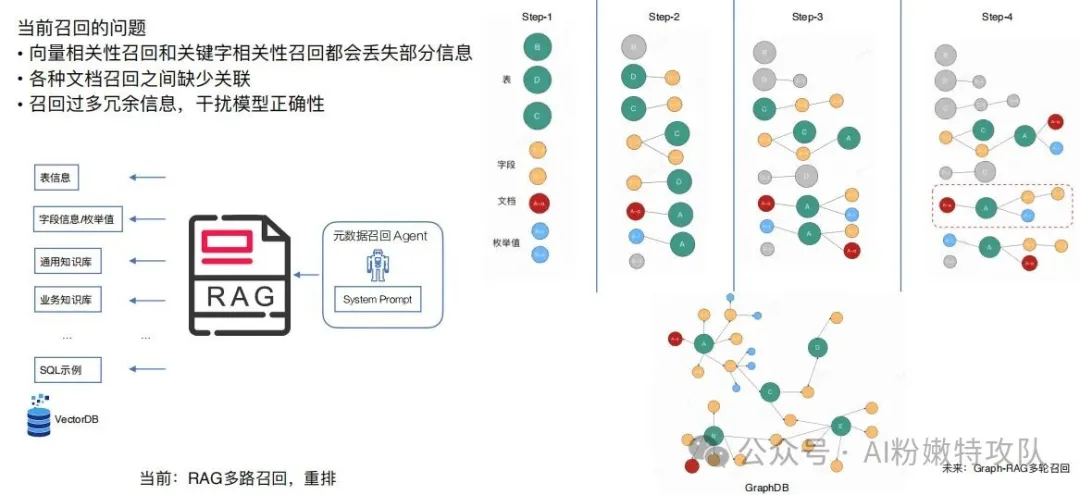
首先,在系統建設階段,需要用NER(命名實體識別)對所有的知識文檔進行信息要素抽取。
包括數據庫表結構、字段說明、業務文檔、SQL示例等等,從中提取出各種實體,比如表名、字段名、指標名、業務概念這些。
然后,基于這些實體之間的關系來構建知識圖譜。
比如,某個字段屬于哪張表、某個指標需要哪些字段來計算、不同業務術語之間是同義詞關系等等,這樣就把原本分散的知識片段通過實體和關系連接成一個網絡。
當用戶提問的時候,系統再次使用NER從問題中識別出關鍵實體。
比如,用戶說"北京近7天新用戶復購率",就能識別出"北京"、"近7天"、"新用戶"、"復購率"這些關鍵實體。
接著,就是在已經構建好的知識圖譜中,以這些問題實體為起點進行搜索。
這個搜索過程是分輪進行的。
第一輪:先找到這些實體在圖中對應的節點;
第二輪:從這些節點向外擴展一跳,找到直接相關的其他實體。比如"新用戶"會連接到"用戶注冊表"、"復購率"會連接到"訂單表"等等。
第三輪:繼續擴展,這時候可能會加入關系強度的過濾,只保留那些與用戶問題強相關的知識片段。
第四輪:主要做質量控制,確保召回的知識既完整又干凈。
最終形成一個知識圖,喂給模型作為上下文信息。
方向二:預訓練、微調、強化學習

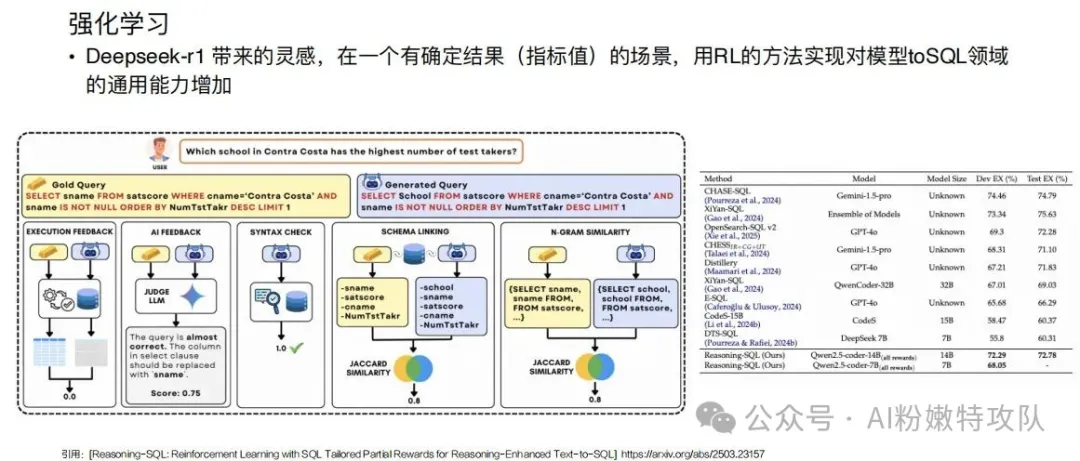
這塊做起來成本就非常高了,感興趣、有實力的朋友可以進一步了解相關論文。
以上,這篇文章已經寫了近11000字。
能看到這里,你對ChatBI的理解,已經超過90%的人。
當再有人跟你說找個開源項目三天就能搞出來ChatBI,就把這篇文章懟他臉上。
寫在最后
寫完后我自己的感覺是,ChatBI這個賽道確實有前景,但坑也確實不少。
技術能解決大部分問題,但剩下那10%往往決定了產品的生死。
AI再強,也永遠是輔助人類,承認這一點,才能做出真正好用的東西。
概念可以炒,PPT可以做得很漂亮,但產品得實打實地解決問題。
ChatBI也好,什么AGI也好,最終還是要回到用戶價值這個原點。
用戶不會為了你的技術有多牛逼而買單,他們只關心自己的問題有沒有被解決。
這個行業變化太快,今天的最佳實踐可能明天就過時了,今天的獨角獸可能下個月就倒了。但有些東西不會變,比如對業務的理解,對用戶的敬畏,還有那份工程師的較真勁兒。
ChatBI也好,其他AI應用也好,都不是銀彈,但也不是騙局。
它們是我們手中的工具,用得好能創造價值,用不好就是在浪費時間和金錢。
關鍵是要知道自己在做什么,為什么要做,以及怎么做得更好。
愿每一個在AI路上前行的朋友,都能找到屬于自己的那個90%,也都能優雅地處理好剩下的10%。
以上,既然看到這里了,如果覺得不錯,隨手點個贊、分享、推薦三連吧,我們,下次再見。
作者:秋水,互動交流,請聯系郵箱:fennenqiushui@qq.com
本文來自博客園,作者:AI粉嫩特攻隊,轉載請注明原文鏈接:http://www.rzrgm.cn/anai/p/19075045

 浙公網安備 33010602011771號
浙公網安備 33010602011771號