
遇見C++ AMP:GPU的線程模型和內(nèi)存模型
遇見C++ AMP:GPU的線程模型和內(nèi)存模型
Written by Allen Lee
I don't care where the enemies are / Can't be stopped / All I know / Go hard
– Linkin Park, Lost In The Echo
C++ AMP、CUDA和OpenCL,選擇哪個(gè)?
在《遇見C++ AMP:在GPU上做并行計(jì)算》發(fā)布之后,我曾被多次問及為何選擇C++ AMP,以及它與CUDA、OpenCL等相比有何優(yōu)勢(shì),看來有必要在進(jìn)入正題之前就這個(gè)問題發(fā)表一下看法了。
在眾多可以影響決策的因素之中,平臺(tái)種類的支持和GPU種類的支持是兩個(gè)非常重要的因素,它們聯(lián)合起來足以直接否決某些選擇。如果我們把這兩個(gè)因素看作兩個(gè)維度,可以把平面分成四個(gè)象限,C++ AMP、CUDA和OpenCL分別位于第二象限、第四象限和第一象限,如圖1所示。如果你想通吃所有平臺(tái)和所有GPU,OpenCL是目前唯一的選擇,當(dāng)然,你也需要為此承擔(dān)相當(dāng)?shù)膹?fù)雜性。CUDA是一個(gè)有趣的選擇,緊貼最新的硬件技術(shù)、數(shù)量可觀的行業(yè)應(yīng)用和類庫支持使之成為一個(gè)無法忽視的選擇,但是,它只能用于NVIDIA的GPU極大地限制了它在商業(yè)應(yīng)用上的采用,我想你不會(huì)為了運(yùn)行我的應(yīng)用特意把顯卡換成NVIDIA的。C++ AMP的情況剛好相反,它適用于各種支持DirectX 11的GPU,但只能在Windows上運(yùn)行。
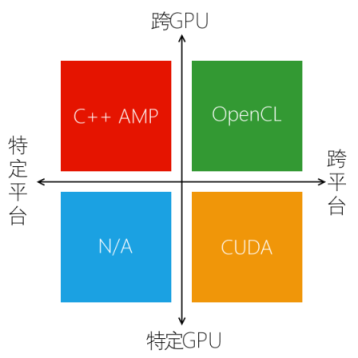
圖 1
這些技術(shù)都有自己的特點(diǎn)和位置,你應(yīng)該根據(jù)項(xiàng)目的具體情況選擇合適的解決方案。如果你正在從事的工作需要進(jìn)行大量計(jì)算,你想盡可能利用硬件特性對(duì)算法進(jìn)行優(yōu)化,而你的機(jī)器剛好有一塊NVIDIA的顯卡,并且你不需要在其他機(jī)器上重復(fù)執(zhí)行這些計(jì)算,那么CUDA將是你的不二之選。盡管NVIDIA已經(jīng)開源CUDA編譯器,并且歡迎其他廠商通過CUDA編譯器SDK添加新的語言/處理器,但AMD不太可能會(huì)為它提供在AMD的GPU上運(yùn)行的擴(kuò)展,畢竟它也有自己的基于OpenCL的AMD APP技術(shù)。如果你正在從事Windows應(yīng)用程序的開發(fā)工作,熟悉C++和Visual Studio,并且希望借助GPU進(jìn)一步提升應(yīng)用程序的性能,那么C++ AMP將是你的不二之選。盡管微軟已經(jīng)開放C++ AMP規(guī)范,Intel的Dillon Sharlet也通過Shevlin Park項(xiàng)目驗(yàn)證了在Clang/LLVM上使用OpenCL實(shí)現(xiàn)C++ AMP是可行的,但這不是一個(gè)產(chǎn)品級(jí)別的商用編譯器,Intel也沒有宣布任何發(fā)布計(jì)劃。如果你確實(shí)需要同時(shí)兼容Windows、Mac OS X和Linux等多個(gè)操作系統(tǒng),并且需要同時(shí)支持NVIDIA和AMD的GPU,那么OpenCL將是你的不二之選。
GPU線程的執(zhí)行
在《遇見C++ AMP:在GPU上做并行計(jì)算》里,我們通過extent對(duì)象告訴parallel_for_each函數(shù)創(chuàng)建多少個(gè)GPU線程,那么,這些GPU線程又是如何組織、分配和執(zhí)行的呢?
首先,我們創(chuàng)建的GPU線程會(huì)被分組,分組的規(guī)格并不固定,但必須滿足兩個(gè)條件:對(duì)應(yīng)的維度必須能被整除,分組的大小不能超過1024。假設(shè)我們的GPU線程是一維的,共8個(gè),如圖2所示,則可以選擇每2個(gè)GPU線程為1組或者每4個(gè)GPU線程為1組,但不能選擇每3個(gè)GPU線程為1組,因?yàn)槭O碌?個(gè)GPU線程不足1組。
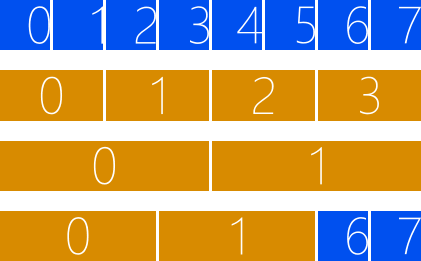
圖 2
假設(shè)我們創(chuàng)建的GPU線程是二維的,3 x 4,共12個(gè),如圖3所示,則可以選擇3 x 1或者3 x 2作為分組的規(guī)格,但不能選擇2 x 2作為分組的規(guī)格,因?yàn)槭O碌?個(gè)GPU線程雖然滿足分組的大小,但不滿足分組的形狀。每個(gè)分組必須完全相同,包括大小和形狀。

圖 3
為了便于解釋,我們的GPU線程只有寥寥數(shù)個(gè),但真實(shí)案例的GPU線程往往是幾十萬甚至幾百萬個(gè),這個(gè)時(shí)候,分組的規(guī)格會(huì)有大量選擇,我們必須仔細(xì)判斷它們是否滿足條件。假設(shè)我們的GPU線程是640 x 480,那么16 x 48、32 x 16和32 x 32都可以選擇,它們分別產(chǎn)生40 x 10、20 x 30和20 x 15個(gè)分組,但32 x 48不能選擇,因?yàn)樗拇笮∫呀?jīng)超過1024了。
接著,這些分組會(huì)被分配到GPU的流多處理器(streaming multiprocessor),每個(gè)流多處理器根據(jù)資源的使用情況可能分得一組或多組GPU線程。在執(zhí)行的過程中,同一組的GPU線程可以同步,不同組的GPU線程無法同步。你可能會(huì)覺得這種有限同步的做法會(huì)極大地限制GPU的作為,但正因?yàn)榻M與組之間是相互獨(dú)立的,GPU才能隨意決定這些分組的執(zhí)行順序。這有什么好處呢?假設(shè)低端的GPU每次只能同時(shí)執(zhí)行2個(gè)分組,那么執(zhí)行8個(gè)分組需要4個(gè)執(zhí)行周期,假設(shè)高端的GPU每次可以同時(shí)執(zhí)行4個(gè)分組,執(zhí)行8個(gè)分組只需2個(gè)執(zhí)行周期,如圖4所示,這意味著我們寫出來的程序具備可伸縮性,能夠自動(dòng)適應(yīng)GPU的計(jì)算資源。
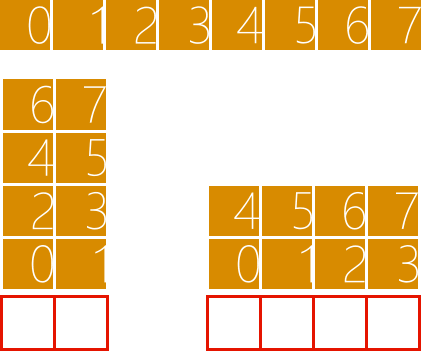
圖 4
說了這么多,是時(shí)候看看代碼了。parallel_for_each函數(shù)有兩種模式,一種是簡單模式,我們通過extent對(duì)象告訴它創(chuàng)建多少GPU線程,C++ AMP負(fù)責(zé)對(duì)GPU線程進(jìn)行分組,另一種是分組模式,我們通過tiled_extent對(duì)象告訴它創(chuàng)建多少GPU線程以及如何進(jìn)行分組。創(chuàng)建tiled_extent對(duì)象非常簡單,只需在現(xiàn)有的extent對(duì)象上調(diào)用tile方法,并告知分組的規(guī)格就行了,如代碼1所示。值得提醒的是,分組的規(guī)格是通過模板參數(shù)告訴tile方法的,這意味著分組的規(guī)格必須在編譯時(shí)確定下來,C++ AMP目前無法做到運(yùn)行時(shí)動(dòng)態(tài)分組。
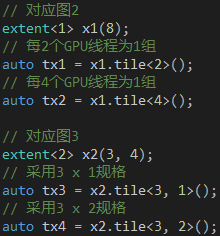
代碼 1
既然C++ AMP不支持運(yùn)行時(shí)動(dòng)態(tài)分組,肯定會(huì)為簡單模式預(yù)先定義一些分組的規(guī)格,那么C++ AMP又是如何確保它們能被整除?假設(shè)我們創(chuàng)建的GPU線程是一維的,共10000個(gè),C++ AMP會(huì)選擇每256個(gè)GPU線程為1組,把前面9984個(gè)GPU線程分成39個(gè)分組,然后補(bǔ)充240個(gè)GPU線程和剩下的16個(gè)GPU線程湊夠1組,執(zhí)行的時(shí)候會(huì)通過邊界測(cè)試確保只有前10000個(gè)GPU線程執(zhí)行我們的代碼。對(duì)于二維和三維的情況,C++ AMP也會(huì)采取這種補(bǔ)充GPU線程的策略,只是分組的規(guī)格不同,必要時(shí)還會(huì)重新排列GPU線程,以便分組能夠順利完成。需要說明的是,簡單模式背后采取的策略屬于實(shí)現(xiàn)細(xì)節(jié),在這里提及是為了滿足部分讀者的好奇心,你的算法不該對(duì)它有所依賴。
共享內(nèi)存的訪問
既然簡單模式可以自動(dòng)分組,為何還要大費(fèi)周章使用分組模式?為了回答這個(gè)問題,我們先要了解一下GPU的內(nèi)存模型。在Kernel里,我們可以訪問全局內(nèi)存、共享內(nèi)存和寄存器,如圖5所示。當(dāng)我們通過array_view對(duì)象把數(shù)據(jù)從主機(jī)內(nèi)存復(fù)制到顯卡內(nèi)存時(shí),這些數(shù)據(jù)會(huì)被保存在全局內(nèi)存,直到應(yīng)用程序退出,所有GPU線程都能訪問全局內(nèi)存,不過訪問速度很慢,大概需要1000個(gè)GPU時(shí)鐘周期,大量的GPU線程反復(fù)執(zhí)行這種高延遲的操作將會(huì)導(dǎo)致GPU計(jì)算資源的閑置,從而降低整體的計(jì)算性能。

圖 5
為了避免反復(fù)從全局內(nèi)存訪問相同的數(shù)據(jù),我們可以把這些數(shù)據(jù)緩存到寄存器或者共享內(nèi)存,因?yàn)樗鼈兗稍贕PU芯片里,所以訪問速度很快。當(dāng)我們?cè)贙ernel里聲明一個(gè)基本類型的變量時(shí),它的數(shù)據(jù)會(huì)被保存在寄存器,直到GPU線程執(zhí)行完畢,每個(gè)GPU線程只能訪問自己的寄存器,寄存器的容量非常小,不過訪問速度非常快,只需1個(gè)GPU時(shí)鐘周期。當(dāng)我們?cè)贙ernel里通過tile_static關(guān)鍵字聲明一個(gè)變量時(shí),它的數(shù)據(jù)會(huì)被保存在共享內(nèi)存(也叫tile_static內(nèi)存),直到分組里的所有GPU線程都執(zhí)行完畢,同一組的GPU線程都能訪問相同的共享內(nèi)存,共享內(nèi)存的容量很小,不過訪問速度很快,大概需要10個(gè)GPU時(shí)鐘周期。tile_static關(guān)鍵字只能在分組模式里使用,因此,如果我們想使用共享內(nèi)存,就必須使用分組模式。
如果數(shù)據(jù)只在單個(gè)GPU線程里反復(fù)使用,可以考慮把數(shù)據(jù)緩存到寄存器。如果數(shù)據(jù)會(huì)在多個(gè)GPU線程里反復(fù)使用,可以考慮把數(shù)據(jù)緩存到共享內(nèi)存。共享內(nèi)存的緩存策略是對(duì)全局內(nèi)存的數(shù)據(jù)進(jìn)行分組,然后把這些分組從全局內(nèi)存復(fù)制到共享內(nèi)存。假設(shè)我們需要緩存4 x 4的數(shù)據(jù),可以選擇2 x 2作為分組的規(guī)格把數(shù)據(jù)分成4組,如圖6所示。以右上角的分組為例,我們需要4個(gè)GPU線程分別把這4個(gè)數(shù)據(jù)從全局內(nèi)存復(fù)制到共享內(nèi)存。復(fù)制的過程涉及兩種不同的索引,一種是相對(duì)于所有數(shù)據(jù)的全局索引,用于從全局內(nèi)存訪問數(shù)據(jù),另一種是相對(duì)于單個(gè)分組的本地索引,用于從共享內(nèi)存訪問數(shù)據(jù),比如說,全局索引(1, 2)對(duì)應(yīng)本地索引(1, 0)。
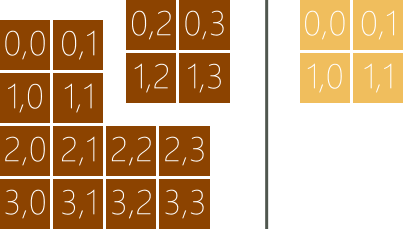
圖 6
在分組模式里,我們可以通過tiled_index對(duì)象訪問索引信息,它的global屬性返回全局索引,local屬性返回本地索引,tile屬性返回分組索引,它是分組作為一個(gè)整體相對(duì)于其他分組的索引,tile_origin屬性返回分組原點(diǎn)的全局索引,它是分組里的(0, 0)位置上的元素的全局索引。還是以右上角的分組為例,(1, 2)位置的global屬性的值是(1, 2),local屬性的值是(1, 0),tile屬性的值是(0, 1),tile_origin屬性的值是(0, 2)。tiled_index對(duì)象將會(huì)通過Lambda的參數(shù)傳給我們,我們將會(huì)在Kernel里通過它的屬性訪問全局內(nèi)存和共享內(nèi)存。
說了這么多,是時(shí)候看看代碼了。正如extent對(duì)象搭配index對(duì)象用于簡單模式,tiled_extent對(duì)象搭配tiled_index對(duì)象用于分組模式,使用的時(shí)候,兩者的模板參數(shù)必須完全匹配,如代碼2所示。parallel_for_each函數(shù)將會(huì)創(chuàng)建16個(gè)GPU線程,每4個(gè)GPU線程為1組,同一組的GPU線程共享一個(gè)2 x 2的數(shù)組變量,每個(gè)元素由一個(gè)GPU線程負(fù)責(zé)復(fù)制,每個(gè)GPU線程通過tiled_index對(duì)象的global屬性獲知從全局內(nèi)存的哪個(gè)位置讀取數(shù)據(jù),通過local屬性獲知向共享內(nèi)存的哪個(gè)位置寫入數(shù)據(jù)。
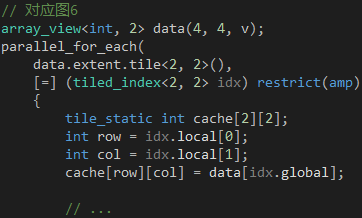
代碼 2
因?yàn)榫彺娴臄?shù)據(jù)會(huì)在多個(gè)GPU線程里使用,所以每個(gè)GPU線程必須等待其他GPU線程緩存完畢才能繼續(xù)執(zhí)行后面的代碼,否則,一些GPU線程還沒開始緩存數(shù)據(jù),另一些GPU線程就開始使用數(shù)據(jù)了,這樣計(jì)算出來的結(jié)果肯定是錯(cuò)的。為了避免這種情況的發(fā)生,我們需要在代碼2后面加上一句idx.barrier.wait();,加上之后的效果就像設(shè)了一道閘門,如圖7所示,它把整個(gè)代碼分成兩個(gè)階段,第一階段緩存數(shù)據(jù),第二階段計(jì)算結(jié)果,緩存完畢的GPU線程會(huì)在閘門前面等待,當(dāng)所有GPU線程都緩存完畢時(shí),就會(huì)打開閘門讓它們進(jìn)入第二階段。
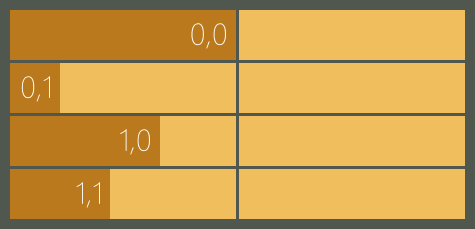
圖 7
總的來說,使用分組模式是為了借助共享內(nèi)存減少全局內(nèi)存的訪問,緩存的過程已經(jīng)包含了一次全局內(nèi)存的訪問,因此,如果我們的算法只需訪問全局內(nèi)存一次,比如《遇見C++ AMP:在GPU上做并行計(jì)算》的"并行計(jì)算矩陣之和",那么緩存數(shù)據(jù)不會(huì)帶來任何改善,反而增加了代碼的復(fù)雜性。
并行計(jì)算矩陣之積
矩陣的乘法需要反復(fù)訪問相同的元素,非常適合用來演示分組模式。接下來,我們將會(huì)分別使用簡單模式和分組模式實(shí)現(xiàn)矩陣的乘法,然后通過對(duì)比了解這兩種實(shí)現(xiàn)的區(qū)別。
設(shè)矩陣
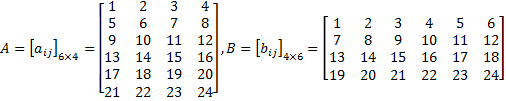
求AB。設(shè)C = AB,根據(jù)定義, ,其中,
,其中,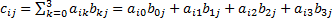
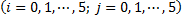 。你可以把這個(gè)公式想象成矩陣A的第i行和矩陣B的第j列兩個(gè)數(shù)組對(duì)應(yīng)位置的元素相乘,然后相加。
。你可以把這個(gè)公式想象成矩陣A的第i行和矩陣B的第j列兩個(gè)數(shù)組對(duì)應(yīng)位置的元素相乘,然后相加。
如何把這些數(shù)學(xué)描述翻譯成代碼呢?第一步,定義A、B和C三個(gè)矩陣,如代碼3所示,iota函數(shù)可以在指定的起止位置之間填充連續(xù)的數(shù)字,正好滿足這里的需求。
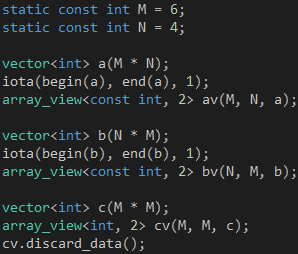
代碼 3
第二步,計(jì)算矩陣C的元素,如代碼4所示,整個(gè)Kernel就是計(jì)算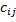 的求和公式, 因?yàn)槊總€(gè)元素的計(jì)算都是獨(dú)立的,所以非常適合并行執(zhí)行。
的求和公式, 因?yàn)槊總€(gè)元素的計(jì)算都是獨(dú)立的,所以非常適合并行執(zhí)行。
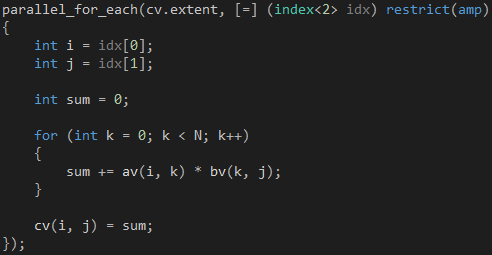
代碼 4
在執(zhí)行代碼4的時(shí)候,parallel_for_each函數(shù)將會(huì)創(chuàng)建36個(gè)GPU線程,每個(gè)GPU線程計(jì)算矩陣C的一個(gè)元素,因?yàn)檫@36個(gè)GPU線程會(huì)同時(shí)執(zhí)行,所以計(jì)算矩陣C的時(shí)間就是計(jì)算一個(gè)元素的時(shí)間。這聽起來已經(jīng)很好,還能更好嗎?仔細(xì)想想,計(jì)算需要訪問矩陣A的第i行一次,那么,計(jì)算矩陣C的第i行將會(huì)訪問矩陣A的第i行M次,M是矩陣C的列數(shù),在這里是6;同理,計(jì)算矩陣C的第j列將會(huì)訪問矩陣B的第j列M次,M是矩陣C的行數(shù),在這里也是6。因?yàn)锳、B和C三個(gè)矩陣的數(shù)據(jù)是保存在全局內(nèi)存的,所以優(yōu)化的關(guān)鍵就是減少全局內(nèi)存的訪問。
根據(jù)上一節(jié)的討論,我們將會(huì)使用分組模式,并把需要反復(fù)訪問的數(shù)據(jù)從全局內(nèi)存緩存到共享內(nèi)存,那么,使用分組模式會(huì)對(duì)性能帶來多少改善,又對(duì)算法造成多少影響呢,這正是我們接下來需要探討的。
第一步,選擇2 x 2作為分塊的規(guī)格對(duì)A、B兩個(gè)矩陣進(jìn)行分塊處理
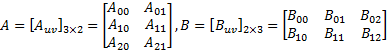
分塊矩陣的乘法和普通矩陣的乘法是一樣的,設(shè)C = AB,根據(jù)定義,分塊矩陣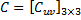 ,其中,
,其中,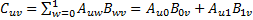
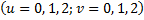 。
。
第二步,把parallel_for_each函數(shù)改成分組模式,如代碼5所示。T是子塊的邊長,W是分塊矩陣A的列數(shù),也是分塊矩陣B的行數(shù)。
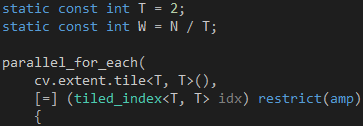
代碼 5
第三步,分別緩存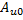 和
和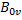 ,如代碼6所示。因?yàn)樗鼈兌际? x 2的矩陣,所以緩存它們的工作需要4個(gè)GPU線程協(xié)同完成。正確緩存的關(guān)鍵在于弄清每個(gè)GPU線程負(fù)責(zé)全局內(nèi)存和共享內(nèi)存的哪些位置,共享內(nèi)存的位置可以通過tiled_index對(duì)象的local屬性獲知,而全局內(nèi)存的位置則需要換算一下,因?yàn)閕和j是針對(duì)矩陣C而不是矩陣A和矩陣B的。每個(gè)GPU線程只是分別從矩陣A和矩陣B緩存一個(gè)元素,根據(jù)定義,從矩陣A緩存的元素必定位于第i行,而從矩陣B緩存的元素必定位于第j列。當(dāng)我們緩存
,如代碼6所示。因?yàn)樗鼈兌际? x 2的矩陣,所以緩存它們的工作需要4個(gè)GPU線程協(xié)同完成。正確緩存的關(guān)鍵在于弄清每個(gè)GPU線程負(fù)責(zé)全局內(nèi)存和共享內(nèi)存的哪些位置,共享內(nèi)存的位置可以通過tiled_index對(duì)象的local屬性獲知,而全局內(nèi)存的位置則需要換算一下,因?yàn)閕和j是針對(duì)矩陣C而不是矩陣A和矩陣B的。每個(gè)GPU線程只是分別從矩陣A和矩陣B緩存一個(gè)元素,根據(jù)定義,從矩陣A緩存的元素必定位于第i行,而從矩陣B緩存的元素必定位于第j列。當(dāng)我們緩存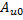 時(shí),子塊位于分塊矩陣A的左上角,tiled_index對(duì)象的local屬性和global屬性指向相同的列,因此,目標(biāo)元素位于矩陣A的第h列,當(dāng)我們緩存
時(shí),子塊位于分塊矩陣A的左上角,tiled_index對(duì)象的local屬性和global屬性指向相同的列,因此,目標(biāo)元素位于矩陣A的第h列,當(dāng)我們緩存 時(shí),我們已經(jīng)從左到右跨過了w個(gè)子塊,因此,目標(biāo)元素位于矩陣A的第h + w * T列。同理,當(dāng)我們緩存
時(shí),我們已經(jīng)從左到右跨過了w個(gè)子塊,因此,目標(biāo)元素位于矩陣A的第h + w * T列。同理,當(dāng)我們緩存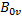 時(shí),子塊位于分塊矩陣B的左上角,目標(biāo)元素位于矩陣B的第g行,當(dāng)我們緩存
時(shí),子塊位于分塊矩陣B的左上角,目標(biāo)元素位于矩陣B的第g行,當(dāng)我們緩存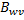 時(shí),我們已經(jīng)從上到下跨過了w個(gè)子塊,因此,目標(biāo)元素位于矩陣B的第g + w * T行。4個(gè)GPU線程都緩存完畢就會(huì)進(jìn)入第二階段。
時(shí),我們已經(jīng)從上到下跨過了w個(gè)子塊,因此,目標(biāo)元素位于矩陣B的第g + w * T行。4個(gè)GPU線程都緩存完畢就會(huì)進(jìn)入第二階段。
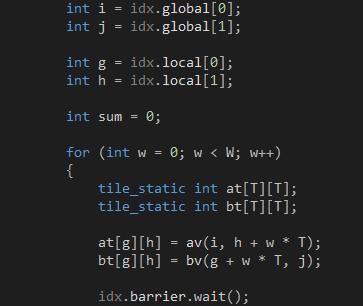
代碼 6
第四步,計(jì)算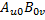 ,如代碼7所示。這是兩個(gè)2 x 2的普通矩陣相乘,需要4個(gè)GPU線程協(xié)同完成,每個(gè)GPU線程計(jì)算結(jié)果矩陣的一個(gè)元素,然后加到變量sum上。4個(gè)GPU線程都計(jì)算完畢就會(huì)重復(fù)第三、四步,緩存
,如代碼7所示。這是兩個(gè)2 x 2的普通矩陣相乘,需要4個(gè)GPU線程協(xié)同完成,每個(gè)GPU線程計(jì)算結(jié)果矩陣的一個(gè)元素,然后加到變量sum上。4個(gè)GPU線程都計(jì)算完畢就會(huì)重復(fù)第三、四步,緩存 和
和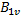 ,計(jì)算
,計(jì)算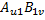 。如果還有其他子塊,那么這個(gè)過程會(huì)一直重復(fù)下去。最終,每個(gè)GPU線程匯總矩陣
。如果還有其他子塊,那么這個(gè)過程會(huì)一直重復(fù)下去。最終,每個(gè)GPU線程匯總矩陣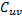 的一個(gè)元素。
的一個(gè)元素。
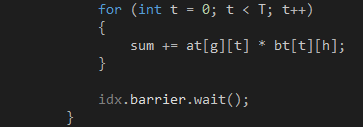
代碼 7
最后一步,把匯總的結(jié)果保存到矩陣C,如代碼8所示。
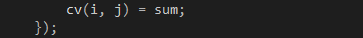
代碼 8
至此,我相信你已經(jīng)深刻地體會(huì)到分組模式的復(fù)雜性。CPU擁有更強(qiáng)的控制部件和更大的緩存區(qū)域,可以預(yù)測(cè)和決定應(yīng)該緩存哪些數(shù)據(jù),而GPU則把原本屬于它們的空間留給更多的運(yùn)算部件,把緩存的控制權(quán)交給程序員,這意味著緩存的邏輯將會(huì)滲透到業(yè)務(wù)的邏輯,從而增加了代碼的復(fù)雜性。
那么,這樣做是否值得?我們可以算一下,在代碼4里,av、bv和cv都是位于全局內(nèi)存,每次訪問都要1000個(gè)GPU時(shí)鐘周期, 讀取N次av和bv,寫入一次cv,總共耗時(shí)2000 * N + 1000個(gè)GPU時(shí)鐘周期,當(dāng)N = 4時(shí),總共耗時(shí)9000個(gè)GPU時(shí)鐘周期。在代碼6、7、8里,at和bt都是位于共享內(nèi)存,每次訪問只要10個(gè)GPU時(shí)鐘周期,讀取W次av和bv,寫入W次at和bt,讀取W * T次at和bt,寫入一次cv,總共耗時(shí) (2000 + 20 + 20 * T) * W + 1000,當(dāng)N = 4,T = 2時(shí),W = 2,總共耗時(shí)5120個(gè)GPU時(shí)鐘周期,約為簡單模式的56.89%,性能的改善非常明顯。如果我們?cè)黾泳仃嚭妥訅K的大小,這個(gè)差距就會(huì)更加明顯,令N = 1024,T = 16,則簡單模式總共耗時(shí)2049000個(gè)GPU時(shí)鐘周期,而分組模式總共耗時(shí)150760個(gè)GPU時(shí)鐘周期,后者是前者的7.36%。
當(dāng)然,這并不是簡單模式和分組模式在性能上的精確差距,因?yàn)槲覀冞€沒考慮訪問寄存器和算術(shù)運(yùn)算的耗時(shí),但這些操作的耗時(shí)和訪問全局內(nèi)存的相比簡直就是小巫見大巫,即使把它們考慮進(jìn)去也不會(huì)對(duì)結(jié)果造成太大影響。
你可能會(huì)問的問題
1. 什么時(shí)候不能使用分組模式?
分組模式最高只能處理三維的數(shù)據(jù)結(jié)構(gòu),四維或者更高的數(shù)據(jù)結(jié)構(gòu)必須使用簡單模式,事實(shí)上,簡單模式會(huì)把四維或者更高的數(shù)據(jù)結(jié)構(gòu)換算成三維的。如果算法沒有反復(fù)從全局內(nèi)存訪問相同的數(shù)據(jù),那也不必使用分組模式。
2. 分組的限制有哪些?
分組的大小不能超過1024,對(duì)應(yīng)的維度必須能被整除,第一、二維度的大小不能超過1024,第三維度的大小不能超過64,分組的總數(shù)不能超過65535。
3. 分組的大小越大越好嗎?
不是的,我們使用分組模式主要是為了使用共享內(nèi)存,一般情況下,分組的大小和它使用的共享內(nèi)存成正比,每個(gè)流多處理器的共享內(nèi)存是有限的,比如說,NVIDIA的GK110 GPU的最大規(guī)格是48K,每個(gè)流多處理器最多可以同時(shí)容納16個(gè)分組,這意味著每個(gè)分組最多只能使用3K,如果每個(gè)分組使用4K,那么每個(gè)流多處理器最多只能同時(shí)容納12個(gè)分組,這意味著流多處理器的計(jì)算能力沒被最大限度使用。
4. 在設(shè)定分組的大小時(shí)需要考慮Warp Size嗎?
在計(jì)算域允許的情況下盡可能考慮,NVIDIA的Warp Size是32,AMD的Wavefront Size是64,因此,分組的大小最好是64的倍數(shù)。
*聲明:本文已經(jīng)首發(fā)于InfoQ中文站,版權(quán)所有,《遇見C++ AMP:GPU的線程模型和內(nèi)存模型》,如需轉(zhuǎn)載,請(qǐng)務(wù)必附帶本聲明,謝謝。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)