
JSON 日志分析的“正確姿勢”:阿里云 SLS 高效實踐指南
作者:范阿冬(無哲)
JSON 格式因其靈活、易擴展、可讀性強等特點,是日志數據中非常常見的格式之一。然而海量的 JSON 日志也給高效分析帶來了挑戰。本文將系統性地介紹在阿里云日志服務(SLS)中處理和分析 JSON 日志的最佳實踐,幫助你從看似無序的數據海洋中精準、快速地挖掘出核心價值。
一、 數據預處理:從源頭奠定高效分析的基礎
對于結構相對固定的 JSON 日志,最佳策略是在數據進入存儲之前就將其“拍平”(Flatten),即將嵌套的 JSON 字段展開為獨立的、扁平化的字段。
這樣做的好處顯而易見:
- 查詢性能更優:避免了在每次查詢時都進行實時解析,直接對獨立字段進行分析,速度更快,效率更高。
- 存儲成本更低:消除了 JSON 格式本身(如大括號、引號、逗號)帶來的冗余,有效降低存儲開銷。
SLS 提供了多種在數據寫入前進行預處理的方式:
方式一:采集時處理(推薦 Logtail 用戶)
如果你使用 Logtail 進行日志采集,可以直接利用其內置的 JSON 插件。該插件能在采集階段就將 JSON 對象解析并展開為多個獨立字段,從源頭實現數據規整化。如果日志中只有部分字段是 JSON 字符串,也可以結合 SPL 語句在插件中對特定字段進行處理。

方式二:寫入時處理(寫入處理器)
當日志來源多樣(例如,除了 Logtail 還有 API、SDK 等),或者你無法控制采集端的配置時,可以在 SLS 的 Logstore 上配置一個寫入處理器(Ingestion Processor)。所有寫入該 Logstore 的數據,在落盤前都會經過處理器的統一加工,同樣可以實現 JSON 的展開。這提供了一個集中、統一的數據治理入口。

方式三:寫入后處理(數據加工)
如果 JSON 日志已經存入 Logstore,也無需擔心。可以通過數據加工任務,讀取源 Logstore 的數據,使用 SPL 進行處理,然后將加工后的結構化數據寫入一個新的 Logstore。這對于歷史數據的清洗和歸檔非常有用。
無論選擇哪種方式,強大的 SPL 都是你處理 JSON 數據的核心工具,它能輕松完成展開、提取、轉換等各類操作,為后續的高效分析鋪平道路。
二、 配置索引:在保留結構與查詢性能間找到最佳平衡
雖然“拍平”存儲是理想狀態,但有時我們希望保留字段原始的 JSON 結構,以便更好地反映日志的層級關系。同時我們還是需要能夠進行靈活的查詢分析。
你可以為 JSON 字段本身創建 JSON 類型索引,并針對其中最常用的葉子節點路徑(如 Payload.Status)單獨創建子節點索引。這樣,既保留了 Payload 字段的完整 JSON 結構,又能像查詢普通字段一樣,直接對高頻子節點進行高速查詢和分析。

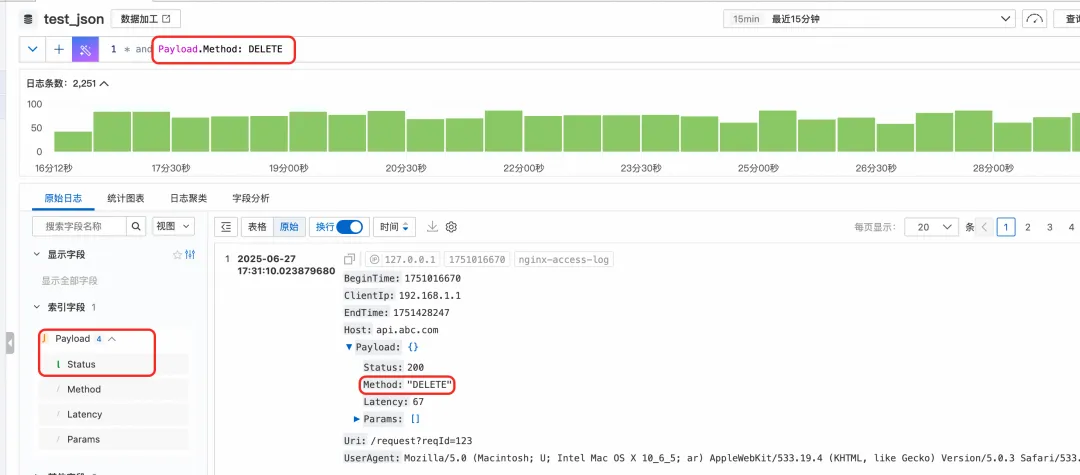
那如果想創建的字段太多怎么辦?可以勾選上“對 Json 內所有文本字段自動索引”,這樣所有的 JSON 的文本類型的子節點會自動加上索引,可以直接查詢。比如這里,我們在索引配置里面并未給 Method 子節點顯示添加索引,但是可以對 Payload.Method 直接進行關鍵詞查詢。
三、 JSON 函數:深入 JSON 內部的瑞士軍刀
前面介紹了可以為 JSON 的子節點添加索引,然后直接分析,但是有些情況下我們無法或者不便添加子節點索引:
(1)JSON 對象包含的字段不確定,無法事先枚舉
(2)對于 JSON 數組,或者 JSON 對象的中間節點,這些是不能單獨建立索引的
SLS 強大的 JSON 分析函數便派上了用場。它們允許你在 SQL 查詢中對 JSON 數據進行實時、靈活的深度分析。
json_extract vs. json_extract_scalar 選擇合適的武器
這兩個函數是 JSON 提取的基礎,但用途不同:
json_extract(json,json_path):返回一個 JSON 對象或 JSON 數組。當你需要對 JSON 結構本身進行操作時(如計算數組長度),應使用此函數。json_extract_scalar(json,json_path):返回一個標量值(字符串、數字、布爾值),但其返回類型始終是varchar(字符串)。這是最常用的函數,用于提取字段值進行分析。
注意:使用 json_extract_scalar 提取數值進行計算時,需要先用 CAST 函數將其轉換為數值類型。
* | select
json_extract_scalar(Payload, '$.Method') as method,
avg(
cast(
json_extract_scalar(Payload, '$.Latency') as bigint
)
) as latency
group by
method
在什么場景下使用 json_extract 函數呢?
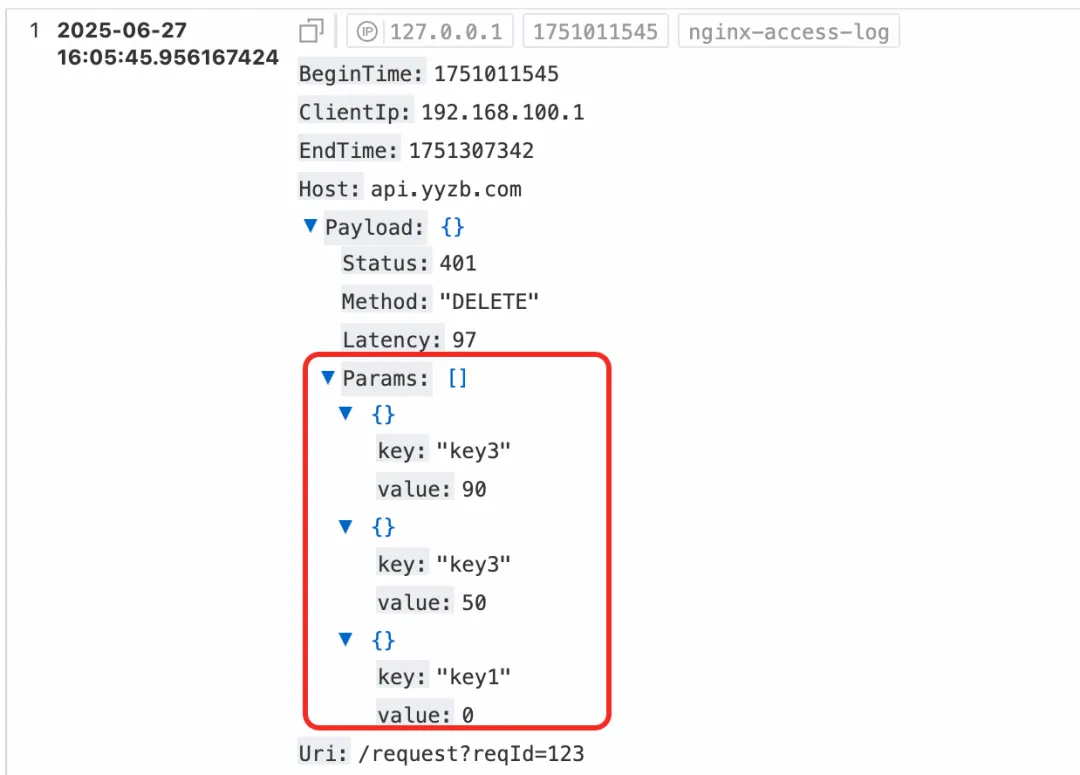
當我們需要對 JSON 對象結構本身進行一些分析處理的時候。比如下面這個日志樣例,Payload 是 JSON 日志字段,它有一個 Params 子數組,數組中又是一個個的 JSON 對象。

假設我們現在要分析每一條日志中的 Params 數組的平均長度,這個就是在分析 JSON 數組,就需要用 json_extract 函數先把數組提取出來,再用 json_array_lenth 函數去求數組的長度,然后再求平均值。
* | select
avg(
json_array_length(json_extract(Payload, '$.Params'))
)
json_extract_long/double/bool:告別繁瑣的類型轉換
json_extract_scalar 的返回值始終是 varchar 類型,這意味著在進行數值計算前,必須使用 CAST 函數進行轉換。這不僅增加了 SQL 的復雜度,還會帶來額外的性能開銷。
為了簡化查詢并提升性能,SLS 提供了類型預置的提取函數。它們可以直接提取指定類型的值,省去了 CAST 操作。
json_extract_long(json,json_path): 提取為 64 位整型json_extract_double(json,json_path): 提取為雙精度浮點型json_extract_bool(json,json_path): 提取為布爾型
例如前面的例子中的
cast(json_extract_scalar(Payload, '$.Latency') as bigint) as latency
可以簡化成
json_extract_long(Payload, '$.Latency') as latency
json_path:玩轉 JSON 路徑,精準定位
使用 json_extract 或者 json_extract_scalar 等函數從 JSON 數據中提取的時候,需要指定 json_path 字段,用來表明需要提取 JSON 中的哪一部分。
json_path 的基本格式是類似"$.a.b",$符號代表當前 JSON 對象根節點,然后通過"."號引用到要提取的節點。
- 那如果 JSON 的 key 值本身是 a.b 的形式呢?
比如 Payload 有一個子節點的名字是 user.agent,這種情況下可以用中括號[]代替.號,中括號里的節點名稱要用雙引號括起來。
* | select json_extract_scalar(Payload, '$.["user.agent"]')
- 那如果是要獲提取 JSON 數組中的某個元素呢?
這種情況下,也可以用中括號[],中括號中用數字來表示數字下標,下標從 0 開始。
* | select json_extract_long(Payload, '$.Params[0].value')
JSON 數組分析:unnest 幫你“化繁為簡”
當單個日志條目中包含一個項目列表(即 JSON 數組)時,一個常見的分析需求是將數組展開,對其中每個元素進行聚合分析。unnest 函數正是為此而生,它可以將數組中的每個元素抽出來作為獨立的行。
日志樣例
* | select
json_extract_scalar(kv, '$.key') as key,
avg(json_extract_long(kv, '$.value')) as value
FROM log,
unnest(
cast(json_extract(Payload, '$.Params') as array(json))
) as t(kv)
group by
key
執行結果

執行過程解析:
json_extract提取出Params數組。CAST(... AS array(json))將其轉換為 SLS 可識別的 JSON 數組類型。UNNEST(...) AS t(kv)將數組展開,每一行中的kv列都是原數組的一個元素(一個 JSON 對象)。- 最后,我們就可以對
kv應用json_extract函數,并進行分組聚合了。
四、SQL Copilot:智能生成 SQL 語句
面對復雜的分析需求,手寫 SQL 不僅耗時,還容易出錯。阿里云 SLS 內置的 SQL Copilot 功能,徹底改變了這一現狀。你只需用自然語言描述分析目標(例如:“展開 Payload 中的 Params 數組,按 key 分組計算 value 的平均值”),Copilot 就能自動為你生成精準的 SQL 查詢語句。
這意味著你可以將更多精力聚焦于“分析什么”,而非“如何查詢”。
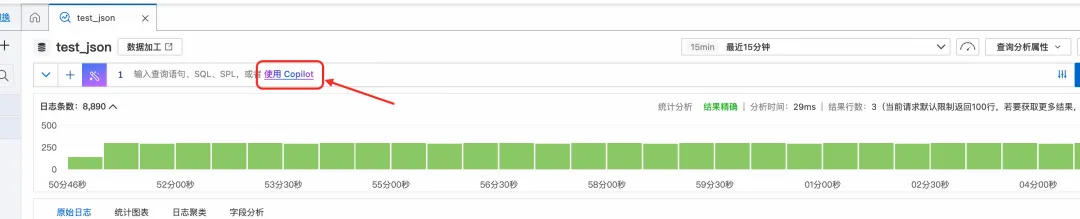

實踐建議:在分析之初,不妨先用 SQL Copilot 生成基礎查詢,再根據具體需求進行微調和優化,事半功倍。
總結與展望
高效分析 JSON 日志是一個系統工程,SLS 為此提供了從數據入口到查詢分析的全鏈路解決方案:
- 數據規整化優先:若條件允許,通過采集插件、寫入處理器或數據加工在寫入前將 JSON 展開,是實現高性能、低成本分析的最佳途徑。
- 善用索引:對于以 JSON 格式存儲的日志,為高頻訪問路徑創建子索引,或開啟自動全文索引,是加速查詢的關鍵。
- 掌握核心函數:在需要實時、靈活分析時,熟練運用
json_extract系列函數、unnest等 JSON 分析函數,它們是你深入數據內部的強大武器。 - 擁抱 AI 能力:借助 SQL Copilot,讓自然語言成為你與數據對話的橋梁,極大簡化分析過程。
掌握這些方法與技巧,你將能夠從容應對各種復雜的 JSON 日志分析場景,真正將海量日志數據轉化為驅動業務決策的寶貴資產。
點擊此處,查看日志服務 SLS 產品詳情

 浙公網安備 33010602011771號
浙公網安備 33010602011771號