
開源VLM模型一覽
0 概述
**VLM可以做的任務類型**- 視覺定位/物體檢測(Visual grounding)
- 圖像和視頻總結(image caption)
- 視覺問答(visual question answering)
- 圖像-文本對比學習
- 生成式任務
- 對齊式任務文本解析和手寫文檔
- 圖像分類
- 語義分割
- 圖像文本檢索
- 動作識別
開源的VLM系列:
- Qwen-VL系列---阿里
- GLM-VL系列---智譜AI
- Intern-VL系列 ---上海Ai Lab
- Kimi -VL----月之暗面
- Deepseek-VL2 ---深度求索
1 Qwen-vl系列
QWenVL是第一個版本,訓練的模型較小(~9.6B),并且不支持高清分辨率的圖像;QWen2-VL將模型的參數量增加到~70B,支持動態的分辨率;QWen2.5-VL將模型的數據量增加到4.1T token,并且借鑒了LLM中的RL和COT技術。 **Qwen3-VL**是目前 Qwen 家族最強的視覺-[語言模型],上下文長度**原生 256K、可拓展到 1M**,視頻理解更強,**GUI 級視覺 Agent** 更穩,OCR 擴到 **32 種語言**;適合復雜多模態工作流與視頻/長文檔檢索總結。1.1 Qwen-VL 2023.8 開創
Qwen系列首個視覺語言模型,基于**Qwen-7B**擴展,支持圖像、文本、邊界框作為輸入,支持**448x448**的高分辨率圖像,并對中文光學字符識別進行了優化。小結:QWen-VL和主流多模態框架非常像,對標的模型是Instruct-BLIP和LLaVA。作為初版的模型,QWen-VL的參數量較小、并且不支持動態分辨率的圖像。
論文:《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》
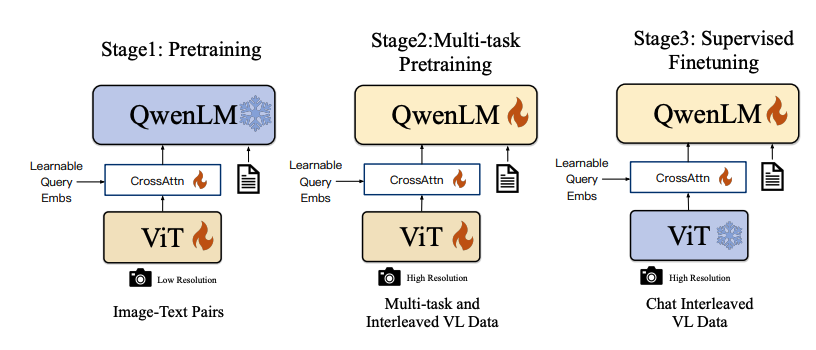
架構:以Qwen-LM作為大型語言模型基座,視覺編碼器采用Openclip ViT-bigG,通過交叉注意力層與LLM集成。
? 輸入輸出:支持圖像、文本、邊界框作為輸入,輸出包括視覺問答、圖像內文本識別、邊界框定位等。
? 分辨率處理:依賴固定的輸入分辨率448x448。
? 位置嵌入:采用標準的位置嵌入方式。
? 視頻理解:視頻理解能力有限,無明確的長視頻處理能力。
? 訓練方法:采用三階段訓練,包括預訓練、多任務預訓練和監督微調。

1.2 Qwen2-VL 2024.9 基座
核心創新是**Naive Dynamic Resolution(NDR)**與 **M-RoPE**,統一處理 **圖像與視頻**,提供 **2B/8B/72B** 尺寸,奠定了后續系列的高分辨率與視頻建模底座。參數規模覆蓋 **2B/8B/72B**。小結:QWen2-VL在QWen-VL的基礎上大大地提升了參數量和數據量,性能可以對標GPT-4o。
論文:《Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution》
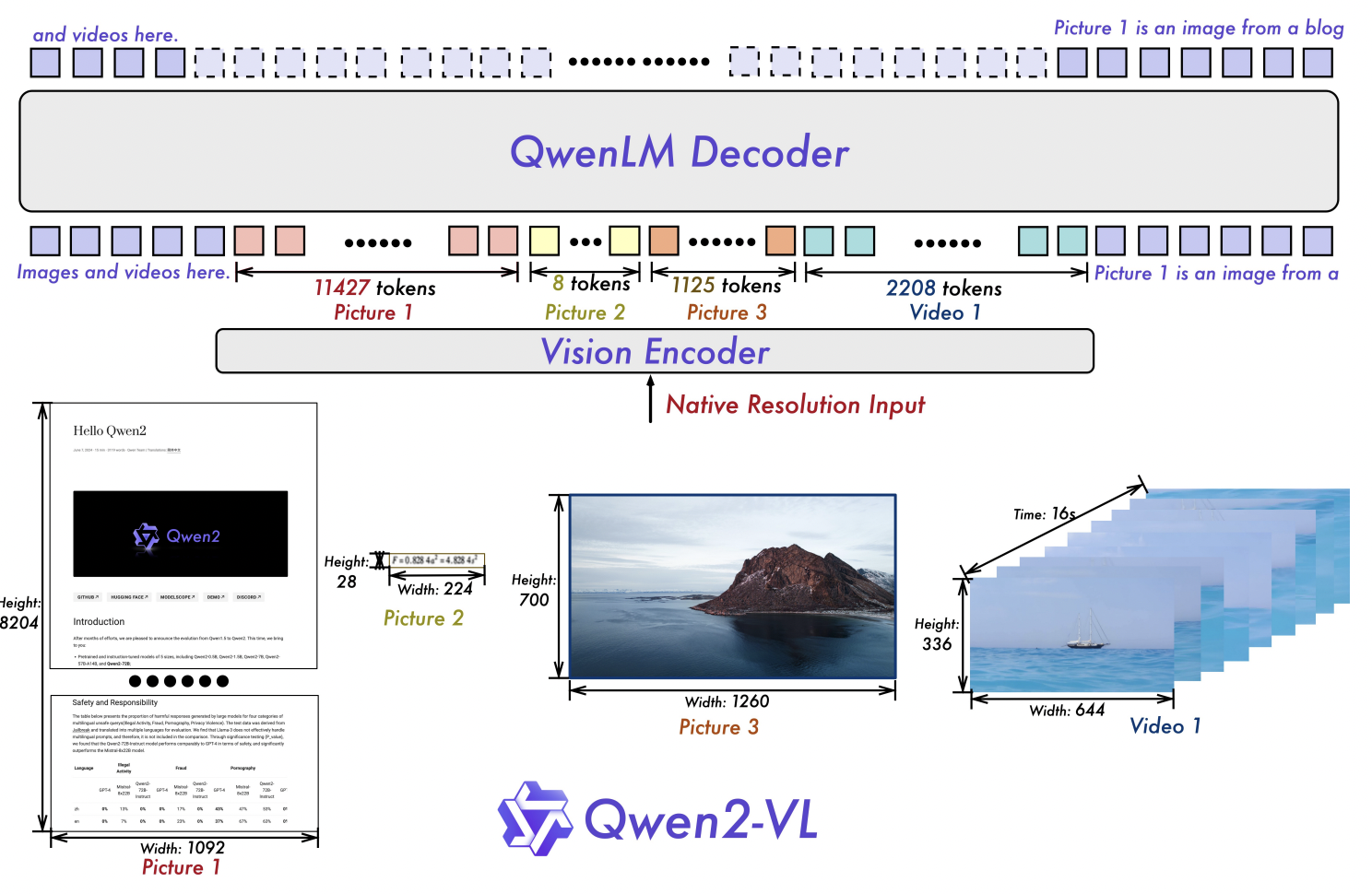
架構:
- 視覺編碼器采用重新設計的ViT,參數量為675M,且跨LLM尺寸恒定。
- 輸入輸出:輸入輸出能力在Qwen-VL基礎上進一步增強,支持更復雜的多模態任務。
- 分辨率處理:引入“樸素動態分辨率”機制,可將任意分辨率的圖像處理為動態數量的視覺標記,解決了固定分辨率的局限性。
- 位置嵌入:引入“多模態旋轉位置嵌入(M-RoPE)”,用于處理一維文本、二維視覺和三維視頻模態的位置信息。
- 視頻理解:視頻理解能力顯著提升,能夠處理20分鐘以上的視頻。
- 訓練方法:訓練配方更復雜,整合了多階段訓練策略。

1.3 Qwen2.5-VL 2025.1 功能強化
在 2 代基礎上大幅增強 文檔解析(QwenVL HTML)、精確定位(BBox/Points + 穩定 JSON 輸出)、長視頻(>1h)事件定位、視覺 Agent 等能力;開源有 **3B/7B/72B **等尺寸可選,并提供 AWQ 量化。小結:QWen2.5-VL在很多任務上的表現都小幅度領先GPT-4o,并且模型的NLP能力也保持的很好。同時,QWen2.5-VL將LLM中最新的技術例如RL、COT等都用在了VLM上。
論文:《Qwen2.5-VL Technical Report》
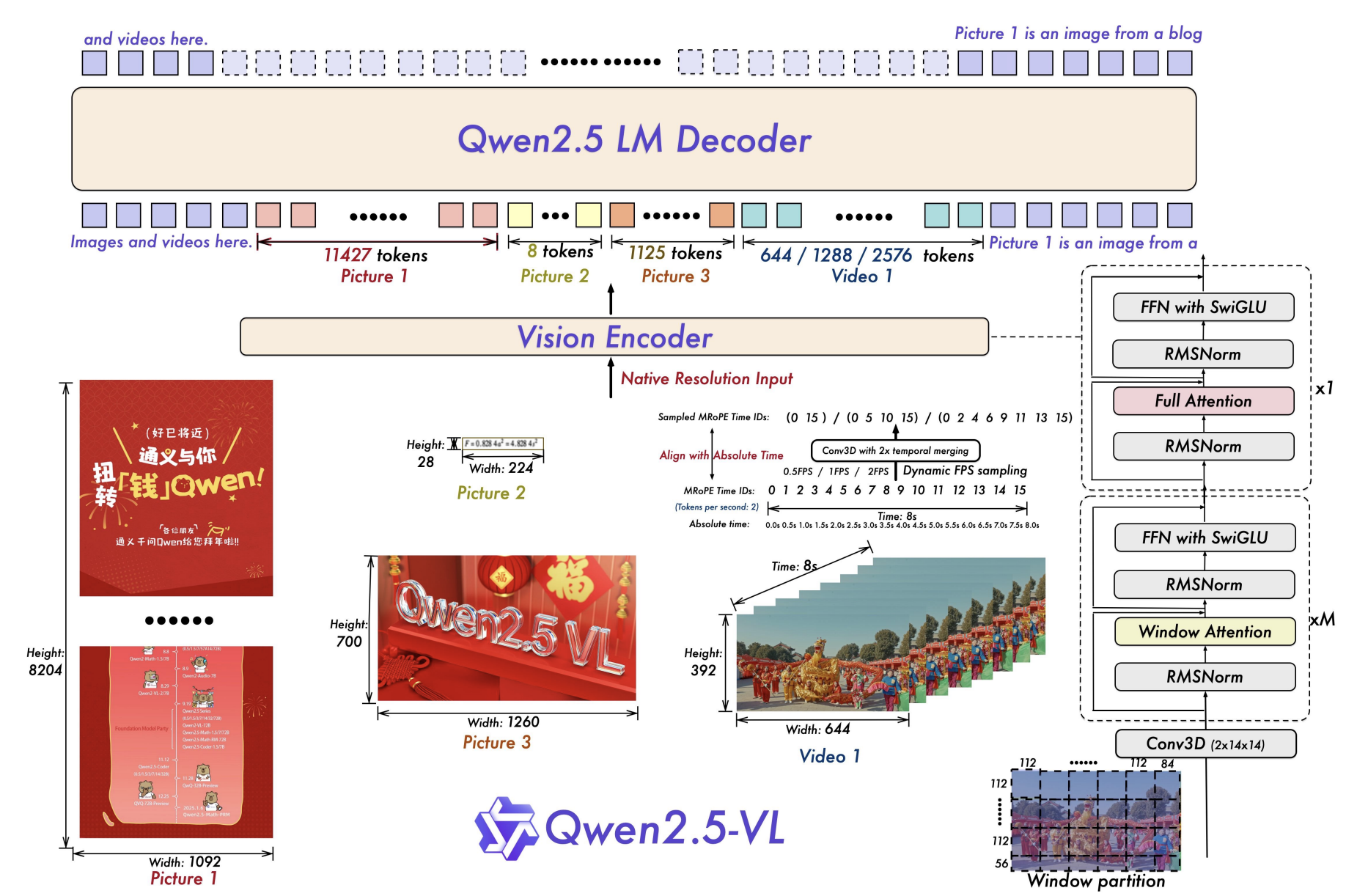
- 視覺編碼器進一步升級,采用從頭訓練的帶有窗口注意力的ViT,架構更緊密地與LLM設計原則對齊,如RMSNorm、SwiGLU等。
- 文檔解析格式 QwenVL HTML,能夠輸出帶 bbox 的 HTML 結構,適配票據、表單、論文、網頁、手機截圖等多場景。
- 精確定位與結構化 JSON:支持點/框/屬性的穩定 JSON 輸出(例如檢測頭部/手部關鍵點或機動車頭盔狀態)。
- 長視頻理解:面向 >1 小時視頻,新增“事件捕獲”能力(按片段定位)。
- 視覺 Agent:直接進行電腦/手機的 GUI 操作(工具調用 + 推理)。
1.4 Qwen3-VL 2025.9 系統躍遷
目前 Qwen 家族最強的視覺-[語言模型],支持 **Dense 與 MoE 架構**,上下文長度 **原生 256K、可拓展到 1M**,視頻理解更強,**GUI 級視覺 Agent** 更穩,OCR 擴到 **32 種語言**;適合復雜多模態工作流與視頻/長文檔檢索總結。推出 MoE 與 Dense 系列,已放出 Qwen3-VL-235B-A22B 與 Qwen3-VL-30B-A3B(含 Thinking 版、FP8 版本);README 明確 原生 256K→1M上下文、視覺 Agent/視頻/空間三維推理全面升級。
github:https://github.com/QwenLM/Qwen3-VL
模型架構升級:
- 交錯式MRoPE:通過強大的位置嵌入,在時間、寬度和高度上實現全頻譜分配,增強長時視頻推理能力。
- DeepStack:融合多層級的ViT特征,以捕捉細粒度的細節并優化圖像與文本的對齊效果。
- 文本-時間戳對齊:超越T-RoPE,實現精確的時間戳錨定事件定位,從而增強視頻的時間建模能力。
Qwen3-VL 的目標,是讓模型不僅能“看到”圖像或視頻,更能真正看懂世界、理解事件、做出行動。為此,我們在多個關鍵能力維度上做了系統性升級,力求讓視覺大模型從“感知”走向“認知”,從“識別”邁向“推理與執行”。
關鍵升級:
- 視覺智能體(Visual Agent):Qwen3-VL 能操作電腦和手機界面、識別 GUI 元素、理解按鈕功能、調用工具、執行任務,在 OS World 等 benchmark 上達到世界頂尖水平,能通過調用工具有效提升在細粒度感知任務的表現。
- 純文本能力媲美頂級語言模型:Qwen3-VL 在預訓練早期即混合文本與視覺模態協同訓練,文本能力持續強化,最終在純文本任務上表現與 Qwen3-235B-A22B-2507 純文本旗艦模型不相上下 —— 是真正“文本根基扎實、多模態全能”的新一代視覺語言模型。
- 視覺 Coding 能力大幅提升:實現圖像生成代碼以及視頻生成代碼,例如看到設計圖,代碼生成 Draw.io/HTML/CSS/JS 代碼,真正實現“所見即所得”的視覺編程。
- 空間感知能力大幅提升:2D grounding 從絕對坐標變為相對坐標,支持判斷物體方位、視角變化、遮擋關系,能實現 3D grounding,為復雜場景下的空間推理和具身場景打下基礎。
- 長上下文支持和長視頻理解:全系列模型原生支持 256K token 的上下文長度,并可擴展至 100 萬 token。這意味著,無論是幾百頁的技術文檔、整本教材,還是長達兩小時的視頻,都能完整輸入、全程記憶、精準檢索,支持視頻精確定位到秒級別時刻。
- 多模態思考能力顯著增強:Thinking 模型重點優化了 STEM 與數學推理能力。面對專業學科問題,模型能捕捉細節、抽絲剝繭、分析因果、給出有邏輯、有依據的答案,在 MathVision、MMMU、MathVista 等權威評測中達到領先水平。
- 視覺感知與識別能力全面升級:通過優化預訓練數據的質量和廣度,模型現在能識別更豐富的對象類別——從名人、動漫角色、商品、地標,到動植物等,覆蓋日常生活與專業領域的“萬物識別”需求。
- OCR 支持更多語言及復雜場景:支持的中英外的語言從 10 種擴展到 32 種,覆蓋更多國家和地區;在復雜光線、模糊、傾斜等實拍挑戰性場景下表現更穩定;對生僻字、古籍字、專業術語的識別準確率也顯著提升;超長文檔理解和精細結構還原能力進一步提升。
模型性能
我們從十個維度全面評估了模型的視覺能力,涵蓋綜合大學題目、數學與科學推理、邏輯謎題、通用視覺問答、主觀體驗與指令遵循、多語言文本識別與圖表文檔解析、二維與三維目標定位、多圖理解、具身與空間感知、視頻理解、智能體任務執行以及代碼生成等方面。整體來看,Qwen3-VL-235B-A22B-Instruct 在非推理類模型中多數指標表現最優,顯著超越了 Gemini 2.5 Pro 和 GPT-5 等閉源模型,同時刷新了開源多模態模型的最佳成績,展現了其在復雜視覺任務中的強大泛化能力與綜合性能。
更多方面的性能可以查看官方文檔。
1.5 Qwen-vl系列內對比:
| 維度 | Qwen2-VL | Qwen2.5-VL | Qwen3-VL |
|---|---|---|---|
| 圖像分辨率與Token | NDR 動態分辨率 -> 動態 token | 延續并在定位/文檔/多物體識別上強化 | 在 DeepStack 下進一步細粒度對齊 |
| 位置編碼 | M-RoPE | M-RoPE + 任務側適配 | Interleaved-MRoPE + 文本-時間戳對齊 |
| 視頻 | 統一范式(圖像/視頻) | >1h 長視頻 + 事件片段定位 | 更強長視頻,秒級索引與時間對齊 |
| 文檔解析 | 基礎能力 | QwenVL HTML 結構化解析 | 解析質量/魯棒性繼續增強 |
| OCR | 強 | 多語種 OCR(票據、表格等結構化提取) | 32 語種,低光/模糊/傾斜更穩 |
| 定位/輸出 | 基礎 | BBox/Points + 穩定 JSON | 2D 定位更強,并向 3D空間推理擴展 |
| 視覺 Agent | 初步 | 可操作 PC/手機(工具/GUI) | GUI 交互更強(元素/功能理解、任務閉環) |
| 上下文長度 | 輕度長上下文 | 進一步增強(文檔/視頻工作流) | 原生 256K -> 1M(書本/小時級視頻) |
| 尺寸/變體 | 2B/8B/72B | 3B/7B/72B(后有 32B)+ AWQ | Dense & MoE,如 235B-A22B、30B-A3B(含 FP8 版) |
2 GLM-VL系列
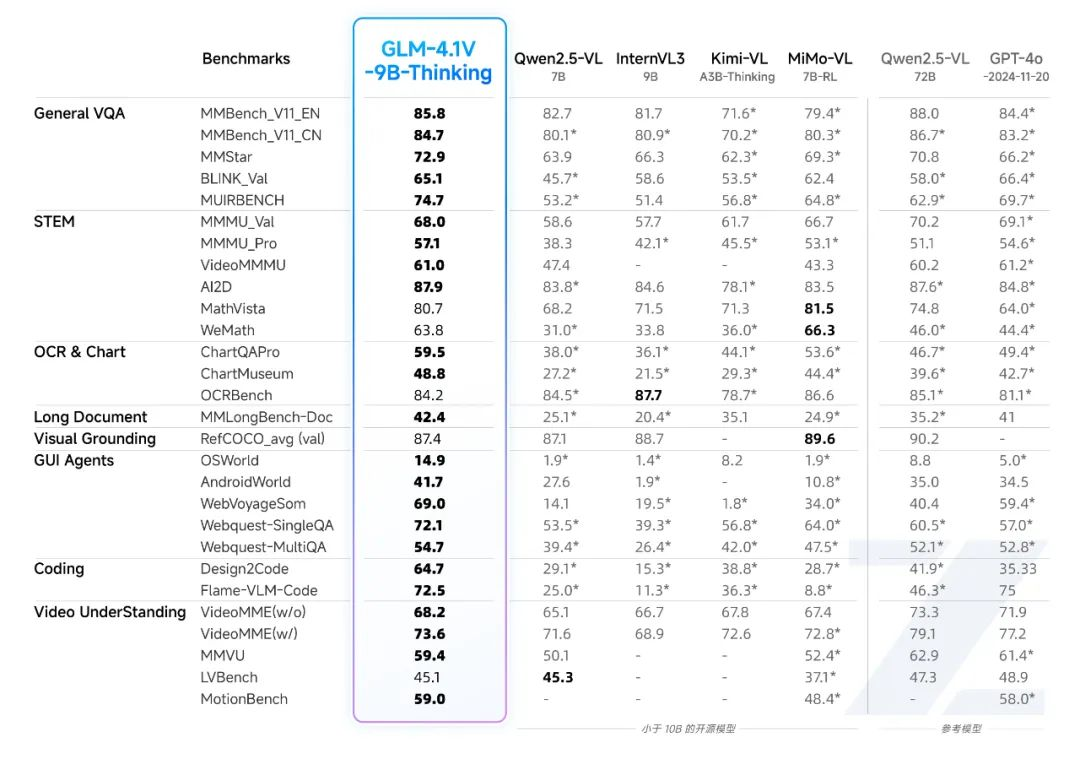
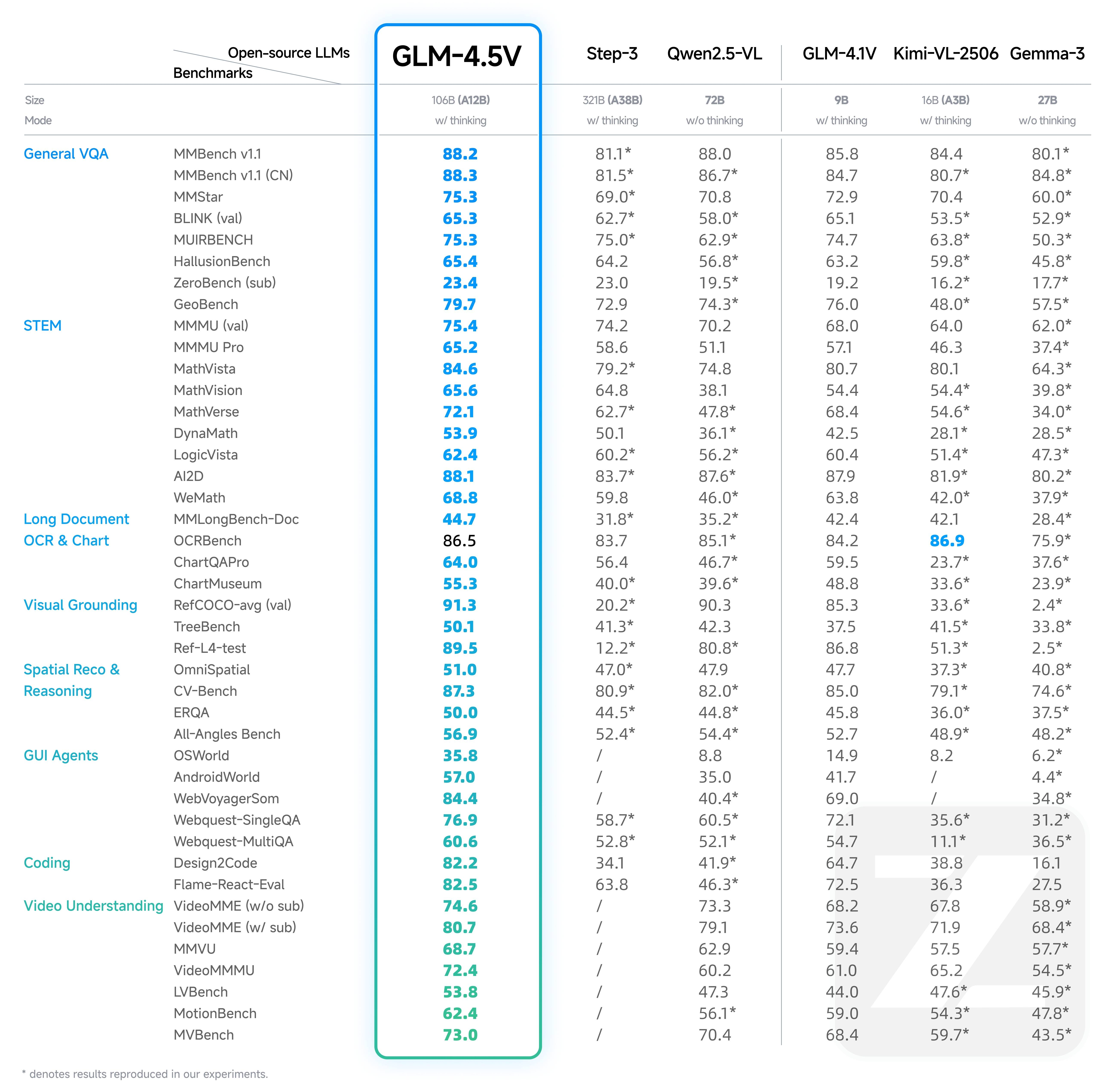
發布GLM-4.1V-9B-Thinking和GLM-4.5V兩個模型,其中GLM-4.5V是一個參數量106B,激活12B的MOE結構的模型,且包含thinking和non-thinking兩個。其中比較有亮點的是GLM-4.1V-9B-Thinking一個9B的模型在29個Benchmark上超過了Qwen2.5- VL -72B(non-thinking模型)。大模型的發展方向有兩個,一個往大的方向發展:不斷的探索scaling law。一個是往小的方向發展:參數量比較你小,但是性能比你好。所以GLM-4.1V-9B-Thinking一個9B參數的模型在多個方面超過一個72B的模型,還是很令人吃驚的。
GLM-4.1V-9B-Thinking成功的關鍵我覺得有兩個:1. 高質量數據的構建(具體數量位置,數據集也沒有開源)2. ReinforcementLearning with Curriculum Sampling (RLCS) ,RLCS在訓練的過程通過樣本的困難程度動態的去采樣合適難度的樣本(不要太難、也不要太簡單,seed-1.5VL中有同樣的思想),這個不是超過Qwen-72B的關鍵,關鍵其實還是在RL階段構建的任務是綜合的,包含各種任務,在訓練方法上即包括RLVF也包含RLHF,并且兩者結合。 對于大規模的RL,很容易訓練不穩定,智普團隊在這篇論文也給出一些發現和洞察,比如針對各個任務設計合適的獎勵系統,要不然很容易遇到reward hacking等問題。
參考:GLM-VL系列論文解析
2.1 GLM-4.1V-Thinking 2025.7
由智譜AI與清華大學聯合研發,采用Reinforcement Learning with Curriculum Sampling (RLCS)訓練框架,通過大規模預訓練構建高潛力基礎模型,結合監督微調和強化學習,實現跨任務能力提升。在28個公共基準測試中,該模型**(9B參數)**幾乎全面超越Qwen2.5-VL-7B,在18項任務上媲美甚至優于更大規模的Qwen2.5-VL-72B,并在長文檔理解、STEM推理等任務上與GPT-4o表現相當或更優。論文:GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
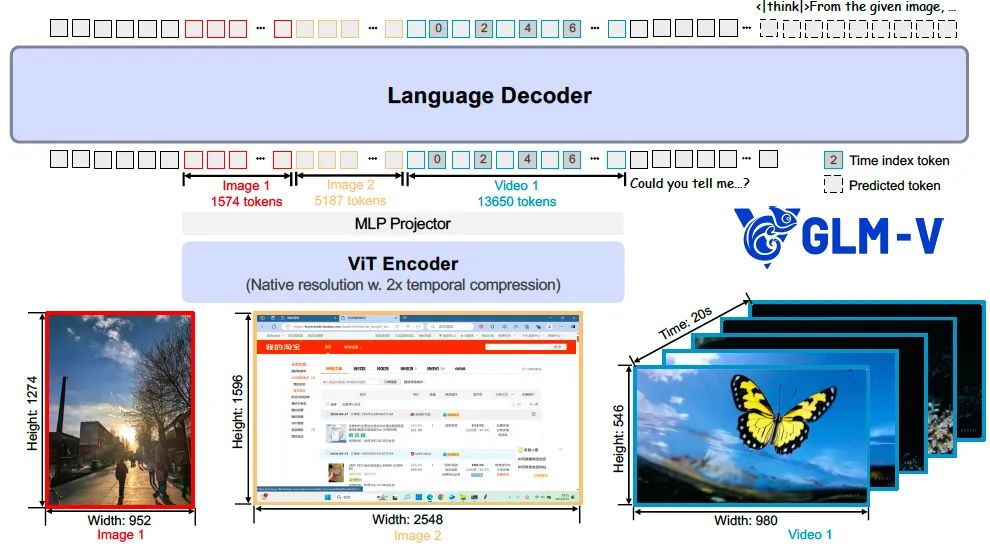
GLM-4.1V-Thinking 模型架構由三個核心模塊組成:視覺編碼器(ViT Encoder)、多層感知機適配器(MLP Projector)以及語言解碼器(Language Decoder)。
我們選用 AIMv2-Huge 作為視覺編碼器,GLM 作為語言解碼器。在視覺編碼器部分,我們將原始的二維卷積替換為三維卷積,從而實現對視頻輸入在時間維度上的下采樣,有效提升了處理效率。對于靜態圖像輸入,則通過復制幀的方式以保持輸入格式的一致性。
為進一步增強模型對任意圖像分辨率和寬高比的適應能力,我們引入了兩項關鍵改進。
其一,融合二維旋轉位置編碼(2D-RoPE),使模型能夠穩定處理極端寬高比(如超過200:1)和超高分辨率(如4K以上)的圖像;
其二,為保留ViT預訓練模型的原有能力,我們保留了其可學習的絕對位置嵌入,并通過雙三次插值方式在訓練過程中動態適配不同分辨率輸入。
在語言解碼器中,我們對原始的旋轉位置編碼(RoPE)進行了三維擴展(3D-RoPE)。這一設計顯著增強了模型在多模態輸入處理中的空間理解能力,同時保持了其在文本生成方面的原始性能。
模型能力:
GLM-4.1V-9B-Thinking 通過有效的混合訓練融合了豐富的多模態模型能力,包括但不限于:
- 視頻理解 : 能夠解析最長兩小時的視頻內容,通過推理對視頻中的時間、人物、事件和邏輯關系進行準確分析;
- 圖像問 答 : 對圖像中的內容進行深入分析和解答,具備較強的邏輯能力和世界知識;
- 學科 解題 : 支持對數學、物理、生物、化學等學科問題的看圖解題,通過推理給出詳細的思考過程;
- 文字識 別 : 對圖片和視頻中的文字和圖表內容進行準確抽取和結構化輸出;
- 文檔解讀 : 對金融、政務、教育等領域的文檔內容進行準確的原生理解、抽取、提煉和問答;
- Grounding : 識別圖片中的特定區域并抽取坐標位置,支持各種需要定位信息的下游任務;
- GUI Agent : 識別網頁、電腦屏幕、手機屏幕等交互界面元素,支持點擊、滑動等指令執行能力;
- 代碼生成 : 能夠基于輸入的圖片文字內容自動編寫前端代碼,看圖寫網頁。
2.2 GLM-4.5V 2025.8
GLM-4.5V 是智譜新一代基于 MOE 架構的視覺推理模型,以 106B 的總參數量和 12B 激活參數量,在各類基準測試中達到全球同級別開源多模態模型 SOTA,涵蓋圖像、視頻、文檔理解及 GUI 任務等常見任務。推薦場景:
- 前端復刻:支持將網頁截圖或完整瀏覽錄屏輸入模型,自動解析布局與交互邏輯,高精度還原頁面元素與二級頁面結構,生成可交互的 HTML 代碼,便于直接使用或二次優化。
- Grounding:可根據文本描述精準定位指定人物或物體,支持按外貌、衣著等多條件組合篩選。適用于安檢、質檢、內容審核、遙感監測等實業場景,定位精度高。
- GUI Agent:識別并理解屏幕畫面,執行點擊、滑動等操作指令,精準完成如 PPT 修改、Word 編輯等任務,全程自動化,適用于各類辦公場景,為智能體操作任務提供可靠支持。
- 復雜長文檔解讀:支持對長文檔進行深度解析,處理文本、表格、圖形等多模態內容,可總結、翻譯、提取關鍵信息,并在原有觀點基礎上提出新見解,適用于研報分析、科研、教育等專業場景。
- 圖像識別和推理:結合強推理能力與豐富世界知識,在無需搜索的情況下推斷圖像背景信息。支持將圖表、曲線等內容轉為結構化數據,精確還原內容與布局,適用于無電子版表格的快速數字化處理,避免手動錄入的繁瑣與錯誤。
- 視頻理解:支持解析長時視頻內容,精準識別并推理視頻中的時間線、人物關系、事件發展及因果邏輯,適用于安防監控、影視內容分析、輿情事件追蹤等領域,實現高效的視頻信息抽取與洞察。
- 學科解題:具備圖文感知、知識儲備與推理能力,能夠解決復雜的圖文結合題目,適用于 K12 教育場景中的解題和講解需求。
3 Intern-vl系列
InternVL系列是Shanghai AI Laboratory開源的一系列多模態大模型。InternVL (2023/12)
創新點:
- 大規模視覺編碼器(InternViT-6B),解決參數規模不匹配問題。
- 雙組件架構與語言中間件(InternViT-6B + QLLaMA)。
- 漸進式對齊策略,包括對比學習和生成學習。
- 越的性能表現,在32個通用視覺-語言基準測試中領先。
InternVL 1.5 (2024/4)
主要創新點:
- 強大的視覺編碼器,復用了V1.0中提出的6B大視覺模型。
- 動態高分辨率技術,支持4K分辨率輸入。
- 高質量雙語數據集,構建了覆蓋常見場景和文檔圖像的中英文高質量數據集。
- 整個模型架構非常簡潔,框架允許圖像模態和已經編碼好詞匯表的文本一起輸入到InternLM2-Chat-20B。I
InternVL 3.5 (2025/08)
論文:InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
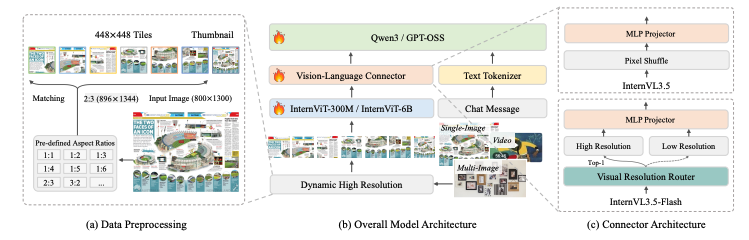
主要創新點:
- 級聯強化學習(Cascade RL),結合離線RL和在線RL的兩階段訓練策略。
- 視覺分辨率路由器(ViR),動態調整圖像token壓縮率,提升處理高分辨率圖像的效率。
- 解耦視覺-語言部署(DvD),將視覺編碼器和語言模型分離到不同的GPU服務器上,并行異步執行。
- 模型規模與能力,提供從1B到241B等多種參數規模的版本,支持GUI交互和具身智能等新型智能體任務。
- 綜合性能與影響:InternVL 3.5,尤其是其最大的InternVL3.5-241B-A28B模型,在包括通用多模態理解、復雜推理、純文本任務以及智能體任務在內的廣泛基準測試中,取得了開源模型中的最先進(SOTA)性能。
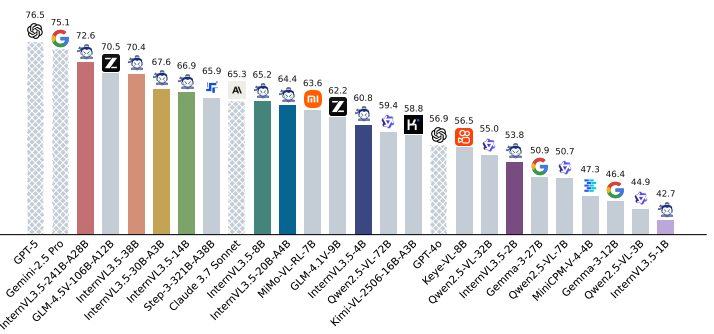
InternVL3.5的主要功能
多模態感知:在圖像、視頻問答等多模態感知任務中表現出色,241B-A28B 模型以 74.1 的平均得分超越現有開源模型,接近商業模型 GPT-5(74.0)。
多模態推理:在多學科推理基準 MMMU 中獲得 77.7 分,較前代提升超 5 個百分點,位列開源榜首。
文本能力:在 AIME、GPQA 及 IFEval 等多個基準中,模型可以取得 85.3 的均分,處于開源領先。
GUI 智能體:強化了 GUI 智能體能力,可實現跨平臺自動化操作,例如在 ScreenSpot GUI 定位任務中以 92.9 分超越主流開源模型。
具身空間推理:具備更強的 grounding 能力,可以泛化到全新的復雜具身場景,支持可泛化的長程物體抓取操作。
矢量圖形處理:在 SGP-Bench 以 70.7 分刷新開源紀錄,能夠有效應用于網頁圖形生成與工程圖紙解析等專業場景。
4 Kimi-VL系列
Kimi-VL系列是由Moonshot AI(月之暗面)開發的開源視覺語言模型,專注于多模態理解和推理能力。發布時間:? Kimi-VL:2025年4月11日正式發布。
? Kimi-VL-Thinking:與Kimi-VL同時發布,作為支持長思考推理能力的版本。
代碼和模型發布的地址:https://github.com/MoonshotAI/Kimi-VL
Kimi-VL的架構由三個主要部分組成:原生分辨率視覺編碼器(MoonViT)、MLP投影器和MoE語言模型,
- 視覺編碼器(MoonViT):能夠原生處理不同分辨率的圖像,無需復雜的子圖像分割和拼接操作。
- MLP投影器:用于將視覺特征投影到語言模型的嵌入空間。
- MoE語言模型:基于Moonlight模型,具有高效的參數激活機制,支持長鏈推理(CoT)。
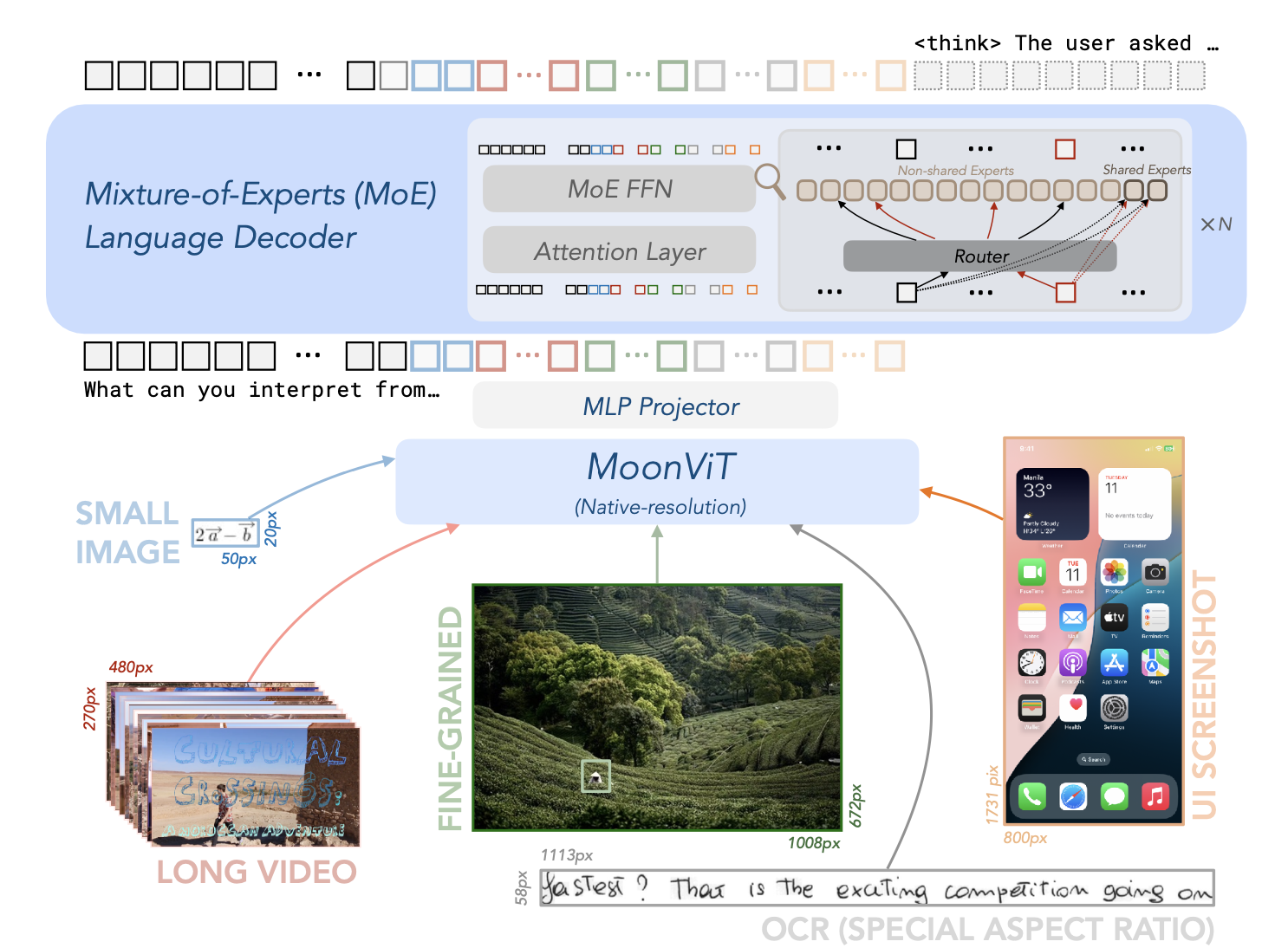
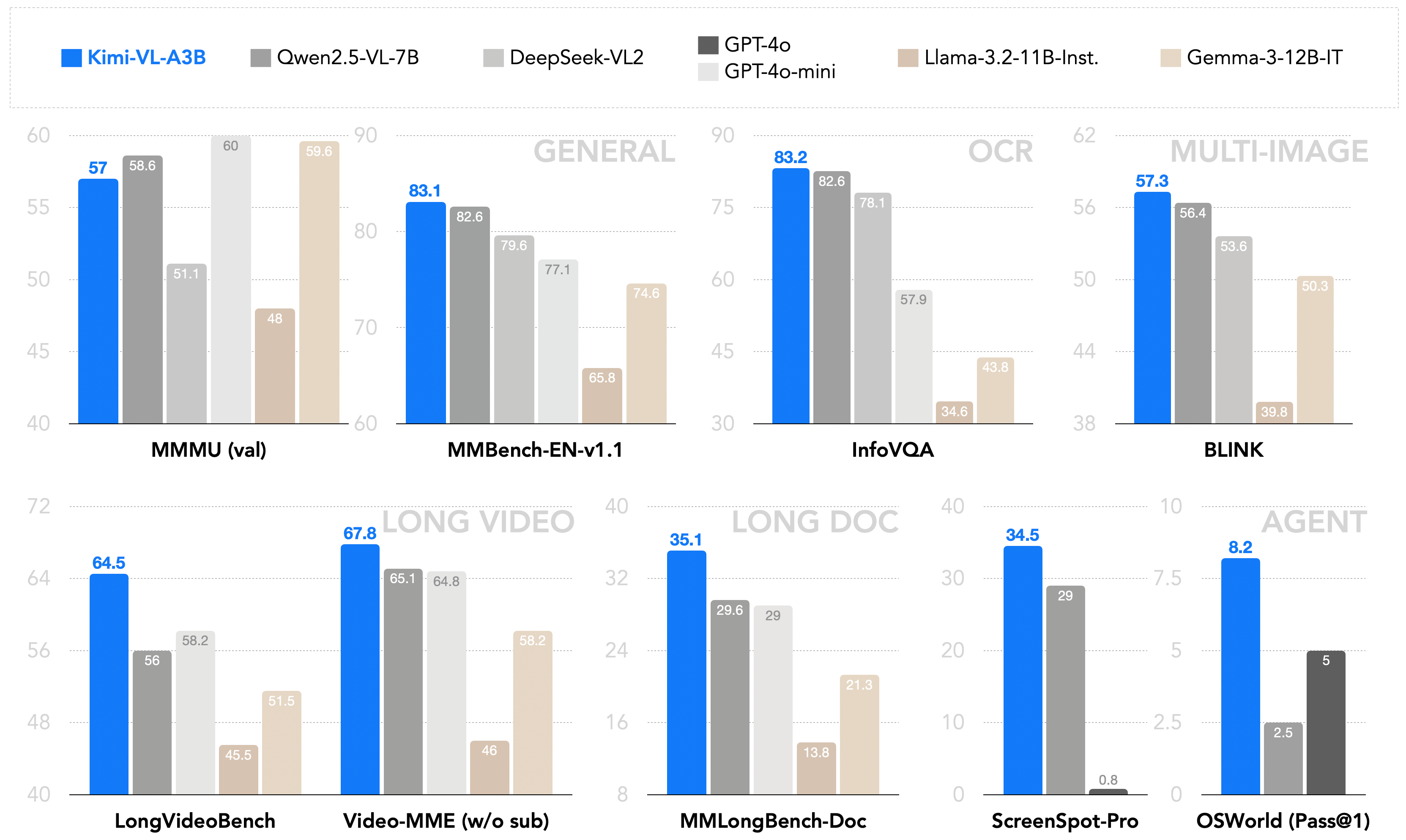
作為一個高效的模型,Kimi-VL能夠穩健地處理多種任務(細粒度感知、數學、大學水平的問題、OCR、代理等),這些任務覆蓋了廣泛的輸入形式(單圖像、多圖像、視頻、長文檔等)。與現有的10B級密集型視覺語言模型(VLMs)和DeepSeek-VL2(A4.5B)的簡要比較:
憑借有效的長思考能力,Kimi-VL-A3B-Thinking(2504版本)能夠在MathVision基準測試中達到與30B/70B前沿開源視覺語言模型(VLMs)相當的性能:
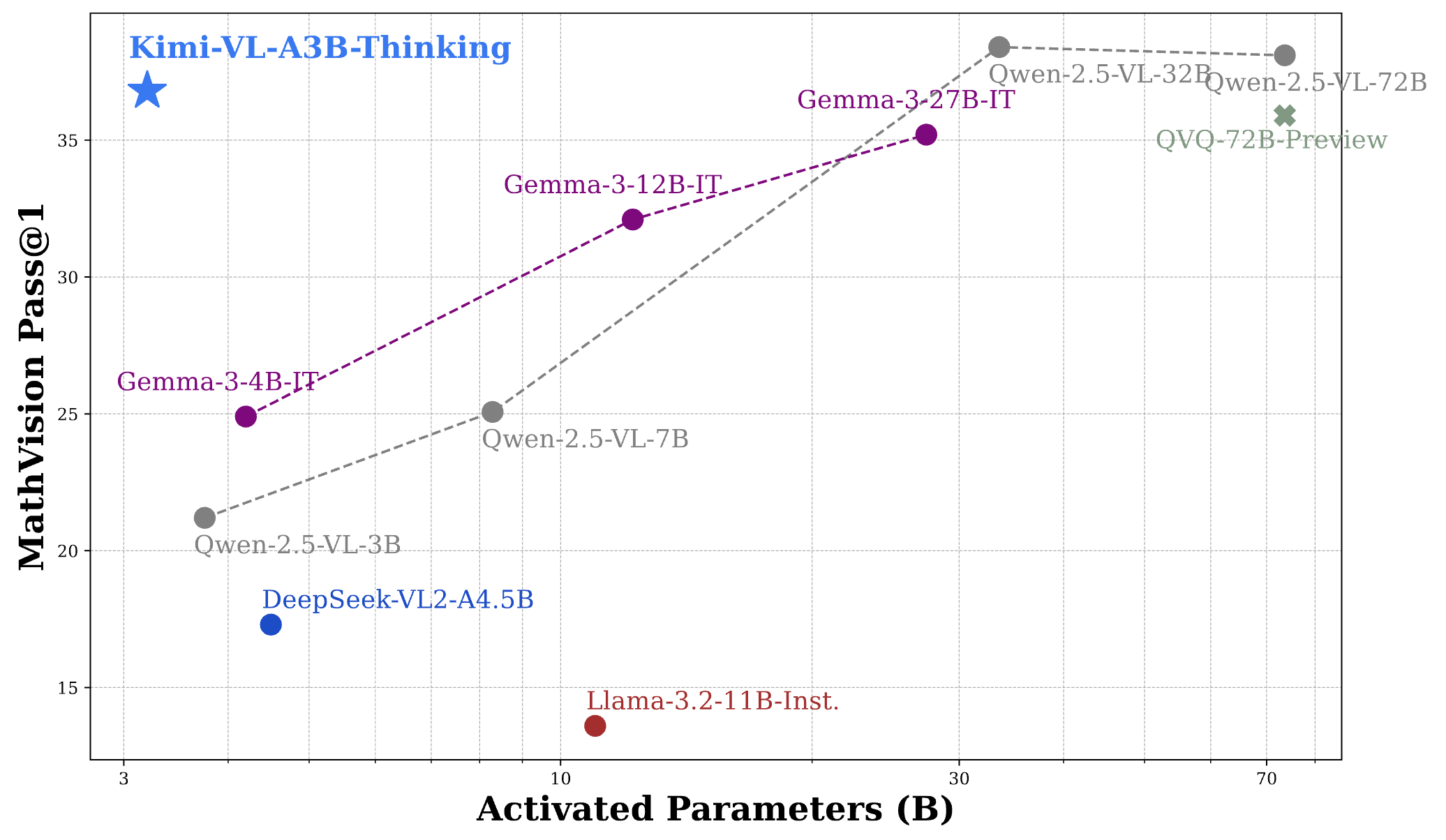
對于常見的通用多模態感知和理解、OCR、長視頻和長文檔、視頻感知以及操作系統代理(OS-agent)的使用,我們推薦使用Kimi-VL-A3B-Instruct進行高效的推理;同時,我們的新思考版本Kimi-VL-A3B-Thinking-2506在實現更好的多模態推理技能的同時,也具有出色的多模態感知、長視頻和長文檔以及操作系統代理定位能力。
| Model | #Total Params | #Activated Params | Context Length |
|---|---|---|---|
| Kimi-VL-A3B-Thinking-2506 | 16B | 3B | 128K |
| Kimi-VL-A3B-Instruct | 16B | 3B | 128K |
| Kimi-VL-A3B-Thinking (deprecated) | 16B | 3B | 128K |
5 DeepSeek-VL系列
DeepSeek-VL發布時間:2024年3月
版本:1.3B和7B參數規模,共4個版本(包括基礎版和對話版)
DeepSeek-VL2 2024年12月
https://github.com/deepseek-ai/DeepSeek-VL2
論文標題:DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
DeepSeek-VL2 在 DeepSeek-VL 基礎上做了兩個主要升級。
- 視覺組件結合了 Dynamic Tiling 視覺編碼策略,旨在處理具有不同縱橫比的高分辨率圖像。
- 語言組件利用具有多頭潛在注意力機制的DeepSeek MoE模型,該機制將鍵值緩存壓縮成潛在向量,以實現高效推理和高吞吐量。
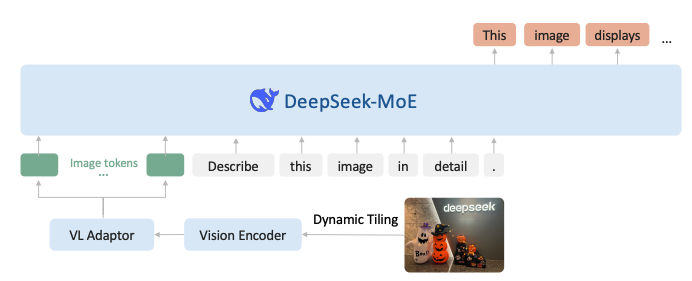
在改進的視覺語言數據集上進行訓練,在各種任務中展示了優越的能力,包括 VQA、OCR、文檔/表格/圖表理解和視覺定位(Visual grounding)等。DeepSeek-VL2系列有三個模型:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small和DeepSeek-VL2,分別具有10億、28億和45億個激活參數。
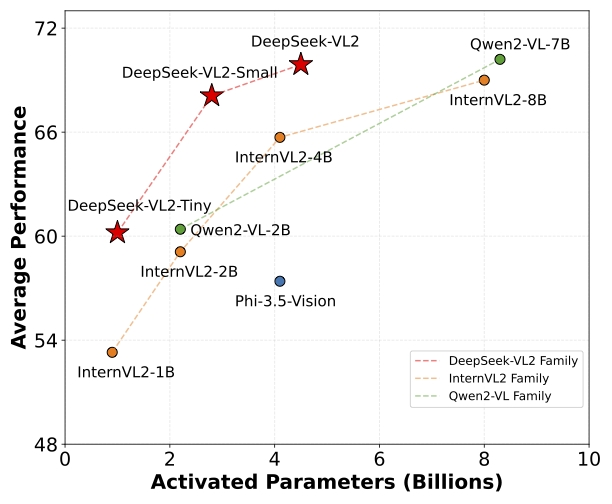
參考:
1,Qwen3-VL 全面解析:從 Qwen2-VL → Qwen2.5-VL → Qwen3-VL 的三代進化。
2,Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
3,Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
4,Qwen2.5-VL Technical Report
5,https://github.com/QwenLM/Qwen3-VL
6,GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
7,InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency

 浙公網安備 33010602011771號
浙公網安備 33010602011771號