
RAG 實踐(三)-基于Langchain的RAG demo
通常來說基于LangChain實現一個RAG的原理如下:
加載文件 -> 讀取文本 -> 文本分割 -> 文本向量化 -> 問句向量化 -> 在文本向量中匹配出與問句向量最相似的top k個 -> 匹配出的文本作為上下文和問題一起添加到prompt中 -> 提交給LLM生成回答。
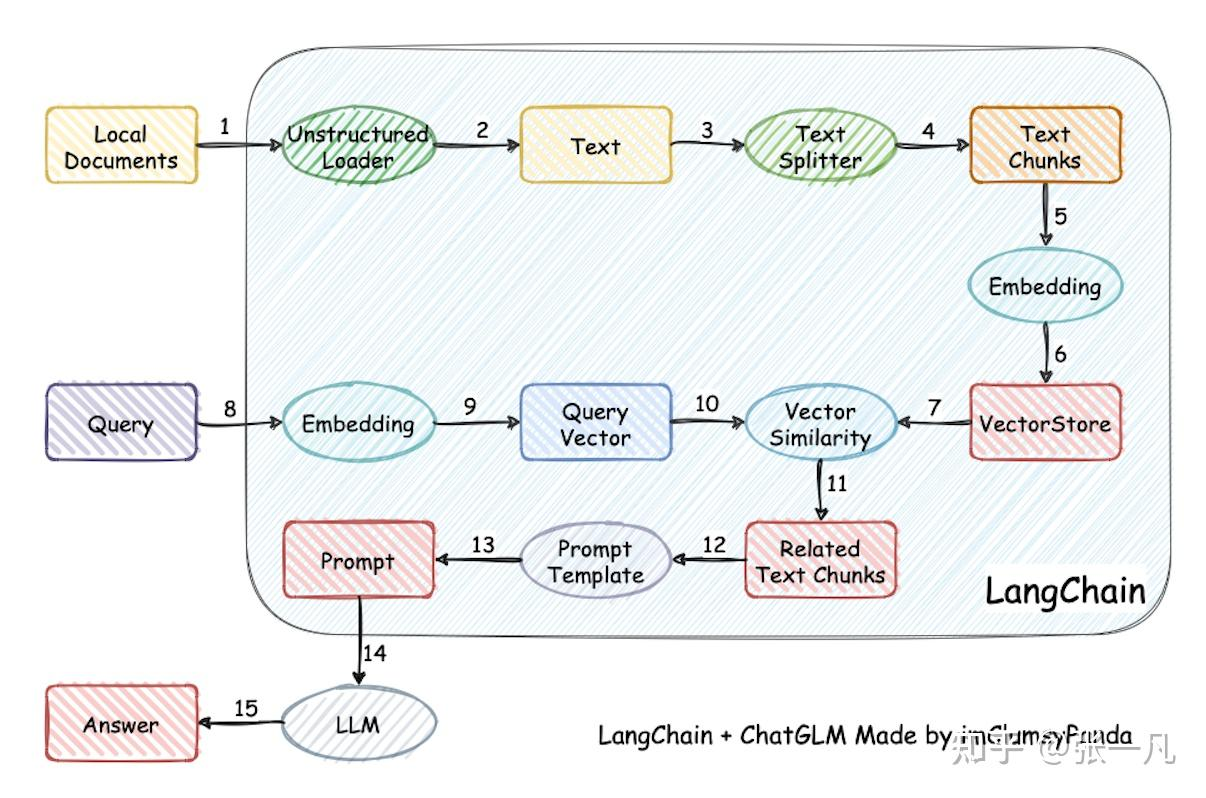
核心流程包括:
- 數據攝取:加載 PDF/Word/ 網頁等格式文件
- 文本分塊:將長文本拆分為 500-1000 字的語義片段
- 向量索引:通過 Embedding 模型生成向量存儲到數據庫
- 檢索增強:根據用戶問題檢索相關文檔片段
- 生成優化:將檢索結果與問題結合生成最終回答
| 組件 | 推薦方案 | 替代方案 |
|---|---|---|
| 文本加載 | PyPDF2/Unstructured | BeautifulSoup(網頁) |
| 分塊工具 | RecursiveCharacterTextSplitter | CharacterTextSplitter |
| Embedding | BAAI/BGE-large-zh-v1.5 | text-embedding-ada-002 |
| 向量數據庫 | FAISS(本地)/Pinecone(云端) | Chroma/Qdrant |
| LLM | Qwen-1.8/InternLM-3.0 | GPT-4-Turbo |
| 部署框架 | FastAPI+Uvicorn | Flask+Gunicorn |
數據采集:
from langchain_community.document_loaders import PyPDFLoader
# 1. 文本加載:加載 PDF 文件
def load_pdf(file_path):
loader = PyPDFLoader(file_path)
documents = loader.load()
return documents
文本分塊:
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 2. 文本分塊
def split_text(documents, chunk_size=1000, chunk_overlap=200):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = text_splitter.split_documents(documents)
return chunks
向量數據庫初始化:
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
# 3. 獲取嵌入并存入 FAISS
def create_embeddings_and_store(chunks):
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vectorstore = FAISS.from_documents(chunks, embeddings)
vectorstore.save_local("faiss_index")
return vectorstore
RAG 系統核心組件構建:
檢索器配置
# 4. 配置檢索器
def configure_retriever(vectorstore):
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5, "score_threshold": 0.7})
return retriever
云端模型調用:
from langchain_community.chat_models import ChatOpenAI
llm= ChatOpenAI(model="qwen-plus",
openai_api_key="sk-xxx”,
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
RAG 鏈構建
from langchain.chains import RetrievalQA
prompt_template = """
已知信息:
{context}
用戶問題:
{question}
請基于已知信息,以專業技術文檔的格式回答用戶問題,要求邏輯清晰、步驟明確。
"""
chain_type_kwargs = {
"prompt": PromptTemplate.from_template(prompt_template),
"verbose": True
}
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs
)
核心評估指標
| 指標 | 計算方法 | 優化方向 |
|---|---|---|
| 上下文召回率 | 檢索到的關鍵信息數 / 總關鍵信息數 | 調整分塊策略、優化 Embedding |
| 答案忠實度 | 基于檢索內容的事實數 / 答案總事實數 | 強化 prompt 約束、增加檢索結果權重 |
| 響應相關性 | 人工標注相關性評分 | 優化檢索排序、調整 prompt 模板 |
檢索優化
# 混合檢索(向量+關鍵詞)
from langchain.retrievers import EnsembleRetriever
vector_retriever = vector_db.as_retriever()
bm25_retriever = BM25Retriever.from_documents(chunks)
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.7, 0.3]
)
生成優化
# 流式輸出
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = ChatOpenAI(
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
temperature=0.1
)
多模態支持:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, Tool
tools = [
Tool(
name="ImageSearch",
func=lambda query: image_search_api(query),
description="用于搜索與查詢相關的圖片"
)
]
agent = initialize_agent(
tools,
OpenAI(temperature=0),
agent="zero-shot-react-description",
verbose=True
)
長期記憶增強:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
memory=memory
)

 浙公網安備 33010602011771號
浙公網安備 33010602011771號