
日常問題排查-Younggc突然變長
日常問題排查-Younggc突然變長
前言
研發突然反饋一個版本上線后線上系統younggc時間變長,而這個版本修改的代碼就是非常普通的CRUD,但是younggc時間就硬生生暴漲了100%。導致天天告警,雖然問題不大,但非常想知道原因,于是向我求助。
問題現場
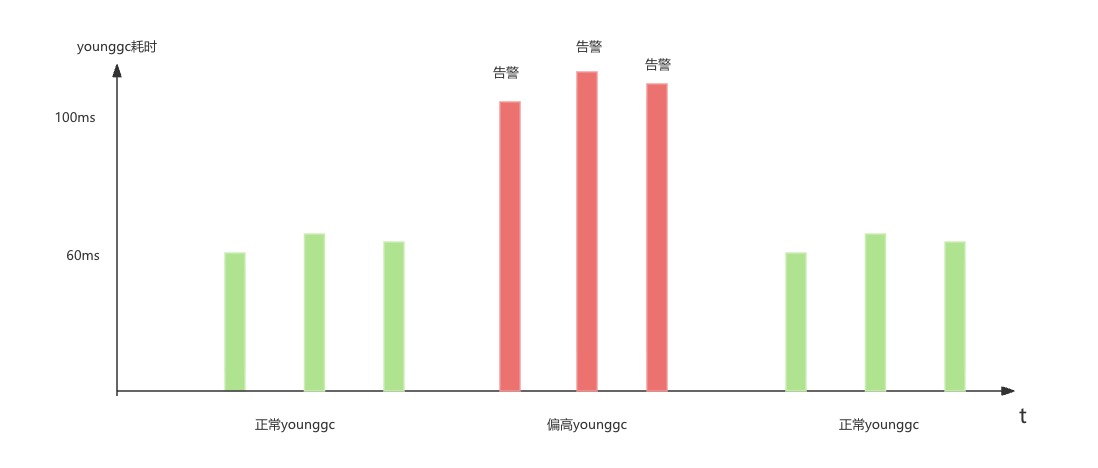
如下圖所示,younggc一個版本后從60ms漲到了120ms。而告警的閾值在100ms,導致每次younggc都告警。顯然,調整告警閾值是最簡單的方案,但作為一個有好奇心對技術很執著的同學,他很糾結于這個問題。當然我也是遇到有意思的問題就必須去一探究竟的性格,兩者一拍即合。
代碼改動
第一反應肯定是去看代碼的變化,代碼改變如下所示:
改之前:
void functionA(){
......
a.setBuinsessKey(key1);
......
}
改之后:
void functionB(){
......
a.setBusinessKey(Key1);
a.setBuinessesKey(Key2);
a.setBusinessKey(Key3);
......
}
看著這微小的改動引起了這么大的變化,這是不可能的。筆者第一時間便否決了這種可能性。
流量變化
以這么多年我troubleshooting的第一直覺,肯定是負載變化才能引起younggc耗時的變化。詢問那位同學,他明顯是已經考慮了這樣的問題。當即甩給了我相關的監控截圖。從分鐘級的尺度來講,沒有任何變化。
容器問題
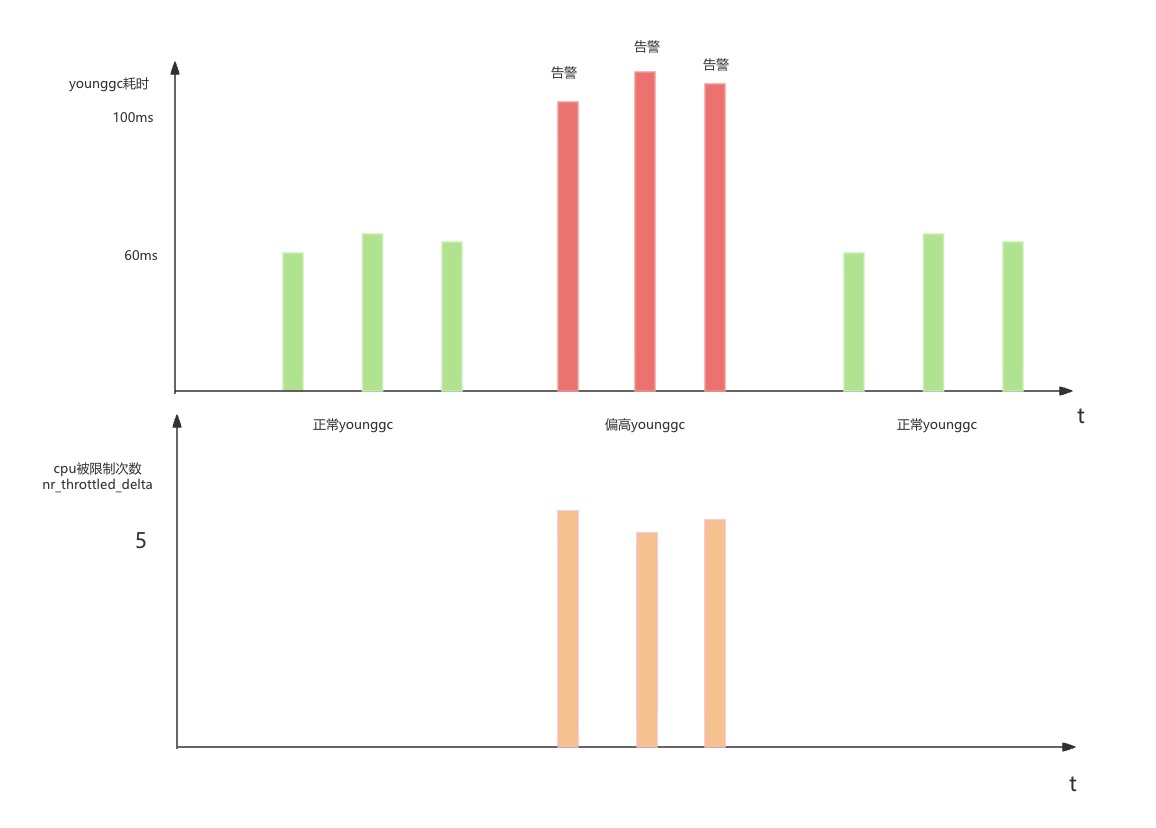
由于younggc耗時高集中在幾臺機器上,于是筆者登陸上那幾臺機器,發現在younggc耗時變高的時候都出現了nr_throttled,也就是當前容器的CPU時間片消耗達到了配置的cgroup上限,導致被kernel強制offline了。但到底是younggc導致了throttle還是throttle導致了younggc,這個因果關系以現有的信息來說完全無法判斷。
Younggc日志
既然不能一眼看出來原因,那只能上去分析gc日志了,比對一下gc。發現差距在Object Copy上。
偏長younggc 120ms
[Object Copy (ms): Min: 107.5, Avg:108.2,Max:108.9,Diff:0.8,Sum: 869.5]
正常younggc 60ms
[Object Copy (ms): Min: 55.2, Avg: 56.1, Max:56.3, Diff: 1.1,Sum: 450.0]
嗯,從這個數據來判斷,肯定是要Copy的數據變多了。為什么會變多呢?看看其younggc后的各年代的變化。
偏長younggc 120ms
[Eden: 4804.0M(4804.0M)->0.0B(4784.0M) Survivors: 108.0M->128.0M Heap: 6632.7M(8192.0M)->1848.8M(8192.0M)]
正常younggc 60ms
[Eden: 4848.0M(4848.0M)->0.0B(4832.0M) Survivors: 64.0M->80.0M Heap: 6717.7M(8192.0M)->1888.0M(8192.0M)]
筆者敏銳的觀察到Survivor區變大了。偏長Younggc Survivor區是108M,而正常Younggc Survivor區是64M。
Object Copy哪些數據
問了一下gemini,object copy的對象一般有從
1.從Eden Region復制到Survivor Region
2.從Survivor Region復制到老年代Region
這兩個地方進行Copy。也就是說,如果Survivor區變大了之后,Object Copy的數據應該是會變多。
嗯,雖然大模型經常忽悠我,但這個回答還是比較符合邏輯的,姑且就相信他。
觀察gc監控
鑒于上面的分析,筆者突然覺得Younggc的時間很有可能和Survivor區的大小成正比關系。一旦Survivor區大于一個閾值,那么Younggc時間就會超過100ms,進而導致告警。為了驗證這個關系,筆者去觀察了不同機器正常younggc和偏長younggc的關系。發現完全符合這個規律。
為什么Survivor區會變化
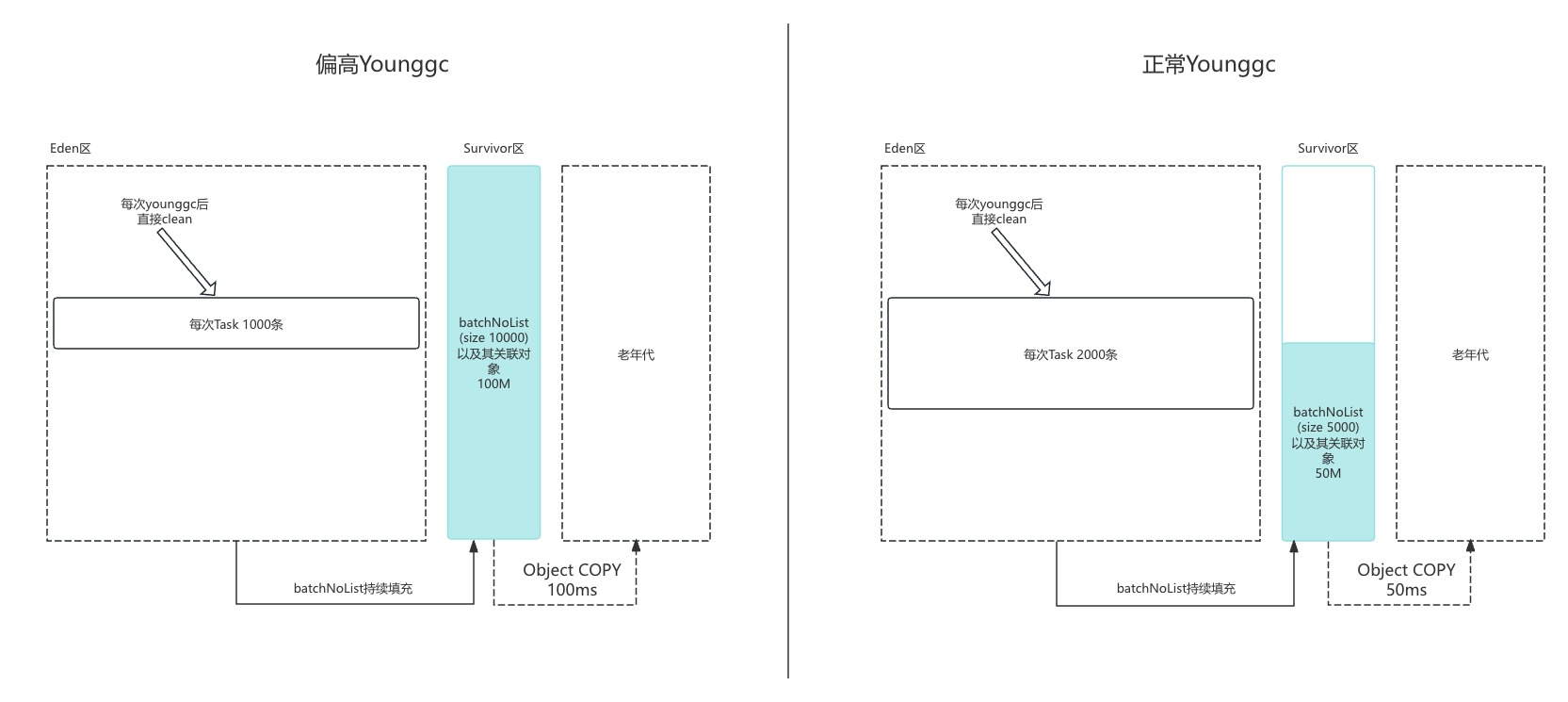
由于分鐘級的請求量沒有任何變化。監控當前的精度只能到分鐘級,于是筆者只能在請求機器上的日志中尋找相關的線索。比較了相關的業務日志,筆者敏銳的發現了一個不一樣的地方。在相同數據量的情況下,分批的次數越多它的Younggc越長。
如果一共需要處理100W條數據
case 1: 分了10000批,每批處理1000條數據,Survivor區100M。對應的younggc在100-120ms
case 2: 分了5000批,每批處理2000條數據,Survivor區50M,對應的youggc在50-70ms
發現了這個規律之后,筆者去看了下業務系統的源代碼。其偽代碼如下所示:
// 這邊的batchNo就是
for(long batchNo : batchNoList) {
// 按照批次從數據庫中撈取相關數據
List<Task> task = selectFromDBBatchNo(bachNo);
// 處理相關數據
handleTask(task);
}
看到這段代碼,上面的規律就很好理解了,batchNoList以及其相關數據是一直在for的計數里面,一直到處理完畢整個batchNoList以及其相關數據的引用都不會被回收。所以batchNoList(批次)數量越大,在Survivor區younggc的時候需要copy到old區的數據量就越多。反而在每次循環的循環體中,通過batchNo從數據庫中撈取的數據在處理完之后就沒用了,younggc的時候自然消亡,完全不參與相關younggc運算。
為什么以前沒問題上了個版本就出問題了
首先這個肯定和修改的代碼沒有關系,筆者推測是由于上游流量的變化導致了批次數量的變化。這個也在后續的數據分析中得到了相關的印證。
解決方案
找到根本原因之后,解決這個問題就很簡單了,將分批數給設定一個最大值,強制限制分批大小。代碼只需寥寥數行,但是要知道怎么改則需要大量的觀察和分析。
總結
Younggc時間變長是一個比較棘手的問題,因為它的可觀測信息過少,而且往往和代碼變更無關,而和請求分布導致的內存生成速率與存活分布有關。這時候只有通過大量的觀察來分析各種數據間的相關性然后通過底層原理推斷出因果性,最后才能找到根因。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號