

面試必殺技,講一講Spring中的循環依賴(轉)
原文:https://developer.aliyun.com/article/766880
作者:程序員DMZ
來源:阿里云開發者社區
前言
Spring中的循環依賴一直是Spring中一個很重要的話題,一方面是因為源碼中為了解決循環依賴做了很多處理,另外一方面是因為面試的時候,如果問到Spring中比較高階的問題,那么循環依賴必定逃不掉。如果你回答得好,那么這就是你的必殺技,反正,那就是面試官的必殺技,這也是取這個標題的原因,當然,本文的目的是為了讓你在之后的所有面試中能多一個必殺技,專門用來絕殺面試官!
本文的核心思想就是,
當面試官問:
“請講一講Spring中的循環依賴。”的時候,
我們到底該怎么回答?
主要分下面幾點
- 什么是循環依賴?
- 什么情況下循環依賴可以被處理?
- Spring是如何解決的循環依賴?
同時本文希望糾正幾個目前業界內經常出現的幾個關于循環依賴的錯誤的說法
- 只有在setter方式注入的情況下,循環依賴才能解決(錯)
- 三級緩存的目的是為了提高效率(錯)
OK,鋪墊已經做完了,接下來我們開始正文
什么是循環依賴?
從字面上來理解就是A依賴B的同時B也依賴了A,就像下面這樣

體現到代碼層次就是這個樣子
@Component public class A { // A中注入了B @Autowired private B b; } @Component public class B { // B中也注入了A @Autowired private A a; }
第二種循環依賴:A循環依賴自己,它其實是A<->B循環依賴的一種特例
// 自己依賴自己 @Component public class A { // A中注入了A @Autowired private A a; }
第三種循環依賴:間接循環依賴,如圖

什么情況下循環依賴可以被處理?
在回答這個問題之前首先要明確一點,Spring解決循環依賴是有前置條件的
- 出現循環依賴的Bean必須要是單例
- 依賴注入的方式不能全是構造器注入的方式(很多博客上說,只能解決setter方法的循環依賴,這是錯誤的)
其中第一點應該很好理解,第二點:不能全是構造器注入是什么意思呢?我們還是用代碼說話
@Component public class A { // @Autowired // private B b; public A(B b) { } } @Component public class B { // @Autowired // private A a; public B(A a){ } }
在上面的例子中,A中注入B的方式是通過構造器,B中注入A的方式也是通過構造器,這個時候循環依賴是無法被解決,如果你的項目中有兩個這樣相互依賴的Bean,在啟動時就會報出以下錯誤:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
為了測試循環依賴的解決情況跟注入方式的關系,我們做如下四種情況的測試

具體的測試代碼跟簡單,我就不放了。從上面的測試結果我們可以看到,不是只有在setter方法注入的情況下循環依賴才能被解決,即使存在構造器注入的場景下,循環依賴依然被可以被正常處理掉。
那么到底是為什么呢?Spring到底是怎么處理的循環依賴呢?不要急,我們接著往下看
Spring是如何解決的循環依賴?
關于循環依賴的解決方式應該要分兩種情況來討論
- 簡單的循環依賴(沒有AOP)
- 結合了AOP的循環依賴
簡單的循環依賴(沒有AOP)
我們先來分析一個最簡單的例子,就是上面提到的那個demo
@Component public class A { // A中注入了B @Autowired private B b; } @Component public class B { // B中也注入了A @Autowired private A a; }
通過上文我們已經知道了這種情況下的循環依賴是能夠被解決的,那么具體的流程是什么呢?我們一步步分析
首先,我們要知道Spring在創建Bean的時候默認是按照自然排序來進行創建的,所以第一步Spring會去創建A。
與此同時,我們應該知道,Spring在創建Bean的過程中分為三步
- 實例化,對應方法:
AbstractAutowireCapableBeanFactory中的createBeanInstance方法 - 屬性注入,對應方法:
AbstractAutowireCapableBeanFactory的populateBean方法 - 初始化,對應方法:
AbstractAutowireCapableBeanFactory的initializeBean
這些方法在之前源碼分析的文章中都做過詳細的解讀了,如果你之前沒看過我的文章,那么你只需要知道
- 實例化,簡單理解就是new了一個對象
- 屬性注入,為實例化中new出來的對象填充屬性
- 初始化,執行aware接口中的方法,初始化方法,完成
AOP代理
基于上面的知識,我們開始解讀整個循環依賴處理的過程,整個流程應該是以A的創建為起點,前文也說了,第一步就是創建A嘛!
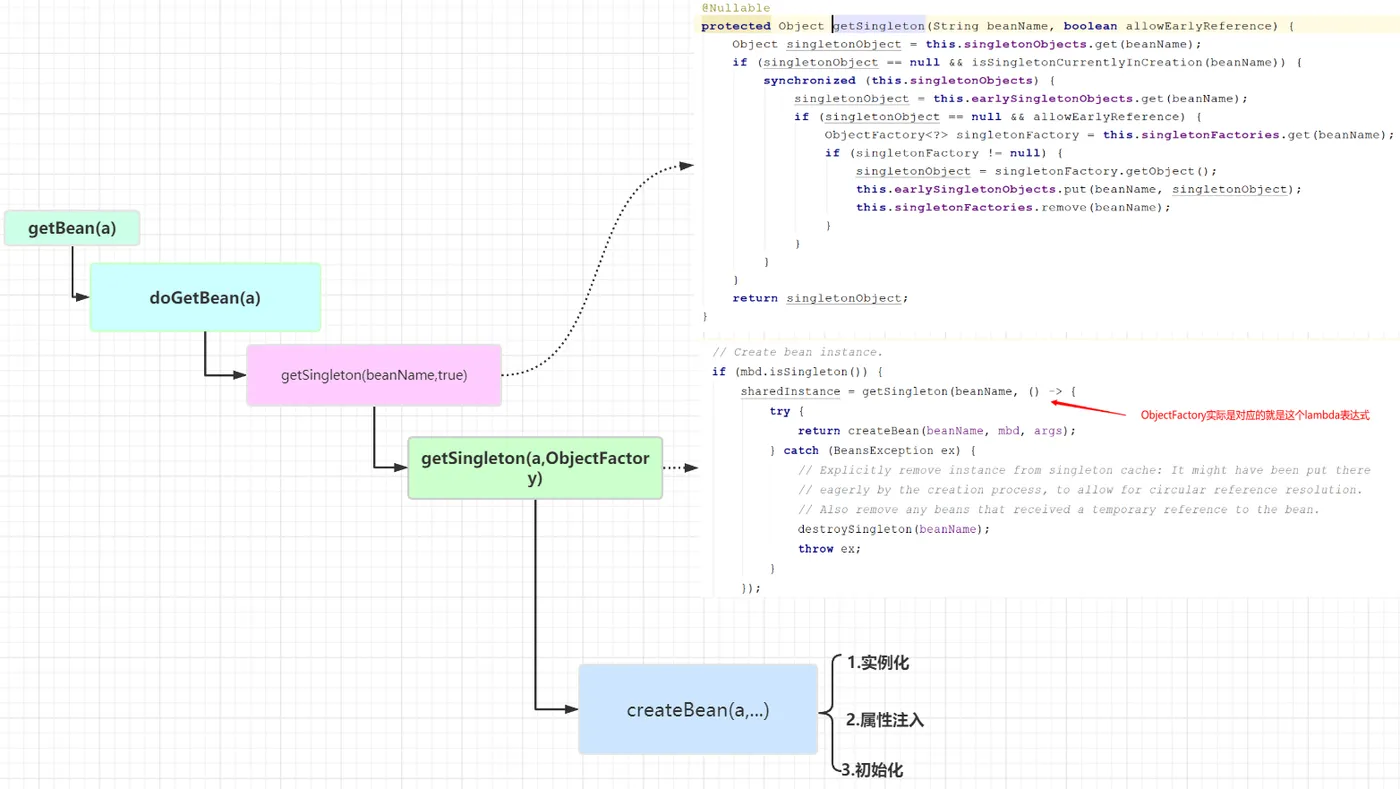
創建A的過程實際上就是調用getBean方法,這個方法有兩層含義
- 創建一個新的Bean
- 從緩存中獲取到已經被創建的對象
我們現在分析的是第一層含義,因為這個時候緩存中還沒有A嘛!
調用getSingleton(beanName)
首先調用getSingleton(a)方法,這個方法又會調用getSingleton(beanName, true),在上圖中我省略了這一步
public Object getSingleton(String beanName) { return getSingleton(beanName, true); }
getSingleton(beanName, true)這個方法實際上就是到緩存中嘗試去獲取Bean,整個緩存分為三級
singletonObjects,一級緩存,存儲的是所有創建好了的單例BeanearlySingletonObjects,二級緩存,完成實例化,但是還未進行屬性注入及初始化的對象singletonFactories,三級緩存,提前暴露的一個對象工廠ObjectFactory,二級緩存中存儲的就是從這個工廠中獲取到的對象。
因為A是第一次被創建,所以不管哪個緩存中必然都是沒有的(不過,這里),因此會進入getSingleton的另外一個重載方法getSingleton(beanName, singletonFactory)。
注:在getSingleton(String beanName)中,當三級緩存中緩存(對象工廠)時,會調用其getObject方法生成bean對象,并將其緩存在二級緩存中,從三級緩存中刪除,也就是說三級緩存只會使用一次。這樣下次再獲取bean時就直接用二級緩存了。后面會講到,當bean完全創建完成后,將bean放入一級緩存,從二級緩存中刪除。
調用getSingleton(beanName, singletonFactory)
這個方法就是用來創建Bean的,其源碼如下:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) { Assert.notNull(beanName, "Bean name must not be null"); synchronized (this.singletonObjects) { Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null) { // .... // 省略異常處理及日志 // .... // 在單例對象創建前先做一個標記 // 將beanName放入到singletonsCurrentlyInCreation這個集合中 // 標志著這個單例Bean正在創建 // 如果同一個單例Bean多次被創建,這里會拋出異常 beforeSingletonCreation(beanName); boolean newSingleton = false; boolean recordSuppressedExceptions = (this.suppressedExceptions == null); if (recordSuppressedExceptions) { this.suppressedExceptions = new LinkedHashSet<>(); } try { // 上游傳入的lambda在這里會被執行,調用createBean方法創建一個Bean后返回 singletonObject = singletonFactory.getObject(); newSingleton = true; } // ... // 省略catch異常處理 // ... finally { if (recordSuppressedExceptions) { this.suppressedExceptions = null; } // 創建完成后將對應的beanName從singletonsCurrentlyInCreation移除 afterSingletonCreation(beanName); } if (newSingleton) { // 添加到一級緩存singletonObjects中 addSingleton(beanName, singletonObject); } } return singletonObject; } }
該方法是在doGetBean方法中被調用的,如下
// Create bean instance. if (mbd.isSingleton()) { sharedInstance = getSingleton(beanName, () -> { try { return createBean(beanName, mbd, args); } catch (BeansException ex) { // Explicitly remove instance from singleton cache: It might have been put there // eagerly by the creation process, to allow for circular reference resolution. // Also remove any beans that received a temporary reference to the bean. destroySingleton(beanName); throw ex; } }); bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd); }
上面的代碼我們主要抓住一點,通過createBean方法返回的Bean是完全創建完成的bean,getSingleton方法中調用createBean,將bean放到了一級緩存,也就是單例池中。那么到這里我們可以得出一個結論:一級緩存中存儲的是已經完全創建好了的單例Bean
下面我們詳細分析下createBean方法,它調用doCreateBean,doCreateBean源碼如圖

在完成Bean的實例化后,調用addSingletonFactory將Bean包裝成一個工廠添加進了三級緩存中,源碼如下:
// 這里傳入的參數也是一個lambda表達式,() -> getEarlyBeanReference(beanName, mbd, bean) protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) { Assert.notNull(singletonFactory, "Singleton factory must not be null"); synchronized (this.singletonObjects) { if (!this.singletonObjects.containsKey(beanName)) { // 添加到三級緩存中 this.singletonFactories.put(beanName, singletonFactory); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName); } } }
這里只是添加了一個工廠,通過這個工廠(ObjectFactory)的getObject方法可以得到一個對象,而這個對象實際上就是通過getEarlyBeanReference這個方法創建的。那么,什么時候會去調用這個工廠的getObject方法呢?這個時候就要到創建B的流程了。
當A完成了實例化并添加進了三級緩存后,就要開始為A進行屬性注入了,在注入時發現A依賴了B,那么這個時候Spring又會去getBean(b),然后反射調用setter方法完成屬性注入。
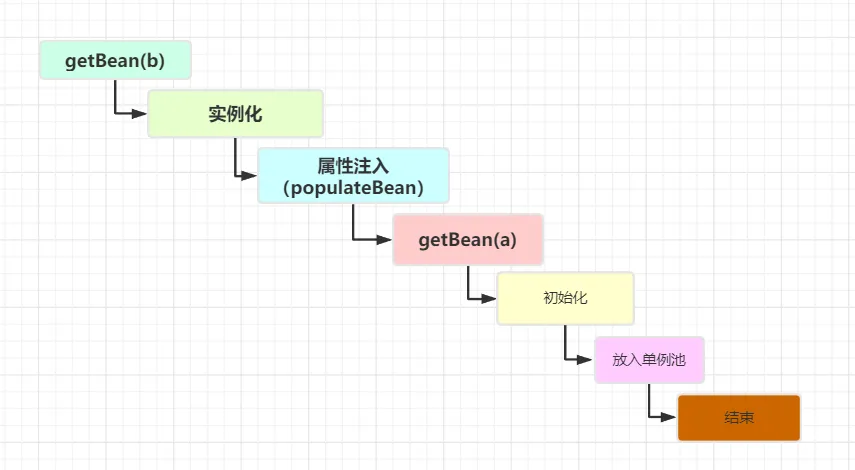
因為B需要注入A,所以在創建B的時候,又會去調用getBean(a),這個時候就又回到之前的流程了,但是不同的是,之前的getBean是為了創建Bean,而此時再調用getBean不是為了創建了,而是要從緩存中獲取,因為之前A在實例化后已經將其放入了三級緩存singletonFactories中,所以此時getBean(a)的流程就是這樣子了
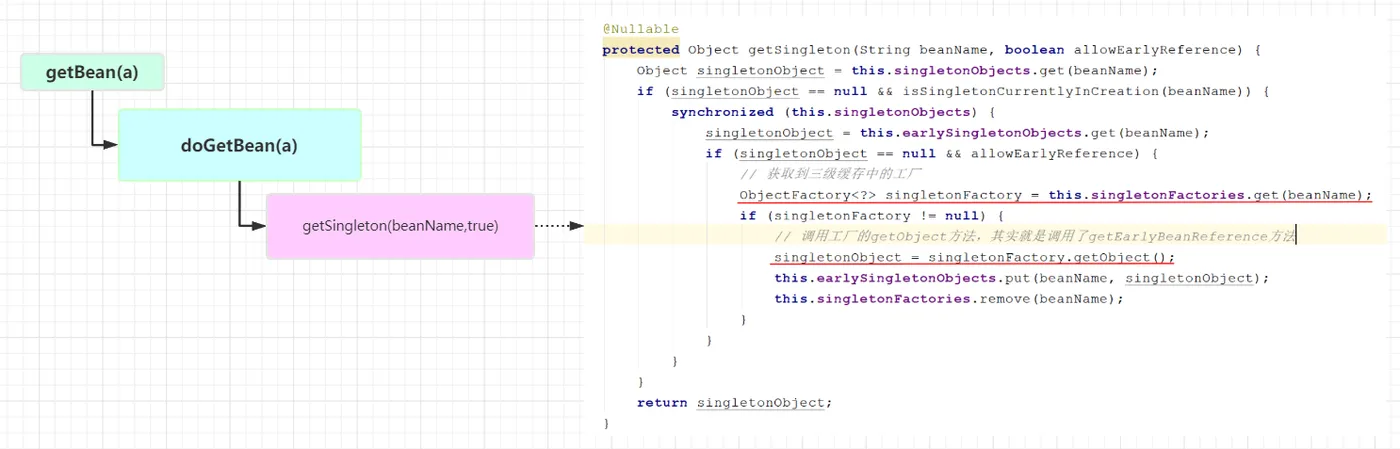
從這里我們可以看出,注入到B中的A是通過getEarlyBeanReference方法提前暴露出去的一個對象,還不是一個完整的Bean,那么getEarlyBeanReference到底干了啥了,我們看下它的源碼
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) { for (BeanPostProcessor bp : getBeanPostProcessors()) { if (bp instanceof SmartInstantiationAwareBeanPostProcessor) { SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp; exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName); } } } return exposedObject; }
它實際上就是調用了后置處理器的getEarlyBeanReference,而真正實現了這個方法的后置處理器只有一個,就是通過@EnableAspectJAutoProxy注解導入的AnnotationAwareAspectJAutoProxyCreator。也就是說如果在不考慮AOP的情況下,上面的代碼等價于:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; return exposedObject; }
也就是說這個工廠啥都沒干,直接將實例化階段創建的對象返回了!所以說在不考慮AOP的情況下三級緩存有用嘛?講道理,真的沒什么用,我直接將這個對象放到二級緩存中不是一點問題都沒有嗎?如果你說它提高了效率,那你告訴我提高的效率在哪?

那么三級緩存到底有什么作用呢?不要急,我們先把整個流程走完,在下文結合AOP分析循環依賴的時候你就能體會到三級緩存的作用!
到這里不知道小伙伴們會不會有疑問,B中提前注入了一個沒有經過初始化的A類型對象不會有問題嗎?
答:不會
這個時候我們需要將整個創建A這個Bean的流程走完,如下圖:

從上圖中我們可以看到,雖然在創建B時會提前給B注入了一個還未初始化的A對象,但是在創建A的流程中一直使用的是注入到B中的A對象的引用,之后會根據這個引用對A進行初始化,所以這是沒有問題的。
結合了AOP的循環依賴
之前我們已經說過了,在普通的循環依賴的情況下,三級緩存沒有任何作用。三級緩存實際上跟Spring中的AOP相關,我們再來看一看getEarlyBeanReference的代碼:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) { for (BeanPostProcessor bp : getBeanPostProcessors()) { if (bp instanceof SmartInstantiationAwareBeanPostProcessor) { SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp; exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName); } } } return exposedObject; }
如果在開啟AOP的情況下,那么就是調用到AnnotationAwareAspectJAutoProxyCreator的getEarlyBeanReference方法,對應的源碼如下:
public Object getEarlyBeanReference(Object bean, String beanName) { Object cacheKey = getCacheKey(bean.getClass(), beanName); this.earlyProxyReferences.put(cacheKey, bean); // 如果需要代理,返回一個代理對象,不需要代理,直接返回當前傳入的這個bean對象 return wrapIfNecessary(bean, beanName, cacheKey); }
回到上面的例子,我們對A進行了AOP代理的話,那么此時getEarlyBeanReference將返回一個代理后的對象,而不是實例化階段創建的對象,這樣就意味著B中注入的A將是一個代理對象而不是A的實例化階段創建后的對象。
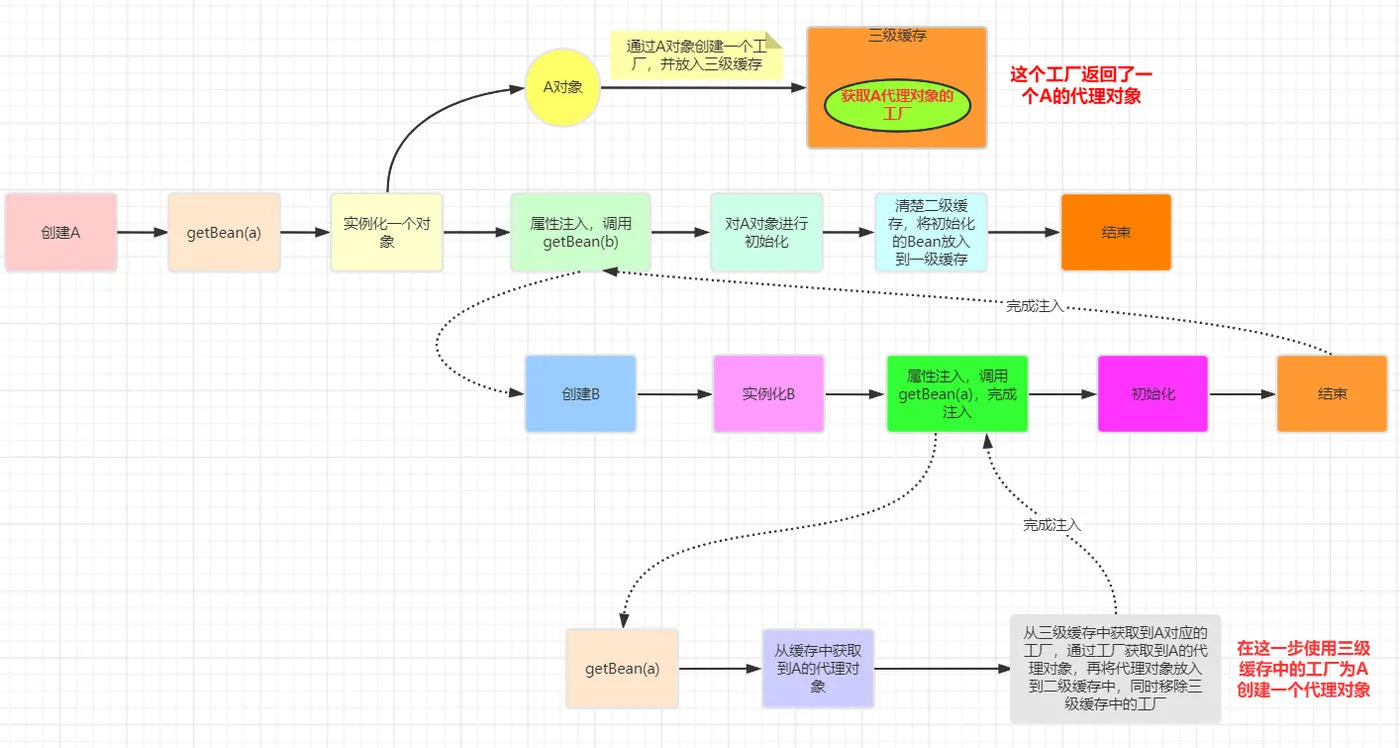
看到這個圖你可能會產生下面這些疑問
1. 在給B注入的時候為什么要注入一個代理對象?
答:當我們對A進行了AOP代理時,說明我們希望從容器中獲取到的就是A代理后的對象而不是A本身,因此把A當作依賴進行注入時也要注入它的代理對象
2. 明明初始化的時候是A對象,那么Spring是在哪里將代理對象放入到容器中的呢?

在完成初始化后,Spring又調用了一次getSingleton方法,這一次傳入的參數又不一樣了,false可以理解為禁用三級緩存,前面圖中已經提到過了,在為B中注入A時已經將三級緩存中的工廠取出,并從工廠中獲取到了一個對象放入到了二級緩存中,所以這里的這個getSingleton方法做的時間就是從二級緩存中獲取到這個代理后的A對象。exposedObject == bean可以認為是必定成立的,除非你非要在初始化階段的后置處理器中替換掉正常流程中的Bean,例如增加一個后置處理器:
@Component public class MyPostProcessor implements BeanPostProcessor { @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { if (beanName.equals("a")) { return new A(); } return bean; } }
不過,請不要做這種騷操作,徒增煩惱!
3. 初始化的時候是對A對象本身進行初始化,而容器中以及注入到B中的都是代理對象,這樣不會有問題嗎?
答:不會,這是因為不管是cglib代理還是jdk動態代理生成的代理類,內部都持有一個目標類的引用,當調用代理對象的方法時,實際會去調用目標對象的方法,A完成初始化相當于代理對象自身也完成了初始化
4. 三級緩存為什么要使用工廠而不是直接使用引用?換而言之,為什么需要這個三級緩存,直接通過二級緩存暴露一個引用不行嗎?
答:這個工廠的目的在于延遲對實例化階段生成的對象的代理,只有真正發生循環依賴的時候,才去提前生成代理對象,否則只會創建一個工廠并將其放入到三級緩存中,但是不會去通過這個工廠去真正創建對象
我們思考一種簡單的情況,就以單獨創建A為例,假設AB之間現在沒有依賴關系,但是A被代理了,這個時候當A完成實例化后還是會進入下面這段代碼:
// A是單例的,mbd.isSingleton()條件滿足 // allowCircularReferences:這個變量代表是否允許循環依賴,默認是開啟的,條件也滿足 // isSingletonCurrentlyInCreation:正在在創建A,也滿足 // 所以earlySingletonExposure=true boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName)); // 還是會進入到這段代碼中 if (earlySingletonExposure) { // 還是會通過三級緩存提前暴露一個工廠對象 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); }
看到了吧,即使沒有循環依賴,也會將其添加到三級緩存中,而且是不得不添加到三級緩存中,因為到目前為止Spring也不能確定這個Bean有沒有跟別的Bean出現循環依賴。
假設我們在這里直接使用二級緩存的話,那么意味著所有的Bean在這一步都要完成AOP代理。這樣做有必要嗎?
不僅沒有必要,而且違背了Spring在結合AOP跟Bean的生命周期的設計!Spring結合AOP跟Bean的生命周期本身就是通過AnnotationAwareAspectJAutoProxyCreator這個后置處理器來完成的,在這個后置處理的postProcessAfterInitialization方法中對初始化后的Bean完成AOP代理。如果出現了循環依賴,那沒有辦法,只有給Bean先創建代理,但是沒有出現循環依賴的情況下,設計之初就是讓Bean在生命周期的最后一步完成代理而不是在實例化后就立馬完成代理。
三級緩存真的提高了效率了嗎?
現在我們已經知道了三級緩存的真正作用,但是這個答案可能還無法說服你,所以我們再最后總結分析一波,三級緩存真的提高了效率了嗎?分為兩點討論:
- 沒有進行
AOP的Bean間的循環依賴
從上文分析可以看出,這種情況下三級緩存根本沒用!所以不會存在什么提高了效率的說法
- 進行了
AOP的Bean間的循環依賴
就以我們上的A、B為例,其中A被AOP代理,我們先分析下使用了三級緩存的情況下,A、B的創建流程
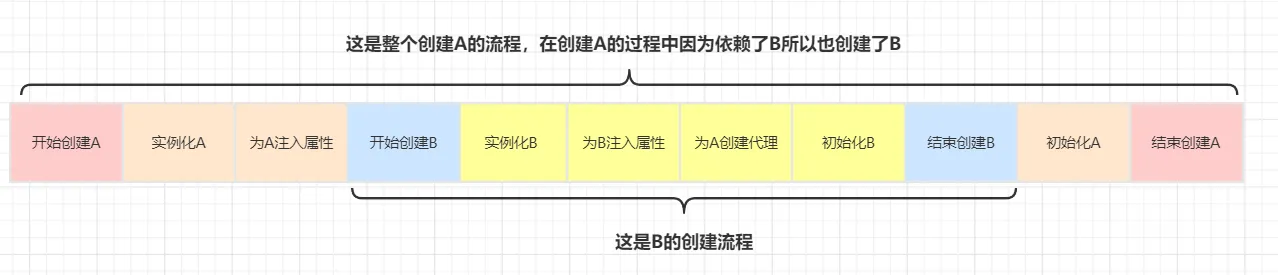
假設不使用三級緩存,直接在二級緩存中
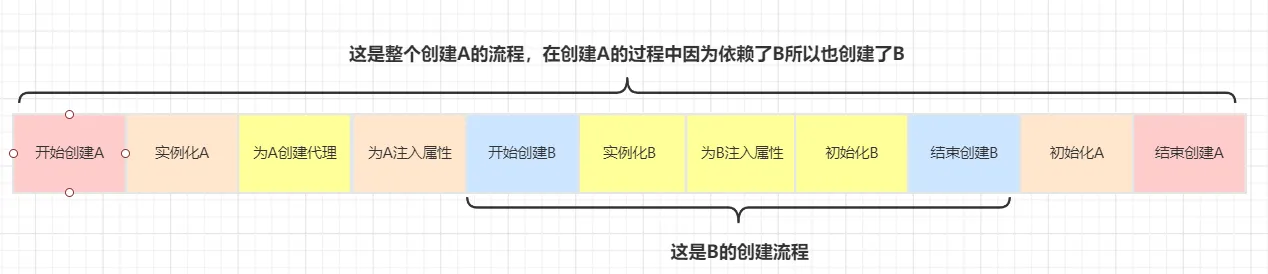
上面兩個流程的唯一區別在于為A對象創建代理的時機不同,在使用了三級緩存的情況下為A創建代理的時機是在B中需要注入A的時候,而不使用三級緩存的話在A實例化后就需要馬上為A創建代理然后放入到二級緩存中去。對于整個A、B的創建過程而言,消耗的時間是一樣的
綜上,不管是哪種情況,三級緩存提高了效率這種說法都是錯誤的!
總結
面試官:”Spring是如何解決的循環依賴?“
答:Spring通過三級緩存解決了循環依賴,其中一級緩存為單例池(singletonObjects),二級緩存為早期曝光對象earlySingletonObjects,三級緩存為早期曝光對象工廠(singletonFactories)。當A、B兩個類發生循環引用時,在A完成實例化后,就使用實例化后的對象去創建一個對象工廠,并添加到三級緩存中,如果A被AOP代理,那么通過這個工廠獲取到的就是A代理后的對象,如果A沒有被AOP代理,那么這個工廠獲取到的就是A實例化的對象。當A進行屬性注入時,會去創建B,同時B又依賴了A,所以創建B的同時又會去調用getBean(a)來獲取需要的依賴,此時的getBean(a)會從緩存中獲取,第一步,先獲取到三級緩存中的工廠;第二步,調用對象工工廠的getObject方法來獲取到對應的對象,得到這個對象后將其注入到B中。緊接著B會走完它的生命周期流程,包括初始化、后置處理器等。當B創建完后,會將B再注入到A中,此時A再完成它的整個生命周期。至此,循環依賴結束!
面試官:”為什么要使用三級緩存呢?二級緩存能解決循環依賴嗎?“
答:如果要使用二級緩存解決循環依賴,意味著所有Bean在實例化后就要完成AOP代理,這樣違背了Spring設計的原則,Spring在設計之初就是通過AnnotationAwareAspectJAutoProxyCreator這個后置處理器來在Bean生命周期的最后一步來完成AOP代理,而不是在實例化后就立馬進行AOP代理。
一道思考題
為什么在下表中的第三種情況的循環依賴能被解決,而第四種情況不能被解決呢?
提示:Spring在創建Bean時默認會根據自然排序進行創建,所以A會先于B進行創建

如果本文對你由幫助的話,記得點個贊吧!也歡迎關注我的公眾號,微信搜索:程序員DMZ,或者掃描下方二維碼,跟著我一起認認真真學Java,踏踏實實做一個coder。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號