
Ollama大模型推理場景下3090和4090性能實測
 使用Ollama的快速模型部署,來實測英偉達的RTX 3090和RTX 4090這兩張顯卡,在大語言模型推理場景中的性能差異。
選擇 Qwen3的模型進行測試,考慮到顯存都是24GB,分別選擇一個FP16精度和一個Q4_K_M量化后的大模型進行測試。
使用Ollama的快速模型部署,來實測英偉達的RTX 3090和RTX 4090這兩張顯卡,在大語言模型推理場景中的性能差異。
選擇 Qwen3的模型進行測試,考慮到顯存都是24GB,分別選擇一個FP16精度和一個Q4_K_M量化后的大模型進行測試。
Ollama 是一個開源的大型語言模型(LLM)部署服務工具,能讓用戶能夠輕松地在本地運行、管理和與大型語言模型進行交互。
我們使用Ollama的快速模型部署,來實測英偉達的RTX 3090和RTX 4090這兩張顯卡,在大語言模型推理場景中的性能差異。
3090和4090的顯卡參數對比
| RTX 3090 | RTX 4090 | |
|---|---|---|
| 架構 | Ampere | Ada Lovelace |
| CUDA核心數 | 10,496 | 16,384 |
| 顯存容量 | 24 GB GDDR6X | 24 GB GDDR6X |
| 顯存帶寬 | 936 GB/s | 1,008 GB/s |
| TDP功耗 | 350W | 450W |
| FP32 算力 | 35.6 TFLOPS | 82.6 TFLOPS |
| Tensor FP16 算力 | 142 TFLOPS | 330 TFLOPS |
3090和4090的顯存參數比較接近,顯存容量都是24GB,顯存帶寬差異也不大;算力方面,4090的單精度和Tensor FP16算力差不多是3090的2.3倍。
Ollama大模型推理測試
大模型選擇
這里選擇 Qwen3的模型進行測試,考慮到3090和4090的顯存都是24GB,分別選擇一個FP16精度和一個Q4_K_M量化后的大模型進行測試:
| 模型 | 精度 | 大小 |
|---|---|---|
| qwen3:8b | fp16 | 16 GB |
| qwen3:14b | q4_K_M | 9.3 GB |
借助DeepSeek 生成測試腳本,使用復雜度近似的8個prompts;MAX_TOKENS配置256,讓每次請求需要一定的生成時長便于采樣顯卡的使用指標,減少波動;同時需要模型預熱,消除第一次推理響應延時過大的問題。
我們在GPU算力租賃平臺 晨澗云 直接租用Ollama云容器進行測試,分別創建3090和4090兩種顯卡的容器實例,啟動后訪問Open WebUI 選擇模型:
然后就可以執行推理性能測試腳本,查看輸出結果。
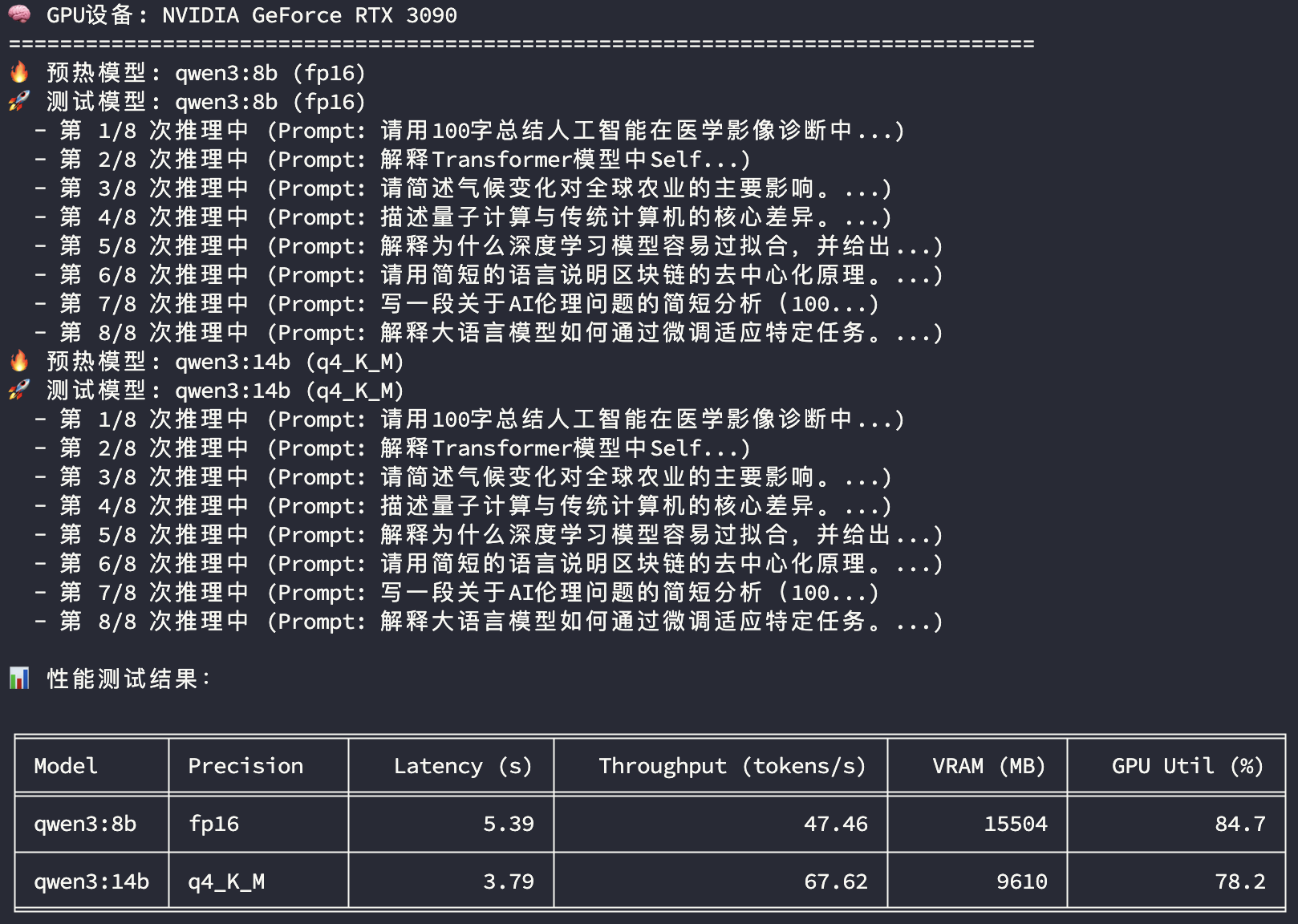
3090推理性能
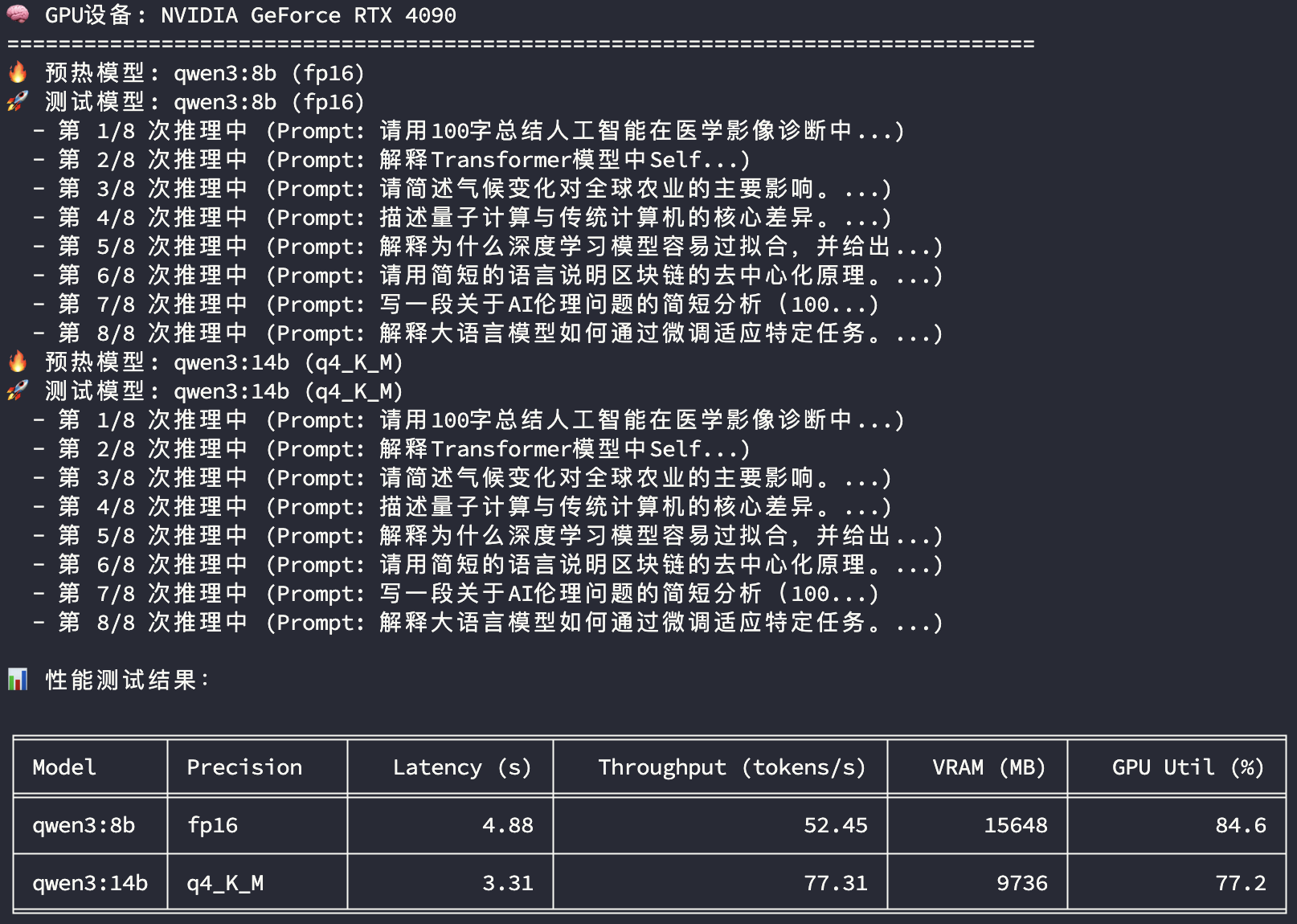
4090推理性能
測試結果解釋
-
Latency (s):多次推理平均響應時長
-
Throughput (tokens/s):多次推理平均Token生成速度
-
VRAM (MB):多次推理平均顯存使用量
-
GPU Util (%):多次推理平均GPU使用率
3090顯卡和4090顯卡在兩個模型推理過程中的顯存使用和GPU使用率都比較接近,所以主要比較平均響應時長及平均Token生成速度兩個指標:
| qwen3:8b fp16 | qwen3:14b q4_K_M | ||
|---|---|---|---|
| 響應時長(s) | 3090 | 5.39 | 3.79 |
| 響應時長(s) | 4090 | 4.88 | 3.31 |
| 響應時長(s) | 差異 | 90.5% | 87.3% |
| Token生成速度(tokens/s) | 3090 | 47.46 | 67.62 |
| Token生成速度(tokens/s) | 4090 | 52.45 | 77.31 |
| Token生成速度(tokens/s) | 差異 | 110.5% | 114.3% |
4090在量化模型的推理性能相較FP16精度的模型會更突出一點,FP16精度模型推理性能4090比3090高10%左右,Q4_K_M量化模型4090比3090的推理性能高14%左右。
但相較顯卡本身參數的算力值2.3倍的差異,在推理場景下4090的優勢并沒有想象中的那么明顯。
Ollama因為更多考慮的是本地和邊緣算力的輕量級快速部署場景,所以在推理性能,特別是多GPU高并發場景下,不如vLLM和SGLang等框架,后續準備比較在vLLM下不同顯卡的推理性能,也可以跟Ollama比較下不同大模型推理框架的性能差異。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號