
基于ResNet-50模型訓練場景下實測3090和4090的性能
 選擇了英偉達的RTX 3090和RTX 4090兩張顯卡,在實際的深度學習場景進行性能實測,基于ResNet-50模型訓練比較下被稱為「上一代卡皇」的 3090 和「當前消費級主力」的 4090 的實際性能到底差多少?
選擇了英偉達的RTX 3090和RTX 4090兩張顯卡,在實際的深度學習場景進行性能實測,基于ResNet-50模型訓練比較下被稱為「上一代卡皇」的 3090 和「當前消費級主力」的 4090 的實際性能到底差多少?
我們選擇了英偉達的RTX 3090和RTX 4090兩張顯卡,基于實際的深度學習中訓練的場景進行性能實測,來比較下被稱為「上一代卡皇」的 3090 和「當前消費級主力」的 4090 的實際性能到底差多少。
顯卡會被運用到不同的場景,比如3D游戲、圖像渲染、深度學習、AI大模型等,顯卡的產品參數也在各種場景做了優化,比如有渲染核心、光追核心、AI加速等,在實際場景中,特別是深度學習和AI方面的應用,各種顯卡的性能表現到底如何,或者如何更有效地從深度學習等應用場景測試顯卡的性能?
RTX 3090和RTX 4090參數對比
先對比先3090和4090兩張顯卡的參數規格:
| RTX 3090 | RTX 4090 | |
|---|---|---|
| 架構 | Ampere | Ada Lovelace |
| CUDA核心數 | 10,496 | 16,384 |
| 顯存容量 | 24 GB GDDR6X | 24 GB GDDR6X |
| 顯存帶寬 | 936 GB/s | 1,008 GB/s |
| TDP功耗 | 350W | 450W |
| FP32 算力 | 35.6 TFLOPS | 82.6 TFLOPS |
| Tensor FP16 算力 | 142 TFLOPS | 330 TFLOPS |
-
3090和4090在顯存層面比較接近,顯存容量都是24GB,顯存帶寬差異也不大
-
算力方面,4090無論是單精度還是Tensor FP16都是3090的2.3倍左右
-
其他方面,4090基于新的Ada Lovelace架構,并且功耗也遠高于3090
基于深度學習的模型訓練測試
這里選擇ResNet-50進行模型訓練來實測顯卡性能,為什么是ResNet-50?
ResNet-50是經典的計算機視覺模型,一種深度為50 層的卷積神經網絡(CNN);模型比較平衡,參數數量及顯存占用適中,涵蓋了深度學習訓練的關鍵計算模式,包含大量矩陣計算,可以評估AI核心的算力。
我們基于Pytorch框架來訓練ResNet-50模型,基于CIFAR-10數據集進行測試,來比較樣本吞吐速度、顯卡使用、GPU使用率等。
從節省成本和使用便利性考慮,可以直接從GPU算力平臺租用GPU算力,我們在 晨澗云 分別租3090和4090兩種機器進行模型訓練的對比測試:
RTX 3090

RTX 4090
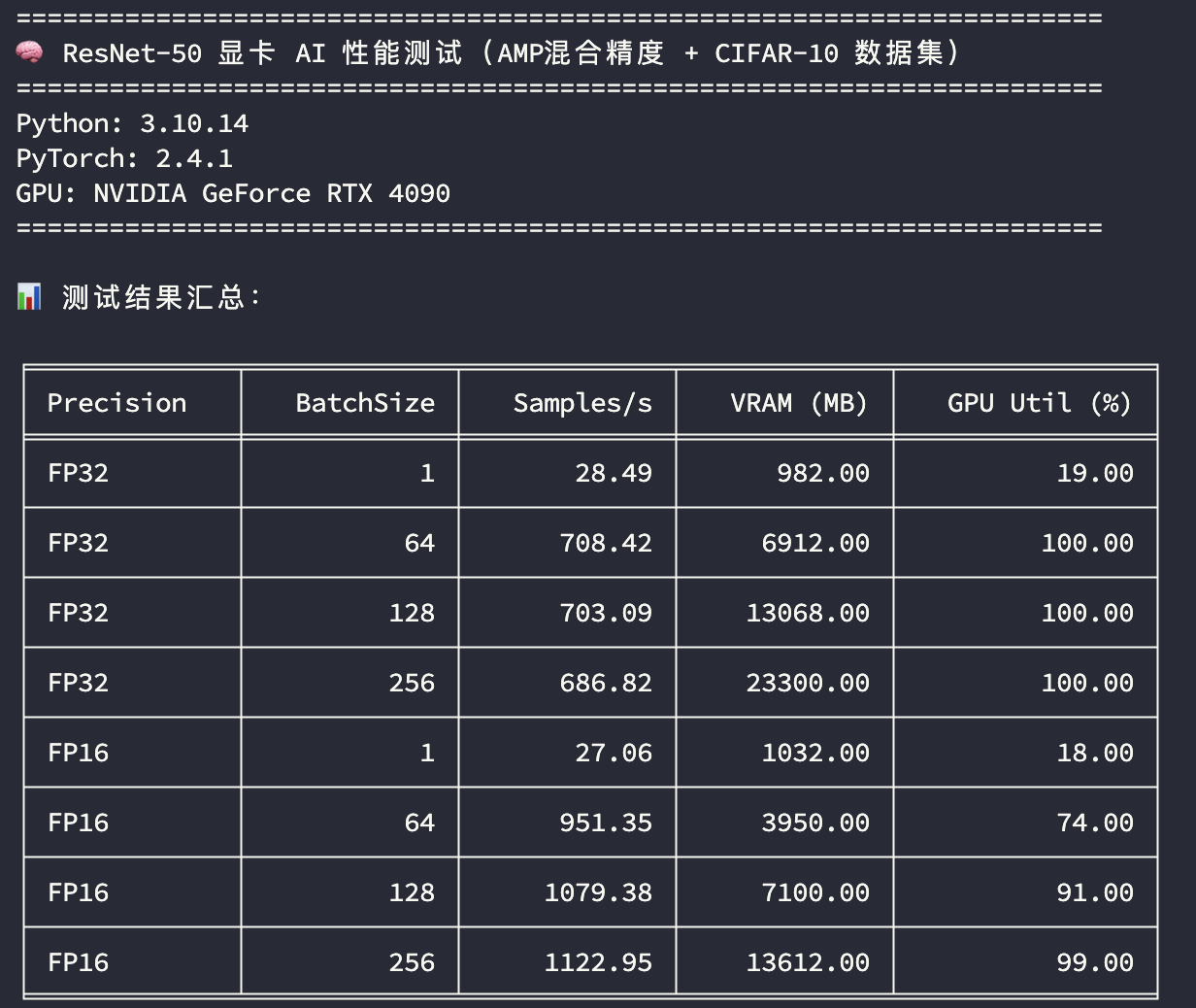
測試結果解釋
這里從不同的訓練精度,不同的訓練批次大小來比較3090和4090訓練吞吐量的差異,同時關注顯存和GPU的峰值使用情況:
-
精度:FP32 表示使用單精度訓練,FP16 表示使用混合精度訓練
-
BatchSize:訓練批次大小
-
Samples/s:每秒樣本吞吐量
-
VRAM (MB):峰值顯存使用量
-
GPU Util (%):峰值GPU利用率
從上圖中主要看在GPU使用率比較高的場景下(如 BatchSize=256),模型訓練樣本的吞吐速度比較;無論是單精度還是混合精度,RTX 4090的樣本吞吐速度都在RTX 3090的1.45倍左右。
這個結果跟顯卡本身的算力(TFLOPS)值存在一定的差異,當然訓練還跟其他環境配置直接相關,比如機器的CPU、顯卡PCIe接口的版本等,而且這個只能說明在計算機視覺模型的訓練場景的性能表現,在其他應用場景,如大模型推理、文生圖、科學計算等性能基準又會有不同表現,需要分開測試評估。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號