
顯卡參數(shù)對(duì)算力性能的影響
 AI時(shí)代大模型的應(yīng)用已經(jīng)滲透到日常的角角落落,同時(shí)算力變成了普遍的需求,在購(gòu)買顯卡或者租用GPU云算力的時(shí)候,如何選擇合適的顯卡呢,需要關(guān)注哪些參數(shù)?
本文以最常見的英偉達(dá)顯卡為例,來說說顯卡的各種參數(shù)是如何影響算力性能的。
AI時(shí)代大模型的應(yīng)用已經(jīng)滲透到日常的角角落落,同時(shí)算力變成了普遍的需求,在購(gòu)買顯卡或者租用GPU云算力的時(shí)候,如何選擇合適的顯卡呢,需要關(guān)注哪些參數(shù)?
本文以最常見的英偉達(dá)顯卡為例,來說說顯卡的各種參數(shù)是如何影響算力性能的。
AI時(shí)代大模型的應(yīng)用已經(jīng)滲透到日常的角角落落,同時(shí)算力變成了普遍的需求,企業(yè)或者個(gè)人在購(gòu)買顯卡或者租用GPU云算力的時(shí)候,如何選擇合適的顯卡呢,需要關(guān)注哪些參數(shù)?
下面以最常見的英偉達(dá)顯卡為例,來說說顯卡的各種參數(shù)是如何影響算力性能的。
Nvidia顯卡比較
先看看英偉達(dá)官網(wǎng)是怎么比較自己的顯卡產(chǎn)品線的:
隨著顯卡技術(shù)的不斷革新,最重要的是架構(gòu)和平臺(tái)的革新,新的架構(gòu)帶來更多的特性,比如光追、AI加速等,同時(shí)提供更強(qiáng)大的算力,英偉達(dá)最新架構(gòu)Blackwell 單芯片的算力性能、帶寬都大幅提升,帶來AI推理性能的10倍級(jí)飛躍。
顯卡架構(gòu)是產(chǎn)品線升級(jí)帶來的代差,再來看看具體的產(chǎn)品線的顯卡對(duì)比,如最新的50系顯卡比較了哪些參數(shù):
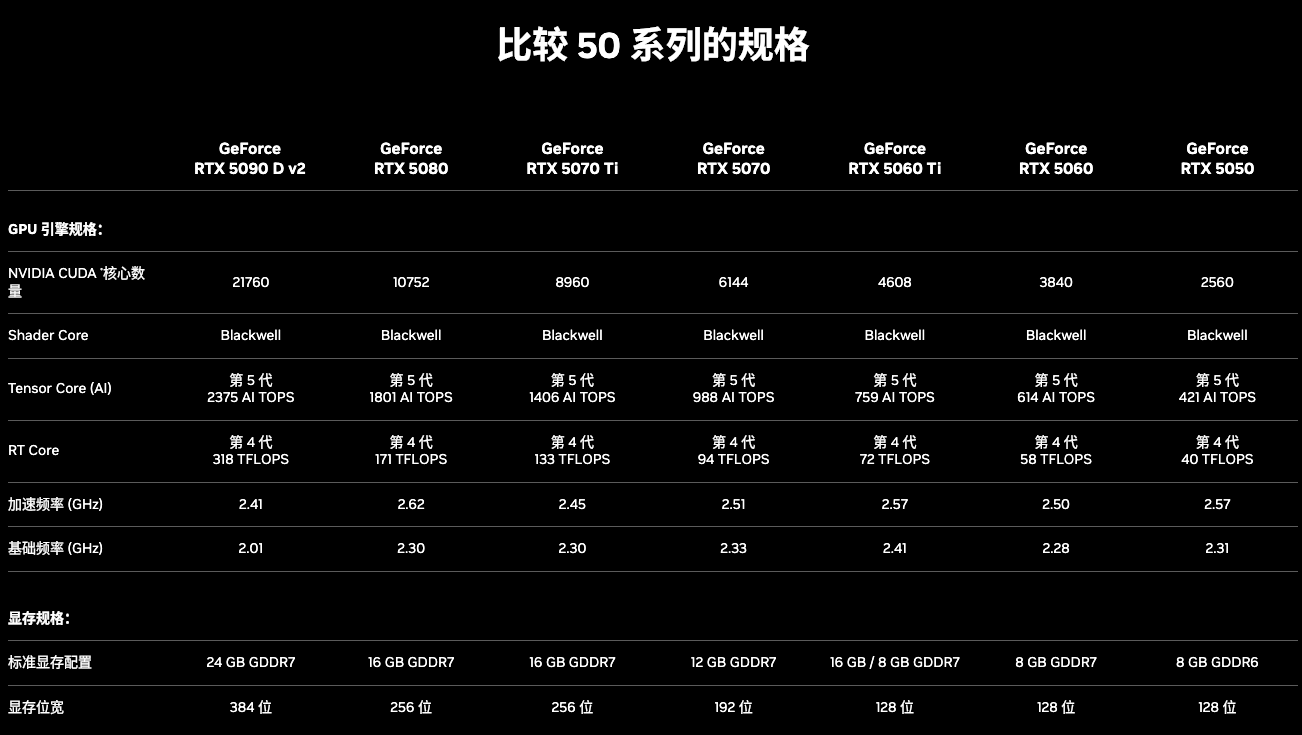
顯卡參數(shù)
顯卡最主要的組成部分就是核心及顯存。
1. 顯卡核心
核心直接決定顯卡的計(jì)算能力。
1.1 CUDA核心數(shù)(流處理器數(shù)量)
GPU的核心計(jì)算單元,核心越多,并行計(jì)算能力越強(qiáng)。
1.2 Shader Core
渲染核心,負(fù)責(zé)像素點(diǎn)的渲染工作。
1.3 Tensor Core
AI加速核心,用于加速深度學(xué)習(xí)中神經(jīng)網(wǎng)絡(luò)訓(xùn)練和推理的矩陣計(jì)算。
1.4 RT Core
光追核心,用作于光線追蹤效果。
1.5 基礎(chǔ)頻率
類似CPU主頻,每個(gè)核心默認(rèn)的運(yùn)行頻率。
1.6 加速頻率
核心可以達(dá)到的最大頻率。
2. 顯存(VRAM)
顯存決定加載模型、圖像紋理的速度和大小上限。
2.1 顯存類型
類似于內(nèi)存,顯存的類型叫GDDR,比50系基本用的GDDR7,40系用的GDDR6,越新的顯存類型擁有更高的帶寬和更快的速率。
2.2 顯存容量
顯存容量決定了一張顯卡同時(shí)能處理的數(shù)據(jù)大小,在模型加載、模型訓(xùn)練的各種應(yīng)用場(chǎng)景中顯存的大小也是選擇顯卡的關(guān)鍵因素。
2.3 顯存帶寬
其實(shí)顯存的數(shù)據(jù)通道大小叫位寬,顯存位寬決定GPU核心一次能從顯存中讀取多少數(shù)據(jù);位寬 × 頻率 = 顯存帶寬,顯存的帶寬決定了顯存數(shù)據(jù)吞吐速率。
3. 其他
3.1 功耗(TDP)
不同顯卡功耗不同,高功耗的顯卡需要消耗更多的電力成本,也需要更好的散熱,比如4090的功耗是450W,5090的功耗是575W。
3.2 接口
PCIe 3.0 / 4.0 / 5.0 / NVLink 等,使用的接口類型決定了顯卡與主板CPU之間的通信帶寬,比如更高版本的PCIe會(huì)有更大的帶寬;而NVLink則幫我們解決GPU之間數(shù)據(jù)傳輸?shù)膯栴},NVLink支持兩個(gè)GPU之間直接進(jìn)行數(shù)據(jù)傳輸。
云算力平臺(tái)
當(dāng)前很多的云算力租賃平臺(tái)都顯示了很多顯卡的算力參數(shù),比如 晨澗云 平臺(tái)的首頁就顯示了各類顯卡的顯存及TFLOPS(每秒浮點(diǎn)運(yùn)算次數(shù))的算力值:
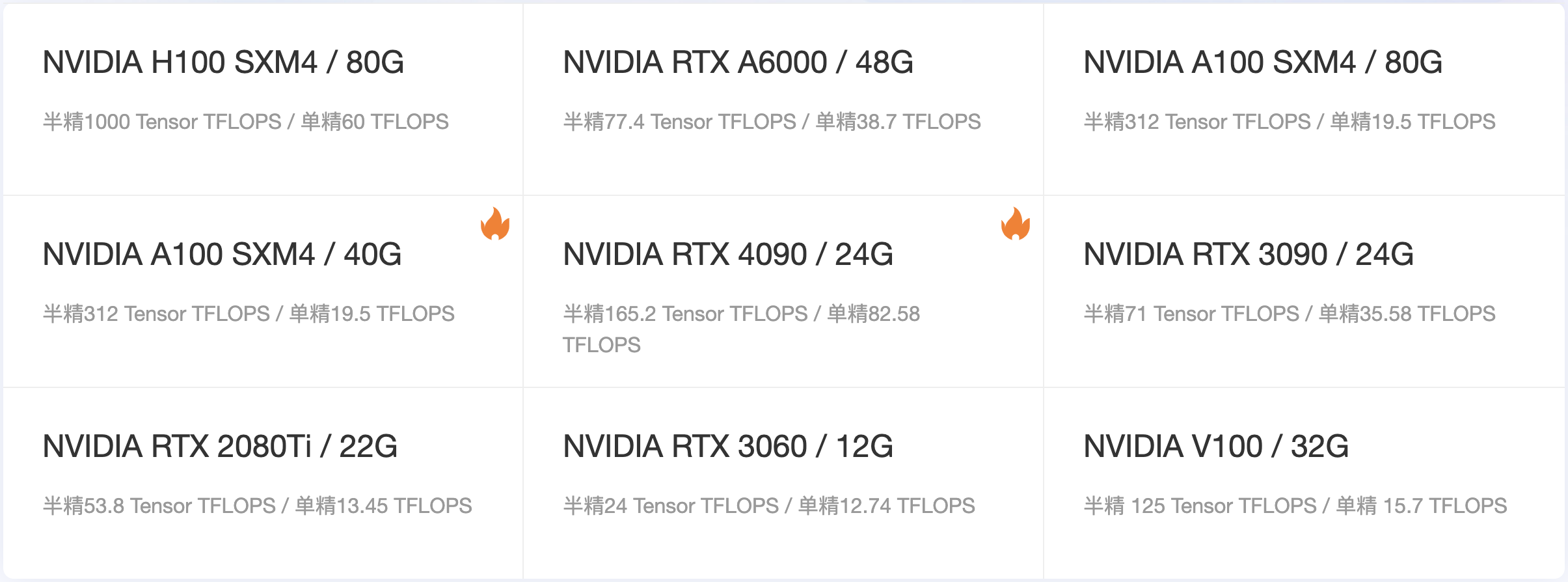
綜合來說,我們?cè)谶x擇顯卡的時(shí)候需要先確定應(yīng)用場(chǎng)景,比如是渲染、模型訓(xùn)練、AI推理還是科學(xué)計(jì)算等,然后確定需要的顯存大小,因?yàn)轱@存不夠就沒法進(jìn)行相應(yīng)的計(jì)算,而核心的計(jì)算性能會(huì)影響總體的運(yùn)算速度和響應(yīng)能力;同時(shí)需要綜合考慮其他參數(shù),權(quán)衡成本和收益。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)