

字節大模型應用開發框架 Eino 全解(一)|結合 RAG 知識庫案例分析框架生態
 大家好,這里是白澤,Eino 是字節開源的 Golang 大模型應用開發框架,諸如豆包、扣子等 Agent 應用或工作流都是借助這個框架進行開發。
我將通過《字節大模型應用開發框架 Eino 全解》系列,從框架結構、組件生態、以及項目案例、mcp集成等維度,帶你全方面掌握 Golang 大模型應用開發。
大家好,這里是白澤,Eino 是字節開源的 Golang 大模型應用開發框架,諸如豆包、扣子等 Agent 應用或工作流都是借助這個框架進行開發。
我將通過《字節大模型應用開發框架 Eino 全解》系列,從框架結構、組件生態、以及項目案例、mcp集成等維度,帶你全方面掌握 Golang 大模型應用開發。
前言
大家好,這里是白澤,Eino 是字節開源的 Golang 大模型應用開發框架,諸如豆包、扣子等 Agent 應用或工作流都是借助這個框架進行開發。
我將通過《字節大模型應用開發框架 Eino 全解》系列,從框架結構、組件生態、以及項目案例、mcp集成等維度,帶你全方面掌握 Golang 大模型應用開發。
本章介紹
- Eino 框架生態介紹,以及相關倉庫地址。
- 借助白澤上一期開源的 Eino 編寫的 基于 Redis 文檔向量檢索系統,梳理 Eino 框架的各個組件模塊,以及交互、編排方式。
Eino 框架生態
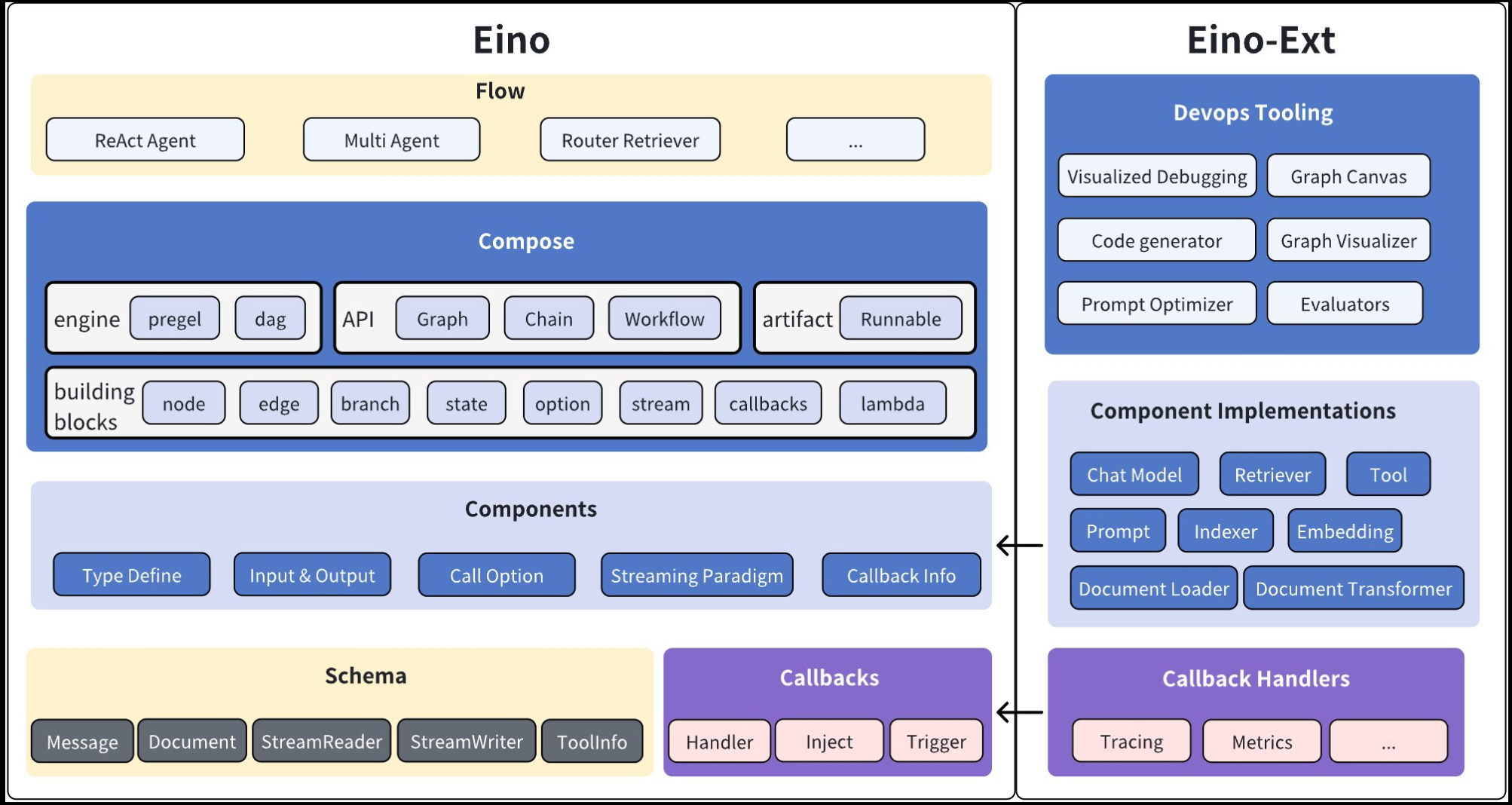
- Eino(主代碼倉庫):包含類型定義、流處理機制、組件抽象、編排功能、切面機制等。
- EinoExt:組件實現、回調處理程序實現、組件使用示例,以及各種工具,如評估器、提示優化器等。
- Eino Devops:可視化開發、可視化調試等。
- EinoExamples:是包含示例應用程序和最佳實踐的代碼倉庫。
- Eino 用戶手冊:快速理解 Eino 中的概念,掌握基于 Eino 開發設計 AI 應用的技能。(Eino 開源不滿一年,文檔仍在完善)
Redis 文檔向量檢索系統(RAG)
接下來將通過這個案例,介紹一下 Eino 框架的各個組件,以及如何使用組件進行編排構建 Agent,同時帶你熟悉一下 Eino 本身的代碼結構。
項目地址:https://github.com/BaiZe1998/go-learning/tree/main/eino_assistant
項目架構圖:
整個項目包含三個階段,索引構建、檢查索引、回答生成、接下來以索引構建階段為例,介紹一下用上了 Eino 哪些組件,以及組件之間的關系,完整的項目講解可以看往期的文章。
?? 整個過程中我們的項目中會同時引入 Eino庫 和 Eino-Ext 庫的內容,希望你能體會 Eino 生態將穩定的類型定義、組件抽象、編排邏輯放置在 Eino 主庫中,而將可擴展的組件、工具實現拆分到 Eino-Ext 庫中的好處。
一、組件初始化
Eino 組件大全
- tool: 對接外部工具,提供了常用工具集。
- chatmodel:對接各家大模型的調用接口。
- callbacks:一些工具的 hook 能力的實現。
- chattemplate:提示詞工程相關,處理和格式化提示模板的組件。
- indexer:Indexer 為把文本進行索引存儲,一般使用 Embedding 做語義化索引,也可做分詞索引等,以便于 Retriever 中召回使用。
- retriver:Retriever 用于把 Indexer 構建索引之后的內容進行召回,在 AI 應用中,一般使用 Embedding 進行語義相似性召回。
- document:對接各家的文檔切分和過濾。
- embeding:對接各家文檔向量化模型。
索引構建本質上也是一個局部完整的工作流,可以借助編輯器插件 Eino Dev 完成可視化的編輯工作流,在可視化的編輯窗口,編排工作流。
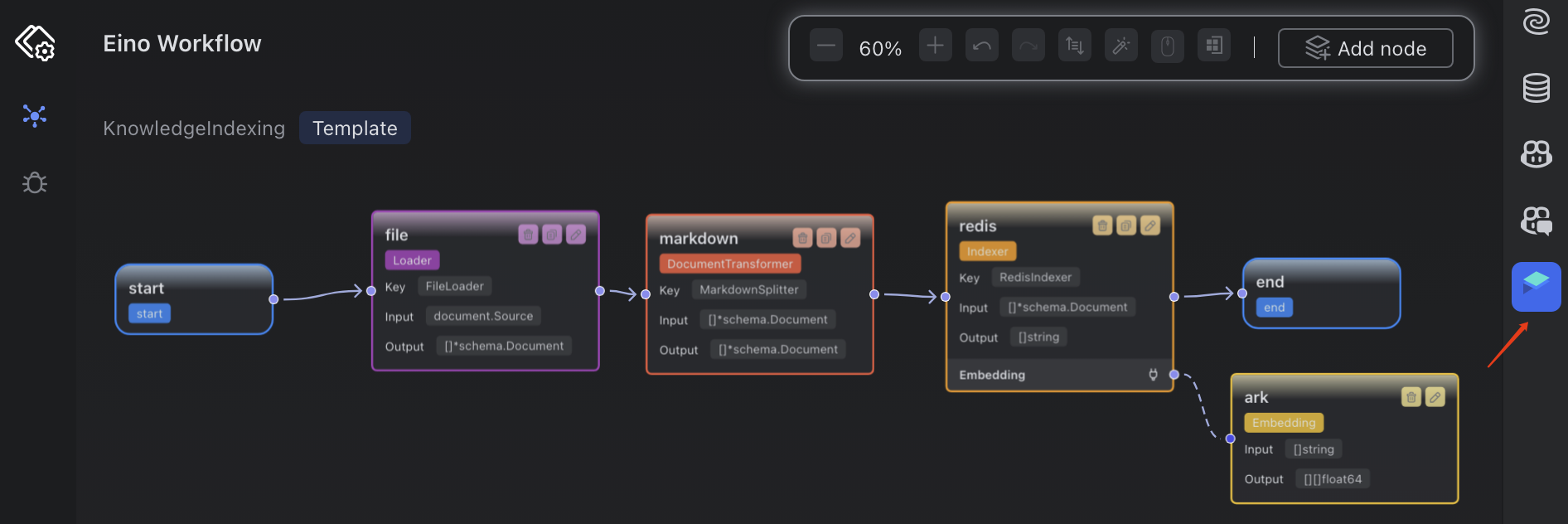
點擊 generate 直接生成如下5個文件,然后手動替換內部的業務邏輯。
Eino Dev 插件的使用將在組件講解篇完成后,單出一期講解。
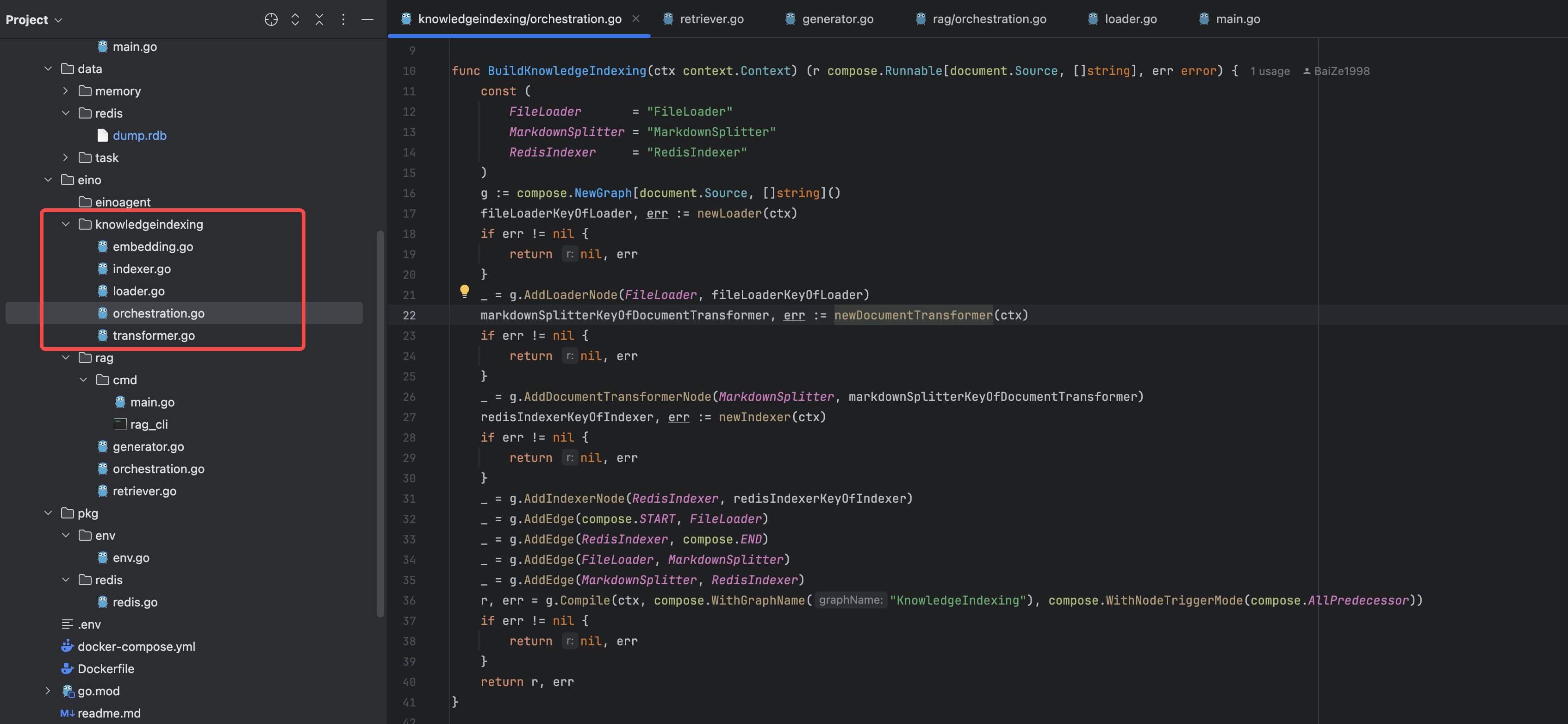
接下來我們看一下五個文件的內容,特別是關注 import 的庫的來源。
- loader.go 創建文件加載組件
package knowledgeindexing
import (
"context"
"github.com/cloudwego/eino-ext/components/document/loader/file"
"github.com/cloudwego/eino/components/document"
)
// newLoader component initialization function of node 'FileLoader' in graph 'KnowledgeIndexing'
func newLoader(ctx context.Context) (ldr document.Loader, err error) {
// TODO Modify component configuration here.
config := &file.FileLoaderConfig{}
ldr, err = file.NewFileLoader(ctx, config)
if err != nil {
return nil, err
}
return ldr, nil
}
document.Loader:
返回值類型是一個接口,定義在 Eino 主庫的 components/document 目錄下。
type Loader interface {
Load(ctx context.Context, src Source, opts ...LoaderOption) ([]*schema.Document, error)
}
file.NewFileLoader:
返回一個具體的文件加載的實現,定義在 Eino-Ext 庫的 components/document 目錄下,是對應關系。
unc NewFileLoader(ctx context.Context, config *FileLoaderConfig) (*FileLoader, error) {
if config == nil {
config = &FileLoaderConfig{}
}
if config.Parser == nil {
parser, err := parser.NewExtParser(ctx,
&parser.ExtParserConfig{
FallbackParser: parser.TextParser{},
},
)
if err != nil {
return nil, fmt.Errorf("new file parser fail: %w", err)
}
config.Parser = parser
}
return &FileLoader{FileLoaderConfig: *config}, nil
}
- transformer.go 創建 markdown 文件分割組件
import (
"context"
"github.com/cloudwego/eino-ext/components/document/transformer/splitter/markdown"
"github.com/cloudwego/eino/components/document"
)
// newDocumentTransformer component initialization function of node 'MarkdownSplitter' in graph 'KnowledgeIndexing'
func newDocumentTransformer(ctx context.Context) (tfr document.Transformer, err error) {
// TODO Modify component configuration here.
config := &markdown.HeaderConfig{
Headers: map[string]string{
"#": "title",
},
TrimHeaders: false}
tfr, err = markdown.NewHeaderSplitter(ctx, config)
if err != nil {
return nil, err
}
return tfr, nil
}
document.Transformer:
返回值類型是一個接口,定義在 Eino 主庫的 components/document 目錄下,定義文檔的過濾和分割。
// Transformer is to convert documents, such as split or filter.
type Transformer interface {
Transform(ctx context.Context, src []*schema.Document, opts ...TransformerOption) ([]*schema.Document, error)
}
markdown.NewHeaderSplitter:
創建一個基于 # 標簽進行分割的 markdown 組件,定義在 Eino-Ext 擴展庫的 components/document/transformer/splitter/markdown 目錄下。
func NewHeaderSplitter(ctx context.Context, config *HeaderConfig) (document.Transformer, error) {
if len(config.Headers) == 0 {
return nil, fmt.Errorf("no headers specified")
}
for k := range config.Headers {
for _, c := range k {
if c != '#' {
return nil, fmt.Errorf("header can only consist of '#': %s", k)
}
}
}
return &headerSplitter{
headers: config.Headers,
trimHeaders: config.TrimHeaders,
}, nil
}
到這一步你應該有了大致的感受,Eino 和 Eino-Ext 是相輔相成的。
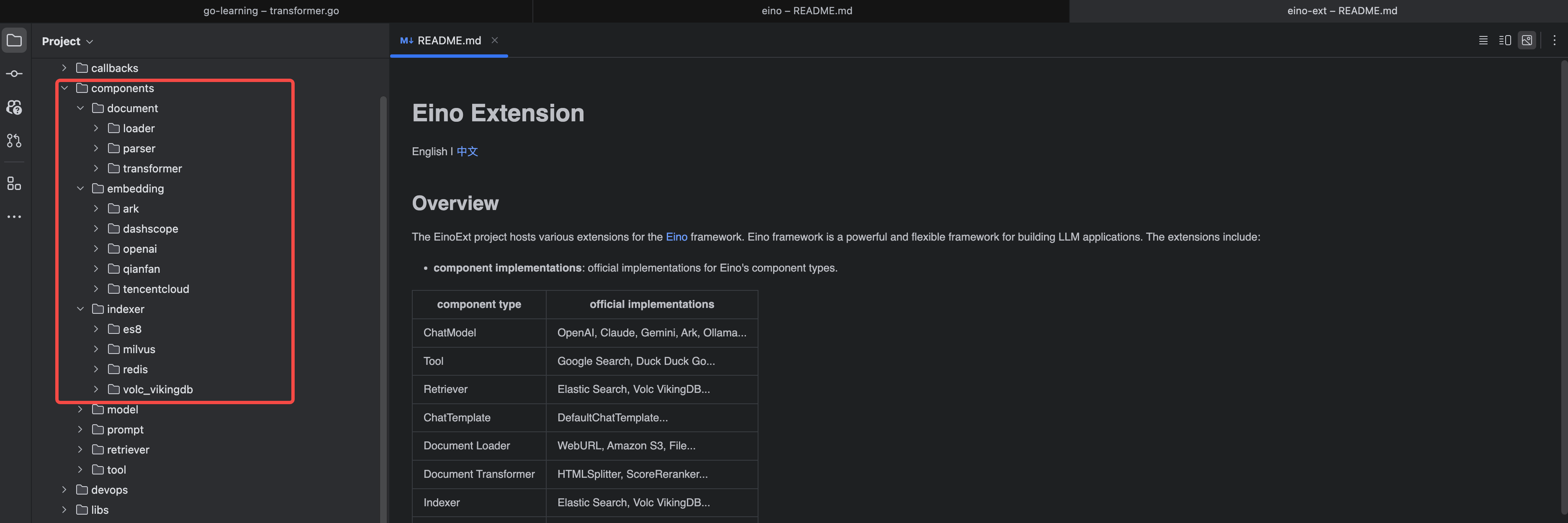
看一下 Eino 庫的組件目錄結構。

看一下 Eino-Ext 的組件目錄結構。
- embedding.go
文檔向量化,需要在初始化的時候,指定一個向量化的模型,用于將文檔數據向量化之后,存入 Redis 向量索引中(也可以使用其他向量數據庫),這里使用了字節的 doubao-embedding-large-text-240915 模型。
package knowledgeindexing
import (
"context"
"os"
"github.com/cloudwego/eino-ext/components/embedding/ark"
"github.com/cloudwego/eino/components/embedding"
)
func newEmbedding(ctx context.Context) (eb embedding.Embedder, err error) {
// TODO Modify component configuration here.
config := &ark.EmbeddingConfig{
BaseURL: "https://ark.cn-beijing.volces.com/api/v3",
APIKey: os.Getenv("ARK_API_KEY"),
Model: os.Getenv("ARK_EMBEDDING_MODEL"),
}
eb, err = ark.NewEmbedder(ctx, config)
if err != nil {
return nil, err
}
return eb, nil
}
- indexer.go(這一步需要你本地通過啟動一個 redis)
Redis向量索引(通過RediSearch模塊實現)是一種高性能的向量數據庫功能,它允許:
-
向量存儲: 在Redis中存儲高維向量數據
-
語義搜索: 基于向量相似度進行搜索(而非簡單的關鍵詞匹配)
-
KNN查詢: 使用K-Nearest Neighbors算法找到最接近的向量
Redis向量索引的核心概念:
-
哈希結構: 使用Redis Hash存儲文檔內容、元數據和向量
-
向量字段: 特殊字段類型,支持高效的向量操作
-
相似度計算: 支持多種距離度量方式(如余弦相似度、歐氏距離)
import (
"context"
"encoding/json"
"fmt"
"log"
"os"
"github.com/cloudwego/eino-ext/components/indexer/redis"
"github.com/cloudwego/eino/components/indexer"
"github.com/cloudwego/eino/schema"
"github.com/google/uuid"
redisCli "github.com/redis/go-redis/v9"
redispkg "eino_assistant/pkg/redis"
)
func init() {
// 初始化索引
err := redispkg.Init()
if err != nil {
log.Fatalf("failed to init redis index: %v", err)
}
}
// newIndexer component initialization function of node 'RedisIndexer' in graph 'KnowledgeIndexing'
func newIndexer(ctx context.Context) (idr indexer.Indexer, err error) {
// TODO Modify component configuration here.
redisAddr := os.Getenv("REDIS_ADDR")
redisClient := redisCli.NewClient(&redisCli.Options{
Addr: redisAddr,
Protocol: 2,
})
// 文檔向量轉換配置
config := &redis.IndexerConfig{
Client: redisClient,
KeyPrefix: redispkg.RedisPrefix,
BatchSize: 1,
// 文檔到 hash 的邏輯轉換
DocumentToHashes: func(ctx context.Context, doc *schema.Document) (*redis.Hashes, error) {
if doc.ID == "" {
doc.ID = uuid.New().String()
}
key := doc.ID
metadataBytes, err := json.Marshal(doc.MetaData)
if err != nil {
return nil, fmt.Errorf("failed to marshal metadata: %w", err)
}
return &redis.Hashes{
Key: key,
Field2Value: map[string]redis.FieldValue{
redispkg.ContentField: {Value: doc.Content, EmbedKey: redispkg.VectorField},
redispkg.MetadataField: {Value: metadataBytes},
},
}, nil
},
}
// 配置 doubao 嵌入模型(文檔向量化)
embeddingIns11, err := newEmbedding(ctx)
if err != nil {
return nil, err
}
config.Embedding = embeddingIns11
idr, err = redis.NewIndexer(ctx, config)
if err != nil {
return nil, err
}
return idr, nil
}
二、組件編排
orchestration.go
文檔索引構建階段,上文的代碼文件連同 orchestration.go 都是通過插件生成的,編排完 ui 工作流,就會為你生成組件之間的流式代碼。
import (
"context"
"github.com/cloudwego/eino/components/document"
"github.com/cloudwego/eino/compose"
)
func BuildKnowledgeIndexing(ctx context.Context) (r compose.Runnable[document.Source, []string], err error) {
const (
FileLoader = "FileLoader"
MarkdownSplitter = "MarkdownSplitter"
RedisIndexer = "RedisIndexer"
)
g := compose.NewGraph[document.Source, []string]()
fileLoaderKeyOfLoader, err := newLoader(ctx)
if err != nil {
return nil, err
}
_ = g.AddLoaderNode(FileLoader, fileLoaderKeyOfLoader)
markdownSplitterKeyOfDocumentTransformer, err := newDocumentTransformer(ctx)
if err != nil {
return nil, err
}
_ = g.AddDocumentTransformerNode(MarkdownSplitter, markdownSplitterKeyOfDocumentTransformer)
redisIndexerKeyOfIndexer, err := newIndexer(ctx)
if err != nil {
return nil, err
}
// 編排的核心:通過點和邊的概念,順序處理數據
_ = g.AddIndexerNode(RedisIndexer, redisIndexerKeyOfIndexer)
_ = g.AddEdge(compose.START, FileLoader)
_ = g.AddEdge(RedisIndexer, compose.END)
_ = g.AddEdge(FileLoader, MarkdownSplitter)
_ = g.AddEdge(MarkdownSplitter, RedisIndexer)
r, err = g.Compile(ctx, compose.WithGraphName("KnowledgeIndexing"), compose.WithNodeTriggerMode(compose.AllPredecessor))
if err != nil {
return nil, err
}
return r, err
}
?? 通過 import 的庫可以看到,編排的流程抽象和數據傳輸類型,都是定義在 Eino 主庫當中的,這里使用了范型來動態定義輸入和輸出類型,此外 Eino 允許上下游之間通過流式或者非流失的形式交換數據,這都是框架的能力。
// Runnable is the interface for an executable object. Graph, Chain can be compiled into Runnable.
// runnable is the core conception of eino, we do downgrade compatibility for four data flow patterns,
// and can automatically connect components that only implement one or more methods.
// eg, if a component only implements Stream() method, you can still call Invoke() to convert stream output to invoke output.
type Runnable[I, O any] interface {
Invoke(ctx context.Context, input I, opts ...Option) (output O, err error)
Stream(ctx context.Context, input I, opts ...Option) (output *schema.StreamReader[O], err error)
Collect(ctx context.Context, input *schema.StreamReader[I], opts ...Option) (output O, err error)
Transform(ctx context.Context, input *schema.StreamReader[I], opts ...Option) (output *schema.StreamReader[O], err error)
}
Eino 提供了兩組用于編排的 API:
| API | 特性和使用場景 |
|---|---|
| Chain | 簡單的鏈式有向圖,只能向前推進。 |
| Graph | 循環或非循環有向圖。功能強大且靈活。 |
我們來創建一個簡單的 chain: 一個模版(ChatTemplate)接一個大模型(ChatModel)。

chain, _ := NewChain[map[string]any, *Message]().
AppendChatTemplate(prompt).
AppendChatModel(model).
Compile(ctx)
chain.Invoke(ctx, map[string]any{"query": "what's your name?"})
現在,我們來創建一個 Graph,先用一個 ChatModel 生成回復或者 Tool 調用指令,如生成了 Tool 調用指令,就用一個 ToolsNode 執行這些 Tool。
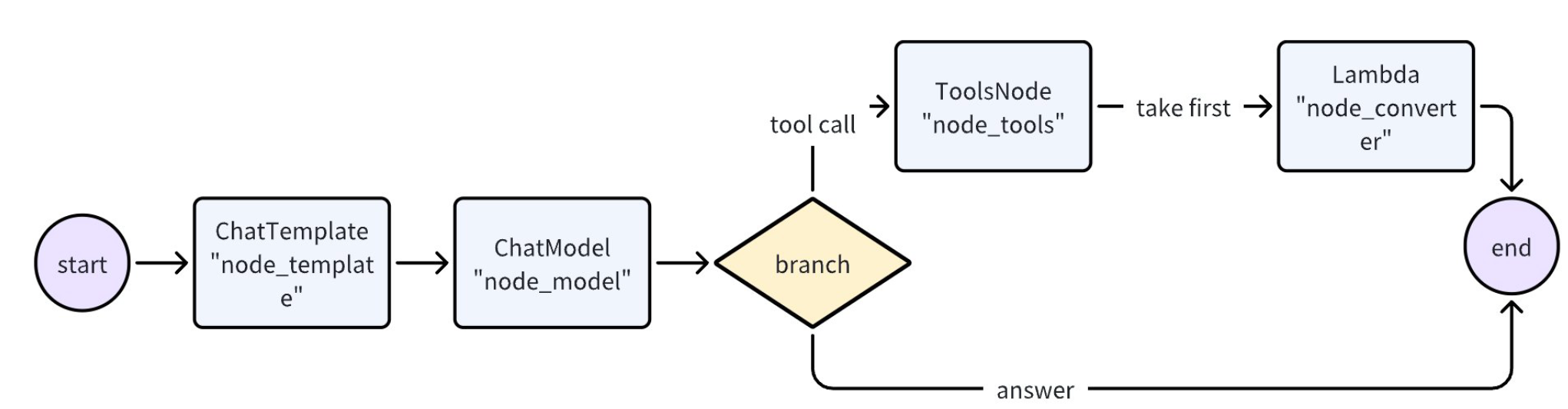
graph := NewGraph[map[string]any, *schema.Message]()
_ = graph.AddChatTemplateNode("node_template", chatTpl)
_ = graph.AddChatModelNode("node_model", chatModel)
_ = graph.AddToolsNode("node_tools", toolsNode)
_ = graph.AddLambdaNode("node_converter", takeOne)
_ = graph.AddEdge(START, "node_template")
_ = graph.AddEdge("node_template", "node_model")
_ = graph.AddBranch("node_model", branch)
_ = graph.AddEdge("node_tools", "node_converter")
_ = graph.AddEdge("node_converter", END)
compiledGraph, err := graph.Compile(ctx)
if err != nil {
return err
}
out, err := r.Invoke(ctx, map[string]any{"query":"Beijing's weather this weekend"})
小節
下一章講解如何通過 Eino 集成 MCP,敬請期待。
公眾號【白澤talk】,Golang|AI 大模型應用開發相關知識星球:白澤說 ,添加: baize_talk02 咨詢加入~

 浙公網安備 33010602011771號
浙公網安備 33010602011771號