
分布式同步服務(wù)中間件
概念
分布式同步服務(wù)中間件:使用分布式一致性協(xié)議,提供分布式環(huán)境下的同步服務(wù)。內(nèi)部有多個節(jié)點,如果其中一個節(jié)點崩潰了,其他節(jié)點就自動接管其功能,繼續(xù)對外提供服務(wù),好像什么都沒有發(fā)生過一樣。
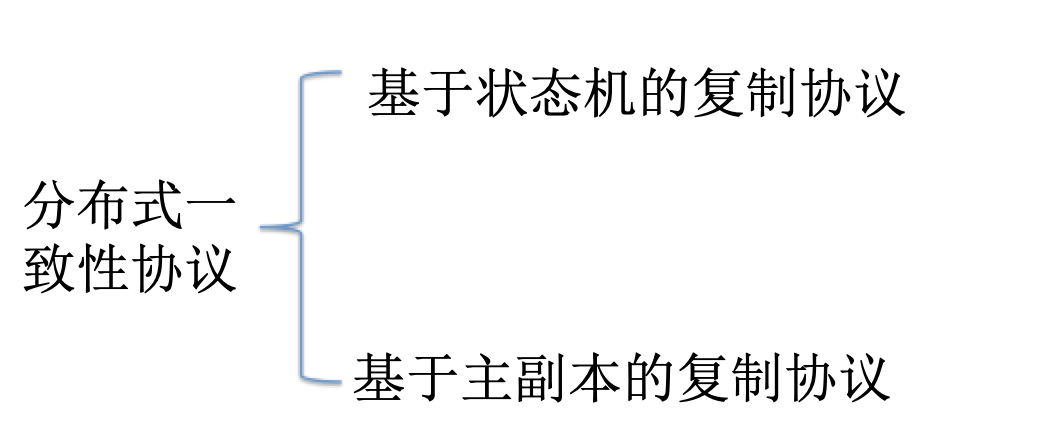
基于狀態(tài)機的復(fù)制協(xié)議(Paxos、Raft):
集群中的每個節(jié)點都可以響應(yīng)客戶的請求,如果某個節(jié)點A響應(yīng)了客戶的請求,就由A將該請求發(fā)送給集群中的每個節(jié)點;集群中的每個節(jié)點都維護一個狀態(tài)機,為了保證數(shù)據(jù)的一致性,每個節(jié)點都按照同樣的順序執(zhí)行一系列的用戶請求。
基于主副本的復(fù)制協(xié)議(ZAB,Zookeeper Atomic Broadcast):
只有主副本處理客戶需求;每隔一段時間,主副本就給其他節(jié)點發(fā)送一個變化更新。
分布式同步服務(wù)舉例
Chubby是谷歌公司實現(xiàn)的以Paxos協(xié)議為基礎(chǔ)的分布式同步服務(wù)。
Zookeeper是谷歌Chubby的開源實現(xiàn),是基于ZAB協(xié)議的。
以下的原理介紹,都會通過這2者來進行說明。
同步服務(wù)的實現(xiàn)原理
如何消除單點故障
Chubby和ZooKeeper通過Master選舉來幫助分布式系統(tǒng)解決單點故障, 保證該系統(tǒng)中每時每刻只有一個Master為分布式系統(tǒng)提供服務(wù)。只是Paxos協(xié)議本身具有領(lǐng)導(dǎo)選舉協(xié)議,ZAB協(xié)議中不包括領(lǐng)導(dǎo)選舉過程,需要一個額外的領(lǐng)導(dǎo)選舉協(xié)議。
如何實現(xiàn)高可用
ZooKeeper通過復(fù)制來實現(xiàn)高可用性,只要集合體中半數(shù)以上的機器處于可用狀態(tài),它就能夠提供服務(wù)。從概念上來說,ZooKeeper它所做的就是確保對Znode樹的每一個修改都會被復(fù)制到集合體中超過半數(shù)的 機器上。
如何保證一致性
ZK集群中每個Server,都保存一份數(shù)據(jù)副本。Zookeeper使用簡單的同步策略,給客戶端提供以下兩條基本保證來實現(xiàn)數(shù)據(jù)的一致性:
(1)線性化的寫支持,即所有的更新操作以某種次序順序執(zhí)行。
(2)先進先出的客戶端順序,即一個客戶端發(fā)起的所有操作,按照其發(fā)起順序執(zhí)行。
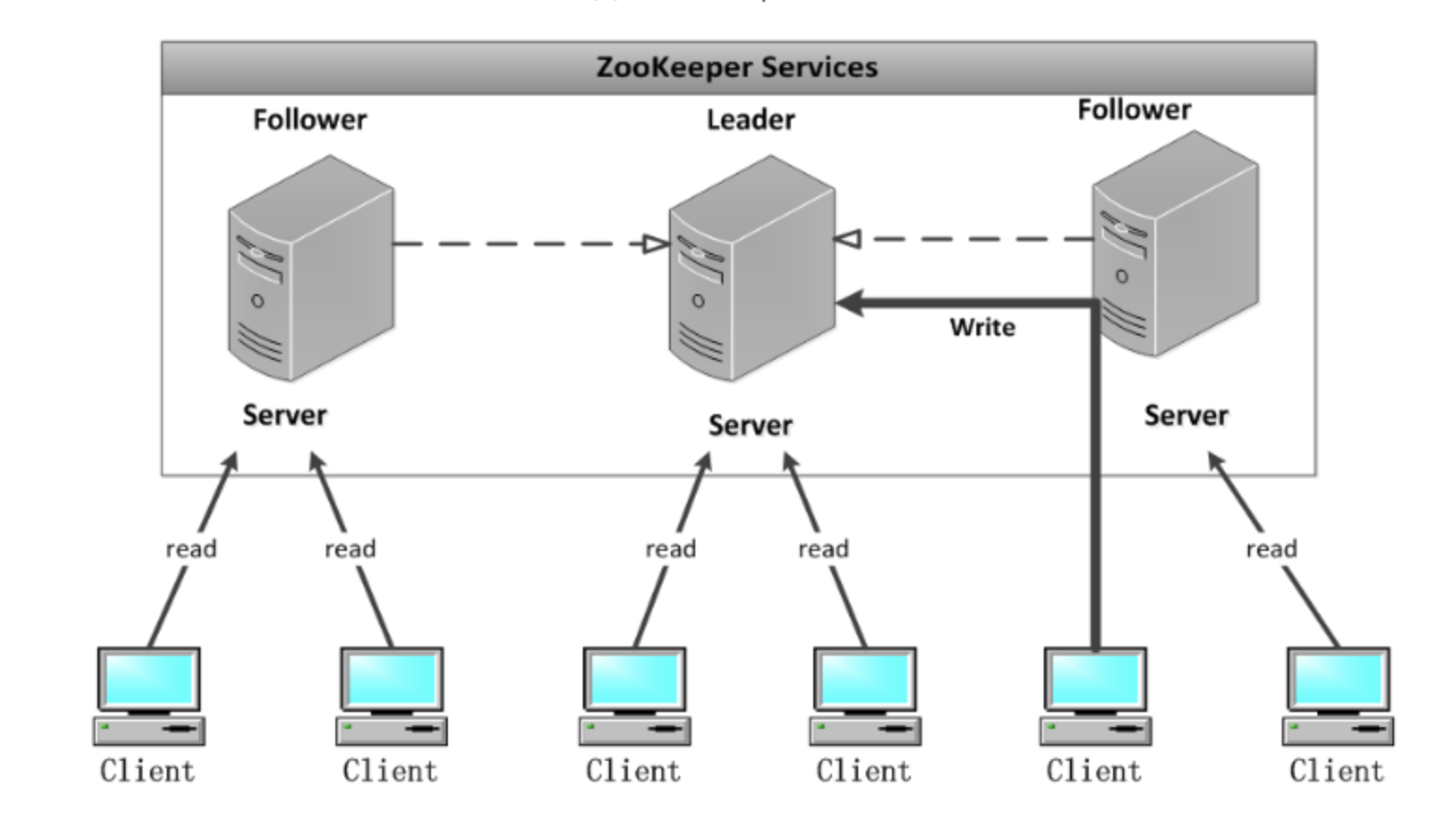
所有的讀請求由Zk Server 本地響應(yīng),所有的更新請求將轉(zhuǎn)發(fā)給Leader,由Leader實施。讀請求,由每臺Server數(shù)據(jù)庫的本地副本來進行服務(wù)。改變服務(wù)器的狀態(tài)的寫請求,需要通過一致性協(xié)議來處理。
Zookeeper的核心是原子廣播機制,這個機制保證了各個server之間的同步。在廣播模式ZooKeeper Server會接受Client請求,所有的寫請求都被轉(zhuǎn)發(fā)給領(lǐng)導(dǎo)者,再由領(lǐng)導(dǎo)者將更新廣播給跟隨者。當(dāng)半數(shù)以上的跟隨者已經(jīng)將修改持久化之后,領(lǐng)導(dǎo)者才會提交這個更新,然后客戶端才會收到一個更新成功的響應(yīng)。這個用來達成共識的協(xié)議被設(shè)計成具有原子性,因此每個修改要么成功要么失敗。
具體來說,Zookeeper從以下幾點保證數(shù)據(jù)的一致性:
① 順序一致性
來自任意特定客戶端的更新都會按其發(fā)送順序被提交。也就是說,如果一個客戶端將Znode z的值更新為a,在之后的操作中,它又將z的值更新為b,則沒有客戶端能夠在看到z的值是b之后再看到值a。
② 原子性
每個更新要么成功,要么失敗。這意味著如果一個更新失敗,則不會有客戶端會看到這個更新的結(jié)果。
③ 單一系統(tǒng)映像
一個客戶端無論連接到哪一臺服務(wù)器,它看到的都是同樣的系統(tǒng)視圖。這意味著,如果一個客戶端在同一個會話中連接到一臺新的服務(wù)器,它所看到的系統(tǒng)狀態(tài)不會比在之前服務(wù)器上所看到的更老。當(dāng)一臺服務(wù)器出現(xiàn)故障,導(dǎo)致它的一個客戶端需要嘗試連接集合體中其他的服務(wù)器時,所有滯后于故障服務(wù)器的服務(wù)器都不會接受該 連接請求,除非這些服務(wù)器趕上故障服務(wù)器。同樣的,Zab要保證同一個leader的發(fā)起的事務(wù)要按順序被apply,同時還要保證只有先前的leader的所有事務(wù)都被apply之后,新選的leader才能在發(fā)起事務(wù)。(為了保證每 個Server的數(shù)據(jù)視圖的一致性)
④ 持久性
一個更新一旦成功,其結(jié)果就會持久存在并且不會被撤銷。這表明更新不會受到服務(wù)器故障的影響。
Zookeeper實踐
ZooKeeper是一種為分布式應(yīng)用所設(shè)計的高可用、高性能且一致的開源協(xié)調(diào)服務(wù),它提供了一項基本服務(wù):分布式鎖服務(wù)。后來,開發(fā)者在分布式鎖的基礎(chǔ)上,摸索了出了其他的使用方法:配置維護、組服務(wù)、分布式消息隊列、分布式通知/協(xié)調(diào)等。
ZooKeeper所提供的服務(wù)主要是通過:數(shù)據(jù)結(jié)構(gòu)+原語+watcher機制,三個部分來實現(xiàn)的:
- 數(shù)據(jù)結(jié)構(gòu)——Znode, 在結(jié)構(gòu)上和標準文件系統(tǒng)的非常相似,都是采用這種樹形層次結(jié)構(gòu),ZooKeeper樹中的每個節(jié)點被稱為—Znode。
- 原語——關(guān)于Znode的一些操作;
- 通知機制——Watcher機制,服務(wù)通過消息以網(wǎng)絡(luò)的形式發(fā)送給分布式應(yīng)用程序。
安裝、配置、啟動
下載:3.14版本,不要下載最新版
配置:cp conf/zoo_sample.cfg conf/zoo.cfg
啟動zookeeper:bin/zkServer.sh start
停止zookeeper:bin/zkServer.sh stop
用zookeeper客戶端連接下服務(wù)端:bin/zkCli.sh
退出客戶端連接:quit
客戶端命令操作zookeeper
查看當(dāng)前zookeeper所包含的內(nèi)容: ls /
創(chuàng)建新的znode: create /username lxy
獲取znode下的字符串:get /username
修改znode的字符串:set /username sheron
刪除znode:delete /username
基于Zookeeper實現(xiàn)配置管理
假設(shè)我們的程序是分布式部署在多臺機器上,如果我們要改變程序的配置文件,需要逐臺機器去修改,非常麻煩,現(xiàn)在把這些配置全部放到zookeeper上去,保存在 zookeeper 的某個目錄節(jié)點中,然后所有相關(guān)應(yīng)用程序?qū)@個目錄節(jié)點進行監(jiān)聽,一旦配置信息發(fā)生變化,每個應(yīng)用程序就會收到 zookeeper 的通知,然后從 zookeeper 獲取新的配置信息應(yīng)用到系統(tǒng)中。
- 啟動3個zookeeper實例子
./bin/zkServer.sh start conf/zoo-1.cfg
./bin/zkServer.sh start conf/zoo-2.cfg
./bin/zkServer.sh start conf/zoo-3.cfg
其中,3臺服務(wù)器的配置分別如下:
三臺服務(wù)器的ip:127.0.0.1
clientPort:2184、2182、2183
服務(wù)器與集群中的 Leader 服務(wù)器交換信息的端口:2888、2889、2890
執(zhí)行選舉時服務(wù)器相互通信的端口:3888、3889、3890
- 查看3臺服務(wù)器的角色
./bin/zkServer.sh status conf/zoo-1.cfg
./bin/zkServer.sh status conf/zoo-2.cfg
./bin/zkServer.sh status conf/zoo-3.cfg
可以看到1個leader、2個follower。
- 連接其中一臺服務(wù)器的客戶端,修改配置,看看其他服務(wù)器的表現(xiàn)
連接3號服務(wù)器:./bin/zkCli.sh -server 127.0.0.1:2183
修改配置:set /username daniu
quit
連接1號服務(wù)器:./bin/zkCli.sh -server 127.0.0.1:2184
查看配置:get /username
- 在sofa4程序中監(jiān)聽配置
public class ZooKeeperProSync implements Watcher {
private static CountDownLatch connectedSemaphore = new CountDownLatch(1);
private static ZooKeeper zk = null;
private static Stat stat = new Stat();
public static void main(String[] args) throws Exception {
//zookeeper配置數(shù)據(jù)存放路徑
String path = "/username";
//連接zookeeper并且注冊一個默認的監(jiān)聽器
zk = new ZooKeeper("127.0.0.1:2182", 5000, //
new ZooKeeperProSync());
//等待zk連接成功的通知
connectedSemaphore.await();
//獲取path目錄節(jié)點的配置數(shù)據(jù),并注冊默認的監(jiān)聽器
System.out.println(new String(zk.getData(path, true, stat)));
Thread.sleep(Integer.MAX_VALUE);
}
public void process(WatchedEvent event) {
if (KeeperState.SyncConnected == event.getState()) { //zk連接成功通知事件
if (EventType.None == event.getType() && null == event.getPath()) {
connectedSemaphore.countDown();
} else if (event.getType() == EventType.NodeDataChanged) { //zk目錄節(jié)點數(shù)據(jù)變化通知事件
try {
System.out.println("配置已修改,新值為:" + new String(zk.getData(event.getPath(), true, stat)));
} catch (Exception e) {
}
}
}
}
}
上面代碼中,我們監(jiān)聽的是第2臺服務(wù)器,我們?nèi)バ薷?臺機器中的任意一臺機器的配置,看看是否能監(jiān)聽到:
set /username xiaoniu
set /username sheron
看到控制臺打印:
配置已修改,新值為:xiaoniu
配置已修改,新值為:sheron
成功。
基于Zookeeper實現(xiàn)分布式鎖
分布式鎖主要用于在分布式環(huán)境中保護共享資源實現(xiàn)互斥訪問,以達到保證數(shù)據(jù)的一致性。
- 獲取分布式鎖思路
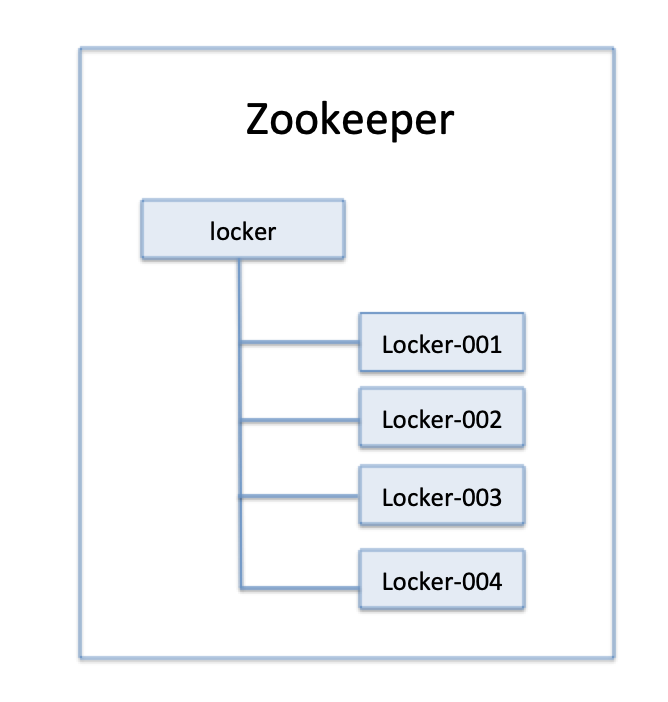
圖1 節(jié)點存儲結(jié)構(gòu)
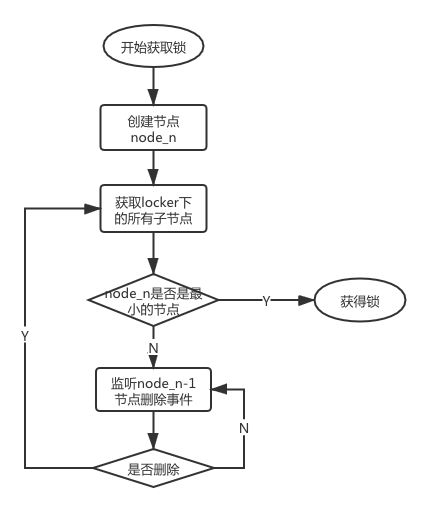
在獲取分布式鎖的時候在locker節(jié)點下創(chuàng)建臨時順序節(jié)點,釋放鎖的時候刪除該臨時節(jié)點。客戶端調(diào)用createNode方法在locker下創(chuàng)建臨時順序節(jié)點,然后調(diào)用getChildren(“l(fā)ocker”)來獲取locker下面的所有子節(jié)點,注意此時不用設(shè)置任何Watcher。客戶端獲取到所有的子節(jié)點path之后,如果發(fā)現(xiàn)自己在之前創(chuàng)建的子節(jié)點序號最小,那么就認為該客戶端獲取到了鎖。如果發(fā)現(xiàn)自己創(chuàng)建的節(jié)點并非locker所有子節(jié)點中最小的,說明自己還沒有獲取到鎖,此時客戶端需要找到比自己小的那個節(jié)點,然后對其調(diào)用exist()方法,同時對其注冊事件監(jiān)聽器。之后,讓這個被關(guān)注的節(jié)點刪除,則客戶端的Watcher會收到相應(yīng)通知,此時再次判斷自己創(chuàng)建的節(jié)點是否是locker子節(jié)點中序號最小的,如果是則獲取到了鎖,如果不是則重復(fù)以上步驟繼續(xù)獲取到比自己小的一個節(jié)點并注冊監(jiān)聽。當(dāng)前這個過程中還需要許多的邏輯判斷。
- 實現(xiàn)方法
(1)DistributedLock
鎖接口,包括“獲取鎖”、“釋放鎖”。
(2)BaseDistributedLock
主要用于與Zookeeper交互,包含“嘗試獲取鎖”、“釋放鎖”的方法。
(3)SimpleDistributedLockMutex
互斥鎖類,實現(xiàn)以上定義的鎖接口,同時繼承基類BaseDistributedLock。
獲取分布式鎖的重點邏輯在于BaseDistributedLock,實現(xiàn)了基于Zookeeper實現(xiàn)分布式鎖的細節(jié)。
- 驗證
public class LockTest {
public static void main(String[] args) throws Exception {
ZkClient zkClient1 = new ZkClient(
"127.0.0.1:2182",
2000000
);
String basePath = "/locker";
SimpleDistributedLockMutex locker1 = new SimpleDistributedLockMutex(zkClient1, basePath);
// locker 1 嘗試獲取鎖
locker1.acquire(-1, null);
// 在其他線程 locker 2 嘗試獲取鎖
LockTest test = new LockTest();
MyThread myThread = test.new MyThread();
myThread.start();
// locker 1 等待3秒 釋放鎖
Thread.currentThread().sleep(3000);
locker1.release();
}
class MyThread extends Thread {
@Override
public void run() {
ZkClient zkClient2 = new ZkClient(
"127.0.0.1:2183",
2000000
);
String basePath = "/locker";
SimpleDistributedLockMutex locker2 = new SimpleDistributedLockMutex(zkClient2, basePath);
try {
//在另一個線程里 locker 2 嘗試獲取鎖
locker2.acquire(-1, null);
} catch (Exception e) {
}
}
}
}
結(jié)果:
Sheron觀測--- /locker/lock-0000000057: 創(chuàng)建了節(jié)點
Sheron觀測--- /locker/lock-0000000057: 獲取了鎖
Sheron觀測--- /locker/lock-0000000058: 創(chuàng)建了節(jié)點
Sheron觀測--- /locker/lock-0000000058: 沒有獲取鎖, 等待 /locker/lock-0000000057釋放鎖
Sheron觀測--- /locker/lock-0000000057: 釋放了鎖
Sheron觀測--- /locker/lock-0000000057: 被觀測到釋放了鎖
Sheron觀測--- /locker/lock-0000000058: 獲取了鎖
分析:57號節(jié)點是/locker下的第一個節(jié)點,所以它可以直接獲取鎖,58號節(jié)點創(chuàng)建后,要等待57號節(jié)點釋放鎖,當(dāng)過了3秒鐘,57號節(jié)點釋放掉了鎖,這時候58號節(jié)點獲取到了鎖。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號