
輕松掌握 Linux 文本處理三劍客:grep、awk 和 sed 實(shí)戰(zhàn)演練
Shell 腳本語(yǔ)言編程有哪些優(yōu)勢(shì)呢?
Shell 腳本語(yǔ)言的優(yōu)勢(shì)在于能夠以最輕量級(jí)最快捷的速度處理 Linux 操作系統(tǒng)偏底層的業(yè)務(wù)。比如軟件的自動(dòng)化安裝、更新版本,監(jiān)控報(bào)警,日志分析等。雖然其他高級(jí)編程語(yǔ)言如 PHP、Python、Ruby 等語(yǔ)言也能做到,但是效率和開(kāi)發(fā)成本上會(huì)大打折扣,所謂“殺雞用牛刀”,有點(diǎn)得不償失。
成熟的技術(shù)人會(huì)摒棄華而不實(shí)的方法,而會(huì)根據(jù)不同的場(chǎng)景選擇最合適的工具去解決問(wèn)題,樸實(shí)而高效。比如本文著重介紹的 Linux 三劍客:grep、awk 和 sed 就是 Linux 文本處理問(wèn)題的最高效工具。
下面,我們將依次介紹 Linux 文本處理三劍客的基礎(chǔ)語(yǔ)法,使用場(chǎng)景和特性,以及給出對(duì)應(yīng)的實(shí)戰(zhàn)演練題目。
Shell 編程環(huán)境安裝
- Windows 用戶,建議安裝 Git Bash 軟件。
- Mac 用戶,建議安裝 iterm2 軟件。
- ssh 工具
Linux 三劍客介紹


- grep:主要用于文本內(nèi)容查找,支持正則表達(dá)式。
- awk:主要用于文本內(nèi)容的分析處理,也常用于處理數(shù)據(jù),生成報(bào)告,非常適用于需要按列處理的數(shù)據(jù)。(現(xiàn)在很多Linux使用gawk)
- sed:全稱為 Stream editor ,主要用于文本內(nèi)容的編輯,默認(rèn)只處理模式空間,不改變?cè)瓟?shù)據(jù),而且 sed 使用逐行讀取的方式處理數(shù)據(jù)。


- -A<行數(shù) x>:除了顯示符合范本樣式的那一列之外,并顯示該行之后的 x 行內(nèi)容。
- -B<行數(shù) x>:除了顯示符合樣式的那一行之外,并顯示該行之前的 x 行內(nèi)容。
- -C<行數(shù) x>:除了顯示符合樣式的那一行之外,并顯示該行之前后的 x 行內(nèi)容。
- -c:統(tǒng)計(jì)匹配的行數(shù)
- -e :實(shí)現(xiàn)多個(gè)選項(xiàng)間的邏輯or 關(guān)系
- -E:擴(kuò)展的正則表達(dá)式
- -f 文件名:從文件獲取 PATTERN 匹配
- -F :相當(dāng)于fgrep
- -i --ignore-case #忽略字符大小寫(xiě)的差別。
- -n:顯示匹配的行號(hào)
- -o:僅顯示匹配到的字符串
- -q:靜默模式,不輸出任何信息
- -s:不顯示錯(cuò)誤信息。
- -v:顯示不被 pattern 匹配到的行,相當(dāng)于[^] 反向匹配
- -w :匹配 整個(gè)單詞
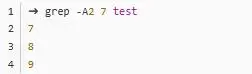
-A2 7 的效果就是找到 7 ,然后輸出 7 后面兩行。-B2 7和-C2 7就是找到 7 ,然后分別輸出 7 前面兩行和前后兩行:

grep -c命令的作用就是輸出匹配到的行數(shù),比如我們想找包含aaa的有幾行,一眼就能看出來(lái)有兩行,第一行和第三行都包含:grep -e命令是實(shí)現(xiàn)多個(gè)匹配之間的或關(guān)系,比如我們想找包含aaaa或者bbbb的,顯然應(yīng)該返回第一行和第二行:
grep -F相當(dāng)于fgrep命令,就是將pattern視為固定字符串。比如搜索'aa*'不帶-F和帶上,區(qū)別如下:

可以看到第二次就找不到了,因?yàn)樗阉鞯氖?aa*這個(gè)字符串,而不是正則表達(dá)式。grep -f 文件名的使用方法是把后面這個(gè)文件里的內(nèi)容當(dāng)做pattern。比如我們有個(gè)文件,名字是 grep.txt,然后內(nèi)容是aa*,使用方法如下:

實(shí)際上等同于grep 'aa*' testgrep -i --ignore-case作用是忽略大小寫(xiě)。grep -n顯示匹配的行號(hào),就是多顯示了個(gè)行號(hào),不用細(xì)說(shuō)。grep -o僅顯示匹配到的字符串,還是用剛才的aa*距離,之前顯示的都是匹配到的字符所在的整行,這個(gè)命令是只顯示匹配到的字符:

grep -q不打印匹配結(jié)果。剛看到這個(gè)我疑惑了半天,讓你搜索字符串,你不給我結(jié)果那有啥用?然后發(fā)現(xiàn)還有一條很多教程沒(méi)說(shuō):如果有匹配的內(nèi)容則立即返回狀態(tài)值 0。所以一般用在shell腳本中,在 if 判斷里面。grep -s不顯示錯(cuò)誤信息,不解釋。grep -v顯示不被匹配到的行,相當(dāng)于[^]反向匹配,最常見(jiàn)的還是用在查找線程的命令里,有時(shí)候會(huì)打印grep線程,可以再加上這么一個(gè)去除自己:
-
? ps -ef|grep Typora
-
501 91616 1 0 五11上午 ?? 13:39.32 /Applications/Typora.app/Contents/MacOS/Typora
-
501 14814 93748 0 5:33下午 ttys002 0:00.00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn Typora
-
-
? ps -ef|grep Typora|grep -v grep
-
501 91616 1 0 五11上午 ?? 13:39.32 /Applications/Typora.app/Contents/MacOS/Typora
可以看到第二次就沒(méi)有打印grep線程自身grep -w匹配整個(gè)單詞,只有完全符合pattern的單次才會(huì)匹配到:

可以看到第二次結(jié)果為空,因?yàn)闆](méi)有aaa這個(gè)單詞。
grep 實(shí)戰(zhàn)演練題目
- 找出 nginx.log 中所有 404 和 503 報(bào)錯(cuò)的 log 數(shù)據(jù)
$grep -E ' 404 | 500 ' nginx.log | wc -l
$awk '$9~/404|500/' nginx.log | wc -l




- -F fs or --field-separator fs 指定輸入文件折分隔符,fs是一個(gè)字符串或者是一個(gè)正則表達(dá)式,如-F:。
- -v var=value or --asign var=value 賦值一個(gè)用戶定義變量。
- -f scripfile or --file scriptfile 從腳本文件中讀取awk命令。

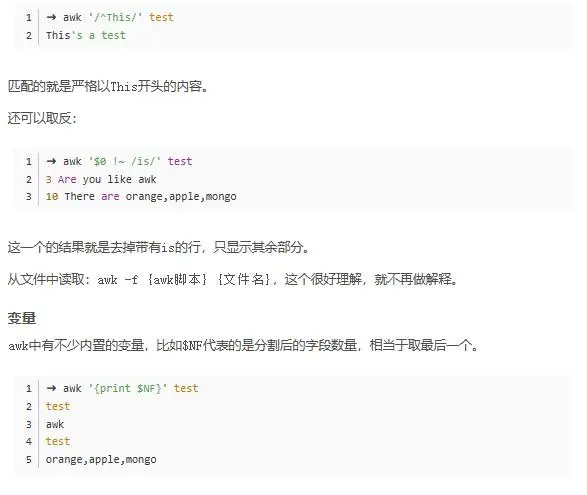
awk '{print $1,$4}' test就可以看到:對(duì)比可以很清楚的發(fā)現(xiàn),這行語(yǔ)句的作用是打印每行的第一個(gè)和第四個(gè)單詞。這里如果是$0的話就是把整行都輸出出來(lái)。awk- -F命令以指定使用哪個(gè)分隔符,默認(rèn)是空格或者 tab 鍵:
10 There are orange、apple和mongo三項(xiàng),然后我們要的是第二項(xiàng)。
- FILENAME:當(dāng)前文件名
- FS:字段分隔符,默認(rèn)是空格和制表符。
- RS:行分隔符,用于分割每一行,默認(rèn)是換行符。
- OFS:輸出字段的分隔符,用于打印時(shí)分隔字段,默認(rèn)為空格。
- ORS:輸出記錄的分隔符,用于打印時(shí)分隔記錄,默認(rèn)為換行符。
- OFMT:數(shù)字輸出的格式,默認(rèn)為%.6g。
- toupper():字符轉(zhuǎn)為大寫(xiě)。
- tolower():字符轉(zhuǎn)為小寫(xiě)。
- length():返回字符串長(zhǎng)度。
- substr():返回子字符串。
- sin():正弦。
- cos():余弦。
- sqrt():平方根。
- rand():隨機(jī)數(shù)。
sed
pattern表達(dá)式
- 20 30,35 行數(shù)與行數(shù)范圍
- /pattern/ 正則匹配
- //,// 正則匹配的區(qū)間
action
- d 刪除
- p 打印,通暢結(jié)合-n參數(shù)
- s/REGEXP/REPLACEMENT/[FLAGS]
- 替換時(shí)引用 \1 \2 匹配的字段
sed
sed 命令的作用是利用腳本來(lái)處理文本文件。使用方法: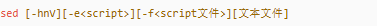
參數(shù)說(shuō)明:
- -e<script>或--expression=<script> 以選項(xiàng)中指定的 script 來(lái)處理輸入的文本文件,這個(gè)-e可以省略,直接寫(xiě)表達(dá)式。
- -f<script文件>或--file=<script文件>以選項(xiàng)中指定的 script 文件來(lái)處理輸入的文本文件。
- -h或--help顯示幫助。
- -n 或 --quiet 或 --silent 僅顯示 script 處理后的結(jié)果。
- -V 或 --version 顯示版本信息。
- a:新增, a 的后面可以接字串,而這些字串會(huì)在新的一行出現(xiàn)(目前的下一行)~
- c:取代, c 的后面可以接字串,這些字串可以取代 n1,n2 之間的行!
- d:刪除,因?yàn)槭莿h除啊,所以 d 后面通常不接任何咚咚;
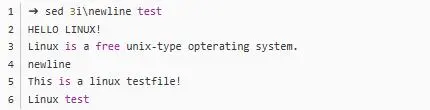
- i:插入, i 的后面可以接字串,而這些字串會(huì)在新的一行出現(xiàn)(目前的上一行);
- p:打印,亦即將某個(gè)選擇的數(shù)據(jù)印出。通常 p 會(huì)與參數(shù) sed -n 一起運(yùn)行~
- s:取代,通常這個(gè) s 的動(dòng)作可以搭配正規(guī)表示法,例如 1,20s/old/new/g 。

增加內(nèi)容
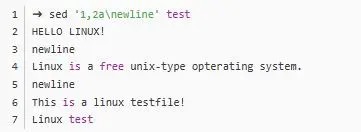
sed -e 3a\newLine testfile這個(gè)命令的意思就是,在第三行后面追加newLine這么一行字符,字符前面要用反斜線作區(qū)分。執(zhí)行完畢之后可以看到結(jié)果: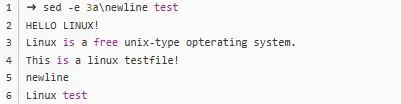
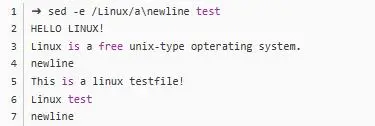
sed /Linux/i\newline test是在所有匹配到Linux的行前面插入:
刪除
d,用法跟前面也很相似,就不贅述,例子如下:
替換
c。舉個(gè)栗子: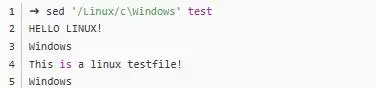
s,但是用法由不太一樣了,最常見(jiàn)的用法:sed 's/old/new/g'其中old代表想要匹配的字符,new是想要替換的字符,比如: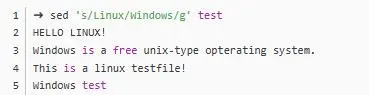
/g的意思是一行中的每一次匹配,因?yàn)橐恍兄锌赡芷ヅ涞胶芏啻巍N覀兡靡粋€(gè)新的文本文件做例子:
a變成大寫(xiě)A,那應(yīng)該這么寫(xiě):a出現(xiàn)。s還有很多用法,還是回到第一個(gè)文件,比如可以用/^/和/$/分別代表行首和行尾:
- ^ 表示一行的開(kāi)頭。如:/^#/ 以#開(kāi)頭的匹配。
- $ 表示一行的結(jié)尾。如:/}$/ 以}結(jié)尾的匹配。
- \< 表示詞首。如:`\ 表示以 abc 為首的詞。
- \> 表示詞尾。如:abc\> 表示以 abc 結(jié)尾的詞。
- . 表示任何單個(gè)字符。
- * 表示某個(gè)字符出現(xiàn)了0次或多次。
- [ ] 字符集合。如:[abc] 表示匹配a或b或c,還有 [a-zA-Z] 表示匹配所有的26個(gè)字符。如果其中有^表示反,如 [^a] 表示非a的字符
//括起來(lái):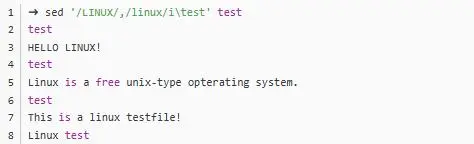
LINUX的那一行,到匹配到linux的那一行,也就是 123 這三行多個(gè)匹配
-e命令可以執(zhí)行多次匹配,相當(dāng)于順序依次執(zhí)行兩個(gè)sed命令:

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)