
python核心編程6-10
第六章 序列: 字符串、列表和元組
本章主題
- 序列簡介
- 字符串
- 列表
- 元組
接下來學習這類數據類型,成員有序排列的,且可以通過下標偏移量訪問到它的一個或者幾個成員,這類 Python 類型統稱為序列,包括下面這些:字符串(普通字符串和 unicode 字符串),列表,和元組類型。
首先學習下適用于所有序列類型的操作符和內建函數(BIFs),
- 簡介
- 操作符
- 內建函數
- 內建函數(如果可用)
- 特性(如果可用)
- 相關模塊(如果可用)
6.1 序列
- 它的每一個元素可以通過指定一個偏移量的方式得到
- 多個元素可以通過切片操作的方式一次得到
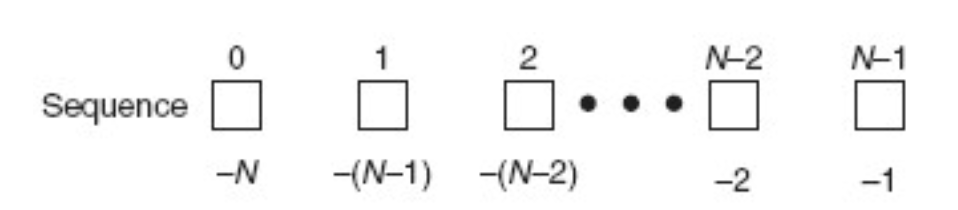
- 下標偏移量 是從 0 開始到 總元素數-1 結束
6.1.1 標準類型操作符
標準類型操作符(參見 4.5 節)一般都能適用于所有的序列類型。
6.1.2 序列類型操作符
表 6.1 列出了對所有序列類型都適用的操作符。操作符是按照優先級從高到底的順序排列的。

成員關系操作符 (in, not in)
判斷一個元素是否屬于一個序列的,返回值 True/False,滿足成員關系就返回 True,否則返 回 False。比如對字符串類型來說,判斷一個字符是否屬于這個字符串,對元組類型來說,就代表了一個對象是否屬于該對象序列。
操作語法:obj [not] in sequence
連接操作符( + )
把一個序列和另一個相同類型的序列做連接。sequence1 + sequence2,該表達式的結果是一個包含 sequence1 和 sequence2 的內容的新序列。
但是這個操作不是最快或者說最有效的。
- 對字符串來說,該操作不如把所有的子字符串放到一個列表或可迭代對象中,然后調用一個 join方法來把所有的內容連接在一起節約內存。
- 對列表來說,推薦用列表類型的 extend()方法來把兩個或者多個列表對象合并。
當你需要簡單地把兩個對象的內容合并,或者說不能依賴于可變對象的那些沒有返回值(實際上它返回一個 None)的內建方法來完成的時候時, 連接操作符還是很方便的一個選擇。
重復操作符 ( * )
一個序列的多份拷貝。sequence * copies_int
像連接操作符一樣,該操作符返回一個新的包含多份原對象拷貝的對象。
切片操作符 ( [], [:], [::] )
- 用方括號加一個下標的方式訪問它的每一個元素;
sequence[index]
1.index范圍是 0 <= inde <= len(sequece)-1
2.也可以使用負索引,范圍是 -len(sequence) <= index <= -1。
3.正負索引的區別在于正索引以序列的開始為起點,負索引以序列的結束為起點。 - 通過在方括號中用冒號把開始下標和結束下標分開的方式來訪問一組連續的元素,
sequence[starting_index:ending_index]
1.起始索引和結束索引都是可選的,若沒有提供或者用 None 作為索引值,切片操作會從序列的最開始處開始,或者直到序列的最末尾結束。eg:[:][:3][3:]
這種訪問序列的方式叫做切片。
用步長索引來進行擴展的切片操作。切片操作還有第三個索引被用做步長參數。可以把這個參數看成跟內建函數 range()里面的步長參數一樣來理解。
>>> a=[1, 2, 3, 4]
>>> a[::-1] # 可以視作"翻轉"操作
[4, 3, 2, 1]
>>>
>>> a[::2] # 隔一個取一個的操作
[1, 3]
切片索引的開始和結束素引值可以超過字符串的長度。起始索引可以小于 0,而對于結束索引,即使索引值為 100 的元素并不存在也不會報錯。
>>> a=[1, 2, 3, 4]
>>> a[-100:100]
[1, 2, 3, 4]
6.1.3 內建函數(BIFs)
TODO
6.2 字符串
在引號間包含字符的方式創建它。Python 里面單引號和雙引號的作用是相同的。
字符串是一種直接量或者說是一種標量,這意味著 Python 解釋器在處理字符串時是把它作為單一值并且不會包含其他 Python 類型的。
字符串是不可變類型。
字符串是由 獨立的字符組成的,并且這些字符可以通過切片操作順序地訪問。
- 在其他類shell腳本語言中,通常轉義字符僅僅在雙引號字符串中起作用,在單一號括起的字符串中不起作用。Python 用"原始字符串"操作符來創建直接量字符串,所以再做區分就沒什么意義了。
- 其他的語言,比如 C 語言里面用單引號來標示字符,雙引號標示字符串,而在 Python 里面沒有字符這個類型.
Python 實際上有 3 類字符串.通常意義的字符串(str)和 Unicode 字符串(unicode)實際上都是抽象類 basestring 的子類。basestring 是不能實例化的。
字符串的創建和賦值
創建一個字符串就像使用一個標量一樣簡單,當然你也可以把 str()作為工廠方法來創建一個字符串并把它賦值給一個變量。
>>> aString = "Hello world!" # 雙引號
>>> bString = 'Hello world!' # 單引號
>>> print(aString)
Hello world! # 輸出不帶引號
>>> aString
'Hello world!' # 輸出帶引號
>>> s = str(range(4))
>>> s = str(list(range(4))) # 把一個列表轉換成一個字符串
>>> s
'[0, 1, 2, 3]'
如何訪問字符串的值(字符和子串)
Python 里面沒有字符這個類型,而是用長度為 1 的字符串來表示這個概念。切片方式來訪問字符和子串。
>>> aString = "Hello world!"
>>> aString[0]
'H'
>>> aString[:3]
'Hel'
如何改變字符串
你可以通過給一個變量賦值(或者重賦值)的方式“更新”一個已有的字符串。
>>> aString = "Hello world!"
>>> aString
'Hello world!'
>>> aString = "very good!"
>>> aString
'very good!'
>>>
字符串類型是不可變的,所以你要改變一個字符串就必須通過創建一個新串的方式來實現。
如何刪除字符和字符串
字符串是不可變的,所以你不能僅僅刪除一個字符串里的某個字符,你能做的是清空一個空字符串,或者是把剔除了不需要的部分后的字符串組合起來形成一個新串。
>>> aString = "Hello world!"
>>> aString
'Hello world!'
>>> aString = aString[:3] + aString[:4]
>>> aString
'HelHell'
>>>
# 通過賦一個空字符串或者使用 del 語句來清空或者刪除一個字符串:
>>> aString = ''
>>> aString
''
>>> del aString
>>> aString
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'aString' is not defined
# 在大部分應用程序里,沒有必要顯式的刪除字符串。定義這個字符串的代碼最終會結束,那時 Python 會自動釋放這些字符串。
6.3 字符串和操作符
6.3.1 標準類型操作符
第4 章介紹了一些適用于包括標準類型在內的大部分對象的操作符,再看一下這些其中的一些操作符是怎樣作用于字符串類型的。
>>> str1 = 'abc'
>>> str2 = '1mn'
>>> str3 = 'xyz'
>>> str1 < str2 # 在做比較操作時,字符串是按照 ASCII 值的大小來比較的.
False
>>> str2 != str3
True
>>>
>>> str1 < str3 and str2 == "xyz"
False
>>>
6.3.2 序列操作符
切片( [ ] 和 [ : ] )
用一個參數來調用切片操作符結果是一個單一字符,而使用一個數值范圍(用':')作為參數調用切片操作的參數會返回一串連續地字符。
對任何范圍[start:end],可以訪問到包括 start 在內到 end(不包括 end)的所有字符。
訪問單個字符時使用不在允許范圍內的索引值會導致錯誤。
正向索引和反向索引和list的使用方法是一樣的。
成員操作符(in ,not in)
判斷一個字符或者一個子串(中的字符)是否出現在另一個字符串中。
成員操作符不是用來判斷一個字符串是否包含另一個字符串的,這樣的功能由 find()或者 index()(還有它們的兄弟:rfind()和 rindex())函數來完成。
字符和字符串都可以判斷啊
string 模塊預定義的字符串:
>>> import string
>>> string.ascii_uppercase
'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
>>> string.ascii_lowercase
'abcdefghijklmnopqrstuvwxyz'
>>> string.ascii_letters
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
>>> string.digits
'0123456789'
一個小code case,判斷一個標識符是否合法:首先要以字母或者下劃線開始,后面要跟字母,下劃線或者或數字. 只檢查長度大于等于 2 的標識符。
我寫的
import string
import sys
user_input = input("please enter the sysboml:")
if len(user_input) < 2:
print("the length of input doesn't equal 2 ")
sys.exit(-1)
if user_input[0] in string.ascii_letters + "_":
for letter in user_input[1:]:
if letter not in string.digits + string.ascii_letters + "_":
print("error")
sys.exit(-1)
else:
print("the first letter is not valid!")
sys.exit(-1)
print("ok")
書本里的code
#!usr/bin/env python 2
import string
alphas = string.ascii_letters + '_'
nums = string.digits
print('Welcome to the Identifier Checker v1.0')
print('Testees must be at least 2 chars long.')
myInput = input('Identifier to test? ')
if len(myInput) > 1:
if myInput[0] not in alphas:
print('''invalid: first symbol must be alphabetic''')
else:
for otherChar in myInput[1:]:
if otherChar not in alphas + nums:
print('''invalid: remaining symbols must be alphanumeric''')
break
else: # for 循環的 else 語句是一個可選項,它只在 for 循環完整的結束,沒有遇到 break 時執行。
print("okay as an identifier")
關于程序的解釋,其他都很so easy。
關于性能的特殊提示:
從性能的的角度來考慮,把重復操作作為參數放到循環里面進行是非常低效的。while i < len(myString): print 'character %d is:', myString[I]
每次循環迭代都要運行一次這個函數.如果把這個值做一次保存,就可以用更為高效的方式重寫循環操作。length = len(myString) while i < length: print 'character %d is:', myString[I]
這個方法同樣適用于上面的例子。for循環里面的if otherChar not in alphas + nums:,被合并的這兩個字符串沒變過,而每次都會重新進行一次計算.如果先把這兩個字符串存為一個新字符串,就可以直接引用這個字符串而不用進行重復計算了。alphnums = alphas + nums for otherChar in myInput[1:]:
這段程序的問題:
- 標識符的長度必須大于 1. 程序并沒有真正定義出 Python 標識符的范圍(例子里是要求長度為2以上)。
- 是沒有考慮到 Python 的關鍵字,而這些都是作為保留字,不允許用做標識符的。
連接符( + )
運行時刻字符串連接
可以通過連接操作符來從原有字符串獲得一個新的字符串。
>>> 'Spanish' + 'Inquisition'
'SpanishInquisition'
現在已經沒有必要導入 string 模塊了,除非需要訪問該模塊自己定義的字符串常量。
出于性能方面的考慮, 建議不要用 string 模塊。原因是 Python 必須為每一個參加連接操作的字符串分配新的內存,包括新產生的字符串。推薦使用字符串格式化操作符(%),或者把所有的字符串放到一個列表中去,用 join()方法來把它們連接在 一起。
>>> '%s %s' % ('Spanish', 'Inquisition')
'Spanish Inquisition'
>>> s = ' '.join(('Spanish', 'Inquisition', 'Made Easy'))
>>> s
'Spanish Inquisition Made Easy'
>>> # no need to import string to use string.upper():
...
>>> ('%s%s' % (s[:3], s[20])).upper()
'SPAM'
>>>
編譯時字符串連接
Python 的語法允許你在源碼中把幾個字符串連在一起寫,以此來構建新字符串:
>>> foo = "Hello" 'world'
>>> foo
'Helloworld'
>>>
這種方法可以把長的字符串分成幾部分來寫,而不用加反斜杠。如上所示, 可以在一行里面混用兩種分號。這種寫法的好處是你可以把注釋也加進來。
>>> f = urllib.urlopen('http://' # protocol ... 'localhost'# hostname
... ':8000' # port
... '/cgi-bin/friends2.py') # file
普通字符串轉化為 Unicode 字符串
如果把一個普通字符串和一個 Unicode 字符串做連接處理,Python 會在連接操作前先把普 通字符串轉化為 Unicode 字符串:
>>> 'Hello' + u' ' + 'World' + u'!'
'Hello World!'
重復操作符( * )
重復操作符創建一個包含了原有字符串的多個拷貝的新串。
>>> 'Ni!' * 3
'Ni!Ni!Ni!'
>>> who = 'knights'
>>> who * 2
'knightsknights'
>>> who # 像其他的標準操作符一樣,原變量是不被修改的
'knights'

 浙公網安備 33010602011771號
浙公網安備 33010602011771號