
python核心編程1-5
第一章
1. python定義
繼承了傳統編譯語言的強大性和通用性,也借鑒了簡單腳本和解釋型語言的易用性
2. python起源
1989年底羅薩姆始創了python。他期望有一種工具可以完成日常系統管理任務,并能夠訪問Amoeba分布式操作系統的系統調用。羅薩姆為此創造出了一種通用的程序設計語言。1991年,python發布了第一個公開發行版。
3. python特點
3.1 高級
語言的升級:匯編語言→C→C++\Java等現代編譯語言→可以進行系統調用的解釋性腳本語言,perl、python等。
這些語言都有高級的數據結構:
- 比如python有列表(數組)和字典(哈希表)內建于語言本身。
- C中,混雜數組(python中的列表)和哈希表(python中的字典)沒有標準庫,需要重復實現。
- C++使用標準模板庫改善了這一情況,但還是很難與python的列表和字典的簡潔和易讀相提并論的。
3.2 面向對象
python的面向對象特性是與生俱來的。python不僅是一門面向對象語言,它融合了多種編程風格,比如借鑒了像Lisp這樣的函數語言的特性。
3.3 可升級
Python 提倡簡潔的代碼設計、高級的 數據結構和模塊化的組件,這些特點可以讓你在提升項目的范圍和規模的同時,確保靈活性、 一致性并縮短必要的調試時間。
我們試圖用“可升級”來傳達一種觀 念,這就是:Python 提供了基本的開發模塊,你可以在它上面開發你的軟件,而且當這些需要擴展和增長時,Python 的可插入性和模塊化架構則能使你的項目生機盎然和易于管理
3.4 可移植性
在各種不同的系統上可以看到 Python。
因為 Python 是用 C 寫的,又由于 C 的可移植性,使得 Python 可以運行 在任何帶有 ANSI C 編譯器的平臺上。
盡管有一些針對不同平臺開發的特有模塊,但是在任何一個平臺上用 Python 開發的通用軟件都可以稍事修改或者原封不動的在其他平臺上運行。這種可移植性既適用于不同的架構,也適用于不同的操作系統。
3.5 可擴展
就算項目中有大量的 Python 代碼,也可以有條不紊地通過將其分離為多個文件或模塊加以組織管理。而且你可以從一個模塊中選取代碼,而從另一個模塊中讀取屬性。
對于所有模塊,Python 的訪問語法都是相同的。不管這個模塊是標準庫的還是自己創建的,哪怕是用其他語言寫的擴展。
代碼中的瓶頸,可能是在性能分析中總排在前面的那些熱門或者一些特別強調性能的地方, 可以作為 Python 擴展用 C 重寫。很多時候,使用編譯型代碼重寫程序的瓶頸部分絕對是益處多多的,因為它能明顯提升整體性能。
程序設計語言中的這種可擴展性使得工程師能夠靈活附加或定制工具,縮短開發周期。
此外,還有像 PyRex 這樣的工具,允許 C 和 Python 混合編程,使編寫擴展更加輕而易舉,因為它會把所有的代碼都轉換成 C 語言代碼。
- Python 的標準實現是使用 C 語言完成的(也就是 CPython),所以要使用 C 和 C++ 編寫 Python 擴展。
- Python 的 Java 實現被稱作 Jython,要使用 Java 編寫其擴展。
- IronPython,這是針對 .NET 或 Mono 平臺的 C# 實現。可以使用 C# 或者 VB.Net 擴展 IronPython。
3.6 易學
Python 關鍵字少、結構簡單、語法清晰。
可能感覺比較新鮮的東西可能就是 Python 的面向對象特點了。
3.7 易讀
python沒有其他語言通常用來訪問變量、定義代碼塊和進行模式匹配的命令式符號。
Python 沒有給你多少機會使你能夠寫出晦澀難懂的代碼,而是讓其 他人很快就能理解你寫的代碼,反之亦然。
3.8 易維護
Python 項目的成功很大程度上要歸功于其源代碼的易于維護。得出這個結論并不難,因為 Python 本身就是易于學習和閱讀的。
3.9 健壯性
python允許程序員在錯誤發生的時候根據出錯條件提供處理機制。
一旦程序由于錯誤崩潰,解釋程序就會轉出一個“堆棧跟蹤”,那里面有可用到的全部信息,包括你程序崩潰的原因以及那段代碼(文件名、行數、行數調用等等)出錯了。這些錯誤被稱為異常。如果在運行時發生這樣的錯誤,Python 使你能夠監控這些錯誤并進行處理。
這些異常處理可以采取相應的措施,例如解決問題、重定向程序流、執行清除或維護步驟、 正常關閉應用程序、亦或干脆忽略掉。
3.10 高效的快速原型開發工具
與那些封閉僵化的語言不同,Python 有許多面向其他系統的接口,它的功能足夠強大和強壯,所以完全可以使用 Python 開發整個系統的原型。
顯然, 傳統的編譯型語言也能實現同樣的系統建模,但是 Python 工程方面的簡潔性可以在同樣的時間內游刃有余的完成相同的工作。
此外,大家已經為 Python 開發了為數眾多的擴展庫,無論你打算開發什么樣的應用程序,都可能找到先行的前輩。你所要做的全部事情,就是來 個“即插即用”!
3.11 內存管理器
C 或者 C++最大的弊病在于內存管理是由開發者負責的。
Python 中,由于內存管理是由 Python 解釋器負責的,所以開發人員就可以從內存事務中解放出來,全神貫注于最直接的目標,僅僅致力于開發計劃中首要的應用程序。這會使錯誤更少、程序更健壯、開發周期更短。
3.12 解釋器和(字節)變異性
Python 是一種解釋型語言,這意味著開發過程中沒有了編譯這個環節。
由于不是以本地機器碼運行,純粹的解釋型語言通常比編譯型語言運行的慢。
然而,類似于 Java,Python 實際上是字節編譯的,其結果就是可以生成一種近似機器語言的中間形式。這不僅改善了 Python 的性能,還同時使它保持了解釋型語言的優點。
Python 源文件通常用.py 擴展名。當源文件被解釋器加載或者顯式地進行字節碼編譯的時候會被編譯成字節碼。由于調用解釋器的方式不同,源文件會被編譯成帶有.pyc 或.pyo 擴展名的文件。
4. 下載和安裝python
得到所有 Python 相關軟件:去訪問它的網站(http://python.org)
Python 的可應用平臺非常廣泛。可以將其劃分成如下的幾大類和可用平臺:
- 所有 Unix 衍生系統(Linux,MacOS X,Solaris,FreeBSD 等等)
- Win32 家族(Windows NT,2000,XP 等等)
- 早期平臺:MacOS 8/9,Windows 3.x,DOS,OS/2,AIX
- 掌上平臺(掌上電腦/移動電話):Nokia Series 60/SymbianOS,Windows CE/PocketPC,Sharp Zaurus/arm-linux,PalmOS
- 游戲控制臺:Sony PS2,PSP,Nintendo GameCube
- 實時平臺:VxWorks,QNX
- 其他實現版本:Jython,IronPython,stackless
- 其他
一些平臺有其對應二進制版本, 可以直接安裝,另外一些則需要在安裝前手工編譯。
Unix 衍生系統(Linux,MacOS X,Solaris,FreeBSD 等等)
基于 Unix 的系統可能已經安裝了 Python。通過命令行運行 Python,查看它是否在搜索路徑中而且運行正常。
Windows/DOS 系統
首先從前文提到的 python.org 網站下載 msi 文件(例如,python-2.5.msi),之后執行該文件安裝 Python。
如果打算開發 Win32 程序,例如使用 COM 或 MFC,或需要 Win32 庫,強烈建議下載并安裝 Python 的 Windows 擴展。
之后就可以通過 DOS 命令行窗口或者 IDLE 和 Pythonwin 中的一個來運行 Python 了,IDLE 是 Python 缺省的 IDE(Integrated Development Environment,集成開發環境),而 Pythonwin 則來自 Windows 擴展模塊。
自己動手編譯 Python
對絕大多數其它平臺 , 下載 .tgz 文件, 解壓縮這些文件, 執行以下操作以編譯Python:
1. ./configure
2. make
3. make install
關于安裝位置
如今,在系統上安裝多種版本的 Python 比較常見。要設置好庫文件的安裝位置。
- Unix 中,可執行文件通常會將 Python 安裝到/usr/local/bin 子目錄下,而庫文件則通常安裝在/usr/local/lib/python2.x 子目錄下,其中的 2.x 是你正在使用的版本號。
- MacOS X 系統中,Python 則安裝在/sw/bin 以及/或者 /usr/local/bin 子目錄下。而庫文件則在/sw/lib,/usr/local/lib, 以及/或者 /Library/Frameworks/Python.framework/Versions子 目錄下。
- Windows 中,默認的安裝地址是 C:\Python2x。請避免將其安裝在 C:\Program Files 目錄下(雖然這是通常安裝程序的文件夾)。DOS 是不支持“Program Files” 這樣的長文件名的,它通常會被用“Progra~1”這個別名代替。這有可能給程序運行帶來一些麻煩。所以,將 Python 安裝在 C:\Python 目錄下,這樣標準庫文件就會被安裝在 C:\Python\Lib 目錄下。
5. 運行python
有三種不同的辦法來啟動 Python:
- 最簡單的方式就是交互式的啟動解釋器,每次輸入一行Python 代碼來執行。
- 另外一種啟動 Python 的方法是運行 Python 腳本。這樣會調用相關的腳本解釋器。
- 最后一種辦法就是用集成開發環境中的圖形用戶界面運行 Python。集成開發環境通常整合了其他的工具,例如集成的調試器、文本編輯器,而且支持各種像 CVS 這樣的源代碼版本控制工具。
5.1 命令行上的交互式解釋器
在命令行上啟動解釋器,你馬上就可以開始編寫 Python 代碼。
-
Unix 衍生系統(Linux,MacOS X,Solaris,FreeBSD 等等)
1.1 將 Python 所在路徑添加到系統搜索路徑之中就可以直接輸入python啟動python, 否則就必須輸入Python的完整路徑名才可以啟動Python。Python一般安裝在 /usr/bin 或/usr/local/bin子目錄中。
1.2 如何將 Python 添加到搜索路徑中:檢查登錄啟動腳本, 找到以 set path 或 PATH= 指令開始,后面跟著一串目錄的那行, 然后添加解釋器的完整路徑。更新一下 shell 路徑變量。 -
Windoes/DOS 環境
2.1 如何將 Python 添加到搜索路徑中:編輯 C:\autoexec.bat 文件并將完整的 Python 安裝路徑添加其中,一般是 C:\Python 或 C:\Program Files\Python(或者它在 DOS 中的簡寫 名字 C:\Progra~1\Python)。然后直接輸入python就可以啟動python
5.2 從命令行啟動腳本
《Unix 衍生系統(Linux,MacOS X,Solaris,FreeBSD 等等)》
- 不管哪種 Unix 平臺, Python 腳本都可以象下面這樣,在命令行上通過解釋器執行:
$ python script.py
- Unix 平臺還可以在指定 Python 解釋器的情況下,自動執行 Python 解釋器。如果你使用的是類 Unix 平臺, 可以 在腳本的第一行使用 shell 魔術字符串(“sh-bang”) ,在 #!之后寫上 Python 解釋器的完整路徑:
#!/usr/local/bin/python
- 有一個更好的方案, 許多 Unix 系統有一個命令叫 env, 位于 /bin 或 /usr/bin 中。它會幫你在系統搜索路徑中找到 python 解釋器。如果你的系統擁有 env, 你的啟動行就可以改為下面這樣
#!/usr/bin/env python
或者, 如果你的 env 位于 /bin 的話,
#!/bin/env python
當你不能確定 Python 的具體路徑或者 Python 的路徑經常變化時(但不能挪到系統搜索路徑之外), env 就非常有用。
在腳本首行書寫了合適的啟動指令之后, 這個腳本就能夠直接執行。當調用腳本時, 會先載入 Python 解釋器, 然后運行腳本:
script.py
注意, 在鍵入文件名之前, 必須先將這個文件的屬性設置為可以執行。在文件列表中, 你的文件應該將它設置為自己擁有 rwx 權限。
《Windows/DOS 環境》
DOS 命令窗口不支持自動執行機制,不過至少在 WinXP 當中, 它能象在 Windows 中一樣 做到通過輸入文件名執行腳本: 這就是“文件類型”接口。這個接口允許 Windows 根據文件擴 展名識別文件類型, 從而調用相應的程序來處理這個文件。舉例來說, 如果你安裝了帶有 PythonWin 的 Python, 雙擊一個帶有 .py 擴展名的 Python 腳本就會自動調用 Python 或 PythonWin IDE(如果你安裝了的話)來執行你的腳本。 運行以下命令就和雙擊它的效果一樣:
C:\> script.py
這樣無論是基于 Unix 操作系統還是 Win32 操作系統都可以無需在命令行指定 Python 解釋器的情況下運行腳本,但是如果調用腳本時,得到類似“命令無法識別”之類的錯誤提示 信息,你也總能正確處理。
5.3 集成開發環境
TODO
5.4 其它的集成開發環境和執行環境
TODO
6. python文檔
- 最便捷的方式就是從 Python 網站查看在線文檔。
- 如果使用的是 Win32 系統,在 C:\Python2x\Doc\目錄下會找到一個名為 Python2x.chm 的離線幫助文檔。其他的離線文檔包括 PDF 和 PostScript (PS)文件。
- 如果下載了 Python 發行版,你會得到 LaTeX 格式的源文件。
- 在本書的網站中,創建了一個包括絕大多數 Python 版本的文檔,只要訪問 http://corepython.com,單擊左側的“Documentation”就可以了。《都是英文的,可以找找對應的中文文檔》
![image]()

7. 比較python
TODO
8. 其他實現
TODO
第二章 python起步
命令行輸入python會看到 Python 的主提示符( >>> )和次提示符( ... )。主提示符是解釋器告訴你它在等待你輸入下一個語句,次提示符告訴你解釋器正在等待你輸入當前語句的其它部分。
[chengqianli@sandbox-test ~]$ python3
Python 3.9.0 (default, Apr 23 2024, 20:29:01)
[GCC 10.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> for i in range(0, 10):
... print(i)
...
0
1
2
3
4
5
6
7
8
9
Python 有兩種主要的方式來完成你的要求:
- 語句:語句使用關鍵字來組成命令,類似告訴解釋器一個命令。你告訴 Python 做什么,它就為你做什么,語句可以有輸出,也可以沒有輸出。eg:print 'Hello World!'
- 表達式(函數、算術表達式等):表達式沒有關鍵字。它們可以是使用數學運算符構成的算術表達式,也可以是使用括號調用的函數。它們可以接受用戶輸入,也可以不接受用戶輸入,有些會有輸出,有些則沒有。eg:abs(-4)
TODO:使用括號調用的函數,這個和語句有什么區別?
2.1 程序輸出,print語句及“HelloWorld!”
在交互式解釋器中, 用 print 語句顯示變量的字符串表示,或者僅使用變量名查看該變量的原始值。
eg:
>>> myString = 'Hello World!'
>>> print myString
Hello World! # 在僅用變量名時,輸出的字符串是被用單引號括起來了的。這是為了讓非字符串對象也能以字符串的方式顯示在屏幕上--即它顯示的是該對象的字符串表示,而不僅僅是字符串本身
>>> myString
'Hello World!' # 引號表示你剛剛輸入的變量的值是一個字符串
等你對 Python 有了較深入的了解之后, 你就知道 print 語句調用 str()函數顯示對象,而交互式解釋器則調用 repr()函數來顯示對象。
TODO:這里沒明白
2.2 程序輸入和 raw_input()內建函數
下劃線(_)在解釋器中表示最后一個表達式的值。上面的代碼執行之后, 下劃線變量會包含字符串:
>>> _
Hello World!
Python的print語句,與字符串格式運算符( %)結合使用,可實現字符串替換功能
>>> print "%s is number %d!" % ("Python", 1)
Python is number 1!
- %s 表示由一個字符串來替換,而%d 表示由一個整數來替換,另外一個很常用的就是%f, 它 表示由一個浮點數來替換。
- Python 非常靈活,所以即使 你將數字傳遞給 %s,也不會像其他要求嚴格的語言一樣引發嚴重后果。
Print 語句也支持將輸出重定向到文件。符號 >> 用來重定向輸出,下面例子將輸出重定向到標準錯誤輸出:
import sys
print >> sys.stderr, 'Fatal error: invalid input!'
# 下面是一個將輸出重定向到日志文件的例子:
logfile = open('/tmp/mylog.txt', 'a')
print >> logfile, 'Fatal error: invalid input!'
logfile.close()
從用戶得到數據輸入的方法是使用 raw_input()內建函數。它讀取標準輸入,并將讀取到的數據賦值給指定的變量。 可以使用 int() 內建函數將用戶輸入的字符串轉換為整數。
# 文本輸入
>>> user = raw_input('Enter login name: ')
Enter login name: root
# 數字輸入
>> num = raw_input('Now enter a number: ')
Now enter a number: 1024
>>> print 'Doubling your number: %d' % (int(num) * 2)
Doubling your number: 2048
如果需要得到一個生疏函數的幫助,只需要對它調用內建函數help()。通過用函數名作為 help()的參數就能得到相應的幫助信息。
>>> help(raw_input)
Help on built-in function raw_input in module __builtin__:
raw_input(...) raw_input([prompt]) -> string
核心風格: 一直在函數外做用戶交互操作
新手在需要顯示信息或得到用戶輸入時, 很容易使用 print 語句和 raw_input()內建函數。不過建議函數應該保持其清晰性, 也就是它只應該接受參數,返回結果。從用戶那里得到需要的數據, 然后調用函數處理, 從函數得到返回值,然后顯示結果給用戶。 這樣你就能夠在其它地方也可以使用你的函數而不必擔心自定義輸出的問題。這個規則的一個例外是,如果函數的基本功能就是為了得到用戶輸出, 或者就是為了輸出信息,這時在函數體使用 print 語句或raw_input() 也未嘗不可。
更重要的,將函數分為兩大類:
- 一類只做事,不需要返回值(比如與用戶交互或設置變量的值),
- 另一類則執行一些運算,最后返回結果。
如果輸出就是函數的目的,那么在函數體內使用 print 語句也是可以接受的選擇。
2.3 注釋
- Python 使用 # 符號標示注釋;
- 有一種叫做文檔字符串的特別注釋。可以在模塊、類或者函數的起始添加一個字符串,起到在線文檔的功能;與普通注釋不同,文檔字符串可以在運行時訪問,也可以用來自動生成文檔;
def foo():
"This is a doc string."
return True
2.4 運算符
標準算術運算符
+ - * / // % **
Python 有兩種除法運算符,單斜杠用作傳統除法, 雙斜杠用作浮點除法(對結果進行四舍五入)。
- 單斜杠:傳統除法是指如果兩個操作數都是整數的話, 它將執行是地板除(取比商小的最大整數);
- 雙斜杠:浮點除法是真正的除法,不管操作數是什么類型,浮點除法總是執行真正的除法;
運算符優先級:+ 和 - 優先級最低, *, /, //,%優先級較高, 單目運算符 + 和 - 優先級更高, 乘方的優先級最高。
標準比較運算符
比較運算根據表達式的值的真假返回布爾值:
< <= > >= == != <>
Python 支持兩種“不等于”比較運算符, != 和 <> , 分別是 C 風格和 ABC/Pascal 風格。后者慢慢地被淘汰了。
邏輯運算符
and or not
使用邏輯運算符可以將任意表達式連接在一起,并得到一個布爾值。
>>> 3 < 4 < 5
True
# 這個例子在其他語言中通常是不合法的,不過 Python 支持這樣的表達式, 既簡潔又優美。
核心風格: 合理使用括號增強代碼的可讀性,在沒用括號的話,會使程序得到錯誤結果,或使代碼可讀性降低,引起閱讀者困惑。
2.5 變量和賦值
變量名命名規則:
- 字母開頭的標識符--意指大寫或小寫字母,其它的字符可以是數字,字母, 或下劃線。
- Python 變量名是大小寫敏感的, 也就是說變量 "cAsE" 與 "CaSe" 是兩個不同的變量。
Python 是動態類型語言,不需要預先聲明變量的類型。 變量的類型和值在賦值那一刻被初始化。變量賦值通過=來執行。
Python 也支持增量賦值,也就是運算符和等號合并在一起。
n = n * 10
等同于
n *= 10
Python 不支持 C 語言中的自增 1 和自減 1 運算符, 這是因為 + 和 - 也是單目運算符, Python 會將 --n 解釋為-(-n) 從而得到 n , 同樣 ++n 的結果也是 n.
2.6 數字
Python 支持五種基本數字類型,其中有三種是整數類型:
- int (有符號整數)
- long (長整數)
- bool (布爾值)
- float (浮點值)
- complex (復數)
- Python 的長整數所能表達的范圍遠遠超過 C 語言的長整數, Python 長整數僅受限于用戶計算機的虛擬內存總數。
- 從 Python2.3 開始,再也不會報整型溢出錯誤, 結果會自動的被轉換為長整數。
- 盡管布爾值由常量 True 和 False 來表示, 若將布爾值放到一個數值上下文環境中(比方將 True 與一個數字相加), True 會被當成整數值 1, 而 False 則會被當成整數值 0。
- 復數(包括-1 的平方根, 即所謂的虛數)在其它語言中通常不被直接支持(一般通過類來實現)。
- decimal, 用于十進制浮點數。不過它并不是內建類型,須先導入 decimal 模塊才可以使用這種數值類型。
由于需求日漸強烈, Python 2.4 增加 了這種類型。舉例來說,由于在二進制表示中有一個無限循環片段,數字 1.1 無法用二進制浮 點數精確表示。因此, 數字 1.1 實際上會被表示成:
>>> 1.1
1.1000000000000001
>>> print decimal.Decimal('1.1')
1.1
2.7 字符串
- Python 支持使用成對的單引號或雙引號, 三引號(三個連續的單引號或者雙引號)可以用來包含特殊字符。
- 使用索引運算符( [ ] )和切 片運算符( [ : ] )可以得到子字符串。
- 字符串有其特有的索引規則:第一個字符的索引是 0, 最后一個字符的索引是 -1。
- 加號( + )用于字符串連接運算。
- 星號( * )則用于字符串重復。
>>> pystr = 'Python'
>>> pystr[0]
'P'
>>> pystr[2:5]
'tho'
>>> pystr + iscool
'Pythonis cool!'
>>> pystr * 2
'PythonPython'
2.8 列表和元組
可以將列表和元組當成普通的“數組”,它能保存任意數量任意類型的 Python 對象。通過從 0 開始的數字索引訪問元素,但是列表和元組可以存儲不同類型的對象。
列表和元組有幾處重要的區別:
- 列表元素用中括號( [ ])包裹,元素的個數及元素的值可以改變。
- 元組元素用小括號(( ))包裹,不可以更改(盡管他們的內容可以)。元組可以看成是只讀的列表。
通過切片運算( [ ] 和 [ : ] )可以得到子集。
2.9 字典
字典是 Python 中的映射數據類型,工作原理類似 Perl 中的關聯數組或者哈希表,由鍵- 值(key-value)對構成。
- 幾乎所有類型的 Python 對象都可以用作鍵,不過一般還是以數字或者 字符串最為常用。
- 值可以是任意類型的 Python 對象,字典元素用大括號({ })包裹。
>> aDict = {'host': 'earth'} # create dict
>>> aDict['port'] = 80 # add to dict
>>> aDict
{'host': 'earth', 'port': 80}
>>> aDict.keys()
['host', 'port']
>>> aDict['host']
'earth'
>>> for key in aDict:
... print key, aDict[key] ...
2.10 代碼塊及縮進對齊
代碼塊通過縮進對齊表達代碼邏輯而不是使用大括號,因為沒有了額外的字符,程序的可讀性更高。
2.11 if語句
標準 if 條件語句的語法如下:
if expression:
if_suite
else:
else_suite
如果表達式的值非 0 或者為布爾值 True, 則代碼組 if_suite 被執行; 否則就去執行else_suit。
elif (意指 “else-if ”)語句,語法如下:
if expression1:
if_suite
elif expression2:
elif_suite
else:
else_suite
2.12 while 循環
語句 while_suite 會被連續不斷的循環執行, 直到表達式的值變成 0 或 False; 接著 Python 會執行下一句代碼。
while expression:
while_suite
2.13 for循環和range()內建函數
Python 中的 for 循環與傳統的 for 循環(計數器循環)不太一樣,Python 中的 for 接受可迭代對象(例如序列或迭代器)作為其參數,每次 迭代其中一個元素。
>> for item in ['e-mail', 'net-surfing', 'homework',
'chat']:
... print item
...
e-mail
net-surfing
homework
chat
- print 語句默認會給每一行添加一個換行符。只要在 print 語句的最后添加一個逗號(,), 就可以改變它這種行為
- 一個額外的沒有任何參數的 print 語句, 它用來輸出一個換行符
- 逗號的 print 語句輸出的元素之間會自動添加一個空格.
>>> print()
>>> print("abc", "efg", "hij")
abc efg hij
>>>
Python 提供了一個 range()內建函數來生成列表.
>>> for eachNum in range(3):
... print eachNum
...
0
1
2
字符串迭代
>> foo = 'abc'
>>> for c in foo:
... print c
...
a
b
c
# range()函數經常和 len()函數一起用于字符串索引。 在這里我們要顯示每一個元素及其索引值:
>>> foo = 'abc'
>>> for i in range(len(foo)):
... print foo[i], '(%d)' % i
...
a (0)
b (1)
c (2)
# enumerate() 函數可以同時循環索引和元素
>>> for i, ch in enumerate(foo):
... print ch, '(%d)' % i
...
a (0)
b (1)
c (2)
2.13 列表解析
可以在一行中使用一個 for 循環將所有值放到一個列表當中:
> squared = [x ** 2 for x in range(4)] >>> for i in squared:
... print i
0
1
4
9
列表解析甚至能做更復雜的事情, 比如挑選出符合要求的值放入列表:
>>> sqdEvens = [x ** 2 for x in range(8) if not x % 2]
>>>
>>> for i in sqdEvens:
... print i
0
4
16
36
2.15 文件和內建函數open()、file()
如何打開文件
handle = open(file_name, access_mode = 'r')
- access_mode 中 'r' 表示讀取, 'w' 表示寫入, 'a' 表示添加。其他:'+' 表示讀寫, 'b'表示二進制訪 問。如果未提供 access_mode , 默認值為 'r'。
- 如果 open() 成功, 一個文件對象句柄會被返回。所有后續的文件操作都必須通過此文件句柄進行。當一個文件對象返回之后, 就可以訪問它的一些方法, 比如 readlines() 和 close().
filename = raw_input('Enter file name: ')
fobj = open(filename, 'r')
for eachLine in fobj:
print eachLine,
fobj.close()
代碼沒有用循環一次取一行顯示。而是一次讀入文件的所有行, 然后關閉文件, 再迭代每一行輸出。這樣的好處是快速完整的訪問文件,這樣代碼更清晰。
需要注意的是文件的大小。 上面的代碼適用于文件大小適中的文件。對于很大的文件來說, 上面的代碼會占用太多的內存, 這時最好一次讀一行。
代碼在 print 語句中使用逗號來抑制自動生成的換行符號, 因為文件中的每行文本已經自帶了換行字符。
file()內建函數是最近才添加到 Python 當中的。它的功能等同于 open(), 不過 file() 這個名字可以更確切的表明它是一個工廠函數。(生成文件對象)類似 int()生成整數對象,dict()生成字典對象。
2.16 錯誤和異常
Python 允許在程序運行時檢測錯誤。當檢測到一個錯誤, Python 解釋器就引發一個異常, 并顯示異常的詳細信息。可以根據這些信息迅速定位問題并進行調試, 并找出處理錯誤的辦法。
要給代碼添加錯誤檢測及異常處理, 只要將它們封裝在 try-except 語句當中。 try 之后的代碼組, 就是要管理的代碼。 except 之后的代碼組, 則是處理錯誤的代碼。
try:
filename = raw_input('Enter file name: ')
fobj = open(filename, 'r')
for eachLine in fobj:
print eachLine, fobj.close()
except IOError, e:
print 'file open error:', e
程序員也可以通過使用 raise 語句故意引發一個異常。
2.17 函數
Python 中的函數使用小括號( () )調用。函數在調用之前必須先定義。 如果函數中沒有 return 語句, 就會自動返回 None 對象。
Python 是通過引用調用的。 這意味著函數內對參數的改變會影響到原始對象。不過事實上只有可變對象會受此影響, 對不可變對象來說, 它的行為類似按值調用。
如何定義函數
def function_name([arguments]):
"optional documentation string"
function_suite # 函數體的代碼組
如何調用函數
def addMe2Me(x):
'apply + operation to argument'
return (x + x)
>>> addMe2Me(4.25)
8.5
>>>
>>> addMe2Me(10)
20
>>>
>>> addMe2Me('Python')
'PythonPython'
>>>
>>> addMe2Me([-1, 'abc'])
[-1, 'abc', -1, 'abc']
注意一下, + 運 算符在非數值類型中如何工作。
默認參數
函數的參數可以有一個默認值, 如果提供有默認值,在函數定義中, 參數以賦值語句的形式提供。事實上這僅僅是提供默認參數的語法,它表示函數調用時如果沒有提供這個參數,它就取這個值做為默認值。
>>> def foo(debug=True):
... 'determine if in debug mode with default argument'
... if debug:
... print 'in debug mode'
... print 'done'
...
>>> foo()
in debug mode
done
>>> foo(False)
done
如果沒有傳遞參數給函數 foo(), debug 自動拿到一個值, True. 在第二次調用 foo()時, 傳遞一個參數 False 給 foo(),默認參數就沒有被使用。
2.18 類
類是面向對象編程的核心, 它扮演相關數據及邏輯的容器角色。它們提供了創建“真實” 對象(也就是實例)的藍圖。
如何定義類
class ClassName(base_class[es]):
"optional documentation string"
static_member_declarations
method_declarations
使用 class 關鍵字定義類。可以提供一個可選的父類或者說基類; 如果沒有合適的基類,那就使用 object 作為基類。
class FooClass(object):
"""my very first class: FooClass"""
version = 0.1 # class (data) attribute
def __init__(self, nm='John Doe'):
"""constructor"""
self.name = nm # class instance (data) attribute
print 'Created a class instance for', nm
def showname(self):
"""display instance attribute and class name""" print 'Your name is', self.name
print 'My name is', self.__class__.__name__
def showver(self):
"""display class(static) attribute"""
print self.version # references FooClass.version def addMe2Me(self, x): # does not use 'self' """apply + operation to argument"""
return x + x
def addMe2Me(self, x): # does not use 'self' """apply + operation to argument"""
return x + x
該類定義了一個靜態變量 version, 它將被所有實例及四個方法共享. _init_()方法是一個特殊名字, 所有名字開始和結束都有兩個下劃線的方法都是特殊方法。
當一個類實例被創建時, _init_()方法會自動執行, 在類實例創建完畢后執行, 類似構建函數。_init_()可以被當成構建函數, 不過不象其它語言中的構建函數, 它并不創建實例--它僅僅是對象創建后執行的第一個方法。它的目的是執行一些該對象的必要的初 始化工作。通過創建自己的 _init_()方法覆蓋默認的_init_()方法(默認的方法什么也不做),從而能夠修飾剛剛創建的對象。這個例子初始化了一個名為 name 的類實例屬性(或者說成員)。這個變量僅在類實例中存在, 它并不是實際類本身的一部分。_init_()需要一個默認的參數。你也注意到每個方法都有 的一個參數, self。
什么是 self ? 它是類實例自身的引用。其他語言通常使用一個名為 this 的標識符。
如何創建類
>>> foo1 = FooClass()
Created a class instance for John Doe
>>> foo1.showname() Your name is John Doe
My name is __main__.FooClass
>>>
>>> foo1.showver()
0.1
>>> print foo1.addMe2Me(5)
10
>>> print foo1.addMe2Me('xyz')
屏幕上顯示的字符串正是自動調用 __init__() 方法的結果。
在 showname()方法中,顯示 self._class_._name_ 變量的值。對一個實例來說, 這個變量表示實例化它的 類的名字。(self.__class__引用實際的類)。
2.19 模塊
模塊是一種組織形式, 它將彼此有關系的 Python 代碼組織到一個個獨立文件當中。模塊的名字就是不帶 .py 后綴的文件名。一個模塊創建之后, 你可以從另一個模塊中使用 import 語句導入這個模塊來使用。
# 導入模塊
import module_name
# 一旦導入完成, 一個模塊的屬性(函數和變量)可以通過句點訪問。
module.function()
module.variable
# 舉例
>>> import sys
>>> sys.stdout.write('Hello World!\n')
Hello World!
>>> sys.platform
'win32'
>>> sys.version
'2.4.2 (#67, Sep 28 2005, 10:51:12) [MSC v.1310 32 bit
(Intel)]'
代碼的輸出與 print 語句完全相同。 唯一的區別在于這次調用了標準輸出 的 write()方法,而且需要顯式的在字符串中提供換行字符,write() 不會自動在字符串后面添加換行符號。
核心筆記:什么是“PEP”?
一個 PEP 就是一個 Python 增強提案(PythonEnhancement Proposal), 這也是在新版 Python 中增加新特性的方式。 它們不但提供了新特性的完整描述, 還有添加這些新特性的理由, 如果需要的話, 還會提供新的語法、 技術實現細節、向后兼容信息等等。在一個新特性被整合進 Python 之前,必須通過 Python 開發社區,PEP 作者及實現者,還有 Python 的創始人,Guido van Rossum(Python 終身的仁慈的獨裁者)的一致同意。PEP1 闡述了 PEP 的目標及書寫指南。 在 PEP0 中可以找到所有的 PEP。 PEP 索引的網址是: http://python.org/dev/peps.
2.19 實用的函數
本章實用的內建函數
表 2.1 對新 Python 程序員有用的內建函數
函數 描述
dir([obj]) 顯示對象的屬性,如果沒有提供參數, 則顯示全局變量的名字
help([obj]) 以一種整齊美觀的形式 顯示對象的文檔字符串, 如果沒有提供任何參 數, 則會進入交互式幫助。
int(obj) 將一個對象轉換為整數
len(obj) 返回對象的長度
open(fn, mode) 以 mode('r' = 讀, 'w'= 寫)方式打開一個文件名為 fn 的文件
range([[start,]stop[,step]) 返回一個整數列表。起始值為 start, 結束值為 stop - 1; start 默認值為 0, step默認值為1。
raw_input(str) 等待用戶輸入一個字符串, 可以提供一個可選的參數 str 用作提示信 息。
str(obj) 將一個對象轉換為字符串
type(obj) 返回對象的類型(返回值本身是一個 type 對象!
語句和語法
變量賦值
標識符和關鍵字
基本風格指南
內存管理
第一個 Python 程序
第三章
3.1 語句和語法
Python 語句中有一些基本規則和特殊字符:
- 井號(#)表示之后的字符為 Python 注釋
- 換行 (\n) 是標準的行分隔符(通常一個語句一行)
- 反斜線 ( \ ) 繼續上一行
- 分號 ( ; )將兩個語句連接在一行中
- 冒號 ( : ) 將代碼塊的頭和體分開
- 語句(代碼塊)用縮進塊的方式體現
- 不同的縮進深度分隔不同的代碼塊
- Python文件以模塊的形式組織
3.1.1 注釋( # )
注釋語句從 # 字符開始,注釋可以在一行的任何地方開始,解釋器會忽略掉該行 # 之后的所有內容。
3.1.2 繼續( \ )
一行過長的語句可以使用反斜杠( \ ) 分解成幾行,如下例:
# check conditions
if (weather_is_hot == 1) and \
(shark_warnings == 0):
send_goto_beach_mesg_to_pager()
有兩種例外情況一個語句不使用反斜線也可以跨行。
- 在使用閉合操作符時,單一語句可以跨多行,例如:在含有小括號、中括號、花括號時可以多行書寫。
- 三引號包括下的字符串也可以跨行書寫。
# display a string with triple quotes
print'''hi there, this is a long message for you
that goes over multiple lines... you will find
out soon that triple quotes in Python allows
this kind of fun! it is like a day on the beach!'''
# set some variables
go_surf, get_a_tan_while, boat_size, toll_money = (1,'windsurfing', 40.0, -2.00)
如果要在使用反斜線換行和使用括號元素換行作一個選擇,推薦使用括號,這樣可讀 性會更好。
3.1.3 多個語句構成代碼組
縮進相同的一組語句構成一個代碼塊,我們稱之代碼組。像 if、while、def 和 class 這樣 的復合語句,首行以關鍵字開始,以冒號( : )結束,該行之后的一行或多行代碼構成代碼組。 我們將首行及后面的代碼組稱為一個子句(clause)。
3.1.4 代碼組由不同的縮進分隔
代碼的層次關系是通過同樣深度的空格或制表符縮進體現的。同一代碼組的代碼行必須嚴格左對齊(左邊有同樣多的空格或同樣多的制表符),如果不嚴格遵守這個規則,同一組的代碼就可能被當成另一個組,甚至 會導致語法錯誤。
核心風格:縮進四個空格寬度,避免使用制表符
縮進多大寬度才合適?兩個太少,六到八個又太多,推薦使用四個空格寬度。不同的文本編輯器中制表符代表的空白寬度不一,如果你的代碼要跨平臺應用,或者會被不同的編輯器讀寫,建議不要使用制表符。使用空格或制表符這兩種風格都得到了 Python 創始人 Guido van Rossum 的支持,并被收錄到 Python 代碼風格指南文檔。
使用縮進對齊這種方式組織代碼,風格優雅,大大提高了代碼的可讀性。 而且它有效的避免了"懸掛 else"(dangling-else)問題,和未寫大括號的單一子句問題。
3.1.5 同一行書寫多個語句
分號( ; )允許將多個語句寫在同一行上,語句之間用;隔開,而這些語句也不能在這行開始一個新的代碼塊。
import sys; x = 'foo'; sys.stdout.write(x + '\n')
同一行上書寫多個語句會大大降低代碼的可讀性,Python 雖然允許但不提倡你這么做。
3.1.6 模塊
每一個 Python 腳本文件都可以被當成是一個模塊。當一個模塊變得過大,并且驅動了太多功能的話,就應該考慮拆一些代碼出來另外建一個模塊。模塊里的代碼可以是一段直接執行的腳本,也可以是一堆類似庫函數的代碼,從而可以被別的模塊導 入(import)調用。
3.2 變量賦值
賦值運算符
等號(=)是主要的賦值運算符。
anInt = -12
aString = 'cart'
aFloat = -3.1415 * (5.0 ** 2)
anotherString = 'shop' + 'ping'
aList = [3.14e10, '2nd elmt of a list', 8.82-4.371j]
賦值并不是直接將一個值賦給一個變量。Python 語言中,對象是通過引用傳遞的。在賦值時,不管這個對象是新創建的,還 是一個已經存在的,都是將該對象的引用(并不是值)賦值給變量。如果此刻你還不是 100%理解清楚。 在本章的后面部分,我們還會再討論這個話題。
>>> x = 1
>>> y = (x = x + 1) # assignments not expressions! File "<stdin>", line 1
y = (x = x + 1)
^
SyntaxError: invalid syntax
鏈式賦值沒問題
>>> y = x = x + 1
>>> x, y
(2, 2)
增量賦值
+=
-=
*=
/=
%=
**=
<<=>>=
&=
^=
|=
等號可以和一個算術運算符組合在一起, 將計算結果重新賦值給左邊的變量。這被稱為增量賦值。
x=x+1
# 現在可以被寫成:
x += 1
增量賦值相對普通賦值不僅僅是寫法上的改變,最有意義的變化是第一個對象(我們例子中的 A)僅被處理一次。可變對象會被就地修改(無修拷貝引用)。不可變對象則和 A = A +B 的結果一樣(分配一個新對象)
>>> m = 12
>>> m %= 7
>>> m
5
>>> m **= 2
>>> m
25
>>> aList = [123, 'xyz']
>>> aList += [45.6e7]
>>> aList
[123, 'xyz', 456000000.0]
Python 不支持類似 x++ 或 --x 這樣的前置/后置自增/自減運算。
多重賦值
>>> x = y = z = 1
>>> x
1
>>> y
1
>>> z 1
一個值為 1 的整數對象被創建,該對象的同一個引用被賦值給 x、y 和 z 。也就是將一個對象賦給了多個變量。在 Python 當中,將多個對象賦給多個變量也是可以的。
“多元”賦值
采用這種方式賦值時, 等號兩邊的對象都是元組。
>>> x, y, z = 1, 2, 'a string'
>>> x
1
# 通常元組需要用圓括號(小括號)括起來,盡管它們是可選的。建議總是加上圓括號以使代碼有更高的可讀性。
>>> (x, y, z) = (1, 2, 'a string')
在其它類似 C 的語言中, 如果交換兩個值, 使用一個臨時變量比如 tmp 來臨時保存其中一個值:
/* C 語言中兩個變量交換 */ tmp = x;
x = y;
y = tmp;
Python 的多元賦值方式可以實現無需中間變量交換兩個變量的值。
# swapping variables in Python
>>> x, y = 1, 2
>>> x
1
>>> y
2
>>> x, y = y, x
>>> x
2
>>> y
1
顯然, Python 在賦值之前已經事先對 x 和 y 的新值做了計算。
3.3 標識符
標識符是語言中允許作為名字的有效字符串集合。有一部分是關鍵字,構成語言的標識符。這樣的標識符是不能做它用的標識符的,否則會引起語法錯誤(SyntaxError 異常)。
Python 還有稱為 built-in 標識符集合,雖然它們不是保留字,但不推薦使用這些特別的名字(見 3.3.3)。
3.3.1 合法的 Python 標識符
Python 標識符字符串規則和其他大部分用 C 編寫的高級語言相似:
- 第一個字符必須是字母或下劃線(_)
- 剩下的字符可以是字母和數字或下劃線
- 大小寫敏感
3.3.2 關鍵字
Python 的關鍵字列在下表中。任何語言的關鍵字應該保持相對的穩定,但Python 是一門不斷成長和進化的語言,關鍵字列表和 iskeyword()函數都放入了 keyword 模塊以便查閱。
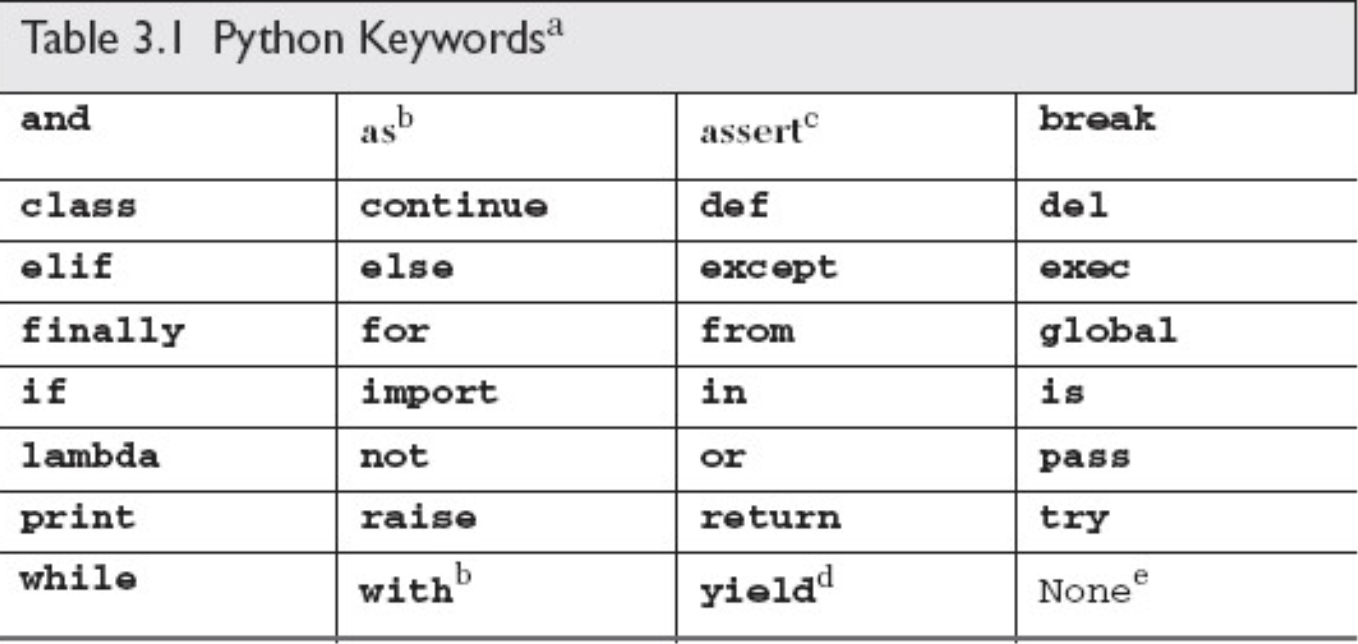
3.3.3 內建
除了關鍵字之外,Python 還有可以在任何一級代碼使用的“內建”的名字集合,這些名字可以由解釋器設置或使用。雖然 built-in 不是關鍵字,但是應該把它當作“系統保留字”,不做他用。然而,有些情況要求覆蓋(也就是:重定義,替換)它們。Python 不支持重載標識符, 所以任何時刻都只有一個名字綁定。
built-in 是__builtins__模塊的成員,在程序開始或在交互解釋器中給出>>>提示之前,由解釋器自動導入的。把它們看成適用在任何一級 Python 代碼的全局變量。
3.3.4 專用下劃線標識符
Python 用下劃線作為變量前綴和后綴指定特殊變量。這里對 Python 中下劃線的特殊用法做了總結:
- _xxx 不用'from module import *'導入
- __xxx__系統定義名字
- __xxx 類中的私有變量名
核心風格:避免用下劃線作為變量名的開始
因為下劃線對解釋器有特殊的意義,而且是內建標識符所使用的符號,建議程序員避免用下劃線作為變量名的開始。一般來講,變量名_xxx 被看作是“私有的”,在模塊或類外不可以使用。當變量是私有的時候,用_xxx 來表示變量是很好的習慣。因為變量名__xxx__對 Python 來說有特殊含義,對于普通的變量應當避免這種命名風格。
3.4 基本風格指南
1)注釋:既不能缺少注釋,也不能過度使用注釋。盡可能使注釋簡潔明了,并放在最合適的地方,并確保注釋的準確性。
2)文檔:通過__doc__特別變量,動態獲得文檔字串。在模塊,類聲明,或函數聲明中第一個沒有賦值的字符串可以用屬性 obj.__doc__來進行訪問,其中 obj 是一個模塊,類,或函數的名字。這在運行時刻也可以運行。
3)縮進:縮進對齊有非常重要的作用,得考慮用什么樣的縮進風格才讓代碼容易閱讀。在選擇要空的格數的時候,常識也起著非常大的作用:
- 1 或 2 可能不夠,很難確定代碼語句屬于哪個塊
- 8 至 10 可能太多,如果代碼內嵌的層次太多,就會使得代碼很難閱讀。
- 4個空格非常的流行。五和六個也不壞,但是文本編輯器通常不支持這樣的設置,所以也不經常使用。三個和七個是邊界情況。
- 當使用制表符 Tab 的時候,請記住不同的文本編輯器對它的設置是不一樣。推薦您不要使用 Tab,如果您的代碼會存在并運行在不同的平臺上,或者會用不同的文本編輯器打開,推薦您不要使用 Tab。
4)選擇標識符名稱:請為變量選擇短而意義豐富的標識符。雖然變量名的長度對于今天的編程語言不再是一個問題,但是使用簡短的名字依然是個好習慣,這個原則同樣使用于模塊(Python 文件)的命名。
5)Python 風格指南:Guido van Rossum 在多年前寫下 Python 代碼風格指南。目前它已經被至少三個 PEP 代替: 7(C 代碼風格指南)、8(Python 代碼風格指南)和 257(文檔字符串規范)。這些 PEP 被歸檔、維護并定期更新。
“Pythonic”這個術語指的是以 Python 的方式去編寫代碼、組織邏輯,及對象行為。PEP 20 寫的是 Python 之禪, 你可以從那里開始你探索“Pythonic”真正含義的旅程。
如果你不能上網,但想看到這篇詩句, Python 解釋器輸入 import this 然后回車。下面是一些網上資源:
www.Python.org/dev/peps/pep-0007/
www.Python.org/dev/peps/pep-0008/
www.Python.org/dev/peps/pep-0020/
www.Python.org/dev/peps/pep-0257/
3.4.1 模塊結構和布局
用模塊來合理組織 Python 代碼是簡單又自然的方法。應該建立一種統一且容易閱讀的結構,并將它應用到每一個文件中去。下面就是一種非常合理的布局:
(1) 起始行(Unix) :Unix 環境下才使用起始行,有起始行就能夠僅輸入腳本名字來執行腳本。
(2) 模塊文檔:簡要介紹模塊的功能及重要全局變量的含義,模塊外可通過 module.doc 訪問這些內容。
(3) 模塊導入 :導入當前模塊的代碼需要的所有模塊;每個模塊僅導入一次(當前模塊被加載時);函數內部的模塊導入代碼不會被執行, 除非該函數正在執行。
(4)變量定義:這里定義的變量為全局變量,本模塊中的所有函數都可直接使用。除非必須,否則就要盡量使用局部變量代替全局變量。這樣做,代碼不但容易維護還可以提高性能并節省內存。
(5)類定義語句:所有的類都需要在這里定義。當模塊被導入時 class 語句會被執行, 類也就會被定義。類的文檔變量是 class.doc。
(6)函數定義語句:此處定義的函數可以通過 module.function()在外部被訪問到,當模塊被導入時 def 語句 會被執行, 函數也就都會定義好,函數的文檔變量是 function.doc。
(7) 主程序:無論這個模塊是被別的模塊導入還是作為腳本直接執行,都會執行這部分代碼。通常這里不會有太多功能性代碼,而且根據執行的模式調用不同的函數。
圖 3–1 一個典型模塊的內部結構圖解。
TODO
3.5 內存管理
本節的主題是變量和內存管理的細節, 包括:
- 變量無須事先聲明
- 變量無須指定類型
- 程序員不用關心內存管理
- 變量名會被“回收”
- del 語句能夠直接釋放資源
3.5.1 變量定義
大多數編譯型語言,變量在使用前必須先聲明:
- 嚴苛的C 語言:變量聲明必須位于代碼塊最開始,且在任何其他語句之前。
- 像 C++和 Java:允許“隨時隨地”聲明變量,不過仍必須在變量被使用前聲明變量的名字和類型。
Python 中,無需此類顯式變量聲明語句,變量在第一次被賦值時自動聲明。和其他大多數語言一樣,變量只有被創建和賦值后才能被使用。
3.5.2 動態類型
不但變量名無需事先聲明,而且也無需類型聲明,對象的類型和內存占用都是運行時確定的。盡管代碼被編譯成字節碼,Python 仍然是一種解釋型語言。在創建--也就是賦值時,解釋器會根據語法和右側的操作數來決定新對象的類型。 在對象創建后,一個該對象的應用會被賦值給左側的變量。
3.5.3 內存分配
在為變量分配內存時,是在借用系統資源,用完之后, 應該釋放借用的系統資源。Python 解釋器承擔了內存管理的復雜任務, 這大大簡化了應用程序的編寫。
3.5.4 引用計數
要保持追蹤內存中的對象, Python 使用了引用計數這一簡單技術。Python 內部記錄著所有使用中的對象各有多少引用。一個內部跟蹤變量,稱為一個引用計數器。至于每個對象各有多少個引用, 簡稱引用計數。當對象被創建時, 就創建了一個引用計數, 當這個對象不再需要時, 也就是說, 這個對象的引用計數變為 0 時, 它被垃圾回收。(嚴格來說這不是 100%正確,不過現階段你可以就這么認為)
增加引用計數
當對象被創建并(將其引用)賦值給變量時,該對象的引用計數就被設置為 1。
當同一個對象(的引用)又被賦值給其它變量時,或作為參數傳遞給函數, 方法或類實例時, 或者被賦值為一個窗口對象的成員時,該對象的一個新的引用,或者稱作別名,就被創建 (則該對象的引用計數自動加 1)。
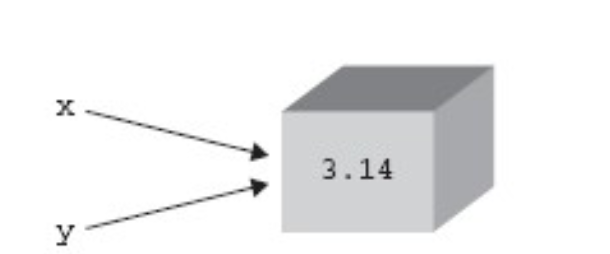
請看以下聲明:
x = 3.14 # x 是第一個引用,該對象的引用計數被設置為 1。
y= x # 語句 y=x 創建了一個指向同一對象的別名 y。事實上并沒有為 Y 創建一個新對象, 而是該對象的引用計數增加了 1 次(變成了2)。這是對象引用計數增加的方式之一。還有一些其它的方式也能增加對象的引用計數,如下總結。
總之,對象的引用計數在
-
對象被創建 ,x = 3.14
-
或另外的別名被創建 ,y= x
-
或被作為參數傳遞給函數(新的本地引用) foobar(x)
-
或成為容器對象的一個元素 myList = [123, x, 'xyz']
減少引用計數
當對象的引用被銷毀時,引用計數會減小。最明顯的例子就是當引用離開其作用范圍時, 這種情況最經常出現在函數運行結束時,所有局部變量都被自動銷毀,對象的引用計數也就隨之減少。
當變量被賦值給另外一個對象時,原對象的引用計數也會自動減 1:
foo = 'xyz' # 當字符串對象"xyz"被創建并賦值給 foo 時, 它的引用計數是 1
bar = foo # 當增加了一個別名 bar 時, 引用計數變成了 2
foo = 123 # foo 被重新賦值給整數對象 123 時, xyz 對象的引用計數自動減 1,又重新變成了 1
其它造成對象的引用計數減少的方式包括使用 del 語句刪除一個變量, 或者當一個對象被移出一個窗口對象時(或該容器對象本身的引用計數變成了 0 時)。總結一下, 一個對象的引用計數在以下情況會減少:
- 一個本地引用離開了其作用范圍。比如 foobar()函數結束時。
- 對象的別名被顯式的銷毀。 del y # or del x
- 對象的一個別名被賦值給其它的對象,x = 123
- 對象被從一個窗口對象中移除 myList.remove(x)
- 窗口對象本身被銷毀 del myList # or goes out-of-scope 參閱 11.8 了解更多變量作用范圍的信息。
del 語句
Del 語句會刪除對象的一個引用,它的語法是: del obj1[, obj2[,... objN]]
例如,在上例中執行 del y
會產生兩個結果: 從現在的名字空間中刪除y & x的引用計數減一
引申一步, 執行 del x 會刪除該對象的最后一個引用, 也就是該對象的引用計數會減為 0, 這會導致該對象從此“無法訪問”或“無法抵達”。 從此刻起, 該對象就成為垃圾回收機制的回收對象。 注意任何追蹤或調試程序會給一個對象增加一個額外的引用, 這會推遲該對象被回收的時間。
3.5.5 垃圾收集
不再被使用的內存會被一種稱為垃圾收集的機制釋放。雖然解釋器跟蹤對象的引用計數, 但垃圾收集器負責釋放內存。垃圾收集器是一塊獨立代碼, 它用來尋找引用計數為 0 的對象。它也負責檢查那些雖然引用計數大于 0 但也應該被銷毀的對象。 特定情形會導致循環引用。
一個循環引用發生在當你有至少兩個對象互相引用時, 也就是說所有的引用都消失時, 這些引用仍然存在, 這說明只靠引用計數是不夠的。Python 的垃圾收集器實際上是一個引用計數器和一個循環垃圾收集器。 當一個對象的引用計數變為 0,解釋器會暫停,釋放掉這個對象和僅有這個對象可訪問(可到達)的其它對象。作為引用計數的補充, 垃圾收集器也會留心被分配的總量很大(及未通過引用計數銷毀的那些)的對象。 在這種情況下, 解釋器會暫停下來, 試圖清理所有未引用的循環。
3.6 第一個Python程序
- makeTextFile.py, 創建一個文本文件。 它提示用戶輸入每一行文本, 然后將結果寫到文件中。
- readTextFile.py 讀取并 顯示該文本文件的內容。
創建文件(makeTextFile.py):用戶輸入一個(尚不存在的)文件名, 然后由用戶輸入該文件的每一行。最后將所有文本寫入文本文件。
#!/usr/bin/env python
'makeTextFile.py -- create text file' # UNIX 啟動行之后是模塊的文檔字符串。
import os
ls = os.linesep # 為 os.linesep 屬性取了一個新別名。一方面縮短變量名,另一方面改善訪問該變量的性能。
while True:
filename = input("please input the file name:")
if os.path.exists(filename):
print("the filename exists, please input another filename")
else:
break
all = []
while True:
entry = input('> ')
if entry == '':
break
all.append(entry + ls) # +ls 為每一行添加行結束符,對 Unix 平臺,是'\n', 對 DOS 或 win32 平臺,則是 '\r\n'。通過使用 os.lineseq,不必關心程序運行在什么平臺,也不必要根據不同的平臺決定使用哪種行結束符。
with open(filename, "w") as f:
f.writelines(all)
#!/usr/bin/env Python
'readTextFile.py -- read and display text file'
import os.path
while True:
filename = input("please input the filename:")
if os.path.exists(filename) is False:
print("the file doesn't exit")
else:
break
try:
fobj = open(filename, "r")
except IOError as e:
print("file open error", str(e))
else:
for each_line in fobj:
print(each_line.strip())
# try-except-else 語句。
# try 子句是一段希望監測錯誤的代碼塊。嘗試打開用戶輸入的文件。
# except 子句是處理錯誤的地方。檢查 open() 是否失敗-通常是 IOError 類型 的錯誤。
# else 子句在 try 代碼塊運行無誤時執行
3.6 相關模塊和開發工具
Python 代碼風格指南(PEP8), Python 快速參考和 Python 常見問答都是開發者很重要的 “工具”。另外, 還有一些模塊會幫助你成為一個優秀的 Python 程序員。
Debugger: pdb
Logger: logging
Profilers: profile, hotshot, cProfile
調試模塊 pdb 允許你設置(條件)斷點,代碼逐行執行,檢查堆棧。它還支持事后調試。
logging 模塊是在 Python2.3 中新增的, 它定義了一些函數和類幫助你的程序實現靈活的日志系統。共有五級日志級別: 緊急, 錯誤,警告,信息和調試。
因為不同的人們為了滿足不同的需求重復實現了很多性能測試器,Python 也有好幾個性能測試模塊。
- 最早的 Python profile 模塊是 Python 寫成的,用來測試函數的執行時間,及每次腳本執行的總時間,既沒有特定函數的執行時間也沒有被包含的子函數調用時間。 在三個 profile 模塊中,它是最老的也是最慢的,盡管如此, 它仍然可以提供一些有價值的性能信息。
- hotshot 模塊是在 Python2.2 中新增的,它的目標是取代 profile 模塊, 它修復了 profile 模塊的一些錯誤, 因為它是用 C 語言寫成,所以它有效的提高了性能。 注意 hotshot 重點解決了性能測試過載的問題, 但卻需要更多的時間來生成結果。Python2.5 版修復了 hotshot 模塊的一個關于時間計量的嚴重 bug。
- cProfile 模塊是 Python2.5 新增的, 它用來替換掉已經有歷史的 hotshot 和 profile 模 塊。被作者確認的它的一個較明顯的缺點是它需要花較長時間從日志文件中載入分析結果, 不支持子函數狀態細節及某些結果不準。它也是用 C 語言來實現的。
第四章
首先了解什么是 Python 對象→然后討論內建類型(標準類型)→討論標準類型運算符和內建函數→給出對標準類型的不同分類方式。最后提一提 Python 目前還不支持的類型(這對那些有其他高級語言經驗的人會有所幫助)。
4.1 Python 對象
Python 使用對象模型來存儲數據。
所有的 Python 對像都擁有三個特性:身份,類型和值。
- 身份:每一個對象都有唯一的身份標識自己,任何對象的身份可以使用內建函數 id()來得到。這個值可以被認為是該對象的內存地址。
- 類型:對象的類型決定了該對象可以保存什么類型的值,可以進行什么樣的操作,以及遵循什么樣的規則。可以用內建函數 type()查看 Python 對象的類型。因為在 Python 中類型也是對象,所以 type()返回的是對象而不是簡單的字符串。
- 值:對象表示的數據項
上面三個特性在對象創建的時候就被賦值,除了值之外,其它兩個特性都是只讀的。對于新風格的類型和類, 對象的類型也是可以改變的。
對象的值是否可以更改被稱為對象的可改變性(mutability),小節 4.7 中會討論這個問題。
Python 有一系列的基本(內建)數據類型,必要時也可以創建自定義類型來滿足應用程序的需求。
4.1.1 對象屬性
某些 Python 對象有屬性、值或相關聯的可執行代碼(方法)。Python 用點(.) 標記法來訪問屬性。屬性包括相應對象的名字等等。最常用的屬性是函數和方法,不過有一些 Python 類型也有數據屬性。含有數據屬性的對象包括(但不限于):類、類實例、模塊、復數和文件。
4.2 標準類型
- 數字(分為幾個子類型,其中有三個是整型)
- 整型
- 布爾型
- 長整型
- 浮點型
- 復數型
- 字符串
- 列表
- 元組
- 字典
把標準類型也稱作“基本數據類型”,因為這些類型是 Python 內建的基本數據類型。
4.3 其他內建類型
- 類型(Type)
- Null 對象 (None)
- 文件
- 集合/固定集合
- 函數/方法
- 模塊
- 類
這些是做 Python 開發時可能會用到的一些數據類型。這里先討論 Type 和 None 類型的使用,其他類型將在其他章節中討論。
4.3.1 類型對象和 type 類型對象
雖然看上去把類型本身也當成對象有點特別。對象的一系列固有行為和特性(比如支持哪些運算,具有哪些方法)必須事先定義好。從這個角度看,類型正是保存這些信息的最佳位置。描述一種類型所需要的信息不可能用一個字符串來搞定,所以類型不能是一個簡單的字符串,這些信息不能也不應該和數據保存在一起, 所以將類型定義成對象。
下面來正式介紹內建函數 type()。通過調用 type()函數你能夠得到特定對象的類型信息:
>>> type(42)
<type 'int'>
type 函數有,輸出結果<type 'int'>。不過你應當意識到它并不是一個簡簡單單的告訴你 42 是個整數這樣 的字符串。<type 'int'>實際上是一個類型對象,碰巧它輸出了一個字符串來告訴你它是個 int 型對象。
那么類型對象的類型是什么?
>>> type(type(42))
<type 'type'>
所有類型對象的類型都是 type,它也是所有 Python 類型的根和所有 Python 標準類的默認元類(metaclass)。
隨著 Python 2.2 中類型和類的統一,類型對象在面向對象編程和日常對象使用中扮演著更加重要的角色。從現在起, 類就是類型,實例是對應類型的對象。
4.3.2 None, Python 的 Null 對象
Python有一個特殊的類型,被稱作 Null 對象或者 NoneType,它只有一個值,那就是 None。 它不支持任何運算也沒有任何內建方法。和 None 類型最接近的 C 類型就 是 void,None 類型的值和 C 的 NULL 值非常相似(其他類似的對象和值包括 Perl 的 undef 和 Java 的 void 類型與 null 值)。
None 沒有什么有用的屬性,它的布爾值總是 False。
所有標準對象均可用于布爾測試,同類型的對象之間可以比較大小。每個對象天生具有布爾 True 或 False 值。空對象、值為零的任何數字或者 Null 對象 None 的布爾值都是 False。
下列對象的布爾值是 False:
- None
- False (布爾類型)
- 所有的值為零的數
- 0 (整型)
- (浮點型)
- 0L (長整型)
- 0.0+0.0j (復數)
- "" (空字符串)
- [] (空列表)
- () (空元組)
- {} (空字典)
值不是上面列出來的任何值的對象的布爾值都是 True,例如 non-empty、non-zero 等等。
用戶創建的類實例如果定義了 nonzero(nonzero())或 length(len())且值為 0,那 么它們的布爾值就是 False。
4.4 內部類型
- 代碼
- 幀
- 跟蹤記錄
- 切片
- 省略
- Xrange
一般的程序員通常不會直接和這些對象打交道。不過為了這一章的完整性,還是在這里介紹一下它們。請參閱源代碼或者 Python 的內部文檔和在線文檔獲得更詳盡的信息。
你如果對異常感到迷惑的話,可以告訴你它們是用類來實現的。
4.4.1 代碼對象
代碼對象是編譯過的 Python 源代碼片段,它是可執行對象。通過調用內建函數 compile() 可以得到代碼對象。代碼對象可以被 exec 命令或 eval()內建函數來執行。在第 14 章將詳細研究代碼對象。
代碼對象本身不包含任何執行環境信息, 它是用戶自定義函數的核心, 在被執行時動態獲得上下文。(事實上代碼對象是函數的一個屬性)一個函數除了有代碼對象屬性以外,還有一 些其它函數必須的屬性,包括函數名,文檔字符串,默認參數,及全局命名空間等等。
4.4.2 幀對象
幀對象表示 Python 的執行棧幀。幀對象包含 Python 解釋器在運行時所需要知道的所有信息。它的屬性包括指向上一幀的鏈接,正在被執行的代碼對象(參見上文),本地及全局名字空間字典以及當前指令等。每次函數調用產生一個新的幀,每一個幀對象都會相應創建一個 C 棧幀。用到幀對象的一個地方是跟蹤記錄對象(參見下一節)
4.4.3 跟蹤記錄對象
當你的代碼出錯時, Python 就會引發一個異常。如果異常未被捕獲和處理, 解釋器就會退出腳本運行,顯示類似下面的診斷信息:
Traceback (innermost last):
File "<stdin>", line N?, in ???
ErrorName: error reason
當異常發生時,一個包含針對異常的棧跟蹤信息的跟蹤記錄對象被創建。如果一個異常有自己的處理程序,處理程序就可以訪問這個跟蹤記錄對象。
4.4.4 切片對象
當使用 Python 擴展的切片語法時,就會創建切片對象。擴展的切片語法允許對不同的索引切片操作,包括步進切片,多維切片,及省略切片。
多維切片語法是 sequence[start1 : end1, start2 : end2], 或使用省略號, sequence[...,start1 : end1 ]. 切片對象也可以由內建函數 slice()來生成。
步進切片允許利用第三個切片元素進行步進切片,它的語法為 sequence[起始索引 : 結束索引 : 步進值]。
下面是幾個步進切片的例子:
>> foostr = 'abcde'
>> foostr[::-1]
'edcba'
>> foostr[::-2]
'eca'
>>> foolist = [123, 'xba', 342.23, 'abc']
>>> foolist[::-1]
['abc', 342.23, 'xba', 123]
4.4.5 省略對象
省略對象用于擴展切片語法中,起記號作用。 這個對象在切片語法中表示省略號。類似Null 對象 None, 省略對象有一個唯一的名字 Ellipsis, 它的布爾值始終為 True.
4.4.6 XRange 對象
調用內建函數 xrange() 會生成一個 Xrange 對象,xrange()是內建函數 range()的兄弟版本, 用于需要節省內存使用或 range()無法完成的超大數據集場合。在第 8 章你可以找到更多關于 range() 和 xrange() 的使用信息。
4.5 標準類型運算符
4.5.1 對象值的比較
比較運算符用來判斷同類型對象是否相等,所有的內建類型均支持比較運算,比較運算返回布爾值 True 或 False。
注意:實際進行的比較運算因類型而異。比如數字類型根據數值的大小和符號比較, 字符串按照字符序列值進行比較,等等。
>>> 2 == 2
True
>>> 2.46 <= 8.33
True
>>> 5+4j >= 2-3j
True
>>> 'abc' == 'xyz'
False
>>> 'abc' > 'xyz'
False
>>> 'abc' < 'xyz'
True
>>> [3, 'abc'] == ['abc', 3]
False
>>> [3, 'abc'] == [3, 'abc']
True
# 不同于很多其它語言,多個比較操作可以在同一行上進行,求值順序為從左到右。
>>> 3<4<7 #sameas(3<4)and(4<7) True
>>> 4>3==3 #sameas(4>3)and(3==3) True
>>> 4 < 3 < 5 != 2 < 7
False
比較操作是針對對象的值進行的,比較的是對象的數值而不是對象本身。后面會研究對象身份的比較。
表 4.1 標準類型值比較運算符
運算符 功能
expr1 < expr2 expr1 小于 expr2
expr1 > expr2 expr1 大于 expr2
expr1 <= expr2 expr1 小于等于 expr2
expr1 >= expr2 expr1 大于等于 expr2
expr1 == expr2 expr1 等于 expr2
expr1 != expr2 expr1 不等于 expr2 (C 風格)
expr1 <> expr2 expr1 不等于 expr2 (ABC/Pascal 風格)
注: 未來很有可能不再支持 <> 運算符,建議您一直使用 != 運算符。
4.5.2 對象身份比較
對象可以被賦值到另一個變量(通過引用)。因為每個變量都指向同一個(共享的)數據對象,只要任何一個引用發生改變,該對象的其它引用也會隨之改變。
為了方便理解,最好先別考慮變量的值,而是將變量名看作對象的一個鏈接。看以下三個例子:
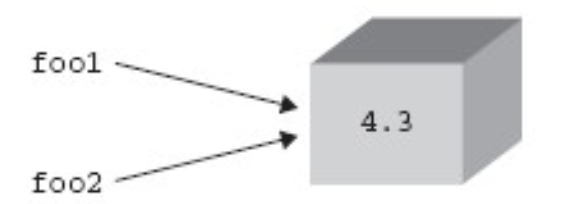
例 1: foo1 和 foo2 指向相同的對象
foo1 = foo2 = 4.3
多重賦值,將 4.3 這個值賦給了 foo1 和 foo2 這兩個變量。它還有另一層含義,事實是一個值為 4.3 的數字對象被創建,然后這個對象的引用被賦值給 foo1 和 foo2, 結果就是 foo1 和 foo2 指向同一個對 象。如下圖
例 2: foo1 和 foo2 指向相同的對象
foo1 = 4.3
foo2 = foo1
一個值為 4.3 的數值對象被創建,然后賦給一個變量,當執行 foo2 = foo1 時, foo2 被指向 foo1 所指向的同一個對象, 這是因為 Python 通過傳遞引用來處理對象。foo2 就成為原始值 4.3 的一個新的引用。 這樣 foo1 和 foo2 就都指向了同一個對 象。和上圖一樣。
例 3: foo1 和 foo2 指向不同的對象
foo1 = 4.3
foo2 = 1.3 + 3.0
這個例子有所不同。首先一個數字對象被創建,賦值給 foo1。然后第二個數值對象被創建并賦值給 foo2. 盡管兩個對象保存的是同樣大小的值,但事實上系統中保存的都是兩個獨立的對象,其中 foo1 是第一個對象的引用, foo2 則是第二個對象的引用。如下圖。 對象就象一個裝著內容的盒子。當一個對象被賦值到一個變量,就象在這個盒子上貼了一個標簽,表示創建了一個引用。每當這個對象有了一個新的引用,就會在盒子上新貼一張標簽。當一個引用被銷毀時, 這個標簽就會被撕掉。當所有的標簽都被撕掉時, 這個盒子就會被回收。那么,Python 是怎么知道這個盒子有多少個標簽呢?
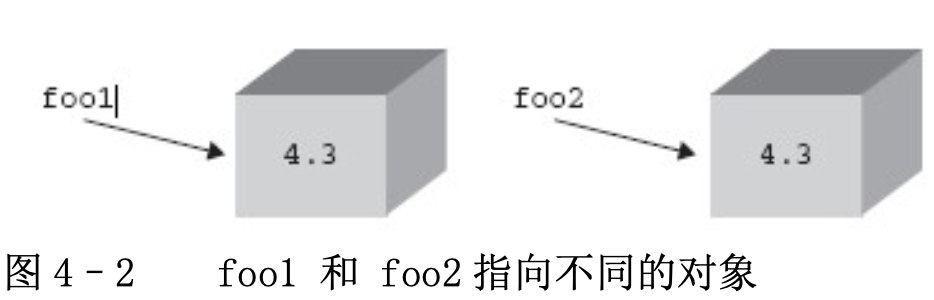
每個對象都天生具有一個計數器,記錄它自己的引用次數。這個數目表示有多少個變量指向該對象(引用計數)。
Python 提供了 is 和 is not 運算符來測試兩個變量是否指向同一個對象。
a is b
# 這個表達式等價于下面的表達式
id(a) == id(b)
對象身份比較運算符擁有同樣的優先級,表 4.2 列出了這些運算符。下面的例子創建了一個變量,然后將第二個變量指向同一個對象。
>>> a = [ 5, 'hat', -9.3]
>>> b = a
>>> a is b
True
>>> a is not b
False
>>> b = 2.5e-5
>>> b
2.5e-005
>>> a
[5, 'hat', -9.3]
>>> a is b
False
>>> a is not b
True
表4.2 標準類型對象身份比較運算符(is 與 not 標識符都是 Python 關鍵字。)
運算符 功能
obj1 is obj2 obj1 和 obj2 是同一個對象
obj1 is not obj2 obj1 和 obj2 不是同一個對象
上面的例子使用的是浮點數而不是整數。整數對象和字符串對象是不可變對象,所以Python會很高效的緩存它們。這會造成我們認為Python應該創建新對象時,它卻沒有創建新對象的假象。eg:
>>> a = 1
>>> id(a)
8402824
>>> b = 1
>>> id(b)
8402824
>>>c = 1.0
>> id(c)
8651220
>> d = 1.0
>> id(d)
8651204
a 和 b 指向了相同的整數對象,但是 c 和 d 并沒有指向相同的浮點數對象。我們可能會希望 a 與 b 能和 c 與 d 一樣,因為我們本意就是為了創建兩個整數對象,而不是像 b = a 這樣的結果。
Python 僅緩存簡單整數,因為它認為在 Python 應用程序中這些小整數會經常被用到。在寫作本書的時候,Python 緩存的整數范圍是(-1, 100),不過這個范圍是會改變的,所以不要在你的應用程序使用這個特性。
Python 2.3 中決定,在預定義緩存字符串表之外的字符串,如果不再有任何引用指向它, 那這個字符串將不會被緩存。也就是說, 被緩存的字符串將不會象以前那樣永生不滅,對象回收器一樣可以回收不再被使用的字符串。
4.5.3 布爾類型
布爾邏輯運算符 and, or 和 not,這些運算符的優先級按從高到低的順序列于表 4.3. not 運算符擁有最高優先級,只比所有比較運算符低一級。 and 和 or 運算符則相應的再低一級。
表4.3 標準類型布爾運算符
運算符 功能
not expr expr 的邏輯非 (否)
expr1 and expr2 expr1 和 expr2 的邏輯與
expr1 or expr2 expr1 和 expr2 的邏輯或
>>> x, y = 3.1415926536, -1024
>>> x < 5.0
True
>>> not (x < 5.0) False
>>> (x < 5.0) or (y > 2.718281828) True
>>> (x < 5.0) and (y > 2.718281828) False
>>> not (x is y)
True
4.6 標準類型內建函數
除了這些運算符,Python 提供了一些內建函數用于這些基本對象類型: cmp(), repr(), str(), type(), 和等同于 repr()函數的單反引號(``) 運算符。
表 4.4 標準類型內建函數
函數 功能
cmp(obj1, obj2) 比較 obj1 和 obj2, 根據比較結果返回整數 i:
i < 0 if obj1 < obj2
i > 0 if obj1 > obj2
i == 0 if obj1 == obj2
repr(obj) 或 obj 返回一個對象的字符串表示 str(obj) 返回對象適合可讀性好的字符串表示
type(obj) 得到一個對象的類型,并返回相應的 type 對象
4.6.1 type()
在 Python2.2 以前, type() 是內建函數。不過從那時起,它變成了一個“工廠函數”。
type() 的用法:type(object) ,接受一個對象做為參數,并返回它的類型。它的返回值是一個類型對象。
>>> type(4) # int type
<type 'int'>
>>> type('Hello World!')
<type 'string'>
# string type
>>> type(type(4)) # type type
<type 'type'>
通過內建函數 type() 得到了一個整數和一個字符串的類型;為了確認一下類型本身也是類型,對 type()的返回值再次調用 type()。
注意 type()的輸出, 它看上去不象一個典型的 Python 數據類型,比如一個整數或一個字符串,一些東西被 <和>包裹著。這種語法是為了告訴你它是一個對象。每個對象都可以實現一 個可打印的字符串表示。
不過并不總是這樣, 對那些不容易顯示的對象來說, Python 會以一 個相對標準的格式表示這個對象,格式通常是這種形式:<object_something_or_another>,以這種形式顯示的對象通常會提供對象類別,對象 id 或位置, 或者其它合適的信息。
4.6.2 cmp()
用于比較兩個對象 obj1 和 obj2:
- 如果 obj1 小于 obj2, 則返回一個負整 數
- 如果 obj1 大于 obj2 則返回一個正整數
- 如果 obj1 等于 obj2, 則返回 0。
它的行為非常類似于 C 語言的 strcmp()函數。比較是在對象之間進行的,不管是標準類型對象還是用戶自定 義對象。如果是用戶自定義對象,cmp()會調用該類的特殊方法__cmp__()。在第 13 章會詳細介紹類的這些特殊方法。下面是幾個使用 cmp()內建函數的對數值和字符串對象進行比較的例子。
>>> a, b = -4, 12
>>> cmp(a,b)
-1
>>> cmp(b,a)
1
>>> b = -4
>>> cmp(a,b)
0
>>>
>>> a, b = 'abc', 'xyz'
>>> cmp(a,b)
-23
>>> cmp(b,a)
23
>>> b = 'abc'
>>> cmp(a,b)
0
后面我們會研究 cmp()用于其它對象的比較操作。
4.6.3 str()和 repr() (及 `` 運算符)
內建函數 str() 和 repr() 或反引號運算符(``) 可以方便的以字符串的方式獲取對象的內容、類型、數值屬性等信息。
- str()函數得到的字符串可讀性好
- 而 repr()函數得到的字符串通常可以用來重新獲得該對象, 通常情況下 obj == eval(repr(obj)) 這個等式是成立的。
這兩個函數接受一個對象做為其參數,返回適當的字符串。下面隨機取一些 Python 對象來查看他們的字符串表示。
>>> str(4.53-2j)
'(4.53-2j)'
>>>
>>> str(1)
'1'
>>>
>>> str(2e10)
'20000000000.0'
>>>
>>> str([0, 5, 9, 9])
'[0, 5, 9, 9]'
>>>
>>> repr([0, 5, 9, 9])
'[0, 5, 9, 9]'
>>>
>>> `[0, 5, 9, 9]`
'[0, 5, 9, 9]'
盡管 str(),repr()和運算在特性和功能方面都非常相似,repr() 和 做的是完全一樣的事情,它們返回的是一個對象的“官方”字符串表示, 即絕大多數情況下可以通過求值運算(eval()內建函數)重新得到該對象,但 str()不同,str() 致力于生成一個對象的可讀性好的字符串表示,它的返回結果通常無法用于 eval()求值, 但很適合用于 print 語句輸出。但并不是所有 repr()返回的字符串都能夠用eval()內建函數得到原來的對象:
>>> eval(`type(type))`)
File "<stdin>", line 1 eval(`type(type))`)
^
SyntaxError: invalid syntax
也就是說 repr() 輸出對 Python 比較友好, 而 str()的輸出對人比較友好。雖然如此,很多情況下這三者的輸出仍然都是完全一樣的。
核心筆記:為什么有了 repr()還需要``?
你偶爾會遇到某個運算符和某個函數是做同樣一件事情。之所以如此是因為某些場合函數會比運算符更適合使用。舉個例子,當處理類似函數這樣的可執行對象或根據不同的數據項調用不同的函數處理時,函數就比運算符用起來方便。另一個例子就是雙星號(****)乘方運算和 pow()內建函數,x **** y 和 pow(x,y) 執行的都是 x 的 y 次方。
譯者注:Python 社區目前已經不鼓勵繼續使用``運算符。
4.6.4 type() 和 isinstance()
Python 不支持方法或函數重載,因此你必須自己保證調用的就是你想要的函數或對象。 (參閱 Python 常見問答 4.75 節)。幸運的是,type()內建函數可以幫助你確認這一點。一個名字里究竟保存的是什么?相當多,尤其是這是一個類型的名字時。
確認接收到的類型對象的身份有很多時候都是很有用的。為了達到此目的,Python 提供了一個內建函數 type(). type()返回任意 Python 對象對象的類型,而不局限于標準類型。來看幾個使用 type()內建函數返回多種對象類型的例子:
>>> type('')
<type 'str'>
>>>
>>> s = 'xyz'
>>> type(s)
<type 'str'>
>>>
>>> type(100)
<type 'int'>
>>> type(0+0j)
<type 'complex'>
>>> type(0L)
<type 'long'>
>>> type(0.0)
<type 'float'>
>>>
>>> type([])
<type 'list'>
>>> type(())
<type 'tuple'>
>>> type({})
<type 'dict'>
>>> type(type)
<type 'type'>
>>>
>>> class Foo: pass
...
>>> foo = Foo()
>>> class Bar(object): pass
...
>>> bar = Bar()
>>>
>>> type(Foo)
<type 'classobj'>
>>> type(foo)
<type 'instance'>
>>> type(Bar)
<type 'type'>
>>> type(bar)
<class '__main__.Bar'>
Python2.2 統一了類型和類, 如果你使用的是低于 Python2.2 的解釋器,你可能看到不一樣的輸出結果。
>>> type('')
<type 'string'>
>>> type(0L)
<type 'long int'>
>>> type({})
<type 'dictionary'>
>>> type(type)
<type 'builtin_function_or_method'>
>>>
>>> type(Foo) # assumes Foo created as in above
<type 'class'>
>>> type(foo) # assumes foo instantiated also
<type 'instance'>
除了內建函數 type(), 還有一個內建函數叫 isinstance()。會在第 13 章(面向對象編程)正式研究這個函數,不過還是要簡要介紹一下如何利用它來確認一個對象的類型。
下面腳本演示在運行時環境使用 isinstance() 和 type()函數。 隨后討論 type()的使用以及怎么將這個例子移植為改用 isinstance()。
運行 typechk.py, 我們會得到以下輸出:
-69 is a number of type: int
9999999999999999999999 is a number of type: int
98.6 is a number of type: float
(-5.2+1.9j) is a number of type: complex
xxx is not a number at all!!
函數 displayNumType() 接受一個數值參數,它使用內建函數 type()來確認數值的類型 。
def displayNumType(num):
# print(num)
if isinstance(num, (int, float, complex)):
print('a number of type:', type(num).__name__)
else:
print('not a number at all!!')
displayNumType(-69)
displayNumType(9999999999999999999999)
displayNumType(98.6)
displayNumType(-5.2+1.9j)
displayNumType('xxx')
例子進階
原始這個完成同樣功能的函數與本書的第一版中的例子已經大不相同:
def displayNumType(num):
print(num)
if type(num) == type(0):
print('an integer')
elif type(num) == type(0.0):
print('a float')
elif type(num) == type(0+0j):
print('a complex number')
else:
print('not a number at all!!')
減少函數調用的次數
仔細研究一下上面代碼,會看到調用了兩次 type()。要知道每次調用函數都會付出性能代價, 如果我們能減少函數的調用次數, 就會提高程序的性能。
利用在本章我們前面提到的 types 模塊, 我們還有另一種比較對象類型的方法,那就是將檢測得到的類型與一個已知類型進行比較。如果這樣, 我們就可以直接使用 type 對象而不用每次計算出這個對象來。那么我們現在修改一下代碼,改為只調用一次 type()函數:
>>> import types
>>> if type(num) == types.IntType...
對象值比較 VS 對象身份比較
在這一章的前面部分我們討論了對象的值比較和身份比較, 如果你了解其中的關鍵點,你就會發現我們的代碼在性能上還不是最優的.在運行時期,只有一個類型對象來表示整數類型. 也就是說,type(0),type(42),type(-100) 都是同一個對象: <type 'int'>(types.IntType 也 是這個對象)
如果它們是同一個對象, 我們為什么還要浪費時間去獲得并比較它們的值呢(我們已經知道它們是相同的了!)? 所以比較對象本身是一個更好地方案.下面是改進后的代碼:
if type(num) is types.IntType... # or type(0)
這樣做有意義嗎? 我們用對象身份的比較來替代對象值的比較。如果對象是不同的,那意味著原來的變量一定是不同類型的。(因為每一個類型只有一個類型對象),我們就沒有必要去檢查(值)了。 一次這樣的調用可能無關緊要,不過當很多類似的代碼遍布在你的應用程序中的 時候,就有影響了。
減少查詢次數
這是一個對前一個例子較小的改進,如果你的程序像我們的例子中做很多次比較的話,程序的性能就會有一些差異。為了得到整數的對象類型,解釋器不得不首先查找 types 這個模塊的名字,然后在該模塊的字典中查找 IntType。通過使用 from-import,你可以減少一次查詢:
from types import IntTyp
if type(num) is IntType...
慣例和代碼風格
Python2.2 對類型和類的統一導致 isinstance()內建函數的使用率大大增加。我們將在 第 13 章(面向對象編程)正式介紹 isinstance(),在這里我們簡單瀏覽一下。
這個布爾函數接受一個或多個對象做為其參數,由于類型和類現在都是一回事, int 現在 既是一個類型又是一個類。我們可以使用 isinstance() 函數來讓我們的 if 語句更方便,并具 有更好的可讀性。
if isinstance(num, int)...
在判斷對象類型時也使用 isinstance() 已經被廣為接受,我們上面的 typechk.py 腳本
最終與改成了使用 isinstance() 函數。值得一提的是, isinstance()接受一個類型對象的元 組做為參數, 這樣我們就不必像使用 type()時那樣寫一堆 if-elif-else 判斷了。
4.6.5 Python類型運算符和內建函數總結
表 4.5 列出了所有運算符和內建函數,其中運算符順序是按優先級從高到低排列的。同一 種灰度的運算符擁有同樣的優先級。注意在 operator 模塊中有這些(和絕大多數 Python)運算符相應的同功能的函數可供使用。
表 4.5 標準類型運算符和內建函數。
4.7 類型工廠函數
Python 2.2 統一了類型和類, 所有的內建類型現在也都是類, 在這基礎之上, 原來的所謂內建轉換函數象 int(), type(), list() 等等, 現在都成了工廠函數。 也就是說雖然他們看上去有點象函數, 實質上他們是類。當你調用它們時, 實際上是生成了該類型的一個實例, 就象工廠生產貨物一樣。
下面這些大家熟悉的工廠函數在老的 Python 版里被稱為內建函數:
-
int(), long(), float(), complex()
-
str(), unicode(), basestring()
-
list(), tuple()
-
type()
以前沒有工廠函數的其他類型,現在也都有了工廠函數。除此之外,那些支持新風格的類的全新的數據類型,也添加了相應的工廠函數。下面列出了這些工廠函數:
-
dict()
-
bool()
-
set(), frozenset()
-
object()
-
classmethod()
-
staticmethod()
-
super()
-
property()
-
file()
4.8 標準類型的分類
“標準類型”是 Python 的“基本內建數據對象原始類型”。
-
“基本”:是指這些類型都是Python提供的標準或核心類型。
-
“內建”,是由于這些類型是Python默認就提供的
-
“數據”,因為他們用于一般數據存儲
-
“對象”,因為對象是數據和功能的默認抽象
-
“原始”,因為這些類型提供的是最底層的粒度數據存儲 “類型”,因為他們就是數據類型
上面這些描述實際上并沒有告訴你每個類型如何工作以及它們能發揮什么作用。事實上, 幾個類型共享某一些的特性,比如功能的實現手段,另一些類型則在訪問數據值方面有一些共同之處。我們感興趣的還有這些類型的數據如何更新以及它們能提供什么樣的存儲。 有三種不同的模型可以對基本類型進行分類,每種模型都展示這些類型之間的相互關系。這些模型可以幫助理解類型之間的相互關系以及他們的工作原理。
4.8.1 存儲模型
分類的第一種方式:看這種類型的對象能保存多少個對象。一個能保存單個字面對象的類型稱它為原子或標量存儲,那些可容納多個對象的類型,稱之為容器存儲。(容器對象有時會在文檔中被稱為復合對象,不過這些對象并不僅僅指類型,還包括類似類實例這樣的對象)
容器類型又帶來一個新問題,那就是它是否可以容納不同類型的對象。所有的 Python 容器對象都能夠容納不同類型的對象。表 4.6 按存儲模型對 Python 的類型進行了分類。
字符串看上去像一個容器類型,因為它“包含”字符,不過由于 Python 并沒有字符類型,所以字符串是一個自我包含的文字類型。
表 4.6 以存儲模型為標準的類型分類
分類 Python 類型
標量/原子類型 數值(所有的數值類型),字符串(全部是文字)
容器類型 列表、元組、字典
4.8.2 更新模型
另一種分類的方式:針對每一個類型問一個問題:“對象創建成功之 后,它的值可以進行更新嗎?” 可變對象允許他們的值被更新,而不可變對象則不允許他們的值被更改。表 4.7 列出了支持更新和不支持更新的類型。
x = 'Python numbers and strings'
x = 'are immutable?!? What gives?'
i=0
i=i+1
你可能會疑問,“字符串和數字不可變嗎?”。沒錯,是這樣,不過你還沒有搞清楚幕后的真相。上面的例子中,事實上是一個新對象被創建,然后它取代了舊對象。
新創建的對象被關聯到原來的變量名, 舊對象被丟棄,垃圾回收器會在適當的時機回收這些對象。你可以通過內建函數 id()來確認對象的身份在兩次賦值前后發生了變化。
表 4.7 以更新模型為標準的類型分類
分類 Python 類型
可變類型 列表, 字典
不可變類型 數字、字符串、元組
在上面的例子里加上 id()調用, 就會清楚的看到對象實際上已經被替換了:
>>> x = 'Python numbers and strings'
>>> print id(x)
16191392
>>> x = 'are immutable?!? What gives?'
>>> print id(x)
16191232
>>> i = 0
>>> print id(i)
7749552
>>> i = i + 1
>>> print id(i)
7749600
另一類對象, 列表可以被修改而無須替換原始對象, 看下面的例子:
>>> aList = ['ammonia', 83, 85, 'lady']
>>> aList
['ammonia', 83, 85, 'lady']
>>>
>>> aList[2]
85
>>>
>>> id(aList)
135443480
>>>
>>> aList[2] = aList[2] + 1
>>> aList[3] = 'stereo'
>>> aList
['ammonia', 83, 86, 'stereo']
>>>
>>> id(aList)
135443480
>>>
>>> aList.append('gaudy')
>>> aList.append(aList[2] + 1)
>>> aList
['ammonia', 83, 86, 'stereo', 'gaudy', 87]
>>>
>>> id(aList)
135443480
列表的值不論怎么改變, 列表的 ID 始終保持不變。
4.8.3 訪問模型
根據訪問存儲的數據的方式對數據類型進行分類。在訪問模型中共有三種訪問方式:直接存取,順序,和映射。表 4.8 按訪問方式對數據類型進行了分類。
- 對非容器類型可以直接訪問。所有的數值類型都歸到這一類。
- 序列類型是指容器內的元素按從 0 開始的索引順序訪問。一次可以訪問一個或多個元素(切片(slice))。字符串, 列表和元組都歸到這一類。雖然字符串是簡單文字類型,因為它有能力按照順序訪問子字符串,所以也將它歸到序列類型。
- 映射類型類似序列的索引屬性,不過它的索引并不使用順序的數字偏移量取值, 它的元素無序存放, 通過一個唯一的 key 來訪問,這就是映射類型, 它容納的是哈希鍵-值對的集合。字典
以后的章節中將主要使用訪問模型,詳細介紹各種訪問模型的類型,以及某個分類的類型之間有哪些相同之處(比如運算符和內建函數), 然后討論每種 Python 標準類型。所有類型的特殊運算符,內建函數, 及方法都會在相應的章節特別說明。
為什么要對同樣的數據類型再三分類呢?
- 因為 Python 提供了高級的數據結構,我們需要將那些原始的類型和功能強大的擴展類型區分開來。
- 有助于搞清楚某種類型應該具有什么行為。
- 最后,搞清楚某些分類中的所有類型具有哪些相同的特性。
為什么要用這么多不同的模型或從不同的方面來分類?
所有這些數據類型看上去是很難分類的。它們彼此都有著錯綜復雜的關系,所有類型的共同之處最好能揭示出來,而且我們還想揭示每種類型的獨到之處。沒有兩種類型橫跨所有的分類。(當然,所有的數值子類型做到了這一點, 所以我們將它們歸納到一類當中)。你對每種類型的了解越多,你就越能在自己的程序中使用恰當的類型以達到最佳的性能。
下面匯總表中列出了所有的標準類型, 使用的三個模型, 以及每種類型歸入的分類。
標準類型的分類
數據類型 存儲模型 更新模型 訪問模型
數字 Scalar 不可更改 直接訪問
字符串 Scalar 不可更改 順序訪問
列表 Container 可更改 順序訪問
元組 Container 不可更改 順序訪問
字典 Container 可更改 映射訪問
4.9 不支持的類型
Python 目前還不支持的數據類型:
- char 或 byte:沒有 char 或 byte 類型來保存單一字符或 8 比特整數。可以使用長度為 1 的字符串表示字符或 8 比特整數。
- 指針 :Python 替你管理內存,因此沒有必要訪問指針。可以使用 id()函數得到一個對象的身份號,這是最接近于指針的地址。其實在 Python 中, 一切都是指針。
- int vs short vs long :Python 的普通整數相當于標準整數類型,不需要類似 C 語言中的 int, short, long 這三 種整數類型。事實上 Python 的整數實現等同于 C 語言的長整數。 由于 Python 的整型與長整型密切融合, 用戶幾乎不需要擔心什么。 你僅需要使用一種類型, 就是 Python 的整型。即便數值超出整型的表達范圍, 比如兩個很大的數相乘, Python 會自動的返回一個長整數給你而不會報錯。
- float VS double :C 語言有單精度和雙精度兩種浮點類型。 Python 的浮點類型實際上是 C 語言的雙精度浮點類型。Python 認為同時支持兩種浮點類型的好處與支持兩種浮點類型帶來的開銷不成比例, 所以Python 決定不支持單精度浮點數。對那些寧愿放棄更大的取值范圍而需要更高精確度的用戶來說, Python 還有一種十進制浮點數類型 Decimal。浮點數總是不精確的。Decimals 則擁有任意的精度。在處理金錢這類確定的值時, Decimal 類型就很有用。 在處理重量,長度或其它度量單位的場合, float 足夠用了。
第五章
本章主題
- 數的簡介
- 整型
- 布爾型
- 標準的整型
- 長整型
- 浮點型實數
- 復數
- 操作符
- 內建函數
- 其它數字類型
- 相關模塊
本章會詳細介紹每一種數字類型,它們適用的各種運算符, 以及用于處理數字的內建函數。簡單介紹幾個標準庫中用于處理數字的模塊。
5.1 數字類型
數字提供了標量貯存和直接訪問。它是不可更改類型。
Python 支持多種數字類型:整型、長整型、布爾型、雙精度浮點型、十進制浮點型和復數。
1. 如何創建數值對象并用其賦值 (數字對象)
創建數值對象和給變量賦值一樣同樣簡單:
anInt = 1
aLong = -9999999999999999L
aFloat = 3.1415926535897932384626433832795
aComplex = 1.23+4.56J
2. 如何更新數字對象
通過給數字對象(重新)賦值, 可以“更新”一個數值對象。給更新加上引號,是因為實際上并沒有更新該對象的原始數值。Python 的對象模型與常規對象模型有些不同。你所認為的更新實際上是生成了一個新的數值對象,并得到它的引用。
Python 中,變量更像一個指針指向裝變量值的盒子。 對不可改變類型來說, 你無法改變盒子的內容, 但你可以將指針指向一個新盒子。每次將另外的數字賦給變量的時候,實際上創建了一個新的對象并把它賦給變量。(所有的不可變類型都是這樣)
anInt += 1
aFloat = 2.718281828
3. 如何刪除數字對象
按照 Python 的法則, 你無法真正刪除一個數值對象, 你僅僅是不再使用它而已。如果你實際上想刪除一個數值對象的引用, 使用 del 語句。如果使用一個已經被刪除的對象引用, 會引發 NameError 異常。
del anInt
del aLong, aFloat, aComplex
來看下 Python 的四種主要數字類型。
5.2 整型
Python 有幾種整數類型:
- 布爾類型是只有兩個值的整型。
- 常規整型是絕大多數現代系統都能識別的整型。
- Python 也有長整數類型。然而,它表示的數值大小遠超過 C 語言的長整數 。
5.2.1 布爾型
該類型的取值范圍:布爾值True 和布爾值 False。
5.2.2 標準整數類型
Python 的標準整數類型是最通用的數字類型。在大多數 32 位機器上,標準整數類型的取值范圍是-231 到 231-1,也就是-2,147,483,648 到 2,147,483,647。如果在 64 位機器上使用 64 位編譯器編譯 Python,那么在這個系統上的整數將是 64 位。下面是一些 Python 標準整數類型對象的例子:
0101 84 -237 0x80 017 -680 -0X92
Python 標準整數類型等價于 C 的(有符號)長整型。整數一般以十進制表示,但是 Python 也支持八進制或十六進制來表示整數。如果八進制整數以數字“0”開始, 十六進制整數則以 “0x” 或“0X” 開始。
5.2.3 長整型
C語言的長整數典型的取值范圍是 32 位或 64 位。Python 的長整數類型能表達的數值僅僅與你的機器支持的(虛擬)內存大小有關, 換句話說, Python 能輕松表達很大很大很大的整數。
長整數類型是標準整數類型的超集,當需要使用比標準整數類型更大的整數時,就用長整數類型。在一個整數值后面加個 L(大寫或小寫),表示這個整數是長整數。這個整數可以是十進制,八進制, 或十六進制。eg:
16384L -0x4E8L 017L-2147483648l 052144364L 299792458l 0xDECADEDEADBEEFBADFEEDDEAL -5432101234L
核心風格:用大寫字母 “L”表示長整數
推薦使用大寫的“L”標記長整型, 能避免數字l和小寫L的混淆。目前整型和長整型正在逐漸緩慢的統一,只有在對長整數調用 repr()函數時才有機會看到“L”,如果對長整數對象調用 str()函數就看不到 L 。eg:
>>> aLong = 999999999l
>>> aLong
999999999L
>>> print aLong 999999999
5.2.4 整型和長整型的統一
這兩種整數類型正在逐漸統一為一種。
5.3 雙精度浮點數
Python 中的浮點數類似 C 語言中的 double 類型,是雙精度浮點數,可以用直接的十進制或科學計數法表示。每個浮點數占 8 個字節(64 比特),完全遵守 IEEE754 號規范(52M/11E/1S), 其中 52 個比特用于表示底,11 個比特用于表示指數(可表示的范圍大約是正負 10 的 308.25 次方), 剩下的一個比特表示符號。這看上去相當完美,然而,實際精度依賴于機器架構和創建 Python 解釋器的編譯器。
浮點數值通常都有一個小數點和一個可選的后綴 e(大寫或小寫,表示科學計數法)。在 e 和指數之間可以用正(+)或負(-)表示指數的正負(正數的話可以省略符號)。eg:
0.0
-777.
1.6
-5.555567119
4.3e25
9.384e-23
-2.172818
float(12)
3.1416
4.2E-10
-90.
6.022e23
96e3 * 1.0
1.000000001
-1.609E-19
5.4 復數
現在虛數已經廣泛應用于數值和科學計算應用程序中。一個實數和一個虛數的組合構成一個復數。一個復數是一對有序浮點數(x, y)。表示為 x + yj, 其中 x 是實數部分,y 是虛數部分。
下面是 Python 語言中有關復數的幾個概念:
-
虛數不能單獨存在,它們總是和一個值為0.0的實數部分一起來構成一個復數。
-
復數由實數部分和虛數部分構成
-
表示虛數的語法: real+imagj
-
實數部分和虛數部分都是浮點數
-
虛數部分必須有后綴j或J
下面是一些復數的例子:
64.375+1j 4.23-8.5j 0.23-8.55j 1.23e-045+6.7e+089j 6.23+1.5j -1.23-875J 0+1j 9.80665-8.31441J -.0224+0j
5.4.1 復數的內建屬性
復數對象擁有數據屬性, 分別為該復數的實部和虛部。復數還擁有 conjugate 方法, 調用它可以返回該復數的共軛復數對象。(兩頭牛背上的架子稱為軛,軛使兩頭牛同步行走。共軛即為按一定的規律相配的一對——譯者注)
表 5.1 復數屬性
屬性 描述
num.real 該復數的實數
num num.imag 該復數的虛數
num.conjugate() 返回該復數的共軛復數
>>> aComplex = -8.333-1.47j
>>> aComplex
(-8.333-1.47j)
>>> aComplex.real
-8.333
>>> aComplex.imag
-1.47
>>> aComplex.conjugate()
(-8.333+1.47j)
5.5 運算符
數值類型可進行多種運算。從標準運算符到數值運算符,甚至還有專門的整數運算符。
5.5.1 混合模式運算符
- 當兩個整數相加時, + 號表示整數加法;
- 當兩個浮點數相加時, + 表示浮點數加法;
- 依此類推。
在 Python 中, 非數字類型也可以使用 + 運算符。eg:字符串 A + 字符 串 B 表示把這兩個字符串連接起來, 生成一個新的字符串。關鍵之處在于支持 + 運算符的每種數據類型, 必須告訴 Python, + 運算符應該如何去工作。 這也體現了重載概念的具體應用。
Python 確實支持不同的數字類型相加。 當一個整數和一個浮點數相加時,系統會決定使用整數加法還是浮點數加法(實際上并不存在混合運算)。Python 使用數字類型強制轉換的方法來解決數字類型不一致的問題, 也就是說它會強制將一個操作數轉換為同另一個操作數相同的數據類型。這種操作不是隨意進行的, 它遵循以下基本規則:
- 如果兩個操作數都是同一種數據類型,沒有必要進行類型轉換。
- 僅當兩個操作數類 型不一致時, Python 才會去檢查一個操作數是否可以轉換為另一類型的操作數。如果可以, 轉換它并返回轉換結果。由于某些轉換是不可能的,比如如果將一個復數轉換為非復數類型, 將一個浮點數轉換為整數等等,因此轉換過程必須遵守幾個規則。
要將一個整數轉換為浮點數,只要在整數后面加個.0 就可以了。 要將一個非復數轉換為復數,則只需要要加上一個 “0j” 的虛數部分。這些類型轉換的基本原則是: 整數轉換為浮點數, 非復數轉換為復數。 在 Python 語言參考中這樣描述 coerce() 方法:
-
如果有一個操作數是復數, 另一個操作數被轉換為復數。
-
否則,如果有一個操作數是浮點數, 另一個操作數被轉換為浮點數。
-
否則, 如果有一個操作數是長整數,則另一個操作數被轉換為長整數;
-
否則,兩者必然都是普通整數,無須類型轉換。(參見下文中的示意圖)
數字類型之間的轉換是自動進行的,程序員無須自己編碼處理類型轉換。不過在確實需要明確指定對某種數據類型進行特殊類型轉換的場合, Python 提供了 coerce() 內建函數來幫助你實現這種轉換。(見 5.6.2 小節)
下面演示一下 Python 的自動數據類型轉換。為了讓一個整數和一個浮點數相加, 必須使二者轉換為同一類型。因為浮點數是超集,所以在運算開始之前, 整數必須強制轉換為一個浮點數,運算結果也是浮點數:
>>> 1 + 4.5
5.5
5.5.2 標準類型運算符
第四章中講到的標準運算符都可以用于數值類型。上文中提到的混合模式運算問題, 也就是不同數據類型之間的運算,在運算之前,Python 內部會將兩個操作數轉換為同一數據類型。
下面是一些數字標準運算的例子:
>>> 5.2 == 5.2
True
>>> -719 >= 833
False
>>> 5+4e >= 2-3e
True
>>> 2 < 5 < 9 # same as ( 2 < 5 ) and ( 5 < 9 )
True
>>> 77 > 66 == 66 # same as ( 77 > 66 ) and ( 66 == 66 )
True
>>> 0. < -90.4 < 55.3e2 != 3 < 181
False
>>> (-1 < 1) or (1 < -1)
True
5.5.3 算術運算符
- 單目運算符正號(+)和負號(-)
- 雙目運算符, +,-,*,/,%,還有 ** , 分別表示加法,減法, 乘法, 除法, 取余, 和冪運算。
- 從 Python2.2 起,還增加了一種新的整除運算符 // 。
除法
傳統除法― 對整數操作數,會執行“地板除” (floor,取比商小的最大整數。例如 5 除以 2 等于 2.5,其中“2”就稱為商的“地板”,即“地板除”的結果)。對浮點操作數會執行真正的除法。
在未來的 Python 版本中,Python 開發小組已經決定改變 / 運算符的行為。/ 的行為將變更為真正的除法, 會增加一種新的運算來表示地板除。
下面總結一下 Python 現在的除法規則, 以及未來的除法規則:
傳統除法
如果是整數除法,傳統除法會舍去小數部分,返回一個整數(地板除)。如果操作數之一是浮點數,則執行真正的除法。包括 Python 語言在內的很多語言都是這種行為。
>> 1 / 2 # perform integer result (floor) # 地板除 0
>> 1.0 / 2.0 # returns actual quotient#真正除法 0.5
真正的除法
除法運算總是返回真實的商, 不管操作數是整數還是浮點數。在未來版本的 Python 中, 這將是除法運算的標準行為。現階段通過執行 from future import division 指令, 也可以做到這一點。
>>> from __future__ import division
>>>
>>> 1 / 2 # returns real quotient
0.5
>>> 1.0 / 2.0 # returns real quotient 0.5
地板除
從 Python 2.2 開始, 一個新的運算符 // 已經被增加進來, 以執行地板除: // 除法不管操作數何種數值類型,總是舍去小數部分,返回數字序列中比真正的商小的最接近的數字。
>>> 1 // 2 # floors result, returns integer # 地板除, 返回整數
0
>>> 1.0 // 2.0 # floors result, returns float # 地板除, 返回浮點數
0.0
>>> -1 // 2 # move left on number line# 返回比 –0.5 小的整數, 也就是 -1
-1
取余
整數取余相當容易理解, 浮點數取余就略復雜些。
商取小于等于精確值的最大整數的乘積之差. 即: x - (math.floor(x/y) * y) 或者
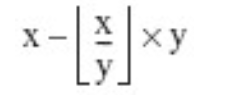
對于復數,取余的定義類似于浮點數,不同之處在于商僅取其實數部分,即: x - (math.floor((x/y).real) * y)。
冪運算
冪運算操作符比其左側操作數的一元操作符優先級低,比起右側操作數的一元操作符的優先級高,由于這個特性你會在算術運算符表中找到兩個 ** .下面舉幾個例子:
>>> 3 ** 2
9
>>> -3 ** 2 # ** 優先級高于左側的 -,先計算 3**2 再取其相反數
-9
>>> (-3) ** 2 # 加括號提高 -的優先級
9
>>> 4.0 ** -1.0# ** 優先級低于右側的 - 0.25,4**(-1)
總結
表 5.3 總結了所有的算術運算符, 從上到下, 計算優先級依次降低。 這里列出的所有運算符都比即將在 5.5.4 小節講到的位運算符優先級高。
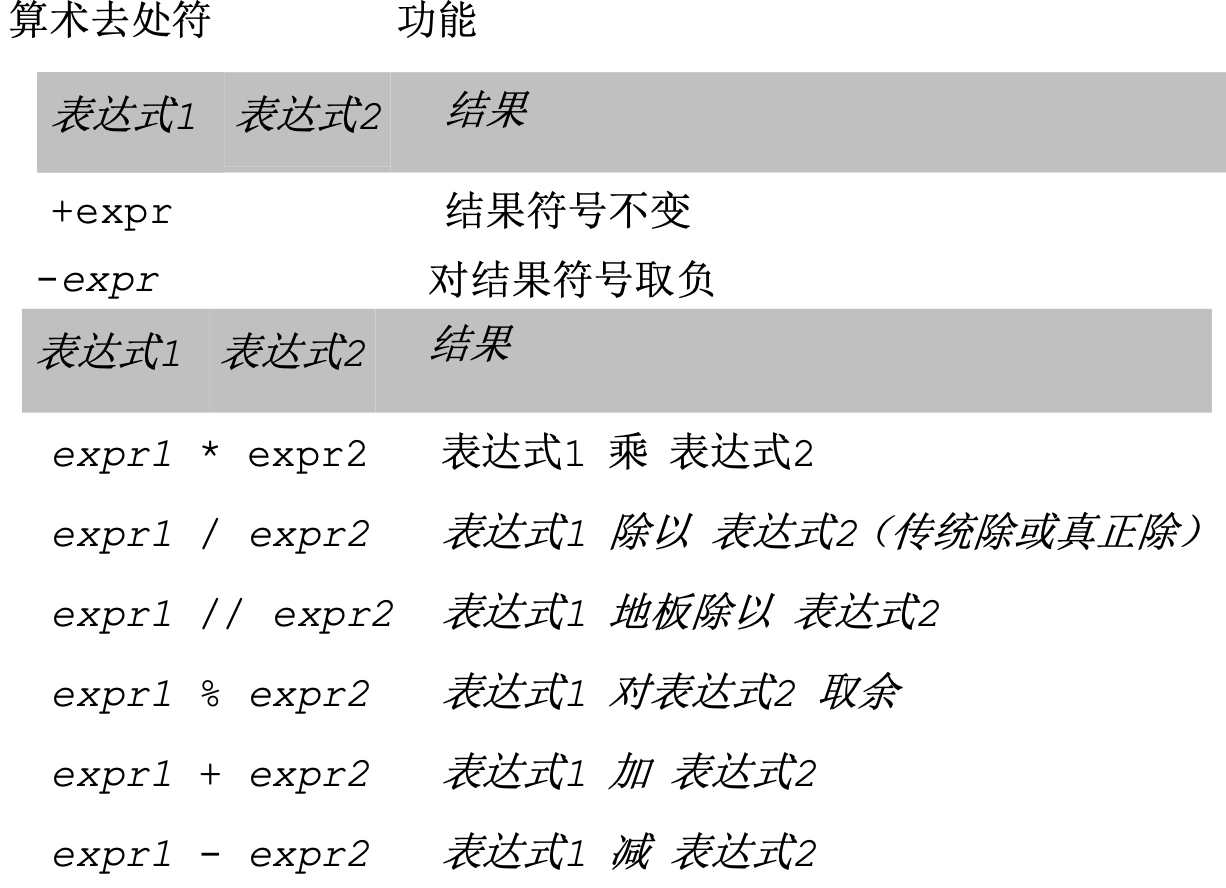
注:** 運算符優先級高于單目運算符
5.5.4 *位運算符(只適用于整數)
Python 整數支持標準位運算:取反(~),按位 與(&), 或(|) 及 異或(^) 及左移(<<)和右 移(>>)。Python 這樣處理位運算:
-
負數會被當成正數的2進制補碼處理。
-
左移和右移 N 位等同于無溢出檢查的 2 的 N 次冪運算: 2**N。
-
對長整數來說, 位運算符使用一種經修改的 2 進制補碼形式,使得符號位可以無限的
向左擴展。
取反(~)運算的優先級與數字單目運算符相同, 是所有位操作符中優先級最高的一個。 左移和右移運算的優先級次之,但低于加減法運算。與, 或, 異或 運算優先級最低。所有位運 算符按優先級高低列在表 5.4 中。
表 5.4 整型位運算符

下面是幾個使用整數 30(011110),45(101101),60(111100)進行位運算的例子:
>>> 30 & 45
12
>>> 30 | 45
63
>>> 45 & 60
44
>>> 45 | 60
61
>>> ~30
-31
>>> ~45
-46
>>> 45 << 1
90
>>> 60 >> 2
15
>>> 30 ^ 45
51
5.6 內建函數與工廠函數
5.6.1 標準類型函數
cmp(), str() 和 type() 內建函數。 這些函數可以用于所有的標準類型。
比較兩個數的大小, 將數字轉換為字符串, 以及返回數字對象的類型。
>>> cmp(-6, 2)
-1
>>> cmp(-4.333333, -2.718281828)
-1
>>> cmp(0xFF, 255)
0
>>> str(0xFF) # 非十進制轉成十進制進行字符串顯示
'255'
>>> str(55.3e2)
'5530.0'
>>> type(0xFF)
<type 'int'>
>>> type(98765432109876543210L)
<type 'long'>
>>> type(2-1j)
<type 'complex'>
5.6.2 數字類型函數
Python 現在擁有一系列針對數字類型的內建函數。
轉換工廠函數
函數 int(), long(), float() 和 complex() 用來將其它數值類型轉換為相應的數值類型。這些函數也接受字符串參數, 返回字符串所表示的數值。
int() 和 long() 在轉換字符串時,接受一個進制參數。如果是數字類型之間的轉換,則這個進制參數不能使用。
內建函數 bool()用來將整數值 1 和 0 轉換為標準布爾 值 True 和 False。
另外, 由于 Python 2.2 對類型和類進行了整合(這里指 Python 的傳統風格類和新風格類 ——譯者注), 所有這些內建函數現在都轉變為工廠函數。所謂工廠函數就是指這些內建函數都是類對象,調用它們時,實際上是創建了一個類實例。
eg:
>>> int(4.25555)
4
>>> long(42)
42L
>>> float(4)
4.0
>>> complex(4)
(4+0j)
>>>
>>> complex(2.4, -8)
(2.4-8j)
>>>
>>> complex(2.3e-10, 45.3e4)
(2.3e-10+453000j)
表 5.5 數值工廠函數總結

功能函數
五個運算內建函數用于數值運算: abs(), coerce(), divmod(), pow(), pow() 和 round()。
abs()返回給定參數的絕對值。如果參數是一個復數,返回math.sqrt(num.real2 +num.imag2)。
>>> abs(-1)
1
>>> abs(10.)
10.0
>>> abs(1.2-2.1j)
2.41867732449
>>> abs(0.23 - 0.78)
0.55
函數 coerce(),從技術上講它是一個數據類型轉換函數,不過它的行為更像一個運算符,因此將它放到了這一小節。函數 coerce()為程序員提供了不依賴 Python 解釋器, 而是自定義兩個數值類型轉換的方法。 對一種新創建的數值類型來說, 這個特性非常有用。函數 coerce()僅回一個包含類型轉換完畢的兩個數值元素的元組。eg:
>>> coerce(1, 2)
(1, 2)
>>>
>>> coerce(1.3, 134L)
(1.3, 134.0)
>>>
>>> coerce(1, 134L)
(1L, 134L)
>>>
>>> coerce(1j, 134L)
(1j, (134+0j))
>>>
>>> coerce(1.23-41j, 134L)
((1.23-41j), (134+0j))
divmod()內建函數把除法和取余運算結合起來, 返回一個包含商和余數的元組。對整數來說,它的返回值就是地板除和取余操作的結果。對浮點數來說, 返回的商部分是math.floor(num1/num2),對復數來說, 商部分是 ath.floor((num1/num2).real)。
>>> divmod(10,3)
(3, 1)
>>> divmod(3,10)
(0, 3)
>>> divmod(10,2.5)
(4.0, 0.0)
>>> divmod(2.5,10)
(0.0, 2.5)
>>> divmod(2+1j, 0.5-1j)
(0j, (2+1j))
函數 pow() 和雙星號 (**) 運算符都可以進行指數運算。區別并不僅僅在于一個是運算符,一個是內建函數。內建函數 pow()還接受第三個可選的參數,一個余數參數。如果有這個參數的, pow() 先進行指數運算,然后將運算結果和第三個參數進行取余運算。這個特性主要用于密碼運算,并且比 pow(x,y) % z 性能更好, 因為該函數的實現類似于 C 函數 pow(x,y,z)。
>>> pow(2,5)
32
>>>
>>> pow(5,2)
25
>>> pow(3.141592,2)
9.86960029446
>>>
>>> pow(1+1j, 3)
(-2+2j)
內建函數 round()用于對浮點數進行四舍五入運算。它有一個可選的小數位數參數。如果不提供小數位參數, 它返回與第一個參數最接近的整數(但仍然是浮點類型)。第二個參數將結果精確到小數點后指定位數。
>>> round(3)
3.0
>>> round(3.45)
3.0
>>> round(3.4999999)
3.0
>>> round(3.4999999, 1)
3.5
>>> round(-3.5)
-4.0
>>> round(-3.4)
-3.0
>>> round(-3.49)
-3.0
>>> round(-3.49, 1)
-3.5
round() 函數是按四舍五入的規則進行取整。round(0.5)得到 1, round(-0.5)得到-1。int(), round(), math.floor() 這幾個函數好像做的是同一件事, 很容易將它們弄混,下面列出它們之間的不同之處:
- 函數int()直接截去小數部分。(返回值為整數)
- 函數floor()得到最接近原數但小于原數的整數。(返回值為浮點數)
- 函數round()得到最接近原數的整數。(返回值為浮點數)
下面例子用四個正數和四個負數作為這三個函數的參數,將返回結果做個比較
(為了便于比較,將 int()函數的返回值也轉換成了浮點數)。
>>> import math
>>> for eachNum in (.2, .7, 1.2, 1.7, -.2, -.7, -1.2, -1.7):
... print "int(%.1f)\t%+.1f" % (eachNum, float(int(each-
Num)))
... print "floor(%.1f)\t%+.1f" % (eachNum,... math.floor(eachNum))
... print "round(%.1f)\t%+.1f" % (eachNum, round(eachNum))
... print '-' * 20
...
int(0.2) +0.0
floor(0.2) +0.0
round(0.2) +0.0
--------------------
int(0.7) +0.0
floor(0.7) +0.0
round(0.7) +1.0
--------------------
int(1.2) +1.0
floor(1.2) +1.0
round(1.2) +1.0
--------------------
int(1.7) +1.0
floor(1.7) +1.0
round(1.7) +2.0
--------------------
int(-0.2) +0.0
floor(-0.2) -1.0
round(-0.2) +0.0
--------------------
int(-0.7) +0.0
floor(-0.7) -1.0
round(-0.7) -1.0
--------------------
int(-1.2) -1.0
floor(-1.2) -2.0
round(-1.2) -1.0
--------------------
int(-1.7) -1.0
floor(-1.7) -2.0
round(-1.7) -2.0
表 5.6 數值運算內建函數

5.6.3 僅用于整數的函數
除了適應于所有數值類型的內建函數之外,Python 還提供一些僅適用于整數的內建函數(標準整數和長整數)。這些函數分為兩類,一類用于進制轉換,另一類用于 ASCII 轉換。
進制轉換函數
除了十進制,Python 整數也支持八進制和 16 進制整數。 有兩個內建函數返回字符串表示的8進制和16進制整數:oct() 和 hex()。它們都接受一個整數(任意進制的)對象,并返回一個對應值的字符串對象。eg:
>>> hex(255)
'0xff'
>>> hex(23094823l)
'0x1606627L'
>>> hex(65535*2)
'0x1fffe'
>>>
>>> oct(255)
'0377'
>>> oct(23094823l)
'0130063047L'
>>> oct(65535*2)
'0377776'
ASCII 轉換函數
Python 提供了 ASCII(美國標準信息交換碼)碼與其序列值之間的轉換函數。每個字符對應一個唯一的整數(0-255)。函數 chr()接受一個單字節整數值,返回一個字符串,其值為對應的字符。函數 ord()則相反,它接受一個字符,返回其對應的整數值。
>>> ord('a')
97
>>> ord('A')
65
>>> ord('0')
48
>>> chr(97)
'a'
>>> chr(65L)
'A'
>>> chr(48)
'0'
表 5.7 僅適用于整數的內建函數
hex(num) 將數字轉換成十六進制數并以字符串形式返回 oct(num) 將數字轉換成八進制數并以字符串形式返回
chr(num) 將ASCII值的數字轉換成ASCII字符,范圍只能是0 <= num <= 255。
ord(chr) 接受一個 ASCII 或 Unicode 字符(長度為1的字符串),返回相應的ASCII 或Unicode 值。
unichr(num) 接受Unicode碼值,返回 其對應的Unicode字符。所接受的碼值范圍依賴于 你的Python是構建于UCS‐2還是UCS‐4。
5.7 其他數字類型
5.7.1 布爾“數”
布爾值對應整數的 1 和 0。下面是有關布爾類型的主要概念:
- 有兩個永不改變的值 True 或 False。
- 布爾型是整型的子類,但是不能再被繼承而生成它的子類。
- 沒有__nonzero__()方法的對象的默認值是True。
- 值為零的任何數字或空集(空列表、空元組和空字典等)在Python中的布爾值都是 False。
- 在數學運算中,Boolean 值的 True 和 False 分別對應于 1 和 0。
- 以前返回整數的大部分標準庫函數和內建布爾型函數現在返回布爾型。
- True和False現在都不是關鍵字,但是在Python將來的版本中會是。
所有 Python 對象都有一個內建的 True 或 False 值。下面是使用內建類型布爾值的一些例子:
# intro
>>> bool(True) True
>>> bool(0) False
>>> bool('0') True
>>> bool([]) False
# 使用布爾數
>>> foo = 42
>>> bar = foo < 100
>>> bar
True
>>> print bar + 100
101
>>> print '%s' % bar
True
>>> print '%d' % bar
1
# 無 __nonzero__()
>>> class C: pass
>>> c = C()
>>> bool(c)
True
>>> bool(C)
True
# 重載 __nonzero__() 使它返回 False
>>> class C:
... def __nonzero__(self):
... return False
...
>>> c = C()
>>> bool(c) False
>>> bool(C) True
# 哦,別這么干!! (無論如何不要這么干!)
>>> True, False = False, True
>>> bool(True)
False
>>> bool(False)
True
5.7.2 十進制浮點數
從 Python2.4 起(參閱 PEP327)十進制浮點制成為一個 Python 特性。主要是因為下面的語句經常會讓程序員抓狂:為什么會這樣?這是因為語言絕大多數 C 語言的雙精度實現都遵守 IEEE 754 規范,其中
>>> 0.1
0.1000000000000001
52 位用于底。因此浮點值只能有 52 位精度,類似這樣的值的二進制表示只能象上面那樣被截斷。0.1 的二進制表示是 0.11001100110011 . . .
因為最接近的二進制表示就是.0001100110011...或 1/16 +1/32 + 1/256 + . . .
這些片斷不停的重復直到舍入出錯。如果我們使用十進制來做同樣的事情, 感覺就會好很多,看上去會有任意的精度。注意下面,你不能混用十進制浮點數和普通的浮點 數。你可以通過字符串或其它十進制數創建十進制數浮點數。你必須導入 decimal 模塊以便使用 Decimal 類:
>>> from decimal import Decimal
>>> dec = Decimal(.1)
Traceback (most recent call last): File "<stdin>", line 1, in ?
File "/usr/local/lib/python2.4/decimal.py", line 523, in __new__
raise TypeError("Cannot convert float to Decimal. " +
TypeError: Cannot convert float to Decimal. First convert the float to a string
>>> dec = Decimal('.1')
>>> dec
Decimal("0.1")
>>> print dec
0.1
>>> dec + 1.0
Traceback (most recent call last): File "<stdin>", line 1, in ?
File "/usr/local/lib/python2.4/decimal.py", line 906, in __add__
other = _convert_other(other)
File "/usr/local/lib/python2.4/decimal.py", line 2863, in _convert_other
raise TypeError, "You can interact Decimal only with int, long or
Decimal data types."
TypeError: You can interact Decimal only with int, long or Decimal data types.
>>>
>>> dec + Decimal('1.0') Decimal("1.1")
>>> print dec + Decimal('1.0')
1.1
可以從 Python 文檔中讀取相關的 PEP 以了解十進制數。十進制數和其它數值類型樣, 可以使用同樣的算術運算符。由于十進制數本質上是一種用于數值計算的特殊類, 在本章的剩余部分將不再專門講解十進制數。
5.8 相關模塊
Python 標準庫中有不少專門用于處理數值類型對象的模塊,它們增強并擴展了內建函數的功能和數值運算的功能。 表 5.8 列出了幾個比較核心的模塊。要詳細了解這些模塊,請參閱這些模塊的文獻或在線文檔。
對高級的數字科學計算應用來說,你會對著名的第三方包 Numeric(NumPy) 和 SciPy 感興趣。關于這兩個包的詳細請訪問下面的網址。http://numeric.scipy.org/ & http://scipy.org/
表 5.8數字類型相關模塊
模塊 介紹
decimal 十進制浮點運算類Decimal
array 高效數值數組(字符,整數,浮點數等等)
math/cmath標準C庫數學運算函數。常規數學運算在match模塊,復數運算在cmath模塊
operator 數字運算符的函數實現。比如 tor.sub(m,n)等價于m-n
random 多種偽隨機數生成器
核心模塊: random
需要隨機數功能時,可以使用random 模塊。該模塊包含多個偽隨機數發生 器,它們均以當前的時間戳為隨機數種子。該模塊中最常用的函數如下:兩個整數參數,返回二者之間的隨機整數
- randrange() 它接受和 range()函數一樣的參數, 隨機返回 range([start,]stop[,step])結果的一項
- uniform() 幾乎和 randint()一樣,不過它返回的是二者之間的一個浮點數(不包括范圍上限)。
- random()類似 uniform() 只不過下限恒等于 0.0,上限恒等于 1.0
- choice()隨機返回給定序列的一個元素
表 5.9 總結了數值類型的所有內建函數和運算符。
- 結果為 number 表示可以為所有四種數值類型,可能與操作數相同
- 與單目運算符有特殊關系,參閱 5.5.3 小節和表 5.2
- 單目運算符
練習

 浙公網安備 33010602011771號
浙公網安備 33010602011771號