
AAAI 2025-FEI: 頻率掩碼嵌入推理:一種非對(duì)比學(xué)習(xí)的時(shí)間序列表示學(xué)習(xí)
title:Frequency-Masked Embedding Inference: A Non-Contrastive Approach for Time Series Representation Learning
PAPER: https://arxiv.org/pdf/2412.20790
CODE: https://github.com/USTBInnovationPark/Frequencymasked-Embedding-Inference
Highlights:
1)非對(duì)比學(xué)習(xí)范式的突破
本文首次提出完全消除對(duì)比學(xué)習(xí)依賴的新范式。通過頻率掩蔽嵌入推斷(FEI)實(shí)現(xiàn)了無需樣本對(duì)約束的表示學(xué)習(xí),解決了對(duì)比學(xué)習(xí)中樣本構(gòu)造偏差和計(jì)算效率低的核心痛點(diǎn)。
2)頻率域操作驅(qū)動(dòng)語義關(guān)系建模
創(chuàng)新性地將頻率掩蔽作為提示信號(hào)引入時(shí)間序列處理,通過選擇性抑制頻域分量引導(dǎo)模型捕捉序列的連續(xù)語義關(guān)系。這種頻率域操作相比傳統(tǒng)時(shí)域增強(qiáng)技術(shù)(如窗口裁剪)更符合時(shí)間序列的本質(zhì)物理特性。
3)雙重推斷分支的協(xié)同優(yōu)化機(jī)制
設(shè)計(jì)兩個(gè)互補(bǔ)的推斷分支,通過參數(shù)共享與交互實(shí)現(xiàn)特征互補(bǔ),突破了單一自監(jiān)督任務(wù)的信息局限性。
研究背景
對(duì)比學(xué)習(xí)范式是當(dāng)前大多數(shù)自監(jiān)督預(yù)訓(xùn)練時(shí)間序列表示方法的基礎(chǔ)。構(gòu)造正負(fù)樣本對(duì)的策略會(huì)顯著影響最終的表示質(zhì)量。然而,由于時(shí)間序列語義的連續(xù)性,對(duì)比學(xué)習(xí)的建模方法難以適應(yīng)時(shí)間序列數(shù)據(jù)的特征。這會(huì)導(dǎo)致諸如難以構(gòu)建難負(fù)樣本對(duì)構(gòu)建過程中可能引入不適當(dāng)?shù)钠畹葐栴}。盡管最近的一些工作(如: 1. TimesURL, 2. SimMTM , 3. InfoTS, 4. TimeDRL, 5. TF-C, and 6. TS2Vec )已經(jīng)開發(fā)了幾種科學(xué)策略來構(gòu)建正負(fù)樣本對(duì),效果更高,但它們?nèi)匀皇艿綄?duì)比學(xué)習(xí)框架的限制。為了從根本上克服對(duì)比學(xué)習(xí)的局限性,本文介紹了頻率掩蔽嵌入推理 (FEI),這是一種新穎的非對(duì)比方法,完全消除了對(duì)正負(fù)樣本的需求。所提出的 FEI 基于提示策略構(gòu)建了 2 個(gè)推理分支: 1) 使用頻率掩碼作為提示來推斷嵌入空間中缺少頻段的目標(biāo)序列的嵌入表示,以及 2) 使用目標(biāo)序列作為提示來推斷其頻率掩碼嵌入。通過這種方式,F(xiàn)EI 支持對(duì)時(shí)間序列進(jìn)行連續(xù)的語義關(guān)系建模。使用線性評(píng)估和端到端微調(diào)對(duì) 8 個(gè)廣泛用于分類和回歸任務(wù)的時(shí)間序列數(shù)據(jù)集進(jìn)行的實(shí)驗(yàn)表明,F(xiàn)EI 在泛化方面明顯優(yōu)于現(xiàn)有的基于對(duì)比的方法。本研究為時(shí)間序列的自我監(jiān)督表示學(xué)習(xí)提供了新的解決方案。
方法
所提出的 FEI 的主要架構(gòu)如下圖所示。對(duì)于一個(gè)原始序列,使用頻域隨機(jī)mask的方式生成一個(gè)其可以視為正樣本的增強(qiáng)序列(target series)。這兩個(gè)序列都使用Encoder+MLP進(jìn)行表征生成。然后使用原始序列的embedding去預(yù)測被mask后序列的embedding,實(shí)現(xiàn)表示學(xué)習(xí)embedding的訓(xùn)練過程。下面展開介紹模型中的各個(gè)模塊,包括Encoder、Masking Block、優(yōu)化目標(biāo)3個(gè)部分。

Encoder
Encoder可以使用各種類型的模型,整體包括2個(gè)Encoder,一個(gè)Encoder用來對(duì)原始序列進(jìn)行表征映射,另一個(gè)Encoder用來對(duì)經(jīng)過Mask后的增強(qiáng)序列進(jìn)行表征映射。由于整體只有正樣本,為了避免表征坍縮(即所有表征學(xué)習(xí)點(diǎn)學(xué)到一塊去),對(duì)于另一個(gè)Encoder使用Momentum Encoder的方式,主要就是增加了衰減累加參數(shù),讓兩個(gè)Encoder參數(shù)空間產(chǎn)生差異。
Masking Block
這部分用來對(duì)原始序列在頻域做mask掩碼操作,以生成一個(gè)可以視為和原始序列互為正樣本對(duì)的增強(qiáng)序列。具體做法,先采用快速傅里葉變換將原序列從時(shí)域映射到頻域,然后隨機(jī)mask掉一部分主成分。這里的mask比例服從均勻分布,且每次樣本mask的比例隨機(jī)。然后再將Mask后的掩碼序列映射回時(shí)域得到增強(qiáng)樣本(文中叫做Target Series)。

為了讓mask部分在前向反饋神經(jīng)網(wǎng)絡(luò)中也參與梯度學(xué)習(xí),文中使用了一個(gè)mask生成網(wǎng)絡(luò),用于學(xué)習(xí)每個(gè)頻率成分是否應(yīng)該mask:

優(yōu)化目標(biāo)
上述模型的優(yōu)化目標(biāo)包括2個(gè)部分。一方面,使用原始序列表征和mask結(jié)果來預(yù)測增強(qiáng)序列的表征;另一方面使用原始序列表征和增強(qiáng)序列的表征來預(yù)測mask的結(jié)果。公式如下,其中D是stop gradient,讓模型在梯度傳播的時(shí)候?qū)W⒂趯?duì)應(yīng)表征的學(xué)習(xí)。

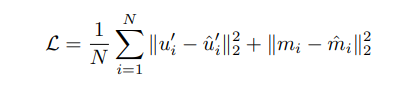
實(shí)驗(yàn)
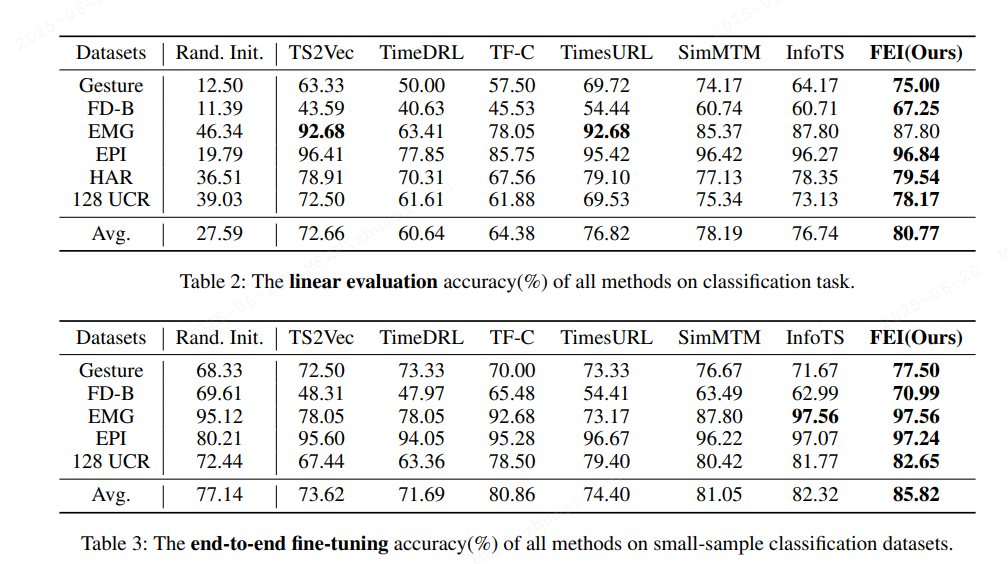
在8個(gè)廣泛使用的時(shí)間序列數(shù)據(jù)集上進(jìn)行的分類和回歸任務(wù)實(shí)驗(yàn)表明,F(xiàn)EI 在泛化性能上顯著優(yōu)于現(xiàn)有的基于對(duì)比學(xué)習(xí)的方法。具體來說,F(xiàn)EI 在分類任務(wù)中的線性評(píng)估和端到端微調(diào)中均表現(xiàn)出色,平均準(zhǔn)確率分別提高了2.15%和3.50%
另外在回歸預(yù)測任務(wù)中表現(xiàn)也實(shí)驗(yàn)SOTA水平:

代碼實(shí)現(xiàn)
FEI 的官方代碼已在 GitHub 上發(fā)布,可以通過以下命令快速開始預(yù)訓(xùn)練:
python ./experiment.py --task_type=p --method=FEI
預(yù)訓(xùn)練完成后,可以使用以下命令驗(yàn)證預(yù)訓(xùn)練模型:
python ./experiment.py --model=./train/model_result/your_model_path --task_type=l --task=c --dataset=FDB --method=FEI
結(jié)論
FEI 提供了一種新的時(shí)間序列自監(jiān)督表示學(xué)習(xí)方法,通過頻率掩碼推理克服了對(duì)比學(xué)習(xí)的局限性,顯著提升了模型的泛化性能

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)