
聊一聊領域驅動與貧血模型
寫在前面
前段時間跟領導討論技術債概念時不可避免地提到了代碼的質量,而影響代碼質量的因素向來都不是單一的,諸如項目因素、管理因素、技術選型、人員素質等等,因為是技術債務,自然就從技術角度來分析,單純從技術角度來看代碼質量,其實又細分很多原因,如代碼設計、代碼規范、編程技巧等等,但我個人覺得這些都是技,并不是代碼混亂的根,代碼之所以混亂的根要從最基礎的層面說起,也就是代碼架構。
但是好像代碼架構也不像是技術選型的產物,它更像是“潤物細無聲”的環境影響產物,一個Java Web項目,不談一個企業,甚至整個行業都有一個共識,應該是Controller、Service、Dao那一套,從代碼目錄結構到內部細節編寫,也不知道是MVC架構的宣傳深入人心還是培訓機構或者企業培訓的連帶效應導致的這種渾然天成的共識。就是這種渾然天成的共識導致了一個很奇怪的現象,那就是 :使用標榜面向對象的Java語言所開發的項目卻十分的不面向對象。這里也不是說面向對象就比面向過程要強,只是各自適用的領域不一樣。超過操作系統到應用層級的應用,不論從需求延申角度、系統規模角度、落地實現角度、擴展維護角度,面向對象都要更好一些。
這也是Java這門語言高居榜首的理由。 Java自誕生之初,各自資料、書籍無一不是在講它的面向對象特性和面向對象設計,隨后的領域驅動設計更是面向對象的集成方法論,在這么多buff的加持下,為什么還是會出現使用面向對象去寫面向過程的代碼呢?答案就在上面的共識里,好像Java項目的開發和貧血模型一直是強綁定的。
嚴格來講,概念上領域驅動其實只有一種概念,并沒有貧血充血之分,DDD官方概念中并沒有明確定義所謂的貧血模式,貧血模式的誕生其實是對于標準領域驅動的簡化,而與之對應的標準的DDD就成了充血。
貧血模型
貧血模式很多人不陌生, 即上文提到的傳統的Controller、Service、Dao的框架基礎之上,配合以Java的對象實體類概念,但實體類僅有屬性和屬性的get和set方法,在整個系統中,對象幾乎只作傳輸介質的作用,不會影響到層次的劃分,業務邏輯多集中在Service中;隨之后續的數據庫技術、ORM框架等等,都在這一體系上繼續壘加,形成了當下最高復制率的JavaWeb項目結構。
還是轉賬這個經典的例子,使用貧血實現:
/** * 賬戶業務對象 */ public class AccountBO { /** * 賬戶ID */ private String accountId; /** * 賬戶余額 */ private Long balance; /** * 是否凍結 */ private boolean isFrozen; public String getAccountId() { return accountId; } public void setAccountId(String accountId) { this.accountId = accountId; } public Long getBalance() { return balance; } public void setBalance(Long balance) { this.balance = balance; } public boolean isFrozen() { return isFrozen; } public void setFrozen(boolean isFrozen) { this.isFrozen = isFrozen; } } /** * 轉賬業務服務實現 */ @Service public class TransferServiceImpl implements TransferService { @Autowired private AccountMapper accountMapper; @Override public boolean transfer(String fromAccountId, String toAccountId, Long amount) { AccountBO fromAccount = accountMapper.getAccountById(fromAccountId); AccountBO toAccount = accountMapper.getAccountById(toAccountId); /** 檢查轉出賬戶 **/ if (fromAccount.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } if (fromAccount.getBalance() < amount) { throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE); } fromAccount.setBalance(fromAccount.getBalance() - amount); /** 檢查轉入賬戶 **/ if (toAccount.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } toAccount.setBalance(toAccount.getBalance() + amount); /** 更新數據庫 **/ accountMapper.updateAccount(fromAccount); accountMapper.updateAccount(toAccount); return Boolean.TRUE; } }
貧血模型的本質
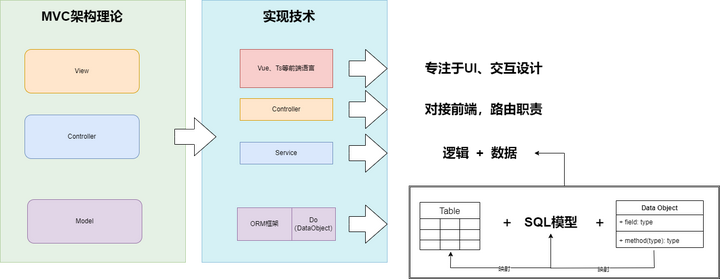
貧血模式本質是在架構指導下技術框架趨于成熟的演進產物;換句話說是MVC架構隨著技術的發展而不斷變體而來。MVC的初衷是一個三層架構,即包含數據結構和業務邏輯的模型Model層、應用程序的用戶界面(UI)展示與交互的視圖層View、用于協調Model與View的劇中調度層Controller,旨在將數據、邏輯和交互解耦。但伴隨著ORM框架、Web框架的進步,慢慢形成了Controller、Service、Dao(ORM)的格局,之后前后端分離的浪潮襲來,導致Controller變成了路由,Dao變成了JDBC的簡化,Do變成了數據結構,頭和尾都明確定位的夾擊下,所有的業務功能只能聚焦于中間的Service里,需求大都集中在了Service,“Service用來承載業務邏輯”的說法更加助長了設計懶惰,形成了 “service=數據+邏輯”的風格,學過C語言的或多或少都聽過一句“程序=數據+算法”,所以貧血就是在輸入輸出都固定框架模式下的面向過程。
貧血模型下的開發特點
貧血模式的service層的定義導致它的底層思維是 “程序=算法+數據” ,與之而來的開發流程或者說特點也就十分明了了。即 功能與數據密不可分、代碼與數據密不可分。最后面向數據編程。

聚焦功能忽視業務
長期使用貧血模式開發的人員,眼里看到的多是UI原型或者功能,對于系統的全貌,永遠是站在功能的角度去描述和了解。往往專注于功能的開發,盡可能地去簡化實現,點到實現功能為止,不做過多的設計與業務的擴展思考。實現往往是單維度的,僅僅是為了滿足某個功能或某個頁面,當需求分析和系統規劃不夠優秀時,后續功能開發時,不可避免會陷入前后矛盾的情景。
面向數據開發
在接手系統時,程序員一般先看兩部分,數據庫里的表和功能,最后才是代碼,或者接到需求時,首先做的就是根據UI或者產品的描述去設計存儲用的表結構,然后再基于表結構去進行代碼設計。也就是說,在實現角度,數據庫的表結構才是根基。
另一方面就是SQL建模,其實也可以說是重SQL輕代碼,絕大多數做Java Web開發地研發人員從根據需求設計表結構、到實現時進行SQL建模十分嫻熟,甚至我見過很多高手,能用一個SQL完成功能開發,把功能和數據的關系極盡所能地壓縮到一個或者幾個SQL中,代碼反而只是一個傳輸媒介。
貧血模式的開發者傾向于將注意力集中在數據上,他們直接在數據表上建模。語言框架更多的功能在于數據庫的訪問和UI的繪制,雖然語言可能是Java這種完全面向對象語言,但其實應用里并沒有什么客觀對象,除了數據庫的容器和訪問者
貧血模型的合理性
說到這好像顯得貧血模式一無是處,其實也不絕對,畢竟 “存在即合理”,裁剪了繁重體系的領域驅動后,貧血模式就變得十分輕便,本身面向過程的特點又讓它復制性和落地效率十分突出,開發人員只需要UI頁面和數據庫的表結構,隨便一個研發都可以快速接手并完成一個功能的開發 ,降低了軟件設計的復雜度,這恰恰和很多開發團隊快速響應的訴求不謀而合。
貧血得以盛行的另一個助力就是Spring,Spring家族作為Java系的行業老大哥框架,積累和沉淀非常豐富,各方面已經封裝的很全面,所以留出的“自由度”就比較少,它的宗旨就是讓開發人員減少重復造輪子,僅僅專注功能的開發就好;這些特點使得Spring本身就帶有限制性質,例如Spring的根基Bean管理機制,把對象的管控牢牢把握在框架中,這種將實體類的管理也交由Spring本身也降低了二次開發時面向對象的屬性,導致在Spring中進行bean之間的引用改造會面臨大范圍的bean嵌套構造器的調用問題。所以使用Spring也就大概率默認使用貧血。
貧血模型的問題
不可否認,面對大多數簡單而生命周期短暫的項目面向數據開發是一種高效的方式,且當需求發生變動,Service按部就班地追加相應的邏輯也是可以快速響應,可是這些都是建立在系統簡單、項目周期短的前提下,一旦面臨長生命周期且業務復雜的大型系統,貧血模式的問題就是:
- 隨著系統體積的增長和需求的蔓延,部分功能設計問題顯露,貧血模式下的代碼特點難以快速重構來響應這一級別的訴求
- 面向過程的形式,讓代碼陷入 “又臭又長的if else”死胡同,隨著不斷地開發,維護和改動成本指數級上漲
- 長時間的“水多了加面,面多了加水”的開發習慣,團隊人員思維固化,難以提出有效地優化或改進,惡性循環
充血模型
充血簡單來講就是OO思想的體系方法論,相比貧血的面向數據,它提出領域的概念,即將業務和數據拆開,對業務部分進行領域劃分并進行OOA,代碼上更重抽象出的領域實體類,將業務邏輯和判定等內容均內聚到實體類中,Service層僅僅充當組合實體對象的畫布,負責簡單封裝部分業務和事務權限管理等;
為了更直觀感受,使用充血模型,對上面的例子進行修改:
/** * 賬戶業務對象 */ public class AccountBO { /** * 賬戶ID */ private String accountId; /** * 賬戶余額 */ private Long balance; /** * 是否凍結 */ private boolean isFrozen; /** * 出借策略 */ private DebitPolicy debitPolicy; /** * 入賬策略 */ private CreditPolicy creditPolicy; /** * 出借方法 * * @param amount 金額 */ public void debit(Long amount) { debitPolicy.preDebit(this, amount); this.balance -= amount; debitPolicy.afterDebit(this, amount); } /** * 轉入方法 * * @param amount 金額 */ public void credit(Long amount) { creditPolicy.preCredit(this, amount); this.balance += amount; creditPolicy.afterCredit(this, amount); } public boolean isFrozen() { return isFrozen; } public void setFrozen(boolean isFrozen) { this.isFrozen = isFrozen; } public String getAccountId() { return accountId; } public void setAccountId(String accountId) { this.accountId = accountId; } public Long getBalance() { return balance; } /** * BO和DO轉換必須加set方法這是一種權衡 */ public void setBalance(Long balance) { this.balance = balance; } public DebitPolicy getDebitPolicy() { return debitPolicy; } public void setDebitPolicy(DebitPolicy debitPolicy) { this.debitPolicy = debitPolicy; } public CreditPolicy getCreditPolicy() { return creditPolicy; } public void setCreditPolicy(CreditPolicy creditPolicy) { this.creditPolicy = creditPolicy; } } /** * 入賬策略實現 */ @Service public class CreditPolicyImpl implements CreditPolicy { @Override public void preCredit(AccountBO account, Long amount) { if (account.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } } @Override public void afterCredit(AccountBO account, Long amount) { System.out.println("afterCredit"); } } /** * 出借策略實現 */ @Service public class DebitPolicyImpl implements DebitPolicy { @Override public void preDebit(AccountBO account, Long amount) { if (account.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } if (account.getBalance() < amount) { throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE); } } @Override public void afterDebit(AccountBO account, Long amount) { System.out.println("afterDebit"); } } /** * 轉賬業務服務實現 */ @Service public class TransferServiceImpl implements TransferService { @Resource private AccountMapper accountMapper; @Resource private CreditPolicy creditPolicy; @Resource private DebitPolicy debitPolicy; @Override public boolean transfer(String fromAccountId, String toAccountId, Long amount) { AccountBO fromAccount = accountMapper.getAccountById(fromAccountId); AccountBO toAccount = accountMapper.getAccountById(toAccountId); //此處采用輕量化地方式解決了自身面向對象和Spring的bean管理權矛盾 fromAccount.setDebitPolicy(debitPolicy); toAccount.setCreditPolicy(creditPolicy); fromAccount.debit(amount); toAccount.credit(amount); accountMapper.updateAccount(fromAccount); accountMapper.updateAccount(toAccount); return Boolean.TRUE; } }
充血模型的開發特點
抽象業務

相比于貧血聚焦于功能、UI頁面,充血模式在面對設計時,需要更上升一層,聚焦于業務。將業務內容抽象出業務對象、對象關系、業務流程、對象依賴,以排列組合對象來滿足業務需求。面對需求,需要層層分析,設計,模型場景推演,做到重業務對象,輕數據,從而實現業務、功能、代碼、數據的清晰劃分,避免直譯式的粘連耦合實現。
通過領域概念將業務與技術分離

領域驅動中突出領域的概念,包含:通用域、支撐域、核心域三部分,其中通用域和支撐域則是純技術流和通用內容,包括持久化、通信技、安全、性能、通用組件、規則等,核心域則是具體業務分析得出的業務塊,其中包含通用的業務語言、領域內的上下文、復雜變化的業務邏輯等。通用域和支撐域負責數據管理、包裝接口、繪制界面、收接消息等系統的基本技術能力,以此來支撐核心域的業務流轉、運作。 通用域、支撐域不與核心域耦合,讓技術歸技術、業務歸業務,做到技術和業務的分離。
充血模型的問題
很多書籍和資料都是在說充血模型是解決貧血模型的良藥,其實也過于吹捧了,之前也提到了,貧血模型有其存在的必要性,充血模型和貧血模型只是適用范圍不同,如果貧血模型的缺點都是由于應用場景導致,那充血確是良藥。但如果單純是管理問題、團隊人員技術問題導致的問題,那強行套用充血才是災難,至于貧血換充血的理由,會在后面提到。這里單純以批評視角說一說充血的問題。
單純看充血模型存在的問題,就兩點:
- 理論過于理想,實踐較為困難
- 邊界難以把控
其實這兩點歸于一點也不為過,那就是充血模型的實踐土壤過于苛刻,因為其脫身于面向對象,著重以面向對象思想解決系統開發中熵增的問題,由此誕生了非常繁重的體系理論,而每一處體系理論都透露著對于團隊人員素質以及業務場景理解的高要求;對于團隊人員素質,這一點是最難的,因為在一個群體中很難把每個研發對于面向對象的理解拉到同一個維度,只能是不要有太大偏差。其次就是設計者很容易陷入到 “設計師的錘子”理論中,即 “手里有錘子,處處是釘子”,很容易過度設計,導致無意義地加重復雜度,畢竟把握“精準平衡” 這四個字對于 架構師、設計師、研發工程師的要求不是一紙證書那么簡單。
從貧血到充血的前制條件
聊怎么做之前,先談一談必要性,即貧血一定要切換為充血么,其實從貧血過度到充血也不是必須品,至于要不要使用充血模式,取決于兩個方面:
- 領域特性
- 團隊成熟度
領域特性
衡量是否必要的第一點就是領域邏輯的復雜度,充血模式最適合具有復雜領域邏輯的應用。如果業務比較復雜,隨著我們對領域邏輯的了解,就能很快感受到基于數據的做法帶來的限制。僅從數據出發,CRUD系統無法創建出好的業務模型。業務的復雜性可以體現在精巧的商業模式、復雜的制造過程、精益的管理方法等方面。
第二點就是領域的穩定性,這里的穩定性是指內在商業邏輯是穩定的,未來的需求主要集中在支撐功能和業務量的擴展上。當然,穩定性指標并不是絕對的,要看它所處的階段。有的軟件功能在時間長度上,幾年內將不斷變化,但一旦改變就不是簡單的變更,例如金融、政策領域的一些法規。或者,雖然業務現階段處于變化之中,但它的商業模式一旦形成,將作為企業的核心資產,例如新興的移動互聯網應用中的各種商業模式。它們都適合采用DDD,即便業務邏輯處在變化之中,我們也可以從DDD的另一個特性——快速測試和驗證領域邏輯中收益,它可以為高頻發布類應用提供很好的支持。
團隊成熟度
另一個說必要性有點不夠準確,應該說是前置條件,那就是團隊的成熟度。
團隊的成熟度首先表現在團隊的技術素養上,如果團隊大多數人還需要花費大量時間去學習和體會面向對象技術(這些技術包括UML語言、面向對象設計、理解面向接口編程、基于服務的架構、設計模式、開發流程、需求分析等),那么在構建通用語言、模型設計和架構解耦上投入的精力就會受到限制,冒然轉為充血模式的領域驅動,將是災難性質的。
其次就是團隊中一定要有 “領域專家”角色,這個領域專家嚴格來說只是一種角色,它可以泛指那些對業務領域的政策、工作流程、關鍵節點和特性都有深刻理解的所有人。一個判斷標準是,他們對領域的論述是有體系的,而不是散亂的,而且十分清楚規則的應用范圍。沒有領域專家,就不會有通用語言和與語言一致的模型和代碼。誰來保證我們是“領域驅動”,還是過度設計?即便是最簡的設計,誰來驗證呢?這個“最簡”只能是個偽概念,領域專家的重要性是不可替代的。
說起前置條件不得不提一下項目的周期。相對來說,領域驅動更適合周期長的項目。交付時間過于緊張的項目,團隊成員的注意力都會集中在功能的開發上,這時候強調領域知識的學習和領域模型的精煉,顯然會和各利益相關者產生工作安排重點的沖突。相反,周期越長的項目,比如核心產品的研發,隨著時間的推移,提煉出的領域模型就會逐步釋放出它的威力。因此,項目生命周期越長,收益越大。
如何從貧血到充血
主要是思考角度的轉換,角度轉換主要指兩方面:需求視角, 不要過分糾結具體的功能,而是上升一層,去理解業務,抽象出業務對象和它們之間的關系;實現視角不要拘泥于具體代碼或實現框架,要站在架構一層上,屏蔽掉系統對于數據的依賴細節,以面向對象的思維去構建系統。
設計視角
“重業務輕功能”
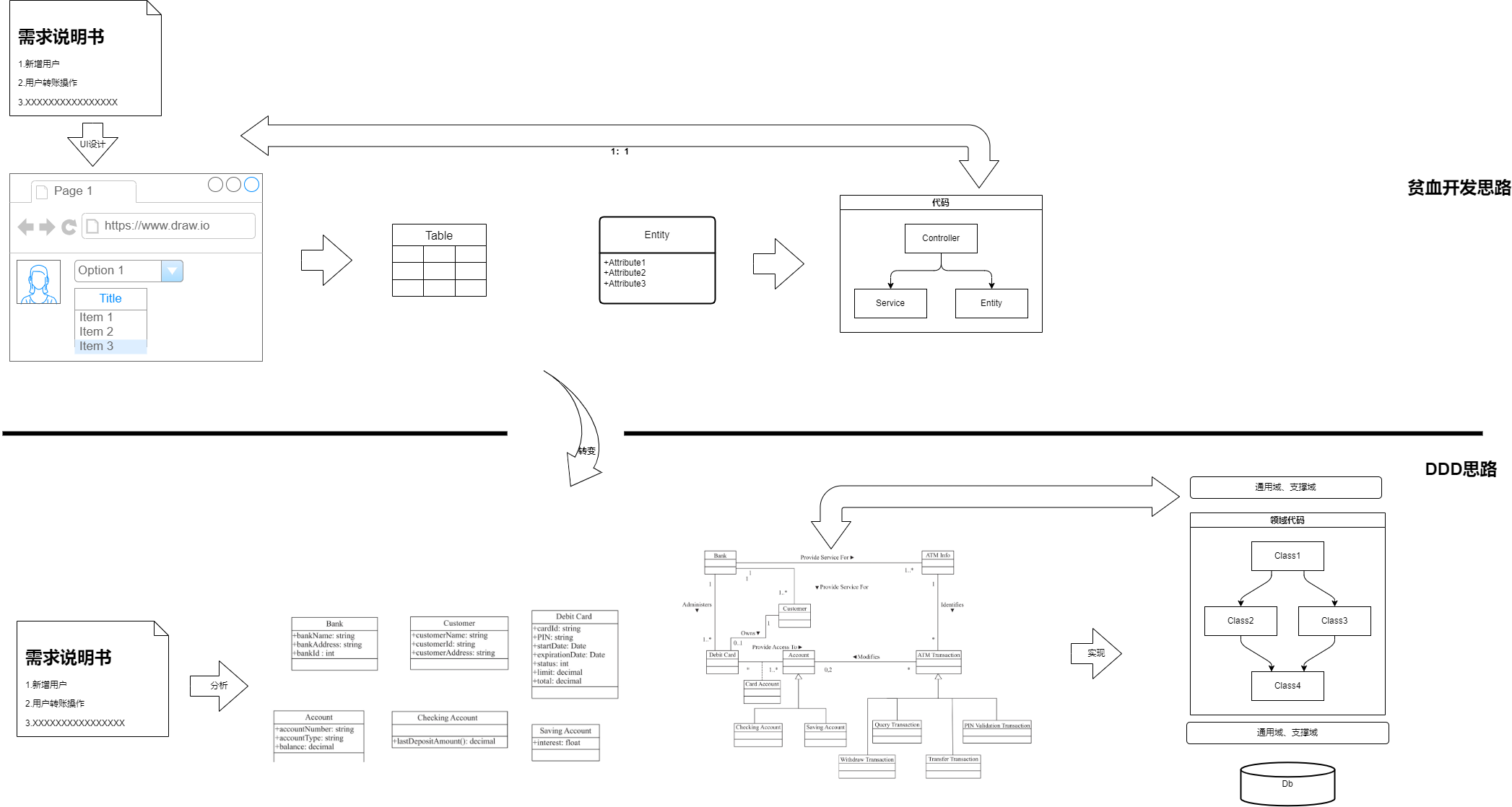
貧血模式所對應的開發方式更為“簡單粗暴”,針對需求和功能頁面,1:1的進行技術實現,直接針對功能復刻存儲結構、參照MVC逐層進行編碼開發,輸出的成果本質上是對功能UI頁面負責;這也是諸多研發人員即便參與工作或者某個項目很久,仍舊無法說清楚所謂“業務”的原因,因為在貧血模式下的開發都是公式化的功能代碼轉化,沒有業務理解和設計。
而DDD實踐的核心則是體系的業務邏輯,也就是說,在需求分析時盡可能的忽略實現細節與功能,轉而進行業務邏輯的推演、建設,即重業務而輕功能。到具體實操上就是轉換建模方式,舍棄ER數據建模轉而使用OO建模。ER數據建模雖然也有一套分析設計方法論,但是由于過于注重數據庫技術而忽視了業務上下文,極容易進入CRUD原子操作的思維。切換為DDD要做的就是轉化這個思維角度,規避CRUD原子操作思維,進而使用日常思維模式、 業務術語來表達,例如使用“下單”替代“創建訂單”,使用“發帖”替代“新增帖子”,使用“開票”替代“新增發票”等。從溝通傳遞開始就要有意識的進行轉換, 如果純粹以技術角度描述而脫離業務上下文,設計的邏輯性將很難去追溯和質疑,就好比說“穿的越少越好”,在冬天說和在夏天說的意義天差地別。在業務全貌的前提下,進行業務對象抽取而非表結構設計,結合抽取的業務對象和業務邏輯去繪制業務模型圖,反向地驗證業務理解的準確性。最終讓輸出的成果對業務模型圖負責。
區分數據結構與對象
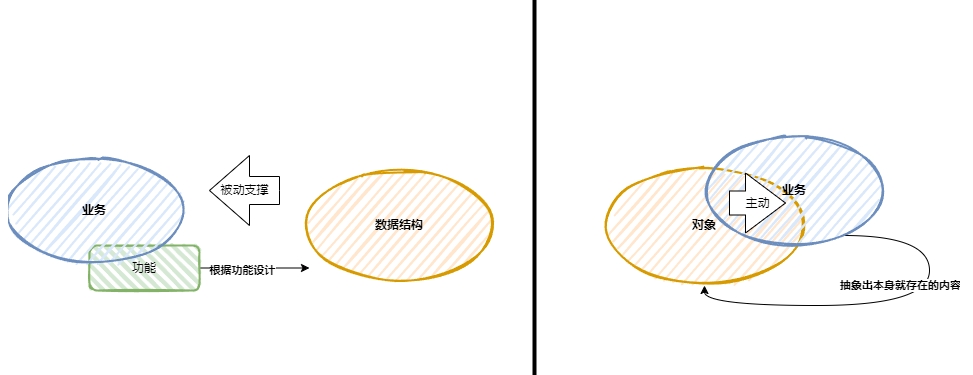
所有的模型、被二級制化的領域邏輯和數據都不可能一直活躍在內存中,而需要被存儲在數據庫或文件中。這時就要明確兩個概念,數據表和對象。數據表是一種數據結構,而對象是數據和行為,也就是說,數據結構中的數據是被外部的某些行為或函數操作的;雖然對象或類中封裝的屬性其實也是數據,但對象或類有行為方法,這些行為可以保護被封裝的屬性數據,外界需要改變對象中的屬性數據時,必須通過公開的行為方法才能實現。因此,對象和數據結構兩者的區別之一就在于對數據的操作是主動還是被動——對象是主動操作數據,而數據結構的數據是被動操作。相對于復雜業務的系統,主動操作數據更容易表達業務,因為業務領域中的業務策略或業務規則都需要動態操作去保證,它們的邏輯性和完整性需要主動操作數據來完成。
技術實現:
切斷數據與代碼強耦合
貧血模型之所以“不面向對象”的一個重要原因就是持久化層的固化,之前也說過了,伴隨著ORM和WEB技術的演進,數據持久層變得“公式化”,這種“公式化”造成了業務代碼與持久化的耦合。 如果不能將這部分代碼分離出去,領域層的獨立性就無從談起了。我們也不可能脫離技術復雜度而獨立開發領域邏輯,所以領域模型要想保持自己的獨立性,離不開存儲庫將其與持久化機制解耦。
貧血模式下很多情況是數據庫表、SQL模型、ORM配置、實體類到Service邏輯集于一人開發,這就導致了一個問題,當個人擁有“穿透權限”時是很容易忽視邊界感的,久而久之就會懈怠去維護層與層之間的邊界,業務模型與底層數據通道耦合,難以重構和復用。

解決這種情況技術上就要建立DDD中支撐域的概念,在業務之下,創建真正的數據層,數據層需要反向依賴業務層中定義的需求接口,即數據層是純技術實現層,實現參照就是各個領域中列出的interface類;對應的開發習慣也需要進行改變,即業務開發人員不要參與數據層的邏輯設計與開發,只需要在Domain中定義數據訴求接口即可,由專門的開發團隊去完成數據層或者說數據底座的開發,這樣能夠保證邊界感,同時也能防止代碼泛濫。通過支撐域數據層和核心域業務層的依賴倒置,實現代碼上的領域模型與數據的解耦。保證業務模型能夠在不受底層技術影響的情況下進行演化,讓我們可以獨立開發領域模型,無須關注架構的技術細節。
利用領域概念進行技術整合
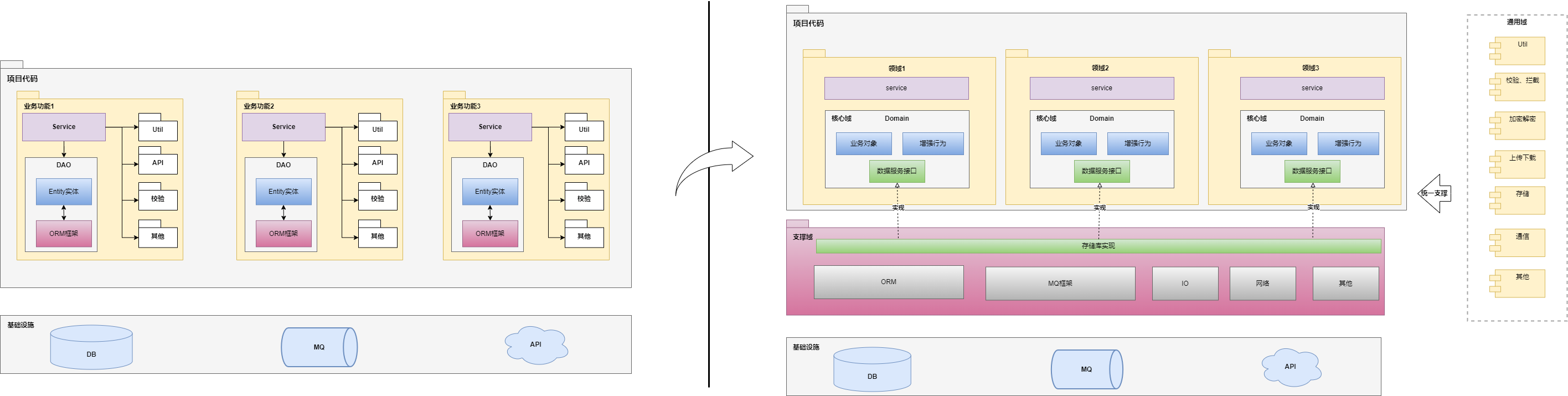
其實也不只是貧血模型,很多系統指數型熵增的一大原因就是技術、業務融為一體,業務除了本身的復雜性外還受限于技術的復雜性,兩者相互糾纏,不死不休。可以先借助DDD思想進行架構的修正,DDD其實并沒有給出明確的架構方案,只是提出了一個“立于不敗”境地的思路——領域劃分,而這種思路和“沒有一成不變的架構,架構是動態演進的”正正契合。
領域劃分中,可以有支撐域、通用域,此時,若是采取分層架構風格且體量較大的系統,則支撐域、通用域就可以作為基礎底座,以純技術的視角進行建設,對外部不可見。類似于上文中提到的數據層,僅僅對核心域暴露支撐接口,且這個接口還是由核心域提供。另外還包括包裝接口、描繪界面、參數校驗、數據封裝、、安全、性能、各類Util工具包等等。而核心領域則可以在這個基座之上拆分為單獨的module,配合整個平臺統一的數據支撐域、組件通用域,形成模塊化組裝形態,各個領域不依賴數據結構、數據獲取方式,而是提出數據需求,由支撐域完成核心域的需求,明確技術和業務的界限。
而對于微服務架構,DDD更多的是利用其領域劃分提供服務劃分依據(主要是核心域),技術上為保證各服務的獨立性,需要弱化支撐域、通用域的概念,轉而技術上將權限下放給各個服務,獨立的各個微服務內部可以有自身獨立的數據交互、數據持久化通道,保證各微服務的獨立管理和演進,這也正是微服務的一個討喜的點——技術上各服務不被條條框框所限制,發展空間較大。但是前提是微服務的劃分是合理的,而這個合理與否,就在于業務領域劃分是否合理。
最后
最后補充一個點,就是心理角色的轉換,切換領域驅動,不論是對研發還是產品經理亦或是其他設計分析人員都是個挑戰,尤其研發人員,作為設計和落地的集中點,更要有成為領域專家的準備。意味著要有等同于產品的業務認識,一起參與需求的分析、業務領域的規劃,而不是拘泥于“一招一式”的具體功能和編碼。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號